返回博客

Scrapeless X Browser-Use
Alex Johnson
Senior Web Scraping Engineer
08-May-2025
浏览器使用是一个浏览器自动化SDK,它利用截图捕捉浏览器状态和动作来模拟用户交互。本章将介绍如何轻松使用浏览器使用通过简单的调用在Web上执行代理任务。
获取Scrapeless API密钥
访问仪表板的设置选项卡:
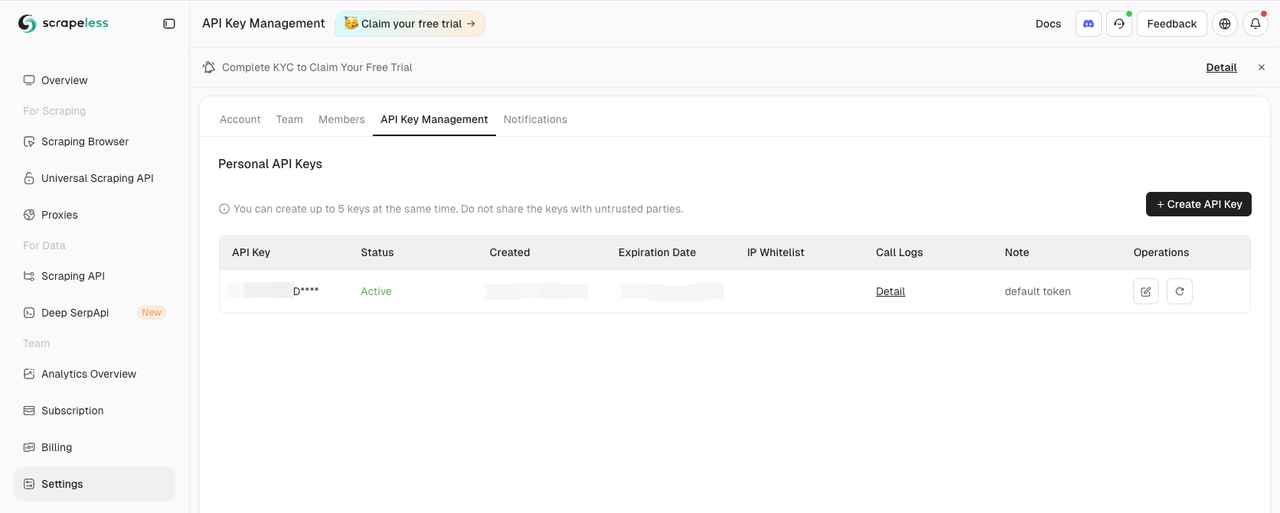
然后复制并在您的.env文件中设置SCRAPELESS_API_KEY环境变量。
您的.env文件中的OPENAI_API_KEY环境变量也是必需的。
.env
OPENAI_API_KEY=您的-openai-api-密钥
SCRAPELESS_API_KEY=您的-scrapeless-api-密钥💡 记得用您的实际API密钥替换示例API密钥
安装浏览器使用
使用pip(Python>=3.11):
Shell
pip install browser-use对于内存功能(由于PyTorch兼容性,要求Python<3.13):
Shell
pip install "browser-use[memory]"设置浏览器和代理配置
以下是配置浏览器并创建自动化代理的方法:
Python
from dotenv import load_dotenv
import os
import asyncio
from urllib.parse import urlencode
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from pydantic import SecretStr
task = "前往Google,搜索'Scrapeless',点击第一条帖子并返回标题"
async def setup_browser() -> Browser:
scrapeless_base_url = "wss://browser.scrapeless.com/browser"
query_params = {
"token": os.environ.get("SCRAPELESS_API_KEY"),
"session_ttl": 180,
"proxy_country": "ANY"
}
browser_ws_endpoint = f"{scrapeless_base_url}?{urlencode(query_params)}"
config = BrowserConfig(cdp_url=browser_ws_endpoint)
browser = Browser(config)
return browser
async def setup_agent(browser: Browser) -> Agent:
llm = ChatOpenAI(
model="gpt-4o", # 或选择您想使用的模型
api_key=SecretStr(os.environ.get("OPENAI_API_KEY")),
)
return Agent(
task=task,
llm=llm,
browser=browser,
)创建主函数
以下是将一切整合在一起的主函数:
Python
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
await browser.close()
asyncio.run(main())运行您的脚本
运行您的脚本:
Shell
python run main.py您应该在Scrapeless仪表板中看到您的Scrapeless会话开始。
完整代码
Python
from dotenv import load_dotenv
import os
import asyncio
from urllib.parse import urlencode
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from pydantic import SecretStr
task = "前往Google,搜索'Scrapeless',点击第一条帖子并返回标题"
async def setup_browser() -> Browser:
scrapeless_base_url = "wss://browser.scrapeless.com/browser"
query_params = {
"token": os.environ.get("SCRAPELESS_API_KEY"),
"session_ttl": 180,
"proxy_country": "ANY"
}
browser_ws_endpoint = f"{scrapeless_base_url}?{urlencode(query_params)}"
config = BrowserConfig(cdp_url=browser_ws_endpoint)
browser = Browser(config)
return browser
async def setup_agent(browser: Browser) -> Agent:
llm = ChatOpenAI(
model="gpt-4o", # 或选择您想使用的模型
api_key=SecretStr(os.environ.get("OPENAI_API_KEY")),
)
return Agent(
task=task,
llm=llm,
browser=browser,
)
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
await browser.close()
asyncio.run(main())💡 当前浏览器使用仅支持Python。
💡 您可以复制实时会话中的URL,以实时查看会话进展,您还可以在会话历史中观看会话回放。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。
最受欢迎的文章



目录