
Cách sử dụng trình duyệt Scraping của Scrapeless để trích xuất dữ liệu từ trang web
Advanced Data Extraction Specialist
Tại sao nên chọn Trình duyệt Scraping của Scrapeless để Web Scraping?
Web scraping đã trở thành một công cụ quan trọng đối với các doanh nghiệp để thu thập dữ liệu thời gian thực, từ giá cả của đối thủ cạnh tranh đến xu hướng thị trường. Một cuộc khảo sát gần đây của Statista cho thấy hơn 70% doanh nghiệp dựa vào web scraping để trích xuất dữ liệu có giá trị, làm cho nó trở thành một phần quan trọng trong việc ra quyết định dựa trên dữ liệu.
Khi thị trường web scraping phát triển, với dự báo đạt 5,4 tỷ USD vào năm 2025 (MarketsandMarkets), các doanh nghiệp ngày càng áp dụng các công cụ scraping vì hiệu quả và khả năng mở rộng của chúng. Tuy nhiên, những thách thức như chặn IP, CAPTCHA và nội dung động có thể làm gián đoạn quá trình scraping.
Scrapeless giải quyết các vấn đề này với các giải pháp dựa trên AI, đảm bảo trích xuất dữ liệu liền mạch ngay cả khi đối mặt với các rào cản chống scraping phổ biến.
Bắt đầu scraping thông minh hơn ngay hôm nay với Trình duyệt Scraping của Scrapeless! Trích xuất dữ liệu từ các trang web một cách dễ dàng với công cụ thân thiện với người dùng của chúng tôi, được thiết kế để xử lý ngay cả các trang web phức tạp nhất. Hãy thử ngay bây giờ và trải nghiệm trích xuất dữ liệu liền mạch như chưa từng có!
Scrapeless cung cấp một giải pháp web scraping tiên tiến dựa trên AI được thiết kế để giúp các doanh nghiệp vượt qua những trở ngại phổ biến này. Bộ công cụ Scrapeless được thiết kế dành cho những người tìm kiếm việc trích xuất dữ liệu chất lượng cao, đáng tin cậy và nhanh chóng từ web. Cho dù bạn muốn scraping các trang web thương mại điện tử, nền tảng truyền thông xã hội hay tổng hợp tin tức, Scrapeless đều cung cấp các công cụ phù hợp để hoàn thành công việc.
Lợi ích chính của Scrapeless bao gồm:
- Quản lý proxy liền mạch: Bảo vệ các phiên scraping của bạn bằng cách luân chuyển IP và phạm vi phủ sóng toàn cầu.
- Giải pháp CAPTCHA dựa trên AI: Tự động giải quyết các thách thức CAPTCHA để đảm bảo việc thu thập dữ liệu của bạn không bị gián đoạn.
- Công nghệ trình duyệt tiên tiến: Điều hướng các trang web động, phức tạp mà không gặp lỗi.
- Giải pháp có thể mở rộng: Từ các tác vụ trích xuất dữ liệu nhỏ đến các hoạt động scraping quy mô lớn, Scrapeless có thể mở rộng để đáp ứng nhu cầu của bạn.
Scrapeless không chỉ là một công cụ scraping khác. Đó là một nền tảng toàn diện giải quyết các thách thức chính liên quan đến web scraping, đảm bảo việc thu thập dữ liệu của bạn vẫn nhanh chóng, hiệu quả và đáng tin cậy. Cho dù bạn là một công ty khởi nghiệp hay một doanh nghiệp lớn, tính linh hoạt của Scrapeless cho phép bạn tùy chỉnh các tác vụ scraping theo nhu cầu cụ thể của mình. Từ quản lý proxy đến xử lý các trang web phức tạp với nội dung động, Scrapeless cung cấp tất cả các công cụ cần thiết để đơn giản hóa các hoạt động web scraping của bạn và tiết kiệm thời gian quý báu.
Trình duyệt Scraping Scrapeless:
Trung tâm của giải pháp web scraping của Scrapeless là Trình duyệt Scraping. Trình duyệt Scraping của Scrapeless được tối ưu hóa để xử lý các tình huống scraping khó khăn nhất và tích hợp liền mạch với bộ công cụ Scrapeless để mang lại trải nghiệm scraping đặc biệt.
Các tính năng chính của Trình duyệt Scraping Scrapeless:
- 🌐 Xử lý nội dung động: Dễ dàng scraping các trang web có JavaScript và nội dung động nặng mà các công cụ khác thường gặp khó khăn.
- 🖥️ Chế độ Headless: Chạy các tác vụ scraping mà không cần mở cửa sổ trình duyệt đầy đủ, cải thiện hiệu suất và giảm sử dụng tài nguyên.
- 🛡️ Công nghệ chống phát hiện: Ngăn chặn phát hiện bằng các kỹ thuật tiên tiến như dấu vân tay trình duyệt và chế độ ẩn danh.
- ⚡ Hiệu quả vượt trội: Nhanh hơn 10 lần so với chế độ trình duyệt truyền thống, chạy trên máy chủ để có thời gian phản hồi nhanh hơn và hỗ trợ truy cập đồng thời quy mô lớn.
- ⏱️ Thời gian hoạt động 99,99%: Khả năng hoạt động đáng tin cậy, 24/7 đảm bảo các tác vụ scraping của bạn luôn chạy đúng lịch trình.
Với Trình duyệt Scraping của Scrapeless, quy trình trích xuất dữ liệu của bạn trở nên nhanh hơn, đáng tin cậy hơn và dễ dàng hơn, đảm bảo bạn có thể tập trung vào việc trích xuất thông tin có giá trị hơn là xử lý các thách thức kỹ thuật của scraping.
Bắt đầu với Trình duyệt Scraping của Scrapeless
API Key (Application Programming Interface Key) là một công cụ được sử dụng để xác minh danh tính và ủy quyền truy cập vào API. Nó thường là một chuỗi duy nhất các chữ cái, số và ký hiệu. API Key đóng vai trò như một "mật khẩu" xác thực khi truy cập API, đảm bảo rằng yêu cầu được thực hiện bởi người dùng hoặc ứng dụng hợp pháp.
✅ Bạn có thể nhận được API KEY bằng cách làm theo các bước dưới đây:
- Sau khi nhấp vào đăng nhập vào Scrapeless, bạn có thể tự động nhận được API KEY tương ứng.
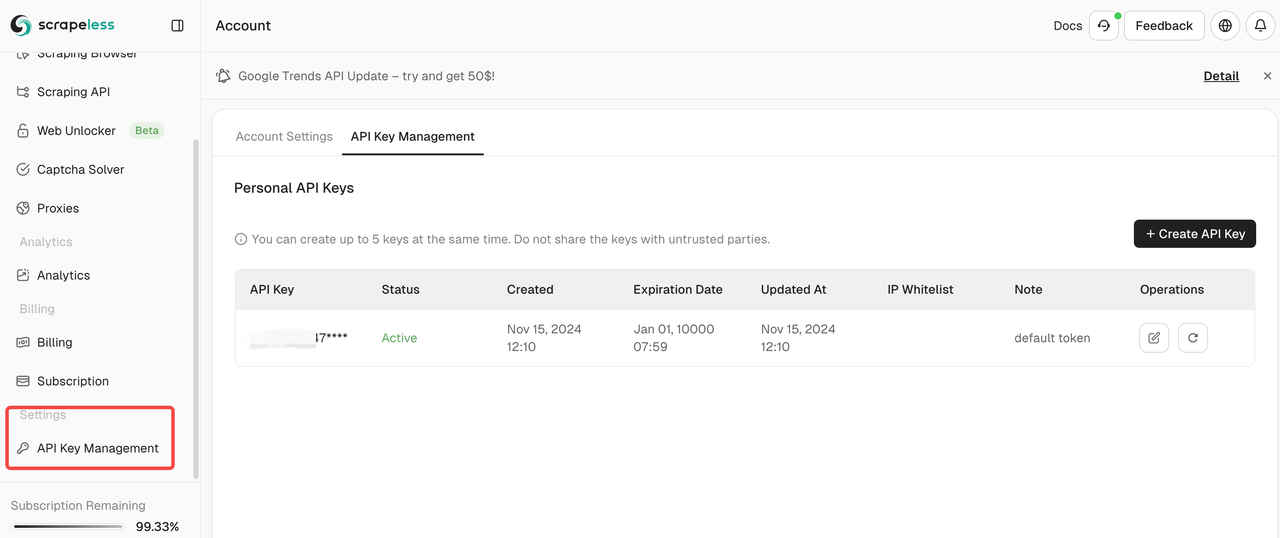
- Bạn có thể thấy API Key của mình trong Quản lý API Key:
Hướng dẫn từng bước để Scraping các trang web với Scrapeless
Trong phần này, chúng ta sẽ sử dụng scrapeless + puppeteer để chứng minh cách thu thập nội dung sản phẩm trên Amazon.
Puppeteer là một thư viện Node.js do Google phát triển, cung cấp một API cấp cao để thực hiện các hoạt động tự động thông qua trình duyệt Chromium hoặc Chrome. Nó có thể được sử dụng để điều khiển trình duyệt, nhấp chuột, nhập liệu, điều hướng, v.v. như một người dùng bình thường, và cũng có thể thu thập nội dung trang, tạo ảnh chụp màn hình và PDF, kiểm tra trang web, v.v.
Đầu tiên, chúng ta cần lấy API Key scrapeless. Bạn có thể tham khảo phần trước để tìm hiểu cách lấy và xem API Key của mình.
Hướng dẫn từng bước để Scraping các trang web với Scrapeless:
- Cài đặt puppeteer thông qua lệnh npm
npm i puppeteer-core- Chuẩn bị các thông số kết nối cho scrapeless. Bạn có thể đặt thời gian phiên và cấu hình quốc gia proxy.
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOU_TOKEN&session_ttl=180&proxy_country=ANY';- Bắt đầu chuẩn bị để thu thập dữ liệu sản phẩm trên Amazon、
- Sử dụng công cụ dành cho nhà phát triển của trình duyệt (F12) để lấy hộp nhập liệu và các phần tử tìm kiếm, và lấy bộ chọn của phần tử.
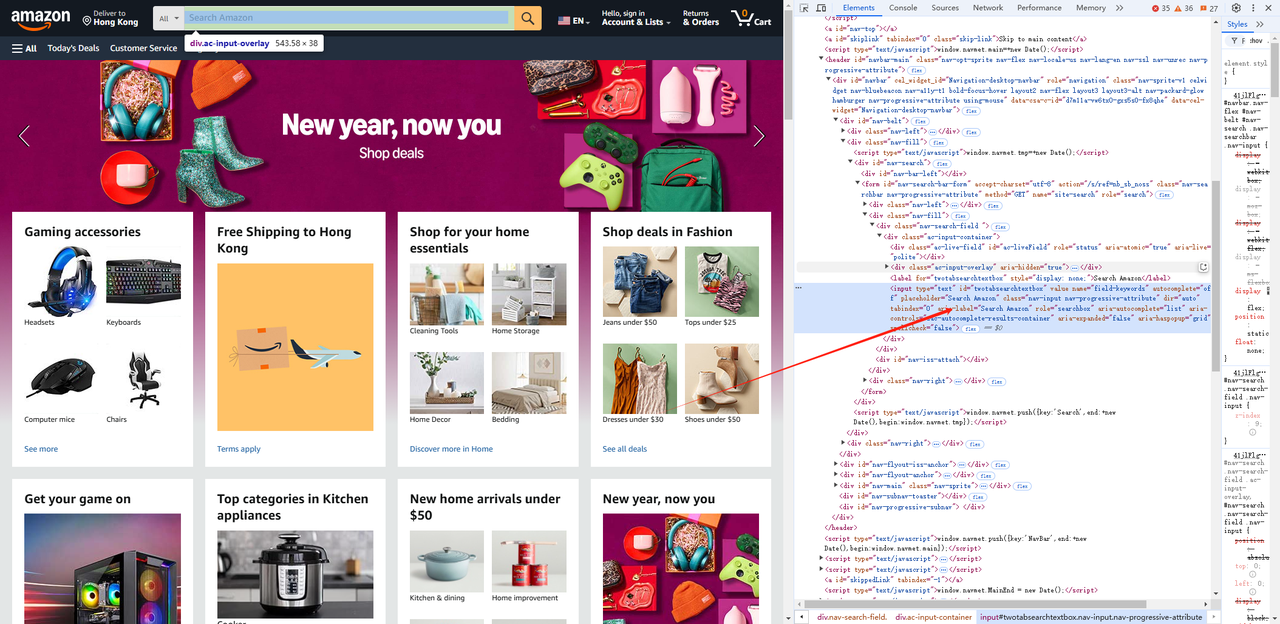
await page.waitForSelector('#twotabsearchtextbox')
await page.type('#twotabsearchtextbox', 'iphone 15', { delay: 100 })
await page.click('#nav-search-submit-button')Bạn có thể thay thế iphone 15 bằng nội dung bạn muốn thu thập.
- Sau đó, chúng ta đến trang danh sách sản phẩm, và chúng ta lấy tất cả các phần tử div có thuộc tính role là listitem.
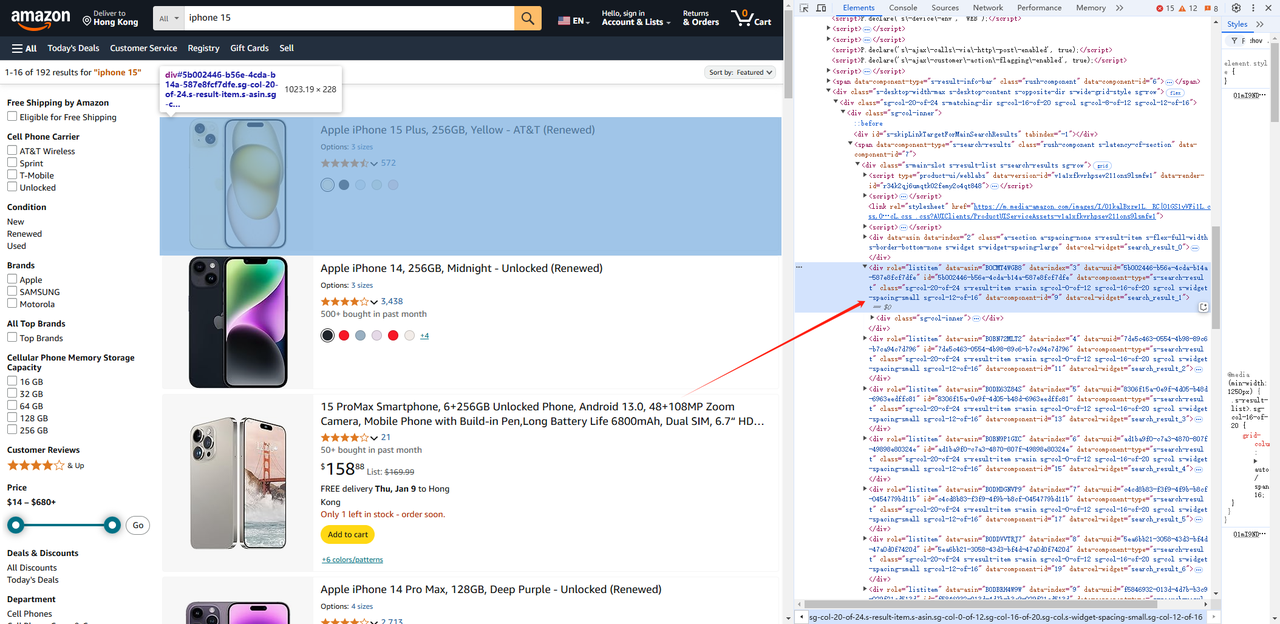
await page.waitForSelector('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]') // Bạn cần chờ phần tử được hiển thị trước khi lấy nó
const list = await page.$$('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')- Tương tự, chúng ta có thể lấy thông tin sản phẩm như hình ảnh, tiêu đề, liên kết, v.v. cho mỗi Element.
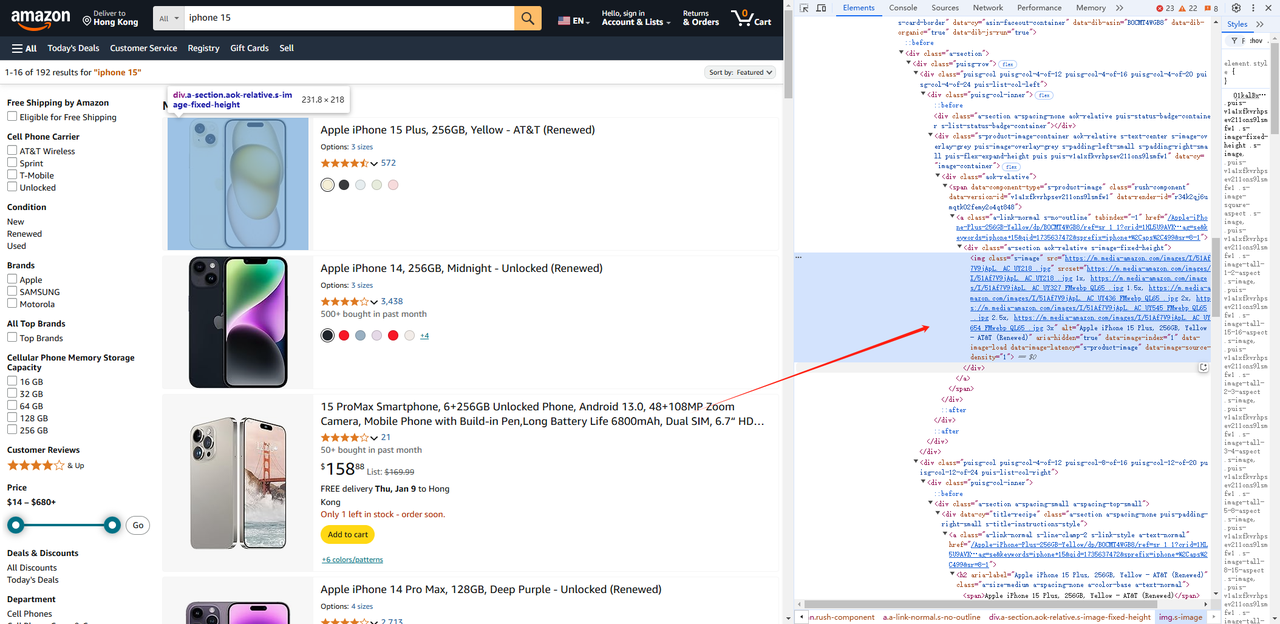
const renderList = []
for (const item of list) {
const img = await item.$('img').then((ele) => {
return ele.evaluate((ele) => {
const img = ele.getAttribute("src")
const title = ele.getAttribute("alt")
return { img, title }
})
})
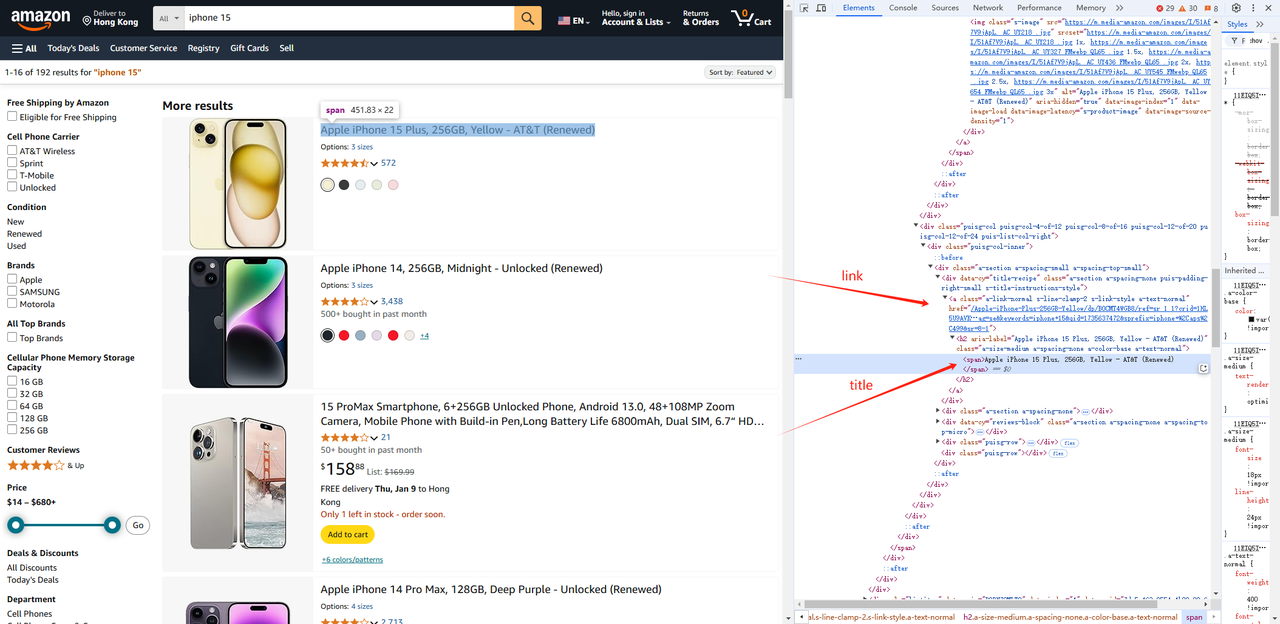
const link = await item.$('.a-link-normal.s-line-clamp-2.s-link-style.a-text-normal').then((ele) => {
return ele.evaluate((ele) => {
return `https://www.amazon.com${ele.getAttribute("href")}`
})
})
img.link = link
renderList.push(img)
}Chạy mã hoàn chỉnh sau đây để lấy nội dung đã thu thập:
import puppeteer from 'puppeteer-core';
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOU_TOKEN&session_ttl=180&proxy_country=ANY';
(async () => {
try {
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL
});
const page = await browser.newPage();
await page.goto('https://www.amazon.com/');
await page.waitForSelector('#twotabsearchtextbox')
await page.type('#twotabsearchtextbox', 'iphone 15', { delay: 100 })
await page.click('#nav-search-submit-button')
await page.waitForSelector('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')
const list = await page.$$('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')
const renderList = []
for (const item of list) {
const img = await item.$('img').then((ele) => {
return ele.evaluate((ele) => {
const img = ele.getAttribute("src")
const title = ele.getAttribute("alt")
return { img, title }
})
})
const link = await item.$('.a-link-normal.s-line-clamp-2.s-link-style.a-text-normal').then((ele) => {
return ele.evaluate((ele) => {
return `https://www.amazon.com${ele.getAttribute("href")}`
})
})
img.link = link
renderList.push(img)
}
console.log(JSON.stringify(renderList))
} catch (e) {
console.error(e)
}
})();[
{
"img": "https://m.media-amazon.com/images/I/61WUSYIQdKL._AC_UY218_.jpg",
"title": "Apple iPhone 14, 256GB, Midnight - Unlocked (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-14-256GB-Midnight/dp/B0BN72MLT2/ref=sr_1_1?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-1"
},
{
"img": "https://m.media-amazon.com/images/I/51Af7V9jApL._AC_UY218_.jpg",
"title": "Apple iPhone 15 Plus, 256GB, Yellow - AT&T (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-Plus-256GB-Yellow/dp/B0CMT4WGB8/ref=sr_1_2?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-2"
},
{
"img": "https://m.media-amazon.com/images/I/71wtsuGLA4L._AC_UY218_.jpg",
"title": "15 ProMax Smartphone, 6+256GB Unlocked Phone, Android 13.0, 48+108MP Zoom Camera, Mobile Phone with Build-in Pen,Long Batt...",
"link": "https://www.amazon.com/15-ProMax-Smartphone-Unlocked-Titanium/dp/B0DK63Z84S/ref=sr_1_3?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-3"
},
{
"img": "https://m.media-amazon.com/images/I/71Xu6GSGm1L._AC_UY218_.jpg",
"title": "Apple iPhone 15 Pro, 128GB, Natural Titanium - Boost Mobile (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-128GB-Natural-Titanium/dp/B0DK7BCPH5/ref=sr_1_4?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-4"
},
{
"img": "https://m.media-amazon.com/images/I/61j3-75mrLL._AC_UY218_.jpg",
"title": "SZV 15 ProMAX 12+512GB Unlocked Cell Phone,Smartphone 6.85\" HD Screen Unlocked Phones,Battery 7000mAh Android 13,5G/Face I...",
"link": "https://www.amazon.com/SZV-Unlocked-Smartphone-Battery-Fingerprint/dp/B0DHDGNVP9/ref=sr_1_5?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-5"
}
]Các tính năng nâng cao dành cho người dùng chuyên nghiệp
Khi thực hiện các hoạt động web scraping quy mô lớn hoặc phức tạp, các tính năng nâng cao là cần thiết để duy trì hiệu quả, vượt qua các trở ngại và mở rộng các tác vụ scraping của bạn. Trình duyệt Scraping Scrapeless cung cấp một loạt các tính năng mạnh mẽ để đáp ứng nhu cầu của người dùng chuyên nghiệp cần hơn là khả năng scraping cơ bản, và cũng cung cấp một số tính năng nâng cao:
- Tùy chỉnh các thông số scraping cho các trường hợp sử dụng cụ thể
Một trong những thách thức chính của web scraping là điều chỉnh các công cụ của bạn để trích xuất chính xác những gì bạn cần mà không tạo ra dữ liệu dư thừa hoặc bỏ lỡ cơ hội. Scrapeless cung cấp các tùy chọn tùy chỉnh nâng cao cho phép người dùng đặt các thông số scraping cụ thể phù hợp với trường hợp sử dụng chính xác của họ.
- Xử lý CAPTCHA và các biện pháp bảo vệ chống scraping
Các trang web thường triển khai các thách thức CAPTCHA và các cơ chế chống scraping phức tạp để chặn các robot tự động. Trình duyệt Scraping Scrapeless là một trình duyệt dấu vân tay dựa trên đám mây với khả năng mở khóa CAPTCHA. Các giải pháp tiên tiến này không chỉ tăng tốc độ thu thập dữ liệu mà còn giảm khả năng bị phát hiện hoặc bị chặn bởi các trang web có biện pháp chống bot mạnh mẽ.
- Sử dụng proxy và luân phiên để mở rộng và tránh bị cấm IP
Việc mở rộng các hoạt động scraping thường dẫn đến việc các trang web cấm IP và giới hạn tốc độ, điều này làm gián đoạn việc thu thập dữ liệu. Để giảm bớt vấn đề này, Scrapeless cung cấp một mạng proxy mạnh mẽ bao gồm luân phiên IP và nhóm proxy để giúp bạn duy trì việc thu thập dữ liệu liên tục, quy mô lớn mà không bị gián đoạn. Scrapeless cung cấp quyền truy cập vào mạng proxy khổng lồ gồm hơn 80 triệu IP từ hơn 200 quốc gia, đảm bảo rằng người dùng có thể phân phối các yêu cầu và tránh bị cấm IP.
Thực hành tốt nhất để Web Scraping hiệu quả
Web scraping là một công cụ mạnh mẽ dành cho các doanh nghiệp muốn thu thập dữ liệu có giá trị từ web. Tuy nhiên, để trích xuất dữ liệu hiệu quả và tránh những cạm bẫy phổ biến, điều quan trọng là phải tuân theo các thực hành tốt nhất. Bằng cách tận dụng các giải pháp dựa trên AI như Scrapeless, các doanh nghiệp có thể nâng cao chiến lược scraping của mình để đảm bảo độ chính xác, tuân thủ và khả năng mở rộng. Dưới đây là phân tích các thực hành tốt nhất về web scraping, bao gồm cả cách Scrapeless có thể tối ưu hóa các quy trình này cho bạn.
Đảm bảo độ chính xác và đầy đủ của dữ liệu
Một trong những thách thức chính của web scraping là đảm bảo dữ liệu được thu thập là chính xác. Khi trích xuất các tập dữ liệu lớn từ nhiều nguồn khác nhau, rất dễ gặp phải các vấn đề như thiếu hoặc không nhất quán trong dữ liệu. Để khắc phục điều này, các thuật toán AI trong Scrapeless có thể tự động phân tích cấu trúc trang web và điều chỉnh phương pháp scraping cho phù hợp với nội dung.
Tuân thủ các tiêu chuẩn pháp lý và đạo đức
Với sự giám sát ngày càng tăng đối với web scraping, điều quan trọng là phải hoạt động trong phạm vi pháp lý và đạo đức. Người dùng scraper phải nhận thức được các luật về quyền riêng tư, điều khoản dịch vụ của trang web và các quy định như GDPR. Scrapeless giúp duy trì sự tuân thủ bằng cách tích hợp khả năng phát hiện robot.txt thông minh để đảm bảo rằng việc scraping tuân thủ các quy tắc do chủ sở hữu trang web đặt ra.
Ngoài ra, AI có thể được sử dụng để phân tích nội dung trang web và lọc dữ liệu nhạy cảm hoặc được bảo vệ, đảm bảo các doanh nghiệp tránh các hành vi không đạo đức. Các thuật toán AI của Scrapeless được thiết kế để giúp người dùng tuân thủ các yêu cầu pháp lý, giúp họ tránh những rủi ro như vi phạm quyền sở hữu trí tuệ hoặc vi phạm quyền riêng tư.
Tránh bị chặn bởi các trang web
Các trang web thường triển khai các biện pháp chống scraping để phát hiện và chặn các scraper tự động. Công nghệ AI trong Scrapeless giúp tránh bị phát hiện bằng cách mô phỏng hành vi duyệt web của con người, làm cho các yêu cầu scraping trông tự nhiên hơn. Thuật toán AI điều chỉnh tần suất yêu cầu, thời gian và tiêu đề để bắt chước hoạt động của người dùng thực, làm giảm đáng kể khả năng bị chặn.
Ngoài ra, Scrapeless sử dụng luân phiên proxy, một hệ thống dựa trên AI tự động chuyển đổi giữa nhiều địa chỉ IP để phân phối các yêu cầu. Điều này giúp bỏ qua các giới hạn tốc độ và ngăn các trang web chặn một địa chỉ IP duy nhất vì gửi quá nhiều yêu cầu. Bằng cách sử dụng luân phiên proxy dựa trên AI một cách thông minh, Scrapeless đảm bảo trích xuất dữ liệu không bị gián đoạn.
Tối ưu hóa công nghệ Scrapeless để Thu thập dữ liệu quy mô lớn
Đối với các doanh nghiệp tham gia vào việc thu thập dữ liệu quy mô lớn, hiệu quả và khả năng mở rộng của scraping là rất quan trọng. Khả năng AI của Scrapeless tự động điều chỉnh chiến lược scraping để đảm bảo hiệu suất tối ưu, ngay cả khi trích xuất dữ liệu từ các trang web phức tạp hoặc lớn. Ví dụ: trình thu thập dữ liệu dựa trên AI của Scrapeless có thể xử lý nội dung động như các trang web sử dụng nhiều JavaScript, cho phép các doanh nghiệp thu thập một phạm vi nội dung rộng hơn mà các công cụ truyền thống có thể gặp khó khăn trong việc xử lý.
Ngoài ra, các thuật toán AI giúp ưu tiên dữ liệu quan trọng nhất, đảm bảo phân bổ tài nguyên hiệu quả khi xử lý lượng thông tin lớn. Điều này cho phép việc thu thập dữ liệu khối lượng lớn liền mạch đáp ứng nhu cầu của doanh nghiệp trong khi duy trì tốc độ và hiệu suất.
Tuân theo các thực hành tốt nhất về web scraping là chìa khóa để tối đa hóa giá trị của dữ liệu được thu thập. Bằng cách tận dụng công nghệ thu thập dữ liệu dựa trên AI của Scrapeless, các doanh nghiệp có thể cải thiện độ chính xác của dữ liệu, đảm bảo tuân thủ pháp luật, tránh bị chặn bởi các trang web và tối ưu hóa hoạt động thu thập dữ liệu cho việc thu thập dữ liệu quy mô lớn. Với Scrapeless, các công ty có thể nhanh chóng, hiệu quả và có đạo đức truy cập dữ liệu họ cần, giúp họ đi trước trong một không gian cạnh tranh, dựa trên dữ liệu.
Khắc phục sự cố Web Scraping phổ biến
- Thay đổi cấu trúc trang web
- Vấn đề: Các trang web thường xuyên cập nhật bố cục hoặc cấu trúc HTML, khiến các scraper dựa trên các thẻ cụ thể bị hỏng.
- Giải pháp: Xây dựng các scraper linh hoạt bằng cách sử dụng các kỹ thuật động hoặc triển khai xử lý lỗi có thể thích ứng với những thay đổi nhỏ. Scrapeless cung cấp một scraper thông minh, mạnh mẽ dựa trên AI phát hiện các thay đổi và điều chỉnh cho phù hợp.
- Chặn IP
- Vấn đề: Các trang web giới hạn số lượng yêu cầu từ một địa chỉ IP duy nhất, chặn các scraper sau quá nhiều lần thử.
- Giải pháp: Sử dụng Proxy Scrapeless với luân phiên IP để phân phối các yêu cầu trên nhiều IP, làm cho việc phát hiện các mô hình scraping và chặn quyền truy cập trở nên khó khăn hơn đối với các trang web.
- CAPTCHA và Cơ chế chống Scraping
- Vấn đề: CAPTCHA và các biện pháp chống bot khác (như các thách thức JavaScript) có thể ngăn chặn scraper của bạn.
- Giải pháp: Tận dụng Scrapeless Captcha Solver để tự động giải quyết CAPTCHA. Đối với các trang có nhiều JavaScript, hãy sử dụng Trình duyệt Scraping Scrapeless, trình duyệt này xử lý nội dung động hiệu quả.
- Giới hạn tốc độ
- Vấn đề: Các trang web giới hạn số lượng yêu cầu trong một khoảng thời gian cụ thể để ngăn ngừa quá tải máy chủ, khiến các scraper bị lỗi.
- Giải pháp: Thiết lập scraper của bạn với proxy và luân phiên, và các điều khiển giới hạn tốc độ để bắt chước hành vi của con người và tránh bị vượt quá giới hạn tốc độ.
- Dữ liệu không chính xác hoặc thiếu thông tin
- Vấn đề: Scraping dẫn đến dữ liệu không đầy đủ hoặc không chính xác do lỗi trong logic scraping hoặc phân tích dữ liệu kém.
- Giải pháp: Triển khai các kiểm tra để xác thực dữ liệu đã scraping và đảm bảo rằng scraper được cấu hình đúng cách. Scrapeless sử dụng các thuật toán dựa trên AI để đảm bảo tính toàn vẹn và nhất quán của dữ liệu.
- Vấn đề pháp lý và đạo đức
- Vấn đề: Scraping một số trang web có thể vi phạm điều khoản dịch vụ hoặc luật địa phương, dẫn đến hậu quả pháp lý.
- Giải pháp: Luôn đảm bảo bạn tuân thủ các tiêu chuẩn pháp lý và đạo đức. Scrapeless cung cấp một khung làm việc tích hợp để giúp đảm bảo các hoạt động scraping của bạn vẫn nằm trong phạm vi pháp luật.
Để biết thêm các thách thức phổ biến trong web scraping và cách giải quyết chúng, hãy đọc: Cách giải quyết các thách thức Web Scraping - Hướng dẫn đầy đủ năm 2025
Câu hỏi thường gặp về Scraping trang web
1. Làm thế nào để tôi scraping một trang web?
Phương pháp đơn giản nhất là sao chép thủ công dữ liệu cần thiết trực tiếp từ trang web và dán nó vào tài liệu.
Bạn cũng có thể sử dụng công cụ dành cho nhà phát triển của trình duyệt (chẳng hạn như chức năng "Inspect" của Chrome) để xem cấu trúc HTML của trang web và trích xuất dữ liệu từ đó. Đơn giản nhất là sử dụng các công cụ không cần mã như Scrapeless, cho phép người dùng dễ dàng thiết lập các tác vụ scraping thông qua giao diện đồ họa mà không cần viết mã.
Với những phương pháp này, bạn có thể scraping trang web hiệu quả và trích xuất dữ liệu cần thiết.
2. Có được không khi scraping dữ liệu từ các trang web?
Web scraping là hợp pháp miễn là bạn tuân theo các điều khoản dịch vụ, chính sách sử dụng dữ liệu và luật địa phương của trang web. Luôn kiểm tra tệp robots.txt và điều khoản dịch vụ của trang web trước khi scraping. Tốt nhất là tuân theo các giới hạn tốc độ và tránh scraping dữ liệu cá nhân hoặc có bản quyền.
3. Làm thế nào để tôi trích xuất tất cả các trang từ một trang web?
Bạn có thể sử dụng một trình thu thập web để scraping tất cả các trang của một trang web. Điều này liên quan đến việc truy cập đệ quy tất cả các liên kết từ trang chủ hoặc các trang chính khác. Các công cụ như Trình duyệt Scraping Scrapeless hoặc API Scrapeless có thể tự động hóa quy trình này, trích xuất dữ liệu từ mọi trang dựa trên cấu trúc của trang web.
4. Công cụ nào được sử dụng để web scraping?
Các công cụ web scraping phổ biến bao gồm Scrapeless, BeautifulSoup, Selenium, Octoparse và Scrapy. Các công cụ này cho phép người dùng tự động hóa quá trình trích xuất dữ liệu từ các trang web bằng cách gửi yêu cầu, phân tích cú pháp nội dung HTML và cung cấp dữ liệu ở các định dạng có cấu trúc như CSV, JSON hoặc Excel.
5. Bạn có thể kiếm tiền bằng web scraping không?
Có, bạn có thể kiếm tiền bằng web scraping bằng cách cung cấp dịch vụ trích xuất dữ liệu cho các doanh nghiệp, tiến hành nghiên cứu thị trường hoặc scraping dữ liệu công khai cho khách hàng. Web scraping cũng có thể được sử dụng để thu thập dữ liệu cho phân tích cạnh tranh, tạo khách hàng tiềm năng hoặc xây dựng các cơ sở dữ liệu chuyên ngành có giá trị đối với các ngành công nghiệp như thương mại điện tử, bất động sản và tài chính.
Kết luận: Tại sao Scrapeless là tương lai của Web Scraping
Scrapeless cung cấp một giải pháp mạnh mẽ, dựa trên AI để đơn giản hóa các tác vụ web scraping, mang lại những lợi ích to lớn cho các nhà phát triển và doanh nghiệp. Với các tính năng tiên tiến của mình, Scrapeless đảm bảo rằng việc thu thập dữ liệu của bạn hiệu quả, chính xác và có thể mở rộng:
- AI Scraping: Tận dụng AI để cải thiện hiệu quả scraping và xử lý nội dung động, phức tạp.
- Nhanh hơn 10 lần: Hoạt động trình duyệt được tối ưu hóa làm cho nó nhanh hơn 10 lần so với các phương pháp scraping truyền thống.
- Bỏ qua CAPTCHA và Chống Scraping: Tự động bỏ qua CAPTCHA và các biện pháp bảo vệ chống bot khác.
- Scraping có thể tùy chỉnh: Tùy chỉnh các thông số scraping để đáp ứng các nhu cầu và trường hợp sử dụng cụ thể.
- Luồng công việc tự động: Tự động hóa dựa trên AI làm giảm sự can thiệp thủ công và đơn giản hóa việc thu thập dữ liệu.
Cho dù bạn là một nhà phát triển muốn cải thiện hiệu quả scraping hay một doanh nghiệp muốn thu thập dữ liệu có cấu trúc ở quy mô lớn, Scrapeless cung cấp một giải
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


