
构建一个基于AI的研究助手,使用Linear + Scrapeless + Claude
Advanced Data Extraction Specialist
现代团队需要即时访问可靠的数据以进行明智的决策。无论您是在研究竞争对手、分析趋势,还是收集市场情报,手动数据收集都会减缓您的工作流程并打断您的开发势头。
通过将Linear的项目管理平台与Scrapeless强大的数据提取API以及Claude AI的分析能力相结合,您可以创建一个智能研究助手,该助手可以直接在您的Linear问题中响应简单命令。
此集成将您的Linear工作区转变为智能指挥中心,在此处输入/search竞争对手分析或/trends AI市场将自动触发全面的数据收集和AI驱动的分析——所有内容都以结构化评论的形式返回到您的Linear问题中。
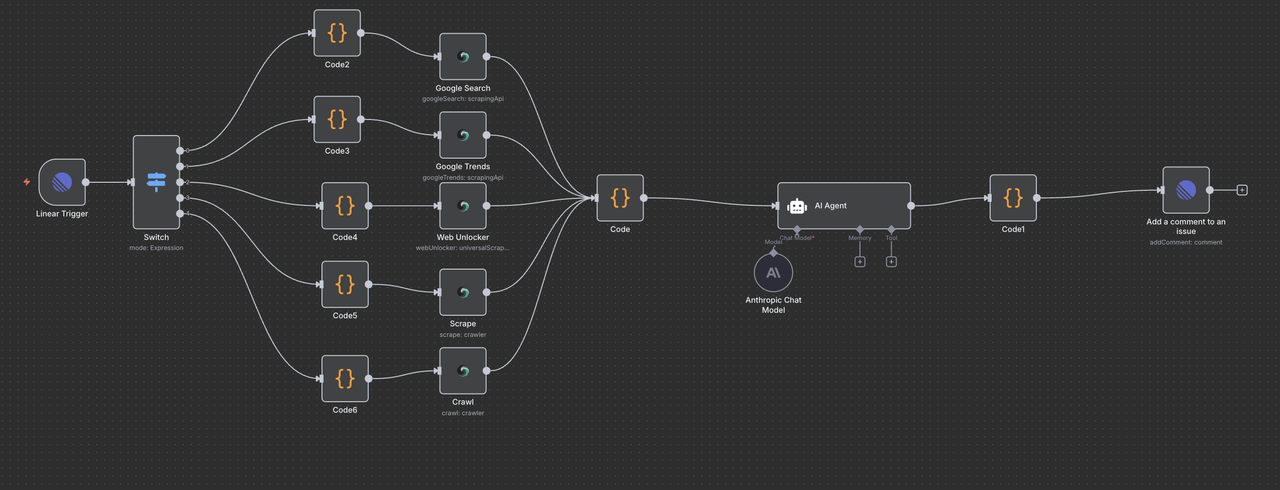
为什么选择Linear + Scrapeless + Claude?
Linear:现代开发工作空间
Linear提供了完美的团队协作和任务管理接口:
- 以问题驱动的工作流程:与开发流程自然集成
- 实时更新:即时通知和同步团队沟通
- Webhook和API:与外部工具的强大自动化能力
- 项目跟踪:内置分析和进度监控
- 团队协作:无缝评论和讨论功能
Scrapeless:企业级数据提取
Scrapeless提供可靠、可扩展的多源数据提取:
- 谷歌搜索: 实现对谷歌SERP数据所有结果类型的全面提取。
- 谷歌趋势: 从谷歌获取关键词趋势数据,包括随时间的流行度、地区兴趣和相关搜索。
- 通用抓取API: 访问和提取通常会阻止机器人访问的JS渲染网站的数据。
- 爬虫: 爬取网站及其链接页面以提取全面数据。
- 抓取: 从单个网页提取信息。
Claude AI:智能数据分析
Claude AI将原始数据转化为可操作的见解:
- 高级推理:复杂的分析和模式识别
- 结构化输出:干净、格式化的响应,适合Linear评论
- 上下文意识:理解商业上下文和用户意图
- 可操作见解:提供建议和下一步措施
- 数据综合:将多个数据源结合成连贯的分析
用例
竞争情报指挥中心
即时竞争对手研究
- 市场定位分析:自动化竞争对手网站的爬取和分析
- 趋势监控:跟踪竞争对手提及和品牌情感变化
- 产品发布检测:识别竞争对手何时推出新功能
- 战略见解:AI驱动的竞争定位分析
命令示例:
/search "competitor product launch" 2024
/trends competitor-brand-name
/crawl https://competitor.com/products市场研究自动化
实时市场情报
- 行业趋势分析:自动化的Google Trends监控市场细分
- 消费者情感:产品类别的搜索趋势分析
- 市场机会识别:AI驱动的市场缺口分析
- 投资研究:初创企业和行业融资趋势分析
命令示例:
/trends "artificial intelligence market"
/search "SaaS startup funding 2024"
/crawl https://techcrunch.com/category/startups产品开发研究
功能研究与验证
- 用户需求分析:产品功能的搜索趋势分析
- 技术研究:自动化文档和API研究
- 最佳实践发现:爬取行业领袖以获取实施模式
- 市场验证:产品市场适应性评估的趋势分析
命令示例:
/search "user authentication best practices"
/trends "mobile app features"
/crawl https://docs.stripe.com/api实施指南
第一步:设置Linear工作区
准备您的Linear环境
-
访问您的Linear工作区
- 前往linear.app并登录您的工作区
- 确保您具有管理员权限以便配置Webhook
- 创建或选择一个进行研究自动化的项目
-
生成Linear API令牌
- 进入Linear设置 > API > 个人API令牌
- 点击**“创建令牌”**并赋予适当的权限
- 复制令牌以用于n8n配置
第二步:设置n8n工作流
创建您的n8n自动化环境
- 设置n8n实例
- 使用n8n云或自托管(注意:自托管需要ngrok设置;在本指南中,我们将使用n8n云)
- 为Linear集成创建新工作流程
- 导入提供的工作流程JSON
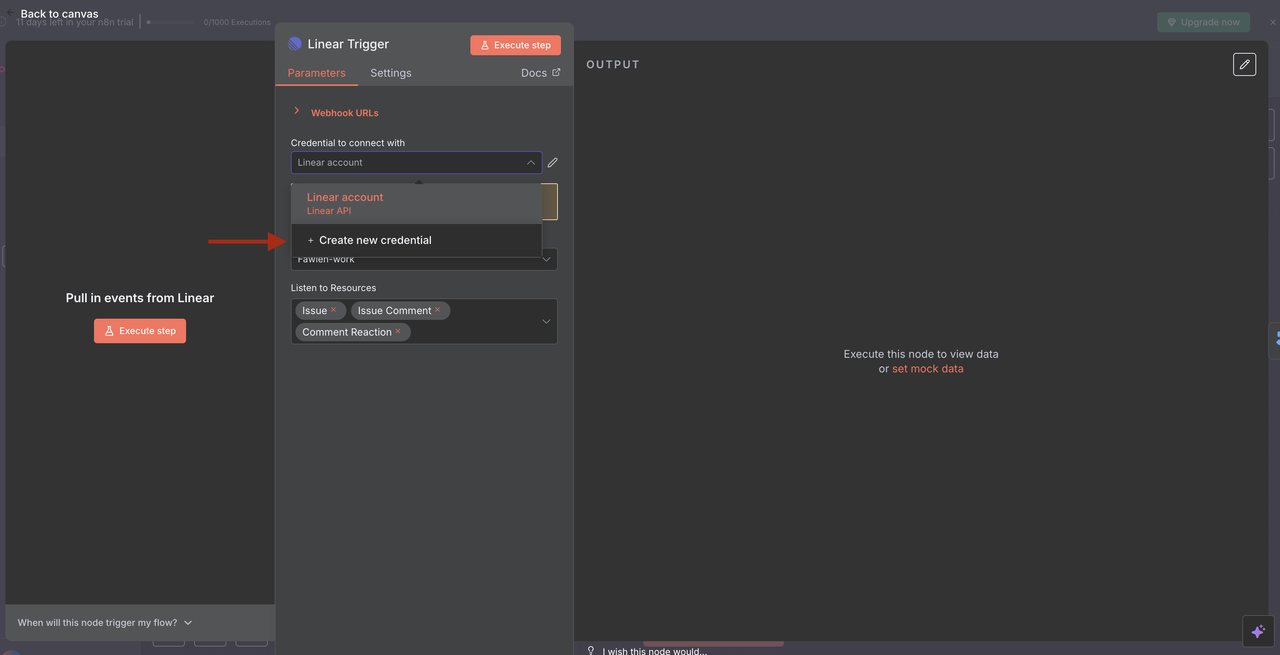
- 配置Linear触发器
- 使用您的API令牌添加Linear凭据
- 设置Webhook以监听问题事件
- 配置团队ID并根据需要应用资源过滤器
第三步:Scrapeless集成设置
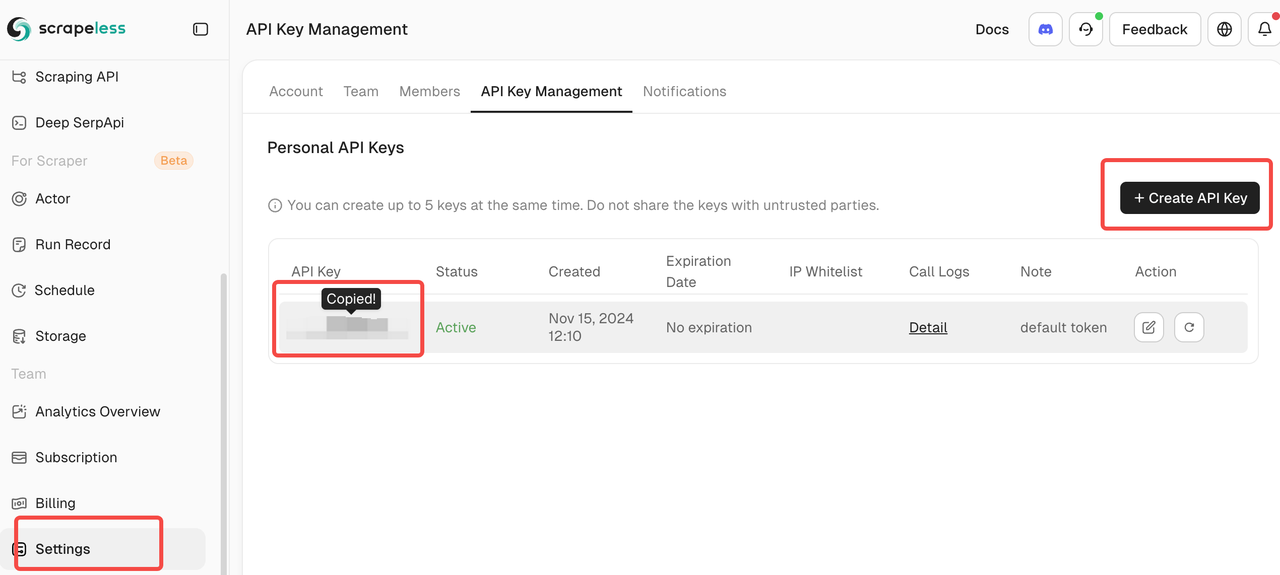
连接您的Scrapeless账户
- 获取Scrapeless凭据
- 在scrapeless.com注册
- 转到仪表盘 > API密钥
- 复制您的API令牌以进行n8n配置
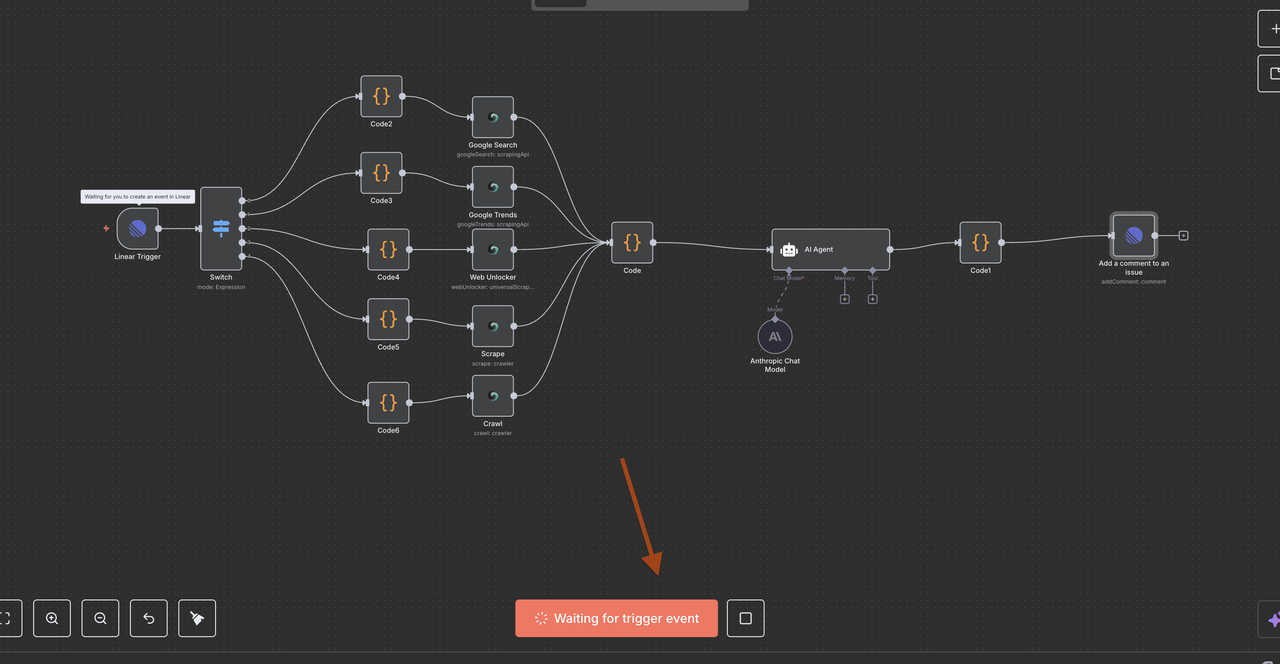
理解工作流程架构
让我们逐步浏览工作流程的每个组件,解释每个节点的功能及其如何协同工作。
第四步:Linear触发器节点(入口点)
起始点:Linear触发器
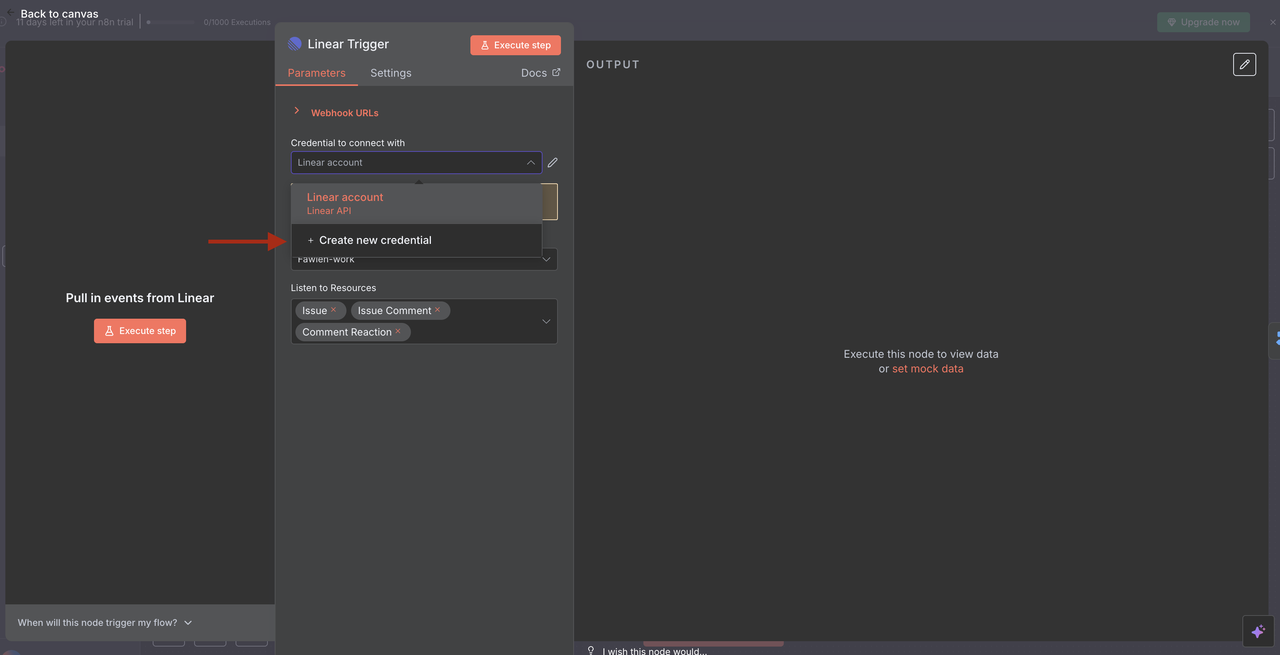
Linear触发器是我们工作流程的入口点。此节点:
功能:
- 监听来自Linear的Webhook事件,无论问题是创建还是更新
- 捕获完整的问题数据,包括标题、描述、团队ID和其他元数据
- 仅在特定事件发生时触发(例如,问题创建、问题更新、评论创建)
配置详情:
- 团队ID:链接到您特定的Linear工作区团队
- 资源:设置为监控
issue、comment和reaction事件 - Webhook URL:由n8n自动生成,必须添加到Linear的Webhook设置中
为什么这很重要:
此节点将您的Linear问题转换为自动化触发器。
例如,当有人在问题标题中输入/search competitor analysis时,Webhook会实时将该数据发送到n8n。
第五步:切换节点(命令路由器)
智能命令检测与路由
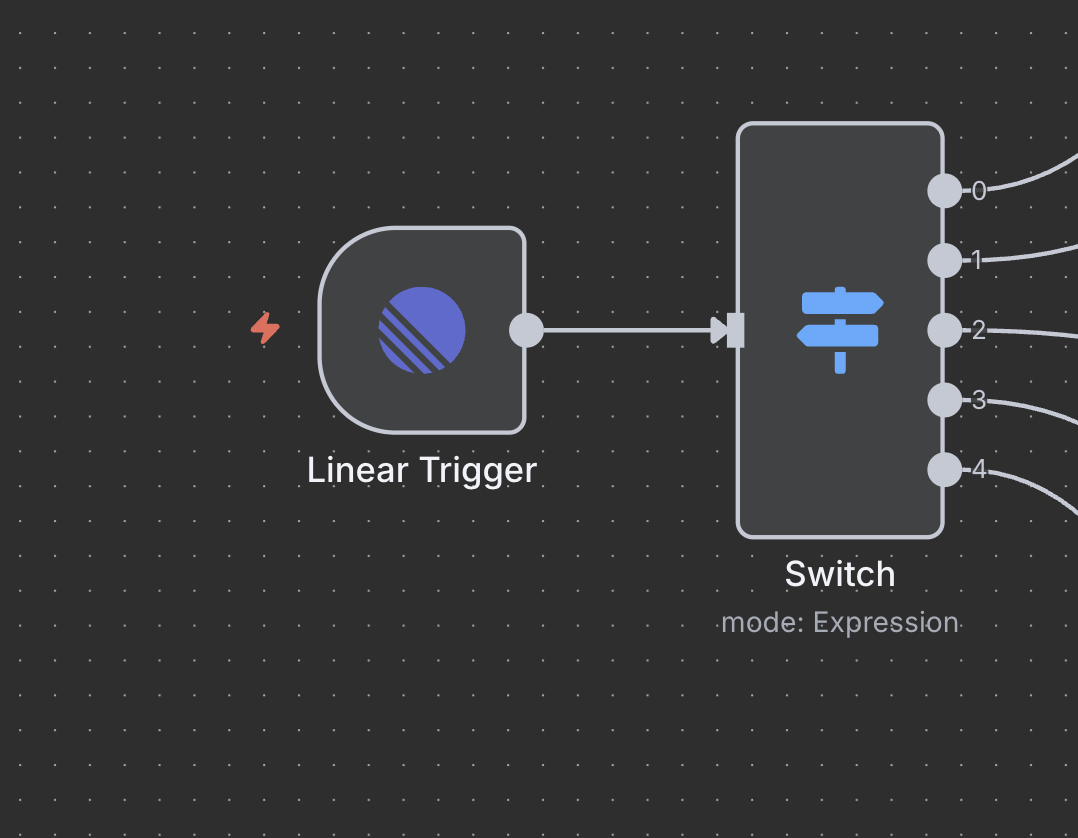
切换节点作为“大脑”,根据问题标题中的命令决定执行哪种类型的研究。
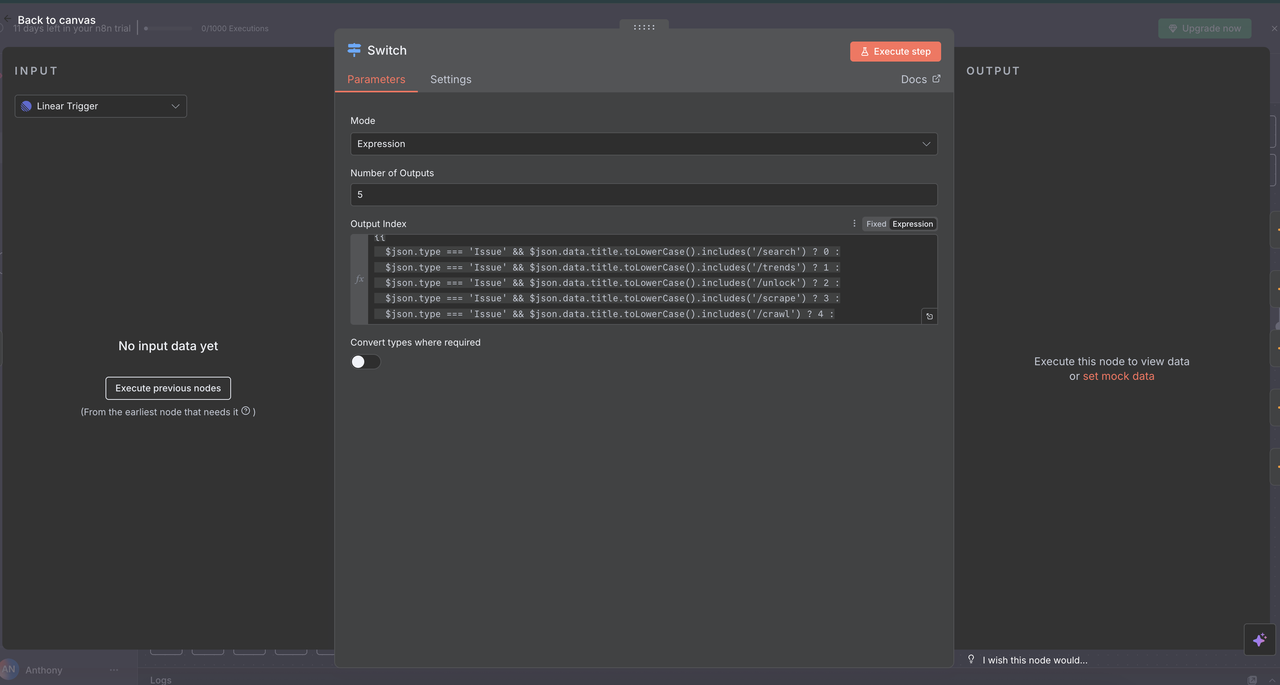
工作原理:
// 命令检测和路由逻辑
{
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/search') ? 0 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/trends') ? 1 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/unlock') ? 2 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/scrape') ? 3 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/crawl') ? 4 :
-1
}路由解释
- 输出0 (
/search):路由到Google搜索API以获取网络搜索结果 - 输出1 (
/trends):路由到Google趋势API以进行趋势分析 - 输出2 (
/unlock):路由到网页解锁器以获取受保护的内容访问 - 输出3 (
/scrape):路由到抓取器以进行单页内容提取 - 输出4 (
/crawl):路由到爬虫以进行多页网站爬取 - 输出-1:未检测到命令,流程自动结束
切换节点配置
- 模式:设置为“表达式”,用于动态路由
- 输出数量:
5(每种命令类型一个) - 表达式:JavaScript代码确定路由逻辑
第六步:标题清理代码节点
准备API处理命令
每条路由包含一个代码节点,在调用Scrapeless API之前,从问题标题中清理命令。
每个代码节点的功能:
js
// 从标题中清理命令以便进行API处理
const originalTitle = $json.data.title;
let cleanTitle = originalTitle;
// 根据检测到的命令移除命令前缀
if (originalTitle.toLowerCase().includes('/search')) {
cleanTitle = originalTitle.replace(/\/search/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/trends')) {
cleanTitle = originalTitle.replace(/\/trends/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/unlock')) {
cleanTitle = originalTitle.replace(/\/unlock/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/scrape')) {
cleanTitle = originalTitle.replace(/\/scrape/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/crawl')) {
cleanTitle = originalTitle.replace(/\/crawl/gi, '').trim();
}
return {
data: {
...($json.data),
title: cleanTitle
}
};示例转换
/search competitor analysis→competitor analysis/trends AI market growth→AI market growth/unlock https://example.com→https://example.com
为什么这个步骤重要
Scrapeless API需要干净的查询,没有命令前缀,以正常运行。
这确保发送到API的数据是精确且可解释的,提高了自动化的可靠性。
第7步:Scrapeless操作节点
本节将逐一讲解每个Scrapeless操作节点及其功能。
7.1 Google搜索节点(/search命令)
目的:
执行谷歌网页搜索并返回自然搜索结果。
配置:
- 操作:
搜索Google(默认) - 查询:
{{ $json.data.title }}(之前步骤中的清理标题) - 国家:
"US"(可以根据地区定制) - 语言:
"en"(英语)
返回内容:
- 自然搜索结果:标题、URL和摘要
- “人们还问”的相关问题
- 元数据:估计的结果数量、搜索持续时间
使用案例:
- 研究竞争对手产品
/search competitor pricing strategy
- 查找行业报告
/search SaaS market report 2024
- 发现最佳实践
/search API security best practices
7.2 Google趋势节点(/trends命令)
目的:
分析特定关键词的搜索趋势数据和随时间的兴趣。
配置:
- 操作:
Google趋势 - 查询:
{{ $json.data.title }}(清理后的关键字或短语) - 时间范围:选择从1个月、3个月、1年等选项
- 地域:设置为
全球或指定地区
返回内容:
- 随时间变化的兴趣图表(0–100尺度)
- 相关查询和趋势话题
- 兴趣的地理分布
- 趋势背景的类别细分
使用案例:
- 市场验证
/trends electric vehicle adoption - 季节分析
/trends holiday shopping trends - 品牌监控
/trends company-name mentions
7.3 网站解锁节点(/unlock命令)
目的:
访问受反机器人机制或支付墙保护的网站内容。
配置:
- 资源:
通用刮取API - URL:
{{ $json.data.title }}(必须包含有效的URL) - 无头:
false(以更好地兼容反机器人机制) - JavaScript渲染:
启用(以完全加载动态内容)
返回内容:
- 页面完整的HTML内容
- JavaScript渲染的最终内容
- 绕过常见反机器人保护的能力
使用案例:
- 竞争对手定价分析
/unlock https://competitor.com/pricing - 获取受限研究
/unlock https://research-site.com/report - 刮取动态应用
/unlock https://spa-application.com/data
7.4 刮取节点(/scrape命令)
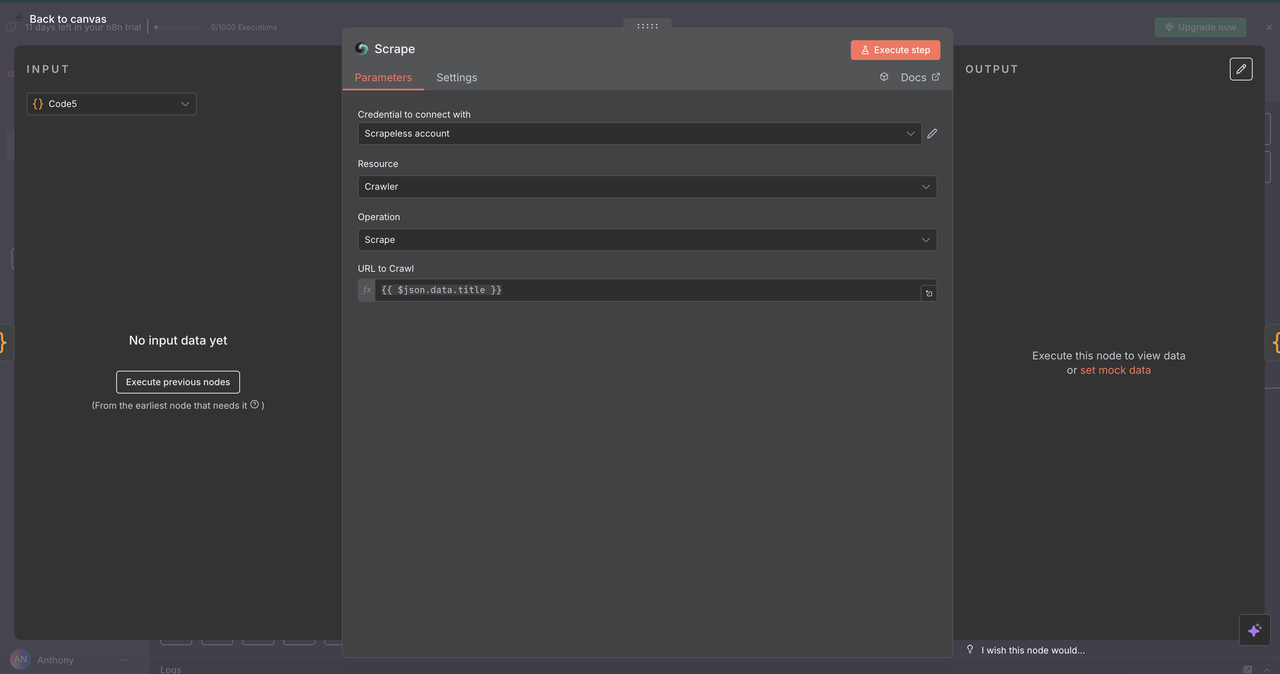
目的:
使用选择器或默认解析从单个网页中提取结构化内容。
配置:
- 资源:
爬虫(此处用于单页抓取) - URL:
{{ $json.data.title }}(目标网页) - 格式:选择输出为
HTML、文本或Markdown - 选择器:可选的CSS选择器,用于针对特定内容
返回内容:
- 来自页面的结构化、干净的文本
- 页面元数据(标题、描述等)
- 默认排除导航/广告
用例:
- 新闻文章提取
/scrape https://news-site.com/article - API 文档解析
/scrape https://api-docs.com/endpoint - 产品信息捕获
/scrape https://product-page.com/item
7.5 爬虫节点 (/crawl 命令)
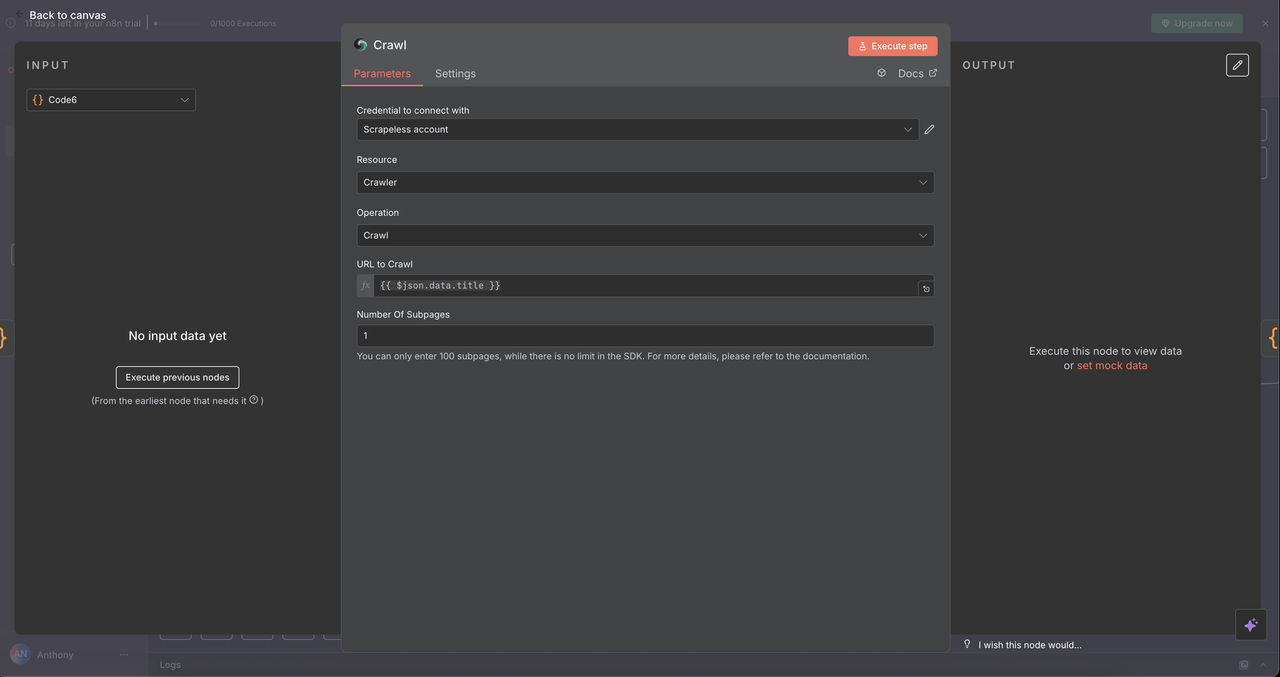
目的:
系统性地抓取一个网站的多个页面以进行全面数据提取。
配置:
- 资源:
爬虫 - 操作:
抓取 - URL:
{{ $json.data.title }}(起始点URL) - 限制抓取页面:可选上限,例如5–10页以避免过载
- 包含/排除模式:正则表达式或字符串过滤器以精细化抓取范围
返回内容:
- 来自多个相关页面的内容
- 网站的导航结构
- 跨目标域/子部分的丰富数据集
用例:
-
竞争者研究
/crawl https://competitor.com
(例如定价、功能、关于页面) -
文档映射
/crawl https://docs.api.com
(抓取整个API或开发者文档) -
内容审计
/crawl https://blog.company.com
(映射文章、类别、标签以进行SEO审查)
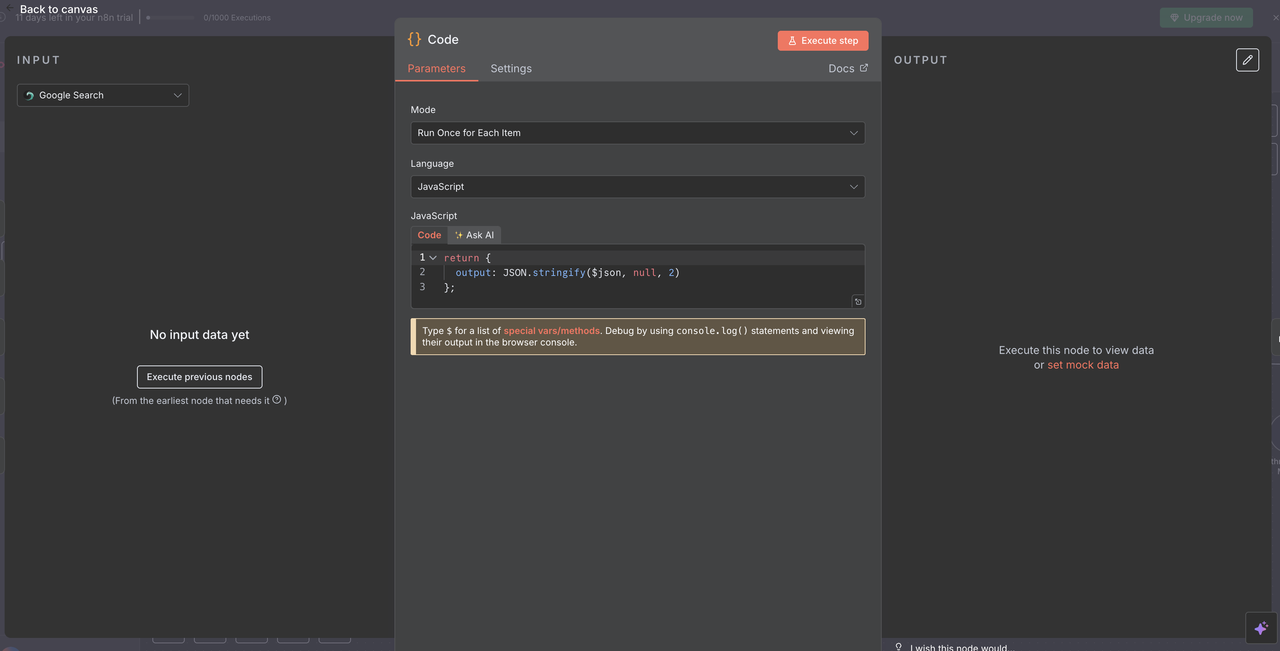
第8步:数据汇聚和处理
将所有Scrapeless结果汇集在一起
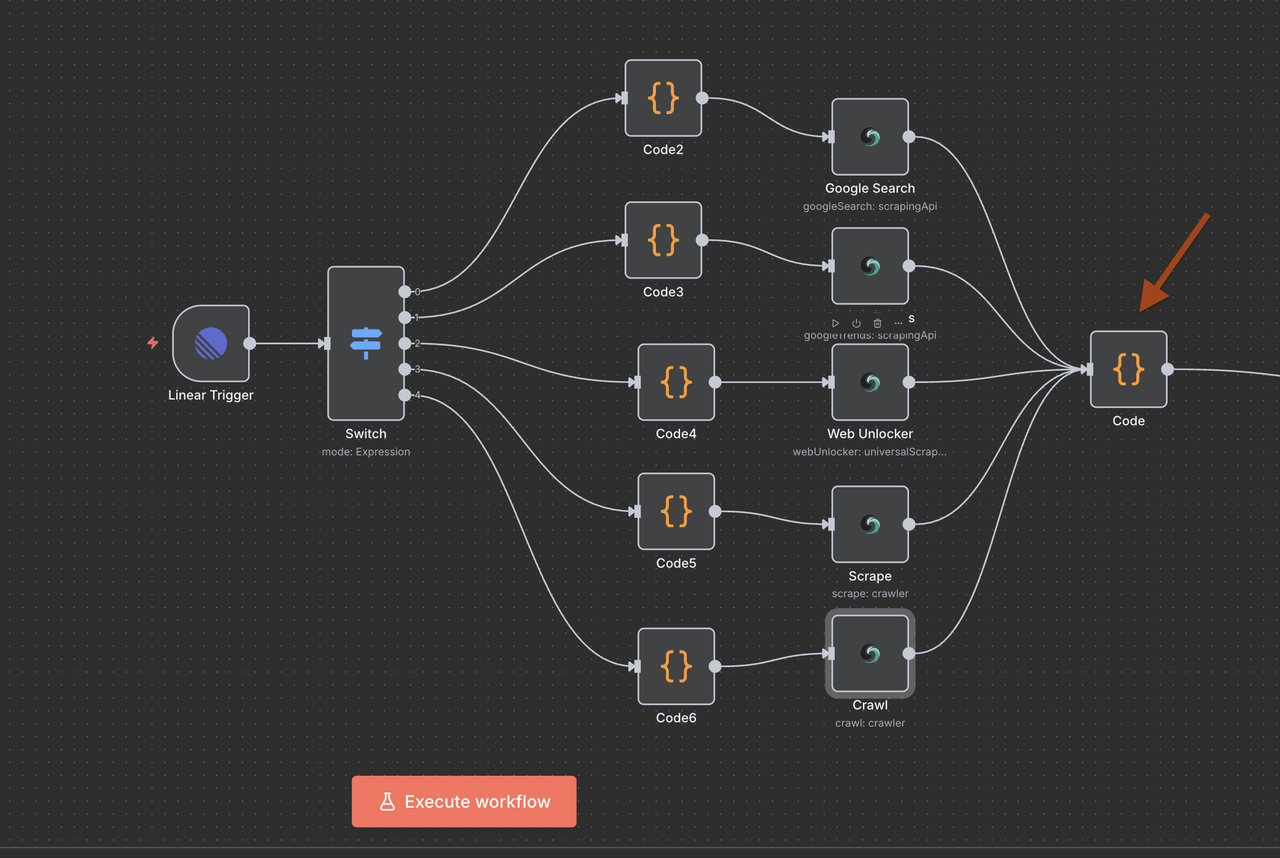
在执行5个Scrapeless操作分支之一后,使用单个代码节点对响应进行标准化以便进行AI处理。
汇聚代码节点的目的:
- 汇总来自任何Scrapeless节点的输出
- 标准化所有命令的数据格式
- 准备Claude或其他AI模型输入的最终负载
代码配置:
javascript
// 将Scrapeless响应转换为AI可读格式
return {
output: JSON.stringify($json, null, 2)
};
第9步:Claude AI分析引擎
智能数据分析与洞察生成
9.1 AI代理节点设置
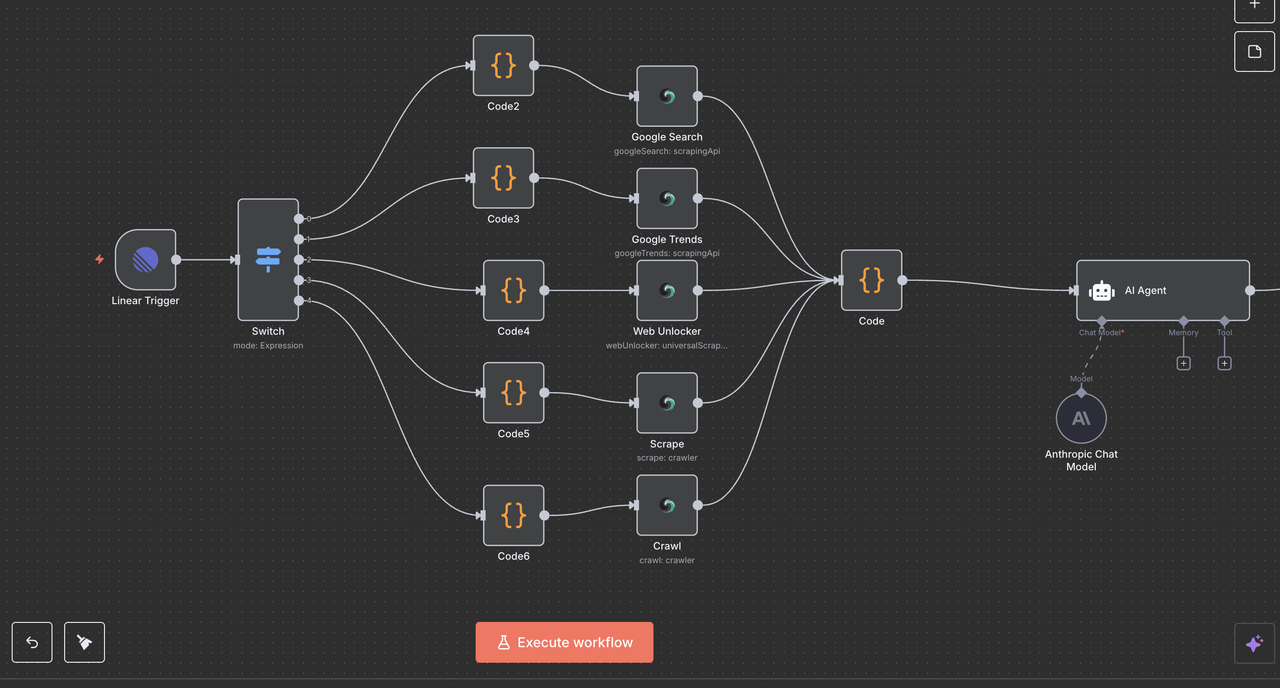
⚠️ 别忘了设置您的Claude API密钥。
AI代理节点是魔法发生的地方——它接收标准化的Scrapeless输出并将其转化为清晰的、可操作的洞察,适合用于Linear评论或其他报告工具。
配置详情:
- 提示类型:
定义 - 文本输入:
{{ $json.output }}(来自汇聚节点的处理后JSON字符串) - 系统消息:为Claude设置基调、角色和任务
AI分析系统提示:
你是数据分析师。简要总结搜索/抓取结果。要客观且简洁。格式化为Linear评论。
分析提供的数据,创建一个结构化的摘要,包括:
- 关键发现和洞察
- 数据来源和可靠性评估
- 可操作的建议
- 相关的指标和趋势
- 进一步研究的下一步
使用清晰的标题和要点格式化你的回答,以便在Linear中轻松阅读。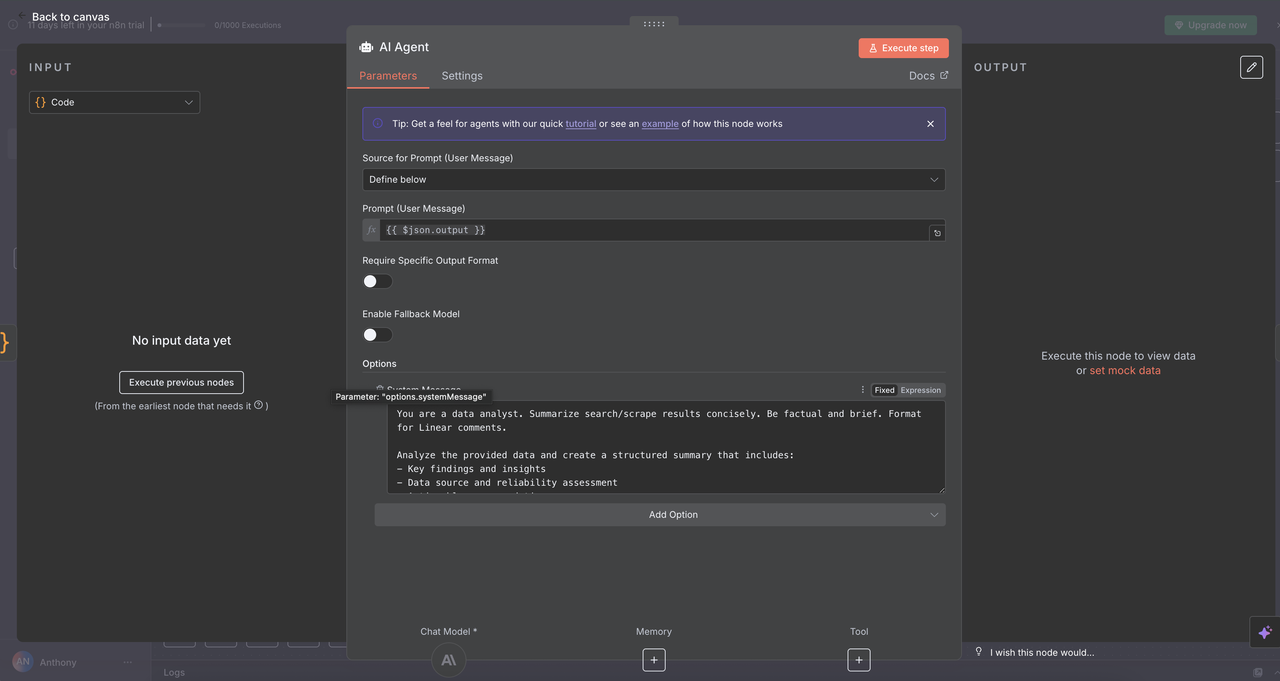
为什么这个提示有效
- 具体性:准确告诉Claude要执行什么类型的分析
- 结构:请求组织良好的输出,各部分清晰
- 上下文:优化为Linear评论格式
- 可操作性:关注团队可以采取行动的洞察
9.2 Claude模型配置
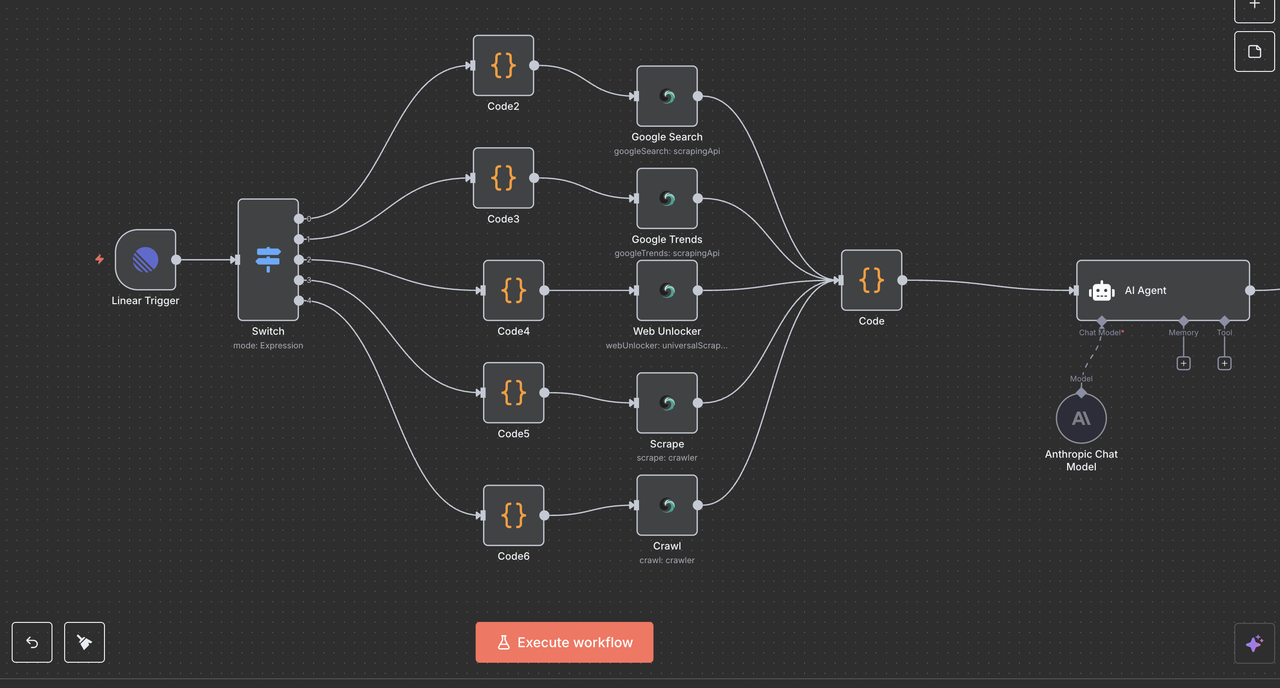
Anthropic聊天模型节点将AI代理与Claude强大的语言处理能力连接起来。
模型选择和参数
- 模型:
claude-3-7-sonnet-20250219(Claude Sonnet 3.7) - 温度:
0.3(在创造力和一致性之间取得平衡) - 最大令牌数:
4000(足够用于全面响应)
为何选择这些设置
- Claude Sonnet 3.7:智能、性能和成本效率的良好平衡
- 低温度(0.3):确保响应事实准确且可重复
- 4000 令牌:足够深入的见解生成,不会过度消耗成本
第 10 步:响应处理和清理
为线性评论准备 Claude 的输出
10.1 响应清理代码节点
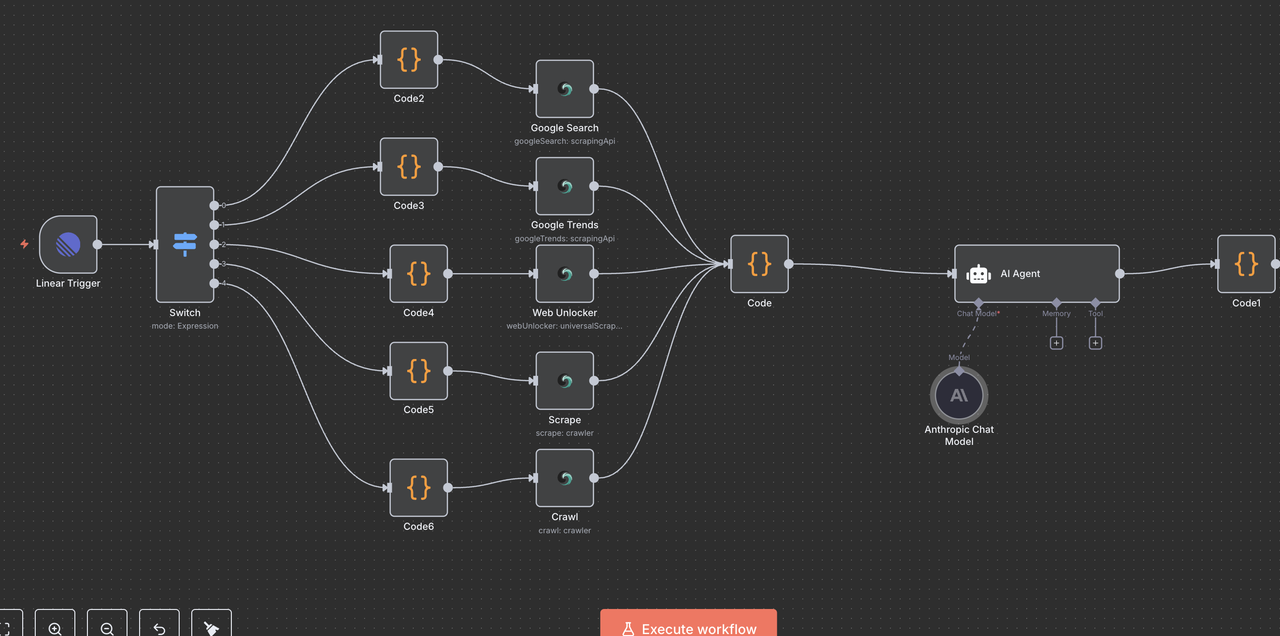
代码节点在 Claude 清理 AI 响应后,用于在线性评论中进行适当的显示。
响应清理代码:
// 清理 Claude AI 响应以适用于线性评论
return {
output: $json.output
.replace(/\\n/g, '\n')
.replace(/\\\"/g, '"')
.replace(/\\\\/g, '\\')
.trim()
};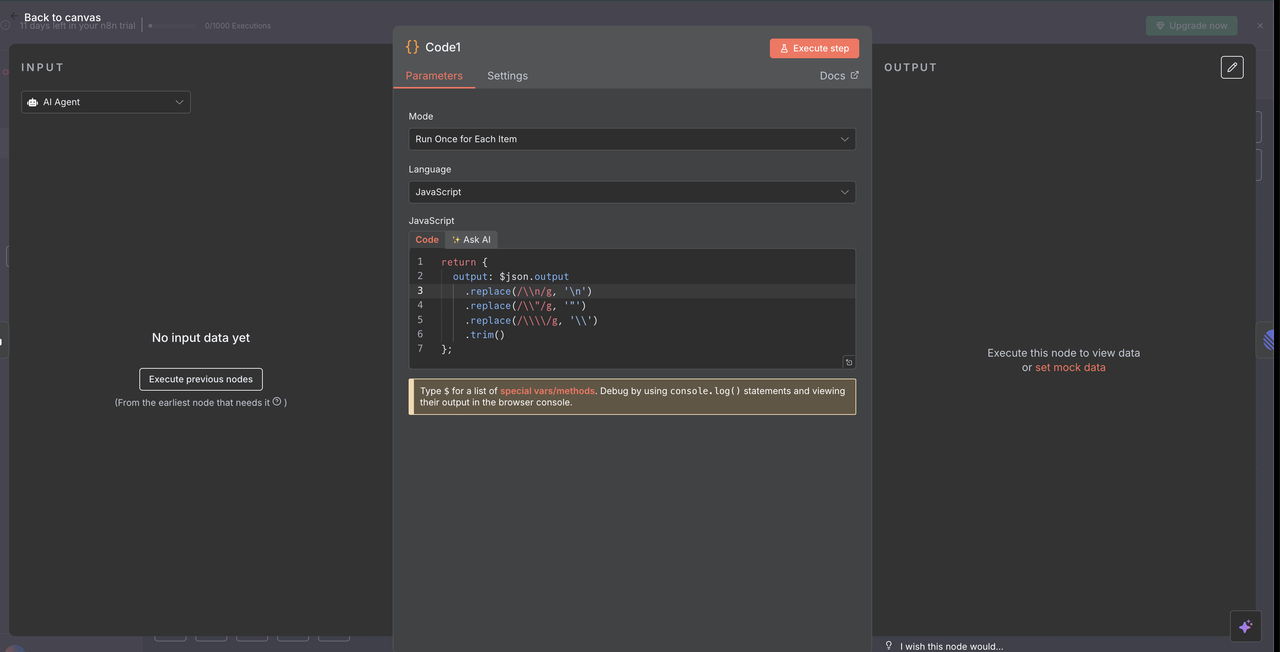
清理的功效
- 移除转义字符:去除 JSON 转义字符,防止错误显示
- 修复换行符:将字面量
\n字符串转换为实际换行 - 规范引号:确保引号在线性评论中正确呈现
- 修剪空格:去掉多余的前导和尾随空格
为何需要清理
- Claude 的输出以 JSON 形式交付,转义特殊字符
- Linear 的 markdown 渲染器需要格式正确的纯文本
- 如果没有这个清理步骤,响应将显示原始转义字符,影响可读性
10.2 线性评论发送
最终的 线性节点 将 AI 生成的分析作为评论返回到原始问题。
配置详细信息:
- 资源:设置为 “评论” 操作
- 问题 ID:
{{ $('Linear Trigger').item.json.data.id }} - 评论:
{{ $json.output }} - 附加字段:可选择性地包括元数据或格式选项
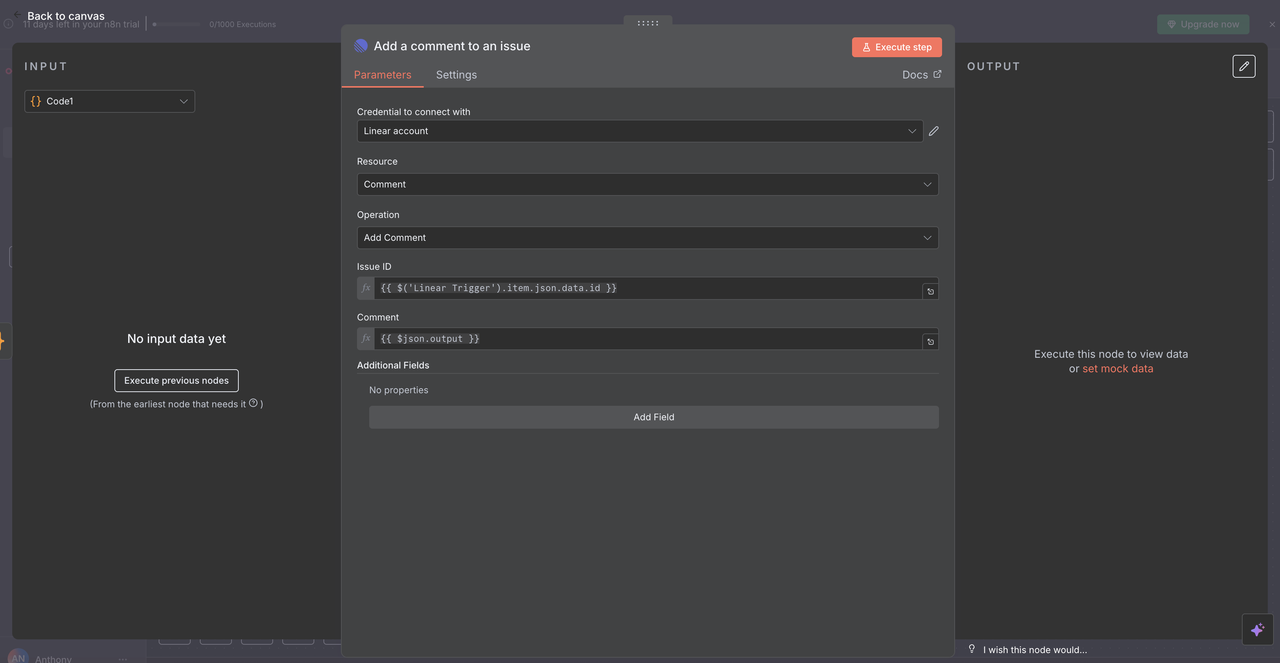
问题 ID 的工作原理
- 引用原始的 线性触发器 节点
- 使用从触发工作流的 webhook 中获得的确切问题 ID
- 确保 AI 响应显示在正确的线性问题上
完整循环
- 用户创建一个带有
/search competitive analysis的问题 - 工作流处理该命令并收集数据
- Claude 分析收集的结果
- 分析作为评论返回到同一问题
- 团队直接在上下文中查看研究见解
第 11 步:测试您的研究助手
验证完整工作流
现在所有节点都已配置,测试每种命令类型以确保正常功能。
11.1 测试每种命令类型
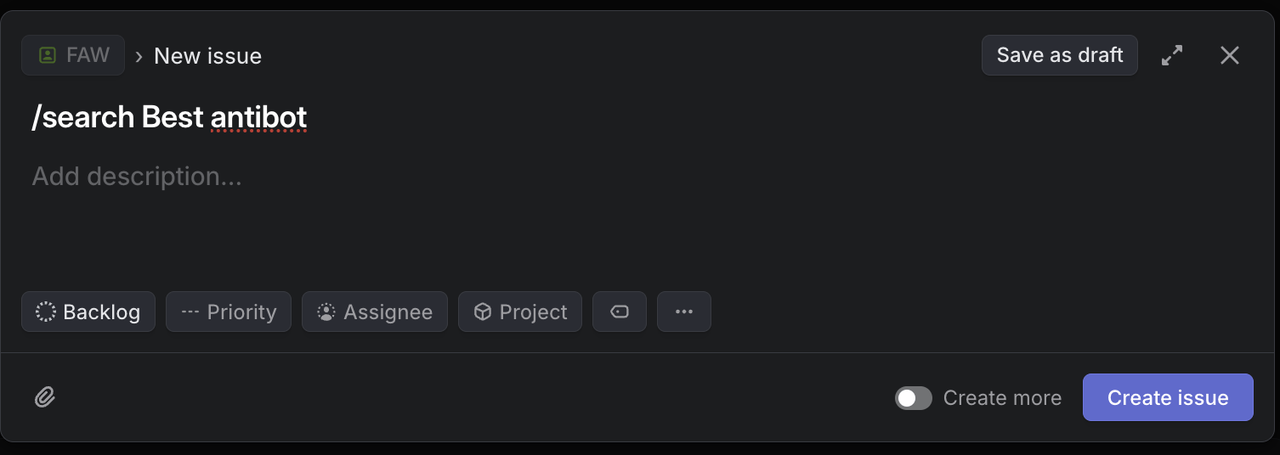
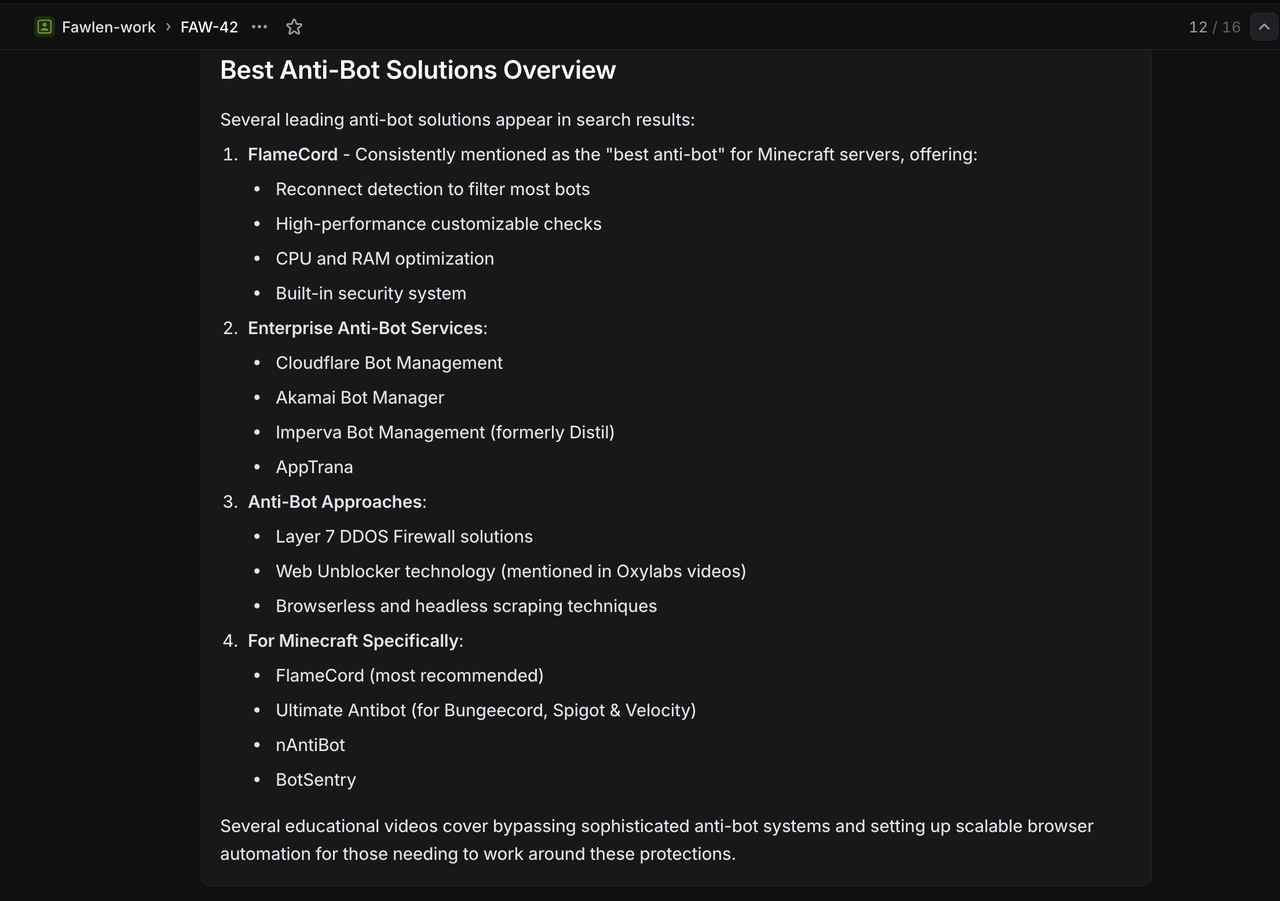
在 Linear 中创建带有以下特定标题的测试问题:
谷歌搜索测试:
`/search competitive analysis for SaaS platforms` 预期结果: 返回关于 SaaS 竞争分析的谷歌搜索结果
谷歌趋势测试:
`/trends artificial intelligence adoption` 预期结果: 返回显示随时间变化的 AI 采用兴趣的趋势数据
网页解锁测试:
`/unlock https://competitor.com/pricing` 预期结果: 从受保护或 JavaScript 重度依赖的定价页面返回内容
抓取器测试:
`/scrape https://news.ycombinator.com` 预期结果: 从 Hacker News 首页返回结构化内容
爬虫测试:
`/crawl https://docs.anthropic.com` 预期结果: 从 Anthropic 文档的多个页面返回内容
故障排除指南
Linear Webhook 问题
- 问题: Webhook 未触发
- 解决方案: 验证 webhook URL 和 Linear 权限
- 检查: n8n webhook 端点状态
Scrapeless API 错误
- 问题: 认证失败
- 解决方案: 验证 API 密钥和帐户限制
- 检查: Scrapeless 仪表板的使用指标
Claude AI 响应问题
- 问题: 分析不佳或不完整
- 解决方案: 精炼系统提示和上下文
- 检查: 输入数据质量和格式
线性评论格式
- 问题: 破损的 markdown 或格式
- 解决方案: 更新响应清理代码
- 检查: 特殊字符处理
结论
Linear 的协作工作空间、Scrapeless 的可靠数据提取和Claude AI 的智能分析的结合,创造了一个强大的研究自动化系统,改变了团队收集和处理信息的方式。
这种集成消除了识别研究需求与获取可操作洞察之间的摩擦。只需在 Linear 问题中键入命令,您的团队就可以触发全面的数据收集和分析工作流程,这通常需要数小时的手动工作。
主要好处
- ⚡ 即时研究:从问题到洞察不到 60 秒
- 🎯 上下文保留:研究与项目讨论保持连接
- 🧠 AI 增强:原始数据自动转化为可操作情报
- 👥 团队效率:整个团队可访问的共享研究
- 📊 综合覆盖:多个数据来源在统一工作流中
将团队的研究能力从被动转变为主动。通过 Linear、Scrapeless 和 Claude 的共同合作,您不仅仅在收集数据——您正在打造一个可以与您的业务一起扩展的竞争情报优势。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


