
Go语言网络爬虫:2025年分步教程
Senior Web Scraping Engineer
大多数用Go语言编写的较大规模网页抓取项目,都始于使用Go语言网页爬虫来发现和组织URL。此工具允许你导航到初始目标域名(也称为“种子URL”),并递归地访问页面上的链接以发现更多链接。
本指南将教你如何构建和优化Go语言网页爬虫,并使用真实的案例进行讲解。在深入学习之前,你还会获得一些有用的补充信息。
事不宜迟,让我们看看今天为你准备了什么有趣的东西吧!
什么是网页爬取?
网页爬取的核心是系统地导航网站以提取有用的数据。网页爬虫(通常称为蜘蛛)获取网页,解析其内容,并处理信息以满足特定目标,例如索引或数据聚合。让我们分解一下:
网页爬虫发送HTTP请求以从服务器检索网页并处理响应。把它想象成你的爬虫和网站之间的一次礼貌的握手——“你好,我可以拿你的数据去转转吗?”
一旦获取页面,爬虫就会通过解析HTML来提取相关数据。DOM结构有助于将页面分解成易于管理的块,而CSS选择器则像一把精确的镊子,挑选出你需要的元素。
大多数网站将其数据分散在多个页面上。爬虫需要在尊重速率限制的同时,导航这个分页的迷宫,避免看起来像一个服用类固醇的饥饿数据机器人。
为什么Go语言在2025年非常适合网页爬取
如果网页爬取是一场竞赛,Go语言将是你车库里想要的那辆跑车。它独特的特性使其成为现代网页爬虫的首选语言。
- 并发性: Go语言的goroutine允许你同时发出多个请求,比你喊出“并行处理”的速度还要快地抓取数据。
- 简洁性: 该语言简洁的语法和极简的设计使你的代码库易于管理,即使是在处理复杂的爬取项目时也是如此。
- 性能: Go语言是编译型语言,这意味着它运行速度极快——非常适合处理大型网页爬取任务,而不会费力。
- 强大的标准库: Go语言的标准库内置支持HTTP请求、JSON解析等等,为你从零开始构建爬虫提供了所需的一切。
为什么还要费力地使用笨重的工具,当你可以用Go语言像喝了咖啡因的土拨鼠一样快速地浏览数据呢?Go语言结合了速度、简洁性和强大的功能,使其成为高效有效地爬取网页的终极选择。
爬取网站是否合法?
网页爬取的合法性并非一概而论。它取决于你如何、在哪里以及为什么爬取。虽然抓取公共数据通常是可以接受的,但违反服务条款或绕过反抓取措施可能会导致法律纠纷。
为了遵守法律,以下是一些黄金法则:
- 遵守robots.txt指令。
- 避免抓取敏感或受限制的信息。
- 如果你不确定某个网站的政策,请寻求许可。
如何构建你的第一个Go语言网页爬虫?
预备条件
- 确保你安装了最新版本的Go。你可以从官方Go语言网站下载安装包并按照说明进行安装。
- 选择你喜欢的IDE。本教程使用Goland作为编辑器。
- 选择一个你熟悉的Go网页抓取库。在这个例子中,我们将使用chromedp。
要验证你的Go安装,请在终端中输入以下命令:
PowerShell
go version如果安装成功,你将看到以下结果:
PowerShell
go version go1.23.4 windows/amd64创建你的工作目录,进入后,输入以下命令:
- 初始化
go mod:
PowerShell
go mod init crawl- 安装
chromedp依赖项:
PowerShell
go get github.com/chromedp/chromedp- 创建
crawl.go文件。
现在我们可以开始编写你的网页抓取代码了。
获取页面元素
访问Lazada,并使用浏览器的开发者工具(F12)轻松识别你需要的页面元素和选择器。
- 获取输入字段及其旁边的搜索按钮:
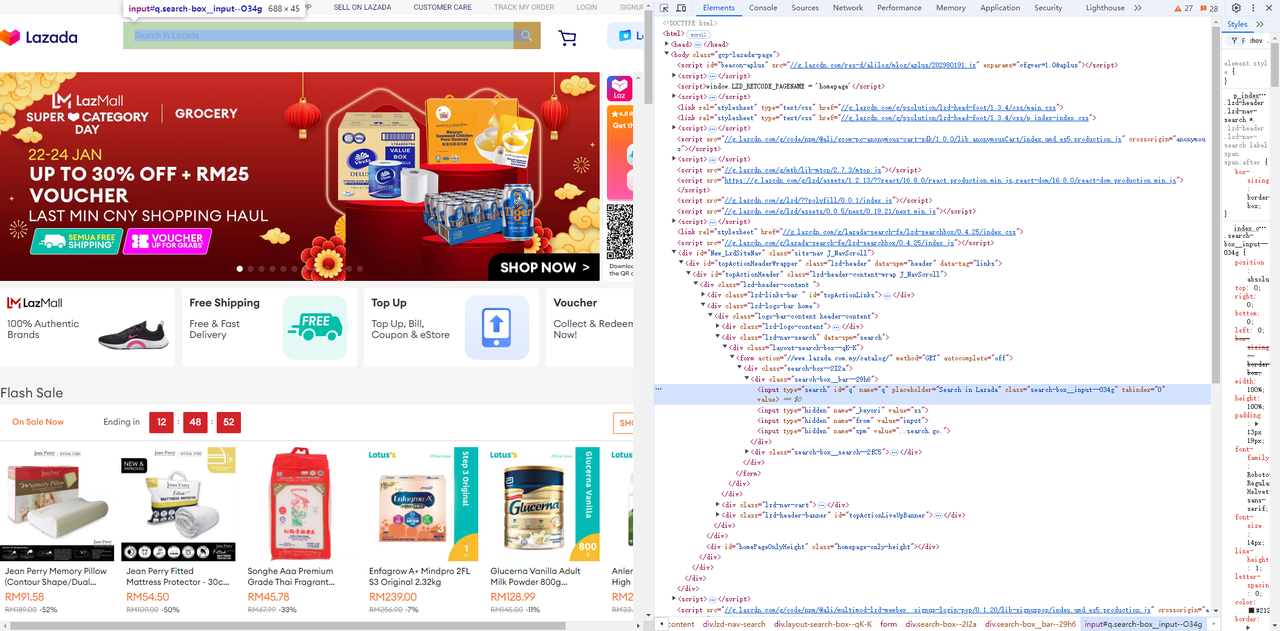
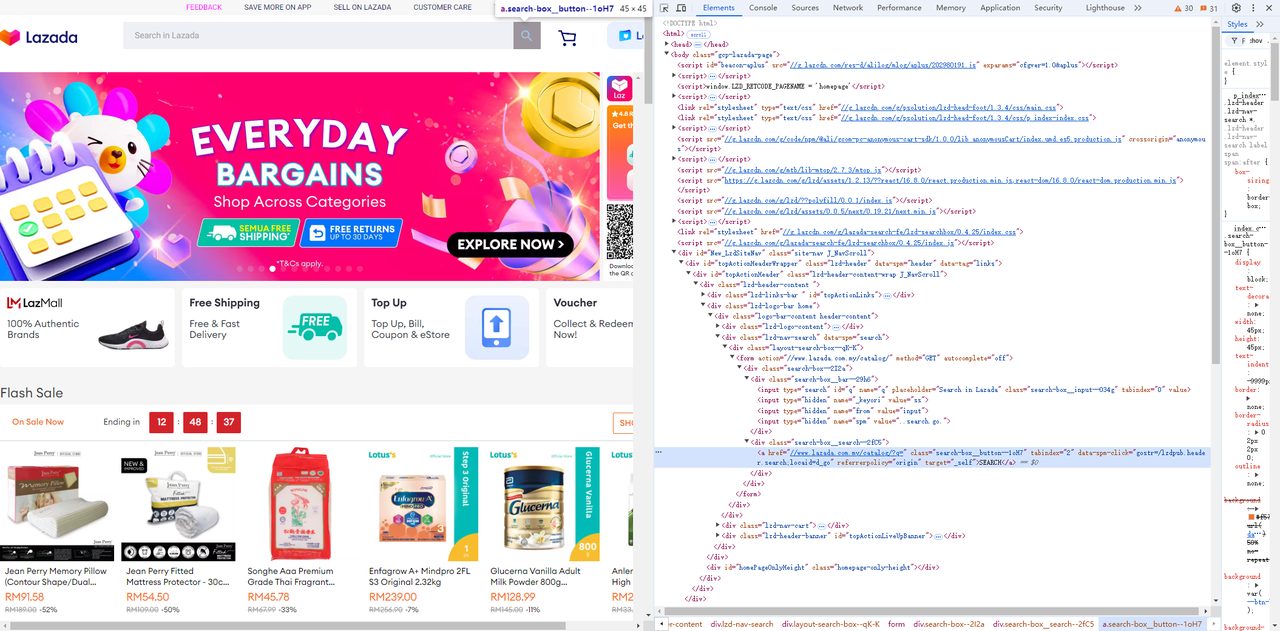
Go
func searchProduct(keyword string) chromedp.Tasks {
return chromedp.Tasks{
// 等待输入元素可见
chromedp.WaitVisible(`input[type=search]`, chromedp.ByQuery),
// 输入搜索产品。
chromedp.SendKeys("input[type=search]", keyword, chromedp.ByQuery),
// 点击搜索
chromedp.Click(".search-box__button--1oH7", chromedp.ByQuery),
}
}- 从产品列表中获取价格、标题和图像元素:
-
产品列表
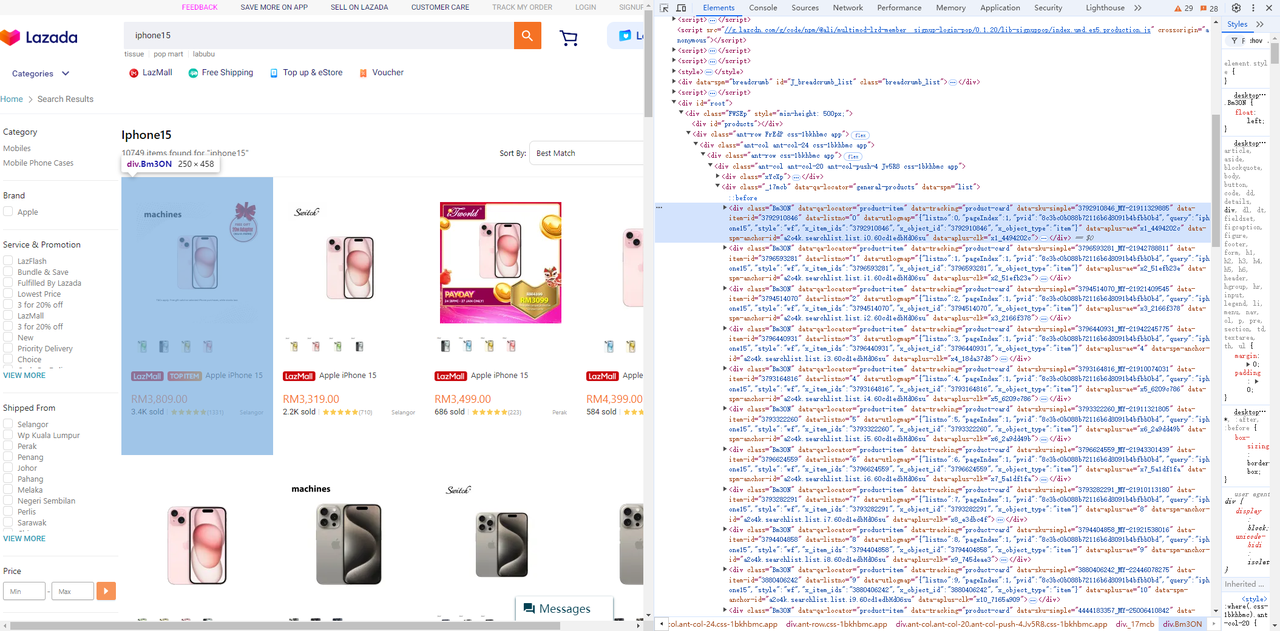
-
图片元素
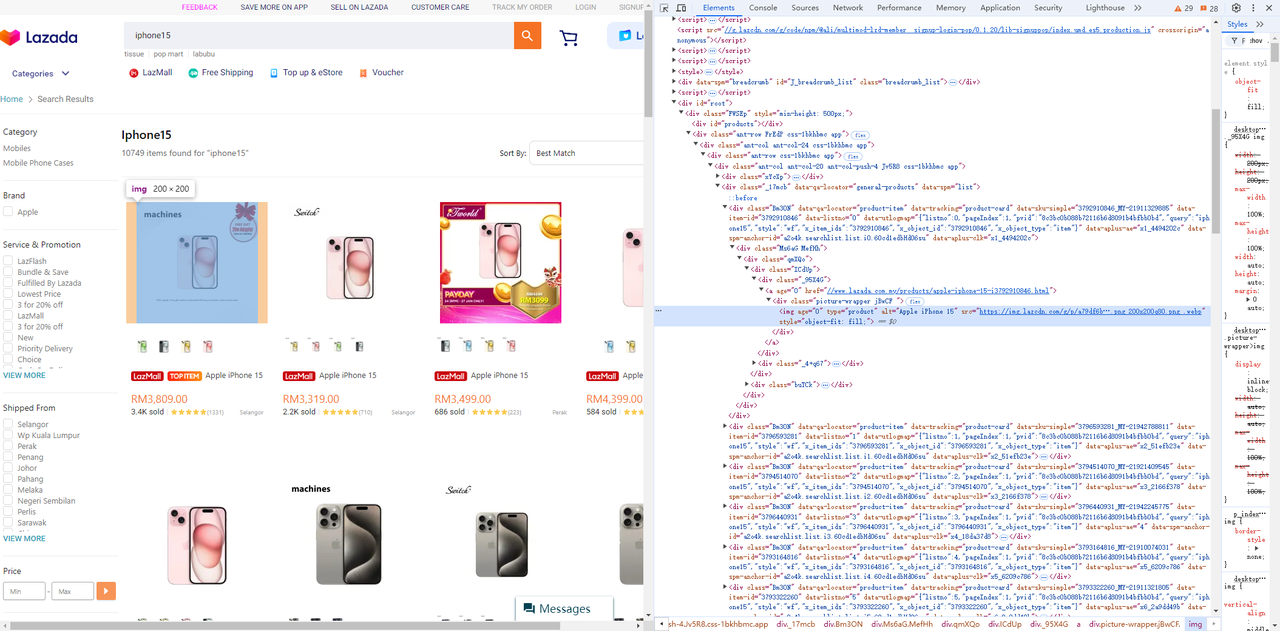
-
标题元素
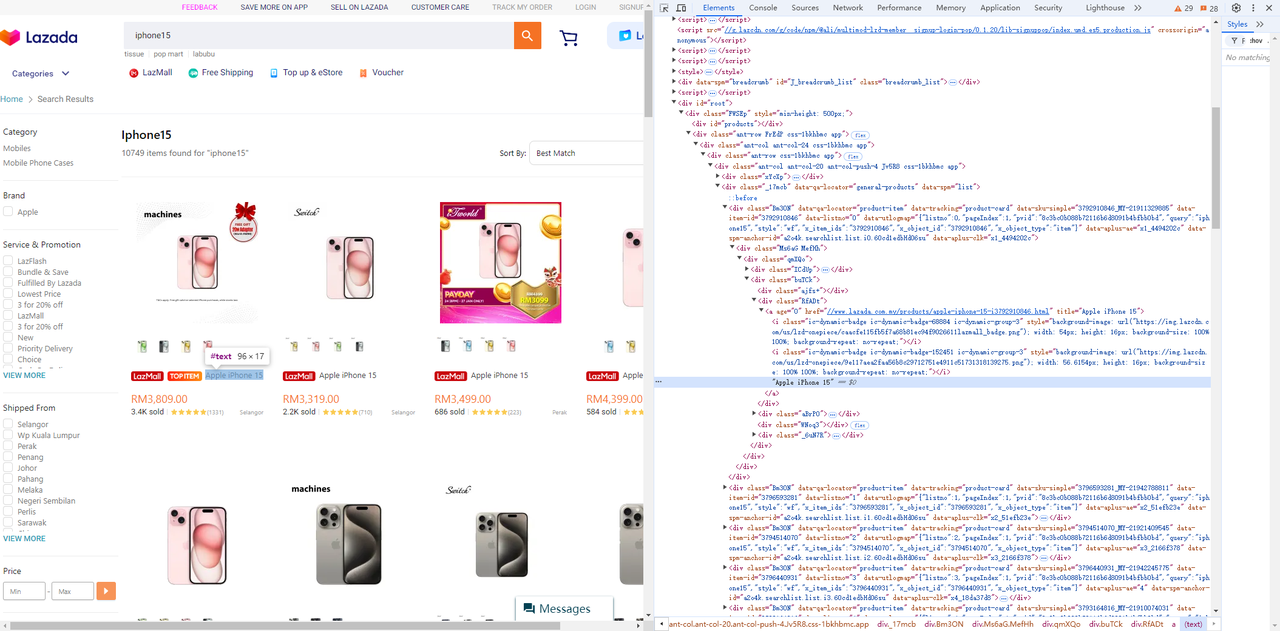
-
价格元素
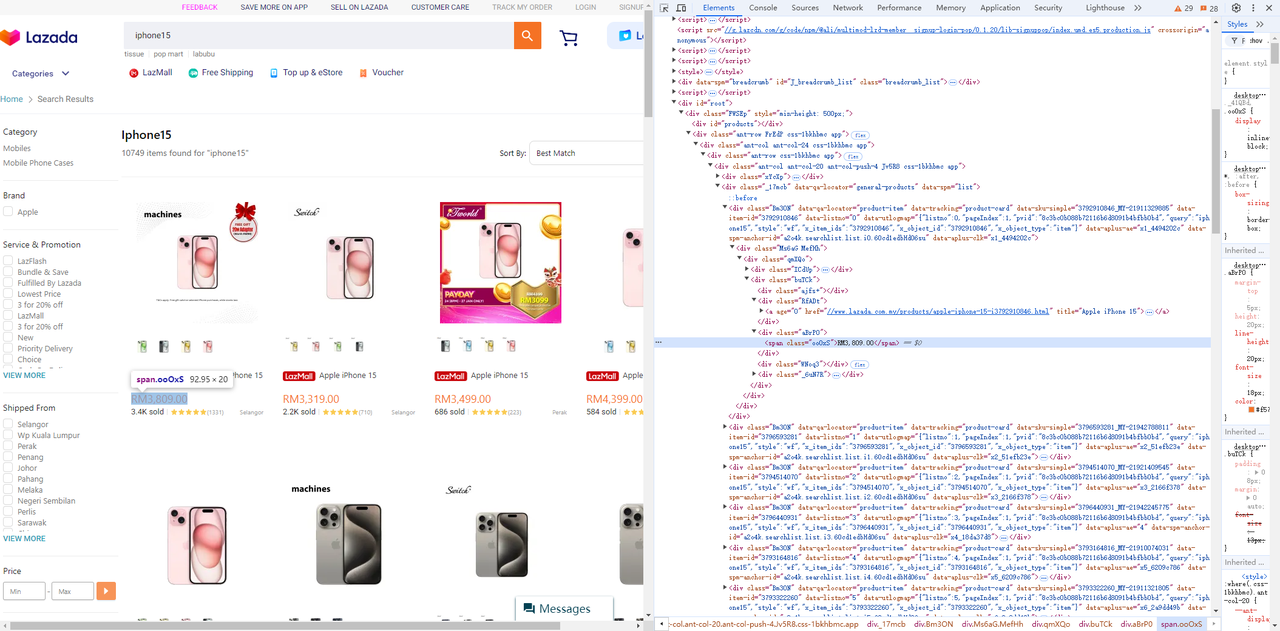
Go
func getNodes(nodes *[]*cdp.Node) chromedp.Tasks {
return chromedp.Tasks{
chromedp.WaitReady(`div[data-spm=list] .Bm3ON`, chromedp.ByQuery),
scrollToBottom(), // 滚动到底部以确保所有页面元素都已呈现。
chromedp.Nodes("div[data-spm=list] .Bm3ON", nodes, chromedp.ByQueryAll),
}
}
func scrollToBottom() chromedp.Action {
return chromedp.ActionFunc(func(ctx context.Context) error {
for i := 0; i < 4; i++ { // 重复滚动以确保所有图片都已加载。
_ = chromedp.Evaluate("window.scrollBy(0, window.innerHeight);", nil).Do(ctx)
time.Sleep(1 * time.Second)
}
return nil
})
}
func getProductData(ctx context.Context, node *cdp.Node) (*Product, error) {
product := new(Product)
err := chromedp.Run(ctx,
chromedp.WaitVisible(".Bm3ON img[type=product]", chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON img[type=product]", "src", &product.Img, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON .RfADt a", "title", &product.Title, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.TextContent(".Bm3ON .aBrP0 span", &product.Price, chromedp.ByQuery, chromedp.FromNode(node)),
)
if err != nil {
return nil, err
}
return product, nil
}设置Chrome环境
为了更方便的调试,我们可以在PowerShell中启动一个Chrome浏览器并指定一个远程调试端口。
PowerShell
chrome.exe --remote-debugging-port=9223我们可以访问http://localhost:9223/json/list来检索浏览器公开的远程调试地址webSocketDebuggerUrl。
PowerShell
[
{
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=localhost:9223/devtools/page/85CE4D807D11D30D5F22C1AA52461080",
"id": "85CE4D807D11D30D5F22C1AA52461080",
"title": "localhost:9223/json/list",
"type": "page",
"url": "http://localhost:9223/json/list",
"webSocketDebuggerUrl": "ws://localhost:9223/devtools/page/85CE4D807D11D30D5F22C1AA52461080"
}
]运行代码
完整的代码如下:
Go
package main
import (
"context"
"encoding/json"
"flag"
"log"
"time"
"github.com/chromedp/cdproto/cdp"
"github.com/chromedp/chromedp"
)
type Product struct {
ID string `json:"id"`
Img string `json:"img"`
Price string `json:"price"`
Title string `json:"title"`
}
func main() {
product := flag.String("product", "iphone15", "你的产品关键词")
url := flag.String("webSocketDebuggerUrl", "", "你的websocket url")
flag.Parse()
var baseCxt context.Context
if *url != "" {
baseCxt, _ = chromedp.NewRemoteAllocator(context.Background(), *url)
} else {
baseCxt = context.Background()
}
ctx, cancel := chromedp.NewContext(
baseCxt,
)
defer cancel()
var nodes []*cdp.Node
err := chromedp.Run(ctx,
chromedp.Navigate(`https://www.lazada.com.my/`),
searchProduct(*product),
getNodes(&nodes),
)
products := make([]*Product, 0, len(nodes))
for _, v := range nodes {
product, err := getProductData(ctx, v)
if err != nil {
log.Println("运行节点任务错误:", err)
continue
}
products = append(products, product)
}
if err != nil {
log.Fatal(err)
}
jsonData, _ := json.Marshal(products)
log.Println(string(jsonData))
}
func searchProduct(keyword string) chromedp.Tasks {
return chromedp.Tasks{
// 等待输入元素可见
chromedp.WaitVisible(`input[type=search]`, chromedp.ByQuery),
// 输入搜索产品。
chromedp.SendKeys("input[type=search]", keyword, chromedp.ByQuery),
// 点击搜索
chromedp.Click(".search-box__button--1oH7", chromedp.ByQuery),
}
}
func getNodes(nodes *[]*cdp.Node) chromedp.Tasks {
return chromedp.Tasks{
chromedp.WaitReady(`div[data-spm=list] .Bm3ON`, chromedp.ByQuery),
scrollToBottom(), // 滚动到底部以确保所有页面元素都已呈现。
chromedp.Nodes("div[data-spm=list] .Bm3ON", nodes, chromedp.ByQueryAll),
}
}
func scrollToBottom() chromedp.Action {
return chromedp.ActionFunc(func(ctx context.Context) error {
for i := 0; i < 4; i++ { // 重复滚动以确保所有图片都已加载。
_ = chromedp.Evaluate("window.scrollBy(0, window.innerHeight);", nil).Do(ctx)
time.Sleep(1 * time.Second)
}
return nil
})
}
func getProductData(ctx context.Context, node *cdp.Node) (*Product, error) {
product := new(Product)
err := chromedp.Run(ctx,
chromedp.WaitVisible(".Bm3ON img[type=product]", chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON img[type=product]", "src", &product.Img, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON .RfADt a", "title", &product.Title, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.TextContent(".Bm3ON .aBrP0 span", &product.Price, chromedp.ByQuery, chromedp.FromNode(node)),
)
if err != nil {
return nil, err
}
product.ID = node.AttributeValue("data-item-id")
return product, nil
}通过运行以下命令,你将检索到抓取的数据结果:
PowerShell
go run .\crawl.go -product="你的关键词" -webSocketDebuggerUrl="你的WEBSOCKETDEBUGGERURL"
JSON
[
{
"id": "3792910846",
"img": "https://img.lazcdn.com/g/p/a79df6b286a0887038c16b7600e38f4f.png_200x200q75.png_.webp",
"price": "RM3,809.00",
"title": "Apple iPhone 15"
},
{
"id": "3796593281",
"img": "https://img.lazcdn.com/g/p/627828b5fa28d708c5b093028cd06069.png_200x200q75.png_.webp",
"price": "RM3,319.00",
"title": "Apple iPhone 15"
},
{
"id": "3794514070",
"img": "https: //img.lazcdn.com/g/p/6f4ddc2693974398666ec731a713bcfd.jpg_200x200q75.jpg_.webp",
"price": "RM3,499.00",
"title": "Apple iPhone 15"
},
{
"id": "3796440931",
"img": "https://img.lazcdn.com/g/p/8df101af902d426f3e3a9748bafa7513.jpg_200x200q75.jpg_.webp",
"price": "RM4,399.00",
"title": "Apple iPhone 15"
},
......
{
"id": "3793164816",
"img": "https://img.lazcdn.com/g/p/b6c3498f75f1215f24712a25799b0d19.png_200x200q75.png_.webp",
"price": "RM3,799.00",
"title": "Apple iPhone 15"
},
{
"id": "3793322260",
"img": "https: //img.lazcdn.com/g/p/67199db1bd904c3b9b7ea0ce32bc6ace.png_200x200q75.png_.webp",
"price": "RM5,644.00",
"title": "[Ready Stock] Apple iPhone 15 Pro"
},
{
"id": "3796624559",
"img": "https://img.lazcdn.com/g/p/81a814a9c829afa200fbc691c9a0c30c.png_200x200q75.png_.webp",
"price": "RM6,679.00",
"title": "Apple iPhone 15 Pro (1TB)"
}
]可扩展网页爬虫的高级技术
你的网页爬虫需要改进!为了有效地收集数据而不会被阻止或超载,你必须实施在速度、可靠性和资源优化之间取得平衡的技术。
让我们探索一些高级策略,以确保你的爬虫在繁重的工作负载下也能出色地工作。
维持你的请求和会话
在进行网页爬取时,在短时间内向服务器发送过多请求肯定会让你被检测到并被封禁。网站通常会监控来自同一客户端的请求频率,突然的激增可能会触发反机器人机制。
Go
package main
import (
"fmt"
"io/ioutil"
"net/http"
"time"
)
func main() {
// 创建可重用的HTTP客户端
client := &http.Client{}
// 要爬取的URL
urls := []string{
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3",
}
// 请求之间的间隔(例如,2秒)
requestInterval := 2 * time.Second
for _, url := range urls {
// 创建一个新的HTTP请求
req, _ := http.NewRequest("GET", url, nil)
req.Header.Set("User-Agent", "Mozilla/5.0 (compatible; WebCrawler/1.0)")
// 发送请求
resp, err := client.Do(req)
if err != nil {
fmt.Println("错误:", err)
continue
}
// 读取并打印响应
body, _ := ioutil.ReadAll(resp.Body)
fmt.Printf("来自 %s 的响应:\n%s\n", url, body)
resp.Body.Close()
// 等待发送下一个请求
time.Sleep(requestInterval)
}
}避免重复链接
没有什么比浪费资源两次爬取相同的URL更糟糕的了。通过维护一个URL集合(例如,哈希映射或Redis数据库)来跟踪已访问的页面,从而实现强大的重复数据删除系统。这不仅可以节省带宽,还可以确保你的爬虫高效运行,并且不会错过新页面。
代理管理以避免IP封禁
大规模抓取通常会触发反机器人措施,从而导致IP被封禁。为避免这种情况,请将代理轮换集成到你的爬虫中。
- 使用代理池将请求分散到多个IP地址。
- 轮换代理以动态方式使你的请求看起来像是来自不同用户和位置。
优先处理特定页面
优先处理特定页面有助于简化你的爬取过程,并让你专注于爬取可用的链接。在当前的爬虫中,我们使用CSS选择器来仅定位分页链接并提取有价值的产品信息。
但是,如果你对页面上的所有链接感兴趣,并且想要优先处理分页,你可以维护一个单独的队列并首先处理分页链接。
Go
package main
import (
"fmt"
"github.com/gocolly/colly"
)
// ...
// 创建变量以将分页链接与其他链接分开
var paginationURLs = []string{}
var otherURLs = []string{}
func main() {
// ...
}
func crawl (currenturl string, maxdepth int) {
// ...
// ----- 查找并访问所有链接 ---- //
// 选择所有锚标记的 href 属性
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
// 获取绝对URL
link := e.Request.AbsoluteURL(e.Attr("href"))
// 检查当前URL是否已被访问
if link != "" && !visitedurls[link] {
// 将当前URL添加到visitedURLs
visitedurls[link] = true
if e.Attr("class") == "page-numbers" {
paginationURLs = append(paginationURLs, link)
} else {
otherURLs = append(otherURLs, link)
}
}
})
// ...
// 首先处理分页链接
for len(paginationURLs) > 0 {
nextURL := paginationURLs[0]
paginationURLs = paginationURLs[1:]
visitedurls[nextURL] = true
err := c.Visit(nextURL)
if err != nil {
fmt.Println("访问页面时出错:", err)
}
}
// 处理其他链接
for len(otherURLs) > 0 {
nextURL := otherURLs[0]
otherURLs = otherURLs[1:]
visitedurls[nextURL] = true
err := c.Visit(nextURL)
if err != nil {
fmt.Println("访问页面时出错:", err)
}
}
}Scrapeless抓取API:有效的爬取工具
为什么Scrapeless抓取API更理想?
Scrapeless抓取API旨在简化从网站提取数据的过程,它可以导航最复杂的网络环境,有效地管理动态内容和JavaScript渲染。
此外,Scrapeless抓取API利用跨越195个国家的全球网络,并支持访问超过7000万个住宅IP。凭借99.9%的正常运行时间和卓越的成功率,Scrapeless轻松克服了IP封锁和CAPTCHA等挑战,使其成为复杂网络自动化和人工智能驱动的数据收集的强大解决方案。
使用我们先进的抓取API,你可以访问所需的数据,而无需编写或维护复杂的抓取脚本!
抓取API的优势
Scrapeless支持高性能JavaScript渲染,允许它处理动态内容(例如通过AJAX或JavaScript加载的数据)并抓取依赖于JS进行内容交付的现代网站。
- 经济实惠的价格: Scrapeless旨在提供超值的性价比。
- 稳定性和可靠性: Scrapeless凭借其久经考验的记录,即使在高工作负载下也能提供稳定的API响应。
- 高成功率: 向提取失败告别,Scrapeless承诺99.99%成功访问Google SERP数据。
- 可扩展性: 借助Scrapeless背后的强大基础设施,轻松处理数千个查询。
立即获取廉价且强大的Scrapeless抓取API!
Scrapeless提供可靠且可扩展的网页抓取平台,价格具有竞争力,为其用户确保卓越的价值:
- 抓取浏览器: 每小时0.09美元起
- 抓取API: 每1k个URL 1.00美元起
- 网页解锁器: 每1k个URL 0.20美元
- 验证码求解器: 每1k个URL 0.80美元起
- 代理: 每GB 2.80美元
通过订阅,你可以在每项服务上享受高达20%的折扣。你是否有特定的需求?今天就联系我们,我们将根据你的需求提供更大的节省!
如何使用Scrapeless抓取API?
使用Scrapeless抓取API来爬取Lazada数据非常容易。你只需要一个简单的请求就可以获得所有想要的数据。如何快速调用Scrapeless API?请按照我的步骤操作:
- 步骤1。登录Scrapeless
- 步骤2。点击“抓取API”
- 步骤3。找到我们的“Lazada”API并输入:
- 步骤4。在左侧的操作框中填写想要爬取的产品的完整信息。当你使用
chromedp来爬取数据时,你已经获得了爬取产品的ID。现在你只需要将ID添加到itemId参数中即可获得关于该产品的更多详细信息。然后选择你想要的表达式语言:
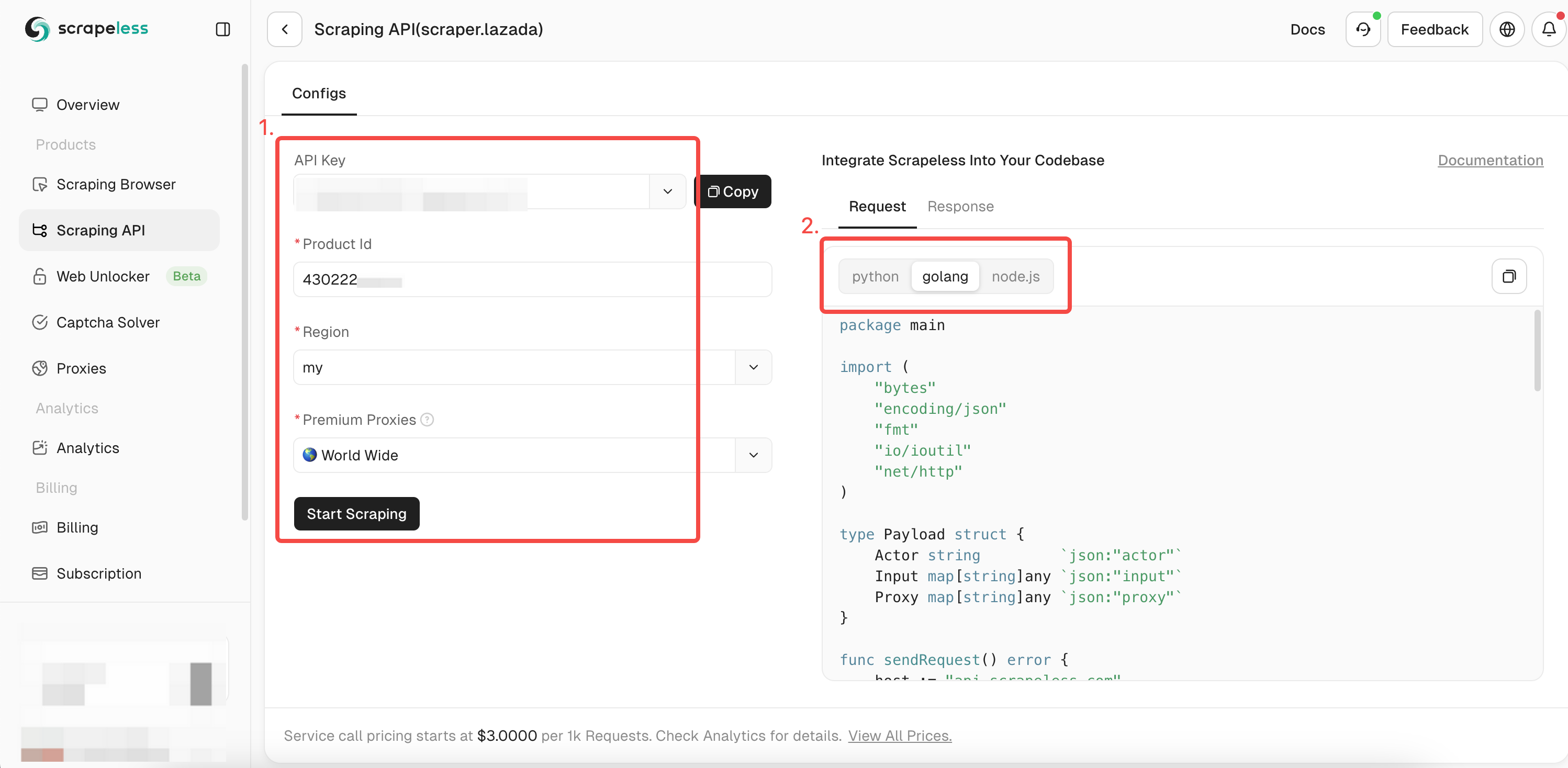
- 步骤5。点击“开始抓取”,产品抓取结果将显示在右侧的预览框中:
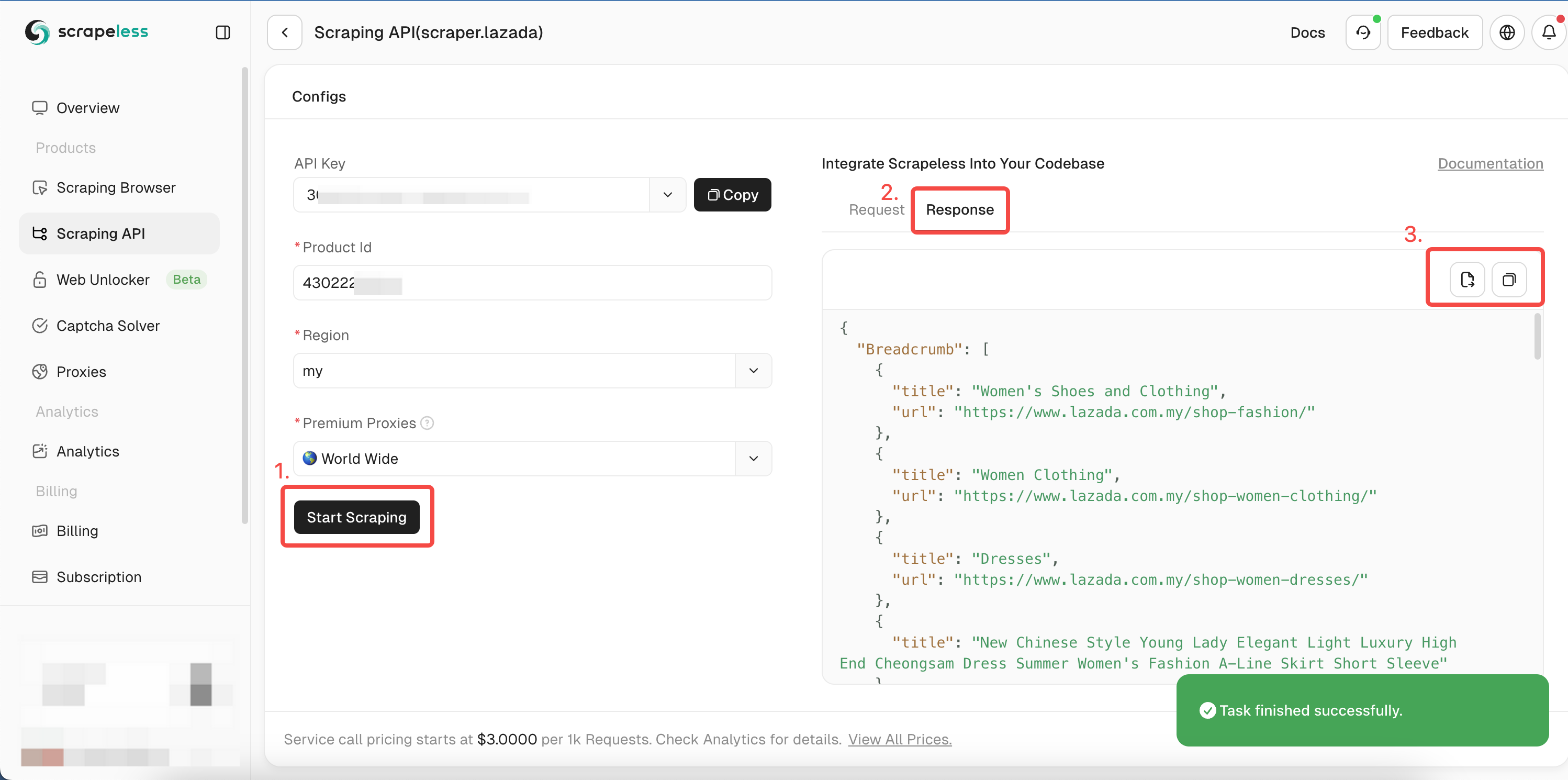
你可以参考我们的Go语言示例代码,或访问我们的API文档以了解其他语言。
Go
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
type Payload struct {
Actor string `json:"actor"`
Input map[string]any `json:"input"`
Proxy map[string]any `json:"proxy"`
}
func sendRequest() error {
host := "api.scrapeless.com"
url := fmt.Sprintf("https://%s/api/v1/scraper/request", host)
token := "你的TOKEN"
headers := map[string]string{"x-api-token": token}
inputData := map[string]any{
"itemId": "3792910846", // 用你想要获取的itemId替换。
"site": "my",
}
proxy := map[string]any{
"country": "ANY",
}
payload := Payload{
Actor: "scraper.lazada",
Input: inputData,
Proxy: proxy,
}
jsonPayload, err := json.Marshal(payload)
if err != nil {
return err
}
req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonPayload))
if err != nil {
return err
}
for key, value := range headers {
req.Header.Set(key, value)
}
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
fmt.Printf("body %s\n", string(body))
return nil
}
func main() {
err := sendRequest()
if err != nil {
fmt.Println("错误:", err)
return
}
}运行后,你将获得以下详细信息数据。包括链接、图片、SKU、评论、相同卖家等等。
由于篇幅限制,我们这里只展示部分抓取结果。您可以访问我们的 Dashboard 并获取免费试用来快速抓取并获得完整的抓取结果!
JSON
{
"Breadcrumb": [
{
"title": "手机与平板",
"url": "https://www.lazada.com.my/shop-mobiles-tablets/"
},
{
"title": "智能手机",
"url": "https://www.lazada.com.my/shop-mobiles/"
},
{
"title": "Apple iPhone 15"
}
],
"deliveryOptions": {
"21911329880": [
{
"badge": false,
"dataType": "delivery",
"deliveryWorkTimeMax": "2025-01-27T23:27+08:00[GMT+08:00]",
"deliveryWorkTimeMin": "2025-01-24T23:27+08:00[GMT+08:00]",
"description": "对于本地商品,您可以在2-4个工作日内收到您的商品。<br/>运费由从卖家购买的商品的总大小/重量决定。<br/><br/><a href=\"https://www.lazada.com.my/helpcenter/shipping_delivery/#answer-faq-whatisshippingfee-ans\" target=\"_blank\">了解更多</a>",
"duringTime": "保证在1月24日至27日之间",
"fee": "RM4.90",
"feeValue": 4.9,
"hasTip": true,
"title": "标准配送",
"type": "standard"
},
{
"badge": true,
"dataType": "service",
"description": "",
"feeValue": 0,
"hasTip": true,
"title": "不支持货到付款",
"type": "noCOD"
}
],
"21911329881": [
{
"badge": false,
"dataType": "delivery",
"deliveryWorkTimeMax": "2025-01-27T23:27+08:00[GMT+08:00]",
"deliveryWorkTimeMin": "2025-01-24T23:27+08:00[GMT+08:00]",
"description": "对于本地商品,您可以在2-4个工作日内收到您的商品。<br/>运费由从卖家购买的商品的总大小/重量决定。<br/><br/><a href=\"https://www.lazada.com.my/helpcenter/shipping_delivery/#answer-faq-whatisshippingfee-ans\" target=\"_blank\">了解更多</a>",
"duringTime": "保证在1月24日至27日之间",
"fee": "RM4.90",
"feeValue": 4.9,
"hasTip": true,
"title": "标准配送",
"type": "standard"
},
{
"badge": true,
"dataType": "service",
"description": "",
"feeValue": 0,
"hasTip": true,
"title": "不支持货到付款",
"type": "noCOD"
}
],
...进一步阅读
Go语言爬取最佳实践和注意事项
并行爬取和并发
同步抓取多个页面可能会导致效率低下,因为任何给定时间只有一个goroutine可以主动处理任务。你的网页爬虫大部分时间都在等待响应和处理数据,然后才继续下一个任务
但是,利用Go的并发功能来尝试并发爬取可以显著减少你的整体爬取时间!
但是,你必须适当地管理并发,以避免压垮目标服务器并触发反机器人限制。
在Go中爬取JavaScript渲染的页面
虽然Colly是一个很棒的网页爬虫工具,具有许多内置功能,但它无法爬取JavaScript渲染的页面(动态内容)。它只能获取和解析静态HTML,而动态内容并不存在于网站的静态HTML中。
但是,你可以与无头浏览器或JavaScript引擎集成以爬取动态内容。
结束语
你学习了如何使用高级编程构建Go语言网页爬虫。请记住,虽然构建网页抓取程序来浏览网页是一个很好的起点,但你必须克服反机器人措施才能访问现代网站。
与其费力地进行可能失败的手动配置,不如考虑使用Scrapeless抓取API,这是绕过任何反机器人系统的最可靠解决方案。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


