
抓取浏览器命令行界面:面向 AI Agent 和开发者的终端优先网页抓取
Senior Web Scraping Engineer
主要要点:
- Scraping Browser CLI 通过直接从终端提供云原生浏览器自动化,彻底改变了网络数据提取。
- 它提供强大的反检测功能、全球住宅代理和持久会话,克服了常见的网络爬虫挑战。
- 与 AI 代理无缝集成,使它们能够以类人精度执行复杂的网络互动和数据收集。
- 发现动态内容处理、表单自动化和构建复杂数据管道的先进技术。
介绍:网络数据提取的演变
在当今数据驱动的世界中,访问和互动网络数据对开发人员、数据科学家以及快速发展的 AI 代理领域至关重要。然而,网络爬虫的环境日益复杂。网站采用复杂的反机器人措施,动态内容加载需要先进的渲染,而管理本地浏览器自动化设置可能资源密集且容易出错。这些挑战通常将本应简单的数据获取任务转变为重大工程难题。
Scraping Browser CLI,由 Scrapeless 提供支持,是解决这些现代网络爬虫困境的强大解决方案。它是一种尖端的基于云的浏览器自动化工具,让您可以通过直观的终端命令轻松抓取、搜索和与网页互动。通过将浏览器执行 offload 到强大的云基础设施,它为人类开发者和 AI 代理提供了无缝的高性能体验,确保可靠和高效的数据提取,而无需承受本地维护或基础设施开销的负担。
什么是 Scraping Browser CLI?
Scraping Browser CLI 是一个先进的命令行接口工具,专门用于云浏览器自动化和深度 AI 代理集成。与需要当地安装 Chrome 或 Chromium 的传统本地浏览器自动化框架(如 Puppeteer 或 Playwright)不同,这个 CLI 完全在 Scrapeless 云基础设施中运行。这一根本差异在可扩展性、可靠性和资源管理方面提供了无与伦比的优势。
这种云原生的方法意味着您可以执行强大的网络互动、进行大规模数据爬取和进行自动化测试,而无需消耗本地系统的计算资源。此外,基于 Scraping Browser CLI 构建的专业技能可以为您的 AI 代理提供完整的云浏览器能力。这使得它们能够像人类用户一样浏览网站、填写表单、点击按钮和提取数据,轻松完成各种网络自动化任务。
核心优势:为什么云原生重要
Scraping Browser CLI 为您的网络爬虫工作流程带来了几个独特的、颠覆性的好处:
- 云执行:所有浏览器操作都在云中运行,完全消除对本地浏览器设置、驱动管理及相关资源消耗的需求。
- 智能反检测:它具有内置的复杂浏览器指纹识别和反机器人机制。这使您能够顺利浏览网站限制和验证码,模拟人类行为。
- 全球代理:集成支持全球住宅代理,使您能够模拟来自不同地理位置的访问,这对于本地化数据提取和绕过地域限制至关重要。
- 会话持久性:先进的会话管理确保跨多个交互保持状态,对于登录和复杂表单提交等多步骤过程至关重要。
- AI 友好设计:CLI 使用直观的元素引用系统(如 @e1, @e2)以便于 AI 代理进行简单、稳健的交互,抽象掉复杂的 DOM 选择器。
欲获取更详细的信息,您可以查看官方文档或访问 GitHub 仓库。
功能和能力:深入分析
Scraping Browser CLI 配备了旨在处理最具挑战性的现代网络爬虫挑战的功能。以下是其核心功能的全面分类:
| 功能类别 | 描述 |
|---|---|
| 云浏览器自动化 | 在云中执行所有操作,无需本地浏览器安装,确保高性能和可扩展性。 |
| 住宅代理支持 | 内置全球住宅代理,具有精确的地理定位目标,便于本地数据访问。 |
| 智能指纹识别 | 自动的浏览器指纹识别和反检测机制,以绕过复杂的反机器人系统。 |
| 会话管理 | 全面支持跨复杂工作流程创建、管理和持久化会话。 |
| AI友好交互 | 专门为无缝AI代理兼容性设计的元素引用系统(@e1,@e2)。 |
| 截图与提取 | 捕获完整页面截图和提取特定结构化内容的强大能力。 |
| 会话录制 | 支持录制会话以便调试、审计和回放。 |
这些功能使其成为一个高度多功能的工具, comparable to other industry-leading solutions, but with a pronounced emphasis on AI agent integration and seamless cloud-native execution.
主要命令概览:您的自动化工具包
CLI提供了直接且直观的语法,用于管理会话和与网页交互。以下是您将用于协调自动化的一些主要命令:
bash
# 会话管理
scrapeless-scraping-browser new-session # 创建新会话
scrapeless-scraping-browser sessions # 列出所有活动会话
scrapeless-scraping-browser stop <id> # 停止特定会话
# 页面导航
scrapeless-scraping-browser open <url> # 打开网页
scrapeless-scraping-browser close # 关闭当前会话
# 页面交互
scrapeless-scraping-browser snapshot -i # 获取交互元素
scrapeless-scraping-browser click @e1 # 点击特定元素
scrapeless-scraping-browser fill @e2 "text" # 填写表单字段
# 数据提取
scrapeless-scraping-browser get text @e1 # 从元素中提取文本
scrapeless-scraping-browser screenshot # 捕获页面截图开始使用:逐步指南
设置Scraping Browser CLI是一个快速而简单的过程,旨在让您在几分钟内开始抓取。
安装
推荐的方法是使用npm全局安装CLI,确保它可以在您的系统中使用:
bash
npm install -g scrapeless-scraping-browser或者,您可以使用npx直接运行而无需安装,以便快速、一时的任务:
bash
npx scrapeless-scraping-browser open https://example.com获取您的API密钥
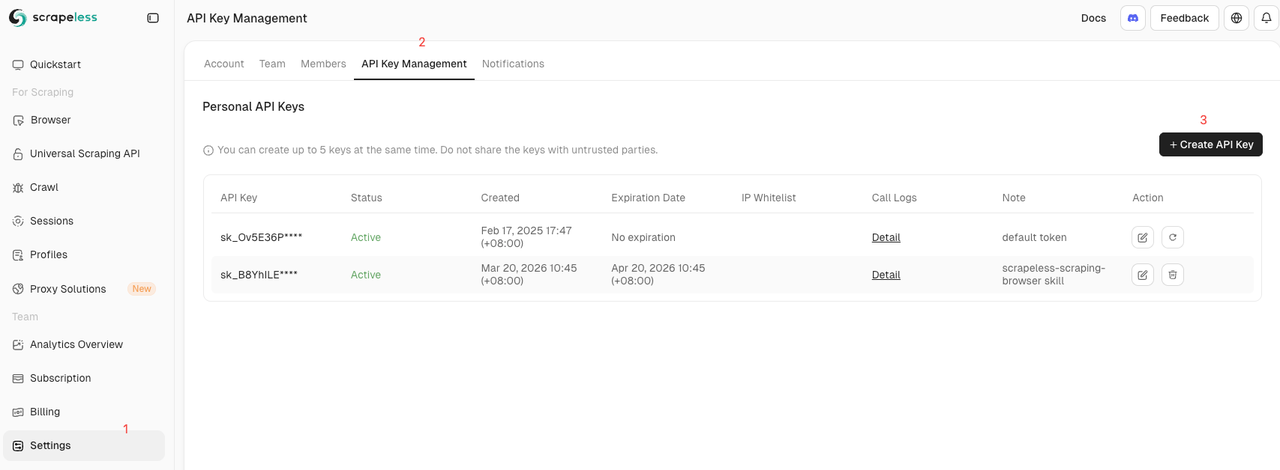
要验证您的请求并访问云基础设施,您需要一个Scrapeless API密钥:
- 访问 Scrapeless Dashboard。
- 登录或注册一个新帐户。
- 导航至API设置页面生成并安全复制您的API密钥。
配置身份验证
您可以使用配置文件或环境变量来配置您的身份验证凭据,为不同的部署环境提供灵活性。
方法1:配置文件(推荐用于持久性)
bash
scrapeless-scraping-browser config set apiKey your_api_key_here方法2:环境变量(适合CI/CD流水线)
bash
export SCRAPELESS_API_KEY=your_api_key_here您可以通过运行以下命令验证您的配置:
bash
scrapeless-scraping-browser config get apiKey
scrapeless-scraping-browser sessions基本工作流示例:协调一个会话
以下是一个简单的基础工作流,演示如何创建一个会话、与页面交互并干净地关闭会话:
bash
# 第一步:创建会话并保存会话ID
SESSION_ID=$(scrapeless-scraping-browser new-session --name "my-workflow" --ttl 3600 --json | jq -r '.taskId')
# 第二步:使用会话ID执行浏览器操作
scrapeless-scraping-browser --session-id $SESSION_ID open https://example.com
scrapeless-scraping-browser --session-id $SESSION_ID snapshot -i
scrapeless-scraping-browser --session-id $SESSION_ID click @e1
# 第三步:完成后关闭会话以释放资源
scrapeless-scraping-browser --session-id $SESSION_ID close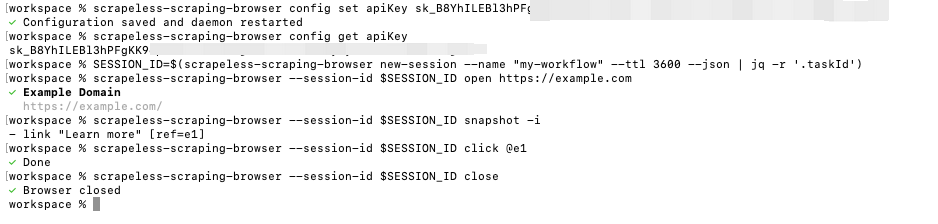
实际用例:从简单提取到复杂自动化
Scraping Browser CLI在各种实用场景中表现出色,从简单的数据提取扩展到协调复杂的多步骤自动化工作流。
抓取任何网站:绕过基础知识
您可以轻松地从任何目标网站提取特定内容,即使是那些具有动态内容的网站:
bash
# 创建会话
SESSION_ID=$(scrapeless-scraping-browser new-session --name "scraping" --ttl 3600 --json | jq -r '.taskId')
# 访问目标网站
scrapeless-scraping-browser --session-id $SESSION_ID open https://www.scrapeless.com
# 获取页面标题
scrapeless-scraping-browser --session-id $SESSION_ID get title
# 获取特定元素的内容
scrapeless-scraping-browser --session-id $SESSION_ID get text "h1"
# 关闭会话
scrapeless-scraping-browser --session-id $SESSION_ID close基于地理位置的请求:本地化数据访问
如果您需要访问特定国家(例如,美国)中出现的数据进行市场研究或本地定价,您可以相应地配置会话:
bash
# 创建地理位置目标的会话
SESSION_ID=$(scrapeless-scraping-browser new-session \
--name "geo-us" \
--proxy-country US \
--ttl 3600 \
--json | jq -r '.taskId')
scrapeless-scraping-browser --session-id $SESSION_ID open https://api.iplook.io
scrapeless-scraping-browser --session-id $SESSION_ID get text "pre"
scrapeless-scraping-browser --session-id $SESSION_ID close自动填表:简化互动
使用CLI的强大交互命令,自动登录、注册过程或复杂搜索表单非常简单:
bash
# 创建会话
SESSION_ID=$(scrapeless-scraping-browser new-session --name "form-fill" --ttl 3600 --json | jq -r '.taskId')
# 打开登录页面
scrapeless-scraping-browser --session-id $SESSION_ID open https://app.scrapeless.com/passport/login
# 获取交互元素
scrapeless-scraping-browser --session-id $SESSION_ID snapshot -i
# 填写表单字段并提交
scrapeless-scraping-browser --session-id $SESSION_ID fill @e2 "this_is_email"
scrapeless-scraping-browser --session-id $SESSION_ID fill @e3 "this_is_pwd"
scrapeless-scraping-browser --session-id $SESSION_ID click @e5控制浏览器会话和录制:简化调试
对于调试复杂脚本或监控自动化任务,您可以启用会话录制并实时与页面互动:
bash
# 创建会话并启用录制
SESSION_ID=$(scrapeless-scraping-browser new-session \
--name "browser-control" \
--recording true \
--ttl 7200 \
--json | jq -r '.taskId')
# 打开页面
scrapeless-scraping-browser --session-id $SESSION_ID open https://www.scrapeless.com
# 获取实时预览链接
scrapeless-scraping-browser --session-id $SESSION_ID live
# 执行页面操作
scrapeless-scraping-browser --session-id $SESSION_ID scroll down 500
scrapeless-scraping-browser --session-id $SESSION_ID screenshot page.png使用Unix管道链接命令:构建数据管道
CLI与标准Unix工具完美集成,使您能够直接在终端中构建复杂、简化的数据管道:
bash
# 链接操作以实现高效执行
scrapeless-scraping-browser open https://example.com \
&& scrapeless-scraping-browser wait --load networkidle \
&& scrapeless-scraping-browser snapshot -i
# 保存截图
scrapeless-scraping-browser screenshot screenshot.png自定义浏览器指纹:高级规避
您可以定义自定义用户代理和其他指纹参数,以满足特定的抓取需求并规避检测:
bash
SESSION_ID=$(scrapeless-scraping-browser new-session \
--name "customer-ua" \
--user-agent "custom_user_agent_string" \
--json | jq -r '.taskId')
scrapeless-scraping-browser --session-id $SESSION_ID open https://example.com赋能AI代理:网络互动的未来
Scraping Browser CLI的一大亮点是其能够无缝集成到AI代理客户端,使其具备真实、强大的网络互动能力。这是相对于传统工具的一个显著优势,与行业向代理工作流的转变相一致。
集成示例:自然语言到网络动作
您可以使用自然语言提示指示您的AI代理,CLI会将其翻译成可靠的网络操作:
bash
USER_PROMPT="使用scrapeless-scraping-browser技能搜索亚马逊上前20款无线耳机的价格信息,并告诉我哪个品牌的平均价格最低。"支持的AI代理
CLI设计为与各种支持技能扩展的AI代理广泛兼容,包括:
- Claude Code
- Cursor
- CodeLlama
- OpenClaw
- 以及许多其他利用MCP(模型上下文协议)等协议的可扩展AI框架。
要了解更多关于如何将AI代理与Scrapeless集成并解锁这些功能,请查看我们关于2026年最佳抓取浏览器:Scrapeless发布抓取浏览器OpenClaw技能的全面指南。
高级配置选项:定制您的环境
对于复杂的企业级数据抓取任务,CLI 提供了广泛的配置参数来微调您的环境。
会话选项
您可以通过各种标志细致配置您的会话环境,以模拟特定的用户档案:
bash
scrapeless-scraping-browser new-session \
--name "advanced-session" \
--ttl 7200 \
--recording true \
--proxy-country US \
--proxy-state CA \
--platform macOS \
--screen-width 1440 \
--screen-height 900 \
--timezone "America/Los_Angeles" \
--languages "en,es"配置管理
轻松管理您的默认设置,以简化工作流程:
bash
# 设置配置
scrapeless-scraping-browser config set proxyCountry US
scrapeless-scraping-browser config set sessionTtl 3600
# 查看所有配置
scrapeless-scraping-browser config list
# 获取特定配置
scrapeless-scraping-browser config get apiKey为什么选择 Scrapeless?竞争优势
在比较网络抓取 CLI 工具时,Scrapeless 凭借提供全面的云原生解决方案而脱颖而出,优先考虑 AI 集成、强大的反检测能力和开发者体验。无论您是在构建专用的 Google Maps 抓取工具、使用 Gemini 抓取工具 监控品牌知名度,还是部署 MCP 服务器,抓取浏览器 CLI 提供了实现 2026 年及以后成功所需的可扩展、可靠的基础设施。
结论:提升您的网络自动化
抓取浏览器 CLI 是一个强大的、颠覆性的云浏览器自动化工具,为开发者和 AI 代理提供了简单而强大的网络交互能力。从简单的数据提取和自动化测试到复杂的网络监控和代理工作流,它以空前的轻松和可靠性处理苛刻的任务。
准备好构建您的 AI 驱动数据管道了吗?
加入我们的活跃社区,领取免费计划,并与其他创新者联系:
Discord
Telegram
常见问题
问:我需要安装本地浏览器吗?
答:不需要。抓取浏览器 CLI 完全在云中运行,在安全、高性能的 Scrapeless 基础设施上执行所有浏览器操作。
问:它如何处理网站的反抓取机制?
答:CLI 具备内置的高级浏览器指纹识别和反检测机制。结合我们广泛的住宅代理网络,它有效地绕过大部分反抓取限制和 CAPTCHA。
问:会话持续多长时间?
答:默认的会话超时时间为 180 秒(3 分钟)。您可以轻松使用 --ttl 参数自定义此持续时间以适应更长的工作流程。
问:我如何保存屏幕截图?
答:使用屏幕截图命令保存图像。支持全页面截图和特定区域捕获,非常适合视觉验证。
问:支持哪些浏览器操作?
答:它支持网页导航、元素点击、表单填写、滚动、等待和截屏等多种常用操作,涵盖几乎所有交互需求。
问:是否有可编程的 API 可用?
答:是的,除了 CLI 命令外,Scrapeless 还提供了强大的 TypeScript/Node.js API 客户端,以便无缝集成到您的应用程序代码库中。
有关网络抓取、AI 自动化和高级技术的更多见解,请访问 Scrapeless 博客。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


