
什么是HTTP/2指纹识别以及如何绕过它?
Advanced Data Extraction Specialist
在当今这个网络抓取和反抓取技术不断发展的世界里,像用户代理伪装和JavaScript绕过这样的传统方法已不足以应对日益复杂的检测机制。随着网站迁移到更高效的HTTP/2协议,HTTP/2指纹识别悄然成为一种强大的新型反抓取工具。
在本文中,你将学习到:
- 什么是HTTP/2以及它是如何工作的
- 六种不同的绕过方法
让我们开始吧!
什么是HTTP/2?
HTTP/2是HTTP协议的第二个主要版本,相较于旧版HTTP/1.1,代表了显著的升级。自2015年推出以来,大约一半的网站现在使用HTTP/2。
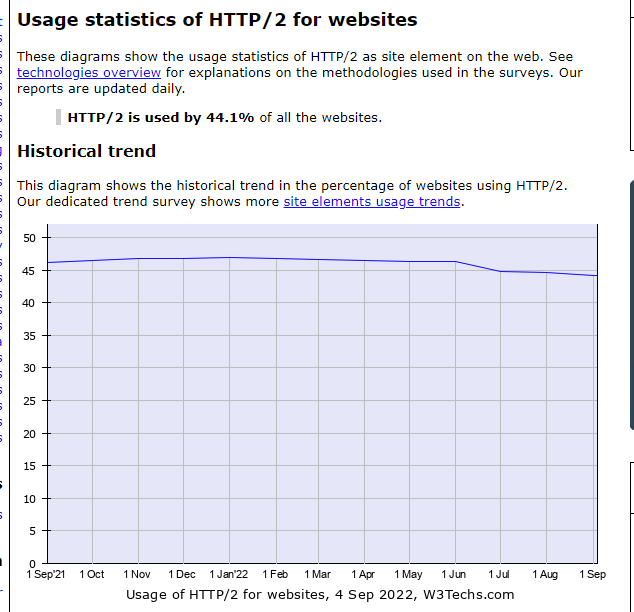
大多数现代网站都在使用它!例如:
- Google(包括Gmail、Google搜索、Google Drive等)
- YouTube
- 亚马逊
- Netflix
你可以通过按F12 → 网络在浏览器中检查请求是使用HTTP/1.1还是h2(代表HTTP/2)。
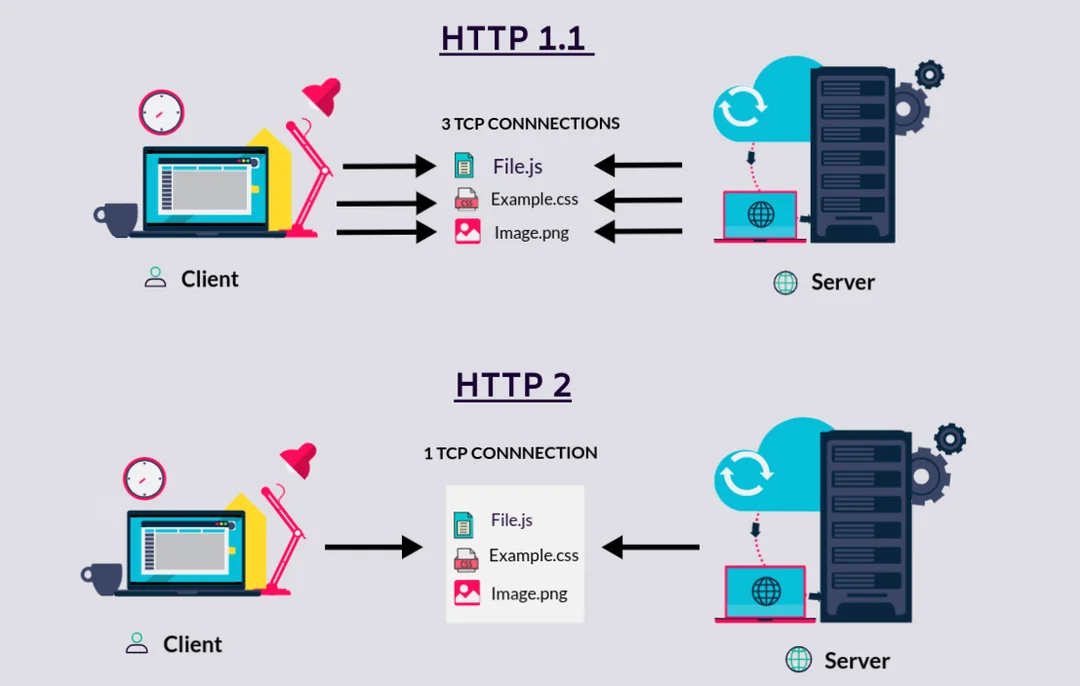
HTTP/2旨在通过多路复用、头部压缩(HPACK)和连接重用等方法来提高网页加载性能。与HTTP/1.1逐个发送数据不同,HTTP/2可以在单一连接上并行发送多个请求和响应。
核心特性:
- 多路复用:多个请求/响应共享TCP连接以提高效率
- 头部压缩:使用HPACK算法减少冗余
- 二进制协议:更高效的传输结构
- 优先级流量控制:改善资源调度能力
什么是HTTP/2指纹识别?
HTTP/2指纹识别是指根据使用HTTP/2协议时的行为差异来识别和分类客户端的过程。这些差异通常体现在协议的实现细节上,不同的浏览器、爬虫库和自动化框架在其基础行为上表现出自然的变异。
简单来说:
它不是查看你的用户代理,而是检查你发送请求时的底层HTTP/2行为特征,以确定你是谁,以及你是否是“非人类脚本”。
正如我们所知,HTTP/2放弃了文本格式,使用二进制格式进行传输,其中包含多个字段,例如:
| 字段 | 目的 |
|---|---|
| SETTINGS帧 | 表示初始连接设置 |
| PRIORITY帧 | 控制请求优先级 |
| WINDOW_UPDATE | 流量控制 |
| 头部顺序 | 发送头部的顺序 |
这些帧/头部字段的值、顺序和组合在不同客户端(浏览器、语言、库)之间有所不同。
指纹识别系统收集这些细节以建立“指纹数据库”,这可以用来确定:
- 你是否正在使用Python的requests + httpx
- 你是否正在使用Playwright + Node.js
- 或者你是否是使用Chrome浏览的“正常用户”
你可以在BrowserLeaks HTTP/2指纹测试页面上检查你的HTTP/2指纹。以下是一个示例:
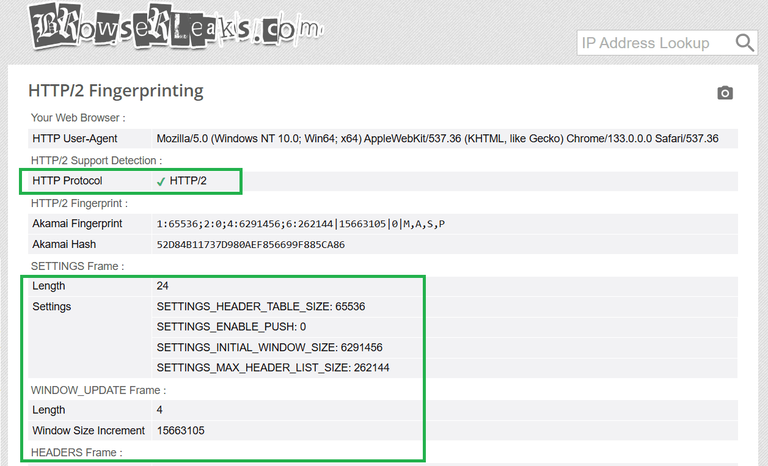
常用于识别的特征包括:
| 特征类型 | 示例描述 |
|---|---|
| SETTINGS帧内容 | 不同的浏览器或库设置不同的参数(例如,最大流) |
| 头部顺序 | 头部的顺序,如:method、path、user-agent、accept-language等 |
| PRIORITY帧使用 | 一些浏览器使用它,而脚本库通常会忽略它 |
| 流量控制行为 | 是否频繁使用WINDOW_UPDATE |
| 初始帧组合 | 某些客户端在开始时发送多个SETTINGS帧,而其他客户端则不发送 |
| TLS指纹(JA3) | 虽然不属于HTTP/2本身,但通常与HTTP/2一起分析。 |
这对网页爬虫来说为什么是致命的?
因为 HTTP/2 指纹识别深入到协议层,因此它比传统的用户代理(UA)或 JavaScript 行为检测更加隐蔽,更难伪造。正如我们之前提到的,它通过分析客户端发起连接时的 SETTINGS 帧、帧顺序、窗口更新和优先级设置等细节,精确识别客户端是否为“伪装成浏览器的爬虫”。大多数常见的爬虫库(如 Python 的 httpx 或 requests,以及 Go 的 net/http)在其底层 HTTP/2 实现上与真实浏览器存在差异,因此很容易被识别出来。
更糟糕的是,这种类型的指纹可以在请求主体发送之前识别客户端,这意味着您的爬虫甚至在发送实际请求负载之前就可能被服务器阻止。
HTTP/2 指纹识别与浏览器指纹识别
尽管 HTTP/2 指纹识别和 浏览器指纹识别 都是客户端识别技术,但它们在不同的层次上运作,并使用不同的识别方法。浏览器指纹识别在浏览器层面工作,依赖 JavaScript 收集包括浏览器版本、插件、字体、屏幕分辨率和设备类型等信息。这些信息可以组合成高度唯一的标识符,帮助服务器判断访问者是否为自动化工具。然而,由于它依赖于前端环境,开发者可以通过修改脚本环境或使用专门的插件来绕过检测。
另一方面,HTTP/2 指纹识别在网络协议层面运作,识别客户端如何构建和发送 HTTP/2 帧。例如,它检查 SETTINGS 帧中字段的顺序、初始窗口大小和优先级设置等低级协议细节。这些特征与操作系统、TLS 库和浏览器引擎的实现密切相关,因此通过简单的配置更改很难伪造。因此,与浏览器指纹识别相比,HTTP/2 指纹识别更隐蔽且更难绕过。
因此,这种新兴的反爬虫技术对自动化工具构成了更严重的挑战。以下部分将详细介绍如何绕过 HTTP/2 指纹识别。
如何绕过 HTTP/2 指纹识别?(6种实用方法)
由于传统的欺骗技术在 HTTP/2 层面很容易被“看穿”,我们需要更高级的策略来使我们的行为更像真实浏览器。以下是当前可用的一些最有效的方法,适合中级到高级的爬虫开发者。这些方法涵盖了从使用无头浏览器到构建自定义客户端的一切。
方法 1:使用真实浏览器再现真实的 HTTP/2 行为
您可以使用自动化控制工具,如 Puppeteer 或 Playwright,来操控真实的 Chromium 浏览器。浏览器使用的 HTTP/2 协议栈和 TLS 握手行为本质上符合“人类用户”的模式,使得指纹识别系统更难检测异常。
TLS 握手是一系列允许双方(通常是客户端和服务器)相互验证、商定加密标准并建立安全数据传输通道的步骤。
实现建议:
- 在“非无头模式”(Headful)下运行 Playwright,以模拟真实用户行为;
- 启用
--enable-features=NetworkServiceInProcess强制使用浏览器内置的 HTTP/2 协议; - 使用
puppeteer-extra-plugin-stealth插件隐藏自动化痕迹; - 配置浏览器上下文,使其与实际用户的语言、时区和屏幕分辨率匹配;
- 结合 IP 代理池和用户代理轮换,进一步避免模式检测。
✅ 优点:对底层协议干预的需要最小;指纹自然“人性化”。
⚠️ 缺点:资源消耗高;爬虫效率受限于浏览器的并发能力。
方法 2:定制 HTTP/2 客户端以模拟真实浏览器指纹
如果您希望在不启动完整浏览器实例的情况下提高并发性能,那么您需要“深入底层” — 手动构建一个能够高度模拟真实浏览器的 HTTP/2 客户端。这种方法允许极其轻量的爬虫请求,同时绕过 HTTP/2 指纹检测。
浏览器发起的 HTTP/2 请求在 TLS 握手阶段和初始帧结构中暴露出几个关键特征,例如:
- TLS 指纹
- ALPN 协议协商顺序
- 初始 SETTINGS 帧的顺序和内容
- 头部顺序和大小写敏感性(区分大小写!)
- 使用
:authority与host头部的区别
这些都可以成为指纹识别系统的“信号源”。以下是如何解决这些问题的建议:
实现建议:
- 使用工具如 undici、http2-wrapper、hyper,或较低级别的库如 curl 或 nghttp2 来实现自定义功能。
- 模拟 Chrome 的 HTTP/2 帧结构,包括 SETTINGS 帧的顺序、WINDOW_UPDATE 行为等。
- 精确复制 TLS 握手过程。可以使用类似 mitmproxy 或 tls-trace 的工具捕获真实浏览器数据作为参考。
- 如果您对这些细节不清楚,可以参考此视频以获取更深入的信息:https://www.youtube.com/watch?v=7BXsaU42yok。
- 使用 Wireshark 或 Chrome DevTools 的 chrome://net-export 进行数据包级比较。
✅ 优点:高性能,能够支持大规模并发,无需依赖真实浏览器。
⚠️ 缺点:开发复杂性极高;需要对协议栈和 TLS 握手机制有熟悉的了解。
方法 3:使用 HTTP/2 浏览器指纹代理服务
您还可以使用中间代理层,如 TLS-Proxy,将常规爬虫请求转换为真实浏览器指纹特征。
工作原理:
- 客户端使用标准库(例如
httpx)发送请求。 - 中间服务接收请求,重构 HTTP/2 帧,并修改 TLS 握手信息。
- 目标服务器接收到模拟 Chrome 或 Safari 的请求。
方法 4:重放真实浏览器会话数据
通过从浏览器导出 NetLog 文件或使用像 Wireshark 之类的工具捕获数据包,您可以收集并重放真实浏览器的 HTTP/2 请求过程。
实施建议:
- 启动浏览器后记录 HTTP/2 帧传输顺序(例如 SETTINGS、PRIORITY、HEADERS)。
- 使用类似 nghttp2 或 h2 的工具重建并发送相同的内容。
- 确保 ALPN 和 JA3 指纹的一致性。
✅ 优点:几乎完美复制真实浏览器请求,使其极具有效性以绕过指纹检测。
⚠️ 缺点:数据包捕获和重放过程复杂,仅适合小规模操作。
方法 5:TLS 指纹同步 (TLS Fingerprinting)
在 HTTP/2 握手之前,浏览器通过 TLS 协议协商(ClientHello)发起连接,这也会生成指纹。
推荐工具:
- tls-client (Node.js)
- uTLS (Go)
- mitmproxy (Python,适合拦截和调试)
✅ TLS 和 ALPN 必须与 HTTP/2 对齐,以实现完整的模拟。
方法 6:使用 Scrapeless 爬虫浏览器
如果您正在寻找更稳定、高效且几乎不可检测的网络爬虫解决方案,Scrapeless 爬虫浏览器 是目前可用的领先选项之一。它运作于云基础设施,并利用动态指纹混淆技术访问敏感网站,而不暴露爬虫的身份。
Scrapeless 的主要特性:
- 真实浏览器环境:在 Chrome 内核级别模拟真实用户行为。
- TLS 指纹欺骗:成功绕过大多数反爬虫机制(例如 Bot、TLS、HTTP/2 指纹识别)。
- 核心技术优势:
- 云部署:无需本地资源;易于集成和扩展。
- 动态指纹混淆:模拟浏览器环境变量和用户行为,增强人类模拟。
- TLS 指纹欺骗:通过伪装为真实浏览器打破传统检测方法。
- 为 AI 代理设计:支持自动化代理和代理浏览器环境。
- 无限并行性:无缝处理大规模爬取任务。
- 与 Playwright/Puppeteer 兼容:不需要代码重构,轻松集成现有的自动化框架。
应用场景:
- 批量数据收集
- 电子商务监控
- 情报爬取
👉 了解更多并试用:https://www.scrapeless.com
如何使用 Scrapeless 绕过 TLS 指纹识别
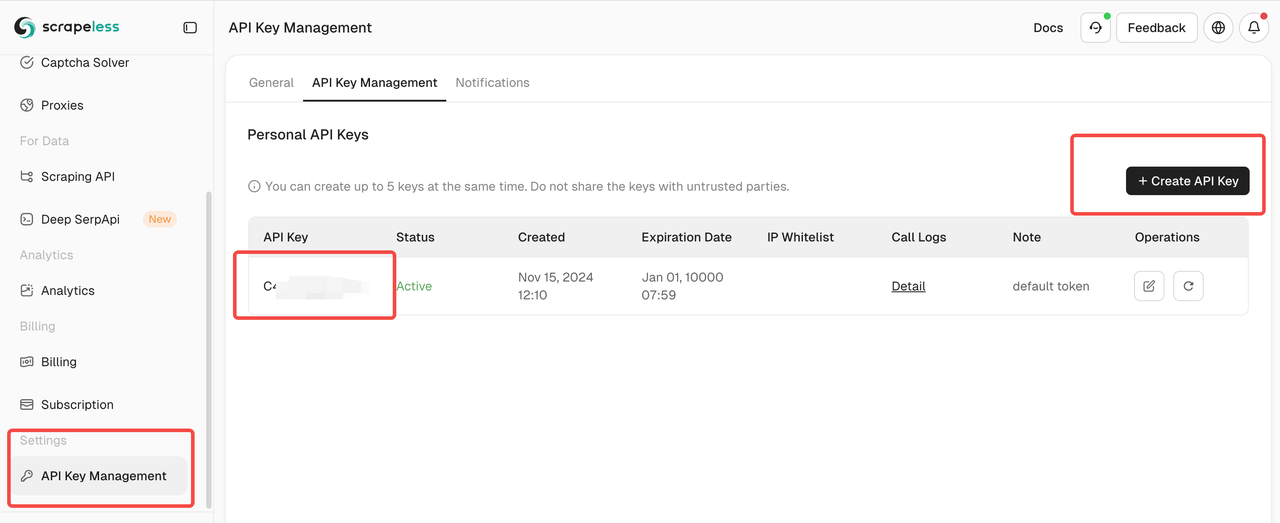
第一步:登录 Scrapeless 并获取您的 API 密钥
您可以在“API 密钥管理”部分创建您的 Scrapeless API 密钥。
第二步:配置并运行爬虫浏览器
-
访问 Scrapeless 浏览器菜单
- 登录您的 Scrapeless 账户,并导航到浏览器配置菜单。
- 在左侧配置您的 API 密钥和代理设置。
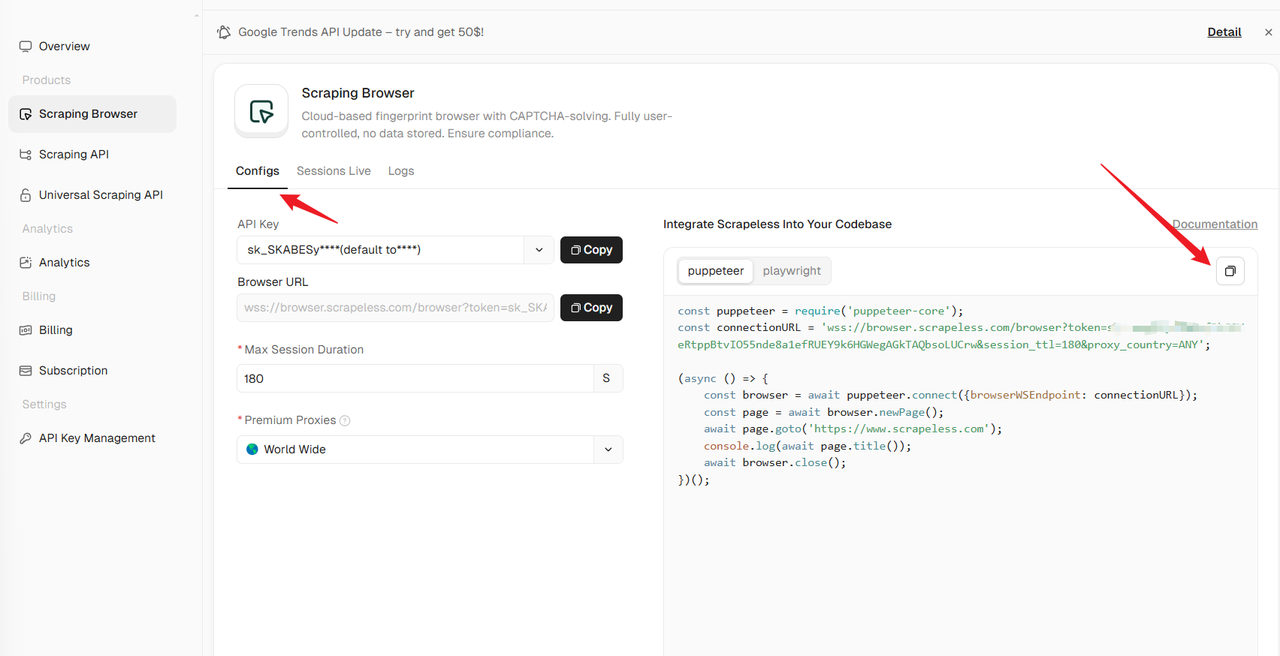
-
选择一个框架并复制示例代码
- 在右侧,选择您偏好的抓取框架(例如,Playwright,Puppeteer)。
- 复制提供的示例代码片段。以下是使用Playwright绕过HTTP/2指纹识别的优化示例:
const { chromium } = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOUR_TOKEN_HERE&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();然后打开您的IDE并运行代码。结果如下:

趋势:协议级反爬虫措施将成为主流
HTTP/2指纹识别只是冰山一角。更多的反爬虫机制正在扩展到更低级别的协议,包括:
- JA3 / JA4 TLS指纹识别
- TCP初始序列号(ISN)分析
- UDP层行为检测(HTTP/3)
- IP层时序行为统计
在未来,反爬虫检测甚至可能在您发送第一个请求之前就将您识别为爬虫。
结论
HTTP/2指纹识别已成为不可或缺的下一代反爬虫技术。仅依赖User-Agent伪装或JavaScript绕过等传统方法已不再足够。要在现代反爬虫系统中脱颖而出,正确的战略涉及全面模拟——从协议栈和TLS到浏览器行为。
如果您正在寻找高性能、低风险的绕过解决方案,Scrapeless抓取浏览器 提供了目前可用的最类人模拟能力。它是数据工程师、增长黑客和安全研究人员的首选。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


