
SDK Scraping không lỗi chính thức ra mắt: Giải pháp toàn diện của bạn cho việc lấy dữ liệu trên web và trình duyệt.
Expert Network Defense Engineer
Chúng tôi rất vui mừng thông báo rằng SDK chính thức của Scrapeless đã được phát hành! 🎉
Đây là cầu nối tuyệt vời giữa bạn và nền tảng Scrapeless mạnh mẽ — giúp việc trích xuất dữ liệu web và tự động hóa trình duyệt trở nên đơn giản hơn bao giờ hết.
Chỉ với vài dòng mã, bạn có thể thực hiện việc thu thập dữ liệu web quy mô lớn và trích xuất dữ liệu SERP, cung cấp hỗ trợ ổn định cho các hệ thống AI Agentic.
SDK Scrapeless cung cấp cho các nhà phát triển một lớp bao bọc chính thức cho tất cả các dịch vụ cốt lõi, bao gồm:
- Trình duyệt thu thập dữ liệu: Một lớp tự động hóa dựa trên Puppeteer và Playwright, hỗ trợ nhấp chuột thật, điền biểu mẫu và các tính năng nâng cao khác.
- API Trình duyệt: Tạo và quản lý phiên trình duyệt, lý tưởng cho các nhu cầu tự động hóa nâng cao.
- API Thu thập dữ liệu: Lấy trang web và trích xuất nội dung ở nhiều định dạng.
- API SERP sâu: Dễ dàng thu thập kết quả tìm kiếm từ Google và nhiều hơn nữa.
- API Thu thập dữ liệu Đa năng: Thu thập dữ liệu web với trình diễn JS, chụp ảnh màn hình, và trích xuất siêu dữ liệu.
- API Proxy: Cấu hình proxy ngay lập tức, bao gồm địa chỉ IP và định vị địa lý.
Dù bạn là kỹ sư dữ liệu, nhà phát triển crawler, hay là một phần của một startup xây dựng sản phẩm dựa trên dữ liệu, SDK Scrapeless giúp bạn thu thập dữ liệu cần thiết nhanh chóng và đáng tin cậy hơn.
Từ tự động hóa trình duyệt đến phân tích kết quả tìm kiếm, từ trích xuất dữ liệu web đến quản lý proxy tự động, SDK Scrapeless tối ưu hóa toàn bộ quy trình thu thập dữ liệu của bạn.
Tài liệu tham khảo sử dụng SDK Scrapeless
Điều kiện tiên quyết
Đăng nhập vào Bảng điều khiển Scrapeless và lấy API Key
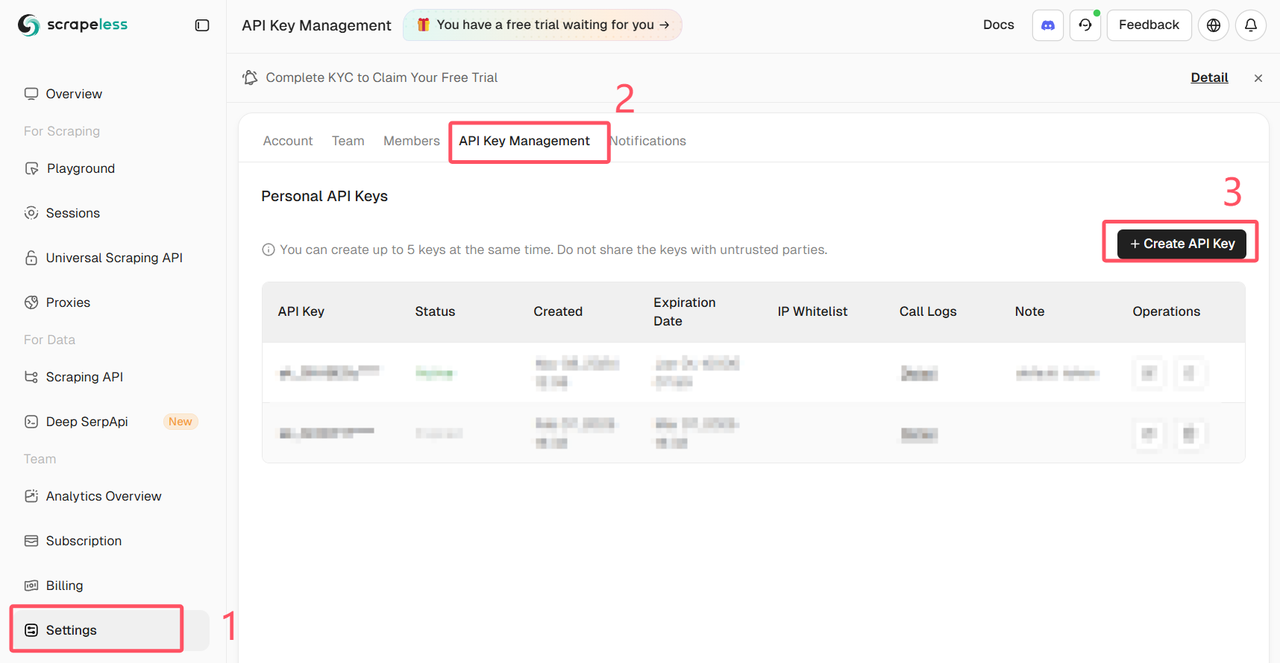
Cài đặt
- npm:
Bash
npm install @scrapeless-ai/sdk- yarn:
Bash
yarn add @scrapeless-ai/sdk- pnpm:
Bash
pnpm add @scrapeless-ai/sdkCấu hình cơ bản
JavaScript
import { Scrapeless } from '@scrapeless-ai/sdk';
// Khởi tạo client
const client = new Scrapeless({
apiKey: 'your-api-key' // Nhận API key của bạn từ https://scrapeless.com
});Biến môi trường
Bạn cũng có thể cấu hình SDK bằng cách sử dụng các biến môi trường:
Bash
# Cần thiết
SCRAPELESS_API_KEY=your-api-key
# Tùy chọn - Các điểm cuối API tùy chỉnh
SCRAPELESS_BASE_API_URL=https://api.scrapeless.com
SCRAPELESS_ACTOR_API_URL=https://actor.scrapeless.com
SCRAPELESS_STORAGE_API_URL=https://storage.scrapeless.com
SCRAPELESS_BROWSER_API_URL=https://browser.scrapeless.com
SCRAPELESS_CRAWL_API_URL=https://crawl.scrapeless.comTrình duyệt thu thập dữ liệu (Lớp bao bọc Tự động hóa Trình duyệt)
Module Trình duyệt thu thập dữ liệu cung cấp một API thống nhất, cấp cao cho tự động hóa trình duyệt, được xây dựng dựa trên API Trình duyệt Scrapeless. Nó hỗ trợ cả Puppeteer và Playwright, và mở rộng đối tượng trang tiêu chuẩn với các phương thức nâng cao như realClick, realFill, và liveURL để tự động hóa gần giống như con người hơn.
Ví dụ Puppeteer:
Python
import { PuppeteerBrowser } from '@scrapeless-ai/sdk';
const browser = await PuppeteerBrowser.connect({
session_name: 'my-session',
session_ttl: 180,
proxy_country: 'US'
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.realClick('#login-btn');
await page.realFill('#username', 'myuser');
const urlInfo = await page.liveURL();
console.log('URL trang hiện tại:', urlInfo.liveURL);
await browser.close();Ví dụ Playwright:
Python
import { PlaywrightBrowser } from '@scrapeless-ai/sdk';
const browser = await PlaywrightBrowser.connect({
session_name: 'my-session',
session_ttl: 180,
proxy_country: 'US'
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.realClick('#login-btn');
await page.realFill('#username', 'myuser');
const urlInfo = await page.liveURL();
console.log('URL trang hiện tại:', urlInfo.liveURL);
await browser.close();👉 Truy cập tài liệu của chúng tôi để biết thêm nhiều trường hợp sử dụng
👉 Tích hợp một lần nhấp qua GitHub
Ví dụ thực hành: Thu thập kết quả tìm kiếm “Air Max” trên Nike.com
Giả sử bạn đang xây dựng một hệ thống backend cho nền tảng so sánh giày và cần lấy kết quả tìm kiếm cho “Air Max” từ trang web chính thức của Nike trong thời gian thực. Thông thường, bạn sẽ phải triển khai Puppeteer, xử lý proxy, né tránh các khối, phân tích cấu trúc trang... mất thời gian và dễ mắc lỗi.
Giờ đây, với SDK Scrapeless, toàn bộ quy trình chỉ mất vài dòng mã:
Bước 1. Cài đặt SDK
Sử dụng trình quản lý gói ưa thích của bạn:
Python
npm install @scrapeless-ai/sdkBước 2. Khởi tạo Client
TypeScript
import { Scrapeless } from '@scrapeless-ai/sdk';
const client = new Scrapeless({
apiKey: 'your-api-key' // Nhận API key của bạn từ https://scrapeless.com
});Bước 3. Cạo SERP Một Nhấp
TypeScript
const results = await client.deepserp.scrape({
actor: 'scraper.google.search',
input: {
q: 'Air Max site:www.nike.com'
}
});
console.log(results);Bạn không cần phải lo lắng về proxy, cơ chế chống bot, mô phỏng trình duyệt hay xoay vòng IP — Scrapeless đã xử lý tất cả những điều đó ở phía sau.
Ví Dụ Kết Quả
JSON
{
inline_images: [
{
position: 1,
thumbnail: 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQtHPNOwXmvXfYfaT_4UqM1IvNBqZDZe7rScA&s',
related_content_id: 'N2x0F2OpsGqRuM,xzJA7z__Ip2bvM',
related_content_link: 'https://www.google.com/search/about-this-image?img=H4sIAAAAAAAA_wEXAOj_ChUIx-WA-v7nv5GdARC32NG7sayq2GoyjCpjFwAAAA%3D%3D&q=https://www.nike.com/t/air-max-1-mens-shoes-2C5sX2&ctx=iv&hl=en-US',
source: 'Nike',
source_logo: '',
title: "Giày Nike Air Max 1 cho Nam",
link: 'https://www.nike.com/t/air-max-1-mens-shoes-2C5sX2',
original: 'https://static.nike.com/a/images/t_PDP_936_v1/f_auto,q_auto:eco/c5ff2a6b-579f-4271-85ea-0cd5131691fa/NIKE+AIR+MAX+1.png',
original_width: 936,
original_height: 1170,
in_stock: false,
is_product: false
},
....
}Bạn có thể lưu trữ những kết quả này trong cơ sở dữ liệu của mình hoặc sử dụng chúng trực tiếp cho hiển thị và phân tích xếp hạng.
Cài Đặt SDK Scrapeless Ngay
SDK Node.js của Scrapeless giúp việc cạo dữ liệu web và tự động hóa trình duyệt dễ dàng hơn bao giờ hết. Dù bạn đang xây dựng một công cụ giám sát giá, một hệ thống phân tích SERP, hay mô phỏng hành vi người dùng thực — một dòng mã kết nối bạn với hạ tầng mạnh mẽ của Scrapeless.
SDK Scrapeless là mã nguồn mở theo giấy phép MIT. Các lập trình viên được chào đón để đóng góp mã, báo cáo vấn đề, hoặc tham gia cộng đồng Discord của chúng tôi để có thêm nhiều ý tưởng!
✅ Có Phiên Bản Dùng Thử Miễn Phí
🔗 Đọc Tài Liệu
💬 Có câu hỏi? Tham gia Cộng Đồng Discord của Chúng Tôi
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


