Cách sử dụng Playwright để bỏ qua CAPTCHA
Advanced Bot Mitigation Engineer
Có CAPTCHA nào đã ngăn bạn cạo web không? Những khó khăn này có thể gây đau đầu khi tự động thu thập dữ liệu. May mắn thay, có 2 cách để vượt qua CAPTCHA bằng Playwright, chúng ta sẽ đi sâu vào bài viết này.
Playwright có thể giải quyết CAPTCHA không?
CAPTCHA được thiết kế để khó đối với bot nhưng đơn giản đối với con người, nhưng chúng ta cũng sẽ xem xét về cách bạn có thể sử dụng Playwright kết hợp với các công cụ hữu ích khác để loại bỏ chúng.
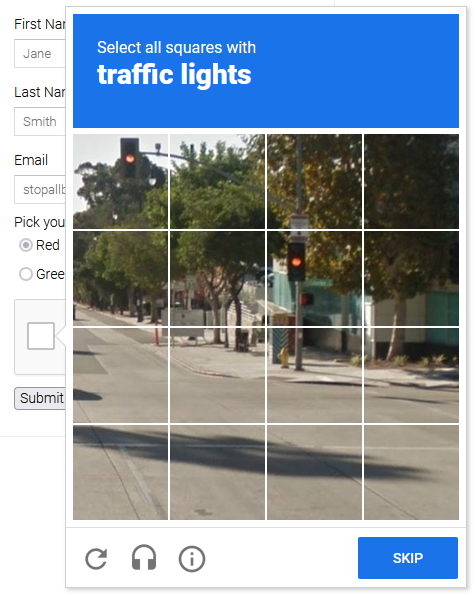
Một bài học quan trọng là bạn có thể: A) hoàn thành bài kiểm tra ngay khi nó xảy ra; hoặc B) tránh hoàn toàn và thử lại nếu nó xuất hiện.
Trong trường hợp đầu tiên, việc sử dụng trình giải CAPTCHA của Playwright sẽ là cần thiết và nó có thể trở nên đắt tiền với số lượng lớn. Để tránh bị phát hiện trong trường hợp thứ hai, trình cạo web của bạn phải bắt chước hành vi của con người tốt hơn. Cả hai chiến lược sẽ được hiển thị, nhưng là điểm khởi đầu, chiến lược thứ hai là tốt nhất.
Bây giờ hãy xem xét cách bạn có thể đưa những điều này vào thực tế!
Phương pháp 1: Sử dụng Playwright cơ bản và trình giải Captcha để bỏ qua CAPTCHA.
Phương pháp đầu tiên chúng ta sẽ thảo luận là sử dụng Playwright với Scrapeless, một dịch vụ giải quyết CAPTCHA bằng cách sử dụng con người thay mặt bạn.
Bạn có mệt mỏi với CAPTCHA và các khối cạo web liên tục không?
Scrapeless: giải pháp cạo web trực tuyến tốt nhất hiện có!
Sử dụng bộ công cụ mạnh mẽ của chúng tôi để khai thác hết tiềm năng của việc trích xuất dữ liệu của bạn:
Trình giải CAPTCHA tốt nhất
Giải quyết tự động các CAPTCHA phức tạp để đảm bảo cạo web liên tục và trơn tru.
Hãy thử miễn phí!
Phương pháp 2: Sử dụng Plugin Stealth trong Playwright
Nếu bạn cần thu thập dữ liệu từ trang web có các chướng ngại vật CAPTCHA khó hơn, thiết lập Playwright trước đó sẽ không hoạt động, nhưng plugin Stealth là một giải pháp thay thế hữu ích. Dự án mã nguồn mở này thêm các yếu tố vào Playwright để khiến nó giống với lưu lượng truy cập web thực tế hơn:
- User-Agent của bạn được ẩn.
- Để tránh xác định địa chỉ IP, WebRTC bị vô hiệu hóa. Nó bảo vệ quyền riêng tư bằng cách ẩn lịch sử duyệt web ngay cả khi nó không đặc biệt cấm các tập lệnh theo dõi.
- Để khiến các yêu cầu của bạn trông tự nhiên hơn, nó nâng cao trình duyệt ẩn danh của bạn bằng các thành phần bổ sung.
- Để tăng thêm sức mạnh cho ví dụ của chúng ta, hãy thử Astra, một trang web có bảo mật Cloudflare tối thiểu.
Trước khi bắt đầu, hãy cài đặt các phụ thuộc cần thiết bằng cách thực hiện lệnh sau trong thư mục dự án của bạn:
language
npm install playwright playwright-extraCần lưu ý rằng khung playwright-extra có plugin Stealth.
Để nâng cao Playwright, hãy sử dụng playwright-extra để khởi chạy trình duyệt Chrome ẩn danh và chromium.use(pluginStealth) để bật puppeteer-extra-plugin-stealth. Bộ công nghệ này cung cấp thêm biện pháp bảo vệ để khiến các trang web khó phát hiện trình thu thập dữ liệu web của bạn hơn.
language
const { chromium } = require('playwright-extra')
// Tải plugin stealth và sử dụng mặc định (tất cả các mẹo để ẩn việc sử dụng playwright)
const pluginStealth = require("puppeteer-extra-plugin-stealth");
// Sử dụng stealth
chromium.use(pluginStealth)
// Đó là tất cả, phần còn lại là việc sử dụng playwright như bình thường 😊
chromium.launch({ headless: true }).then(async browser => {
// Tạo một trang mới
const page = await browser.newPage()
// Đi đến trang web
await page.goto('https://www.scrapeless.com/')
// Chờ trang tải xuống
await page.waitForTimeout(1000);
// Chụp ảnh màn hình
await page.screenshot({ path: 'screen.png'})
// Đóng trình duyệt
console.log('Hoàn thành, kiểm tra ảnh chụp màn hình. ✨')
await browser.close()
})Trang web của chúng tôi được chuẩn bị để scraping khi một trang mới đã được tải bằng browser.newPage() và phương thức page.goto() đã được gọi.
Kết luận
Có thể khó khăn để vượt qua CAPTCHA bằng Playwright vì trở ngại nổi tiếng này được thiết kế để ngăn chặn truy cập tự động vào các trang web. Tuy nhiên, bạn sẽ có thể thu thập dữ liệu mong muốn nếu bạn có các công cụ và thư viện phù hợp.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


