Trình duyệt Cloud không bị rác trong hành động: Điều chỉnh Puppeteer để tự động hóa, quản lý dấu vân tay và CAPTCHA.
Expert Network Defense Engineer
Trong tự động hóa web và các tình huống thu thập dữ liệu, các nhà phát triển thường phải đối mặt với ba thách thức kỹ thuật chính:
- Cách Ly Môi Trường:
Khi chạy hàng chục hoặc thậm chí hàng trăm phiên trình duyệt độc lập đồng thời, các giải pháp triển khai địa phương truyền thống gặp tiêu thụ tài nguyên cao, quản lý phức tạp và cấu hình rườm rà.
- Rủi Ro Phát Hiện Dấu Vân Tay:
Việc truy cập lặp đi lặp lại bằng cùng một dấu vân tay trình duyệt có thể dễ dàng kích hoạt các cơ chế phát hiện bot và dấu vân tay trên các trang web mục tiêu.
- Gián Đoạn CAPTCHA:
Khi được kích hoạt, các xác minh như reCAPTCHA hoặc Cloudflare Turnstile sẽ làm gián đoạn các kịch bản tự động hóa. Việc tích hợp các dịch vụ giải CAPTCHA bên thứ ba không chỉ tăng chi phí phát triển và độ phức tạp, mà còn giảm hiệu suất thực thi.
Những vấn đề này thường yêu cầu các nhà phát triển dành nhiều thời gian để thiết lập môi trường địa phương hoặc tích hợp dịch vụ bên ngoài, làm tăng cả chi phí thời gian và vận hành.
Cốt lõi, điều cần thiết là một công cụ có khả năng:
- Môi Trường Cách Ly Khối Lượng:
Tạo các hồ sơ trình duyệt độc lập thông qua API, với mỗi hồ sơ đại diện cho một phiên trình duyệt hoàn toàn cách ly.
- Ngẫu Nhiên Hóa Dấu Vân Tay Tự Động:
Ngẫu nhiên hóa các tham số chính như User-Agent, múi giờ, ngôn ngữ và độ phân giải màn hình—tất cả trong khi vẫn duy trì tính đồng nhất đầy đủ với các môi trường trình duyệt thực tế.
- Xử Lý CAPTCHA Tích Hợp:
Tự động nhận diện và giải quyết các thử thách CAPTCHA phổ biến mà không cần can thiệp của con người hoặc tích hợp bên thứ ba.
Vậy còn các trình duyệt dấu vân tay thì sao?
Trong tự động hóa doanh nghiệp trong nước, các trình duyệt dấu vân tay triển khai tại chỗ được sử dụng rộng rãi. Tuy nhiên, chúng thường tiêu tốn nhiều tài nguyên hệ thống, khó duy trì đồng nhất qua các phiên, và vẫn yêu cầu các dịch vụ CAPTCHA bên thứ ba để xử lý xác minh.
Ngược lại, các trình duyệt không đầu dựa trên đám mây hiện đại như Scrapeless.com cung cấp một giải pháp thay thế hiệu quả và có thể mở rộng hơn. Chúng cho phép các nhà phát triển:
- Tạo các hồ sơ trình duyệt cách ly thông qua API,
- Ngẫu nhiên hóa dấu vân tay một cách tự nhiên, và
- Tự động xử lý các thử thách CAPTCHA,
tất cả đều trong đám mây—giảm đáng kể chi phí phát triển và bảo trì trong khi hỗ trợ các tải công việc đồng thời cao.
Trong các phần tiếp theo, chúng ta sẽ khám phá một số kịch bản chuẩn để đánh giá cách mà các trình duyệt không đầu dựa trên đám mây hoạt động về mặt cách ly dấu vân tay, đồng thời, và xử lý CAPTCHA.
⚠️ Tuyên bố từ chối trách nhiệm:
Khi sử dụng bất kỳ giải pháp tự động hóa trình duyệt nào, hãy luôn tuân thủ Điều khoản Dịch vụ của trang web mục tiêu, quy tắc robots.txt, và các luật và quy định liên quan.
Việc thu thập dữ liệu cho mục đích trái phép hoặc bất hợp pháp, hoặc xâm phạm quyền lợi của người khác, là nghiêm cấm.
Chúng tôi không chịu trách nhiệm cho bất kỳ hậu quả pháp lý hoặc tổn thất nào phát sinh từ việc lạm dụng.
Thiết lập Môi Trường
Đầu tiên, cài đặt SDK Node của Scrapeless. Nếu bạn chưa có Node, hãy cài đặt Node trước.
bash
npm install @scrapeless-ai/sdk puppeteer-coreKiểm tra kết nối cơ bản
js
// thiết lập khóa API của bạn
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer } from "@scrapeless-ai/sdk";
const browser = await Puppeteer.connect({
sessionName: "sdk_test",
sessionTTL: 180,
proxyCountry: "ANY",
sessionRecording: true,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto("https://www.scrapeless.com");
console.log(await page.title());
await browser.close();Nếu tiêu đề trang được in ra, môi trường đã được cấu hình thành công.
Sẵn sàng để tăng tốc độ tự động hóa web của bạn? Hãy thử Scrapeless Cloud Browser hôm nay và trải nghiệm quản lý hồ sơ liền mạch, dấu vân tay độc lập, và xử lý CAPTCHA tự động—tất cả trong đám mây!
Trường hợp 1: Xác minh dấu vân tay trình duyệt ngẫu nhiên
Mục tiêu: Xác minh rằng dấu vân tay trình duyệt được tạo ra bởi mỗi hồ sơ thực sự độc lập.
Ví dụ này:
- Tạo nhiều hồ sơ độc lập
- Truy cập trang web kiểm tra dấu vân tay: https://xfreetool.com/zh/fingerprint-checker
- Trích xuất và so sánh ID dấu vân tay trình duyệt của mỗi hồ sơ
- Xác nhận tính độc lập và ngẫu nhiên của dấu vân tay
Trang web https://xfreetool.com/zh/fingerprint-checker là một trang web kiểm tra dấu vân tay trình duyệt và tự động thu thập thông tin dấu vân tay từ trình duyệt truy cập.
Ví dụ Mã:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from "@scrapeless-ai/sdk";
// Các hằng số cấu hình
const MAX_PROFILES = 3; // Số lượng hồ sơ tối đa cần thiết
// Khởi tạo client
const client = new ScrapelessClient();
vi
* Lấy ID dấu vân tay trình duyệt từ trang CreepJS
* @param {Object} page - Đối tượng trang Puppeteer
* @returns {Promise<string>} ID dấu vân tay trình duyệt
*/
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector(
'#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div'
);
return fpContainer.textContent;
});
};
/**
* Thực hiện một tác vụ
* @param {string} profileId - ID hồ sơ
* @param {number} taskId - ID tác vụ
* @returns {Promise<string>} ID dấu vân tay trình duyệt
*/
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'Trình duyệt của tôi',
sessionTTL: 45000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});
try {
const page = await browser.newPage();
page.setDefaultTimeout(45000);
await page.goto('https://xfreetool.com/zh/fingerprint-checker', {
waitUntil: 'networkidle0'
});
// Lấy và in thông tin cookie
const cookies = await page.cookies();
console.log(`[${taskId}] Cookies:`);
cookies.forEach(cookie => {
// console.log(` Tên: ${cookie.name}, Giá trị: ${cookie.value}, Miền: ${cookie.domain}`);
});
const fpId = await getFPId(page);
console.log(`[${taskId}] ✓ ID dấu vân tay trình duyệt = ${fpId}`);
return fpId;
} finally {
await browser.close();
}
};
/**
* Tạo một hồ sơ mới
* @returns {Promise<string>} ID hồ sơ mới được tạo
*/
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('Hồ sơ của tôi' + randomString());
console.log('Hồ sơ đã được tạo:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('Tạo hồ sơ thất bại:', error);
throw error;
}
};
/**
* Lấy hoặc tạo danh sách hồ sơ cần thiết
* @param {number} count - Số lượng hồ sơ cần thiết
* @returns {Promise<string[]>} Danh sách ID Hồ sơ
*/
const getProfiles = async (count) => {
try {
// Lấy các hồ sơ hiện có
const response = await client.profiles.list({
page: 1,
pageSize: count
});
const profiles = response?.docs || [];
// Tạo hồ sơ mới nếu hồ sơ hiện có không đủ
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate)
.fill(0)
.map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [
...profiles.map(p => p.profileId),
...newProfiles
];
}
// Trả về `count` hồ sơ đầu tiên nếu có đủ
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('Lấy hồ sơ thất bại:', error);
throw error;
}
};
/**
* Thực hiện các tác vụ đồng thời
*/
const runTasks = async () => {
try {
// Lấy hoặc tạo các hồ sơ cần thiết
const profileIds = await getProfiles(MAX_PROFILES);
// Tạo tác vụ cho mỗi hồ sơ
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
await Promise.all(tasks);
console.log('Tất cả các tác vụ đã hoàn thành thành công');
} catch (error) {
console.error('Lỗi khi thực hiện các tác vụ:', error);
}
};
// Thực hiện các tác vụ
await runTasks();Kết Quả Kiểm Tra:
- 3 hồ sơ được chạy đồng thời, mỗi môi trường hoàn toàn độc lập.
- ID dấu vân tay trình duyệt cho mỗi hồ sơ hoàn toàn khác nhau.
Giải Thích Kết Quả:
-
Độ Độc Nhất Của Dấu Vân Tay
3 hồ sơ trả về các ID dấu vân tay khác nhau. Mỗi lần tạo hồ sơ, dấu vân tay trình duyệt được tạo ngẫu nhiên, tránh việc bị phát hiện do có dấu vân tay trùng lặp.
-
Xác Minh Tính Độc Lập Của Môi Trường
Cookie cho mỗi hồ sơ hoàn toàn độc lập:- Cookies từ Hồ sơ 1 không xuất hiện trong Hồ sơ 2 hay 3
- Nhiều hồ sơ có thể đăng nhập vào các tài khoản khác nhau cùng một lúc mà không ảnh hưởng đến nhau
Trường Hợp 2: Kiểm Tra Tính Độc Lập Của Môi Trường Và Tính Năng Đồng Thời Cao
Mục Tiêu: Xác minh tính độc lập của các hồ sơ trong các kịch bản đồng thời cao, và kiểm tra khả năng tạo nhóm và quản lý hồ sơ.
Trong nhiều trường hợp, để tăng tốc độ thu thập dữ liệu hoặc đăng nhập vào nhiều tài khoản, các công cụ cần hỗ trợ tính đồng thời cao và cách ly môi trường—tương đương với việc có hàng chục hoặc hàng trăm phiên trình duyệt độc lập cùng lúc. Scrapeless hỗ trợ thêm hồ sơ bằng tay hoặc điều khiển hồ sơ qua API.
Ví dụ này:
- Tạo 10 hồ sơ độc lập qua API
- Mỗi hồ sơ đầu tiên truy cập https://abrahamjuliot.github.io/creepjs/ để lấy ID dấu vân tay của trình duyệt
- Sau đó truy cập https://minecraftpocket-servers.com/login/ và chụp ảnh màn hình
- Xác minh tính độc lập của dấu vân tay và cách ly môi trường
Mã ví dụ:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from '@scrapeless-ai/sdk';
// Các hằng số cấu hình
const MAX_PROFILES = 5; // Số lượng hồ sơ tối đa cần thiết
// Khởi tạo client
const client = new ScrapelessClient({});
/**
* Lấy ID dấu vân tay của trình duyệt từ trang CreepJS
* @param {Object} page - Đối tượng trang Puppeteer
* @returns {Promise<string>} ID dấu vân tay của trình duyệt
*/
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector(
'#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div'
);
return fpContainer.textContent;
});
};
/**
* Chạy một tác vụ đơn lẻ
* @param {string} profileId - ID hồ sơ
* @param {number} taskId - ID tác vụ
* @returns {Promise<string>} ID dấu vân tay của trình duyệt
*/
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'My Browser',
sessionTTL: 30000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});
try {
// Bước 1: Lấy dấu vân tay của trình duyệt
let page = await browser.newPage();
page.setDefaultTimeout(30000);
await page.goto('https://abrahamjuliot.github.io/creepjs/', {
waitUntil: 'networkidle0'
});
const fpId = await getFPId(page);
await page.close(); // Đóng trang đầu tiên
// Bước 2: Sử dụng một trang mới để chụp ảnh màn hình
page = await browser.newPage();
const screenshotPath = `fp_${taskId}_${fpId}.png`;
await page.goto('https://minecraftpocket-servers.com/login/', {
waitUntil: 'networkidle0'
});
await page.screenshot({
fullPage: true,
path: screenshotPath
});
console.log(`[${taskId}] ✓ ID dấu vân tay: ${fpId}, Ảnh chụp đã lưu tại: ${screenshotPath}`);
return fpId;
} finally {
await browser.close();
}
};
/**
* Tạo một hồ sơ mới
* @returns {Promise<string>} ID hồ sơ mới được tạo
*/
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('My Profile' + randomString());
console.log('Hồ sơ được tạo:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('Tạo hồ sơ không thành công:', error);
throw error;
}
};
/**
* Lấy hoặc tạo danh sách hồ sơ cần thiết
* @param {number} count - Số lượng hồ sơ cần
* @returns {Promise<string[]>} Danh sách ID Hồ sơ
*/
const getProfiles = async (count) => {
try {
const response = await client.profiles.list({
page: 1,
pageSize: count
});
const profiles = response?.docs || [];
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate)
.fill(0)
.map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [
...profiles.map(p => p.profileId),
...newProfiles
];
}
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('Lấy hồ sơ không thành công:', error);
throw error;
}
};
/**
* Chạy các tác vụ đồng thời
*/
const runTasks = async () => {
try {
console.log(`Bắt đầu chạy các tác vụ, cần ${MAX_PROFILES} hồ sơ`);
const profileIds = await getProfiles(MAX_PROFILES);
console.log(`Đã nhận ${profileIds.length} hồ sơ`);
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
const results = await Promise.all(tasks);
console.log('Tất cả các tác vụ đã hoàn thành thành công!');
console.log('Danh sách ID dấu vân tay:', results);
} catch (error) {
```javascript
console.error('Lỗi khi chạy tác vụ:', error);
}
};
// Thực hiện các tác vụ
await runTasks();Kết Quả Kiểm Tra:
- Độc lập Vân Tay: Vân tay và các tham số môi trường được tạo một cách ngẫu nhiên và hoàn toàn khác biệt.
- Cách Ly Môi Trường: Mỗi tác vụ chạy trong một hồ sơ độc lập; dữ liệu trình duyệt (Cookie, LocalStorage, Session, v.v.) không được chia sẻ.
- Stability Tính Đối Kháng: 10 hồ sơ được tạo và thực hiện đồng thời thành công.
Giải Thích Kết Quả Ví Dụ:
- Quá Trình Tạo Hồ Sơ & Kết Nối
Đầu ra cho thấy toàn bộ quy trình tạo hồ sơ và kết nối trình duyệt:
Hồ sơ được tạo: a27cd6f9-7937-4af0-a0fc-51b2d5c70308
Hồ sơ được tạo: d92b0cb1-5608-4753-92b0-b7125fb18775
...
info Puppeteer: Kết nối thành công với trình duyệt Scrapeless {}
...
Tất cả các tác vụ hoàn thành thành côngTất cả 10 hồ sơ được tạo và kết nối vào Scrapeless Cloud Browser gần như đồng thời, chứng minh tính ổn định trong điều kiện đồng thời cao.
-
Xác Minh Độc Lập Vân Tay
Mỗi hồ sơ trả về một ID vân tay hoàn toàn khác biệt.10 vân tay độc nhất chứng minh rằng vân tay trình duyệt của mỗi hồ sơ được tạo ra độc lập và ngẫu nhiên, không có bản sao.
-
Tính Ổn Định Khi Thực Hiện Đồng Thời Cao
Tất cả 10 tác vụ chạy đồng thời, hoàn thành thành công mà không có lỗi hoặc xung đột. -
Nhiều Cách Tạo Hồ Sơ
Scrapeless cung cấp nhiều cách để tạo và quản lý hồ sơ:
- Tạo Thủ Công Qua Bảng Điều Khiển: Tạo hồ sơ trực tiếp từ Bảng Điều Khiển để bắt đầu nhanh và thực hiện các tác vụ riêng lẻ.
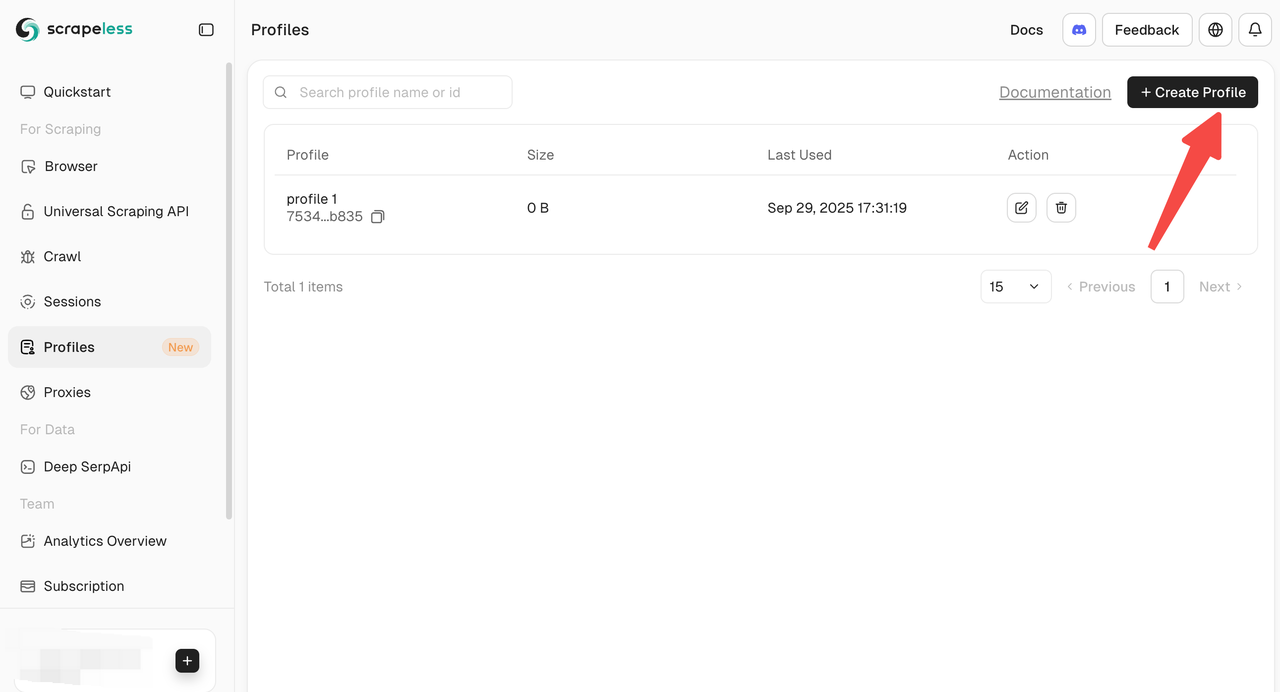
- Tạo Qua API: Tạo hồ sơ một cách lập trình thông qua API Tạo Hồ Sơ cho các tác vụ theo lô.
- Tạo Qua SDK: Sử dụng SDK chính thức để tạo hồ sơ, lý tưởng cho điều kiện đồng thời cao hoặc quy trình tự động tùy chỉnh.
Trường Hợp 3: Thử Thách Cloudflare + Google reCAPTCHA – Bypass CAPTCHA Hoàn Toàn Tự Động mà Không Cần Can Thiệp Thủ Công
Mục Tiêu: Kiểm tra xem Scrapeless Cloud Browser có thể tự động phát hiện và vượt qua reCAPTCHA hoặc các thử thách Cloudflare khi truy cập các trang web và ghi lại quy trình xác minh có thể tái tạo và kết quả hay không.
Ví dụ này:
- Truy cập trang tìm kiếm Amazon https://www.amazon.com/s?k=toy (có xác suất cao kích hoạt reCAPTCHA)
- Tự động xử lý CAPTCHA và trích xuất dữ liệu sản phẩm
- Xác minh khả năng xử lý CAPTCHA tự động
Ví Dụ Mã:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from '@scrapeless-ai/sdk';
const client = new ScrapelessClient();
const MAX_PROFILES = 1; // Số lượng hồ sơ tối đa cần thiết
// Lấy ID vân tay trình duyệt từ trang CreepJS
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector('#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div');
return fpContainer.textContent;
});
};
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'Trình Duyệt Của Tôi',
sessionTTL: 45000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});
try {
let page = await browser.newPage();
page.setDefaultTimeout(45000);
await page.goto('https://www.amazon.com/s?k=toy&crid=37T7KZIWF16VC&sprefix=to%2Caps%2C351&ref=nb_sb_noss_2');
await page.waitForSelector('[role="listitem"]', { timeout: 15000 });
console.log('Trang đã tải thành công...');
const products = await page.evaluate(() => {
const items = [];
const productElements = document.querySelectorAll('[role="listitem"]');
productElements.forEach((product) => {
const titleElement = product.querySelector('[data-cy="title-recipe"] a h2 span');
const title = titleElement ? titleElement.textContent.trim() : 'N/A';
console.log(title);
const priceWhole = product.querySelector('.a-price-whole');
const priceFraction = product.querySelector('.a-price-fraction');
const price = priceWhole && priceFraction
? `$${priceWhole.textContent}${priceFraction.textContent}`
: 'N/A';
const ratingElement = product.querySelector('.a-icon-alt');
const rating = ratingElement ? ratingElement.textContent.split(' ')[0] : 'N/A';
const imageElement = product.querySelector('.s-image');
javascript
const imageUrl = imageElement ? imageElement.src : 'N/A';
const asin = product.getAttribute('data-asin') || 'N/A';
items.push({
title,
price,
rating,
imageUrl,
asin
});
});
return items;
});
console.log(JSON.stringify(products, null, 2));
return products;
} finally {
await browser.close();
}
};
// Tạo một hồ sơ mới
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('Hồ sơ của tôi' + randomString());
console.log('Hồ sơ đã được tạo:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('Tạo hồ sơ không thành công:', error);
throw error;
}
};
// Lấy hoặc tạo các hồ sơ cần thiết
const getProfiles = async (count) => {
try {
const response = await client.profiles.list({ page: 1, pageSize: count });
const profiles = response?.docs;
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate).fill(0).map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [...profiles.map(p => p.profileId), ...newProfiles];
}
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('Lấy hồ sơ không thành công:', error);
throw error;
}
};
// Thực hiện các tác vụ đồng thời
const runTasks = async () => {
try {
const profileIds = await getProfiles(MAX_PROFILES);
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
await Promise.all(tasks);
console.log('Tất cả các tác vụ đã hoàn thành thành công');
} catch (error) {
console.error('Có lỗi xảy ra khi thực hiện các tác vụ:', error);
}
};
// Thực thi các tác vụ
await runTasks();Kết quả kiểm tra:
- Trang tìm kiếm Amazon tự động xử lý reCAPTCHA được kích hoạt
- Thành công trong việc trích xuất tiêu đề sản phẩm, giá, đánh giá, hình ảnh, ASIN và các dữ liệu khác
- Toàn bộ quá trình không yêu cầu can thiệp của con người; CAPTCHA đã được phát hiện và vượt qua tự động
Giải thích kết quả ví dụ:
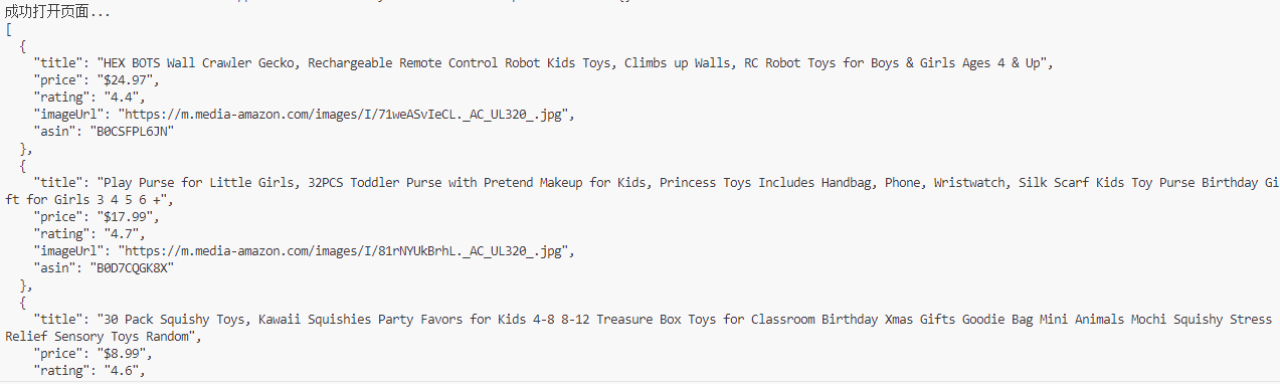
- Vượt qua CAPTCHA thành công & Trích xuất dữ liệu:
Trang tải thành công, và dữ liệu sản phẩm được trích xuất:
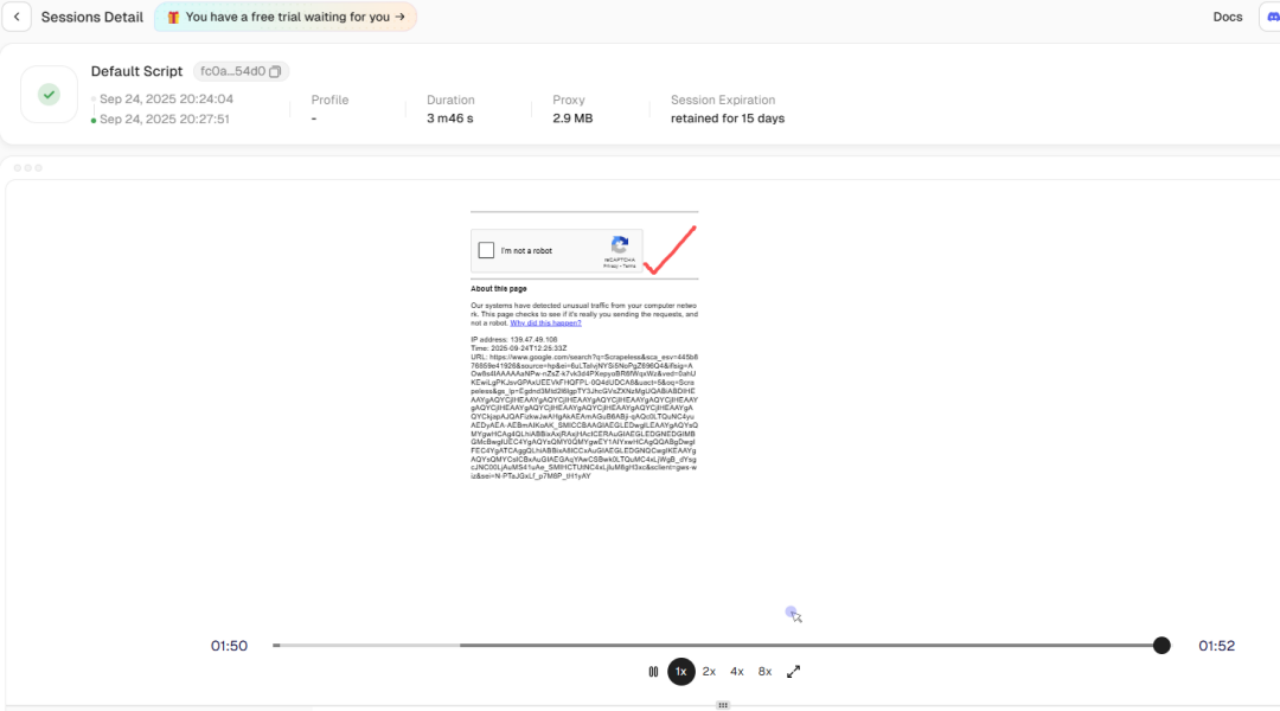
- Xử lý CAPTCHA tự động:
Sử dụng tính năng phát lại Lịch sử Phiên, bạn có thể thấy rằng xác minh rủi ro đã được kích hoạt trong quá trình thu thập dữ liệu, nhưng Scrapeless đã tự động vượt qua reCAPTCHA. Điều này giải quyết trở ngại trong việc thu thập dữ liệu bị chặn trong nền.
Thông thường, việc truy cập các trang tìm kiếm Amazon có thể kích hoạt reCAPTCHA yêu cầu sự tương tác thủ công. Với Scrapeless Cloud Browser:
- reCAPTCHA được phát hiện tự động
- API tích hợp hoàn thành quy trình xác minh tự động
- Script tiếp tục thực hiện và trích xuất dữ liệu sản phẩm
- Khả năng quan sát trên đám mây:
Bảng điều khiển Scrapeless cung cấp:
- Phiên trực tiếp: Giám sát theo thời gian thực các phiên trình duyệt để quan sát quá trình thực thi script
- Lịch sử phiên: Phát lại các phiên trước để gỡ lỗi và xem xét việc xử lý CAPTCHA
Dù trình duyệt chạy trên đám mây, nó mang đến một trải nghiệm tương tự như gỡ lỗi cục bộ, giảm đáng kể khó khăn trong việc gỡ lỗi trình duyệt đám mây.
Tóm tắt
Từ ba kịch bản thực tế, chúng ta có thể tóm tắt hiệu suất của Scrapeless Cloud Browser qua các yếu tố chính:
- Tính đồng thời & Tách biệt môi trường
- Hỗ trợ tạo và quản lý hàng loạt các hồ sơ
- Dấu vân tay, cookie, bộ nhớ đệm và dữ liệu trình duyệt của từng hồ sơ được tách biệt hoàn toàn
- Hỗ trợ hơn 10 tác vụ đồng thời trong các ví dụ mà không có xung đột hoặc tranh chấp tài nguyên; có thể mở rộng đến hàng nghìn tác vụ đồng thời
- Tương đương với việc có hàng trăm hoặc hàng nghìn phiên trình duyệt độc lập chạy đồng thời
- Dấu vân tay trình duyệt ngẫu nhiên
- Mỗi lần tạo hồ sơ ngẫu nhiên sinh ra các tham số cốt lõi như user-agent, múi giờ, ngôn ngữ và độ phân giải màn hình
- Dấu vân tay mô phỏng gần giống với các môi trường trình duyệt thực
- Giảm khả năng bị phát hiện là truy cập tự động
- Tự động hóa CAPTCHA tích hợp
- Hỗ trợ nhận dạng tự động reCAPTCHA, Cloudflare Turnstile/Challenge và các loại CAPTCHA khác
- Hoàn thành xác minh tự động mà không cần sự can thiệp của con người
- Khả năng quan sát trình duyệt đám mây
- Phiên trực tiếp: Giám sát việc thực thi trình duyệt theo thời gian thực
- Lịch sử phiên: Phát lại các phiên trước để gỡ lỗi và xác minh
Đối với các kịch bản tự động hóa yêu cầu cô lập đa môi trường, độ đồng thời cao và vượt qua CAPTCHA, Scrapeless Cloud Browser là một lựa chọn mạnh mẽ.
Sẵn sàng để tăng cường tự động hóa web của bạn? Thử Scrapeless Cloud Browser hôm nay và trải nghiệm quản lý hồ sơ liền mạch, dấu vân tay độc lập, và xử lý CAPTCHA tự động—tất cả đều trên đám mây!
ĐDisclaimer: Bất kỳ công cụ tự động hóa nào cũng phải tuân thủ các điều khoản dịch vụ của trang web mục tiêu và các luật liên quan. Bài viết này chỉ dành cho mục đích nghiên cứu và xác thực kỹ thuật.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


