
Lập trình Web Scraping là gì? Làm thế nào để lấy dữ liệu từ một trang web?
Senior Web Scraping Engineer
Web scraping là quá trình tự động trích xuất dữ liệu từ các trang web, chuyển đổi dữ liệu web không cấu trúc hoặc bán cấu trúc thành các định dạng có cấu trúc như CSV hoặc JSON.
Kỹ thuật này đã thu hút được sự chú ý đáng kể do sự phụ thuộc ngày càng tăng vào dữ liệu để ra quyết định trong nhiều ngành công nghiệp, bao gồm thương mại điện tử, tài chính, tiếp thị và nghiên cứu.
Sử dụng dịch vụ web scraping đáng tin cậy có thể làm tăng thêm hiệu quả của quá trình trích xuất dữ liệu. Điều này đặc biệt quan trọng đối với việc thực hiện nghiên cứu thị trường, thúc đẩy tạo lead cho các nhóm bán hàng và tiếp thị, và cung cấp giám sát giá cả cho các doanh nghiệp bán lẻ và du lịch cạnh tranh.
Web scraping là gì và làm thế nào để scrape một trang web liền mạch?
Tìm hiểu hướng dẫn chi tiết trong bài viết này!
Web scraping là gì?
Web scraping liên quan đến việc sử dụng phần mềm hoặc script để thu thập và xử lý thông tin từ các trang web. Không giống như thu thập dữ liệu thủ công, web scraping tự động hóa quá trình trích xuất, làm cho nó hiệu quả hơn và có thể mở rộng hơn. Mục tiêu chính là thu thập thông tin hành động hoặc tập dữ liệu lớn để phân tích, nghiên cứu hoặc tích hợp vào các ứng dụng.
Web scraping đóng một vai trò quan trọng trong việc cung cấp dữ liệu cho các mô hình máy học, thúc đẩy hơn nữa sự phát triển của công nghệ trí tuệ nhân tạo. Bằng cách tự động hóa quá trình thu thập dữ liệu và mở rộng dữ liệu để thu thập thông tin từ nhiều nguồn khác nhau, web scraping giúp tạo ra các mô hình trí tuệ nhân tạo mạnh mẽ, chính xác và được đào tạo tốt.
Web scraping đặc biệt hữu ích nếu trang web công cộng mà bạn muốn lấy dữ liệu không có API, hoặc chỉ cung cấp quyền truy cập hạn chế vào dữ liệu web!
Trong trường hợp này, các phương pháp truyền thống không thể đáp ứng được nhu cầu, và việc tận dụng các dịch vụ web scraping bên ngoài như Scrapeless có thể là một cách tiếp cận chiến lược. Các dịch vụ này cung cấp các giải pháp hiệu quả và có thể mở rộng hơn. Ngoài ra, đối với những người đang tìm kiếm các tính năng nâng cao, các công cụ như API và Scraping Browser của Scrapeless cung cấp các giải pháp toàn diện, cung cấp các tính năng như xử lý chặn, hoạt động trình duyệt tự động, quản lý phiên và cookie, và trích xuất dữ liệu hiệu quả.
Và so với các sản phẩm tương tự khác, Scrapeless cũng cung cấp giá cả rẻ hơn trong khi vẫn đảm bảo độ ổn định cao. Nó làm giảm gánh nặng chi phí cho các công ty có ngân sách hạn chế nhưng nhu cầu mạnh mẽ.
Web scraping hoạt động như thế nào?
Web scraping là quá trình tự động thu thập dữ liệu không cấu trúc và có cấu trúc. Nó cũng được biết đến rộng rãi là trích xuất dữ liệu web hoặc web data scraping.
Một số trường hợp sử dụng chính của web scraping bao gồm giám sát giá cả, thông tin giá cả, giám sát tin tức, tạo lead, và nghiên cứu thị trường, trong số những người khác.
Nói chung, nó được sử dụng bởi các cá nhân và doanh nghiệp muốn tận dụng dữ liệu web công khai để tạo ra những hiểu biết có giá trị và đưa ra quyết định thông minh hơn.
Web scraping thủ công
Nếu bạn từng sao chép và dán thông tin từ một trang web, bạn đã thực hiện cùng một chức năng như bất kỳ công cụ web scraping nào, ngoại trừ việc bạn đã thực hiện quá trình scraping dữ liệu thủ công:
- Xác định trang web mục tiêu
- Thu thập các URL của các trang mục tiêu
- Gửi yêu cầu đến các URL đó để lấy HTML của trang
- Sử dụng bộ định vị để tìm thông tin trong HTML
- Lưu dữ liệu dưới dạng tệp JSON hoặc CSV hoặc định dạng có cấu trúc khác
Điều này có vẻ đủ cho việc web scraping hàng ngày. Thật không may, nếu bạn cần trích xuất dữ liệu trên quy mô lớn, bạn cần phải giải quyết khá nhiều thách thức.
Ví dụ: nếu bố cục trang web thay đổi, duy trì các công cụ trích xuất dữ liệu và trình thu thập web, quản lý proxy, thực thi javascript, hoặc vượt qua chống bot. Đây là những vấn đề kỹ thuật tiêu tốn tài nguyên nội bộ.
Lúc này, chúng ta cần sử dụng các công cụ tự động hóa mạnh mẽ hơn - Web Scraper
Web scraper
Không giống như quá trình tẻ nhạt khi tự mình trích xuất dữ liệu, web scraping sử dụng máy học và tự động hóa thông minh để thu thập hàng triệu hoặc thậm chí hàng tỷ điểm dữ liệu được trích xuất từ internet.
- Web scraping hoạt động bằng cách gửi yêu cầu HTTP đến một trang web và tìm nạp nội dung HTML của nó.
- Sau đó, script phân tích cấu trúc HTML để định vị và trích xuất các điểm dữ liệu cụ thể bằng cách sử dụng thẻ, thuộc tính hoặc mẫu.
- Các phương pháp nâng cao có thể xử lý nội dung động được hiển thị thông qua JavaScript bằng cách mô phỏng hành vi trình duyệt bằng cách sử dụng các công cụ như Puppeteer hoặc Selenium.
Cho dù bạn tự viết một web scraper hay sử dụng một công cụ trích xuất dữ liệu web mạnh mẽ, bạn cần biết thêm về những điều cơ bản của web scraping hoặc trích xuất dữ liệu web!
Sự khác biệt giữa Web Scraping và Web Crawling
| Tính năng | Web Scraping | Web Crawling |
|---|---|---|
| Mục tiêu | Trích xuất dữ liệu cụ thể | Thu thập liên kết web và xây dựng chỉ mục nội dung |
| Phạm vi | Tập trung vào một số lượng nhỏ trang web và nội dung cụ thể | Thu thập một số lượng lớn trang web |
| Độ phức tạp kỹ thuật | Trung bình, chủ yếu được sử dụng để phân tích dữ liệu | Cao, cần quản lý theo dõi liên kết và loại bỏ trùng lặp |
| Công cụ phổ biến | BeautifulSoup, Puppeteer, Scrapy | Scrapy, Apache Nutch, Selenium |
| Ứng dụng chính | Phân tích dữ liệu, giám sát giá cả thương mại điện tử | Chỉ mục công cụ tìm kiếm, phân tích SEO |
Web scraping
Web scraping là một quá trình tập trung được sử dụng để trích xuất dữ liệu cụ thể từ một trang web và chuyển đổi nó thành một định dạng có cấu trúc, chẳng hạn như CSV hoặc JSON. Mục tiêu là lấy thông tin chính xác, chẳng hạn như giá cả, đánh giá hoặc chi tiết sản phẩm, để phân tích hoặc sử dụng thêm. Scrapers sử dụng các công cụ như XPath, bộ chọn CSS hoặc regex để định vị và trích xuất dữ liệu mong muốn một cách hiệu quả.
Web crawling
Web crawling, thường được gọi là "spidering", là một quá trình tự động duyệt internet để lập chỉ mục và thu thập các trang web bằng cách theo dõi các liên kết. Trình thu thập web thường được sử dụng để xây dựng các tập dữ liệu hoặc chỉ mục lớn, như các chỉ mục cho công cụ tìm kiếm. Trong một số dự án, web crawling là bước chuẩn bị để thu thập URL, sau đó được xử lý bởi một web scraper để trích xuất dữ liệu cụ thể.
2 Phương pháp Web Scraping phổ biến để Scrape một trang web
Để giúp bạn hiểu rõ hơn về cách scrape một trang web, chúng ta sẽ sử dụng 2 công cụ thu thập dữ liệu phổ biến và mạnh mẽ: Scraping API và Scraping Browser để scrape Google Trends.
Scraping API
Với Scraping API tiên tiến, bạn có thể dễ dàng truy cập và scrape dữ liệu Google Trends mà không cần viết hoặc duy trì các script scraping phức tạp. Chỉ cần gọi API mà chúng tôi cung cấp để nhanh chóng nhận được tất cả thông tin bạn cần.
Bạn có thể dễ dàng scrape các danh mục dữ liệu Google Trends như:
- Sự quan tâm theo thời gian
- Phân tích so sánh theo khu vực
- Sự quan tâm theo tiểu vùng
- Các truy vấn liên quan
- Các chủ đề liên quan
Hãy xem các bước chi tiết:
- Bước 1. Đăng nhập vào Scrapeless
- Bước 2. Nhấp vào "Scraping API"
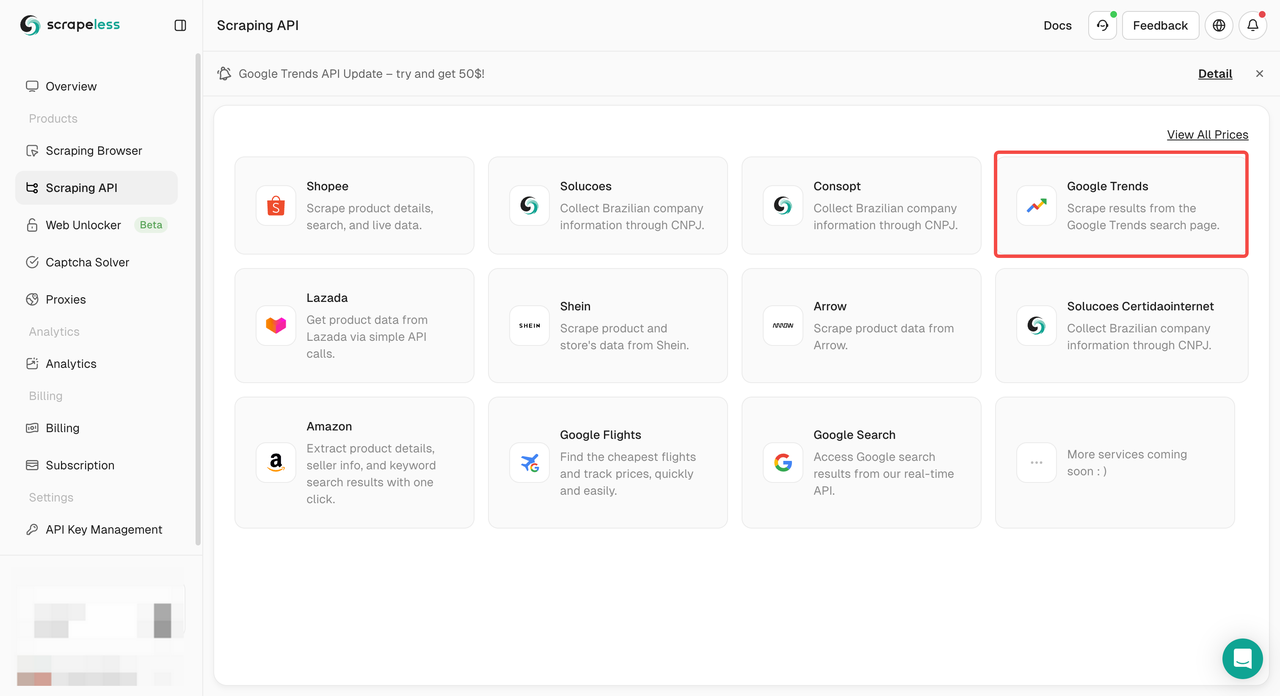
- Bước 3. Tìm bảng điều khiển "Google Trends" của chúng tôi và nhập vào đó:
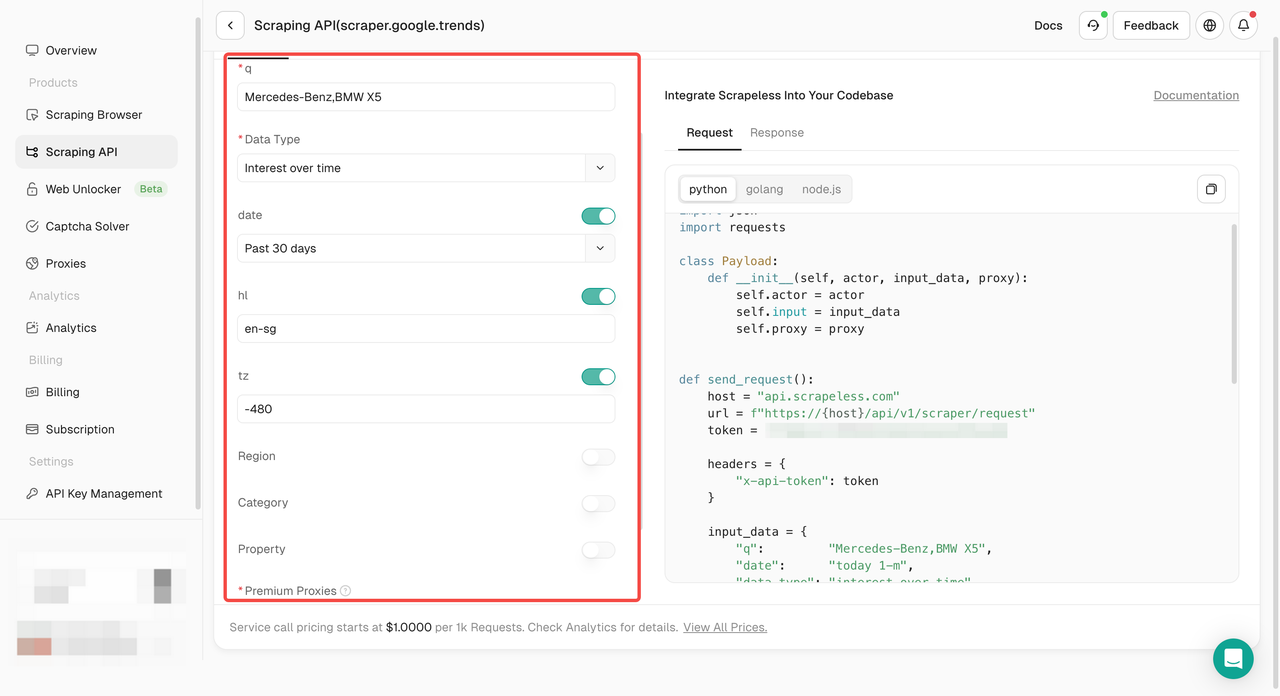
- Bước 4. Cấu hình dữ liệu của bạn trong bảng điều khiển hoạt động bên trái:
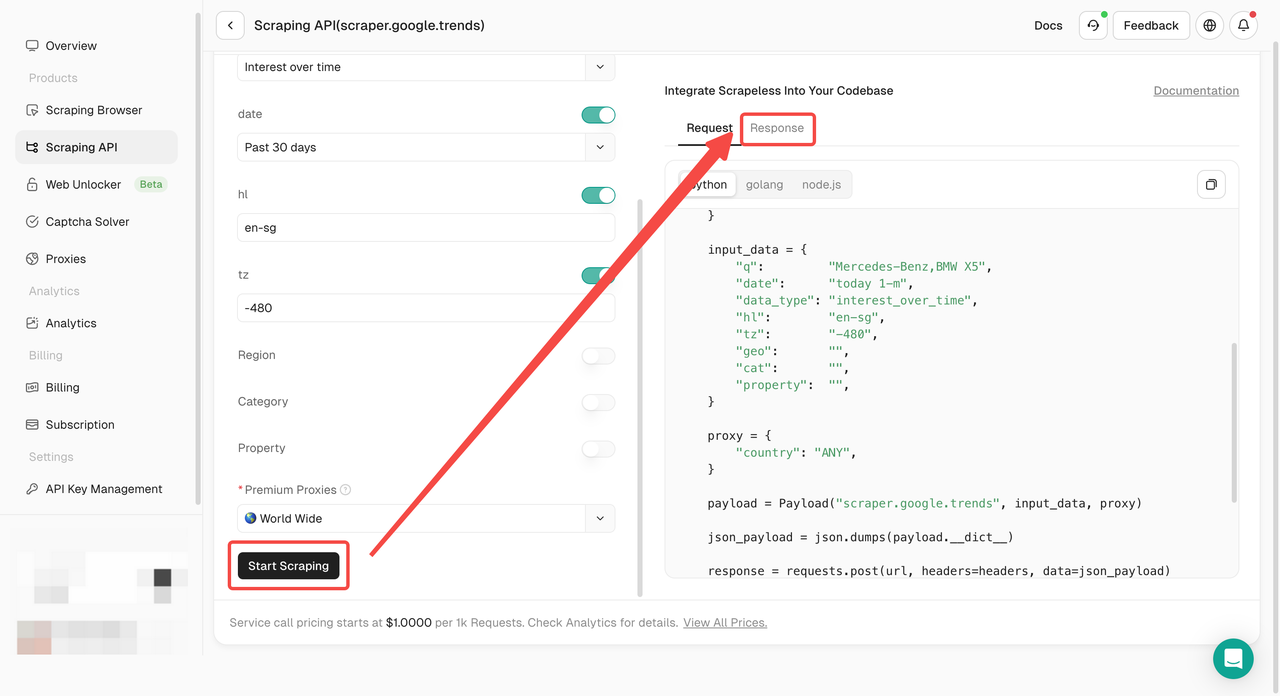
- Bước 5. Nhấp vào nút "Start Scraping" và sau đó bạn có thể nhận được kết quả:
Hoặc bạn có thể triển khai API của chúng tôi vào dự án của riêng bạn như:
- Python
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.trends",
"input": {
"keywords": "Mercedes-Benz,BMW X5",
"geo": "",
"time": "today 1-m",
"category": "0",
"property": ""
},
"proxy": {
"country": "US"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.trends",
"input": {
"data_type": "autocomplete",
"q": "Mercedes-Benz"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}Scraping Browser
Yêu cầu:
- Node.js: Đảm bảo phiên bản 14 trở lên đã được cài đặt.
- npm: Trình quản lý gói Node để xử lý các phụ thuộc.
- Dịch vụ Scrapeless Browserless: Sử dụng dịch vụ trình duyệt do Scrapeless cung cấp.
Sau đó, hãy truy cập bảng điều khiển Scraping Browser, điều hướng đến tab "Settings" và lấy khóa API của bạn.
Sau đó, hãy làm theo các bước của chúng tôi:
- Cài đặt các phụ thuộc cần thiết bằng:
Bash
npm install- Thiết lập biến môi trường
Tạo tệp .env trong thư mục gốc của dự án và thêm khóa API của bạn như sau:
Bash
API_KEY=your_scrapeless_api_key- Tùy chỉnh tham số script
Script được cấu hình sẵn để tìm nạp xu hướng cho "youtube" và "twitter" tại Hoa Kỳ trong 7 ngày qua. Bạn có thể điều chỉnh các cài đặt sau:
- Từ khóa: Thay đổi tham số q trong biến
QUERY_PARAMSđể thay đổi các thuật ngữ tìm kiếm. - Vị trí địa lý: Cập nhật tham số
geođể đặt vị trí mong muốn. - Phạm vi ngày: Điều chỉnh tham số
datedựa trên khoảng thời gian bạn muốn phân tích.
- Đặt Cookie
Để ổn định dữ liệu liên quan đến sự thay đổi sở thích theo thời gian, hãy cấu hình cookie bằng Puppeteer trước khi truy cập trang web:
JavaScript
const cookies = JSON.parse(fs.readFileSync('./data/cookies.json', 'utf-8'));
await browser.setCookie(...cookies);Để tạo tệp cookies.json, hãy đăng nhập vào Google Trends thông qua trình duyệt của bạn và xuất cookie ở định dạng JSON. Nếu bạn không chắc chắn cách thực hiện việc này, hãy xem xét sử dụng tiện ích mở rộng trình duyệt được thiết kế để xuất cookie.
- Thực thi script bằng Node.js:
Bash
node index.jsWeb scraping có thể được sử dụng để làm gì?
Thông tin giá cả
Đúng vậy, thông tin giá cả là trường hợp sử dụng lớn nhất của web scraping.
Trích xuất thông tin sản phẩm và giá cả từ các trang web thương mại điện tử và sau đó biến nó thành thông tin tình báo là một thành phần quan trọng của các công ty thương mại điện tử hiện đại đang tìm cách đưa ra quyết định về giá cả/tiếp thị tốt hơn dựa trên dữ liệu.
Lợi ích của dữ liệu giá web và thông tin giá cả:
- Giá cả động
- Tối ưu hóa doanh thu
- Giám sát đối thủ cạnh tranh
- Giám sát xu hướng sản phẩm
- Tuân thủ thương hiệu và MAP
Nghiên cứu thị trường
Nghiên cứu thị trường rất quan trọng và nên được thúc đẩy bởi thông tin chính xác nhất. Với scraping dữ liệu, bạn có quyền truy cập vào dữ liệu web được scraping với chất lượng cao, khối lượng lớn, thông tin chi tiết cao ở mọi hình dạng và kích thước đang thúc đẩy phân tích thị trường và thông tin tình báo kinh doanh trên toàn thế giới.
- Phân tích xu hướng thị trường
- Giá cả thị trường
- Tối ưu hóa điểm vào
- Nghiên cứu và phát triển
- Giám sát đối thủ cạnh tranh
Dữ liệu thay thế tài chính
Khám phá alpha và tạo ra giá trị từ đầu với dữ liệu web được thiết kế cho các nhà đầu tư.
Ra quyết định chưa bao giờ thông minh hơn và dữ liệu chưa bao giờ có nhiều thông tin chi tiết hơn - dữ liệu web được scraping ngày càng được sử dụng bởi các công ty hàng đầu thế giới vì giá trị chiến lược đáng kinh ngạc của nó.
- Trích xuất thông tin từ hồ sơ SEC
- Đánh giá cơ bản của công ty
- Tích hợp dư luận công khai
- Giám sát tin tức
Bất động sản
Sự chuyển đổi kỹ thuật số của bất động sản trong hai thập kỷ qua có khả năng phá vỡ các doanh nghiệp truyền thống và làm nảy sinh những người chơi mới mạnh mẽ trong ngành.
Bằng cách kết hợp dữ liệu bất động sản được scraping từ web vào hoạt động hàng ngày, các đại lý và môi giới có thể tránh được sự cạnh tranh trực tuyến từ trên xuống và đưa ra quyết định thông minh trên thị trường.
- Đánh giá giá trị tài sản
- Giám sát tỷ lệ trống
- Năng suất cho thuê ước tính
- Hiểu hướng thị trường
Giám sát tin tức và nội dung
Phương tiện truyền thông hiện đại có thể tạo ra giá trị nổi bật hoặc mối đe dọa hiện hữu đối với doanh nghiệp của bạn trong một chu kỳ tin tức duy nhất.
Nếu công ty của bạn dựa vào phân tích tin tức kịp thời, hoặc là một công ty thường xuyên xuất hiện trên các bản tin, thì việc scraping dữ liệu tin tức là giải pháp tối ưu để giám sát, tổng hợp và phân tích các tin tức quan trọng nhất trong ngành của bạn.
- Quyết định đầu tư
- Phân tích dư luận công khai trực tuyến
- Giám sát đối thủ cạnh tranh
- Chiến dịch chính trị
- Phân tích cảm xúc
Tạo lead
Tạo lead là một hoạt động tiếp thị/bán hàng quan trọng đối với tất cả các doanh nghiệp.
Trong một báo cáo của Hubspot năm 2024, 65% nhà tiếp thị inbound cho biết tạo lưu lượng truy cập và lead là thách thức lớn nhất của họ. May mắn thay, trích xuất dữ liệu web có thể được sử dụng để có được danh sách lead có cấu trúc từ web.
Giám sát thương hiệu
Trên thị trường cạnh tranh ngày nay, bảo vệ danh tiếng trực tuyến của bạn là ưu tiên hàng đầu.
Cho dù bạn bán sản phẩm trực tuyến và cần thực thi chính sách giá cả nghiêm ngặt, hay bạn chỉ muốn biết mọi người xem sản phẩm của bạn như thế nào trực tuyến, giám sát thương hiệu bằng web scraping có thể cung cấp cho bạn thông tin đó.
Tự động hóa doanh nghiệp
Trong một số trường hợp, việc truy cập dữ liệu có thể rất khó khăn. Có thể bạn cần trích xuất dữ liệu từ trang web của riêng bạn hoặc của đối tác theo cách có cấu trúc.
Nhưng không có cách dễ dàng nào để làm điều này trong nội bộ, vì vậy đây là một động thái thông minh để tạo một công cụ scraping và scrape dữ liệu trực tiếp. Thay vì cố gắng tìm ra nó với các hệ thống nội bộ phức tạp.
Giám sát MAP
Giám sát Giá quảng cáo tối thiểu (MAP) là một hoạt động tiêu chuẩn để đảm bảo rằng giá cả trực tuyến của một thương hiệu phù hợp với chính sách giá cả của nó.
Giám sát giá cả thủ công là không thể vì số lượng lớn các đại lý và nhà phân phối.
Đó là lý do tại sao web scraping rất thuận tiện vì bạn có thể dễ dàng theo dõi giá cả của sản phẩm.
Làm thế nào để Scrape một trang web miễn phí?
Có rất nhiều giải pháp web scraping miễn phí có sẵn để tự động scraping nội dung và trích xuất dữ liệu từ web. Các giải pháp này bao gồm các giải pháp scraping chỉ cần nhấp và kéo đơn giản dành cho những người không chuyên đến các ứng dụng tập trung vào nhà phát triển mạnh mẽ hơn với nhiều tùy chọn cấu hình và quản lý.
Scraping API và Scraping Browser sẽ trở thành những công cụ mạnh mẽ nhất phù hợp với sự phát triển của xã hội Internet. Chúng có bộ mở khóa web, proxy và CAPTCHA tích hợp sẵn, v.v., làm cho việc web scraping của bạn thuận tiện và nhanh hơn.
Chỉ cần các thao tác cấu hình đơn giản là có thể nhận được dữ liệu chính xác nhất ngay lập tức.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


