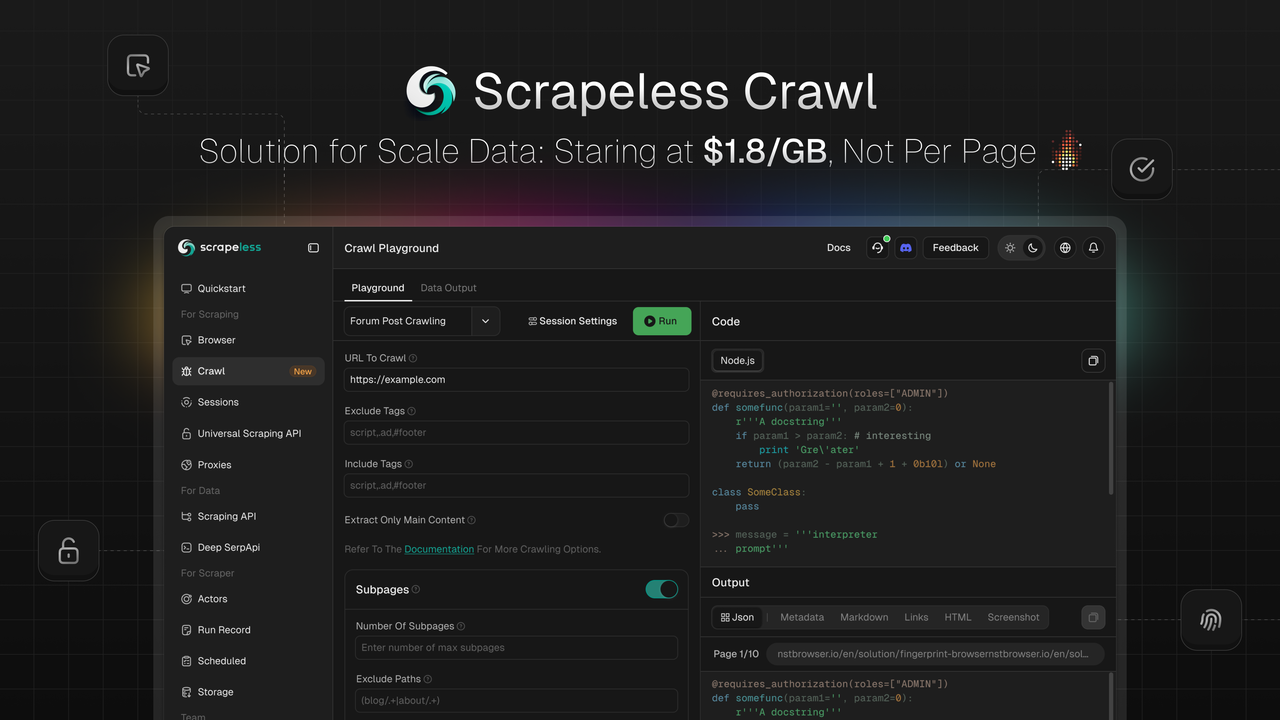
Scrapeless Crawl là gì và nó hoạt động như thế nào?
Senior Web Scraping Engineer
Scrapeless rất vui mừng ra mắt Crawl, tính năng được xây dựng đặc biệt cho việc thu thập và xử lý dữ liệu quy mô lớn. Crawl nổi bật với những ưu điểm cốt lõi như thu thập dữ liệu đệ quy thông minh, khả năng xử lý dữ liệu hàng loạt, và đầu ra đa định dạng linh hoạt, giúp các doanh nghiệp và nhà phát triển thu thập và xử lý dữ liệu web khổng lồ một cách nhanh chóng—cung cấp nhiên liệu cho các ứng dụng trong đào tạo AI, phân tích thị trường, ra quyết định kinh doanh và nhiều hơn nữa.
💡Sắp Ra Mắt: Trích xuất và tóm tắt dữ liệu qua AI LLM Gateway, với việc tích hợp liền mạch cho các framework mã nguồn mở và tích hợp quy trình trực quan—giải quyết những thách thức về nội dung web cho các nhà phát triển AI.
Crawl là gì
Crawl không chỉ là một công cụ thu thập dữ liệu đơn giản mà còn là một nền tảng toàn diện tích hợp cả chức năng thu thập và lướt web.
-
Lướt Dữ Liệu Hàng Loạt: Hỗ trợ lướt web với quy mô lớn trên một trang đơn và lướt đệ quy.
-
Giao Hàng Đa Định Dạng: Tương thích với các định dạng JSON, Markdown, Metadata, HTML, Liên kết, và Ảnh chụp màn hình.
-
Thu Thập Dữ Liệu Chống Phát Hiện: Lõi Chromium phát triển độc lập của chúng tôi cho phép tùy chỉnh cao, quản lý phiên, và khả năng chống phát hiện, như cấu hình dấu vân tay, giải mã CAPTCHA, chế độ ẩn danh, và tùy chỉnh proxy để vượt qua các rào cản trang web.
-
Lõi Chromium Tự Phát Triển: Sử dụng lõi Chromium của chúng tôi, cho phép tùy chỉnh cao, quản lý phiên, và tự động giải CAPTCHA.
1. Giải CAPTCHA Tự Động: Tự động xử lý các loại CAPTCHA phổ biến, bao gồm reCAPTCHA v2 và Cloudflare Turnstile/Challenge.
2. Ghi Lại và Phát Lại Phiên: Chức năng phát lại phiên giúp bạn dễ dàng kiểm tra các hành động và yêu cầu qua bản ghi phát lại, xem xét chúng từng bước để nhanh chóng hiểu quy trình nhằm giải quyết vấn đề và cải thiện quy trình.
3. Lợi Thế Đối Tính: Không giống như các trình thu thập dữ liệu khác có giới hạn đối tính nghiêm ngặt, kế hoạch cơ bản của Crawl hỗ trợ 50 phiên đồng thời, với phiên đồng thời không giới hạn trong kế hoạch cao cấp.
4. Tiết Kiệm Chi Phí: Vượt trội hơn đối thủ trên các trang web có các biện pháp chống thu thập dữ liệu, nó mang lại những lợi thế đáng kể trong việc giải quyết CAPTCHA miễn phí — dự kiến tiết kiệm 70% chi phí.
Tận dụng khả năng thu thập và xử lý dữ liệu tiên tiến, Crawl đảm bảo việc cung cấp dữ liệu tìm kiếm theo thời gian thực có cấu trúc. Điều này giúp các doanh nghiệp và nhà phát triển luôn đi trước các xu hướng thị trường, tối ưu hóa các quy trình tự động dựa trên dữ liệu, và nhanh chóng điều chỉnh chiến lược thị trường.
Giải Quyết Các Thách Thức Dữ Liệu Phức Tạp Với Crawl: Nhanh Hơn, Thông Minh Hơn và Hiệu Quả Hơn
Đối với các nhà phát triển và doanh nghiệp cần dữ liệu web đáng tin cậy theo quy mô, Crawl cũng cung cấp:
✔ Thu Thập Dữ Liệu Tốc Độ Cao – Lấy dữ liệu từ nhiều trang web chỉ trong vài giây
✔ Tích Hợp Liền Mạch – Sẽ sớm tích hợp với các framework mã nguồn mở và tích hợp quy trình trực quan, như Langchain, N8n, Clay, Pipedream, Make, v.v.
✔ Proxy Nhắm Đích Địa Lý – Hỗ trợ Proxy tích hợp sẵn cho 195 quốc gia
✔ Quản Lý Phiên – Quản lý phiên thông minh và xem các phiên LiveURL theo thời gian thực
Cách Sử Dụng Crawl
API Crawl đơn giản hóa việc thu thập dữ liệu bằng cách lấy nội dung cụ thể từ các trang web trong một cuộc gọi duy nhất hoặc lướt toàn bộ trang và các liên kết của nó để thu thập tất cả dữ liệu có sẵn, hỗ trợ trong nhiều định dạng.
Scrapeless cung cấp các điểm cuối để khởi tạo các yêu cầu thu thập dữ liệu và kiểm tra trạng thái/kết quả của chúng. Theo mặc định, việc thu thập dữ liệu là bất đồng bộ: bạn bắt đầu một công việc trước, sau đó theo dõi trạng thái của nó cho đến khi hoàn thành. Tuy nhiên, các SDK của chúng tôi bao gồm một chức năng đơn giản xử lý toàn bộ quy trình và trả về dữ liệu khi công việc kết thúc.
Cài Đặt
Cài đặt SDK Scrapeless bằng NPM:
Bash
npm install @scrapeless-ai/sdkCài đặt SDK Scrapeless bằng PNPM:
Bash
pnpm add @scrapeless-ai/sdkCrawl Một Trang
Lấy dữ liệu cụ thể (ví dụ: chi tiết sản phẩm, đánh giá) từ các trang web trong một cuộc gọi.
Cách Sử Dụng
JavaScript
import { Scrapeless } from "@scrapeless-ai/sdk";
// Khởi tạo client
const client = new Scrapeless({
apiKey: "your-api-key", // Lấy API key của bạn từ https://scrapeless.com
});
(async () => {
const result = await client.scrapingCrawl.scrape.scrapeUrl(
"https://example.com"
);
console.log(result);
})();Cấu Hình Trình Duyệt
Bạn có thể tùy chỉnh các cài đặt phiên cho việc thu thập dữ liệu, chẳng hạn như sử dụng proxy, giống như tạo một phiên trình duyệt mới.
Scrapeless tự động xử lý các CAPTCHA thông thường, bao gồm reCAPTCHA v2 và Cloudflare Turnstile/Challenge—không cần thiết lập thêm, để biết thêm chi tiết, xem giải quyết CAPTCHA.
Để khám phá tất cả các tham số của trình duyệt, hãy kiểm tra Tài liệu API hoặc Tham số Trình duyệt.
JavaScript
import { Scrapeless } from "@scrapeless-ai/sdk";
// Khởi tạo client
const client = new Scrapeless({
apiKey: "your-api-key", // Lấy API key của bạn từ https://scrapeless.com
});
(async () => {
const result = await client.scrapingCrawl.scrapeUrl(
"https://example.com",
{
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();Cấu hình Scrape
Các tham số tùy chọn cho công việc scrape bao gồm định dạng đầu ra, lọc để chỉ trả về nội dung của trang chính, và thiết lập thời gian tối đa cho việc điều hướng trang.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Khởi tạo client
const client = new ScrapingCrawl({
apiKey: "your-api-key", // Lấy API key của bạn từ https://scrapeless.com
});
(async () => {
const result = await client.scrapeUrl(
"https://example.com",
{
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
}
);
console.log(result);
})();Để tham khảo đầy đủ về điểm cuối scrape, hãy xem Tài liệu API
Scrape Theo Lô
Scrape theo lô hoạt động giống như scrape thông thường, ngoại trừ việc thay vì một URL đơn, bạn có thể cung cấp một danh sách các URL để scrape cùng một lúc.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Khởi tạo client
const client = new ScrapingCrawl({
apiKey: "your-api-key", // Lấy API key của bạn từ https://scrapeless.com
});
(async () => {
const result = await client.batchScrapeUrls(
["https://example.com", "https://scrapeless.com"],
{
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();Thuật Cú Crawl
API Crawl hỗ trợ đối tượng crawl định kỳ một trang web và các liên kết của nó để trích xuất tất cả dữ liệu có sẵn.
Để biết cách sử dụng chi tiết, hãy xem Tài liệu API Crawl.
Cách Sử Dụng
Sử dụng crawl định kỳ để khám phá toàn bộ miền và các liên kết của nó, trích xuất mỗi mảnh dữ liệu có thể truy cập.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Khởi tạo client
const client = new ScrapingCrawl({
apiKey: "your-api-key", // Lấy API key của bạn từ https://scrapeless.com
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
scrapeOptions: {
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
},
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();Phản Hồi
JavaScript
{
"success": true,
"status": "completed",
"completed": 2,
"total": 2,
"data": [
{
"url": "https://example.com",
"metadata": {
"title": "Trang Ví dụ",
"description": "Một trang web mẫu"
},
"markdown": "# Trang Ví dụ\nNội dung này...",
...
},
...
]
}Mỗi trang được crawl có trạng thái riêng của nó là completed hoặc failed và có thể có trường lỗi riêng, vì vậy hãy cẩn thận với điều đó.
Để xem toàn bộ lược đồ, hãy xem Tài liệu API.
Cấu Hình Trình Duyệt
Tùy chỉnh cấu hình phiên cho các công việc scrape theo cùng một quy trình như việc tạo một phiên trình duyệt mới. Các tùy chọn có sẵn bao gồm cấu hình proxy. Để xem tất cả các tham số phiên được hỗ trợ, hãy tham khảo Tài liệu API hoặc Tham số Trình duyệt.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Khởi tạo client
const client = new ScrapingCrawl({
apiKey: "your-api-key", // Lấy API key của bạn từ https://scrapeless.com
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();Cấu Hình Lấy Dữ Liệu
Các tham số có thể bao gồm định dạng đầu ra, bộ lọc để chỉ trả về nội dung trang chính, và cài đặt thời gian chờ tối đa cho việc điều hướng trang.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Khởi tạo khách hàng
const client = new ScrapingCrawl({
apiKey: "your-api-key", // Lấy khóa API của bạn từ https://scrapeless.com
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
scrapeOptions: {
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
}
}
);
console.log(result);
})();Để tham khảo đầy đủ về điểm cuối crawl, hãy xem Tài liệu API.
Khám Phá Các Trường Hợp Sử Dụng Đa Dạng của Crawling
Một sân chơi tích hợp sẵn có cho các nhà phát triển để kiểm tra và gỡ lỗi mã của họ, và bạn có thể sử dụng Crawl cho bất kỳ nhu cầu lấy dữ liệu nào, chẳng hạn như:
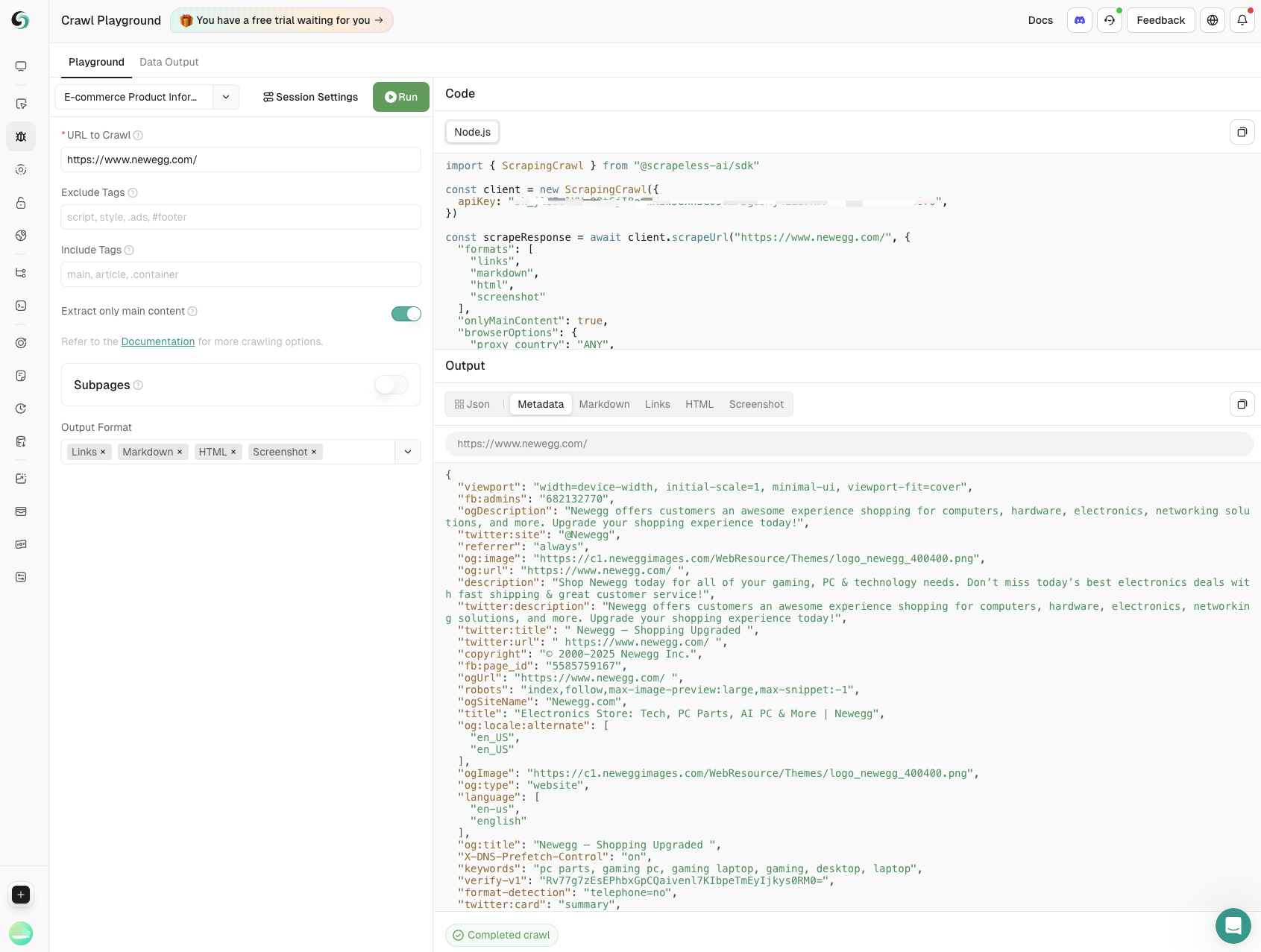
- Lấy Thông Tin Sản Phẩm
Dữ liệu chính bao gồm tên sản phẩm, giá cả, đánh giá của người dùng và số lượng đánh giá được trích xuất bằng cách lấy dữ liệu trên các trang web thương mại điện tử. Hoàn toàn hỗ trợ theo dõi sản phẩm và giúp doanh nghiệp đưa ra quyết định thông minh.
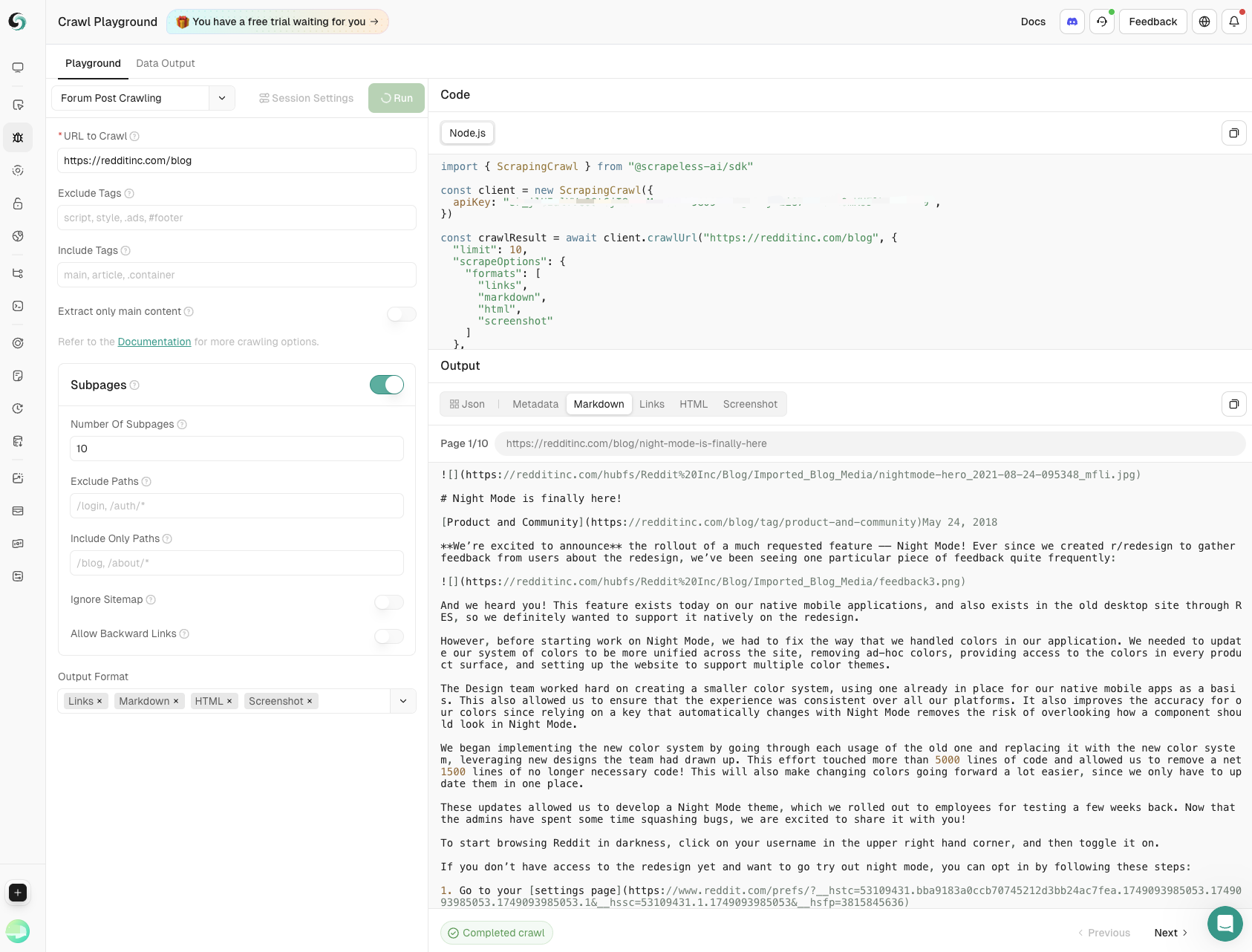
- Lấy Dữ Liệu Bài Đăng Diễn Đàn
Nắm bắt nội dung bài đăng chính và các bình luận phụ với khả năng kiểm soát chính xác về độ sâu và độ rộng, đảm bảo những hiểu biết toàn diện từ các cuộc thảo luận trong cộng đồng.
Thưởng Thức Crawl và Scrape Ngay!
Tiết Kiệm Chi Phí và Phù Hợp với mọi nhu cầu: Bắt đầu từ $1.8/GB, Không phải theo trang
Vượt trội hơn các đối thủ với trình lấy dữ liệu dựa trên Chromium của chúng tôi với mô hình giá kết hợp giữa khối lượng proxy và tỷ lệ theo giờ, mang lại mức tiết kiệm chi phí lên đến 70% cho các dự án dữ liệu quy mô lớn so với các mô hình tính theo số trang.
Đăng Ký Thử Nghiệm Ngay và Nhận Bộ Công Cụ Web Mạnh Mẽ.
💡Đối với người dùng có khối lượng lớn, hãy liên hệ với chúng tôi để có giá tùy chỉnh – mức giá cạnh tranh được điều chỉnh theo nhu cầu của bạn.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


