
基于AI的博客撰写工具,使用Scrapeless和Pinecone数据库
Senior Web Scraping Engineer
您必须是经验丰富的内容创作者。作为一家初创团队,产品的每日更新内容极为丰富。您不仅需要布局大量引流博客来快速增加网站流量,还需要每周准备2-3篇与产品更新推广相关的博客。
与花费大量资金增加付费广告的竞标预算以换取更高的展示位置和更多曝光相比,内容营销仍然具有不可替代的优势:内容范围广,客户获取测试成本低,输出效率高,能源投入相对较低,丰富的领域经验知识基础等。
然而,大量内容营销的结果是什么呢?
不幸的是,许多文章深埋在谷歌搜索的第十页上。
有没有什么好的方法尽量避免“低流量”文章的强烈影响?
您是否曾想创造一个自我更新的SEO写作工具,以克隆表现最佳博客的知识,并大规模生成新内容?
在本指南中,我们将引导您通过使用n8n、Scrapeless、Gemini(您可以根据需要选择其他工具,如Claude/OpenRouter)和Pinecone来构建一个完全自动化的SEO内容生成工作流程。
该工作流程使用一种检索增强生成(RAG)系统来基于现有的高流量博客收集、存储和生成内容。
YouTube教程: https://www.youtube.com/watch?v=MmitAOjyrT4
这个工作流程的作用是什么?
该工作流程将涉及四个步骤:
- 第1部分:调用Scrapeless的爬取来抓取目标网站的所有子页面,并使用抓取深入分析每个页面的整个内容。
- 第2部分:将抓取的数据存储到Pinecone向量存储中。
- 第3部分:使用Scrapeless的谷歌搜索节点全面分析目标主题或关键词的价值。
- 第4部分:传达指令给Gemini,通过RAG集成准备好的数据库中的上下文内容,并生成目标博客或回答问题。
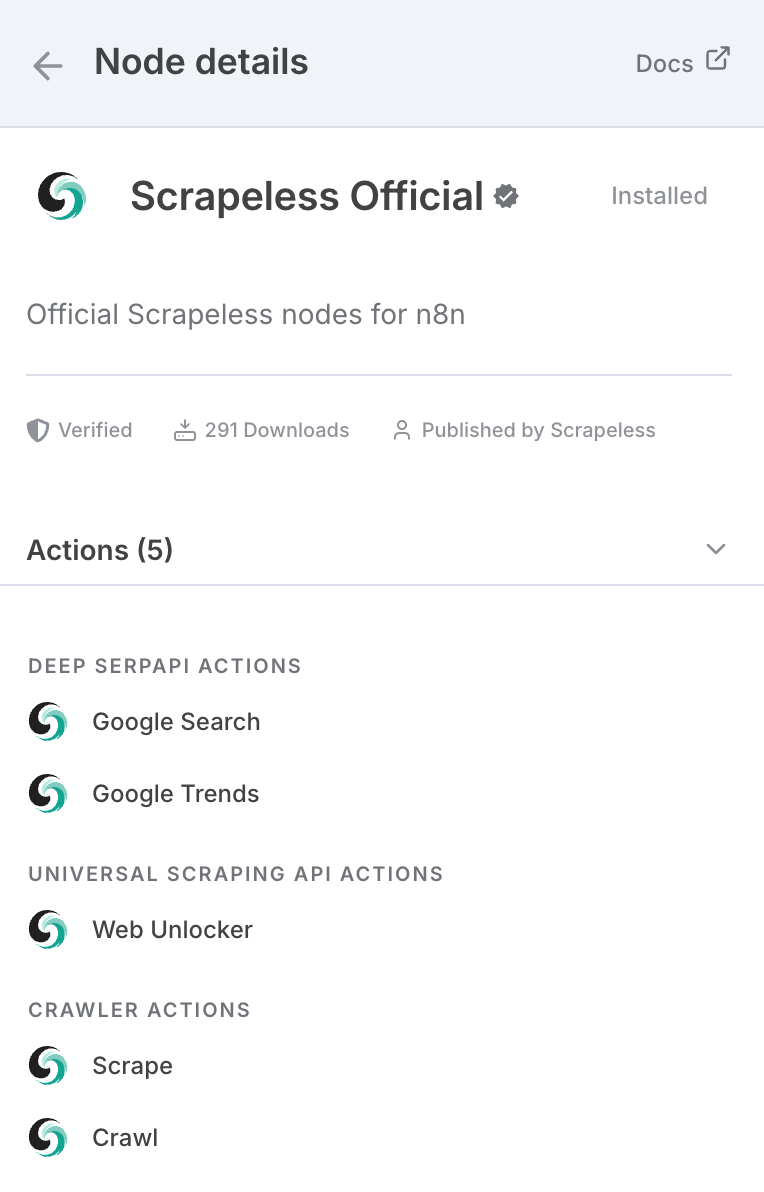
如果您没听说过Scrapeless,它是一家专注于驱动AI代理、自动化工作流程和网络爬虫的领先基础设施公司。Scrapeless提供了基本构件,使开发者和企业能够高效创建智能的、自动化的系统。
从本质上讲,Scrapeless提供浏览器级工具和基于协议的API——例如无头云浏览器、深度SERP API和通用爬虫API——作为AI代理和自动化平台的统一模块化基础。
它确实是为AI应用程序打造的,因为AI模型并不总是掌握许多事情的最新信息,无论是当前事件还是新技术。
除了n8n,还可以通过API调用,并且在像Make这样的主流平台上有节点:
您还可以直接在官方网站上使用它。
要在n8n中使用Scrapeless:
- 转到设置 > 社区节点
- 搜索n8n-nodes-scrapeless并安装它
我们需要首先在n8n上安装Scrapeless社区节点:
认证连接
Scrapeless API密钥
在本教程中,我们将使用Scrapeless服务。请确保您已注册并获得API密钥。
- 在Scrapeless网站上注册以获取API密钥并申请免费试用。
- 然后,您可以打开Scrapeless节点,粘贴您的API密钥到凭证部分,并连接它。
Pinecone索引和API密钥
抓取数据后,我们将整合和处理它,并将所有数据收集到Pinecone数据库中。我们需要提前准备好Pinecone的API密钥和索引。
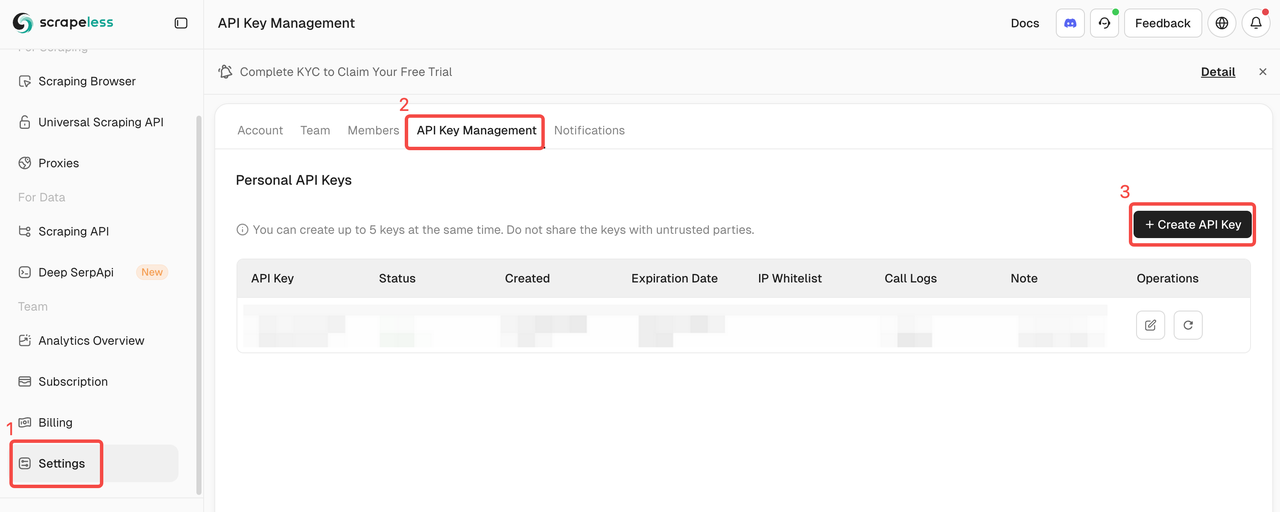
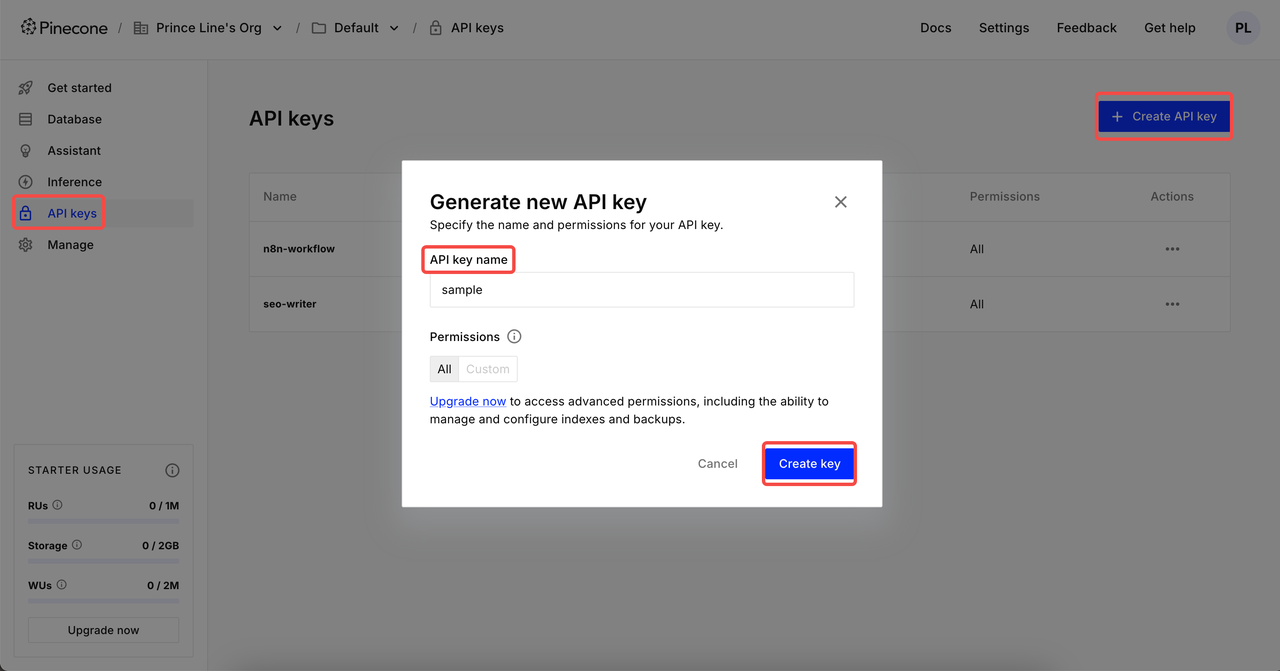
创建API密钥
登录后,点击API密钥 → 点击创建API密钥 → 填写您的API密钥名称 → 创建密钥。现在,您可以在n8n凭证中设置它。
⚠️ 创建完成后,请复制并保存您的API密钥。出于数据安全原因,Pinecone将不再显示已创建的API密钥。
创建索引
点击索引,进入创建页面。设置 索引名称 → 选择 配置的模型 → 设置适当的 维度 → 创建索引。
2 种常见的维度设置:
- Google Gemini Embedding-001 → 768 维度
- OpenAI的text-embedding-3-small → 1536 维度
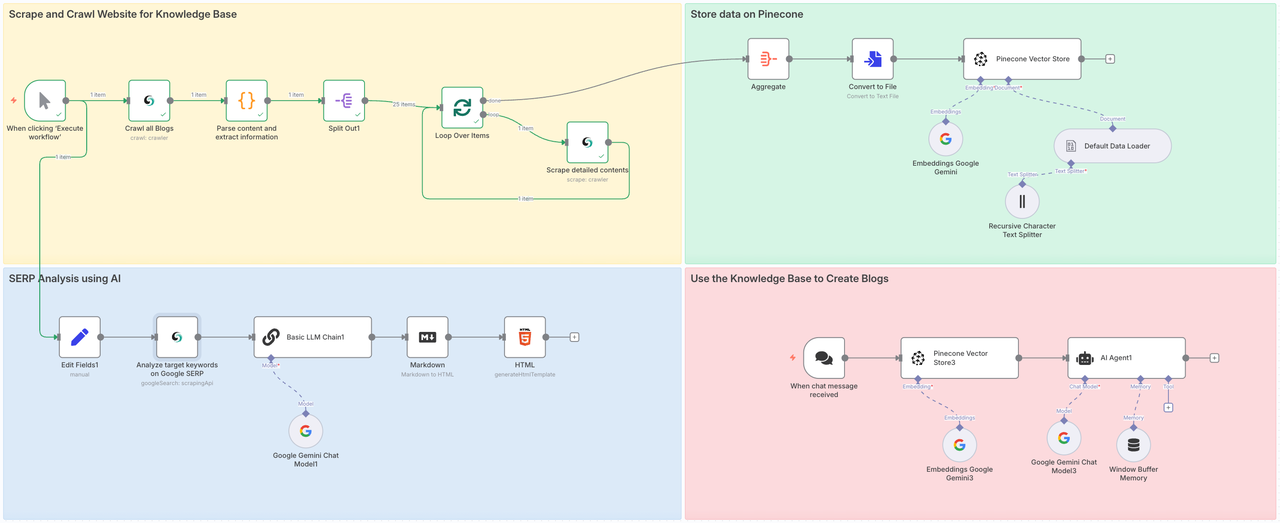
阶段1:抓取和爬取网站以建立知识库
第一阶段是直接聚合所有博客内容。从大范围抓取内容可以让我们的AI代理从各个领域获取数据源,从而确保最终输出文章的质量。
- Scrapeless节点爬取文章页面并收集所有博客帖子URL。
- 然后遍历每一个URL,抓取博客内容,并整理数据。
- 每个博客帖子使用您的AI模型进行嵌入,并存储在Pinecone中。
- 在我们的案例中,我们在短短几分钟内抓取了25篇博客帖子——毫不费力。
Scrapeless 爬取节点
该节点用于爬取目标博客网站的所有内容,包括元数据、子页面内容,并以Markdown格式导出。这是一项大规模内容抓取,通过手动编码无法快速实现。
配置:
- 连接您的 Scrapeless API 密钥
- 资源:
爬虫 - 操作:
爬取 - 输入您目标抓取网站。这里我们使用 https://www.scrapeless.com/zh/blog 作为参考。
代码节点
在获取博客数据后,我们需要解析数据并从中提取所需的结构化信息。
以下是我使用的代码。您可以直接参考:
JavaScript
return items.map(item => {
const md = $input.first().json['0'].markdown;
if (typeof md !== 'string') {
console.warn('Markdown内容不是字符串:', md);
return {
json: {
title: '',
mainContent: '',
extractedLinks: [],
error: 'Markdown内容不是字符串'
}
};
}
const articleTitleMatch = md.match(/^#\s*(.*)/m);
const title = articleTitleMatch ? articleTitleMatch[1].trim() : '未找到标题';
let mainContent = md.replace(/^#\s*.*(\r?\n)+/, '').trim();
const extractedLinks = [];
const linkRegex = /\[([^\]]+)\]\((https?:\/\/[^\s#)]+)\)/g;
let match;
while ((match = linkRegex.exec(mainContent))) {
extractedLinks.push({
text: match[1].trim(),
url: match[2].trim(),
});
}
return {
json: {
title,
mainContent,
extractedLinks,
},
};
});节点: 分割
分割节点可以帮助我们整合清理过的数据并提取所需的URL和文本内容。
循环处理项目 + Scrapeless 抓取
循环处理项目
使用循环处理时间节点与Scrapeless的抓取重复执行爬取任务,深入分析之前获取的所有项目。
Scrapeless 抓取
抓取节点用于抓取之前获取的URL中的所有内容。通过这种方式,可以深入分析每个URL。返回Markdown格式,并整合元数据和其他信息。
阶段2. 在Pinecone中存储数据
我们成功提取了Scrapeless博客页面的全部内容。现在我们需要访问Pinecone向量存储,以存储这些信息,以便我们可以在以后使用。
节点: 聚合
为了方便地将数据存储在知识库中,我们需要使用聚合节点来整合所有内容。
- 聚合:
所有项目数据(合并成单一列表) - 输出放入字段:
data - 包含:
所有字段
节点: 转换为文件
太好了!所有数据已经成功集成。现在我们需要将获取的数据转换为可以直接被 Pinecone 读取的文本格式。为此,只需添加一个转换为文件的操作。
节点:Pinecone 向量存储
现在我们需要配置知识库。使用的节点有:
Pinecone 向量存储Google Gemini默认数据加载器递归字符文本拆分器
上述四个节点将递归地整合和抓取我们所获得的数据。然后所有数据都会集成到 Pinecone 知识库中。
第三阶段:利用 AI 进行 SERP 分析
为确保您撰写的内容能够排名,我们进行实时 SERP 分析:
- 使用 Scrapeless Deep SerpApi 获取您选择的关键词的搜索结果
- 输入 关键词 和 搜索意图(例如,抓取、Google 趋势、API)
- 结果由 LLM 进行分析并总结成 HTML 报告
节点:编辑字段
知识库已准备好!现在是时候确定我们的目标关键词了。在内容框中填写目标关键词并添加意图。
节点:Google 搜索
Google 搜索节点调用 Scrapeless 的 Deep SerpApi 来检索目标关键词。
节点:LLM 链
构建 LLM 链与 Gemini 结合,可以帮助我们分析先前步骤获得的数据,并向 LLM 解释我们需要使用的参考输入和意图,这样 LLM 就可以生成更符合需求的反馈。
节点:Markdown
由于 LLM 通常以 Markdown 格式导出,作为用户我们无法直接以最清晰的方式获取所需的数据,因此请添加一个 Markdown 节点,将 LLM 返回的结果转换为 HTML。
节点:HTML
现在我们需要使用 HTML 节点来标准化结果 - 使用博客/报告格式直观地展示相关内容。
- 操作:
生成 HTML 模板
所需的以下代码:
XML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>报告摘要</title>
<link href="https://fonts.googleapis.com/css2?family=Inter:wght@400;600;700&display=swap" rel="stylesheet">
<style>
body {
margin: 0;
padding: 0;
font-family: 'Inter', sans-serif;
background: #f4f6f8;
display: flex;
align-items: center;
justify-content: center;
min-height: 100vh;
}
.container {
background-color: #ffffff;
max-width: 600px;
width: 90%;
padding: 32px;
border-radius: 16px;
box-shadow: 0 10px 30px rgba(0, 0, 0, 0.1);
text-align: center;
}
h1 {
color: #ff6d5a;
font-size: 28px;
font-weight: 700;
margin-bottom: 12px;
}
h2 {
color: #606770;
font-size: 20px;
font-weight: 600;
margin-bottom: 24px;
}
.content {
color: #333;
font-size: 16px;
line-height: 1.6;
white-space: pre-wrap;
}
@media (max-width: 480px) {
.container {
padding: 20px;
}
h1 {
font-size: 24px;
}
h2 {
font-size: 18px;
}
}
</style>
</head>
<body>
<div class="container">
<h1>数据报告</h1>
<h2>通过自动化处理</h2>
<div class="content">{{ $json.data }}</div>
</div>
<script>
console.log("你好,世界!");
</script>
</body>
</html>该报告包括:
- 排行前列的关键词和长尾词组
- 用户搜索意图趋势
- 建议的博客标题和角度
- 关键词聚类
第四阶段:利用 AI + RAG 生成博客
现在您已经收集并存储了知识,并研究了您的关键词,是时候生成您的博客了。
- 使用 SERP 报告中的洞见构建提示
- 调用 AI 代理(例如,Claude、Gemini 或 OpenRouter)
- 模型从 Pinecone 检索相关上下文,并撰写完整的博客文章
与通用AI输出不同,这里的结果包含了Scrapeless原始内容中的具体想法、短语和语气——这一切都得益于RAG。
最终思考
这个端到端的SEO内容引擎展示了n8n + Scrapeless + 向量数据库 + LLMs 的强大功能。
你可以:
- 用任何其他博客替换Scrapeless博客页面
- 用其他向量存储替换Pinecone
- 使用OpenAI、Claude或Gemini作为你的写作引擎
- 构建自定义发布管道(例如,自动发布到CMS或Notion)
👉 今天就开始,通过安装Scrapeless社区节点并开始大规模生成博客——无需编码。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


