
Cách dùng Python để Scrape thông tin người bán sản phẩm trực tuyến trên Google
Advanced Data Extraction Specialist
Giới thiệu
Trong bối cảnh thương mại điện tử cạnh tranh ngày nay, việc giám sát danh sách sản phẩm và phân tích hiệu suất của người bán trực tuyến trên các nền tảng như Google có thể cung cấp những hiểu biết có giá trị. Tích xuất dữ liệu danh sách Sản phẩm Google cho phép các doanh nghiệp thu thập dữ liệu thời gian thực để so sánh giá cả, theo dõi xu hướng và phân tích đối thủ cạnh tranh. Trong bài viết này, chúng tôi sẽ hướng dẫn bạn cách tích xuất dữ liệu người bán trực tuyến sản phẩm Google bằng Python, sử dụng nhiều phương pháp khác nhau. Chúng tôi cũng sẽ giải thích tại sao Scrapeless là lựa chọn tốt nhất cho các doanh nghiệp đang tìm kiếm giải pháp đáng tin cậy, có khả năng mở rộng và hợp pháp.
Hiểu rõ những thách thức khi tích xuất dữ liệu người bán trực tuyến sản phẩm Google
Khi cố gắng tích xuất dữ liệu người bán trực tuyến sản phẩm Google, một số thách thức chính có thể phát sinh:
- Các biện pháp chống tích xuất dữ liệu: Các trang web triển khai CAPTCHA và chặn IP để ngăn chặn tích xuất dữ liệu tự động, khiến việc trích xuất dữ liệu trở nên khó khăn.
- Nội dung động: Các trang sản phẩm Google thường tải dữ liệu bằng JavaScript, điều này có thể bị bỏ sót bởi các phương pháp tích xuất dữ liệu truyền thống như Requests & BeautifulSoup hoặc Selenium.
- Hạn chế tốc độ: Yêu cầu quá mức trong một thời gian ngắn có thể dẫn đến việc truy cập bị hạn chế, gây ra sự chậm trễ và gián đoạn trong quá trình tích xuất dữ liệu.
Thông báo về quyền riêng tư: Chúng tôi bảo vệ quyền riêng tư của trang web một cách nghiêm túc. Tất cả dữ liệu trong blog này đều công khai và chỉ được sử dụng để minh họa quá trình thu thập dữ liệu. Chúng tôi không lưu trữ bất kỳ thông tin và dữ liệu nào.
Phương pháp 1: Tích xuất dữ liệu người bán trực tuyến sản phẩm Google với API Scrapeless (Giải pháp được đề xuất)
Tại sao Scrapeless là một công cụ tuyệt vời:
- Trích xuất dữ liệu hiệu quả: Scrapeless có thể bỏ qua CAPTCHA và các biện pháp chống bot, cho phép tích xuất dữ liệu trơn tru, không bị gián đoạn.
- Giá cả phải chăng: Chỉ với 0,1 đô la cho 1.000 truy vấn, Scrapeless cung cấp một trong những giải pháp tiết kiệm nhất cho việc tích xuất dữ liệu Google.
- Tích xuất dữ liệu đa nguồn: Ngoài việc tích xuất dữ liệu người bán trực tuyến sản phẩm Google, Scrapeless cho phép bạn thu thập dữ liệu từ Google Maps, Google Hotels, Google Flights, Google News và hơn thế nữa.
- Tốc độ và khả năng mở rộng: Xử lý các tác vụ tích xuất dữ liệu quy mô lớn một cách nhanh chóng, mà không làm chậm tốc độ, làm cho nó lý tưởng cho cả các dự án quy mô nhỏ và doanh nghiệp.
- Dữ liệu có cấu trúc: Công cụ cung cấp dữ liệu sạch, có cấu trúc, sẵn sàng để sử dụng trong phân tích, báo cáo hoặc tích hợp vào hệ thống của bạn.
- Dễ sử dụng: Không cần thiết lập phức tạp — chỉ cần tích hợp khóa API của bạn và bắt đầu tích xuất dữ liệu trong vài phút.
Cách sử dụng API Scrapeless:
- Đăng ký: Đăng ký trên Scrapeless và lấy khóa API của bạn. Đồng thời, bạn cũng có thể nhận dùng thử miễn phí ở đầu bảng điều khiển.
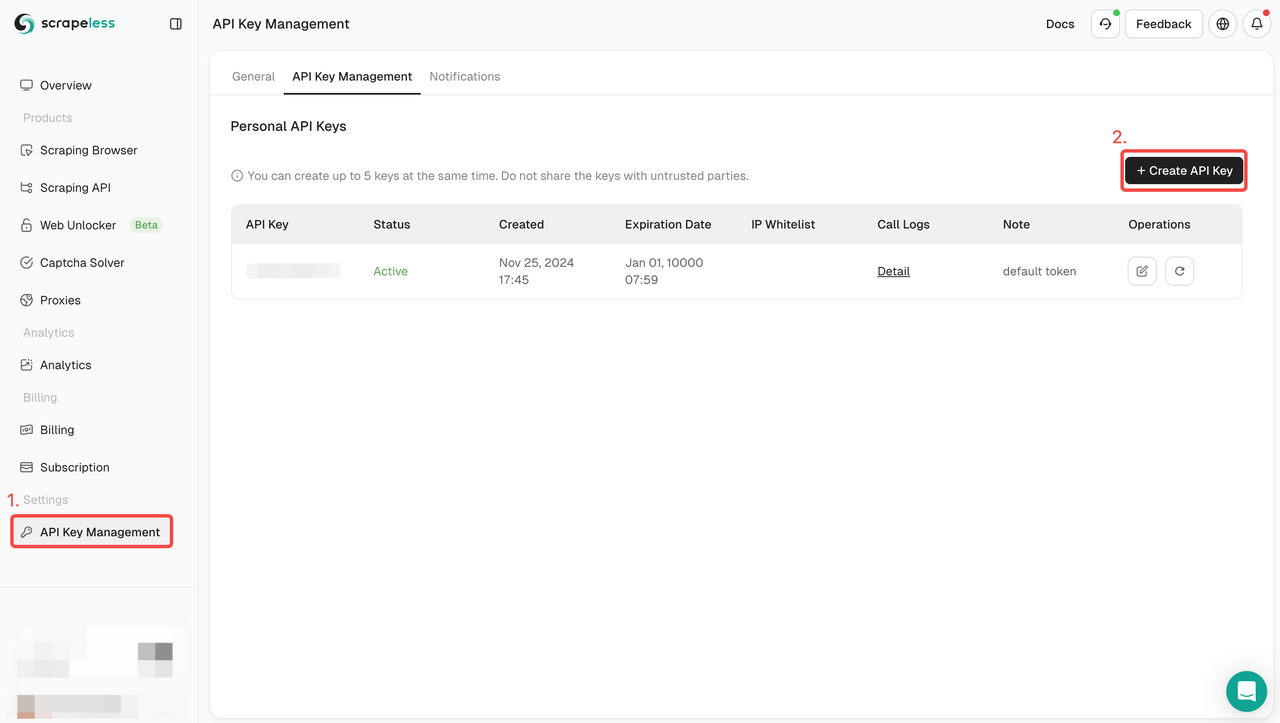
- Tích hợp API: Bao gồm khóa API trong mã của bạn để bắt đầu yêu cầu đến dịch vụ.
- Bắt đầu tích xuất dữ liệu: Bây giờ bạn có thể gửi yêu cầu GET với URL sản phẩm hoặc truy vấn tìm kiếm, và Scrapeless sẽ trả về dữ liệu có cấu trúc bao gồm tên sản phẩm, giá cả, đánh giá và hơn thế nữa.
- Sử dụng dữ liệu: Tận dụng dữ liệu đã thu thập để phân tích đối thủ cạnh tranh, theo dõi xu hướng hoặc bất kỳ dự án nào khác yêu cầu hiểu biết về dữ liệu Google.
Ví dụ mã hoàn chỉnh:
python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_product",
"product_id": "4172129135583325756",
"gl": "us",
"hl": "en",
}
payload = Payload("scraper.google.product", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Dùng thử Scrapeless miễn phí và trải nghiệm cách API của chúng tôi có thể đơn giản hóa quá trình tích xuất dữ liệu người bán trực tuyến sản phẩm Google của bạn. Bắt đầu dùng thử miễn phí tại đây.
Tham gia cộng đồng Discord của chúng tôi để được hỗ trợ, chia sẻ thông tin chi tiết và cập nhật các tính năng mới nhất. Nhấp vào đây để tham gia!
Phương pháp 2: Tích xuất dữ liệu danh sách sản phẩm Google bằng Requests & BeautifulSoup
Trong phương pháp này, chúng ta sẽ đi sâu vào cách tích xuất dữ liệu danh sách sản phẩm Google bằng hai thư viện Python mạnh mẽ: Requests và BeautifulSoup. Các thư viện này cho phép chúng ta gửi yêu cầu HTTP đến các trang sản phẩm Google và phân tích cấu trúc HTML để trích xuất thông tin có giá trị.
Bước 1. Thiết lập môi trường
Đầu tiên, hãy chắc chắn rằng bạn đã cài đặt Python trên hệ thống của mình. Và tạo một thư mục mới để lưu trữ mã cho dự án này. Tiếp theo, bạn cần cài đặt beautifulsoup4 và requests. Bạn có thể làm điều này thông qua PIP:
language
$ pip install requests beautifulsoup4Bước 2. Sử dụng requests để gửi một yêu cầu đơn giản
Bây giờ, chúng ta cần thu thập dữ liệu của sản phẩm Google. Hãy lấy sản phẩm có product_id là 4172129135583325756 làm ví dụ và thu thập một số dữ liệu của OnlineSeller.
Hãy bắt đầu bằng cách sử dụng requests để gửi một yêu cầu GET:
def google_product():
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/jpeg,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "no-cache",
"Pragma": "no-cache",
"Priority": "u=0, i",
"Sec-Ch-Ua": '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
}
response = requests.get('https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8', headers=headers)Như dự kiến, yêu cầu trả về một trang HTML hoàn chỉnh. Bây giờ chúng ta cần trích xuất một số dữ liệu từ trang sau:
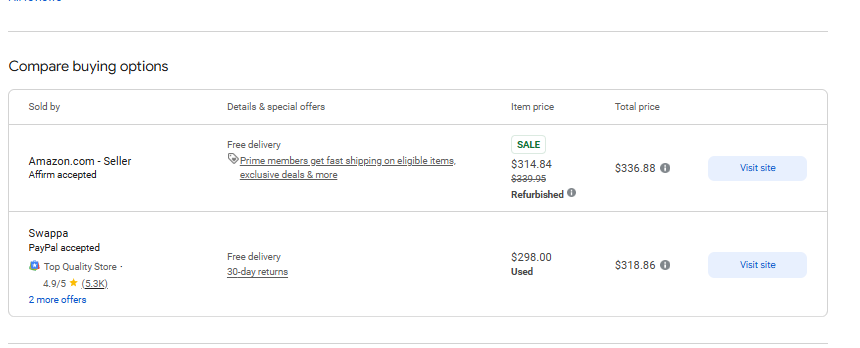
Bước 3. Lấy dữ liệu cụ thể
Như hình ảnh hiển thị, dữ liệu chúng ta cần nằm dưới tr[jscontroller='d5bMlb']:
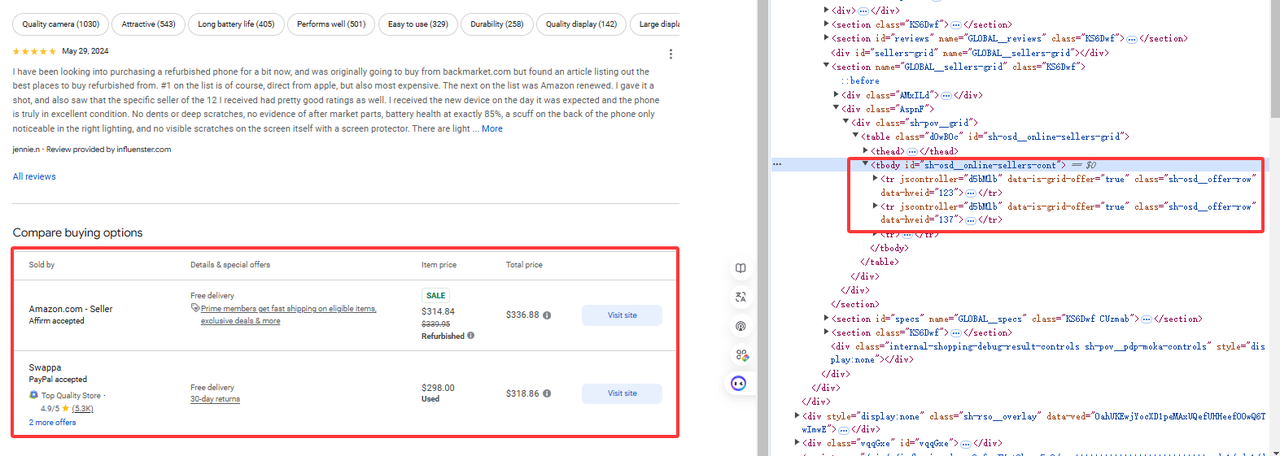
online_sellers = []
soup = BeautifulSoup(response.content, 'html.parser')
for i, row in enumerate(soup.find_all("tr", {"jscontroller": "d5bMlb"})):
name = row.find("a").get_text(strip=True)
payment_methods = row.find_all("div")[1].get_text(strip=True)
link = row.find("a")['href']
details_and_offers_text = row.find_all("td")[1].get_text(strip=True)
base_price = row.find("span", class_="g9WBQb fObmGc").get_text(strip=True)
badge = row.find("span", class_="XhDkmd").get_text(strip=True) if row.find("span", class_="XhDkmd") else ""
link = f"https://www.google.com/{link}"
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_sellers.append({
'name' : name,
'payment_methods' : payment_methods,
'link' : link,
'direct_link' : direct_link,
'details_and_offers' : [{"text": details_and_offers_text}],
'base_price' : base_price,
'badge' : badge
})Sau đó sử dụng BeautifulSoup để phân tích cú pháp trang HTML và lấy các phần tử có liên quan:
Mã hoàn chỉnh
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse, parse_qs
class AdditionalPrice:
def __init__(self, shipping, tax):
self.shipping = shipping
self.tax = tax
class OnlineSeller:
def __init__(self, position, name, payment_methods, link, direct_link, details_and_offers, base_price,
additional_price, badge, total_price):
self.position = position
self.name = name
self.payment_methods = payment_methods
self.link = link
self.direct_link = direct_link
self.details_and_offers = details_and_offers
self.base_price = base_price
self.additional_price = additional_price
self.badge = badge
self.total_price = total_price
def sellers_results(url):
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/jpeg,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "no-cache",
"Pragma": "no-cache",
"Priority": "u=0, i",
"Sec-Ch-Ua": '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
online_sellers = []
for i, row in enumerate(soup.find_all("tr", {"jscontroller": "d5bMlb"})):
name = row.find("a").get_text(strip=True)
payment_methods = row.find_all("div")[1].get_text(strip=True)
link = row.find("a")['href']
details_and_offers_text = row.find_all("td")[1].get_text(strip=True)
base_price = row.find("span", class_="g9WBQb fObmGc").get_text(strip=True)
badge = row.find("span", class_="XhDkmd").get_text(strip=True) if row.find("span", class_="XhDkmd") else ""
link = f"https://www.google.com/{link}"
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_sellers.append({
'name' : name,
'payment_methods' : payment_methods,
'link' : link,
'direct_link' : direct_link,
'details_and_offers' : [{"text": details_and_offers_text}],
'base_price' : base_price,
'badge' : badge
})
return online_sellers
url = 'https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8'
sellers = sellers_results(url)
for seller in sellers:
print(seller)Kết quả in ra màn hình như sau:

Hạn chế
Tất nhiên, chúng ta có thể lấy dữ liệu trở lại bằng ví dụ trên về việc lấy dữ liệu một phần, nhưng có nguy cơ bị chặn IP. Chúng ta không thể thực hiện các yêu cầu lớn, điều này sẽ kích hoạt kiểm soát rủi ro sản phẩm của Google.
Phương pháp 3: Tích xuất dữ liệu người bán trực tuyến sản phẩm Google bằng Selenium
Trong phương pháp này, chúng ta sẽ tìm hiểu cách sử dụng Selenium, một công cụ tự động hóa web mạnh mẽ, để tích xuất dữ liệu danh sách sản phẩm Google từ các người bán trực tuyến. Không giống như Requests và BeautifulSoup, Selenium cho phép chúng ta tương tác với các trang động cần JavaScript để thực thi, điều này làm cho nó hoàn hảo để tích xuất dữ liệu danh sách sản phẩm Google tải nội dung một cách động.
Bước 1: Thiết lập môi trường
Đầu tiên, hãy chắc chắn rằng bạn đã cài đặt Python trên hệ thống của mình. Và tạo một thư mục mới để lưu trữ mã cho dự án này. Tiếp theo, bạn cần cài đặt selenium và webdriver_manager. Bạn có thể làm điều này thông qua PIP:
pip install selenium
pip install webdriver_managerBước 2: Khởi tạo môi trường selenium
Bây giờ, chúng ta cần thêm một số mục cấu hình của selenium và khởi tạo môi trường.
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)Bước 3: Lấy dữ liệu cụ thể
Chúng ta sử dụng selenium để lấy sản phẩm có product_id là 4172129135583325756 và lấy một số dữ liệu của OnlineSeller
driver.get(url)
time.sleep(5) #wait page
online_sellers = []
rows = driver.find_elements(By.CSS_SELECTOR, "tr[jscontroller='d5bMlb']")
for i, row in enumerate(rows):
name = row.find_element(By.TAG_NAME, "a").text.strip()
payment_methods = row.find_elements(By.TAG_NAME, "div")[1].text.strip()
link = row.find_element(By.TAG_NAME, "a").get_attribute('href')
details_and_offers_text = row.find_elements(By.TAG_NAME, "td")[1].text.strip()
base_price = row.find_element(By.CSS_SELECTOR, "span.g9WBQb.fObmGc").text.strip()
badge = row.find_element(By.CSS_SELECTOR, "span.XhDkmd").text.strip() if row.find_elements(By.CSS_SELECTOR, "span.XhDkmd") else ""Mã hoàn chỉnh
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
from urllib.parse import urlparse, parse_qs
class AdditionalPrice:
def __init__(self, shipping, tax):
self.shipping = shipping
self.tax = tax
class OnlineSeller:
def __init__(self, position, name, payment_methods, link, direct_link, details_and_offers, base_price, additional_price, badge, total_price):
self.position = position
self.name = name
self.payment_methods = payment_methods
self.link = link
self.direct_link = direct_link
self.details_and_offers = details_and_offers
self.base_price = base_price
self.additional_price = additional_price
self.badge = badge
self.total_price = total_price
def sellers_results(url):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
try:
driver.get(url)
time.sleep(5)
online_sellers = []
rows = driver.find_elements(By.CSS_SELECTOR, "tr[jscontroller='d5bMlb']")
for i, row in enumerate(rows):
name = row.find_element(By.TAG_NAME, "a").text.strip()
payment_methods = row.find_elements(By.TAG_NAME, "div")[1].text.strip()
link = row.find_element(By.TAG_NAME, "a").get_attribute('href')
details_and_offers_text = row.find_elements(By.TAG_NAME, "td")[1].text.strip()
base_price = row.find_element(By.CSS_SELECTOR, "span.g9WBQb.fObmGc").text.strip()
badge = row.find_element(By.CSS_SELECTOR, "span.XhDkmd").text.strip() if row.find_elements(By.CSS_SELECTOR, "span.XhDkmd") else ""
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_seller = {
'name': name,
'payment_methods': payment_methods,
'link': link,
'direct_link': direct_link,
'details_and_offers': [{"text": details_and_offers_text}],
'base_price': base_price,
'badge': badge
}
online_sellers.append(online_seller)
return online_sellers
finally:
driver.quit()
url = 'https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8'
sellers = sellers_results(url)
for seller in sellers:
print(seller)Kết quả in ra màn hình như sau:

Hạn chế
Selenium là một công cụ mạnh mẽ để tự động hóa các hoạt động của trình duyệt web và được sử dụng rộng rãi trong kiểm thử tự động và thu thập dữ liệu web. Tuy nhiên, nó cần phải đợi trang tải xong, vì vậy nó tương đối chậm trong quá trình thu thập dữ liệu.
Câu hỏi thường gặp
Những phương pháp tốt nhất để tích xuất dữ liệu danh sách sản phẩm Google ở quy mô lớn là gì?
Phương pháp hiệu quả nhất để tích xuất dữ liệu sản phẩm Google quy mô lớn là sử dụng Scrapeless. Nó cung cấp một API nhanh chóng và có khả năng mở rộng, xử lý nội dung động, chặn IP và CAPTCHA một cách hiệu quả, làm cho nó lý tưởng cho các doanh nghiệp.
Làm thế nào để tôi bỏ qua các biện pháp chống tích xuất dữ liệu của Google khi tích xuất dữ liệu danh sách sản phẩm?
Google sử dụng một số biện pháp chống tích xuất dữ liệu, bao gồm CAPTCHA và chặn IP. Scrapeless cung cấp một API bỏ qua các biện pháp này và đảm bảo trích xuất dữ liệu trơn tru, không bị gián đoạn.
Tôi có thể sử dụng các thư viện Python như BeautifulSoup hoặc Selenium để tích xuất dữ liệu danh sách sản phẩm Google không?
Mặc dù BeautifulSoup và Selenium có thể được sử dụng để tích xuất dữ liệu danh sách sản phẩm Google, nhưng chúng có những hạn chế như hiệu suất chậm, nguy cơ bị phát hiện và không thể mở rộng. Scrapeless cung cấp một giải pháp hiệu quả hơn xử lý tất cả các vấn đề này.
Kết luận
Trong bài viết này, chúng tôi đã thảo luận ba phương pháp để tích xuất dữ liệu người bán trực tuyến sản phẩm Google: Requests & BeautifulSoup, Selenium và Scrapeless. Mỗi phương pháp đều có những ưu điểm riêng, nhưng khi nói đến việc xử lý tích xuất dữ liệu quy mô lớn, Scrapeless chắc chắn là lựa chọn tốt nhất cho các doanh nghiệp.
- Requests & BeautifulSoup phù hợp với các tác vụ tích xuất dữ liệu quy mô nhỏ nhưng gặp hạn chế khi xử lý nội dung động hoặc khi mở rộng quy mô. Các công cụ này cũng có nguy cơ bị chặn bởi các biện pháp chống tích xuất dữ liệu.
- Selenium hiệu quả đối với các trang được hiển thị bằng JavaScript, nhưng nó sử dụng nhiều tài nguyên và chậm hơn các tùy chọn khác, làm cho nó ít lý tưởng hơn cho việc tích xuất dữ liệu danh sách sản phẩm Google quy mô lớn.
Mặt khác, Scrapeless giải quyết tất cả các thách thức liên quan đến các phương pháp tích xuất dữ liệu truyền thống. Nó nhanh chóng, đáng tin cậy và hợp pháp, đảm bảo rằng bạn có thể tích xuất dữ liệu người bán trực tuyến sản phẩm Google một cách hiệu quả ở quy mô lớn mà không phải lo lắng về việc bị chặn hoặc gặp phải các trở ngại khác.
Đối với các doanh nghiệp đang tìm kiếm một giải pháp hợp lý, có khả năng mở rộng, Scrapeless là công cụ cần thiết. Nó bỏ qua tất cả các trở ngại của các phương pháp thông thường và cung cấp trải nghiệm mượt mà, không rắc rối để thu thập dữ liệu sản phẩm Google.
Hãy dùng thử Scrapeless ngay hôm nay với phiên bản dùng thử miễn phí và khám phá xem việc mở rộng quy mô các tác vụ tích xuất dữ liệu sản phẩm Google của bạn dễ dàng như thế nào. Bắt đầu dùng thử miễn phí ngay bây giờ.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


