
如何绕过Cloudflare挑战:2025年完整指南
Advanced Data Extraction Specialist
Cloudflare不断发展其安全措施,使得传统抓取方法越来越难以绕过诸如cloudflare-challenge和Cloudflare Turnstile等挑战。由于Cloudflare的更新,开源工具如FlareSolverr已变得无效,导致开发者不得不寻找新的解决方案。
在本指南中,我们将探索2025年绕过Cloudflare安全挑战的最有效方法,包括:
- Scrapeless Scraping Browser – 一个无头浏览器API,实现无缝抓取
- Scrapeless Web Unlocker – 一种强大的JS渲染和交互API
无论您是网页自动化专家还是初学者,本指南提供逐步解决方案,帮助您提取数据而不遇到障碍。
第一部分:理解Cloudflare挑战和安全层
在深入解决方案之前,理解Cloudflare的关键安全机制是至关重要的,这些机制阻止自动请求:
1. Cloudflare JS Challenge
Cloudflare JavaScript挑战(cloudflare-challenge)要求浏览器在访问请求页面之前执行一个脚本。这个脚本生成一个存储在cookies中的清除令牌(cf_clearance)。没有JavaScript执行能力的机器人和抓取工具会未能通过此挑战。
2. Cloudflare Turnstile
Turnstile是Cloudflare的CAPTCHA替代品,动态检测非人类流量。它通常需要执行JavaScript和行为跟踪才能完成。
3. 浏览器指纹识别
Cloudflare使用先进的指纹识别技术检测非人类交互。这包括分析:
- TLS指纹识别(JA3签名)
- HTTP头部和顺序
- WebGL、Canvas和音频指纹识别
4. 限速和IP禁令
即使您一次绕过了挑战,从同一IP的重复请求也可能触发禁令或提高安全级别。
第二部分:Cloudflare JS Challenge与其他挑战的不同之处
与需要用户交互的CAPTCHA不同,JS挑战在后台自动运行,对于合法用户来说,干扰较少,同时仍然阻止可疑流量。然而,对于网页抓取工具和自动化工具来说,绕过JS挑战可能具有挑战性,因为许多基本的HTTP客户端和无头浏览器无法正确执行JavaScript。
第三部分:使用Scrapeless Scraping Browser绕过Cloudflare JS挑战
3.1 什么是Scrapeless Scraping Browser?
Scrapeless Scraping Browser是一种高性能解决方案,提供无头浏览器环境,使您无需维护自己的基础设施即可绕过JavaScript挑战。它与Puppeteer和Playwright集成,实现无缝自动化。
Scrapeless Scraping Browser是最先进的Cloudflare绕过工具,它提供:
✔️ 99.9%的成功率绕过Cloudflare挑战
✔️ 与Puppeteer / Playwright的无缝兼容
✔️ 基于AI,自动适应最新安全政策
✔️ 全球代理支持,减少被禁的风险
3.2 设置与API密钥配置
在使用Scrapeless Scraping Browser之前,请获取一个API密钥:
- 在Scrapeless仪表板上注册
- 从设置标签中获取您的API密钥
🎁 新用户可获得10000个免费API请求! 立即注册
3.3 使用Scrapeless Browser实现Cloudflare绕过
当我们连接到浏览器以访问目标网站时,Scrapeless会自动检测并解决CAPTCHA。然而,我们需要确保CAPTCHA已经成功解决。我们如何实现这一点?好消息!Scrapeless Scraping Browser扩展了标准CDP(Chrome DevTools Protocol),提供一组强大的自定义功能。
您可以通过检查CDP API返回的结果直接观察CAPTCHA解决器的状态:
Captcha.detected:检测到CAPTCHACaptcha.solveFinished: CAPTCHA 成功解决Captcha.solveFailed: CAPTCHA 解决失败
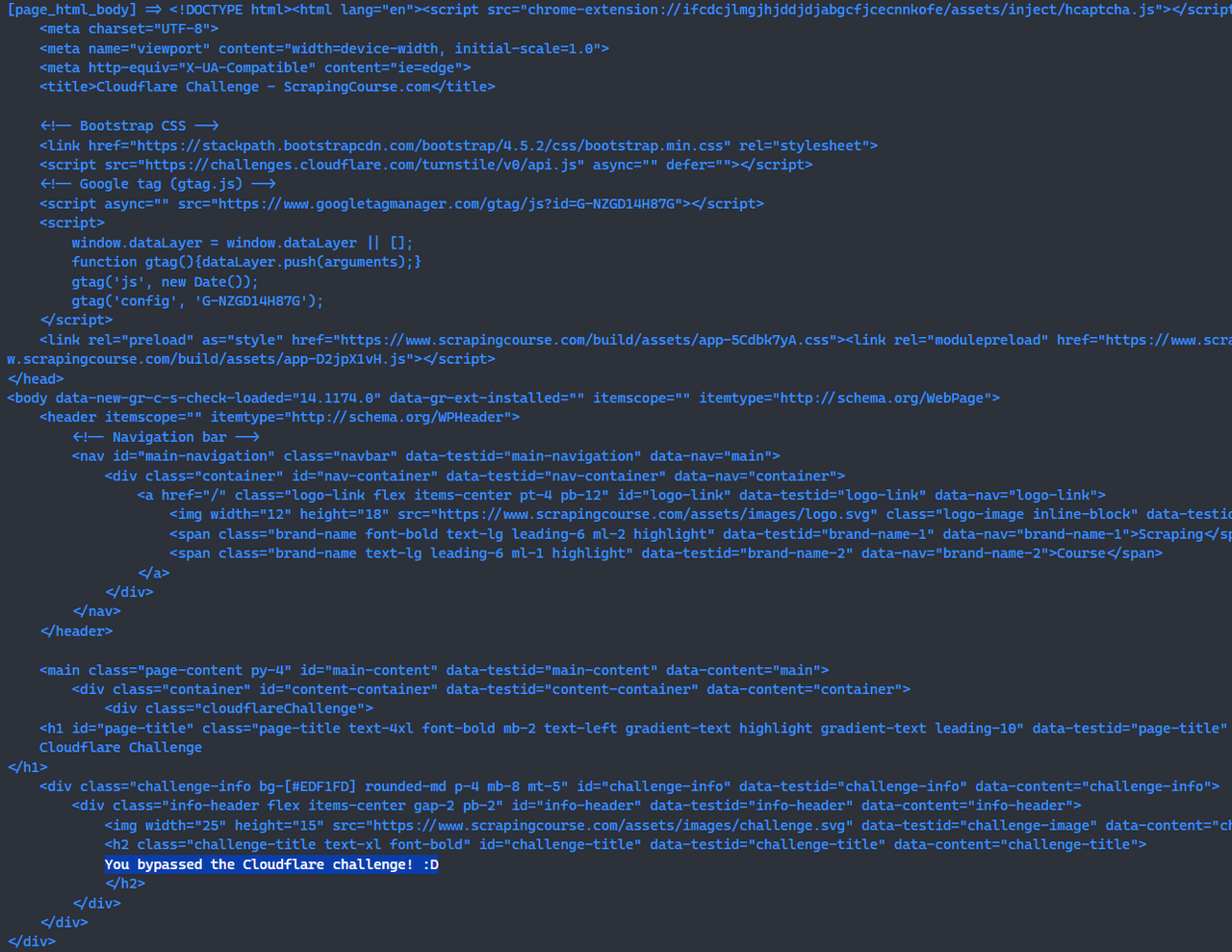
接下来,我们使用scrapeless browserless直接访问cloudflare-challenge测试网站并添加截图,这使我们能够非常直观地看到效果。拍摄截图之前,请注意需要使用waitForSelector等待页面上的元素,确保Cloudflare挑战已成功绕过。
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {waitUntil: 'domcontentloaded'});
// 通过等待页面上的元素,确保Cloudflare挑战已成功绕过。
await page.waitForSelector('main.page-content .challenge-info', {timeout: 30 * 1000})
await page.screenshot({path: 'challenge-bypass.png'});恭喜你! 🎉 你使用scrapeless browserless成功绕过了Cloudflare挑战。

检索cf_clearanceCookie和请求头
此外,在通过Cloudflare挑战后,你还可以从成功页面检索请求头和cf_clearance cookie。
const cookies = await browser.cookies()
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.value开启请求拦截以捕获请求头,匹配Cloudflare挑战后的页面请求。
await page.setRequestInterception(true);
page.on('request', request => {
// 匹配Cloudflare挑战后的页面请求
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});第四部分:使用Scrapeless Scraping Browser绕过Cloudflare Turnstile
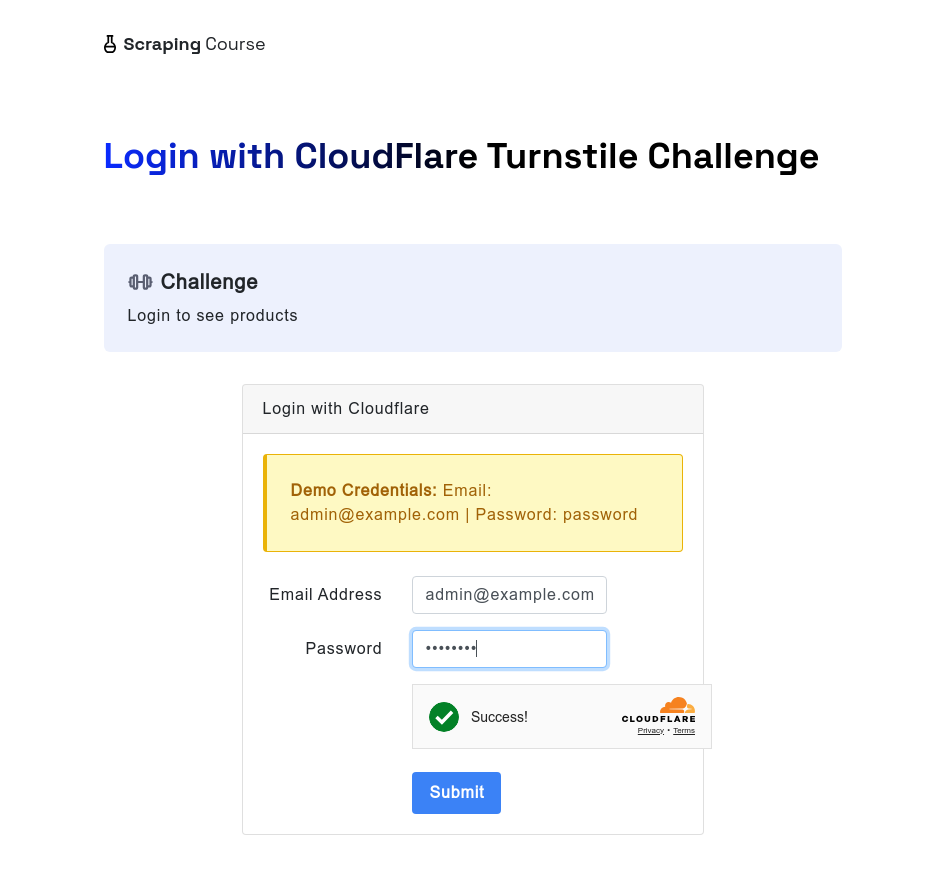
同样,当面对Cloudflare Turnstile时,scrapeless browser仍然可以自动处理。以下示例访问Cloudflare Turnstile测试网站。在输入用户名和密码后,使用waitForFunction方法等待window.turnstile.getResponse()的返回数据,确保挑战已成功绕过。然后拍摄截图并点击登录按钮以导航到下一个页面。
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com')
await page.locator('input[type="password"]').fill('password')
// 等待turnstile成功解锁
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
await page.screenshot({ path: 'challenge-bypass-success.png' });
await page.locator('button[type="submit"]').click()
await page.waitForNavigation()
await page.screenshot({ path: 'next-page.png' });执行此脚本后,你将能够通过截图看到解锁效果。
第五部分:使用Scrapeless Web Unlocker进行JavaScript渲染
Scrapeless Web Unlocker允许JavaScript渲染和动态交互,使其成为绕过Cloudflare的有效工具。
JavaScript渲染
JavaScript渲染使得处理动态加载的内容和单页应用(SPA)成为可能。提供完整的浏览器环境,支持更复杂的页面交互和渲染需求。
js_render=true,我们将使用浏览器请求
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.google.com/",
"js_render": true
},
"proxy": {
"country": "US"
}
}JavaScript指令
提供一套丰富的JavaScript指令,允许你动态地与网页交互。
这些指令使你能够单击元素、填写表单、提交表单或等待特定元素出现,提供灵活性以完成点击“查看更多”按钮或提交表单等任务。
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://example.com",
"js_render": true,
"js_instructions": [
{
"wait_for": [
".dynamic-content",
30000
]
// 等待元素
},
{
"click": [
"#load-more",
1000
]
// 点击元素
},
{
"fill": [
"#search-input",
"搜索词"
]
// 填写表单
},
{
"keyboard": [
"按下",
"回车"
]
// 模拟按键
},
{
"evaluate": "window.scrollTo(0, document.body.scrollHeight)"
// 执行自定义 JS
}
]
}
}挑战绕过示例
以下示例代码使用 axios 向 Scrapeless 的 Web Unlocker 服务发送请求。它启用 js_render,并使用 js_instructions 参数的 wait_for 指令,在绕过 Cloudflare 挑战后等待页面上的一个元素:
import axios from 'axios'
async function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v1/unlocker/request`;
const API_KEY = '你的_api_key'
const payload = {
actor: "unlocker.webunlocker",
proxy: {
country: "US"
},
input: {
url: "https://www.scrapingcourse.com/cloudflare-challenge",
js_render: true,
js_instructions: [
{
wait_for: [
"main.page-content .challenge-info",
30000
]
}
]
},
}
try {
const response = await axios.post(url, payload, {
headers: {
'Content-Type': 'application/json',
'x-api-token': API_KEY
}
});
console.log("[page_html_body] =>", response.data);
} catch (error) {
console.error('错误:', error);
}
}
sendRequest();🎉 执行以上脚本后,你将可以在控制台中看到成功绕过 Cloudflare 挑战的页面 HTML。
Scrapeless - 更强大的动态网站解锁解决方案
对于动态网站、Ajax 加载和单页应用(SPA),Scrapeless 提供 Web Unlocker,能够自动解决 Cloudflare 挑战,避免被检测为机器人。
✅ AI 驱动的自动绕过,适应 Cloudflare 反爬虫更新
✅ 全球代理池支持,稳定绕过 IP 限制
✅ 与 Puppeteer / Playwright 的无缝兼容
💡 立即尝试 Scrapeless Web Unlocker,轻松抓取动态网站数据! 👉 立即体验
关于 Cloudflare 挑战的常见问题
问:什么是 Cloudflare 挑战?
答:Cloudflare 挑战是一种用于保护网站免受恶意活动(如机器人攻击和 DDoS 攻击)的安全措施。当 Cloudflare 检测到可疑行为时,它会向访问者提出挑战,以验证他们是合法用户。
问:为什么我在受到 Cloudflare 保护的网站上被挑战?
答:你可能因多种原因受到挑战,包括与您的 IP 地址相关的高威胁评分、IP 地址的可疑活动历史、检测到类似机器人的自动流量,或网站所有者为针对您的区域或用户代理而设置的特定规则。Cloudflare 还会验证您的浏览器是否满足某些标准。
问:Cloudflare 挑战的不同类型是什么?
答:Cloudflare 使用不同类型的挑战,包括托管挑战、JS 挑战和互动挑战。推荐使用托管挑战,其中 Cloudflare 根据请求特征动态选择合适的挑战类型。JS 挑战会呈现一个需要浏览器进行 JavaScript 处理的页面。互动挑战要求访问者与页面互动以解决难题。
问:什么是托管挑战?
答:托管挑战是一种动态系统,Cloudflare 根据请求的特征选择适当的挑战类型。可能包括非互动式挑战页面、自定义互动挑战或私人访问令牌。目标是最小化 CAPTCHA 的使用,减少用户解决这些挑战所花费的时间。
今天就加入 Scrapeless Discord 社区!🚀 与专家爬虫互动,获取绕过 Cloudflare 挑战的独家技巧,及时了解最新功能。点击这里立即加入。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


