
Cách nhanh chóng thu thập dữ liệu hồ sơ Instagram?
Specialist in Anti-Bot Strategies
Instagram là một trong những nền tảng mạng xã hội phổ biến nhất với hàng triệu người dùng trên toàn thế giới. Thu thập dữ liệu hồ sơ Instagram rất hữu ích để giúp các doanh nghiệp, nhà phát triển, chuyên gia phân tích dữ liệu cho phân tích tiếp thị, nghiên cứu cạnh tranh hoặc quản lý dữ liệu cá nhân.
Trong bài viết này, chúng tôi sẽ hướng dẫn bạn quy trình thu thập dữ liệu hồ sơ Instagram một cách chi tiết. Chúng tôi sẽ giải thích cách tạo một trình thu thập dữ liệu Instagram để trích xuất dữ liệu từ hồ sơ Instagram và các trang bài đăng.
Đã đến lúc tìm hiểu cách nhanh chóng thu thập dữ liệu Ins bằng API Thu thập dữ liệu tiện lợi.
- #Phương pháp 1. Xây dựng trình thu thập dữ liệu hồ sơ Instagram bằng Python của bạn
- #Phương pháp 2. Sử dụng API Thu thập dữ liệu để thu thập dữ liệu dễ dàng
Tại sao lại thu thập dữ liệu hồ sơ Instagram?
Dữ liệu công khai của Instagram rất lớn và có thể cung cấp tất cả các loại thông tin chi tiết. Thu thập dữ liệu hồ sơ có thể cung cấp cho bạn thông tin giá trị về người dùng phổ biến trên toàn thế giới, giúp bạn dự đoán xu hướng, theo dõi nhận thức thương hiệu, hiểu cách cải thiện hiệu suất Instagram của mình hoặc giúp các doanh nghiệp tìm kiếm khách hàng tiềm năng và tiếp cận khách hàng mới bằng cách kết nối với các hồ sơ Instagram phổ biến có sở thích tương tự.
Ngoài ra, dữ liệu Instagram đã thu thập là một nguồn tài nguyên khả thi cho các nghiên cứu phân tích cảm xúc. Dữ liệu này có thể được tìm thấy trong các bài đăng và bình luận và có thể được sử dụng để thu thập ý kiến cộng đồng về các xu hướng và tin tức cụ thể.
Phương pháp 1. Trình thu thập dữ liệu hồ sơ Instagram bằng Python
Hãy bắt đầu bằng cách thu thập dữ liệu hồ sơ người dùng Instagram! Tiếp theo, chúng tôi sẽ giải thích chi tiết cách thu thập thông tin hồ sơ của người dùng Instagram ladygaga. Chúng ta có thể làm điều đó bằng cách làm theo các bước dưới đây:
Chúng tôi bảo vệ quyền riêng tư của trang web một cách nghiêm túc. Tất cả dữ liệu trong blog này đều công khai và chỉ được sử dụng để chứng minh quá trình thu thập dữ liệu. Chúng tôi không lưu bất kỳ thông tin và dữ liệu nào.
Bước 1. Phân tích trang mục tiêu
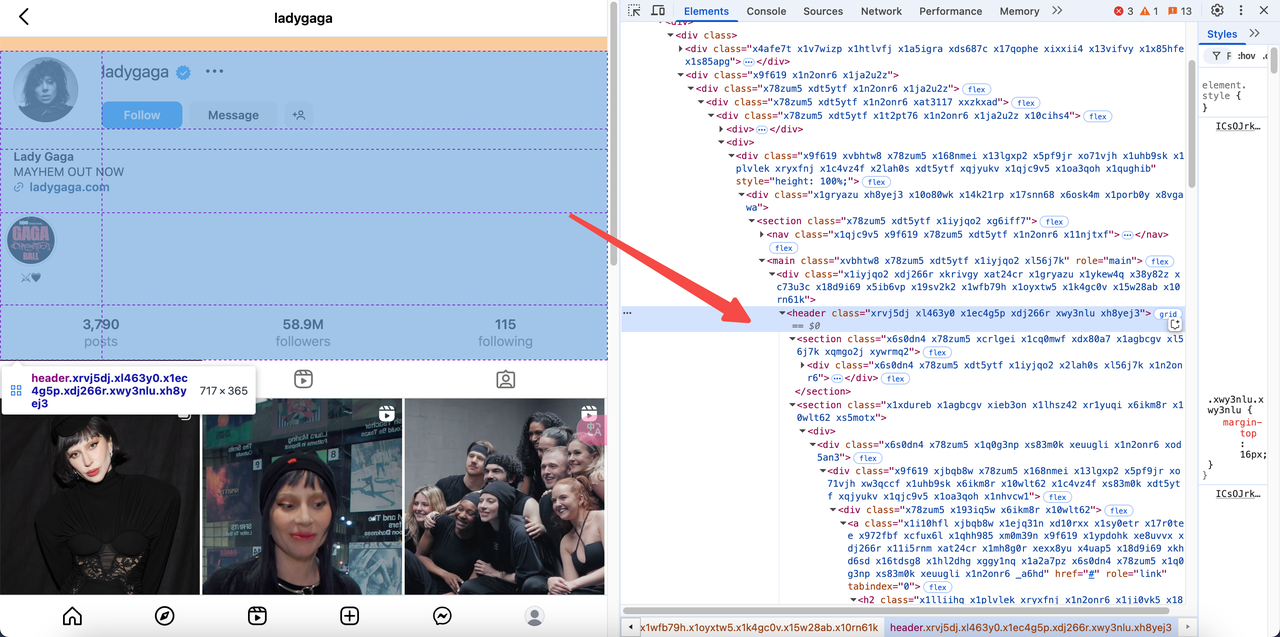
- Truy cập URL mục tiêu: https://www.instagram.com/ladygaga/.
- Kiểm tra mã nguồn trang để định vị dữ liệu JSON được nhúng:
- Instagram nhúng thông tin người dùng trong thẻ
scriptvới định dạngwindow._sharedData. - Chúng ta có thể trích xuất dữ liệu này bằng cách phân tích cú pháp HTML.
Bước 2. Cài đặt các thư viện cần thiết
Đảm bảo các thư viện Python sau được cài đặt:
pip install requests beautifulsoup4
Bước 3. Thiết lập tiêu đề yêu cầu
Để giả lập truy cập trình duyệt, hãy đặt tiêu đề User-Agent và Referer để tránh bị chặn bởi các cơ chế chống thu thập dữ liệu.
Python
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": "https://www.instagram.com/"
}Bước 4. Phân tích cú pháp dữ liệu JSON
Chúng ta cần trích xuất nội dung window._sharedData từ thẻ script trong HTML và chuyển đổi nó thành một từ điển Python.
Python
soup = BeautifulSoup(response.text, "html.parser")
script_tag = soup.find("script", type="application/ld+json")
if not script_tag:
print("Error: JSON data not found in the page.")
return None
# Phân tích cú pháp dữ liệu JSON
try:
data = json.loads(script_tag.string)
except json.JSONDecodeError:
print("Error: Failed to parse JSON data.")
return NoneBước 5. Trích xuất các trường cần thiết
Truy xuất tên người dùng, tiểu sử, số lượng người theo dõi, số lượng bài đăng và các thông tin liên quan khác từ dữ liệu JSON đã phân tích cú pháp.
Mã hoàn chỉnh
Dưới đây là mã Python đầy đủ, bạn có thể sử dụng trực tiếp để thu thập thông tin hồ sơ của Lady Gaga:
Python
import requests
from bs4 import BeautifulSoup
import json
def scrape_instagram_profile(username):
url = f"https://www.instagram.com/ladygaga/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": "https://www.instagram.com/"
}
response = requests.get(url, headers=headers)
if response.status_code != 200:
print(f"Error: Unable to fetch data for {username}. Status code: {response.status_code}")
return None
soup = BeautifulSoup(response.text, "html.parser")
script_tag = soup.find("script", type="application/ld+json")
if not script_tag:
print("Error: JSON data not found in the page.")
return None
# Phân tích cú pháp dữ liệu JSON
try:
data = json.loads(script_tag.string)
except json.JSONDecodeError:
print("Error: Failed to parse JSON data.")
return None
profile = {
"username": data["author"]["name"],
"bio": data["description"],
"follower_count": data["author"]["interactionStatistic"][0]["userInteractionCount"],
"post_count": data["author"]["interactionStatistic"][1]["userInteractionCount"]
}
return profile
# Ví dụ sử dụng
if __name__ == "__main__":
username = "ladygaga"
profile_data = scrape_instagram_profile(username)
if profile_data:
print("Dữ liệu hồ sơ Instagram:")
print(json.dumps(profile_data, indent=4, ensure_ascii=False))Kết quả thu thập dữ liệu
Sau khi chạy mã, đầu ra profile_data sẽ bao gồm các trường sau:
JSON
{
"username": "ladygaga",
"bio": "Lady Gaga MAYHEM OUT NOW",
"follower_count": "58.9M",
"post_count": "3,790"
}Phương pháp 2. API Thu thập dữ liệu Scrapeless (Đề xuất)
Thu thập dữ liệu Instagram khá dễ dàng. Tuy nhiên, Instagram cực kỳ hạn chế về quyền truy cập vào dữ liệu công khai của nó. Nó chỉ cho phép một vài yêu cầu mỗi ngày đối với người dùng không đăng nhập, vượt quá giới hạn này, nó sẽ chuyển hướng các yêu cầu đến trang đăng nhập.
Làm thế nào để tránh bị chặn trình thu thập dữ liệu Instagram? Scrapeless là công cụ thu thập dữ liệu lý tưởng của bạn!
Scrapeless cung cấp các API thu thập dữ liệu web, mở chặn web và trích xuất dữ liệu cho việc thu thập dữ liệu quy mô lớn.
- Vượt qua bảo vệ chống bot: Tránh bị chặn khi thu thập dữ liệu web!
- Proxy dân cư luân phiên: Ngăn chặn việc cấm IP và chặn địa lý.
- Hiển thị JavaScript: Thu thập dữ liệu các trang web động thông qua trình duyệt đám mây.
- Python và Typescript SDKs, cũng như tích hợp Scrapy.
API Thu thập dữ liệu Instagram này có miễn phí không?
Có. Scrapeless cung cấp cho bạn $2 tín dụng miễn phí. Bạn có thể đăng ký trực tiếp để nhận tín dụng miễn phí. Với Trình thu thập dữ liệu hồ sơ Instagram, bạn có thể dễ dàng thu thập thông tin người dùng miễn phí!
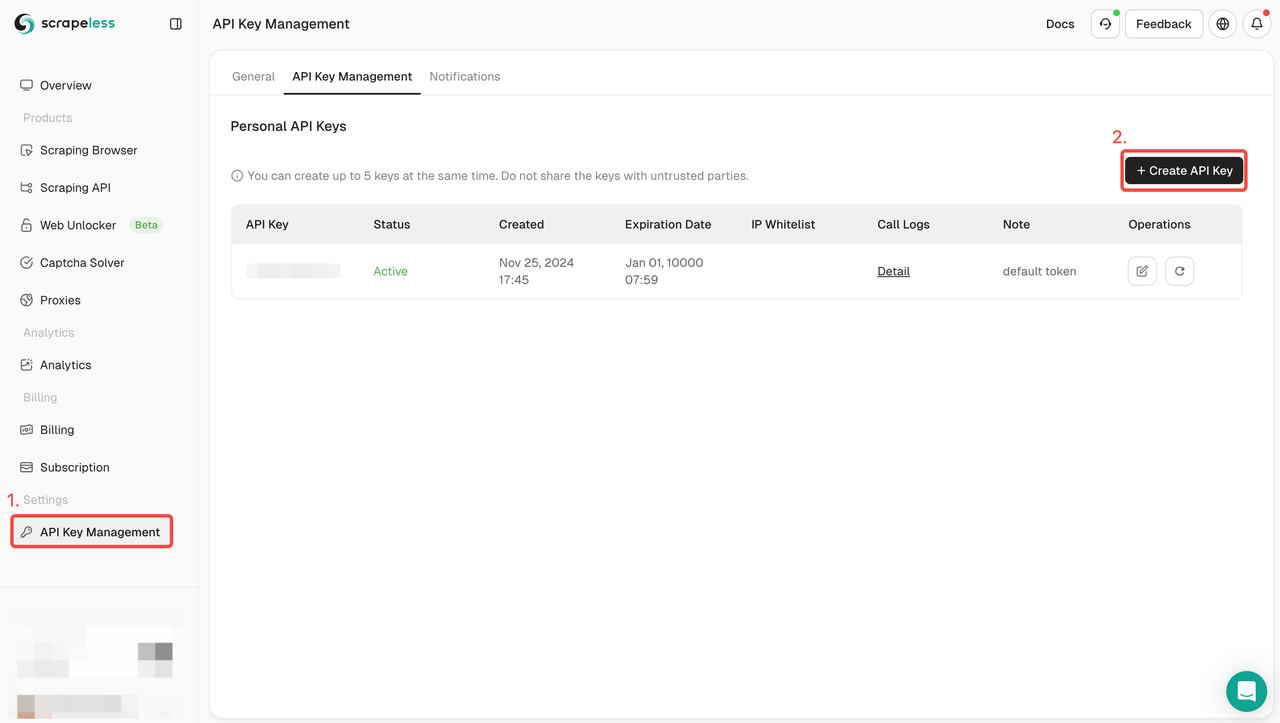
Bước 1. Tạo mã thông báo API của bạn
Để bắt đầu, bạn cần lấy Khóa API của mình từ Bảng điều khiển Scrapeless:
- Đăng nhập vào Bảng điều khiển Scrapeless.
- Điều hướng đến Quản lý Khóa API.
- Nhấp vào Tạo để tạo Khóa API duy nhất của bạn.
- Sau khi tạo xong, chỉ cần nhấp vào Khóa API để sao chép nó.
Kết luận
Trong hướng dẫn này, chúng tôi đã giới thiệu 2 cách hiệu quả để lấy dữ liệu hồ sơ Instagram. Chúng tôi đã chỉ ra cách xử lý xác thực, thực hiện yêu cầu, xử lý phản hồi và tích hợp IP proxy để có độ ổn định và bảo mật tốt hơn.
Làm theo hướng dẫn này, bạn có thể dễ dàng bắt đầu trích xuất dữ liệu hồ sơ Instagram cho mục đích cá nhân hoặc thương mại trong khi vẫn duy trì quyền riêng tư và tránh các vấn đề như giới hạn tốc độ.
Để cải thiện hiệu quả thu thập dữ liệu, chúng tôi khuyên bạn nên sử dụng API thu thập dữ liệu nâng cao, chỉ cần các thông số cấu hình đơn giản để hoàn thành việc trích xuất dữ liệu!
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


