
Cách thiết lập Undetected ChromeDriver trong Scrapeless?
Advanced Data Extraction Specialist
Khám phá cách Undetected ChromeDriver giúp vượt qua các hệ thống chống bot để thu thập dữ liệu web, cùng với hướng dẫn từng bước, các phương pháp nâng cao và những hạn chế chính. Hơn nữa, tìm hiểu về Scrapeless - một giải pháp thay thế mạnh mẽ hơn cho nhu cầu thu thập dữ liệu chuyên nghiệp.
Trong hướng dẫn này, bạn sẽ học được:
- Undetected ChromeDriver là gì và nó có thể hữu ích như thế nào
- Cách nó giảm thiểu việc phát hiện bot
- Cách sử dụng nó với Python để thu thập dữ liệu web
- Cách sử dụng và phương pháp nâng cao
- Những hạn chế và nhược điểm chính của nó
- Giải pháp thay thế được khuyến nghị: Scrapeless
- Phân tích kỹ thuật về các cơ chế phát hiện chống bot
Hãy cùng khám phá!
Undetected ChromeDriver là gì?
Undetected ChromeDriver là một thư viện Python cung cấp phiên bản tối ưu hóa của ChromeDriver của Selenium. Thư viện này đã được vá để hạn chế khả năng phát hiện bởi các dịch vụ chống bot như:
- Imperva
- DataDome
- Distil Networks
- và nhiều hơn nữa...
Nó cũng có thể giúp vượt qua một số biện pháp bảo vệ của Cloudflare, mặc dù việc này có thể khó khăn hơn.
Nếu bạn đã từng sử dụng các công cụ tự động hóa trình duyệt như Selenium, bạn biết rằng chúng cho phép bạn điều khiển các trình duyệt theo cách lập trình. Để làm được điều này, chúng cấu hình các trình duyệt khác với các thiết lập của người dùng thông thường.
Các hệ thống chống bot tìm kiếm những khác biệt, hay còn gọi là "rò rỉ", để xác định các bot trình duyệt tự động. Undetected ChromeDriver vá các trình điều khiển Chrome để giảm thiểu những dấu hiệu này, giảm thiểu việc phát hiện bot. Điều này khiến nó trở nên lý tưởng để thu thập dữ liệu từ các trang web được bảo vệ bởi các biện pháp chống thu thập dữ liệu!
Undetected ChromeDriver hoạt động như thế nào?
Undetected ChromeDriver giảm thiểu việc phát hiện từ Cloudflare, Imperva, DataDome và các giải pháp tương tự bằng cách sử dụng các kỹ thuật sau:
- Đổi tên các biến Selenium để giống với các biến được sử dụng bởi các trình duyệt thật
- Sử dụng chuỗi User-Agent hợp pháp, thực tế để tránh bị phát hiện
- Cho phép người dùng mô phỏng tương tác tự nhiên của con người
- Quản lý cookie và phiên đúng cách trong khi điều hướng các trang web
- Cho phép sử dụng proxy để vượt qua việc chặn IP và ngăn chặn việc giới hạn tốc độ
Những phương pháp này giúp trình duyệt được điều khiển bởi thư viện vượt qua các biện pháp phòng chống thu thập dữ liệu một cách hiệu quả.
Sử dụng Undetected ChromeDriver để Thu thập Dữ liệu Web: Hướng dẫn Từng bước
Bước #1: Các yêu cầu cần thiết và thiết lập dự án
Undetected ChromeDriver có các yêu cầu cần thiết sau:
- Phiên bản mới nhất của Chrome
- Python 3.6+: Nếu Python 3.6 hoặc mới hơn chưa được cài đặt trên máy tính của bạn, hãy tải xuống từ trang chính thức và làm theo hướng dẫn cài đặt.
Lưu ý: Thư viện sẽ tự động tải xuống và vá tệp nhị phân trình điều khiển cho bạn, vì vậy không cần phải tải xuống ChromeDriver một cách thủ công.
Tạo một thư mục cho dự án của bạn:
language
mkdir undetected-chromedriver-scraper
cd undetected-chromedriver-scraper
python -m venv envKích hoạt môi trường ảo:
language
# Trên Linux hoặc macOS
source env/bin/activate
# Trên Windows
env\Scripts\activateBước #2: Cài đặt Undetected ChromeDriver
Cài đặt Undetected ChromeDriver qua gói pip:
language
pip install undetected_chromedriverThư viện này sẽ tự động cài đặt Selenium, vì nó là một trong những phụ thuộc của nó.
Bước #3: Thiết lập ban đầu
Tạo một tệp scraper.py và nhập undetected_chromedriver:
language
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
# Khởi tạo một phiên bản Chrome
driver = uc.Chrome()
# Kết nối đến trang web mục tiêu
driver.get("https://scrapeless.com")
# Logic thu thập dữ liệu...
# Đóng trình duyệt
driver.quit()Bước #4: Triển khai Logic Thu thập Dữ liệu
Bây giờ hãy thêm logic để trích xuất dữ liệu từ trang Apple:
language
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
import time
# Tạo một phiên bản trình điều khiển web Chrome
driver = uc.Chrome()
# Kết nối đến trang web Apple
driver.get("https://www.apple.com/fr/")
# Để trang web có thời gian tải hoàn chỉnh
time.sleep(3)
# Tạo một từ điển để lưu trữ thông tin sản phẩm
apple_products = {}
try:
# Tìm các phần sản phẩm (sử dụng các lớp từ HTML được cung cấp)
product_sections = driver.find_elements(By.CSS_SELECTOR, ".homepage-section.collection-module .unit-wrapper")
for i, section in enumerate(product_sections):
try:
# Trích xuất tên sản phẩm (tiêu đề)
headline = section.find_element(By.CSS_SELECTOR, ".headline, .logo-image").get_attribute("textContent").strip()
# Trích xuất mô tả (phụ đề)
python
subhead_element = section.find_element(By.CSS_SELECTOR, ".subhead")
subhead = subhead_element.text
# Lấy liên kết nếu có
link = ""
try:
link_element = section.find_element(By.CSS_SELECTOR, ".unit-link")
link = link_element.get_attribute("href")
except:
pass
apple_products[f"product_{i+1}"] = {
"name": headline,
"description": subhead,
"link": link
}
except Exception as e:
print(f"Lỗi khi xử lý phần {i+1}: {e}")
# Xuất dữ liệu đã thu thập ra JSON
with open("apple_products.json", "w", encoding="utf-8") as json_file:
json.dump(apple_products, json_file, indent=4, ensure_ascii=False)
print(f"Đã thu thập thành công {len(apple_products)} sản phẩm Apple")
except Exception as e:
print(f"Lỗi trong quá trình thu thập: {e}")
finally:
# Đóng trình duyệt và giải phóng tài nguyên
driver.quit()Chạy nó với:
language
python scraper.pyUndetected ChromeDriver: Cách sử dụng nâng cao
Bây giờ bạn đã hiểu cách mà thư viện hoạt động, bạn đã sẵn sàng khám phá một số kịch bản nâng cao hơn.
Chọn Phiên bản Chrome Cụ thể
Bạn có thể chỉ định một phiên bản cụ thể của Chrome cho thư viện sử dụng bằng cách đặt tham số version_main:
language
import undetected_chromedriver as uc
# Chỉ định phiên bản mục tiêu của Chrome
driver = uc.Chrome(version_main=105)Với Cú pháp
Để tránh gọi thủ công phương thức quit() khi bạn không còn cần driver, bạn có thể sử dụng cú pháp with:
language
import undetected_chromedriver as uc
with uc.Chrome() as driver:
driver.get("https://example.com")
# Phần còn lại của mã của bạn...Hạn chế của Undetected ChromeDriver
Mặc dù undetected_chromedriver là một thư viện Python mạnh mẽ, nó vẫn có một số hạn chế đã biết:
Khối IP
Thư viện không giấu địa chỉ IP của bạn. Nếu bạn đang chạy một script từ trung tâm dữ liệu, khả năng cao là việc phát hiện vẫn sẽ xảy ra. Tương tự, nếu địa chỉ IP của bạn có uy tín kém, bạn cũng có thể bị chặn.
Để giấu IP của bạn, bạn cần tích hợp trình duyệt kiểm soát với một máy chủ proxy, như đã trình bày trước đó.
Không Hỗ trợ Điều hướng GUI
Do cách thức hoạt động bên trong của module, bạn phải duyệt theo cách lập trình bằng cách sử dụng phương thức get(). Tránh sử dụng GUI của trình duyệt để điều hướng thủ công—việc tương tác với trang bằng bàn phím hoặc chuột sẽ làm tăng nguy cơ bị phát hiện.
Hỗ trợ Hạn chế cho Chế độ Headless
Chế độ headless không được hỗ trợ hoàn toàn bởi thư viện undetected_chromedriver. Tuy nhiên, bạn có thể thử nghiệm với nó bằng cách sử dụng:
language
driver = uc.Chrome(headless=True)Vấn đề Ổn định
Kết quả có thể khác nhau do nhiều yếu tố. Không có đảm bảo nào được đưa ra, ngoài những nỗ lực liên tục để hiểu và chống lại các thuật toán phát hiện. Một script vượt qua hệ thống chống bot thành công hôm nay có thể thất bại vào ngày mai nếu các phương pháp bảo vệ nhận được cập nhật.
Lựa chọn thay thế được khuyến nghị: Scrapeless
Do các hạn chế của Undetected ChromeDriver, Scrapeless cung cấp một lựa chọn thay thế mạnh mẽ và đáng tin cậy hơn cho việc thu thập dữ liệu web mà không bị chặn.
Chúng tôi bảo vệ quyền riêng tư của trang web một cách nghiêm ngặt. Tất cả dữ liệu trong blog này đều công khai và chỉ được sử dụng như một sự minh họa cho quy trình thu thập thông tin. Chúng tôi không lưu trữ bất kỳ thông tin và dữ liệu nào.
Tại sao Scrapeless tốt hơn
Scrapeless là một dịch vụ trình duyệt từ xa giải quyết các vấn đề cố hữu với cách tiếp cận Undetected ChromeDriver:
-
Cập nhật liên tục: Không giống như Undetected ChromeDriver có thể ngừng hoạt động sau khi các hệ thống chống bot được cập nhật, Scrapeless được cập nhật liên tục bởi đội ngũ của nó.
-
Xoay vòng IP tích hợp: Scrapeless cung cấp xoay vòng IP tự động, loại bỏ vấn đề bị chặn IP của Undetected ChromeDriver.
-
Cấu hình tối ưu hóa: Các trình duyệt Scrapeless đã được tối ưu hóa để tránh bị phát hiện, điều này làm cho quá trình trở nên đơn giản hơn nhiều.
-
Giải quyết CAPTCHA tự động: Scrapeless có thể tự động giải quyết các CAPTCHA mà bạn có thể gặp phải.
-
Tương thích với nhiều framework: Hoạt động với Playwright, Puppeteer và các công cụ tự động hóa khác.
Đăng nhập vào Scrapeless để dùng thử miễn phí.
Đọc thêm: Cách Bỏ Qua Cloudflare Với Puppeteer
Cách sử dụng Scrapeless để thu thập dữ liệu web (mà không bị chặn)
Dưới đây là cách thực hiện một giải pháp tương tự với Scrapeless bằng Playwright:
Bước 1: Đăng ký và đăng nhập vào Scrapeless
Bước 2: Lấy mã API của Scrapeless
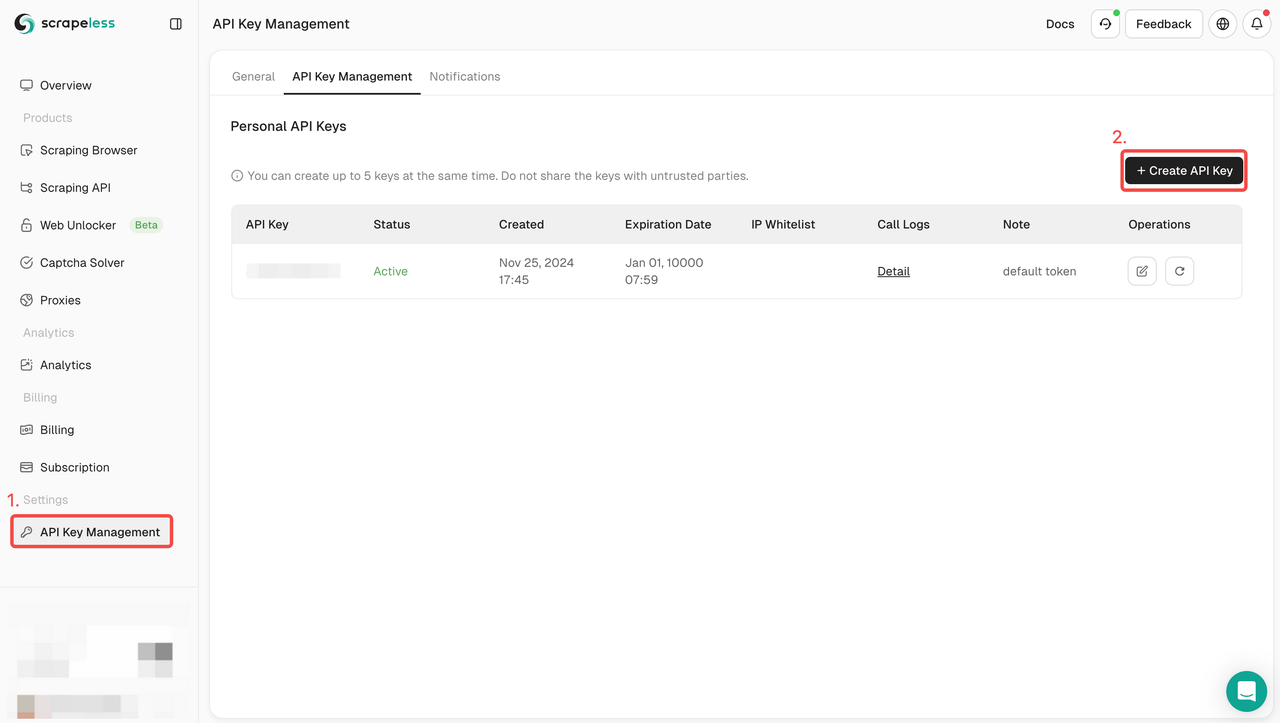
Bước 3: Bạn có thể tích hợp đoạn mã sau vào dự án của mình
```language
const {chromium} = require('playwright-core');
// URL kết nối Scrapeless với mã token của bạn
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOUR_TOKEN_HERE&session_ttl=180&proxy_country=ANY';
(async () => {
// Kết nối với trình duyệt Scrapeless từ xa
const browser = await chromium.connectOverCDP(connectionURL);
try {
// Tạo một trang mới
const page = await browser.newPage();
// Điều hướng đến website của Apple
console.log('Đang điều hướng đến website của Apple...');
await page.goto('https://www.apple.com/fr/', {
waitUntil: 'domcontentloaded',
timeout: 60000
});
console.log('Trang đã được tải thành công');
// Chờ các phần sản phẩm có sẵn
await page.waitForSelector('.homepage-section.collection-module', { timeout: 10000 });
// Lấy thông tin sản phẩm nổi bật từ trang chủ
const products = await page.evaluate(() => {
const results = [];
// Lấy tất cả các phần sản phẩm
const productSections = document.querySelectorAll('.homepage-section.collection-module .unit-wrapper');
productSections.forEach((section, index) => {
try {
// Lấy tên sản phẩm - có thể ở .headline hoặc .logo-image
const headlineEl = section.querySelector('.headline') || section.querySelector('.logo-image');
const headline = headlineEl ? headlineEl.textContent.trim() : 'Sản phẩm không rõ';
// Lấy mô tả sản phẩm
const subheadEl = section.querySelector('.subhead');
const subhead = subheadEl ? subheadEl.textContent.trim() : '';
// Lấy liên kết sản phẩm
const linkEl = section.querySelector('.unit-link');
const link = linkEl ? linkEl.getAttribute('href') : '';
results.push({
name: headline,
description: subhead,
link: link
});
} catch (err) {
console.error(`Lỗi khi xử lý phần ${index}: ${err.message}`);
}
});
return results;
});
// Hiển thị kết quả
console.log('Tìm thấy các sản phẩm của Apple:');
console.log(JSON.stringify(products, null, 2));
console.log(`Tổng số sản phẩm tìm thấy: ${products.length}`);
} catch (error) {
console.error('Đã xảy ra lỗi:', error);
} finally {
// Đóng trình duyệt
await browser.close();
console.log('Trình duyệt đã đóng');
}
})();Bạn cũng có thể tham gia Scrapeless Discord để tham gia chương trình hỗ trợ nhà phát triển và nhận tới 500k tín dụng sử dụng API SERP miễn phí.
Phân Tích Kỹ Thuật Nâng Cao
Phát Hiện Bot: Nó Hoạt Động Như Thế Nào
Các hệ thống chống bot sử dụng nhiều kỹ thuật để phát hiện tự động hóa:
-
Nhận diện dấu vân tay trình duyệt: Thu thập hàng chục thuộc tính trình duyệt (font chữ, canvas, WebGL, v.v.) để tạo ra một chữ ký độc đáo.
-
Phát hiện WebDriver: Tìm kiếm sự hiện diện của API WebDriver hoặc các dấu hiệu của nó.
-
Phân tích hành vi: Phân tích chuyển động chuột, cú nhấp chuột, tốc độ gõ phím mà khác biệt giữa con người và bot.
-
Phát hiện bất thường trong điều hướng: Nhận diện các mẫu đáng ngờ như yêu cầu quá nhanh hoặc thiếu tải hình ảnh/CSS.
Đọc thêm: Cách Bỏ Qua Chống Bot
Cách Undetected ChromeDriver Bỏ Qua Phát Hiện
Undetected ChromeDriver vượt qua những phát hiện này bằng cách:
-
Loại bỏ các chỉ báo WebDriver: Loại bỏ thuộc tính
navigator.webdrivervà các dấu vết khác của WebDriver. -
Sửa chữa Cdc_: Chỉnh sửa các biến của Chrome Driver Controller mà được biết đến là các chữ ký của ChromeDriver.
-
Sử dụng User-Agent thực tế: Thay thế User-Agent mặc định bằng các chuỗi cập nhật.
-
Giảm thiểu thay đổi cấu hình: Giảm thiểu các thay đổi so với hành vi mặc định của trình duyệt Chrome.
Mã kỹ thuật cho thấy cách Undetected ChromeDriver sửa chữa driver:
language
Trích dẫn đơn giản từ mã nguồn của Undetected ChromeDriver
def _patch_driver_executable():
"""
Sửa chữa tệp nhị phân ChromeDriver để loại bỏ dấu hiệu của tự động hóa
"""
linect = 0
replacement = os.urandom(32).hex()
with io.open(self.executable_path, "r+b") as fh:
for line in iter(lambda: fh.readline(), b""):
if b"cdc_" in line.lower():
fh.seek(-len(line), 1)
newline = re.sub(
b"cdc_.{22}", b"cdc_" + replacement.encode(), line
)
fh.write(newline)
linect += 1
return linectTại Sao Scrapeless Hiệu Quả Hơn
Scrapeless tiếp cận vấn đề theo một cách khác bằng cách:
-
Môi trường đã được cấu hình sẵn: Sử dụng các trình duyệt đã được tối ưu hóa để giả lập người dùng.
-
Hạ tầng đám mây: Chạy trình duyệt trên đám mây với xác thực dấu vân tay đúng cách.
-
Xoay vòng proxy thông minh: Tự động xoay vòng IP dựa trên trang web mục tiêu.
-
Quản lý dấu vân tay nâng cao: Duy trì các dấu vân tay trình duyệt nhất quán trong suốt phiên làm việc.
-
Chặn WebRTC, Canvas và Plugin: Chặn các kỹ thuật giả lập dấu vân tay phổ biến.
Đăng nhập vào Scrapeless để dùng thử miễn phí.
Kết luận
Trong bài viết này, bạn đã học cách đối phó với việc phát hiện bot trong Selenium sử dụng Undetected ChromeDriver. Thư viện này cung cấp một phiên bản đã vá của ChromeDriver để thu thập dữ liệu web mà không bị chặn.
Thách thức là các công nghệ chống bot nâng cao như Cloudflare vẫn có thể phát hiện và chặn các script của bạn. Các thư viện như undetected_chromedriver không ổn định—trong khi chúng có thể hoạt động hôm nay, chúng có thể không hoạt động vào ngày mai.
Đối với nhu cầu thu thập dữ liệu chuyên nghiệp, các giải pháp dựa trên đám mây như Scrapeless cung cấp một lựa chọn đáng tin cậy hơn. Họ cung cấp các trình duyệt từ xa đã được cấu hình sẵn, được thiết kế đặc biệt để vượt qua các biện pháp chống bot, với các tính năng bổ sung như xoay vòng IP và giải CAPTCHA.
Sự lựa chọn giữa Undetected ChromeDriver và Scrapeless phụ thuộc vào nhu cầu cụ thể của bạn:
- Undetected ChromeDriver: Tốt cho các dự án nhỏ, miễn phí và mã nguồn mở, nhưng yêu cầu nhiều bảo trì và có thể kém tin cậy hơn.
- Scrapeless: Tốt hơn cho nhu cầu thu thập dữ liệu chuyên nghiệp, đáng tin cậy hơn, được cập nhật liên tục, nhưng đi kèm với chi phí đăng ký.
Bằng cách hiểu cách hoạt động của các công nghệ vượt qua chống bot này, bạn có thể chọn công cụ phù hợp cho các dự án thu thập dữ liệu web của mình và tránh những cạm bẫy phổ biến của việc thu thập dữ liệu tự động.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


