
Cách lấy dữ liệu từ trang web yêu cầu đăng nhập bằng Python (2026)
Expert Network Defense Engineer
Sau nhiều năm xây dựng trình thu thập dữ liệu, các bức tường đăng nhập vẫn là một trong những thách thức khó khăn nhất. Hướng dẫn này tập trung vào các phương pháp thực tế hoạt động trong các dự án thực: từ đăng nhập bằng biểu mẫu đơn giản đến bảo vệ CSRF và các trang được bảo vệ bởi WAF hiện đại và các hệ thống chống bot. Các ví dụ được trình bày bằng Python khi có liên quan, và tôi kết thúc bằng cách chỉ cách sử dụng trình duyệt từ xa (Scrapeless Browser) để xử lý các bảo vệ khó khăn nhất.
Hướng dẫn này chỉ dành cho mục đích giáo dục. Tôn trọng các điều khoản dịch vụ và quy định về quyền riêng tư của trang (ví dụ: GDPR). Đừng thu thập nội dung mà bạn không được phép truy cập.
Những gì hướng dẫn này đề cập
- Thu thập dữ liệu từ các trang yêu cầu tên người dùng và mật khẩu đơn giản.
- Đăng nhập vào các trang yêu cầu mã CSRF.
- Truy cập nội dung đằng sau bảo vệ WAF cơ bản.
- Xử lý các bảo vệ chống bot nâng cao bằng cách sử dụng trình duyệt từ xa (Scrapeless Browser) được điều khiển thông qua Puppeteer.
Bạn có thể thu thập dữ liệu từ các trang yêu cầu đăng nhập không?
Có — về mặt kỹ thuật, bạn có thể lấy dữ liệu từ các trang sau khi đăng nhập. Tuy nhiên, các giới hạn pháp lý và đạo đức áp dụng. Các nền tảng xã hội và các trang có dữ liệu cá nhân đặc biệt nhạy cảm. Luôn kiểm tra chính sách robots của trang đích, các điều khoản dịch vụ và luật pháp áp dụng.
Về mặt kỹ thuật, các bước chính là:
- Hiểu quy trình đăng nhập.
- Tái tạo các yêu cầu (và mã) cần thiết một cách có lập trình.
- Giữ trạng thái đã xác thực (cookies, phiên).
- Xử lý kiểm tra phía khách hàng khi cần thiết.
1) Đăng nhập bằng tên người dùng + mật khẩu đơn giản (Requests + BeautifulSoup)
Kết luận trước: Nếu đăng nhập là biểu mẫu HTTP cơ bản, hãy sử dụng phiên và POST thông tin đăng nhập.
Cài đặt các thư viện:
bash
pip3 install requests beautifulsoup4Ví dụ mã:
python
import requests
from bs4 import BeautifulSoup
login_url = "https://www.example.com/login"
payload = {
"email": "admin@example.com",
"password": "password",
}
with requests.Session() as session:
r = session.post(login_url, data=payload)
print("Mã trạng thái:", r.status_code)
soup = BeautifulSoup(r.text, "html.parser")
print("Tiêu đề trang:", soup.title.string)Ghi chú:
- Sử dụng
Session()để cookies (id phiên) giữ lại cho các yêu cầu tiếp theo. - Kiểm tra mã phản hồi và nội dung để xác nhận đăng nhập thành công.
- Nếu trang sử dụng chuyển hướng,
requestssẽ theo dõi chúng theo mặc định; kiểm trar.historynếu cần.
2) Đăng nhập được bảo vệ bằng CSRF (lấy mã, sau đó gửi)
Kết luận trước: Nhiều trang yêu cầu mã CSRF. Đầu tiên GET trang đăng nhập, phân tích mã, sau đó POST cùng với mã.
Mô hình:
- GET trang đăng nhập.
- Phân tích mã ẩn từ biểu mẫu.
- POST thông tin đăng nhập + mã bằng cách sử dụng cùng một phiên.
Ví dụ:
python
import requests
from bs4 import BeautifulSoup
login_url = "https://www.example.com/login/csrf"
with requests.Session() as session:
r = session.get(login_url)
soup = BeautifulSoup(r.text, "html.parser")
csrf_token = soup.find("input", {"name": "_token"})["value"]
payload = {
"_token": csrf_token,
"email": "admin@example.com",
"password": "password",
}
r2 = session.post(login_url, data=payload)
soup2 = BeautifulSoup(r2.text, "html.parser")
products = []
for item in soup2.find_all(class_="product-item"):
products.append({
"Tên": item.find(class_="product-name").text.strip(),
"Giá": item.find(class_="product-price").text.strip(),
})
print(products)Mẹo:
- Một số khung sử dụng các tên mã khác nhau; kiểm tra biểu mẫu để tìm tên trường nhập đúng.
- Gửi các tiêu đề thích hợp (User-Agent, Referer) để trông giống như một trình duyệt bình thường.
3) Kiểm tra WAF cơ bản / chống bot — sử dụng một trình duyệt không đầu khi Requests không thành công
Khi các tiêu đề và mã không đủ, hãy mô phỏng một trình duyệt thực với Selenium hoặc một trình duyệt không đầu.
Selenium + Chrome có thể vượt qua nhiều bảo vệ cơ bản vì nó thực thi JavaScript và chạy trong môi trường trình duyệt đầy đủ. Nếu bạn sử dụng Selenium, hãy thêm thời gian chờ hợp lý, các hành động chuột/bàn phím và các tiêu đề trình duyệt bình thường.
Tuy nhiên, một số WAF phát hiện tự động hóa thông qua navigator.webdriver hoặc các thủ thuật khác. Các công cụ như undetected-chromedriver giúp ích, nhưng chúng không được đảm bảo chống lại các kiểm tra nâng cao. Chỉ sử dụng chúng cho các mục đích hợp pháp, được phép.
4) Các bảo vệ chống bot nâng cao — sử dụng phiên trình duyệt thực từ xa (Scrapeless Browser)
Nhận API Key Scrapeless của bạn
Đăng nhập vào Scrapeless và nhận API Key của bạn.
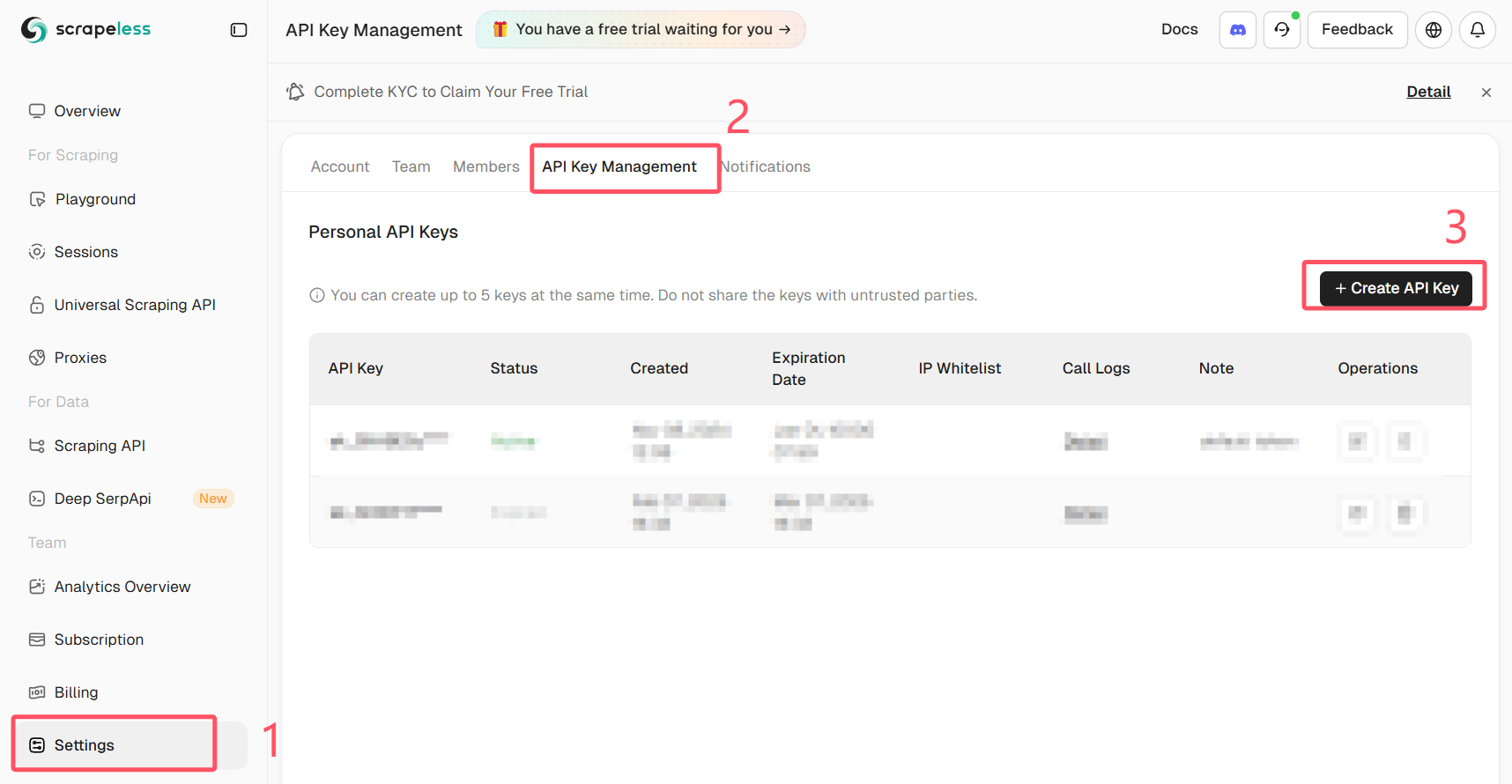
Đối với cách tiếp cận mạnh mẽ nhất, hãy chạy một trình duyệt thực từ xa (không phải một phiên bản không đầu địa phương) và điều khiển nó qua Puppeteer. Scrapeless Browser cung cấp một điểm cuối trình duyệt được quản lý giúp giảm thiểu rủi ro phát hiện và giảm tải độ phức tạp trong việc proxy/hiển thị JS.
Tại sao điều này giúp ích:
- Trình duyệt chạy trong môi trường được quản lý mô phỏng các phiên người dùng thực.
- JS thực thi chính xác như trong trình duyệt của người dùng thực, vì vậy các kiểm tra phía khách hàng sẽ thành công.
- Bạn có thể ghi lại các phiên và sử dụng định tuyến proxy theo nhu cầu.
Dưới đây là một ví dụ cho thấy cách kết nối Puppeteer với Scrapeless Browser và thực hiện đăng nhập tự động. Đoạn mã sử dụng puppeteer-core để kết nối với điểm cuối WebSocket của Scrapeless. Thay thế token, your_email@example.com và your_password bằng các giá trị của riêng bạn và không bao giờ chia sẻ thông tin xác thực công khai.
Quan trọng: không bao giờ cam kết thông tin xác thực thực hoặc mã API vào mã công khai. Lưu trữ bí mật một cách an toàn (biến môi trường hoặc trình quản lý bí mật).
import puppeteer from "puppeteer-core"
// 💡Bật "Sử dụng Cài đặt Chơi thử" sẽ ghi đè các tham số kết nối của mã chơi thử của bạn.
const query = new URLSearchParams({
token: "your-scrapeless-api-key",
proxyCountry: "ANY",
sessionRecording: true,
sessionTTL: 900,
sessionName: "Đăng Nhập Tự Động",
})
const connectionURL = `wss://browser.scrapeless.com/api/v2/browser?${query.toString()}`
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
})
const page = await browser.newPage()
await page.goto("https://github.com/login")
await page.locator("input[name='login']").fill("your_email@example.com")
await page.locator("input[name='password']").fill("your_password")
await page.keyboard.press("Enter")Ghi chú về mẫu:
- Ví dụ sử dụng
puppeteer-coređể gắn kết với một trình duyệt từ xa. Scrapeless cung cấp một điểm cuối WebSocket (browserWSEndpoint) mà Puppeteer có thể sử dụng. - Ghi lại phiên và các tùy chọn proxy được truyền qua các tham số truy vấn. Điều chỉnh theo kế hoạch và nhu cầu Scrapeless của bạn.
- Logic chờ rất quan trọng: sử dụng
waitUntil: "networkidle"hoặcwaitForSelectorrõ ràng để đảm bảo trang đã được tải đầy đủ. - Thay thế mã thông báo mẫu bằng một bí mật an toàn từ môi trường của bạn.
Mẹo thực tiễn và danh sách kiểm tra chống chặn
- Sử dụng API của trang nếu có. Nó an toàn và ổn định hơn.
- Tránh các yêu cầu song song nhanh chóng; giới hạn tốc độ của scraper của bạn.
- Luân chuyển IP và dấu vết phiên khi hợp lệ và cần thiết. Sử dụng các nhà cung cấp proxy uy tín.
- Sử dụng tiêu đề thực tế và xử lý cookie.
- Kiểm tra robots.txt và điều khoản trang. Nếu trang không cho phép thu thập dữ liệu, hãy xem xét việc xin phép hoặc sử dụng nguồn dữ liệu chính thức.
- Ghi lại các bước mà scraper của bạn thực hiện để dễ dàng gỡ lỗi (các yêu cầu, mã phản hồi, chuyển hướng).
Tóm tắt
Bạn đã học được cách:
- Đăng nhập và thu thập dữ liệu từ các trang chấp nhận tên người dùng/mật khẩu đơn giản bằng
requests. - Trích xuất và sử dụng mã thông báo CSRF để xác thực một cách an toàn.
- Sử dụng công cụ tự động hóa trình duyệt khi một trang cần làm đầy đủ JS.
- Sử dụng một trình duyệt được quản lý từ xa (Scrapeless Browser) qua Puppeteer để vượt qua các biện pháp bảo vệ phía khách hàng tiên tiến trong khi giữ môi trường của riêng bạn đơn giản.
Khi các biện pháp bảo vệ mạnh mẽ, phương pháp trình duyệt được quản lý thường là con đường đáng tin cậy nhất. Sử dụng nó một cách có trách nhiệm và giữ cho thông tin xác thực và mã API của bạn được an toàn.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


