
Cách sử dụng Python để thu thập dữ liệu sản phẩm từ Lazada?
Specialist in Anti-Bot Strategies
Lấy dữ liệu sản phẩm Lazada là gì?
Lazada là một sàn thương mại điện tử nơi các thương nhân khác nhau bán hàng hóa, và việc thu thập dữ liệu này rất có lợi cho nhiều ứng dụng, bao gồm theo dõi giá cả, nghiên cứu thị trường, quản lý hàng tồn kho và phân tích đối thủ cạnh tranh.
Lazada cung cấp nhiều tính năng như tùy chọn thanh toán an toàn, đánh giá của khách hàng và hệ thống giao hàng giúp tạo điều kiện thuận lợi cho việc mua hàng và giao hàng tận nhà của khách hàng.
Lấy dữ liệu web Lazada là quá trình thu thập dữ liệu từ trang web Lazada bằng các công cụ hoặc script tự động.
Lấy dữ liệu là việc thu thập thông tin cụ thể từ các trang web Lazada, chẳng hạn như chi tiết sản phẩm (như tên, giá, mô tả và ảnh), thông tin người bán, đánh giá của người dùng và xếp hạng. Tuy nhiên, điều quan trọng cần nhớ là việc thu thập dữ liệu trực tuyến có thể chịu sự ràng buộc pháp lý, và điều khoản dịch vụ của một số trang web hạn chế việc thu thập dữ liệu của họ mà không được phép.
Tại sao bạn cần thu thập dữ liệu web Lazada?
- Theo dõi và so sánh giá cả. Thu thập dữ liệu sản phẩm trên Lazada có thể giúp các doanh nghiệp hoặc người tiêu dùng theo dõi sự biến động giá cả, phân tích xu hướng giá của các sản phẩm tương tự và tìm thời điểm tốt nhất để mua.
- Phân tích thị trường. Các doanh nghiệp có thể thu thập được động lực thị trường như sản phẩm bán chạy nhất, đánh giá của người dùng, thứ hạng sản phẩm, v.v. bằng cách thu thập dữ liệu của Lazada. Điều này giúp tối ưu hóa chiến lược bán hàng, dự đoán nhu cầu thị trường và xây dựng kế hoạch marketing chính xác hơn.
- Thu thập thông tin sản phẩm. Đối với các công ty thương mại điện tử hoặc đại lý cần quản lý danh mục sản phẩm quy mô lớn, việc thu thập dữ liệu sản phẩm của Lazada (như tên sản phẩm, mô tả, giá cả, thông tin hàng tồn kho, v.v.) có thể đẩy nhanh tốc độ nhập và cập nhật dữ liệu sản phẩm và nâng cao hiệu quả.
- Phân tích đối thủ cạnh tranh. Bằng cách thu thập danh sách sản phẩm, chiến lược giá cả và chương trình khuyến mãi của đối thủ cạnh tranh trên Lazada, các công ty có thể hiểu rõ hơn về vị thế thị trường của đối thủ và xây dựng kế hoạch kinh doanh cạnh tranh hơn.
- Phân tích bình luận và xếp hạng. Bình luận và xếp hạng của người dùng là cơ sở quan trọng cho việc ra quyết định của người tiêu dùng. Bằng cách thu thập thông tin này, các công ty có thể phân tích phản hồi của người tiêu dùng về sản phẩm, từ đó cải thiện sản phẩm hoặc dịch vụ và nâng cao trải nghiệm người dùng.
- Xây dựng nền tảng so sánh giá sản phẩm. Một số startup hoặc nền tảng công nghệ cần thu thập dữ liệu của Lazada để xây dựng các trang web hoặc ứng dụng so sánh giá, cho phép người dùng dễ dàng so sánh giá cả và thông tin giảm giá trên các nền tảng khác nhau.
- Quản lý hàng tồn kho tự động. Đối với các nhà bán lẻ, việc thu thập dữ liệu của Lazada có thể tự động kiểm tra xem hàng tồn kho hoặc giá cả của một số sản phẩm có thay đổi hay không, để điều chỉnh chiến lược sản phẩm của họ kịp thời.
- Khám phá cơ hội kinh doanh. Thu thập các sản phẩm bán chạy và các lĩnh vực sản phẩm chưa được khai thác của Lazada để giúp khám phá các cơ hội kinh doanh tiềm năng và mở ra các hướng kinh doanh mới.
Tại sao chọn ngôn ngữ Python để thu thập dữ liệu Lazada?
- Hệ sinh thái crawler mạnh mẽ
Python có rất nhiều thư viện và framework liên quan đến crawler, chẳng hạn như:
requests: đơn giản và dễ sử dụng, phù hợp để gửi yêu cầu HTTP để lấy dữ liệu trang web tĩnh.BeautifulSoup: thư viện phân tích cú pháp HTML nhẹ, dễ dàng trích xuất nội dung trang web.Scrapy: framework crawler mạnh mẽ, hỗ trợ thu thập dữ liệu phân tán hiệu quả và quản lý dữ liệu.Selenium: được sử dụng để xử lý nội dung trang web động, hỗ trợ hoạt động trình duyệt tự động.
Những công cụ này có thể dễ dàng thích ứng với các trường hợp khác nhau của việc thu thập dữ liệu web Lazada.
- Khả năng xử lý dữ liệu phong phú
Python cung cấp các công cụ xử lý và phân tích dữ liệu mạnh mẽ, chẳng hạn như:
pandas: công cụ vận hành bảng dữ liệu hiệu quả, dễ dàng lưu trữ và xử lý dữ liệu thu thập được.csvvàjson: hỗ trợ tích hợp cho các định dạng lưu trữ dữ liệu phổ biến, dễ dàng xuất kết quả.NumPyvàmatplotlib: các công cụ mạnh mẽ để thống kê và trực quan hóa dữ liệu.
Những công cụ này giúp có thể hoàn thành mọi thứ từ thu thập dữ liệu đến phân tích chỉ trong một lần.
- Khả năng xử lý trang web động
Đối với nội dung được tải động của Lazada, Python kết hợp với các công cụ như Selenium và Playwright có thể mô phỏng hành vi của người dùng thực và bỏ qua các giới hạn hiển thị JavaScript. Ngoài ra, với các dịch vụ trình duyệt đám mây (như Browserless), hiệu quả xử lý trang web động có thể được cải thiện hơn nữa.
- Khả năng mở rộng cao
Python có khả năng mở rộng tốt và có thể dễ dàng tích hợp với các công cụ quản lý pool proxy (như proxy-rotator), các công cụ giải quyết CAPTCHA (như anticaptcha) và các dịch vụ lưu trữ dữ liệu (như MySQL và MongoDB) để đáp ứng nhu cầu thu thập dữ liệu quy mô lớn.
Có cách nào dễ dàng để lấy dữ liệu sản phẩm Lazada không?
Việc xây dựng trình thu thập dữ liệu Lazada bằng Python luôn phải bỏ qua việc bị chặn, điều này dường như là một vấn đề đau đầu. May mắn thay, đây là một phương pháp dễ sử dụng để thu thập dữ liệu sản phẩm Lazada mà không gặp khó khăn!
Scrapeless - API lấy dữ liệu Lazada tốt nhất
Scrapeless là một nền tảng lấy dữ liệu web tiên tiến được thiết kế cho các doanh nghiệp và nhà phát triển cần trích xuất dữ liệu chính xác, an toàn và có khả năng mở rộng. Nó cung cấp các giải pháp tiên tiến để đơn giản hóa quá trình thu thập dữ liệu từ nhiều nguồn khác nhau, bao gồm các nền tảng thương mại điện tử như Lazada và Amazon.
Với thiết kế mạnh mẽ, Scrapeless loại bỏ nhu cầu xây dựng và bảo trì các công cụ thu thập dữ liệu của riêng bạn và có thể dễ dàng xử lý các thách thức phức tạp như giải quyết CAPTCHA, hệ thống chống bot và luân chuyển IP. Cho dù bạn muốn thu thập chi tiết sản phẩm, xu hướng giá cả hay đánh giá của khách hàng, Scrapeless đều cung cấp một cách đáng tin cậy và hiệu quả để đáp ứng nhu cầu dữ liệu của bạn.
Cách triển khai API lấy dữ liệu Lazada của Scrapeless?
- Bước 1. Đăng nhập vào Scrapeless.
- Bước 2. Nhấp vào "Scraping API"
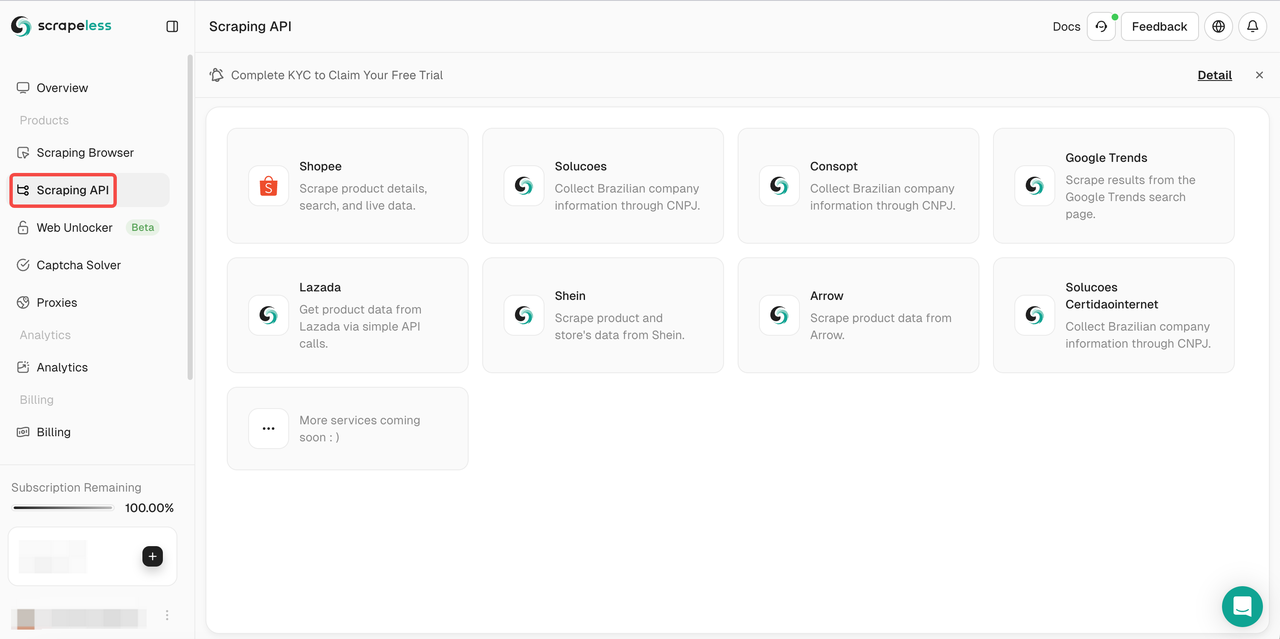
- Bước 3. Chọn Lazada và nhập trang cần lấy dữ liệu của Lazada.
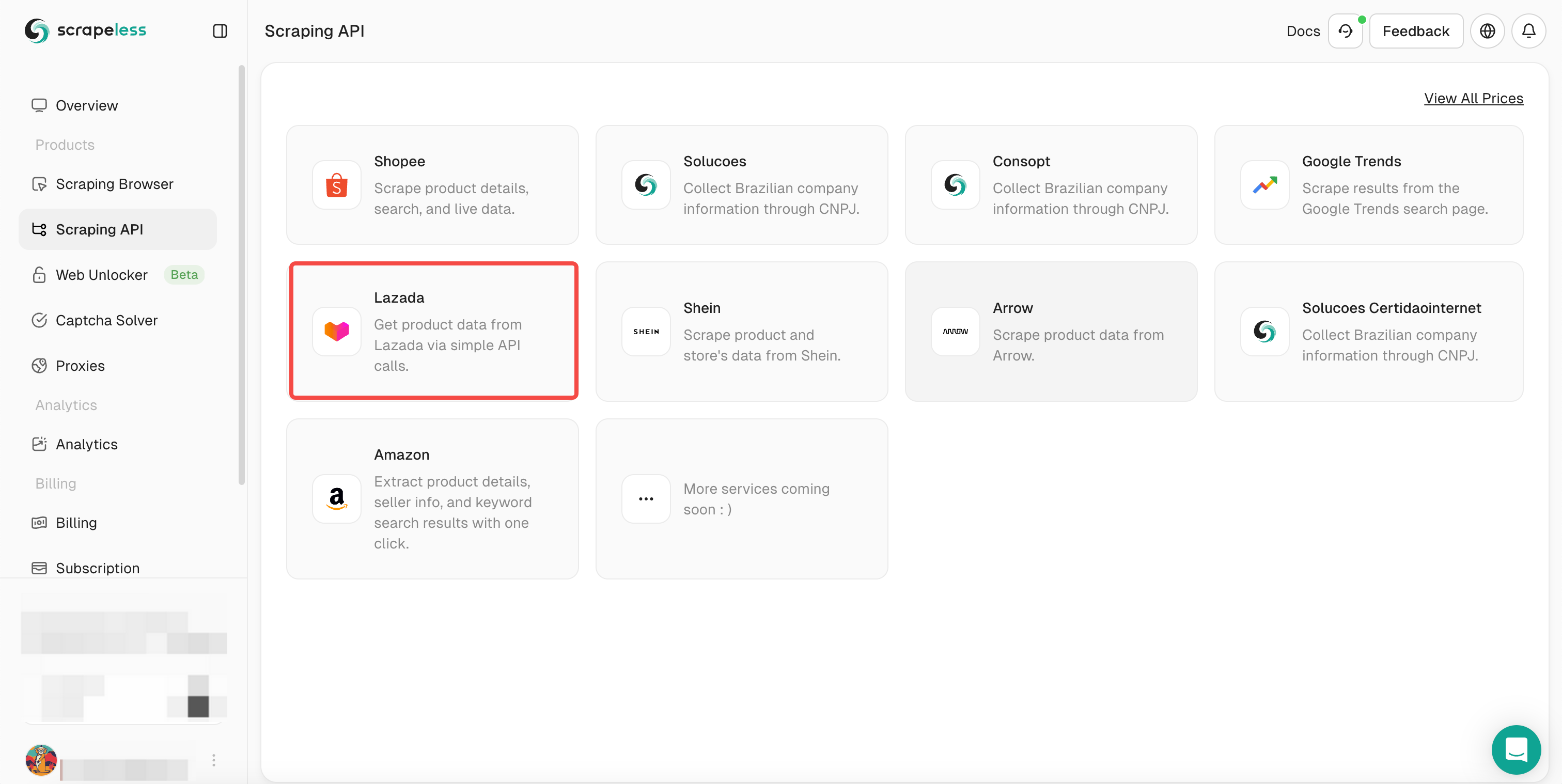
- Bước 4. Kéo xuống Action List và chọn cài đặt điều kiện dữ liệu cần thu thập. Sau đó nhấp vào Start Scraping.
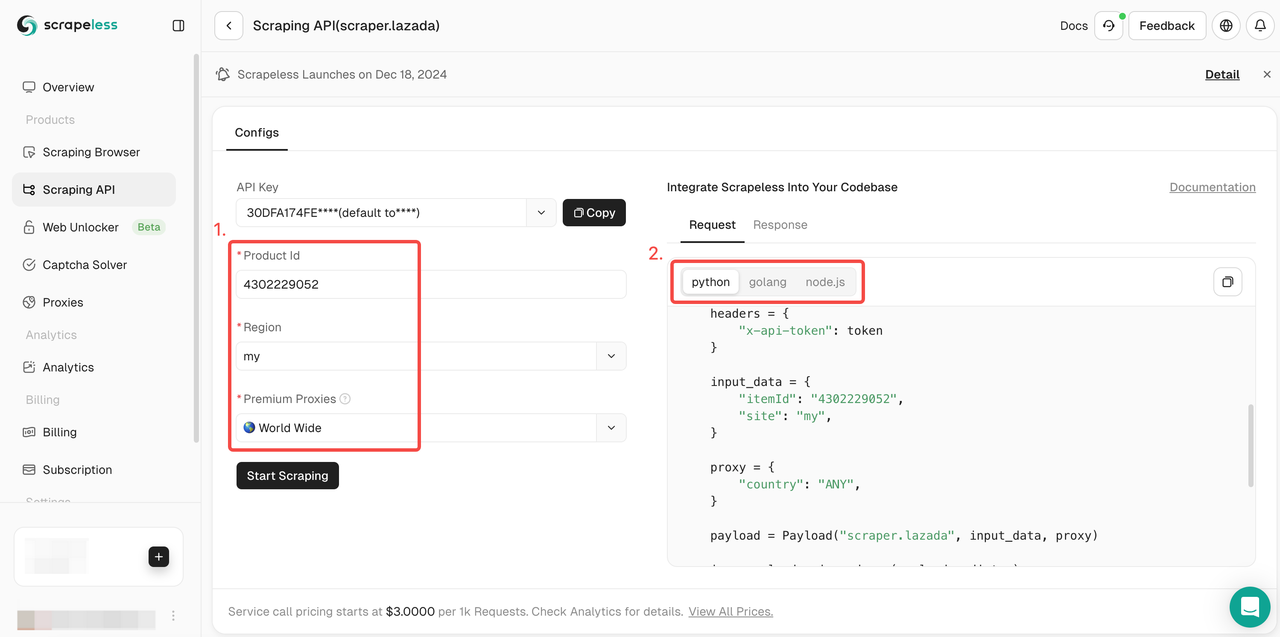
- Bước 5. Việc thu thập sẽ thành công trong vài giây. Dữ liệu có cấu trúc tương ứng sẽ được hiển thị ở bên phải.
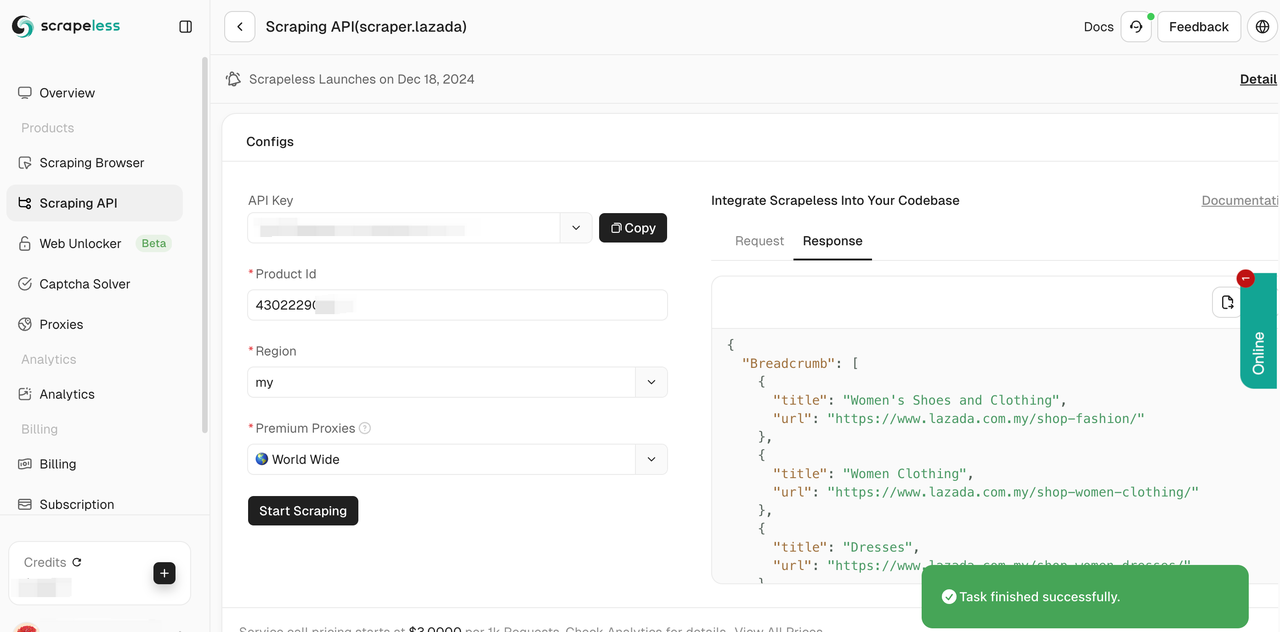
Bạn cũng có thể tích hợp mã tham khảo của chúng tôi vào dự án của bạn và triển khai việc thu thập dữ liệu quy mô lớn của bạn. Ở đây chúng tôi lấy Python làm ví dụ. Bạn cũng có thể sử dụng Golong và NodeJS trong client của chúng tôi.
- Python:
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = " " #your API token
headers = {
"x-api-token": token
}
input_data = {
"itemId": " ", #Input the product ID
"site": "my",
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.lazada", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Cách trích xuất dữ liệu sản phẩm Lazada bằng Python?
Bước 1: Thiết lập môi trường
Cài đặt các thư viện Python cần thiết. Bạn chủ yếu cần requests để gửi yêu cầu HTTP và BeautifulSoup để phân tích cú pháp HTML. Nếu trang web sử dụng nội dung động, bạn có thể sử dụng Selenium hoặc các dịch vụ trình duyệt đám mây như Browserless. Cài đặt các thư viện cần thiết bằng:
Bash
pip install requests beautifulsoup4 seleniumBước 2: Kiểm tra trang web Lazada
Mở Lazada trong trình duyệt của bạn và định vị trang bạn muốn thu thập dữ liệu (ví dụ: danh sách sản phẩm hoặc kết quả tìm kiếm). Sử dụng công cụ dành cho nhà phát triển (F12) để kiểm tra cấu trúc trang và xác định các thẻ và lớp cho dữ liệu sản phẩm như tên, giá và liên kết.
Bước 3: Gửi yêu cầu HTTP
Đối với các trang tĩnh, hãy sử dụng thư viện requests để gửi yêu cầu GET. Bao gồm các tiêu đề như User-Agent để bắt chước một trình duyệt thực.
Python
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
url = 'https://www.lazada.com.my/shop-mobiles/'
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())
else:
print(f" ")Bước 4: Phân tích cú pháp nội dung HTML
Sử dụng BeautifulSoup để trích xuất thông tin sản phẩm bằng cách xác định các thẻ và lớp HTML phù hợp.
Python
products = soup.find_all('div', class_='c16H9d') # Thay thế bằng tên lớp thực tế
for product in products:
name = product.text
print(f"Tên sản phẩm: {name}")Bước 5: Xử lý nội dung động
Nếu nội dung trang được tải động bằng JavaScript, hãy sử dụng Selenium hoặc trình duyệt đám mây để hiển thị toàn bộ nội dung.
Python
from selenium import webdriver
driver = webdriver.Chrome() # Đảm bảo bạn đã cài đặt ChromeDriver
driver.get('https://www.lazada.com.my/shop-mobiles/')
# Chờ nội dung tải và thu thập dữ liệu
elements = driver.find_elements_by_class_name('c16H9d')
for element in elements:
print(f"Tên sản phẩm: {element.text}")
driver.quit()Bước 6: Quản lý các biện pháp chống bot
Lazada có thể sử dụng các kỹ thuật để chặn bot. Sử dụng các chiến lược sau để bỏ qua việc phát hiện:
- Luân chuyển Proxy: Sử dụng proxy luân phiên để tránh bị cấm IP.
- Giả mạo User-Agent: Ngẫu nhiên hóa User-Agent trong tiêu đề.
- Trình duyệt đám mây: Các dịch vụ như Browserless có thể giúp bỏ qua các hệ thống phát hiện nâng cao.
Bước 7: Lưu trữ dữ liệu
Lưu dữ liệu đã thu thập được trong tệp CSV hoặc cơ sở dữ liệu để sử dụng trong tương lai.
Python
import csv
with open('lazada_products.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Tên sản phẩm', 'Giá', 'URL']) # Ví dụ tiêu đề
# Thêm chi tiết sản phẩm ở đâyKết luận
Việc thu thập dữ liệu sản phẩm Lazada mang lại cơ hội đáng kể cho các doanh nghiệp trong lĩnh vực thương mại điện tử. Dữ liệu thu thập được là một nguồn tài nguyên có giá trị cho nghiên cứu thị trường, phân tích đối thủ cạnh tranh, tối ưu hóa giá cả và nhiều sáng kiến chiến lược dựa trên dữ liệu khác.
API lấy dữ liệu Scrapeless giúp việc lấy dữ liệu sản phẩm Lazada đơn giản và hiệu quả. Với khả năng bỏ qua CAPTCHA và luân chuyển IP thông minh, bạn có thể tránh bị chặn trang web và dễ dàng đạt được việc lấy dữ liệu.
Đăng nhập và nhận dùng thử miễn phí ngay!
Đọc thêm:
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


