
Bạn có thể nhận được những tham số phản hồi nào trên Scrapeless?
Senior Web Scraping Engineer
Trong các kịch bản thu thập dữ liệu trên web hiện đại, việc đơn giản chỉ lấy các trang HTML thường không đủ để đáp ứng nhu cầu kinh doanh khi phải đối mặt với các cơ chế chống thu thập dữ liệu tinh vi. Tại Scrapeless, chúng tôi vẫn cam kết nâng cao khả năng sản phẩm từ góc độ của nhà phát triển.
Hôm nay, chúng tôi rất phấn khích thông báo một bản cập nhật quan trọng cho một trong những dịch vụ cốt lõi của Scrapeless — API Thu Thập Dữ Liệu Chung. Web Unlocker hiện hỗ trợ nhiều định dạng phản hồi khác nhau! Cải tiến này nâng cao đáng kể sự linh hoạt của API, mang đến một trải nghiệm thu thập dữ liệu thích ứng và hiệu quả hơn cho người dùng doanh nghiệp và các nhà phát triển.
Tại Sao Chúng Tôi Thực Hiện Bản Cập Nhật?
Trước đây, API Thu Thập Dữ Liệu Chung mặc định trả về nội dung trang HTML, điều này phù hợp cho việc truy cập nhanh các trang không mã hóa hoặc các trang web có biện pháp chống thu thập dữ liệu yếu hơn. Tuy nhiên, khi nhu cầu tự động hóa của người dùng tăng lên, chúng tôi nhận thấy rằng nhiều người dùng vẫn phải xử lý thủ công các cấu trúc dữ liệu, làm sạch nội dung và trích xuất các phần tử sau khi lấy được HTML — gây ra gánh nặng phát triển không cần thiết. Chúng tôi có thể tối ưu hóa quy trình này để cung cấp nội dung đã được xử lý trước trong một bước không?
Bây giờ bạn có thể!
Chúng tôi đã cải tiến logic phản hồi. Bằng cách cấu hình tham số response_type, các nhà phát triển có thể linh hoạt chỉ định định dạng dữ liệu mong muốn. Dù bạn cần HTML thô, văn bản thuần, hay siêu dữ liệu có cấu trúc, chỉ cần cấu hình tham số đơn giản là đủ.
Bây Giờ, Các Định Dạng Phản Hồi Bạn Có Thể Nhận:
Các định dạng hiện tại được hỗ trợ bao gồm nhưng không giới hạn ở:
- Bộ lọc đầu ra JSON: Sử dụng tham số
outputsđể lọc dữ liệu định dạng JSON. Các loại bộ lọc cho phép bao gồmemail,phone_numbers,headings, và 9 loại khác, với kết quả được trả về trong JSON có cấu trúc. - Nhiều định dạng trả về: Ngoài việc lọc JSON, bạn có thể trực tiếp chỉ định định dạng phản hồi bằng cách thêm tham số
response_typevào yêu cầu của bạn (ví dụ:response_type=plaintext).
Các định dạng hiện tại được hỗ trợ bao gồm:
HTML: Trích xuất nội dung trang ở định dạng HTML (lý tưởng cho các trang tĩnh).Plaintext: Trả về nội dung thu thập được dưới dạng văn bản thuần, không có thẻ HTML hoặc định dạng Markdown—hoàn hảo cho xử lý hoặc phân tích văn bản.Markdown: Trích xuất nội dung trang ở định dạng Markdown (tối ưu cho các trang dựa trên Markdown tĩnh), giúp dễ đọc và xử lý hơn.PNG/JPEG: Bằng cách đặtresponse_type=png, chụp ảnh màn hình của trang mục tiêu và trả về ở định dạng PNG hoặc JPEG (với tùy chọn cho ảnh chụp toàn trang).
Chú ý: Định dạng phản hồi mặc định là html.
Hãy Cùng Tìm Hiểu Ví Dụ
1. Bộ lọc giá trị trả về JSON:
Bạn có thể sử dụng tham số outputs để lọc dữ liệu ở định dạng JSON. Khi tham số này được đặt, loại phản hồi sẽ bị cố định thành JSON.
Tham số này chấp nhận một danh sách tên bộ lọc ngăn cách bằng dấu phẩy và trả về dữ liệu ở định dạng JSON có cấu trúc. Các loại bộ lọc được hỗ trợ bao gồm: phone_numbers, headings, images, audios, videos, links, menus, hashtags, emails, metadata, tables, và favicon.
Mẫu mã bên dưới minh họa cách lấy toàn bộ thông tin hình ảnh trên trang chính của trang web scrapeless:
Javascript
JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://www.scrapeless.com",
js_render: true,
outputs: "images"
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('outputs.json', response.data.data, 'utf8');
}
})();Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.scrapeless.com",
"js_render": True,
"outputs": "images",
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('outputs.json', 'w', encoding='utf-8') as f:
f.write(response.json()["data"])- Kết quả:
JSON
{
"images": [
"data:image/svg+xml;base64,PHN2ZyBzdHJva2U9IiNGRkZGRkYiIGZpbGw9IiNGRkZGRkYiIHN0cm9rZS13aWR0aD0iMCIgdmlld0JveD0iMCAwIDI0IDI0IiBoZWlnaHQ9IjIwMHB4IiB3aWR0aD0iMjAwcHgiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+PHJlY3Qgd2lkdGg9IjIwIiBoZWlnaHQ9IjIwIiB4PSIyIiB5PSIyIiBmaWxsPSJub25lIiBzdHJva2Utd2lkdGg9IjIiIHJ4PSIyIj48L3JlY3Q+PC9zdmc+Cg==",
"https://www.scrapeless.com/_next/image?url=%2Fassets%2Fimages%2Fcode%2Fcode-l.jpg&w=3840&q=75",
plaintext
"https://www.scrapeless.com/_next/image?url=%2Fassets%2Fimages%2Fregulate-compliance.png&w=640&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fimages%2Fauthor-avatars%2Falex-johnson.png&w=48&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fdeep-serp-api-online%2Fd723e1e516e3dd956ba31c9671cde8ea.jpeg&w=3840&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fscrapeless-web-scraping-toolkit%2Fac20e5f6aaec5c78c5076cb254c2eb78.png&w=3840&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fimages%2Fauthor-avatars%2Femily-chen.png&w=48&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fgoogle-shopping-scrape%2F251f14aedd946d0918d29ef710a1b385.png&w=3840&q=75"
Plain Text
# API Scrapeless
## Tài liệu
- Trình duyệt Scraping [CDP API](https://apidocs.scrapeless.com/doc-801748.md):
- API Scraping > shopee [Danh sách Actor](https://apidocs.scrapeless.com/doc-754333.md):
- API Scraping > amazon [Tham số API](https://apidocs.scrapeless.com/doc-857373.md):
- API Scraping > tìm kiếm google [Tham số API](https://apidocs.scrapeless.com/doc-800321.md):
- API Scraping > xu hướng google [Tham số API](https://apidocs.scrapeless.com/doc-796980.md):
- API Scraping > chuyến bay google [Tham số API](https://apidocs.scrapeless.com/doc-796979.md):
- API Scraping > biểu đồ chuyến bay google [Tham số API](https://apidocs.scrapeless.com/doc-908741.md):
- API Scraping > bản đồ google [Tham số API (Bản đồ Google)](https://apidocs.scrapeless.com/doc-834792.md):
- API Scraping > bản đồ google [Tham số API (Tự động hoàn thành Bản đồ Google)](https://apidocs.scrapeless.com/doc-834799.md):
- API Scraping > bản đồ google [Tham số API (Đánh giá từ đóng góp viên Bản đồ Google)](https://apidocs.scrapeless.com/doc-834806.md):
- API Scraping > bản đồ google [Tham số API (Chỉ đường Bản đồ Google)](https://apidocs.scrapeless.com/doc-834821.md):
- API Scraping > bản đồ google [Tham số API (Đánh giá Bản đồ Google)](https://apidocs.scrapeless.com/doc-834831.md):
- API Scraping > học giả google [Tham số API (Học giả Google)](https://apidocs.scrapeless.com/doc-842638.md):
- API Scraping > học giả google [Tham số API (Tác giả Học giả Google)](https://apidocs.scrapeless.com/doc-842645.md):
- API Scraping > học giả google [Tham số API (Trích dẫn Học giả Google)](https://apidocs.scrapeless.com/doc-842647.md):
- API Scraping > học giả google [Tham số API (Hồ sơ Học giả Google)](https://apidocs.scrapeless.com/doc-842649.md):
- API Scraping > việc làm google [Tham số API](https://apidocs.scrapeless.com/doc-850038.md):
- API Scraping > mua sắm google [Tham số API](https://apidocs.scrapeless.com/doc-853695.md):
- API Scraping > khách sạn google [Tham số API](https://apidocs.scrapeless.com/doc-865231.md):
- API Scraping > khách sạn google [Các loại tài sản cho Cho thuê Kỳ nghỉ Google được hỗ trợ](https://apidocs.scrapeless.com/doc-890578.md):
- API Scraping > khách sạn google [Các loại tài sản Khách sạn Google được hỗ trợ](https://apidocs.scrapeless.com/doc-890580.md):
- API Scraping > khách sạn google [Các tiện nghi Khách sạn Google được hỗ trợ](https://apidocs.scrapeless.com/doc-890631.md):
- API Scraping > tin tức google [Tham số API](https://apidocs.scrapeless.com/doc-866643.md):
- API Scraping > lens google [Tham số API](https://apidocs.scrapeless.com/doc-866644.md):
- API Scraping > tài chính google [Tham số API](https://apidocs.scrapeless.com/doc-873763.md):
- API Scraping > sản phẩm google [Tham số API](https://apidocs.scrapeless.com/doc-880407.md):
- API Scraping [cửa hàng google play](https://apidocs.scrapeless.com/folder-3277506.md):
- API Scraping > cửa hàng google play [Tham số API](https://apidocs.scrapeless.com/doc-882690.md):
- API Scraping > cửa hàng google play [Các danh mục Google Play được hỗ trợ](https://apidocs.scrapeless.com/doc-882822.md):
- API Scraping > quảng cáo google [Tham số API](https://apidocs.scrapeless.com/doc-881439.md):
- API Scraping tổng hợp [Tài liệu JS Render](https://apidocs.scrapeless.com/doc-801406.md):
## Tài liệu API
- Người dùng [Lấy Thông tin Người dùng](https://apidocs.scrapeless.com/api-11949851.md): Lấy thông tin cơ bản về người dùng đang xác thực, bao gồm số dư tài khoản và chi tiết kế hoạch đăng ký.
- Trình duyệt Scraping [Kết nối](https://apidocs.scrapeless.com/api-11949901.md):
- Trình duyệt Scraping [Phiên đang chạy](https://apidocs.scrapeless.com/api-16890953.md): Lấy tất cả các phiên đang chạy
- Trình duyệt Scraping [URL trực tiếp](https://apidocs.scrapeless.com/api-16891208.md): Lấy URL trực tiếp của một phiên đang chạy theo ID nhiệm vụ phiên
- API Scraping > shopee [Sản phẩm Shopee](https://apidocs.scrapeless.com/api-11953650.md):
- API Scraping > shopee [Tìm kiếm Shopee](https://apidocs.scrapeless.com/api-11954010.md):
- API Scraping > shopee [Gợi ý Shopee](https://apidocs.scrapeless.com/api-11954111.md):
- API Scraping > trang web br [Cnpjreva Solutions](https://apidocs.scrapeless.com/api-11954435.md): URL mục tiêu `https://solucoes.receita.fazenda.gov.br/servicos/cnpjreva/valida_recaptcha.asp`
- API Scraping > trang web br [Certidaointernet Solutions](https://apidocs.scrapeless.com/api-12160439.md): URL mục tiêu `https://solucoes.receita.fazenda.gov.br/Servicos/certidaointernet/pj/emitir`- Scraping API > các trang web br Dịch vụ thuế: url mục tiêu
https://servicos.receita.fazenda.gov.br/servicos/cpf/consultasituacao/ConsultaPublica.asp - Scraping API > các trang web br Consopt: url mục tiêu
https://consopt.www8.receita.fazenda.gov.br/consultaoptantes - Scraping API > amazon sản phẩm:
- Scraping API > amazon người bán:
- Scraping API > amazon từ khóa:
- Scraping API > tìm kiếm google Tìm kiếm Google:
- Scraping API > tìm kiếm google Hình ảnh Google:
- Scraping API > tìm kiếm google Địa phương Google:
- Scraping API > xu hướng google Tự hoàn thành:
- Scraping API > xu hướng google Sở thích theo thời gian:
- Scraping API > xu hướng google So sánh phân bố theo vùng:
- Scraping API > xu hướng google Sở thích theo tiểu vùng:
- Scraping API > xu hướng google Câu hỏi liên quan:
- Scraping API > xu hướng google Chủ đề liên quan:
- Scraping API > xu hướng google Xu hướng hiện tại:
- Scraping API > chuyến bay google Khứ hồi:
- Scraping API > chuyến bay google Một chiều:
- Scraping API > chuyến bay google Đa thành phố:
- Scraping API > biểu đồ chuyến bay google biểu đồ:
- Scraping API > bản đồ google Bản đồ Google:
- Scraping API > bản đồ google Bản đồ Google Tự hoàn thành:
- Scraping API > bản đồ google Đánh giá của người đóng góp trên Bản đồ Google:
- Scraping API > bản đồ google Chỉ đường trên Bản đồ Google:
- Scraping API > bản đồ google Đánh giá trên Bản đồ Google:
- Scraping API > scholar google Google Scholar:
- Scraping API > scholar google Tác giả Google Scholar:
- Scraping API > scholar google Trích dẫn Google Scholar:
- Scraping API > scholar google Hồ sơ Google Scholar:
- Scraping API > việc làm google Google Jobs:
- Scraping API > mua sắm google Google Shopping:
- Scraping API > khách sạn google Google Hotels:
- Scraping API > tin tức google Google News:
- Scraping API > lens google Google Lens:
- Scraping API > tài chính google Google Finance:
- Scraping API > thị trường tài chính google Thị trường Google Finance:
- Scraping API > sản phẩm google Sản phẩm Google:
- Scraping API > cửa hàng google play Google Play Games:
- Scraping API > cửa hàng google play Google Play Books:
- Scraping API > cửa hàng google play Google Play Movies:
- Scraping API > cửa hàng google play Sản phẩm Google Play:
- Scraping API > cửa hàng google play Ứng dụng Google Play:
- Scraping API > quảng cáo google Google Ads:
- Scraping API Yêu cầu Scraper:
- Scraping API Lấy kết quả Scraper:
- Universal Scraping API JS Render:
- Universal Scraping API Web Unlocker:
- Universal Scraping API Cookie Akamaiweb:
- Universal Scraping API Cảm biến Akamaiweb:
- Crawler > Scrape Lấy dữ liệu một URL đơn:
- Trình thu thập dữ liệu > Thu thập Thu thập nhiều URL:
- Trình thu thập dữ liệu > Thu thập Hủy bỏ một công việc thu thập dữ liệu theo lô:
- Trình thu thập dữ liệu > Thu thập Lấy trạng thái của một lần thu thập dữ liệu:
- Trình thu thập dữ liệu > Thu thập Lấy trạng thái của một công việc thu thập dữ liệu theo lô:
- Trình thu thập dữ liệu > Thu thập Lấy lỗi của một công việc thu thập dữ liệu theo lô:
- Trình thu thập dữ liệu > Thu thập Thu thập nhiều URL dựa trên tùy chọn:
- Trình thu thập dữ liệu > Thu thập Hủy bỏ một công việc thu thập:
- Trình thu thập dữ liệu > Thu thập Lấy trạng thái của một công việc thu thập:
- Trình thu thập dữ liệu > Thu thập Lấy lỗi của một công việc thu thập:
- Công khai trạng thái tác giả:
- Công khai trạng thái tác giả:
### 4. Markdown
Bằng cách thêm `response_type=markdown` vào các tham số yêu cầu, Scrapeless Universal Scraping API sẽ trả về nội dung của một trang cụ thể dưới định dạng Markdown.
Ví dụ sau đây cho thấy hiệu ứng markdown của trang [Hướng dẫn nhanh Trình thu thập dữ liệu](https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started). Chúng tôi trước tiên sử dụng kiểm tra trang để lấy bộ chọn CSS của bảng.
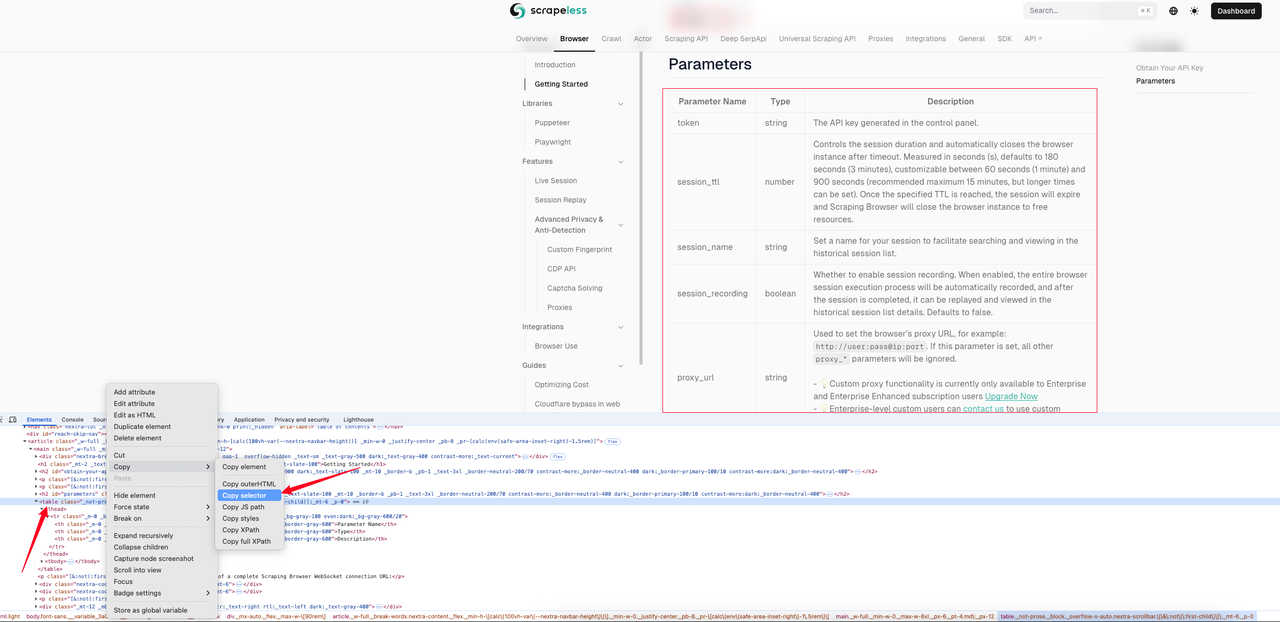
Trong ví dụ này, bộ chọn CSS mà chúng tôi nhận được là: `#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table`. Dưới đây là đoạn mã mẫu hoàn chỉnh.
> Javascript
```JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started",
js_render: true,
response_type: "markdown",
selector: "#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table", // Bộ chọn CSS của phần tử bảng trang
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('response.md', response.data.data, 'utf8');
}
})();Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started",
"js_render": True,
"response_type": "markdown",
"selector": "#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table", # Bộ chọn CSS của phần tử bảng trang
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('response.md', 'w', encoding='utf-8') as f:
f.write(response.json()["data"])Hiển thị văn bản bảng markdown đã thu thập:
Markdown
| Tên tham số | Loại | Mô tả |
| --- | --- | --- |
| token | chuỗi | Khóa API được tạo trong bảng điều khiển. |
| session_ttl | số | Kiểm soát thời gian phiên và tự động đóng phiên trình duyệt sau thời gian chờ. Đo bằng giây (s), mặc định là 180 giây (3 phút), có thể tùy chỉnh từ 60 giây (1 phút) đến 900 giây (tối đa 15 phút, nhưng thời gian dài hơn có thể được thiết lập). Khi TTL được chỉ định đạt được, phiên sẽ hết hạn và Trình thu thập dữ liệu sẽ đóng phiên trình duyệt để giải phóng tài nguyên. |
| session_name | chuỗi | Đặt tên cho phiên của bạn để dễ dàng tìm kiếm và xem trong danh sách phiên lịch sử. |
| session_recording | boolean | Có cho phép ghi lại phiên không. Khi được bật, toàn bộ quá trình thực thi phiên trình duyệt sẽ được ghi lại tự động, và sau khi phiên hoàn tất, nó có thể được phát lại và xem trong chi tiết danh sách phiên lịch sử. Mặc định là false. |
| proxy_url | chuỗi | Được sử dụng để đặt URL proxy cho trình duyệt, ví dụ: http://user:pass@ip:port. Nếu tham số này được thiết lập, tất cả các tham số proxy_* khác sẽ bị bỏ qua. - 💡 Chức năng proxy tùy chỉnh hiện tại chỉ có sẵn cho người dùng đăng ký Doanh nghiệp và Doanh nghiệp Nâng cao Nâng cấp ngay - 💡 Người dùng tùy chỉnh cấp doanh nghiệp có thể liên hệ với chúng tôi để sử dụng các proxy tùy chỉnh. |
| proxy_country | string | Đặt quốc gia/khu vực mục tiêu cho proxy, gửi yêu cầu qua địa chỉ IP từ khu vực đó. Bạn có thể chỉ định mã quốc gia (ví dụ: US cho Hoa Kỳ, GB cho Vương quốc Anh, ANY cho bất kỳ quốc gia nào). Xem mã quốc gia để biết tất cả các tùy chọn được hỗ trợ. |
| fingerprint | string | Dấu vân tay trình duyệt là một “dấu vân tay kỹ thuật số” gần như duy nhất được tạo ra bằng cách sử dụng thông tin cấu hình trình duyệt và thiết bị của bạn, có thể được sử dụng để theo dõi hoạt động trực tuyến của bạn ngay cả khi không có cookie. May mắn thay, việc cấu hình dấu vân tay trong Scraping Browser là tùy chọn. Chúng tôi cung cấp tùy chỉnh sâu về dấu vân tay trình duyệt, chẳng hạn như các tham số cốt lõi như tác nhân người dùng trình duyệt, múi giờ, ngôn ngữ và độ phân giải màn hình, và hỗ trợ mở rộng chức năng thông qua các tham số khởi chạy tùy chỉnh. Phù hợp cho việc quản lý nhiều tài khoản, thu thập dữ liệu và bảo vệ quyền riêng tư, việc sử dụng trình duyệt Chromium của scrapeless hoàn toàn tránh bị phát hiện. Theo mặc định, dịch vụ Scraping Browser của chúng tôi tạo ra một dấu vân tay ngẫu nhiên cho mỗi phiên. Tham chiếu |5. PNG/JPEG
Bằng cách thêm response_type=png vào yêu cầu, bạn có thể chụp màn hình trang mục tiêu và trả về hình ảnh png hoặc jpeg. Khi kết quả phản hồi được đặt thành png hoặc jpeg, bạn có thể thiết lập xem kết quả trả về có toàn màn hình hay không bằng cách sử dụng tham số response_image_full_page=true. Giá trị mặc định của tham số này là false.
Ví dụ mã dưới đây cho thấy cách lấy ảnh chụp màn hình của một khu vực được chỉ định trên trang chủ Scrapeless. Đầu tiên, chúng tôi tìm trình chọn CSS cho khu vực mà chúng tôi muốn chụp lại hình ảnh.
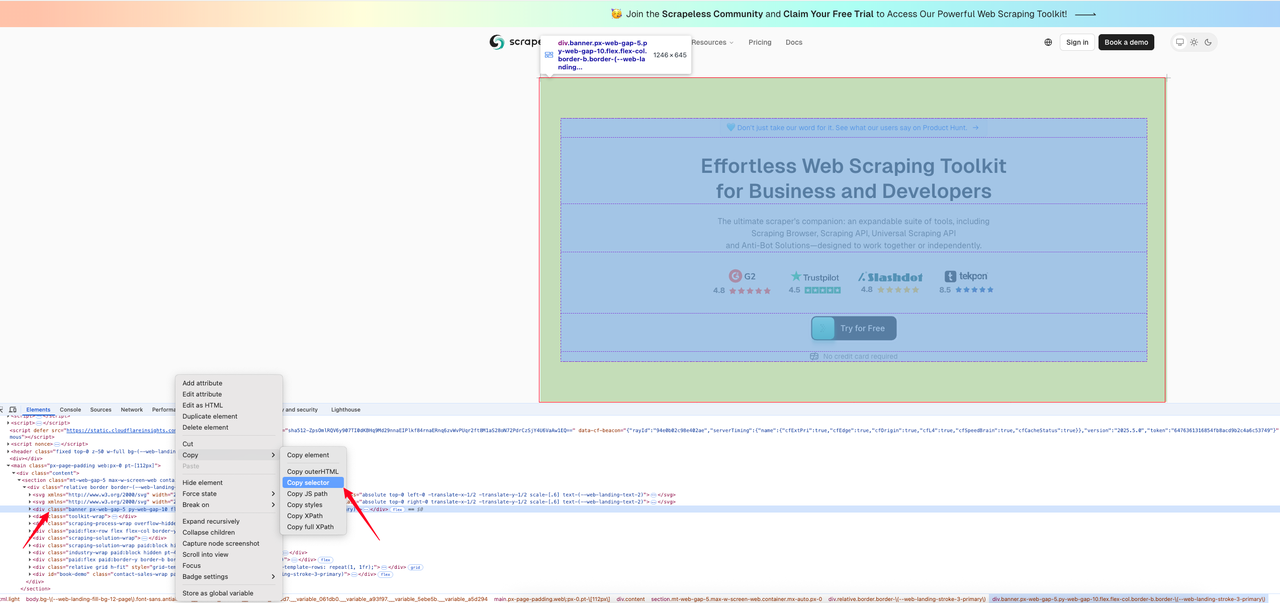
Dưới đây là mã chặn:
Javascript
JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://www.scrapeless.com/en",
js_render: true,
response_type: "png",
selector: "body > main > div > section > div > div.banner.px-web-gap-5.py-web-gap-10.flex.flex-col.border-b.border-\(--web-landing-stroke-3-primary\)", // Trình chọn CSS của phần tử bảng trang
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('response.png',Buffer.from(response.data.data, 'base64'));
}
})(); Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.scrapeless.com/en",
"js_render": True,
"response_type": "png",
"selector": "body > main > div > section > div > div.banner.px-web-gap-5.py-web-gap-10.flex.flex-col.border-b.border-\(--web-landing-stroke-3-primary\)", # Trình chọn CSS của phần tử bảng trang
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('response.png', 'wb') as f:
content = base64.b64decode(response.json()["data"])
f.write(content)- Kết quả trả về PNG:

👉 Truy cập Tài liệu Scrapeless để tìm hiểu thêm
👉 Xem tài liệu API ngay bây giờ: JS Render
Các tình huống sử dụng được bao phủ hoàn toàn
Cập nhật này đặc biệt phù hợp cho:
- Ứng dụng trích xuất nội dung (như tạo tóm tắt, thu thập thông tin)
- Crawl dữ liệu SEO (như phân tích meta, dữ liệu có cấu trúc)
- Nền tảng tổng hợp tin tức (nhanh chóng trích xuất văn bản và tác giả)
- Công cụ phân tích và giám sát liên kết (trích xuất href, thông tin nofollow)
Có thể bạn muốn nhanh chóng thu thập văn bản hoặc muốn dữ liệu có cấu trúc, cập nhật này có thể giúp bạn có được nhiều kết quả hơn với ít nỗ lực hơn.
Trải nghiệm ngay bây giờ
Chức năng đã được ra mắt hoàn toàn trên Scrapeless. Không cần sự ủy quyền bổ sung hoặc kế hoạch nâng cấp. Chỉ cần giới hạn tham số đầu ra hoặc truyền vào tham số response_type để trải nghiệm định dạng dữ liệu trả về mới!
Scrapeless luôn cam kết xây dựng một nền tảng dữ liệu web thông minh, ổn định và dễ sử dụng. Cập nhật này chỉ là một bước tiến mới. Chúng tôi chào đón trải nghiệm và phản hồi của bạn, hãy cùng nhau làm cho việc thu thập dữ liệu web dễ dàng hơn.
🔗 Hãy thử Scrapeless Universal Scraping API ngay bây giờ
📣 Tham gia cộng đồng để nhận được những cập nhật và mẹo thực tiễn đầu tiên!
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


