如何使用 Python 在网页抓取中绕过 CAPTCHA
Advanced Bot Mitigation Engineer
前言
很少有人知道 CAPTCHA 的全称是什么。
实际上,CAPTCHA 全称是“完全自动化的公共图灵测试,用于区分计算机和人类”。
CAPTCHA 旨在通过向计算机呈现难以解决的问题来识别可疑用户和当代机器人,从而帮助网站所有者防止抓取和爬取。由于有大量第三方库可以读取文本、与 HTML 表单交互并抓取复杂的 HTML 结构,因此 Python 是网页抓取的流行选择。因此,在本文中,我们将解释如何使用 Python 解决网页抓取过程中的 CAPTCHA 问题。
除了讨论实用的反 CAPTCHA 解决方案以纳入您的数据收集过程之外,我们还将介绍当今在线环境中可能发现的各种 CAPTCHA 类型。
reCAPTCHA
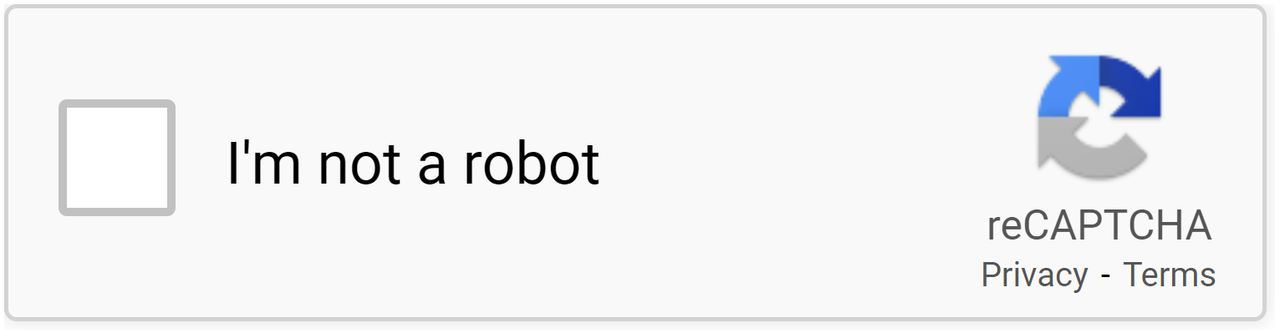
这是 Google 开发的免费 CAPTCHA 解决方案,可提供网站安全保护,它采用尖端方法来识别类似机器人的行为,与 hCAPTCHA 非常相似。Google reCAPTCHA 现在无需用户输入即可识别人类用户。它仅使用用户过去在其他网站上的体验作为识别的基础。Google 搜索、地图、Play、购物以及许多其他服务和产品都广泛使用 reCAPTCHA。
ImageToText CAPTCHA

通常,ImageToText CAPTCHA 是一堆杂乱无章的字母和字符,以难以辨认的样式显示,字符经过了旋转、调整大小和以不同方式扭曲。
音频验证码
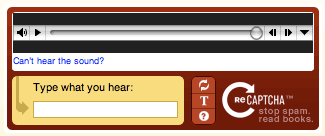
也称为“基于声音的验证码”,它要求用户通过录音输入一系列字母或数字。为了增加难度,音频经常会加入背景噪音。
hCAPTCHA
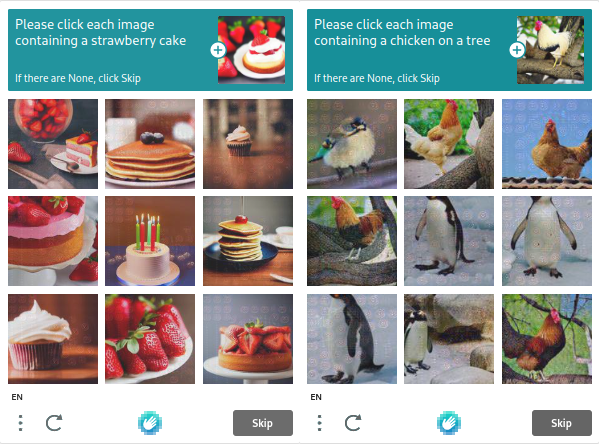
Intuition Machines 是 hCaptcha 的所有者,该公司重视用户隐私,不会收集不必要的数据。因此,它的受欢迎程度正在上升。标准的机器人评估任务,例如方框检查和图片识别,都是使用 hCaptcha 进行的。hCaptcha 中的测试比 reCAPTCHA 中的测试更复杂,但您可以更改参数以使其更难或更容易。
网页抓取是什么?
从网站获取数据的技术称为网页抓取。它需要使用自动化设备从网站中提取数据,有时称为网页抓取器或爬虫。这些程序在网站的层次结构中移动,获取 HTML 代码,然后使用预定义的模式或指南来提取所需的数据。
网页抓取有多种用途,包括:
- 竞品分析:关注竞争对手的互联网存在和策略
- 数据收集:从网站上汇编文本、图片和其他媒体内容
- 价格监控:密切关注和对比来自不同互联网商家的产品成本
- 材料聚合:通过从多个来源收集材料来创建整合的数据库或网站
- 市场研究:分析市场动态、趋势、消费者反馈和其他相关数据。
值得注意的是,尽管网页抓取是一种强大的数据收集工具,但必须以合乎道德和合法的方式执行。抓取私人或敏感信息可能违法,一些网站在其服务条款中明确禁止此类行为。参与在线抓取活动时,请确保始终遵守网站的使用条件和任何适用法律。
网页抓取示例
网页抓取是从网站获取数据的过程,通常是使用工具或编程脚本自动获取的。这是一个基本示例,它使用了 BeautifulSoup 包(这是网页抓取活动的一个广受欢迎的选项)和 Python。
假设我们想要从一个虚构的新闻源中检索最新文章的名称。HTML 的结构可能类似于以下内容:
language
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Sample News Website</title>
</head>
<body>
<div class="article">
<h2 class="title">Breaking News 1</h2>
<p class="content">This is the content of the first article.</p>
</div>
<div class="article">
<h2 class="title">Latest Update: Important Event</h2>
<p class="content">Details about the important event.</p>
</div>
</body>
</html>现在让我们利用 BeautifulSoup 和 Python 来抓取这些文章的标题:
language
import requests
from bs4 import BeautifulSoup
# URL of the sample news website
url = 'https://www.example-news-website.com'
# Send a GET request to the website
response = requests.get(url)
# Parse the HTML content of the page
soup = BeautifulSoup(response.text, 'html.parser')
# Find all div elements with the class 'article' and extract the titles
article_divs = soup.find_all('div', class_='article')
# Extract and print the titles
for article_div in article_divs:
title = article_div.find('h2', class_='title').text
print(f"Title: {title}")为了获取 HTML 内容,我们使用请求库向网站执行 GET 请求。接下来,使用 BeautifulSoup 解析 HTML 内容(本例中使用“html.parser”)。要发现具有 article 类的每个 div 元素,我们使用 find_all。我们找到每篇文章的带有 title 类的 h2 元素并检索其文本内容。
如何在网页抓取时使用 Scrapeless 绕过 CAPTCHA
厌倦了不断被CAPTCHA阻碍你的网页抓取工作?
向您强烈推荐 Scrapeless - 性能强大的一体化网页抓取解决方案。
借助我们强大的工具套件,可以轻松发挥数据抓取的全部潜力:
最佳 CAPTCHA 解码器
自动解决高难度 CAPTCHA,让您的抓取工作无缝丝滑。
免费试用开启中,赶紧来体验吧!
结束语
公共数据收集最常见的障碍之一便是 CAPTCHA,因此找到一种可靠且优越的方法来克服它们至关重要。本文介绍了当前可用的各种 CAPTCHA 类型,并提供了一些您可以在 Web 抓取活动中尝试使用的反 CAPTCHA 解决方案。
如果您对此有任何疑问,或者想要了解有关 Scrapeless 的更多信息,例如 Web Unlocker 或 CAPTCHA Solver,请使用我们的官方网站与我们联系。
FAQ
如何在 Web 抓取时尽可能避免 CAPTCHA?
获取网络数据时,有多种技术可以绕过 CAPTCHA。一个有用的技巧是通过修改 User-Agent 标头来微调抓取器的指纹。此外,您可以考虑使用 Web Unlocker 等自动程序,高效解决 CAPTCHA 问题。
为什么网站所有者使用 CAPTCHA 来防止网页抓取?
CAPTCHA 用于区分危险机器人和真正的访问者。它们是一种安全防护措施,可以防止恶意或具有潜在破坏性的机器人行为,例如垃圾邮件或欺诈交易。
有没有在网页抓取时绕过 CAPTCHA 的方法?
是的,市场上有各种专门用于绕过 CAPTCHA 的服务,示例包括 Web Unlocker 和 CAPTCHA 解算器。Scrapeless 的工具会选择适当的标头、cookie、浏览器属性等,以帮助您显示为合法用户,最终突破目标网站设置的所有障碍。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


