
如何最佳部署 Scrapeless Browser 和 Browser-Use?
Senior Web Scraping Engineer
Scraping Browser 已成为日常数据提取和自动化任务的首选工具。通过将 Browser-Use 与 Scrapeless Scraping Browser 集成,您可以克服浏览器自动化的限制,避免被封锁。
在本文中,我们将使用 Browser-Use 和 Scrapeless Scraping Browser 构建一个自动化的 AI 代理工具来执行自动数据抓取。您将看到它如何为您节省时间和精力,使自动化任务变得轻而易举!
您将学习:
- 什么是 Browser-Use,它如何帮助构建 AI 代理?
- 为什么 Scraping Browser 能有效克服 Browser-Use 的限制?
- 如何使用 Browser-Use 和 Scraping Browser 构建无被封锁的 AI 代理?
什么是 Browser-Use?
Browser-Use 是一个基于 Python 的 AI 浏览器自动化库,旨在赋能 AI 代理先进的浏览器自动化能力。它可以识别网页上的所有互动元素,并允许代理以编程方式与页面交互——执行常见任务,如搜索、点击、填写表单和数据抓取。Browser-Use 的核心是将网站转换为结构化文本,并支持 Playwright 等浏览器框架,从而极大地简化网页交互。
与传统自动化工具不同,Browser-Use 将视觉理解与 HTML 结构解析结合在一起,使 AI 代理能够使用自然语言指令控制浏览器。这使得 AI 在感知页面内容和高效执行任务方面更加智能。此外,它支持多标签管理、元素交互跟踪、自定义操作处理和内置错误恢复机制,以确保自动化工作流程的稳定性和一致性。
更重要的是,Browser-Use 与所有主要的大型语言模型(如 GPT-4、Claude 3、Llama 2)兼容。通过 LangChain 集成,用户只需用自然语言描述任务,AI 代理便能完成复杂的网页操作。对于寻求 AI 驱动网络交互自动化的用户,这是一个强大且有前景的工具。
Browser-Use 在 AI 代理开发中的局限性
如上所述,Browser-Use 并不能像哈利·波特的魔法棒那样运作。相反,它结合视觉输入与 AI 控制,通过 Playwright 来自动化浏览器。
Browser-Use 不可避免地存在一些缺点,但这些限制并不源自自动化框架本身,而是源自它所控制的浏览器。像 Playwright 这样的工具以特定配置和工具启动浏览器进行自动化,这也可能会暴露于反机器人检测系统。
因此,您的 AI 代理可能经常遇到 CAPTCHA 挑战或被封锁的页面,例如“抱歉,我们这边出现了问题。”要充分发挥 Browser-Use 的潜力,需要进行深思熟虑的调整。最终目标是避免触发反机器人系统,以确保您的 AI 自动化运行顺畅。
经过大量测试,我们可以自信地说:Scraping Browser 是最有效的解决方案。
什么是 Scrapeless Scraping Browser?
Scraping Browser 是一款基于云计算的无服务器浏览器自动化工具,旨在解决动态网页抓取中的三个核心问题:高并发瓶颈、反机器人规避和成本控制。
-
它始终提供高并发、抗封锁的无头浏览器环境,帮助开发者轻松抓取动态内容。
-
它配备全球代理 IP 池和指纹识别技术,能够自动解决 CAPTCHA 并绕过封锁机制。
Scrapeless Scraping Browser 专为 AI 开发者设计,具备深度定制的 Chromium 核心和全球分布的代理网络。用户可以无缝运行和管理多个无头浏览器实例,以构建与网络交互的 AI 应用和代理。它消除了本地基础设施和性能瓶颈的限制,使您能够全力专注于构建解决方案。
Browser-Use 和 Scraping Browser 如何协同工作?
当结合使用时,开发者可以利用 Browser-Use 协调浏览器操作,同时依赖于 Scrapeless 的稳定云服务和强大的抗封锁能力,可靠地获取网页数据。
Browser-Use 提供简单的 API,使 AI 代理能够“理解”并与网页内容进行交互。例如,它可以使用 OpenAI 或 Anthropic 等大型语言模型来解释任务指令,并通过 Playwright 在浏览器中完成搜索或链接点击等操作。
Scrapeless的抓取浏览器通过解决其弱点来补充此设置。当处理具有严格反爬措施的大型网站时,其高并发代理支持、验证码解码和浏览器仿真机制确保了稳定的抓取。
总而言之,Browser-Use 处理智能和任务编排,而 Scrapeless 提供了一个强大的抓取基础,使得自动化浏览器任务更加高效和可靠。
如何将抓取浏览器与Browser-Use集成?
第1步:获取Scrapeless API密钥
- 注册并登录到 Scrapeless 控制台。
- 导航到"设置"。
- 点击"API密钥管理"。
然后复制并在您的 .env 文件中设置 SCRAPELESS_API_KEY 环境变量。
要在Browser-Use中启用AI功能,您需要来自外部AI提供商的有效API密钥。在本示例中,我们将使用OpenAI。如果您尚未生成API密钥,请按照OpenAI的官方指南创建一个。
您 .env 文件中的 OPENAI_API_KEY 环境变量也是必需的。
免责声明:以下步骤专注于如何集成OpenAI,但您可以根据需要进行调整,只需确保使用Browser-Use支持的任何其他AI工具。
.evn
OPENAI_API_KEY=your-openai-api-key
SCRAPELESS_API_KEY=your-scrapeless-api-key💡记得用您的实际API密钥替换示例API密钥。
接下来,在您的程序中导入 ChatOpenAI:langchain_openaiagent.py
Plain Text
from langchain_openai import ChatOpenAI请注意,Browser-Use依赖于 LangChain 处理AI集成。因此,即使您没有明确在项目中安装 langchain_openai,它也已可用。
gpt-4o 设置与以下模型的OpenAI集成:
Plain Text
llm = ChatOpenAI(model="gpt-4o")不需要额外的配置。这是因为 langchain_openai 会自动从环境变量 OPENAI_API_KEY 中读取API密钥。
有关与其他AI模型或提供者的集成,请参见官方 Browser-Use 文档。
第2步:安装Browser Use
使用pip(Python至少v.3.11):
Shell
pip install browser-use对于内存功能(由于PyTorch兼容性,需使用Python < 3.13):
Shell
pip install "browser-use[memory]"第3步:设置浏览器和代理配置
以下是如何配置浏览器并创建自动化代理:
Python
from dotenv import load_dotenv
import os
import asyncio
from urllib.parse import urlencode
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from pydantic import SecretStr
task = "去Google,搜索'Scrapeless',点击第一个帖子并返回标题"
SCRAPELESS_API_KEY = os.environ.get("SCRAPELESS_API_KEY")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
async def setup_browser() -> Browser:
scrapeless_base_url = "wss://browser.scrapeless.com/browser"
query_params = {
"token": SCRAPELESS_API_KEY,
"session_ttl": 1800,
"proxy_country": "ANY"
}
browser_ws_endpoint = f"{scrapeless_base_url}?{urlencode(query_params)}"
config = BrowserConfig(cdp_url=browser_ws_endpoint)
browser = Browser(config)
return browser
async def setup_agent(browser: Browser) -> Agent:
llm = ChatOpenAI(
model="gpt-4o", # 或选择您想使用的模型
api_key=SecretStr(OPENAI_API_KEY),
)
return Agent(
task=task,
llm=llm,
browser=browser,
)第4步:创建主函数
以下是将所有内容组合在一起的主函数:
Python
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
await browser.close()
asyncio.run(main())第5步:运行您的脚本
运行您的脚本:
Shell
python run main.py您应该会看到您的Scrapeless会话在 Scrapeless 控制台 中开始。
此外,Scrapeless支持 会话回放,这使得程序可视化成为可能。在运行程序之前,请确保您已启用了网页录制功能。当会话完成后,您可以直接在控制台上查看记录,以帮助您快速排除问题。
完整代码
Python
from dotenv import load_dotenv
import os
import asyncio
from urllib.parse import urlencode
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from pydantic import SecretStr
task = "去谷歌,搜索'Scrapeless',点击第一个帖子并返回标题"
SCRAPELESS_API_KEY = os.environ.get("SCRAPELESS_API_KEY")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
async def setup_browser() -> Browser:
scrapeless_base_url = "wss://browser.scrapeless.com/browser"
query_params = {
"token": SCRAPELESS_API_KEY,
"session_ttl": 1800,
"proxy_country": "ANY"
}
browser_ws_endpoint = f"{scrapeless_base_url}?{urlencode(query_params)}"
config = BrowserConfig(cdp_url=browser_ws_endpoint)
browser = Browser(config)
return browser
async def setup_agent(browser: Browser) -> Agent:
llm = ChatOpenAI(
model="gpt-4o", # 或选择您想使用的模型
api_key=SecretStr(OPENAI_API_KEY),
)
return Agent(
task=task,
llm=llm,
browser=browser,
)
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
await browser.close()
asyncio.run(main())💡Browser Use 当前仅支持 Python。
💡您可以在 实时会话 中复制 URL,以实时查看会话进度,也可以在 会话历史 中观看会话的回放。
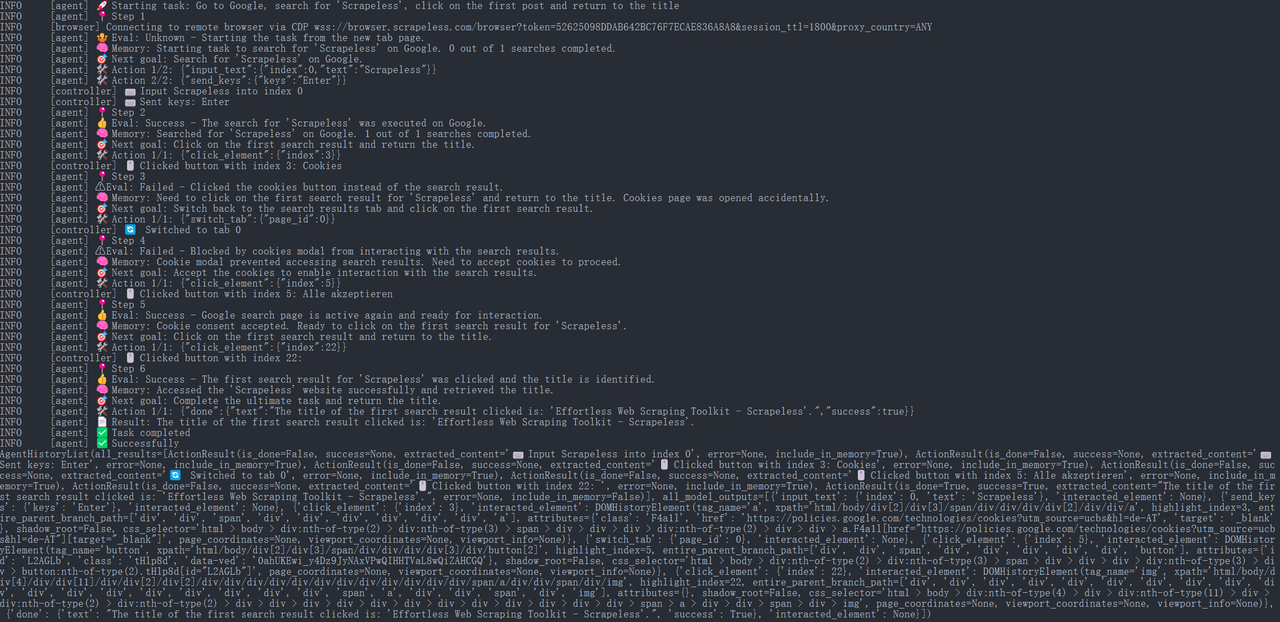
步骤 6. 运行结果
JavaScript
{
"done": {
"text": "点击的第一个搜索结果的标题是:'毫不费力的网页抓取工具包 - Scrapeless'。",
"success": True,
}
}
此时,浏览器使用代理将自动打开该 URL 并打印页面标题:“Scrapeless:毫不费力的网页抓取工具包”(这是 Scrapeless 官方主页上标题的一个示例)。
整个执行过程可以在 Scrapeless 控制台的 "仪表板" → "会话" → "会话历史" 页面中查看,您将在其中看到最近执行会话的详细信息。
步骤 7. 导出结果
为了团队共享和归档的目的,我们可以将抓取的信息保存到 JSON 或 CSV 文件中。例如,以下代码片段展示了如何将标题结果写入文件:
Python
import json
from pathlib import Path
def save_to_json(obj, filename):
path = Path(filename)
path.parent.mkdir(parents=True, exist_ok=True)
with path.open('w', encoding='utf-8') as f:
json.dump(obj, f, ensure_ascii=False, indent=4)
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
save_to_json(result.model_dump(), "scrapeless_update_report.json")
await browser.close()
asyncio.run(main())上述代码演示了如何打开一个文件并以 JSON 格式写入内容,包括搜索关键词、链接和页面标题。生成的 scrapeless_update_report.json 文件可以通过公司的知识库或协作平台内部共享,使团队成员能够方便地查看抓取结果。对于纯文本格式,您只需将扩展名更改为 .txt 并使用基本文本输出方法即可。
总结
通过将 Scrapeless 的 抓取浏览器 服务与浏览器使用 AI 代理结合,我们可以轻松构建一个信息检索和报告的自动化系统。
- Scrapeless 提供了一个稳定高效的云基础抓取解决方案,可以处理复杂的反抓取机制。
- Browser Use 允许 AI 代理智能控制浏览器执行搜索、点击和提取等任务。
这种集成使开发人员能够将繁琐的网络数据收集任务转交给自动化代理,大大提高了研究效率,同时确保准确性和实时结果。
Scrapeless 的抓取浏览器帮助 AI 在检索实时搜索数据时避免网络阻塞,并确保操作稳定性。结合 Browser Use 的灵活策略引擎,我们能够构建一个更强大的 AI 自动化研究工具,为智能商业决策提供强有力的支持。这整套工具使 AI 代理能够像与数据库互动一样“查询”网页内容,极大地降低了手动监控竞争对手的成本,提高了研发和营销团队的效率。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


