
如何在Dify上构建智能商业新闻监测工具?
Advanced Data Extraction Specialist
在当今竞争激烈的环境中,实时了解品牌声誉、行业动态和竞争对手情报对于有效决策至关重要。然而,手动监控新闻和信息耗时、劳动密集且容易错过关键洞察。
该解决方案将领先的无代码AI自动化平台Dify与Scrapeless Deep SerpApi(企业级Google搜索数据接口)集成,构建了一个智能且可扩展的商业新闻监控系统,使企业能够:
- 自动收集和过滤实时新闻
- 利用AI进行智能分析和可操作的洞察
- 自动通过多个渠道推送警报和报告
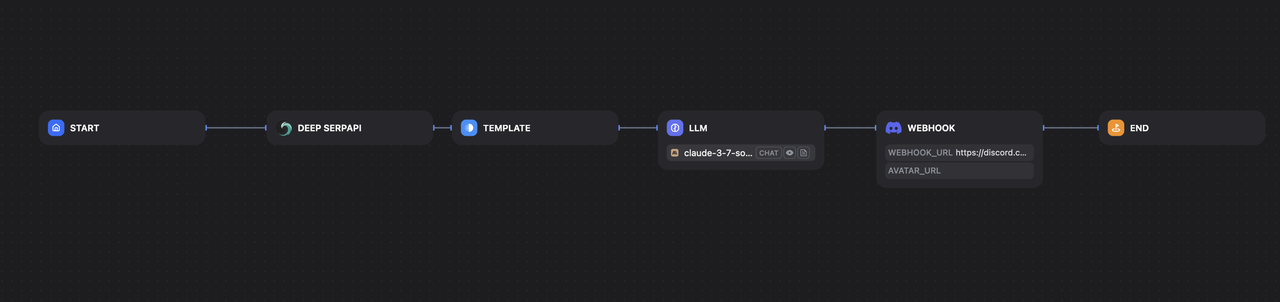
1. 解决方案概述
| 组件 | 描述 |
|---|---|
| Dify智能工作流平台 | 无代码工作流设计与执行,支持拖放集成AI和API |
| Scrapeless Deep SerpApi | 高速、稳定的反封锁Google搜索API,支持多区域和多语言查询 |
| AI模型(如:GPT-4 / Claude) | 执行自动语义分析,生成智能新闻摘要和商业洞察 |
| 通知插件(如:Discord Webhook) | 实时推送监控报告,确保快速信息传递 |
2. 企业级工具概述
Dify智能工作流平台
一个为灵活的企业级工作流设计的无代码AI自动化平台
- 可视化界面,支持拖放工作流构建——无需编码
- 与主流AI模型(GPT-4、Claude 3、Gemini等)无缝集成
- 插件生态系统,用于连接API和外部数据源
- 实时监控,提供详细日志和错误追踪
- 基于角色的访问控制和团队协作支持
- 适合在安全企业环境中私有部署
Scrapeless Deep SerpApi
一个为AI工作流和商业智能设计的实时高保真Google SERP API
Scrapeless Deep SerpApi 专为品牌监控、市场情报、内容生成和AI驱动决策等企业级用例而建。它直接从Google搜索结果中提取实时结构化数据(HTML解析),确保准确性、即时性和可靠性。
主要优势
- 实时Google SERP数据的即时访问(响应时间不足3秒)
- 全面的结果覆盖:自然结果、Google Local、Google Image、Google News等
- 零缓存:直接HTML解析确保最新且可验证的结果
- 反抓取技术:99.9%的成功率,无需手动配置代理
- 支持195+个国家和多语言以进行全球监控
- 以常见数据格式输出结构化数据,便于AI模型和自动化工作流解析和分析
- 透明的基于使用量的计费,没有隐藏限制或字段限制
📌 理想用于:
- 构建企业级媒体监控和警报系统
- 全球跟踪竞争对手活动和市场趋势
- 创建搜索调优数据集以支持增强生成(RAG)
- 规模化推动SEO和内容自动化
3. 环境设置与账户注册
3.1 注册Scrapeless账户并获取API令牌
- 访问Scrapeless仪表板
- 注册一个商务账户
- 登录后,导航至API管理页面以获取您的API令牌
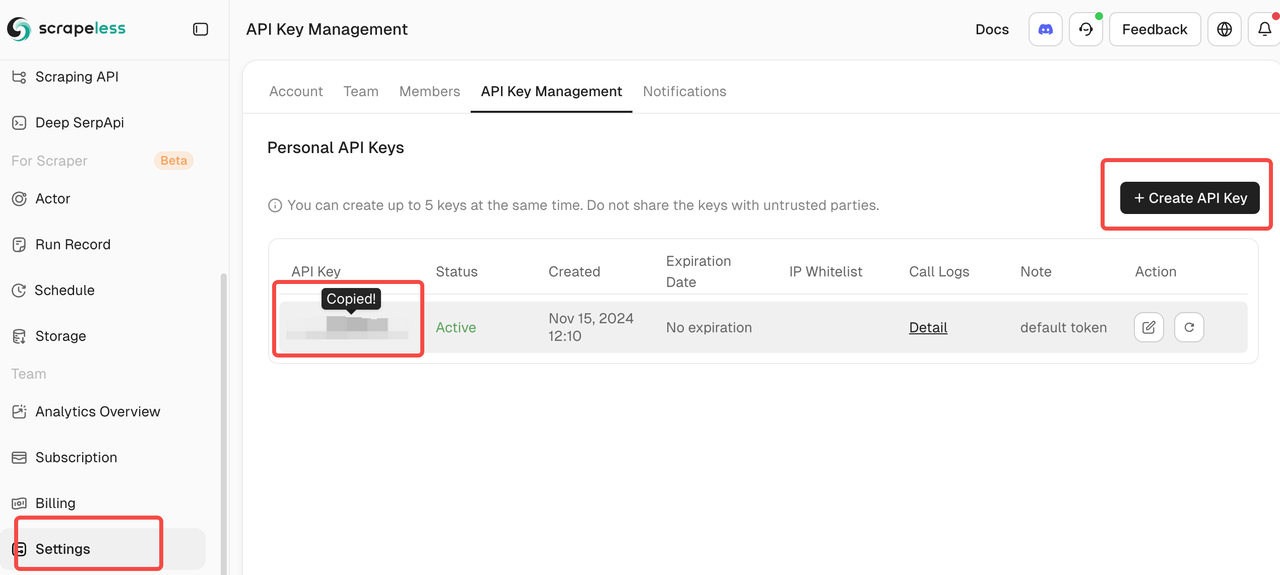
⚠️ 重要:请妥善保管您的API令牌,切勿公开分享。
3.2 注册Dify账户并安装Deep SerpApi插件
-
如果尚未注册Dify,请先注册并安装Deep SerpApi插件。
-
创建一个新应用并选择“工作流”
-
在工作流工作室中,点击“+”按钮以添加新工具
-
在面板中导航到“工具”标签
-
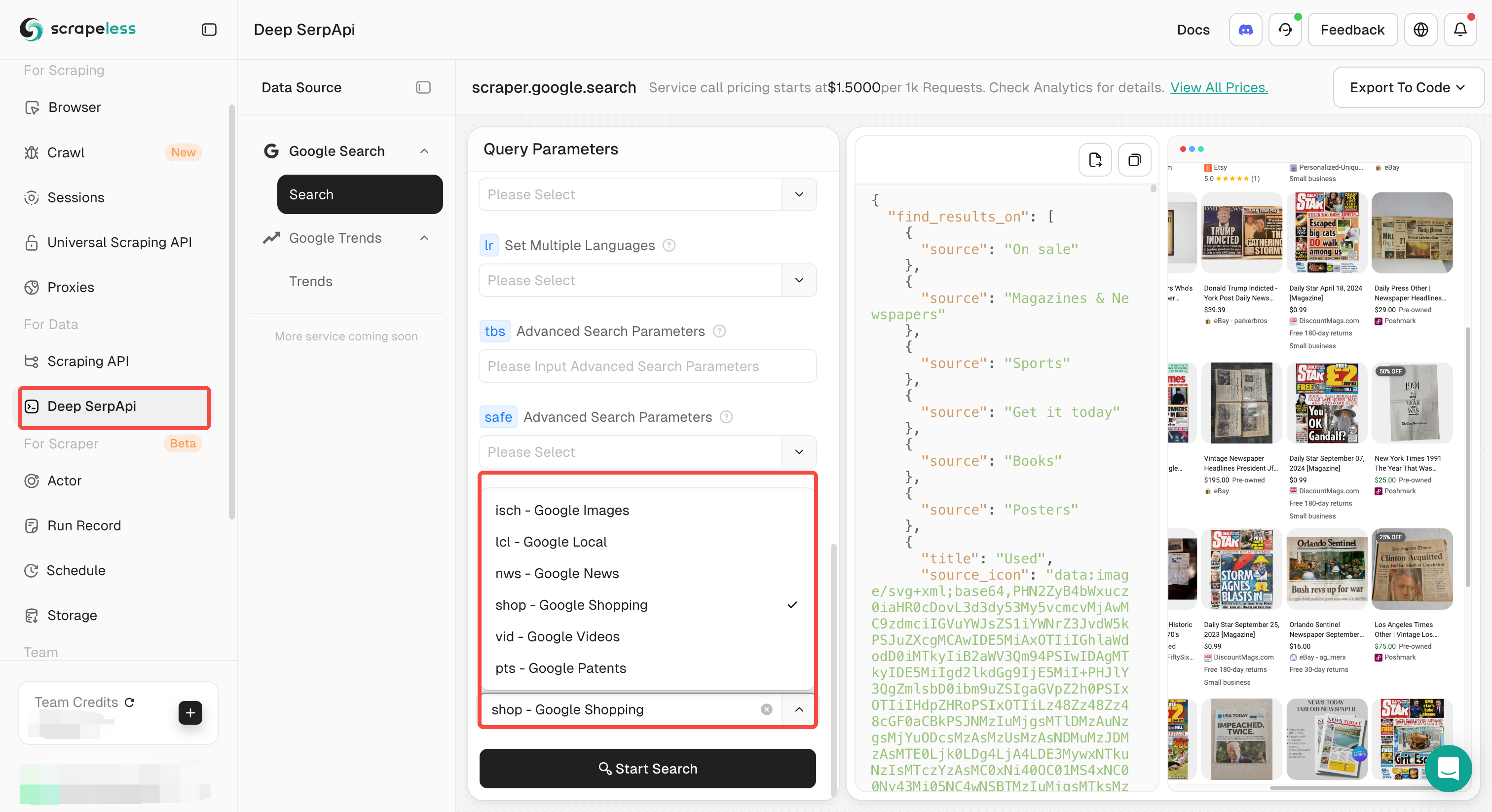
在工具列表中寻找“Deep SerpApi”由scrapelesshq提供
-
点击“Deep SerpApi”将其添加到您的工作流程中
4. 详细配置过程
步骤 1:添加Deep SerpApi节点
-
在工作流程编辑器中点击“+”按钮
-
选择工具选项卡
-
选择**Deep SerpApi (Scrapeless)**并将其添加到您的工作流程中
-
在配置面板中,粘贴之前复制的API令牌
步骤 2:配置搜索参数
- 在Deep SerpApi节点的查询字符串字段中输入您的搜索查询,例如:
"您的公司名称" 新闻
- 支持高级搜索语法,如:
"您的公司名称" OR "行业关键字""公司名称" AND (公告 OR 合作)
- 在此示例中,我们使用:
{{ company }} 最新商业新闻 2025年6月 site:reuters.com OR site:bloomberg.com OR site:cnn.com步骤 3:添加模板节点以格式化搜索结果
-
点击Deep SerpApi节点后的**“+”**按钮。
-
从可用块中选择**“模板”**。
-
在模板字段中,输入以下格式化模板:
搜索结果:
{% for item in arg1[0].organic_results %}
- 标题: {{ item.title }}
- 链接: {{ item.link }}
{% endfor %}- 该模板将以结构化方式显示搜索结果,以便后续的AI分析。
步骤 4:配置AI分析节点
- 点击Deep SerpApi节点后的**“+”**按钮。
- 从可用块中选择**“LLM”**。
- 选择您喜欢的AI模型(建议使用GPT-4)。
您需要点击**“模型提供者设置”**以安装或激活您的模型。
-
您将被带到一个选择LLM的页面。您可以自由选择想要的模型。我们将使用Claude作为示例。
-
在系统提示中,引用搜索结果:
您是一名商业情报分析师。
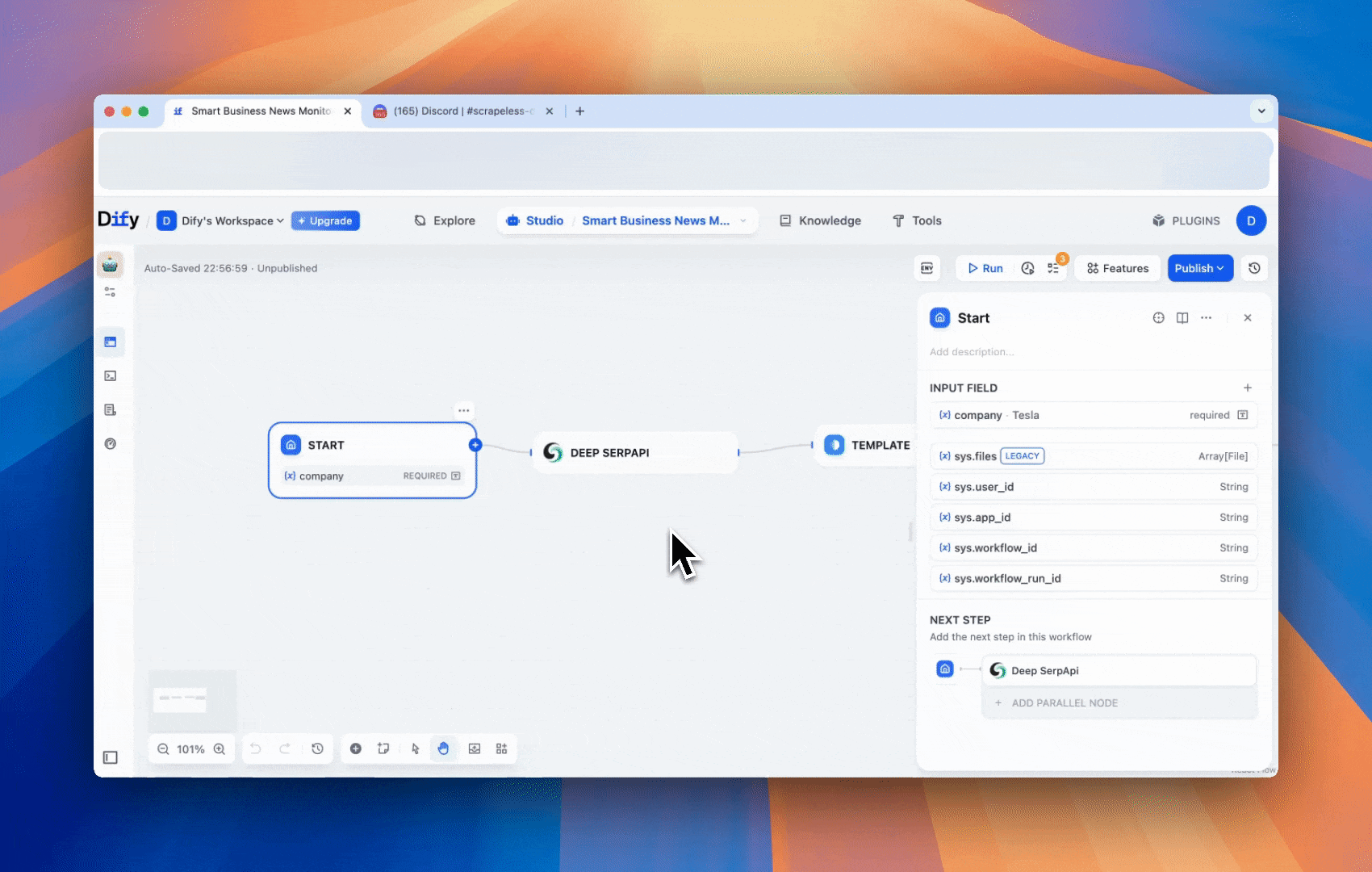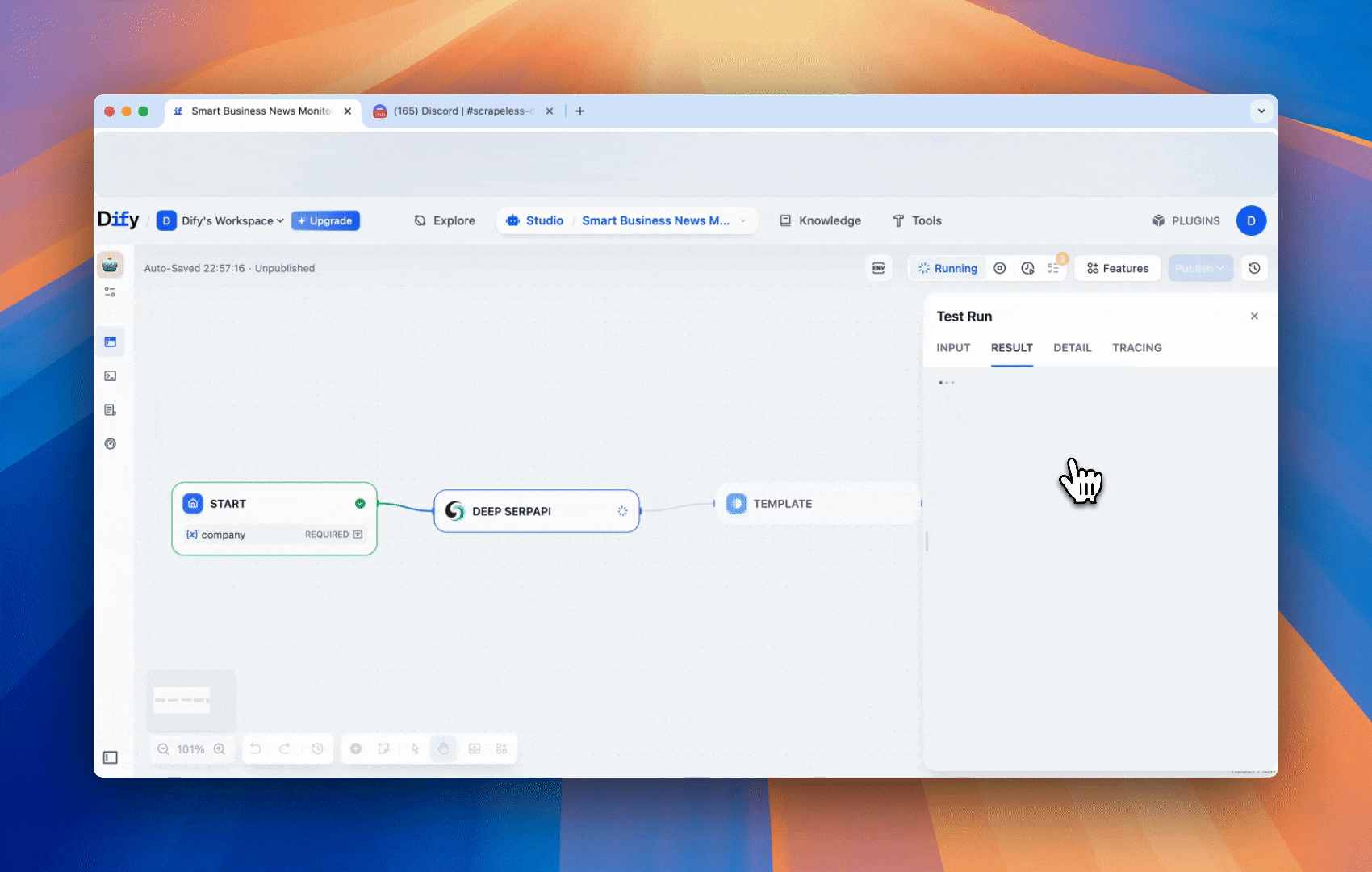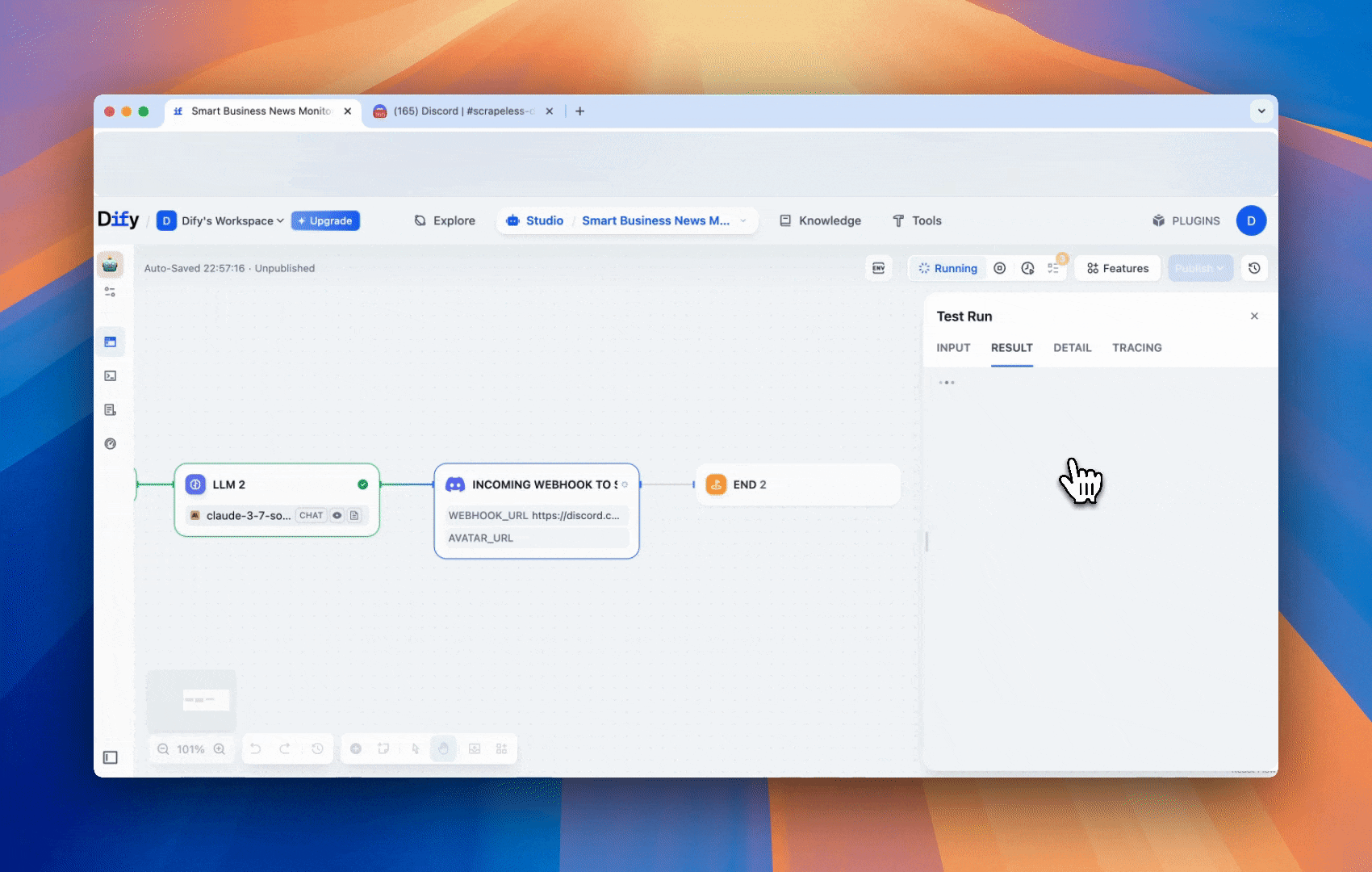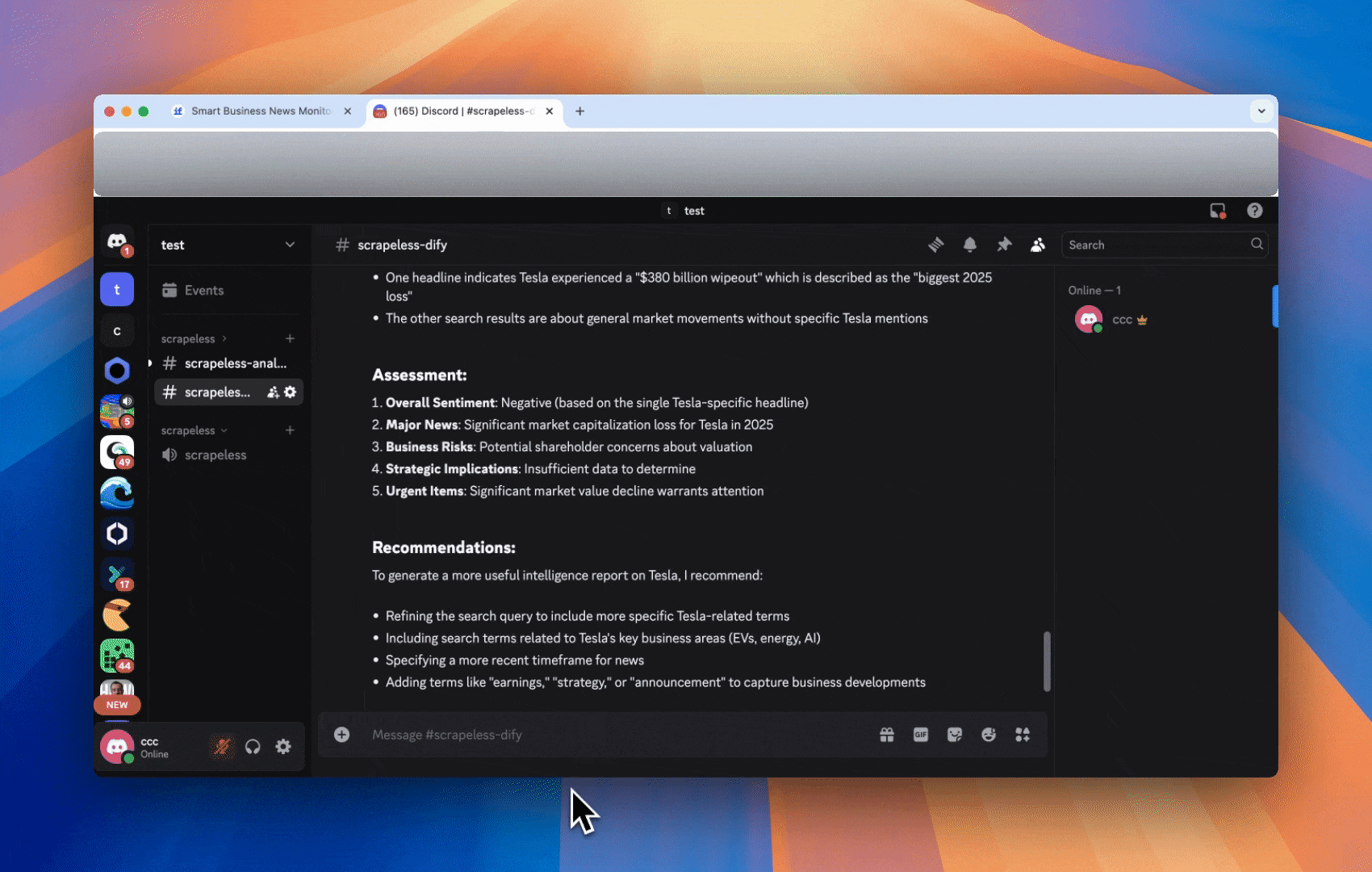
根据以下搜索结果,为公司“{{ company }}”生成一份简明的B2B情报报告。您的报告应包括:
1. 整体情绪(积极/中立/消极)
2. 主要新闻动态或更新
3. 商业风险或机会
4. 对公司的战略影响
5. 任何紧急或值得注意的事项
如果搜索结果过于笼统或缺乏公司特定内容,请指出这一点并建议如何改进查询。
在适当的地方使用要点。保持语气专业且可操作。- 在用户提示中,引用格式化的模板结果:
请分析这些关于公司的搜索结果:基于新闻标题、内容和来源的见解。- 然后,在生成文本框中,使用/调用变量选择器,您可以调用包括输出、文本、系统等变量的列表,以便插入模板或设置变量。
步骤 5:运行和调试工作流程
-
点击界面右上角的运行按钮
-
等待工作流程执行并检查输出结果
-
根据分析结果,调整搜索关键词和 AI 提示以优化性能
第 6 步:集成企业通知渠道(例如 Discord Webhook) (可选)
要在工作流程完成时直接在您的 Discord 服务器接收通知,您可以添加 webhook 集成:
- 添加新块:
- 在您的 LLM 分析 步骤后点击 “+” 按钮
- 从块菜单中选择 “工具”
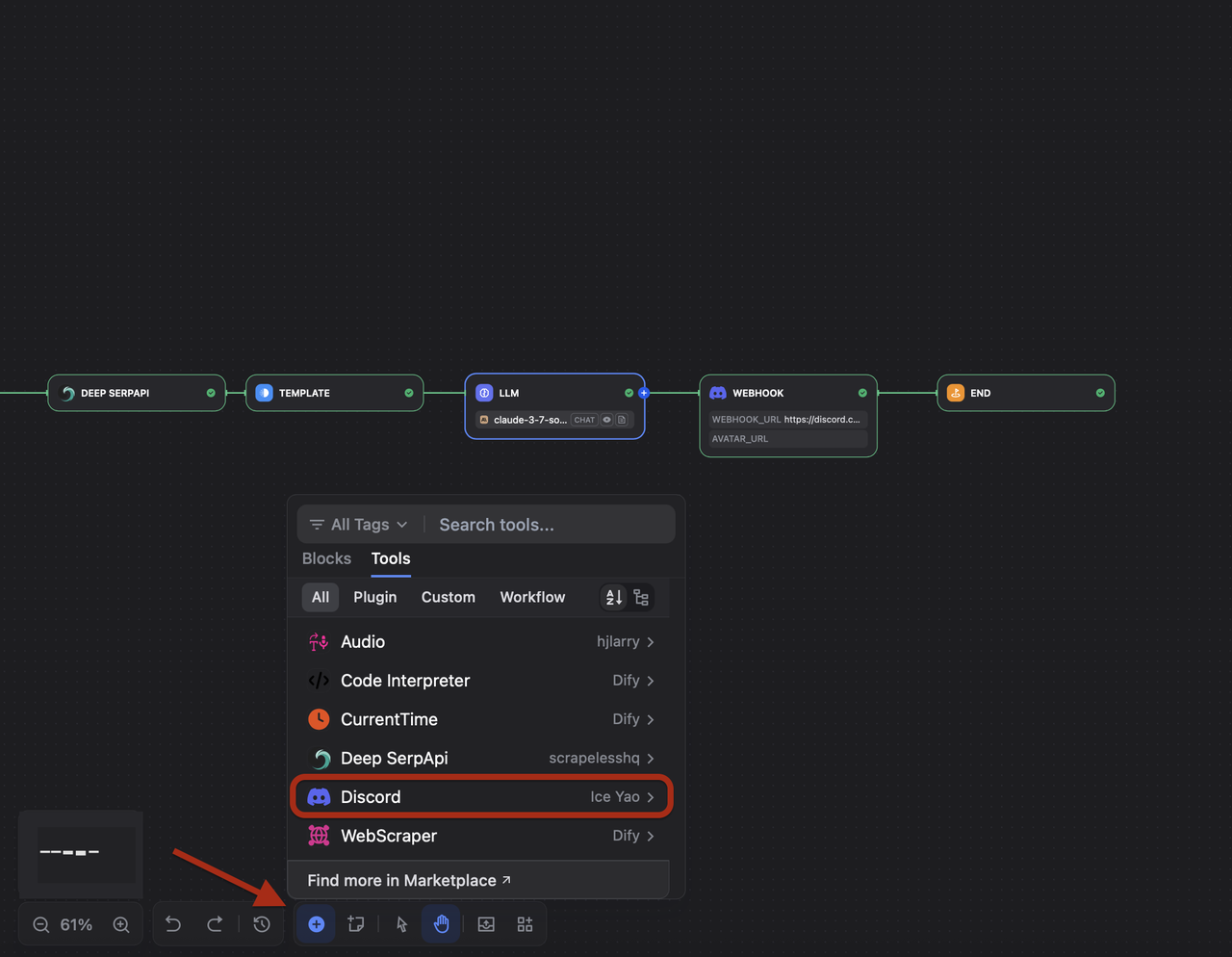
- 在市场中找到 Discord Webhook:
- 在工具部分,点击 “市场”
- 搜索 “Discord” 或 “webhook”
- 如果该工具尚未可用,请安装 Discord webhook 工具 Discord 插件市场
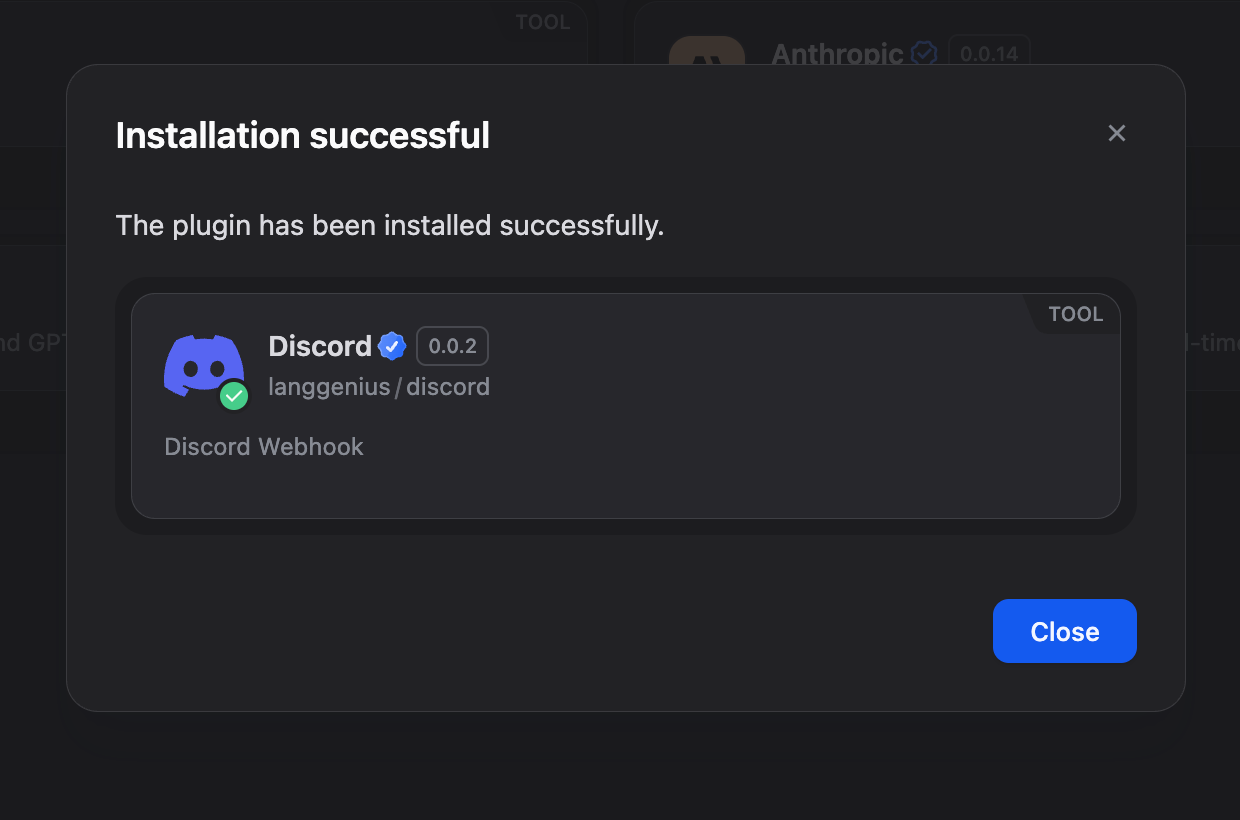
- 配置您的 Webhook:
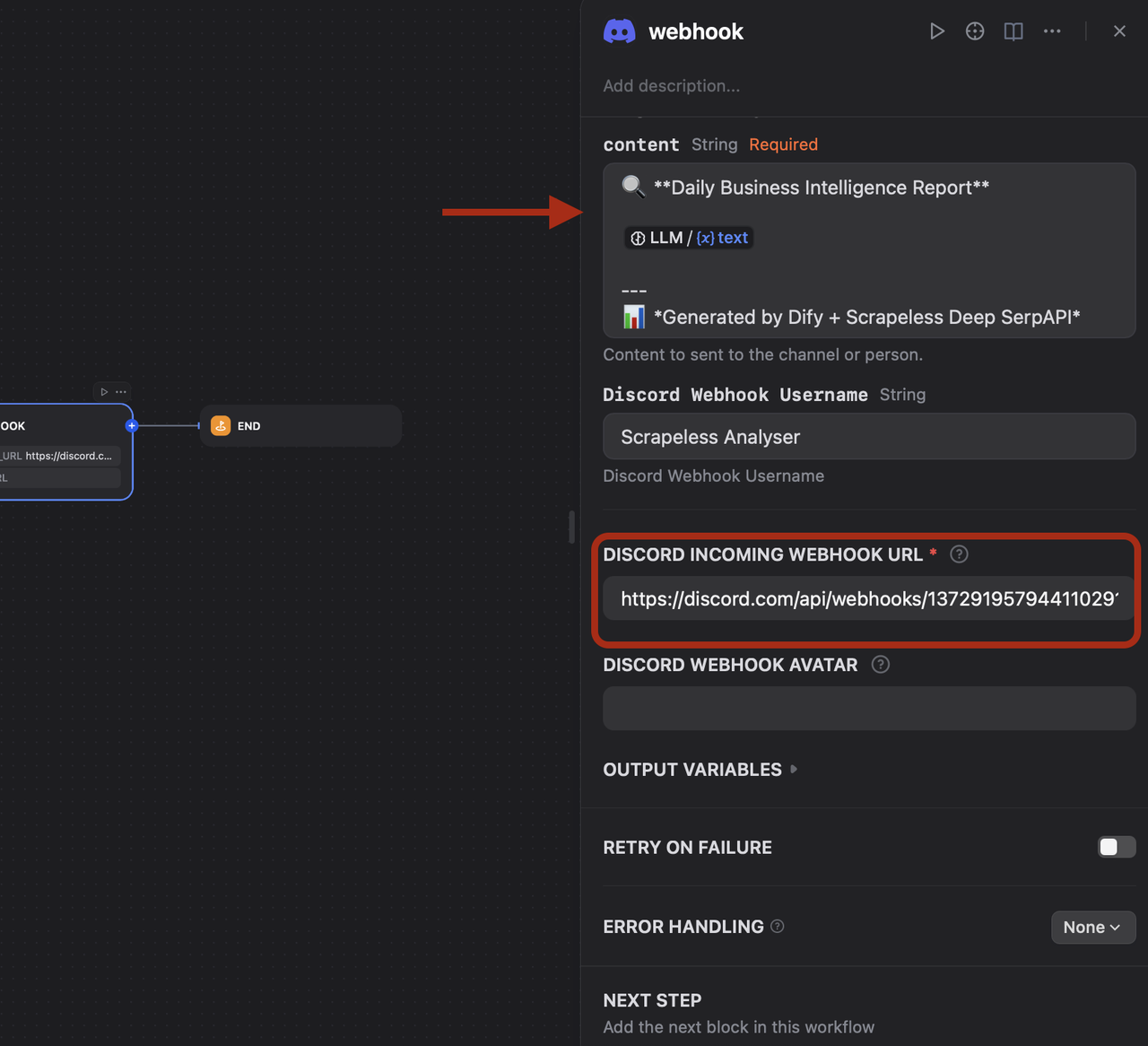
- 选择 Discord Webhook 工具
- 输入您的 Discord Webhook URL (您可以在 Discord 服务器设置中获取)
- 自定义消息格式以包含 分析结果
- 使用来自先前步骤的变量以包含 动态内容
- 消息定制:
- 在通知中包含 搜索查询
- 添加 关键发现摘要
- 格式化消息以便于 Discord 中的阅读
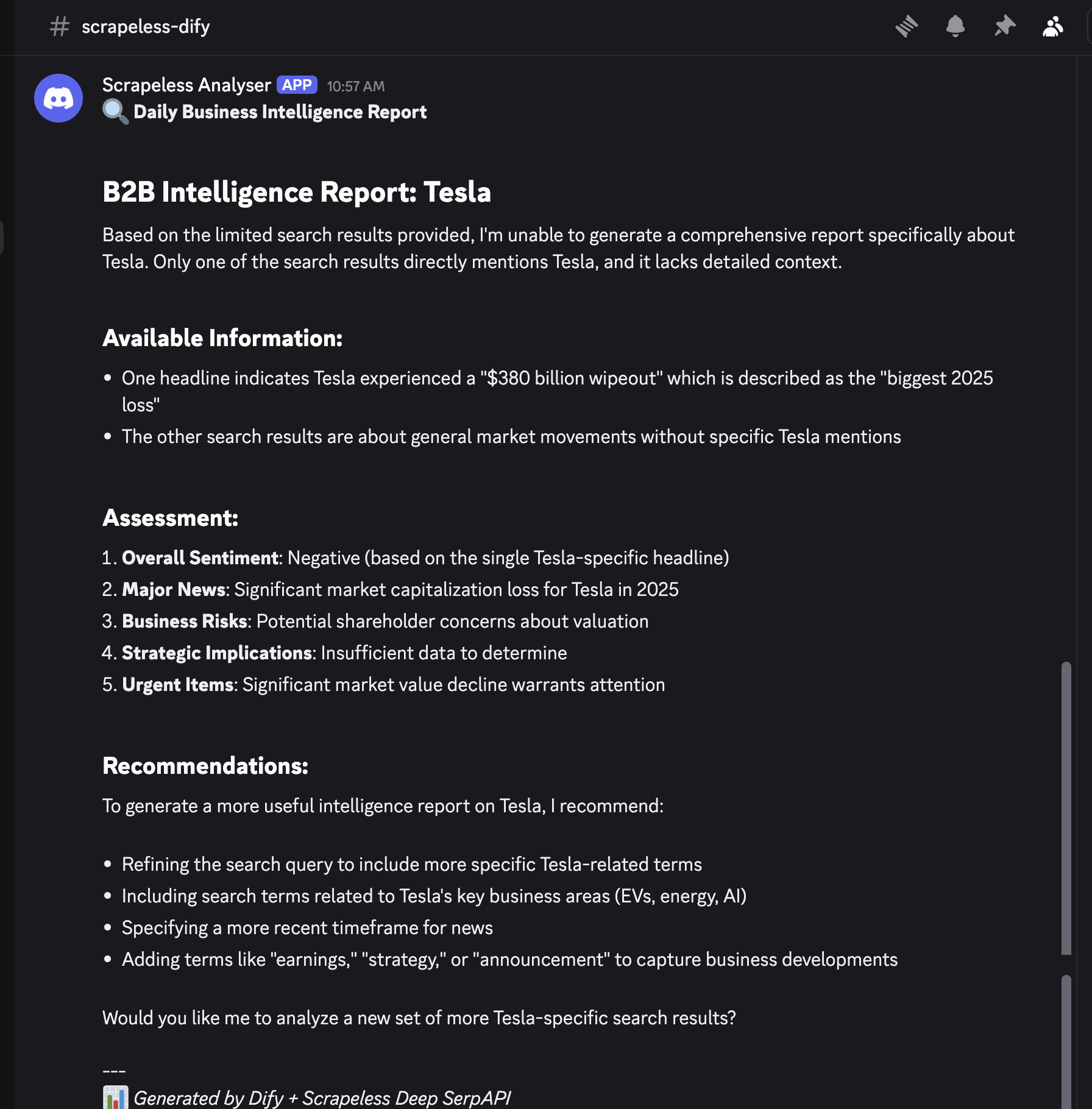
🔍 **每日商业情报报告**
/ context
---
📊 *由 Dify + Scrapeless Deep SerpAPI 生成*注意: 您可以通过遵循相同的过程,并在市场中搜索适当的工具,来使用您选择的任何 webhook 服务(Slack、Microsoft Teams 等)。
第 7 步:添加结束节点以完成工作流程配置
为了正确完成您的工作流程,添加一个结束块:
1. 添加最终块:
- 在您的 webhook 步骤(如果您跳过了 webhook,则在 LLM 步骤后)点击 "+" 按钮
- 从块菜单中选择 "结束"
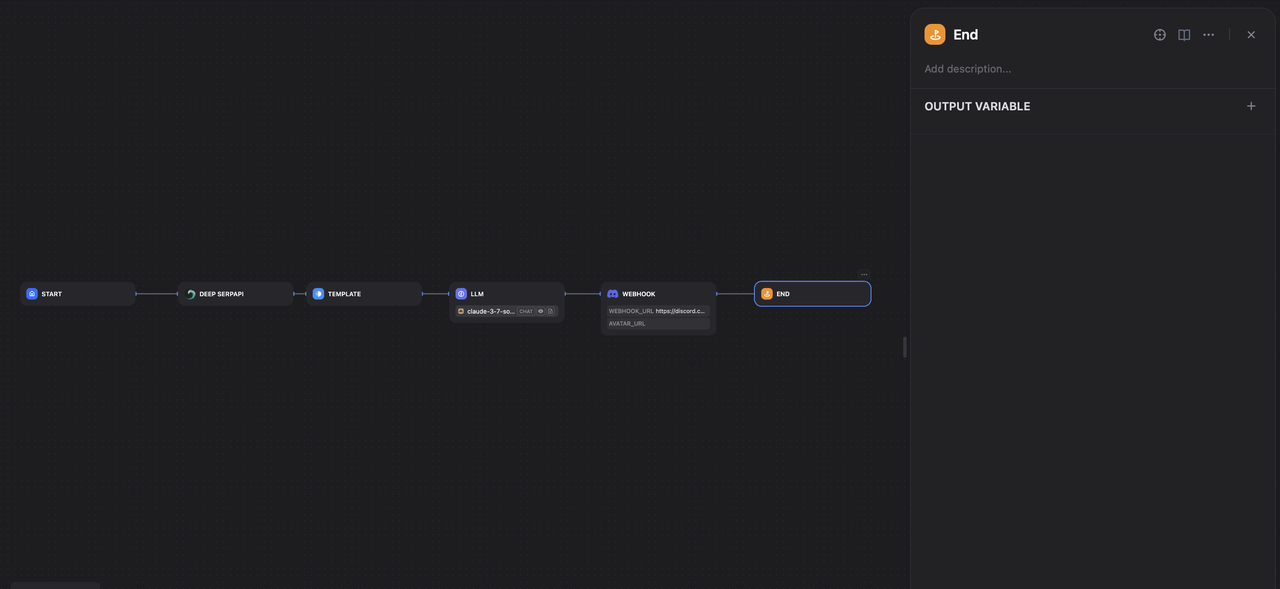
2. 配置结束块:
- 结束块标志着您的工作流程的完成
- 您可以选择配置在工作流程完成时返回的输出变量
- 如果您想将此工作流程作为更大自动化的一部分使用,这将很有用
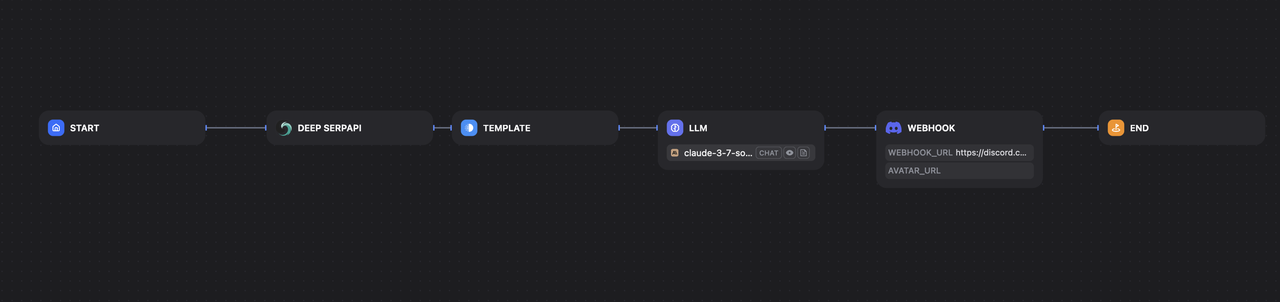
您完整的工作流程现在应如下所示:
第 8 步:输出结果
🚀 准备好提升您的智能工作流程了吗?
立即注册 Scrapeless Google SERP API,即可立即获得 2,500 次免费 API 调用 —— 不需要信用卡。
体验为规模、精准和 AI 原生工作流程构建的实时结构化搜索数据。👉 免费开始 并为您的下一个项目增添动力!
工作流程演示
为了帮助您更好地理解这个智能商业新闻监测工作流程如何从头到尾运行,我们创建了一个简短的 GIF 演示。它展示了每个步骤的操作 —— 从使用 Deep SerpApi 获取实时搜索结果,到通过模板块格式化结果,再到使用 LLM 分析数据,最后通过 Discord webhook 发送洞察。
5. 成功故事与绩效影响
领先金融机构
“从被动到主动” — 实时新闻监测准确率达到 95%
一家主要金融机构在监测与银行法规、声誉风险和宏观经济事件相关的快速变化的新闻周期方面面临挑战。在部署系统之前,他们的合规和风险团队在很大程度上依赖手动媒体追踪,这一过程费时且常常耽误关键响应。
在整合 Dify + Scrapeless 监测系统后:
- 新闻检测延迟减少了 80%,实现了对监管或声誉风险的近实时意识。
- 基于情绪的警报模型的准确性提高到 95%,得益于高质量的结构化 SERP 数据为 AI 分类器提供了支持。
- 跨部门协作得到改善,警报直接推送到内部 Slack 渠道和商业智能仪表板。
- 结果:风险缓解窗口从小时缩短至分钟,减少了负面新闻或错误信息带来的潜在损害。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


