
使用Scrapeless绕过Cloudflare防护和Turnstile验证码 | 完全指南
Advanced Data Extraction Specialist
简介
由于Cloudflare 保护和Cloudflare Turnstile等高级安全机制,网络抓取正变得越来越困难。这些挑战旨在阻止自动化访问,并使机器人难以检索数据。但是,使用**Scrapeless 抓取浏览器**,您可以有效绕过这些限制,并继续无中断地抓取数据。
在本指南中,我们将介绍绕过 Cloudflare 挑战的三个关键方面:
- 如何使用 Scrapeless 浏览器绕过 Cloudflare 保护 – 学习如何绕过 CAPTCHA 和机器人检测等安全措施。
- 如何检索和使用 cf_clearance Cookie 和请求头 – 了解如何提取和使用 cf_clearance cookie 来维护会话持久性。
- 如何使用 Scrapeless 浏览器绕过 Cloudflare Turnstile – 了解如何绕过 Turnstile 挑战并自动化您的抓取任务。
在本教程结束时,您将拥有一个完整的策略来有效地处理 Cloudflare 保护。让我们开始吧!
第1部分:如何使用 Scrapeless 绕过 Cloudflare 保护
本指南将向您展示如何使用 Scrapeless 和 Puppeteer-core 绕过网站上的 Cloudflare 保护。
步骤1:准备工作
1.1 创建项目文件夹
-
为项目创建一个新文件夹,例如 scrapeless-bypass。
-
在您的终端中导航到该文件夹:
cd path/to/scrapeless-bypass1.2 初始化一个 Node.js 项目
运行以下命令以创建 package.json 文件:
npm init -y1.3 安装所需的依赖项
安装 Puppeteer-core,它允许与浏览器实例进行远程连接:
npm install puppeteer-core如果您的系统上尚未安装 Puppeteer,请安装完整版本:
npm install puppeteer puppeteer-core步骤2:获取 Scrapeless API 密钥
2.1 在 Scrapeless 上注册
-
访问 Scrapeless 并创建一个帐户。
-
导航到 API 密钥管理部分。
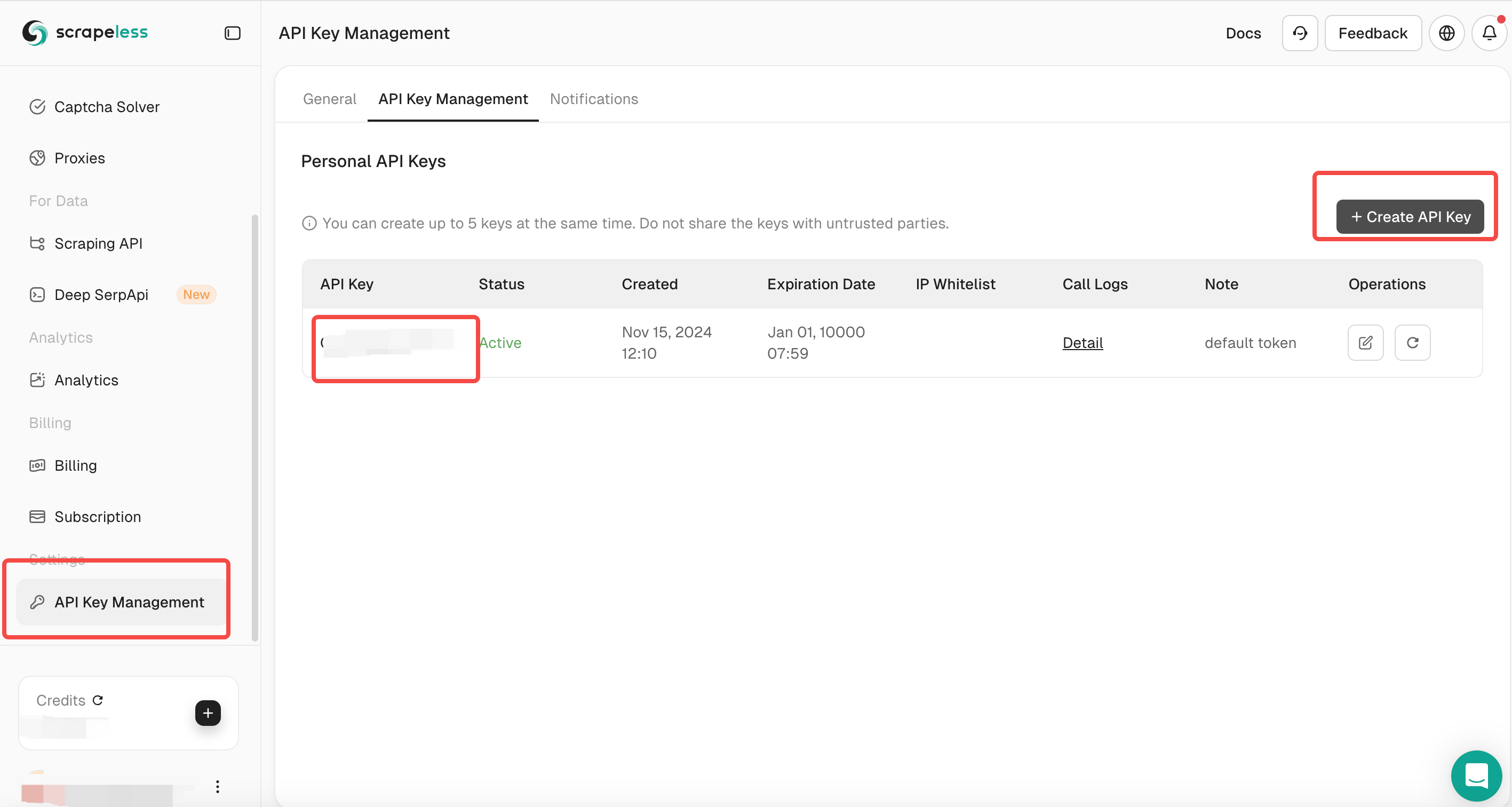
- 生成一个新的 API 密钥并复制它。
🚀准备好更深入地了解如何绕过 Cloudflare 保护吗?
👉 立即登录 以访问高级功能和教程!
🔒 需要额外帮助? 加入我们的 Discord 社区 以获取实时支持和更新!
📈 立即开始使用 Scrapeless 浏览器更智能地抓取数据!"
步骤3:连接到 Scrapeless Browserless
3.1 获取 WebSocket 连接 URL
Scrapeless 提供一个 WebSocket 连接 URL,供 Puppeteer 与基于云的浏览器交互。
格式为:
wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY将 APIKey 替换为您的实际 Scrapeless API 密钥。
3.2 设置连接参数
-
token:您的 Scrapeless API 密钥
-
session_ttl:浏览器会话持续时间(秒)(例如,180 秒)
-
proxy_country:代理服务器的国家代码(例如,英国为 GB,美国为 US)
步骤4:编写 Puppeteer 脚本
4.1 创建脚本文件
在您的项目文件夹中,创建一个名为 bypass-cloudflare.js 的新 JavaScript 文件。
4.2 连接到 Scrapeless 并启动 Puppeteer
将以下代码添加到 bypass-cloudflare.js:
javascript
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'; // 替换为您的实际 API 密钥
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180', // 浏览器会话持续时间(秒)
proxy_country: 'GB', // 代理国家代码
proxy_session_id: 'test_session', // 代理会话 ID(保持相同的 IP)
proxy_session_duration: '5' // 代理会话持续时间(分钟)
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Connected to Scrapeless');4.3 打开网页并绕过 Cloudflare
扩展脚本以打开新页面并导航到受 Cloudflare 保护的网站:
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });4.4 等待页面元素加载
确保在继续之前绕过 Cloudflare 保护:
javascript
await page.waitForSelector('main.page-content .challenge-info', { timeout: 30000 }); // 根据需要调整选择器4.5 捕获屏幕截图
为了验证 Cloudflare 保护是否已成功绕过,请截取页面的屏幕截图:
javascript
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('Screenshot saved as challenge-bypass.png');4.6 完成脚本
这是完整的脚本:
javascript
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'; // 替换为您的实际 API 密钥
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180',
proxy_country: 'GB',
proxy_session_id: 'test_session',
proxy_session_duration: '5'
}).toString();
const connectionURL = `${host}/browser?${query}`;
(async () => {
try {
// 连接到 Scrapeless
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Connected to Scrapeless');
// 打开新页面并导航到目标网站
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });
// 等待页面完全加载
await page.waitForTimeout(5000); // 根据需要调整延迟
await page.waitForSelector('main.page-content', { timeout: 30000 });
// 捕获屏幕截图
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('Screenshot saved as challenge-bypass.png');
// 关闭浏览器
await browser.close();
console.log('Browser closed');
} catch (error) {
console.error('Error:', error);
}
})();步骤5:运行脚本
5.1 保存脚本
确保脚本保存为 bypass-cloudflare.js。
5.2 执行脚本
使用 Node.js 运行脚本:
node bypass-cloudflare.js5.3 预期输出
如果一切设置正确,终端将显示:
Connected to Scrapeless
Screenshot saved as challenge-bypass.png
Browser closedchallenge-bypass.png 文件将出现在您的项目文件夹中,确认 Cloudflare 保护已成功绕过。
🌟想要轻松绕过 Cloudflare 保护吗?
🔑 在此处登录 并立即开始利用 Scrapeless 浏览器的强大工具!
🚀需要专家指导?加入我们的 Discord 社区 获取独家提示和故障排除帮助!
💡使用 Scrapeless 浏览器领先于网络抓取——安全、快速且可靠!"
步骤6:其他注意事项
6.1 API 密钥使用
-
确保您的 API 密钥有效且未超过其请求配额。
-
切勿在公共存储库(例如 GitHub)中公开您的 API 密钥。出于安全考虑,请使用环境变量。
6.2 代理设置
-
调整 proxy_country 参数以选择不同的位置(例如,美国的 US,德国的 DE)。
-
使用一致的 proxy_session_id 来在请求中保持相同的 IP 地址。
6.3 页面选择器
-
目标网站的结构可能会有所不同,需要调整 waitForSelector()。
-
使用 page.evaluate() 检查页面结构并相应地更新选择器。
本指南提供了一种逐步方法,可以使用 Scrapeless 和 Puppeteer-core 绕过 Cloudflare 保护。通过利用 WebSocket 连接、代理设置和元素监控,您可以有效地自动化网络抓取,而不会被 Cloudflare 阻止。
第2部分:如何检索和使用 cf_clearance Cookie 和请求头
成功绕过 Cloudflare 挑战后,您可以从成功的页面响应中检索请求头和 cf_clearance cookie。这些元素对于维护会话持久性和避免重复挑战至关重要。
1. 检索 cf_clearance Cookie
javascript
const cookies = await browser.cookies();
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.value;目的:
-
此代码获取所有 cookie,包括 cf_clearance,这是 Cloudflare 在通过其安全挑战后发出的。
-
cf_clearance cookie 允许后续请求绕过 Cloudflare 的保护,从而减少重复挑战的需要。
2. 启用请求拦截和捕获标头
javascript
await page.setRequestInterception(true);
page.on('request', request => {
// 匹配 Cloudflare 挑战后的页面请求
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});目的:
-
启用请求拦截 (setRequestInterception(true)) 以监控和修改网络请求。
-
侦听请求事件,每当 Puppeteer 发送网络请求时触发。
-
识别 Cloudflare 挑战请求:
-
request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') 确保只拦截相关的请求。
-
request.headers()?.['origin'] 有助于验证合法访问。
-
提取并打印请求头,稍后可用于模拟真实的浏览器请求。
-
继续请求 (request.continue()) 以防止页面加载中断。
🔍正在寻找有效捕获和使用 Cloudflare 的 cf_clearance cookie 的方法吗?
💪 立即登录 以访问所有高级功能,实现更流畅的抓取。
3. 为什么检索 cf_clearance 和标头?
- 会话持久性:
-
cf_clearance cookie 允许后续 HTTP 请求跳过 Cloudflare 挑战。
-
此 cookie 可在多个请求中重复使用,从而最大限度地减少验证提示。
- 模拟真实的浏览器请求:
-
Cloudflare 会检查请求头,例如 User-Agent、Referer 和 Origin。
-
从成功的请求中捕获标头可确保未来的请求可以模拟合法的流量,从而减少检测风险。
- 提高抓取效率:
- 这些详细信息可以存储在数据库或文件中并重复使用,从而防止不必要的挑战并优化请求成功率。
通过实施这些技术,您可以提高网络抓取的可靠性和效率,有效绕过 Cloudflare 的安全措施。🚀
第3部分:如何使用 Scrapeless 浏览器绕过 Cloudflare Turnstile
在本教程的这一部分中,我们将学习如何使用带有 Puppeteer 的 Scrapeless 浏览器绕过 Cloudflare Turnstile 保护。Cloudflare Turnstile 是一种更高级的安全机制,用于阻止机器人和自动抓取。借助 Scrapeless 浏览器,我们可以绕过此保护,就像我们是一个真实用户一样与网站交互。
注意:
“绕过 Cloudflare 保护”和“Cloudflare Turnstile 绕过”针对不同的安全机制。
- 绕过 Cloudflare 保护涉及绕过一般的 Cloudflare 安全措施,例如 CAPTCHA、JavaScript 检查和 IP 速率限制。
- Cloudflare Turnstile 绕过专门针对 Cloudflare 的 Turnstile,这是一种独特的反机器人挑战,它确保了人机交互,而不依赖于传统的 CAPTCHA。绕过 Turnstile 可以击败这种特定的安全机制。
步骤1:打开目标页面
我们将首先打开一个受 Cloudflare Turnstile 保护的网页,该网页通常需要人工验证。以下是打开网页的代码。
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });此代码使用 page.goto() 导航到页面并等待 DOM 内容加载完成。
步骤2:填写登录凭据
页面加载后,我们可以自动化填写登录凭据(例如用户名和密码)以通过登录页面的过程。
javascript
await page.locator('input[type="email"]').fill('admin@example.com');
await page.locator('input[type="password"]').fill('password');步骤3:等待 Turnstile 解锁
Cloudflare Turnstile 通过确保只有人类用户才能继续操作来发挥作用。在此步骤中,我们将等待 Turnstile 被解锁,方法是检查是否从 Turnstile 验证过程接收到响应。
javascript
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});这行代码等待 window.turnstile.getResponse() 的响应,这表示 Turnstile 验证已成功绕过。
💥轻松解锁 Cloudflare Turnstile 背后的内容。
🔓 登录 以访问强大的抓取功能。
💬 加入我们的 Discord 社区 获取个性化帮助、提示和用户见解!
🚀使用 Scrapeless 浏览器简化您的网络抓取——克服任何障碍,包括 Cloudflare 最棘手的挑战!"
步骤4:拍摄屏幕截图进行验证
为了确认绕过是否成功,我们可以拍摄页面的屏幕截图。这有助于我们验证 Turnstile 是否已成功绕过。
javascript
await page.screenshot({ path: 'challenge-bypass-success.png' });步骤5:单击登录按钮
成功绕过 Turnstile 挑战后,我们可以模拟用户单击登录按钮以提交表单。
javascript
await page.locator('button[type="submit"]').click();
await page.waitForNavigation();此代码单击提交按钮并等待页面在登录后导航到下一页。
步骤6:拍摄下一页的屏幕截图
最后,登录后,我们将拍摄另一张屏幕截图以确认导航到下一页是否成功。
javascript
await page.screenshot({ path: 'next-page.png' });完整的代码示例
以下是包含上面概述的所有步骤的完整代码:
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com');
await page.locator('input[type="password"]').fill('password');
// 等待 Turnstile 成功解锁
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
// 绕过后拍摄屏幕截图
await page.screenshot({ path: 'challenge-bypass-success.png' });
// 单击登录按钮
await page.locator('button[type="submit"]').click();
await page.waitForNavigation();
// 拍摄下一页的屏幕截图
await page.screenshot({ path: 'next-page.png' });通过本教程,您已成功学习如何使用 Scrapeless 浏览器和 Puppeteer 绕过 Cloudflare Turnstile 保护。这种方法允许您与网站交互,填写登录表单,并浏览内容,同时绕过 Cloudflare 的安全机制。您可以将此技术扩展到受 Turnstile 保护的其他网站。
准备好使用 Scrapeless 浏览器掌握 Cloudflare 绕过和网络抓取吗?
🚀 立即解锁 Scrapeless 浏览器的全部功能,并开始轻松绕过 Cloudflare 保护、检索 cookie 和标头以及绕过 Turnstile 挑战!
🔑 在此处登录 以访问独家功能并开始充满信心地进行抓取。
💬 加入我们的 Discord 社区 以与其他抓取专家联系,获取故障排除帮助,并随时了解最新的提示和技巧。
💡 不要错过强大的工具和见解,以帮助您使用 Scrapeless 浏览器将网络抓取提升到一个新的水平。
结论
成功绕过 Cloudflare 安全需要合适的工具和策略。使用 Scrapeless 浏览器,您可以轻松绕过 Cloudflare 的防御,检索必要的 cookie 和标头,并在无需人工干预的情况下克服 Turnstile 挑战。
🔑 立即注册 并将您的网络抓取提升到一个新的水平!
💬 需要帮助?加入我们的 Discord 社区 以获得专家见解、故障排除支持并掌握最新的网络抓取技术。
不要让 Cloudflare 减慢您的速度——立即解锁无缝抓取!
常见问题解答:Cloudflare 绕过、cf_clearance Cookie 和 Turnstile 挑战
1. 什么是 Cloudflare 保护,为什么它会阻止网络抓取程序?
Cloudflare 保护是一种安全服务,用于检测和减轻自动流量。它使用 CAPTCHA、JavaScript 挑战和 IP 速率限制等技术来防止机器人访问受保护的内容。
2. 什么是 cf_clearance,它如何帮助绕过 Cloudflare?
cf_clearance cookie 在成功完成 Cloudflare 挑战后发出。它允许浏览器会话在特定持续时间内保持验证状态,从而防止进一步的挑战。通过检索和重复使用此 cookie,抓取程序可以保持不间断的访问。
3. Cloudflare Turnstile 与标准 Cloudflare 保护有何不同?
Cloudflare Turnstile 是一种高级挑战,旨在验证人类的存在,而无需传统的 CAPTCHA。它使用行为分析和其他验证技术来阻止机器人。绕过 Turnstile 需要模拟真实用户交互的自动化工作流程。
4. 使用 Scrapeless 浏览器绕过 Cloudflare 是否合法?
绕过 Cloudflare 的合法性取决于网站的 服务条款 和 当地法规。始终确保您的抓取活动符合网站的政策和适用的法律。
5. 如何开始使用 Scrapeless 浏览器绕过 Cloudflare?
您可以通过 登录 Scrapeless 浏览器 并按照本指南中的步骤实施自动绕过解决方案来开始。
6. 我可以在哪里获得 Scrapeless 浏览器的支持?
加入我们的 Discord 社区 以与其他开发者联系,获取故障排除帮助,并随时了解新功能和最佳实践。
其他资源
了解如何使用 Puppeteer 绕过 Cloudflare 的保护并访问网络内容,而不会触发安全挑战。
如何将未检测到的 ChromeDriver 用于网络抓取
了解使用未检测到的 ChromeDriver 实例来避免在抓取网站时被检测到的技术。
如何使用 Node.js 抓取 Google 酒店价格
有关使用 Node.js 抓取 Google 酒店价格数据以及有效处理反机器人机制的分步指南。
如何使用 Python 抓取 Google Finance 股票报价数据
关于提取 Google Finance 股票报价(包括处理 JavaScript 呈现的数据)的基于 Python 的教程。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


