🎯 Trình duyệt đám mây tùy chỉnh, chống phát hiện được hỗ trợ bởi Chromium tự phát triển, thiết kế dành cho trình thu thập dữ liệu web và tác nhân AI. 👉Dùng thử ngay
Cách sử dụng Selenium với PowerShell [Hướng dẫn 2025]
Emily Chen
Advanced Data Extraction Specialist
01-Mar-2025
Selenium vẫn là lựa chọn phổ biến cho việc thu thập dữ liệu web và kiểm thử thông qua tự động hóa trình duyệt. Những tác vụ này thường được viết bằng các ngôn ngữ kịch bản, bao gồm PowerShell. Để tận dụng khả năng của Selenium với PowerShell, cộng đồng nhà phát triển đã tạo ra các ràng buộc chuyên dụng giúp tích hợp này trở nên khả thi.
Tuy nhiên, việc thu thập dữ liệu web ngày càng trở nên khó khăn hơn do các hệ thống chống bot tinh vi như Cloudflare. Trong hướng dẫn toàn diện này, bạn sẽ khám phá:
Bắt đầu với Selenium và PowerShell
Tương tác với các trang web trong trình duyệt
Tránh bị chặn bởi các hệ thống chống bot
Giải quyết các thách thức Cloudflare với Scrapeless Scraping Browser
Hãy bắt đầu thôi!
Bạn có thể sử dụng Selenium với PowerShell không?
Selenium là thư viện trình duyệt headless phổ biến nhất trong cộng đồng CNTT. API phong phú và nhất quán của nó làm cho nó trở nên hoàn hảo để xây dựng các kịch bản tự động hóa trình duyệt để kiểm thử và thu thập dữ liệu web.
PowerShell là một shell lệnh mạnh mẽ có sẵn trên cả môi trường máy khách và máy chủ Windows. Tự động hóa trình duyệt bổ sung hoàn hảo cho việc viết kịch bản, đó là lý do tại sao cộng đồng nhà phát triển đã tạo ra selenium-powershell, một phiên bản của Selenium WebDriver dành cho PowerShell.
Mặc dù thư viện hiện đang tìm kiếm người duy trì, nhưng nó vẫn là mô-đun được sử dụng nhiều nhất cho tự động hóa web trong PowerShell.
Lưu ý: Nếu bạn cần ôn lại kiến thức cơ bản trước khi bắt đầu hướng dẫn Selenium PowerShell này, hãy xem lại các nguyên tắc cơ bản về thu thập dữ liệu trình duyệt headless và thu thập dữ liệu web với PowerShell.
Thu thập dữ liệu web với Selenium và PowerShell: Kiến thức cơ bản
Lưu ý: Các ví dụ trong bài viết này được thiết kế cho hệ điều hành Windows, vì một số tính năng như mô-đun Selenium-PowerShell và các đối tượng COM là dành riêng cho Windows. Nếu bạn đang sử dụng macOS hoặc Linux, bạn có thể cần phải điều chỉnh các kịch bản này cho phù hợp.
Trong phần này, chúng ta sẽ giới thiệu các khái niệm cơ bản về việc sử dụng Selenium với PowerShell. Trước khi đi sâu vào các trang web được bảo vệ bởi Cloudflare phức tạp hơn như G2, điều hữu ích là hiểu các nguyên tắc cơ bản.
Mục tiêu của chúng ta: Đánh giá G2
Đối với hướng dẫn này, chúng ta sẽ tập trung vào việc thu thập dữ liệu đánh giá từ G2, cụ thể là các đánh giá Airtable tại: https://www.g2.com/products/airtable/reviews. Đây là một ví dụ thực tế về một trang web được bảo vệ bởi Cloudflare gây ra những thách thức đối với các phương pháp thu thập dữ liệu truyền thống.
Điều gì làm cho G2 trở thành mục tiêu thú vị:
Nó được bảo vệ bởi Cloudflare, ngăn chặn hầu hết các nỗ lực thu thập dữ liệu cơ bản
Nó chứa các đánh giá phần mềm kinh doanh có giá trị có thể hữu ích cho nghiên cứu thị trường
Các đánh giá được cấu trúc theo cách làm cho chúng lý tưởng để trích xuất dữ liệu
Nó đại diện cho loại dữ liệu kinh doanh có giá trị cao thường nằm phía sau các hệ thống chống bot
Trước tiên, hãy xem cách tiếp cận Selenium với PowerShell truyền thống sẽ gặp khó khăn như thế nào với trang web này, sau đó xem Scrapeless có thể giải quyết vấn đề như thế nào.
Cài đặt ChromeDriver đúng (Tháng 2 năm 2025)
Một bước quan trọng khi thiết lập Selenium với PowerShell là đảm bảo bạn có phiên bản ChromeDriver chính xác phù hợp với trình duyệt Chrome của mình. Tính đến ngày 28 tháng 2 năm 2025, đây là các phiên bản Chrome mới nhất và các WebDrivers tương ứng:
Chrome Stable (133.0.6943.141):
ChromeDriver dành cho Windows 64 bit: chromedriver-win64.zip
ChromeDriver dành cho Windows 32 bit: chromedriver-win32.zip
ChromeDriver dành cho Mac (Intel): chromedriver-mac-x64.zip
ChromeDriver dành cho Mac (M1/M2): chromedriver-mac-arm64.zip
ChromeDriver dành cho Linux: chromedriver-linux64.zip
Nếu bạn đang sử dụng phiên bản Chrome khác (Beta, Dev hoặc Canary), hãy đảm bảo tải xuống ChromeDriver phù hợp từ phần tương ứng của trang tải xuống Chrome for Testing.
Tải xuống ChromeDriver phù hợp với hệ thống của bạn, giải nén tệp ZIP và đặt tệp thực thi vào thư mục dự án của bạn. Sau đó tham chiếu vị trí này trong kịch bản PowerShell của bạn:
Việc sử dụng phiên bản ChromeDriver chính xác là rất quan trọng - nếu có sự không khớp phiên bản, Selenium sẽ đưa ra lỗi và không thể điều khiển Chrome đúng cách.
Thử thu thập dữ liệu G2 với Selenium cơ bản
Bây giờ, hãy thử truy cập trang đánh giá G2 với thiết lập Selenium cơ bản của chúng ta:
Copy
Import-Module -Name Selenium
# Khởi tạo Selenium WebDriver
$Driver = Start-SeChrome -WebDriverDirectory './chromedriver-win64' -Headless
# Truy cập trang đánh giá G2
Enter-SeUrl 'https://www.g2.com/products/airtable/reviews' -Driver $Driver
# Chờ một lát để trang tải
Start-Sleep -Seconds 5
# Lấy tiêu đề trang
$Title = $Driver.Title
Write-Host "Tiêu đề trang: $Title"
# In nguồn trang
$Html = $Driver.PageSource
$Html | Out-File -FilePath "g2_response.html"
# Đóng trình duyệt
Stop-SeDriver -Driver $Driver
Khi bạn chạy kịch bản này, thay vì nhận được trang đánh giá G2 thực tế, bạn có thể sẽ thấy:
Trang thách thức Cloudflare
Tiêu đề như "Chỉ một chút..." hoặc "Đang kiểm tra trình duyệt của bạn..."
HTML chứa thách thức JavaScript của Cloudflare
Điều này là do Cloudflare phát hiện các trình duyệt tự động như Selenium và đưa ra một thách thức mà cấu hình Selenium cơ bản không thể tự động giải quyết.
Thách thức thu thập dữ liệu G2: Hiểu cấu trúc đánh giá
Trước khi thử trích xuất dữ liệu, hãy hiểu những gì chúng ta đang cố gắng thu thập. Các đánh giá G2 có định dạng có cấu trúc bao gồm:
Tiêu đề đánh giá: Thông thường là tóm tắt được trích dẫn của đánh giá
Xếp hạng: Được hiển thị dưới dạng sao (trên 5)
Ngày: Khi nào đánh giá được xuất bản
Văn bản đánh giá: Được chia thành các phần như "Bạn thích nhất điều gì?" và "Bạn không thích điều gì?"
Thông tin người dùng: Chi tiết về người đã viết đánh giá
Đây là giao diện của một đánh giá G2 điển hình trong cấu trúc HTML:
Copy
<div class="paper__bd">
<div class="d-f mb-1">
<div class="f-1 d-f ai-c mb-half-small-only">
<div class="stars large xlarge--medium-down stars-10"></div>
<div class="time-stamp pl-4th ws-nw">
<span><span class="x-current-review-date" data-poison-date="">
<meta content="2025-02-11" itemprop="datePublished">
<time datetime="2025-02-11">Feb 11, 2025</time>
</span></span>
</div>
</div>
</div>
<div class="d-f">
<div class="f-1">
<div data-poison="">
<a class="pjax" href="https://www.g2.com/products/airtable/reviews/airtable-review-10822745">
<div class="m-0 l2" itemprop="name">"Helped us get a handle on our complicated team-based scheduling and management."</div>
</a>
</div>
<div data-poison-text="">
<div itemprop="reviewBody">
<div>
<div class="l5 mt-2">What do you like best about Airtable?</div>
<div>
<p class="formatted-text">The best part about airtable is it's customiizable nature. We worked with a tech specialist to configure Airtable to meet our unique needs and it has so far been adaptable to everything we needed it to do...</p>
</div>
</div>
<!-- More review sections... -->
</div>
</div>
</div>
</div>
</div>
Giải pháp: Scrapeless Scraping Browser để bỏ qua Cloudflare
Ngay cả với cấu hình Selenium nâng cao, nhiều dự án thu thập dữ liệu bị chặn bởi hệ thống bảo mật của Cloudflare. Đây là lúc Scrapeless Scraping Browser trở thành một giải pháp thay đổi cục diện.
Scrapeless Scraping Browser là gì?
Scrapeless Scraping Browser là một giải pháp hiệu suất cao cung cấp môi trường trình duyệt headless, cho phép bạn bỏ qua các thách thức JavaScript mà không cần duy trì cơ sở hạ tầng của riêng mình. Nó tích hợp với Puppeteer và Playwright để tự động hóa liền mạch và cung cấp:
Được điều khiển bằng AI, tự động thích ứng với các chính sách bảo mật mới nhất
Phạm vi toàn cầu để truy cập nội dung bị hạn chế về mặt địa lý
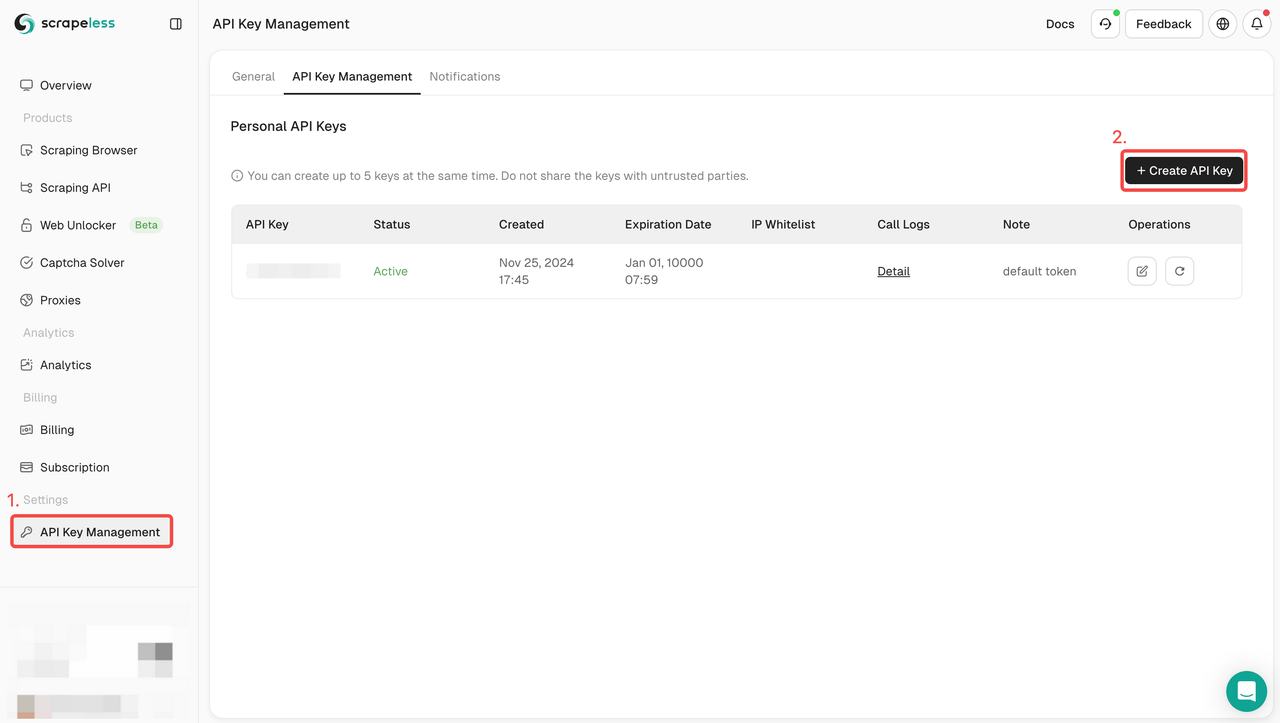
Đăng nhập vào Scrapeless bảng điều khiển ngay lập tức và tạo KHÓA API của bạn trong quản lý KHÓA API
Sử dụng Scrapeless Scraping Browser để trích xuất đánh giá G2
Bây giờ chúng ta đã hiểu tại sao Selenium với PowerShell tiêu chuẩn lại gặp khó khăn với các trang web được bảo vệ bởi Cloudflare như G2, hãy thực hiện một giải pháp sử dụng Scrapeless Scraping Browser.
Thiết lập Scrapeless Scraping Browser với Puppeteer
Cách hiệu quả nhất để sử dụng Scrapeless Scraping Browser là thông qua Node.js với Puppeteer. Đây là cách thiết lập:
Xác minh việc cài đặt bằng cách mở dấu nhắc lệnh và nhập:
Copy
node --version
npm --version
Tạo một thư mục dự án
Tạo một thư mục mới cho dự án thu thập dữ liệu của bạn
Mở dấu nhắc lệnh trong thư mục này
Cài đặt gói cần thiết
Cài đặt puppeteer-core bằng npm:
Copy
npm install puppeteer-core
Tạo kịch bản thu thập dữ liệu của bạn
Tạo một tệp có tên scrape.js với mã sau:
Copy
// scrape.js
const puppeteer = require('puppeteer-core');
async function scrapeG2Reviews() {
// Thay thế bằng mã thông báo Scrapeless API thực tế của bạn
const API_TOKEN = 'YOUR_API_TOKEN_HERE';
// Cấu hình kết nối với Scrapeless Scraping Browser
const connectionURL = `wss://browser.scrapeless.com/browser?token=${API_TOKEN}&session_ttl=180&proxy_country=ANY`;
console.log('Đang kết nối với Scrapeless Scraping Browser...');
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Đã kết nối!');
const page = await browser.newPage();
// Đặt thời gian chờ dài hơn cho việc điều hướng
page.setDefaultNavigationTimeout(120000);
// Mảng để lưu trữ tất cả các đánh giá
const allReviews = [];
// Số trang cần thu thập dữ liệu
const pagesToScrape = 3;
for (let currentPage = 1; currentPage <= pagesToScrape; currentPage++) {
console.log(`Đang điều hướng đến trang ${currentPage}...`);
// Điều hướng trực tiếp đến số trang cụ thể
const pageUrl = currentPage === 1
? 'https://www.g2.com/products/airtable/reviews'
: `https://www.g2.com/products/airtable/reviews?page=${currentPage}`;
await page.goto(pageUrl, {
waitUntil: 'networkidle2',
timeout: 60000
});
console.log(`Trang ${currentPage} đã tải. Đang chụp ảnh màn hình...`);
// Chụp ảnh màn hình để xác minh trang đã tải đúng cách
await page.screenshot({ path: `g2_page_${currentPage}.png` });
// Chờ nội dung trang tải
// Thử các bộ chọn có thể có khác nhau vì cấu trúc có thể đã thay đổi
try {
console.log('Đang chờ nội dung tải...');
// Đầu tiên thử bộ chọn ban đầu
await page.waitForSelector('.paper__bd', { timeout: 10000 })
.then(() => console.log('Đã tìm thấy bộ chọn: .paper__bd'))
.catch(() => console.log('Bộ chọn .paper__bd không tìm thấy, đang thử các phương án thay thế...'));
// Nếu chúng ta vẫn ở đây, hãy kiểm tra cấu trúc trang bằng cách tiếp cận khác
console.log('Đang phân tích cấu trúc trang...');
// Lấy tiêu đề trang để xác minh chúng ta đang ở đúng trang
const pageTitle = await page.title();
console.log('Tiêu đề trang:', pageTitle);
// Trích xuất đánh giá bằng cách tiếp cận tổng quát hơn
console.log('Đang trích xuất đánh giá...');
// Thử trích xuất đánh giá bằng cách tiếp cận linh hoạt hơn
const pageReviews = await page.evaluate(() => {
// Tìm các vùng chứa đánh giá với nhiều bộ chọn
const reviewElements = Array.from(
document.querySelectorAll('.paper__bd, .review-item, .reviews-section article, [data-testid="review-card"]')
);
console.log(`Đã tìm thấy ${reviewElements.length} phần tử đánh giá tiềm năng`);
if (reviewElements.length === 0) {
// Nếu không tìm thấy đánh giá nào với các bộ chọn cụ thể, hãy đổ cấu trúc trang
const html = document.documentElement.outerHTML;
return { error: 'Không tìm thấy đánh giá', html: html.substring(0, 5000) }; // 5000 ký tự đầu tiên để gỡ lỗi
}
return reviewElements.map(review => {
// Thử lấy tiêu đề với nhiều bộ chọn tiềm năng
const titleElement =
review.querySelector('[itemprop="name"], .review-title, h3, h4') ||
review.querySelector('a.pjax div');
const title = titleElement ? titleElement.innerText.trim() : 'Không có tiêu đề';
// Thử lấy ngày với nhiều bộ chọn tiềm năng
const dateElement =
review.querySelector('time, .review-date, [data-testid="review-date"]') ||
review.querySelector('.time-stamp');
const date = dateElement ? dateElement.innerText.trim() : 'Không có ngày';
// Thử lấy xếp hạng với nhiều cách tiếp cận
let rating = 0;
const starsElement = review.querySelector('.stars, .rating, [data-testid="star-rating"]');
if (starsElement) {
// Kiểm tra xem có lớp stars-X không
const starsClass = starsElement.className;
const starsMatch = starsClass.match(/stars-(\d+)/);
if (starsMatch) {
rating = parseInt(starsMatch[1]) / 2;
} else {
// Nếu không thì kiểm tra aria-label có thể chứa xếp hạng không
const ariaLabel = starsElement.getAttribute('aria-label');
if (ariaLabel) {
const ratingMatch = ariaLabel.match(/(\d+(\.\d+)?)/);
if (ratingMatch) {
rating = parseFloat(ratingMatch[1]);
}
}
}
}
// Thử lấy văn bản đánh giá với nhiều bộ chọn tiềm năng
const textElements = review.querySelectorAll('.formatted-text, .review-content, p, [data-testid="review-content"]');
let content = '';
textElements.forEach(el => {
const text = el.innerText.trim();
if (text && !text.includes('Review collected by and hosted on G2.com')) {
content += text + '\n\n';
}
});
return {
title,
date,
rating,
content: content.trim() || 'Không tìm thấy nội dung'
};
});
});
if (pageReviews.error) {
console.log('Lỗi trích xuất đánh giá:', pageReviews.error);
console.log('Đoạn HTML của trang:', pageReviews.html);
} else {
console.log(`Đã trích xuất ${pageReviews.length} đánh giá từ trang ${currentPage}`);
// Thêm vào bộ sưu tập của chúng ta
allReviews.push(...pageReviews);
}
} catch (error) {
console.error('Lỗi trên trang:', error);
// Chụp ảnh màn hình khác khi xảy ra lỗi để gỡ lỗi
await page.screenshot({ path: `error_page_${currentPage}.png` });
// Đổ HTML trang để gỡ lỗi
const html = await page.content();
require('fs').writeFileSync(`error_page_${currentPage}.html`, html);
console.log(`Đã lưu HTML trang lỗi vào error_page_${currentPage}.html`);
}
// Tạm dừng ngắn giữa các trang để thân thiện với máy chủ
await new Promise(r => setTimeout(r, 2000));
}
console.log(`Tổng số đánh giá đã trích xuất: ${allReviews.length}`);
// Lưu tất cả đánh giá vào tệp
require('fs').writeFileSync('g2_reviews.json', JSON.stringify(allReviews, null, 2));
console.log('Đánh giá đã được lưu vào g2_reviews.json');
await browser.close();
console.log('Hoàn tất!');
}
scrapeG2Reviews().catch(console.error);
Chạy kịch bản
Thực thi kịch bản bằng:
Copy
node scrape.js
Định dạng đầu ra JSON
Sau khi chạy kịch bản, bạn sẽ có tệp g2_reviews.json với nội dung trông như thế này:
Copy
[
{
"title": "\"Helped us get a handle on our complicated team-based scheduling and management.\"",
"date": "Feb 11, 2025",
"rating": 5,
"content": "What do you like best about Airtable?\nThe best part about airtable is it's customiizable nature. We worked with a tech specialist to configure Airtable to meet our unique needs and it has so far been adaptable to everything we needed it to do. It has a huge capacity in terms of features and we were able to get it up and running in a fairly short period of time.\n\nWhat do you dislike about Airtable?\nThere are no real downsides except the intial learning curve. I believe we could have built Airtable out as we needed but it would have been a bigger intial time investment. Working with a tech specialist who knew Airtable well really helped us get up and running fast. It was worth the cost."
},
{
"title": "\"Great for organization, has changed our workflow\"",
"date": "Feb 8, 2025",
"rating": 4.5,
"content": "What do you like best about Airtable?\nWhat I like best about Airtable is its flexibility and customizability. It allows us to create databases that perfectly fit our needs, with custom fields, views, and formulas. The ability to link records between tables is incredibly powerful.\n\nWhat do you dislike about Airtable?\nSometimes the learning curve can be steep for new users, especially when dealing with more complex formulas and automations. The pricing can also become quite expensive as your needs grow and you require more records or features."
},
{
"title": "\"Powerful database tool with a spreadsheet interface\"",
"date": "Jan 29, 2025",
"rating": 4,
"content": "What do you like best about Airtable?\nAirtable combines the familiarity of spreadsheets with the power of a database. I appreciate how it allows for different views of the same data - grid, kanban, calendar, etc. It's intuitive enough for non-technical users but powerful enough for complex data management.\n\nWhat do you dislike about Airtable?\nThe free tier is quite limited, and pricing jumps significantly for premium features. Sometimes performance can slow down with large datasets, and there are occasional sync issues when multiple team members are editing simultaneously."
}
]
Tích hợp PowerShell: Sử dụng Scrapeless Scraping Browser từ PowerShell
Nếu bạn thích làm việc với PowerShell, bạn có thể tạo một kịch bản wrapper gọi kịch bản Node.js và xử lý kết quả:
Tạo kịch bản Wrapper PowerShell
Tạo một tệp có tên run-scraper.ps1 với mã sau:
Copy
# Tệp: run-scraper.ps1
Write-Host "Đang bắt đầu thu thập dữ liệu G2.com với Scrapeless Scraping Browser..."
# Tạo thư mục đầu ra
$outputFolder = "G2_Reviews_" + (Get-Date -Format "yyyyMMdd_HHmmss")
New-Item -ItemType Directory -Path $outputFolder -Force | Out-Null
# Chạy kịch bản Node.js và ghi lại đầu ra
$jsonFile = Join-Path $outputFolder "reviews.json"
node scrape.js > $jsonFile
Write-Host "Thu thập dữ liệu Node.js đã hoàn tất. Đang xử lý kết quả..."
# Kiểm tra xem tệp có chứa dữ liệu JSON hợp lệ không
try {
# Đọc nội dung tệp
$content = Get-Content -Path $jsonFile -Raw
# Trích xuất phần JSON (giả sử đó là đầu ra sau tất cả các thông báo console.log)
if ($content -match '\[.*\]') {
$jsonContent = $Matches[0]
Set-Content -Path $jsonFile -Value $jsonContent
# Phân tích JSON thành các đối tượng PowerShell
$reviews = $jsonContent | ConvertFrom-Json
# Xuất sang CSV
$csvPath = Join-Path $outputFolder "g2_reviews.csv"
$reviews | Export-Csv -Path $csvPath -NoTypeInformation -Encoding UTF8
Write-Host "Đã trích xuất thành công $($reviews.Count) đánh giá"
Write-Host "Kết quả đã được lưu vào: $csvPath"
# Phân tích cơ bản
$averageRating = ($reviews | Measure-Object -Property rating -Average).Average
Write-Host "Xếp hạng trung bình: $averageRating trên 5"
$ratingDistribution = $reviews | Group-Object -Property rating | Sort-Object -Property Name
foreach ($ratingGroup in $ratingDistribution) {
Write-Host "$($ratingGroup.Name) sao: $($ratingGroup.Count) đánh giá"
}
} else {
Write-Error "Không thể tìm thấy dữ liệu JSON trong đầu ra"
}
} catch {
Write-Error "Lỗi xử lý dữ liệu JSON: $_"
}
Chạy kịch bản Wrapper PowerShell
Mở PowerShell
Điều hướng đến thư mục dự án của bạn
Thực thi kịch bản:
Copy
.\run-scraper.ps1
Xem xét kết quả
Kịch bản tạo một thư mục có ngày tháng với kết quả JSON và CSV
Thống kê cơ bản được hiển thị trên bảng điều khiển
Tệp CSV có thể được mở trong Excel hoặc các ứng dụng khác để phân tích thêm
Ví dụ nâng cao: Thu thập dữ liệu nhiều trang với Scrapeless Scraping Browser
Đối với trường hợp sử dụng nâng cao hơn, đây là một ví dụ cho thấy cách thu thập dữ liệu đánh giá từ nhiều trang:
Copy
// Tệp: scrape-g2-multipage.js
const puppeteer = require('puppeteer-core');
async function scrapeG2ReviewsMultiPage() {
// Thay thế bằng mã thông báo Scrapeless API thực tế của bạn
const API_TOKEN = 'YOUR_API_TOKEN_HERE';
// Cấu hình kết nối với Scrapeless Scraping Browser
const connectionURL = `wss://browser.scrapeless.com/browser?token=${API_TOKEN}&session_ttl=300&proxy_country=ANY`;
console.log('Đang kết nối với Scrapeless Scraping Browser...');
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Đã kết nối! Đang mở G2.com...');
const page = await browser.newPage();
// Đặt thời gian chờ điều hướng hợp lý
page.setDefaultNavigationTimeout(60000);
// Mảng để lưu trữ tất cả các đánh giá
const allReviews = [];
// Hàm để trích xuất đánh giá từ trang hiện tại
const extractReviews = async () => {
return page.evaluate(() => {
return Array.from(document.querySelectorAll('.paper__bd')).map(review => {
// Tiêu đề
const titleElement = review.querySelector('a.pjax div[itemprop="name"]');
const title = titleElement ? titleElement.innerText : 'Không có tiêu đề';
// Ngày
const dateElement = review.querySelector('time');
const date = dateElement ? dateElement.innerText : 'Không có ngày';
// Xếp hạng
const starsElement = review.querySelector('.stars');
let rating = 0;
if (starsElement) {
const starsClass = starsElement.className;
const match = starsClass.match(/stars-(\d+)/);
if (match) {
rating = parseInt(match[1])/2;
}
}
// Nội dung đánh giá
const contentElements = review.querySelectorAll('.formatted-text');
let content = '';
contentElements.forEach(el => {
const text = el.innerText;
if (!text.includes('Review collected by and hosted on G2.com')) {
content += text + '\n\n';
}
});
return {
title,
date,
rating,
content: content.trim()
};
});
});
};
// Điều hướng đến trang đầu tiên
await page.goto('https://www.g2.com/products/airtable/reviews', {
waitUntil: 'networkidle2'
});
// Chờ đánh giá tải
await page.waitForSelector('.paper__bd', {timeout: 30000});
// Chụp ảnh màn hình trang đầu tiên
await page.screenshot({ path: 'page1.png' });
// Số trang cần thu thập dữ liệu (giới hạn để trình bày)
const pagesToScrape = 3;
let currentPage = 1;
while (currentPage <= pagesToScrape) {
console.log(`Đang thu thập dữ liệu trang ${currentPage}...`);
// Trích xuất đánh giá từ trang hiện tại
const pageReviews = await extractReviews();
console.log(`Đã tìm thấy ${pageReviews.length} đánh giá trên trang ${currentPage}`);
// Thêm vào bộ sưu tập của chúng ta
allReviews.push(...pageReviews);
// Kiểm tra xem có nút trang tiếp theo không
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành.
Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào.
Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba.
Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.