
Giải pháp GEO: Tự động hóa Perplexity với Trình duyệt không rác để Xây dựng động cơ phân tích nội dung
Expert Network Defense Engineer
Biến câu trả lời AI thành lợi thế kinh doanh - Giải pháp GEO của Scrapeless giúp bạn thu thập, phân tích và hành động.
Tối ưu hóa động cơ tạo ra (GEO) đang nhanh chóng trở thành một trong những xu hướng phá vỡ nhất trong ngành tìm kiếm. Khi các mô hình ngôn ngữ lớn (LLMs) định hình lại cách người dùng phát hiện thông tin, đánh giá thương hiệu và đưa ra quyết định, các doanh nghiệp không chỉ cần xuất hiện trong kết quả tìm kiếm truyền thống mà còn phải đảm bảo nội dung của họ xuất hiện trong các câu trả lời do AI tạo ra.
Tuy nhiên, đây chỉ là một khía cạnh của một sự chuyển mình lớn hơn - chúng ta đang bước vào kỷ nguyên của "tìm kiếm phổ quát": người dùng không còn chỉ phụ thuộc vào Google nữa, mà nhận được câu trả lời từ nhiều động cơ AI, ứng dụng trợ lý và mô hình dọc khác nhau. Trong bối cảnh cạnh tranh này, Perplexity đang tăng trưởng với tốc độ đáng kinh ngạc, cung cấp không chỉ câu trả lời tức thì mà còn các trích dẫn nguồn trong thời gian thực, các dòng dữ liệu và phân tích sâu sắc, làm cho nó trở thành một công cụ thiết yếu cho nghiên cứu nội dung, hiểu biết thị trường và theo dõi đối thủ.
Nguồn: Backlinko
Nhưng thách thức thực sự là: nếu bạn vẫn đang hỏi Perplexity từng câu hỏi một cách thủ công, hiệu suất của bạn sẽ không thể theo kịp tốc độ của ngành. Vì vậy, bài viết này sẽ tiết lộ cách sử dụng Scrapeless Browser để tự động hóa Perplexity, biến nó thành một động cơ phân tích nội dung hoạt động liên tục, có khả năng mở rộng giúp bạn có được lợi thế trong kỷ nguyên tìm kiếm tạo ra.
1. GEO là gì và Tại sao nó Quan trọng?
Tối ưu hóa động cơ tạo ra (GEO) là thực hành tạo ra và tối ưu hóa nội dung để nó xuất hiện trong các câu trả lời do AI tạo ra trên các nền tảng như Google AI Overviews, AI Mode, ChatGPT và Perplexity.
Trong quá khứ, thành công có nghĩa là xếp hạng cao trên các trang kết quả tìm kiếm (SERPs). Nhìn về phía trước, khái niệm "ở vị trí cao nhất" có thể sẽ không còn tồn tại. Thay vào đó, bạn cần trở thành sự lựa chọn ưu tiên - giải pháp mà các công cụ AI chọn để trình bày trong câu trả lời của họ.
Dữ liệu tự nói lên tất cả:
- Cơ sở người dùng của Perplexity đã tăng trưởng theo cấp số nhân, vượt qua 100 triệu người dùng hoạt động hàng tháng trong năm nay, đã đạt được 1/20 quy mô của Google.
- Google AI Overviews bây giờ xuất hiện trong hàng tỷ lượt tìm kiếm mỗi tháng - bao phủ ít nhất 13% tất cả các kết quả tìm kiếm.
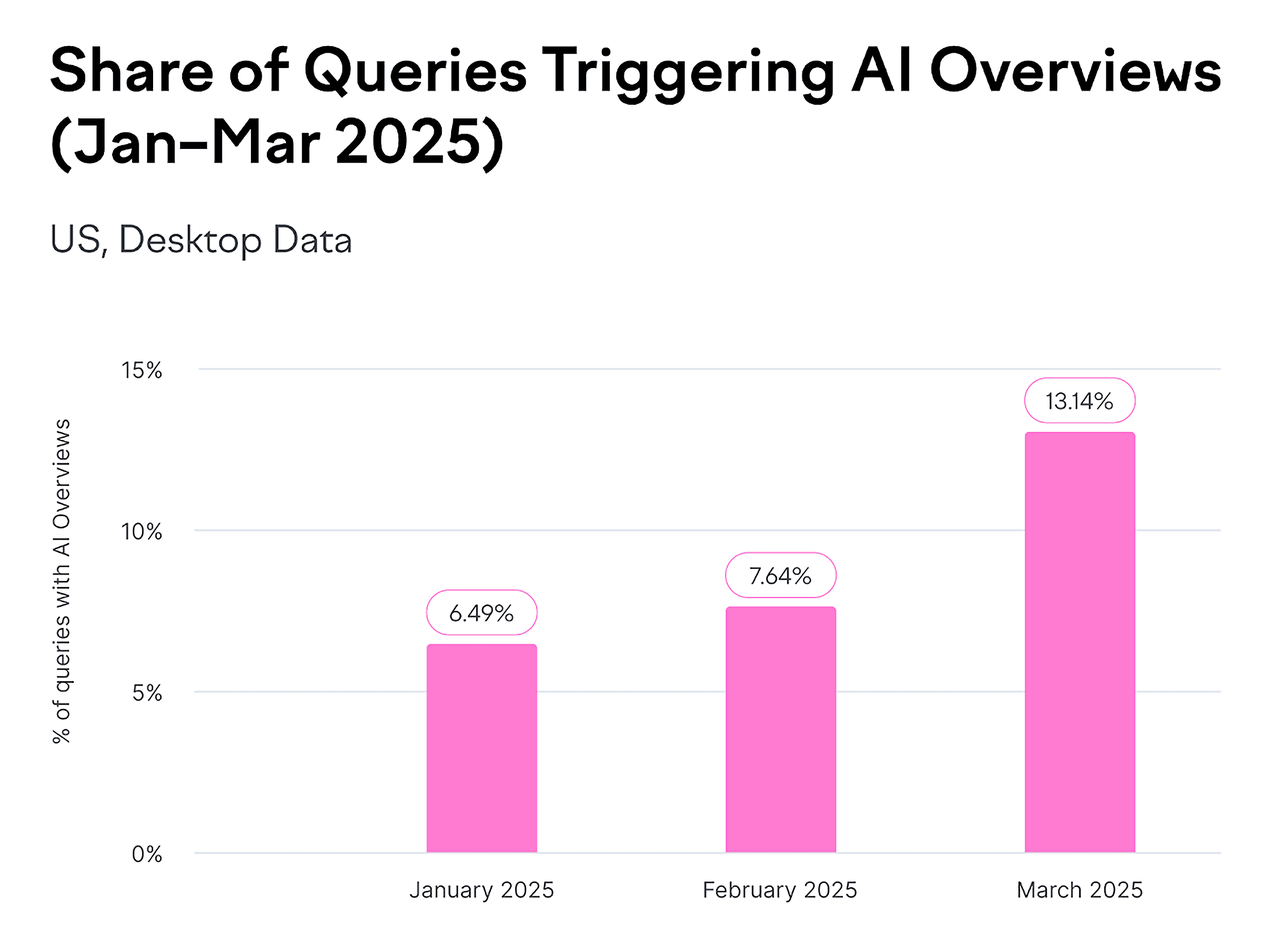
Nguồn: Backlinko
Các mục tiêu cốt lõi của tối ưu hóa GEO không còn chỉ giới hạn ở việc thu hút nhấp chuột mà tập trung vào ba chỉ số chính:
- Tính Hiển thị Thương hiệu: Tăng khả năng thương hiệu của bạn xuất hiện trong các câu trả lời do AI tạo ra.
- Uy tín Nguồn: Đảm bảo miền, nội dung hoặc dữ liệu của bạn được các mô hình chọn lựa như một tài liệu tham khảo đáng tin cậy.
- Sự Liên tục Kể chuyện & Vị trí Tích cực: Giúp AI mô tả thương hiệu của bạn một cách chuyên nghiệp, chính xác và tích cực.
Điều này có nghĩa là logic SEO truyền thống về "xếp hạng từ khóa" đang dần nhường chỗ cho cơ chế trích dẫn nguồn của AI.
Các thương hiệu phải phát triển từ việc "có thể tìm thấy" sang việc "đáng tin cậy, được trích dẫn và được giới thiệu một cách chủ động."
2. Tại sao lại Quan tâm đến Perplexity?
Perplexity AI có khoảng 15 triệu người dùng hoạt động hàng tháng, với tỷ lệ tăng trưởng tiếp tục gia tăng. Đặc biệt ở Bắc Mỹ và châu Âu, nó gần như đã trở thành đồng nghĩa với "tìm kiếm AI."
Đối với các nhóm chiến lược nội dung, SEO và phân tích thị trường, Perplexity không còn chỉ là một “công cụ tìm kiếm AI” - nó đã trở thành một “trung tâm nghiên cứu thông minh” mới.
Bạn có thể sử dụng nó để:
- So sánh sự khác biệt nội dung giữa các tối ưu hóa động cơ tạo ra
- Xem những trang web nào thường được trích dẫn cho cùng một từ khóa ở các thị trường khác nhau
- Tóm tắt nhanh các chiến lược chủ đề của đối thủ
Tuy nhiên, có những thách thức:
👉 Perplexity hiện chỉ hỗ trợ đăng ký ở nước ngoài, khiến nó không thể truy cập cho hầu hết người dùng ở Trung Quốc.
👉 Phiên bản miễn phí không cung cấp quyền truy cập API đầy đủ.
Điều này tạo ra một rào cản tự nhiên cho các doanh nghiệp hoặc nhóm nội dung: họ không thể thu thập và phân tích dữ liệu một cách hệ thống trên quy mô lớn.
3. Tại sao chọn Tự động hóa Scrapeless?
Trình duyệt Scrapeless cung cấp một cách tiếp cận thông minh hơn. Nó không chỉ đơn giản là một trình thu thập dữ liệu - mà là một phiên bản trình duyệt thực chạy trên đám mây. Bạn không cần mở Chrome trên máy tính cá nhân hoặc lo lắng về việc bị phát hiện là bot. Chỉ với một dòng mã Puppeteer, bạn có thể tương tác với các trang web giống như con người.
Ví dụ, bạn có thể:
- Mở
perplexity.ai - Tự động nhập câu hỏi
- Chờ đợi kết quả được tạo ra
- Trích xuất nội dung câu trả lời và liên kết trích dẫn
- Lưu toàn bộ trang HTML, ảnh chụp màn hình, tin nhắn WebSocket và yêu cầu mạng
Lợi thế độc đáo của Trình duyệt Scrapeless
1. Công nghệ chống phát hiện cấp doanh nghiệp
Các trang AI hiện đại như Perplexity có các biện pháp bảo vệ chống thu thập dữ liệu mạnh mẽ:
- Xác minh Cloudflare Turnstile
- Nhận diện dấu vân tay trình duyệt
- Phân tích mẫu hành vi
- Kiểm tra độ tin cậy IP
Cách Scrapeless xử lý điều này:
ts
const CONNECTION_OPTIONS = {
proxyCountry: "US", // Sử dụng IP của Mỹ
sessionRecording: "true", // Ghi lại phiên để gỡ lỗi
sessionTTL: "900", // Giữ phiên trong 15 phút
sessionName: "perplexity-scraper" // Phiên liên tục
};- Tự động mô phỏng hành vi người dùng thực
- Dấu vân tay trình duyệt ngẫu nhiên
- Công cụ giải CAPTCHA tích hợp sẵn
- Mạng proxy bao phủ 195 quốc gia
2. Mạng Proxy Toàn cầu
Các câu trả lời của Perplexity thay đổi theo vị trí người dùng:
- 🇺🇸 Người dùng Mỹ thấy nội dung địa phương của Mỹ
- 🇬🇧 Người dùng Anh thấy góc nhìn của Anh
- 🇯🇵 Người dùng Nhật Bản thấy nội dung bằng tiếng Nhật
Giải pháp Scrapeless:
ts
proxyCountry: "US" // Để có góc nhìn từ Mỹ
proxyCountry: "GB" // Để có thông tin thị trường châu Âu- Thực hiện nhiều truy vấn từ các quốc gia khác nhau để so sánh toàn cầu
- Hỗ trợ 195 nút proxy quốc gia và proxy trình duyệt tùy chỉnh
3. Tính năng duy trì phiên + Phát lại ghi âm
Khi phát triển và gỡ lỗi các kịch bản tự động hóa, những điểm đau phổ biến là:
- ❌ Không biết lỗi xảy ra ở đâu
- ❌ Không thể tái tạo vấn đề
- ❌ Thực hiện lặp đi lặp lại các kịch bản để gỡ lỗi
Phiên trực tiếp Scrapeless:
ts
sessionRecording: "true" // Bật chức năng ghi âm phiên- Xem trực tiếp: Xem quá trình tự động hóa trong trình duyệt trực tiếp
- Phát lại: Phát lại toàn bộ quá trình nếu nó thất bại
4. Chi phí bảo trì bằng không
Các giải pháp truyền thống yêu cầu:
- Puppeteer cục bộ: Bảo trì máy chủ, cập nhật Chrome, xử lý sự cố
- Trình duyệt đám mây tự quản lý: Đội ngũ DevOps, giám sát, mở rộng
- Chi phí hàng tháng: 2 kỹ sư × 20 giờ ≈ $2,000
Trình duyệt Scrapeless:
- ✅ Được lưu trữ trên đám mây, tự động cập nhật
- ✅ Cam kết thời gian hoạt động 99.9%
- ✅ Tự động mở rộng, không lo lắng về gia tăng tải
- 💰 Chi phí: trả theo mức sử dụng, khoảng $50–200/tháng
So sánh ROI:
- Truyền thống: $2,000 (lao động) + $200 (máy chủ) = $2,200/tháng
- Scrapeless: $100/tháng
- Tiết kiệm: 95%!
5. Tích hợp dễ sử dụng
Trình duyệt Scrapeless hoàn toàn tương thích với các thư viện tự động hóa chính:
- ✅ Puppeteer (Node.js)
- ✅ Playwright (Node.js / Python)
- ✅ CDP (Giao thức Công cụ Phát triển Chrome)
Chi phí chuyển đổi gần như bằng không:
ts
import puppeteer from "puppeteer-core"
// Nguyên bản: Trình duyệt cục bộ
// const browser = await puppeteer.launch();
// Chuyển đổi sang Trình duyệt Scrapeless, chỉ cần thay đổi một dòng:
const browser = await puppeteer.connect({
browserWSEndpoint: "wss://browser.scrapeless.com/api/v2/browser?token=YOUR_API_TOKEN"
})
const page = await browser.newPage()
await page.goto("https://google.com")4. Trình duyệt Scrapeless + Puppeteer: Hướng dẫn chi tiết để tự động lấy câu trả lời từ Perplexity.ai
Tiếp theo, chúng ta sẽ sử dụng Trình duyệt Scrapeless + Puppeteer để tự động truy cập Perplexity.ai, gửi câu hỏi và ghi lại câu trả lời, liên kết trang, đoạn mã HTML và dữ liệu mạng.
Không cần cài đặt Chrome cục bộ - đã sẵn sàng sử dụng ngay lập tức, với hỗ trợ cho proxy, ghi âm phiên và giám sát WebSocket.
Bước 1: Cấu hình kết nối Scrapeless
ts
const sleep = (ms) => new Promise(r => setTimeout(r, ms));
const tokenValue = process.env.SCRAPELESS_TOKEN || "YOUR_API_TOKEN";
const CONNECTION_OPTIONS = {
proxyCountry: "ANY", // Tự động chọn nút nhanh nhất
sessionRecording: "true", // Bật ghi âm phiên
sessionTTL: "900", // Giữ phiên trong 15 phút
sessionName: "perplexity-scraper", // Tên phiên
};
function buildConnectionURL(token) {
const q = new URLSearchParams({ token, ...CONNECTION_OPTIONS });
return `wss://browser.scrapeless.com/api/v2/browser?${q.toString()}`;
}- Đăng nhập vào Scrapeless để lấy mã API của bạn.

💡 Điểm chính:
proxyCountry: "ANY"tự động chọn nút nhanh nhất để giảm độ trễ.- Nếu bạn cần nội dung từ một khu vực cụ thể, chẳng hạn như tin tức của Mỹ, hãy thay đổi thành
"US". sessionRecordingcho phép phát lại trong bảng điều khiển để dễ dàng gỡ lỗi.
Bước 2: Kết nối với Trình duyệt Đám mây
ts
const connectionURL = buildConnectionURL(tokenValue);
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: { width: 1280, height: 900 }
});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(120000);
page.setDefaultTimeout(120000);
try {
await page.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
);
} catch (e) {}💡 Chú thích:
puppeteer-corenhẹ; nó kết nối với trình duyệt từ xa mà không cần tải xuống Chromium cục bộ.- Cài đặt User-Agent cho máy tính để bàn giúp tránh phát hiện chống thu thập dữ liệu cơ bản.
- Sử dụng
try-catchlà lập trình phòng ngừa để cải thiện sự vững chắc của kịch bản.
Bước 3: Giám sát Tất cả Hoạt động Mạng (Chủ yếu!)
Đây là một phần quan trọng của kịch bản! Nó thu thập hai loại dữ liệu cùng một lúc:
3.1 Lắng nghe Các Phản hồi HTTP
ts
const rawResponses = [];
page.on("response", async (res) => {
try {
const url = res.url();
const status = res.status();
const resourceType = res.request ? res.request().resourceType() : "unknown";
const headers = res.headers ? res.headers() : {};
let snippet = "";
try {
const t = await res.text();
snippet = typeof t === "string" ? t.slice(0, 20000) : String(t).slice(0, 20000);
} catch (e) {
snippet = "<read-failed>";
}
rawResponses.push({ url, status, resourceType, headers, snippet });
} catch (e) {}
});Nội dung đã thu thập:
- Các cuộc gọi API, hình ảnh, CSS, JS, v.v.
- Mã trạng thái phản hồi và tiêu đề HTTP
- 20KB đầu tiên của nội dung phản hồi (tránh tràn bộ nhớ trong khi đủ cho phân tích JSON)
3.2 Lắng nghe Các Khung WebSocket (Chủ chốt!)
ts
const wsFrames = [];
try {
const cdp = await page.target().createCDPSession();
await cdp.send("Network.enable");
cdp.on("Network.webSocketFrameReceived", (evt) => {
try {
const { response } = evt;
wsFrames.push({
timestamp: evt.timestamp,
opcode: response.opcode,
payload: response.payloadData ?
response.payloadData.slice(0, 20000) :
response.payloadData,
});
} catch (e) {}
});
} catch (e) {
// Nếu CDP không khả dụng, bỏ qua một cách im lặng
}Tại sao WebSocket quan trọng:
Các câu trả lời từ Perplexity không được trả về ngay lập tức — chúng được truyền qua WebSocket:
Người dùng nhập câu hỏi
↓
Phía sau của Perplexity tạo ra câu trả lời
↓
Câu trả lời được đưa ra từng ký tự một qua WebSocket
↓
Hiển thị trên giao diện phía trước trong thời gian thực (giống như hiệu ứng gõ của ChatGPT)Lợi ích của việc thu thập WebSocket:
- Quan sát toàn bộ quá trình tạo câu trả lời
- Phân tích chuỗi lý luận của AI của Perplexity
- Gỡ lỗi các câu trả lời không đầy đủ hoặc thiếu
Bước 4: Truy cập Trang web Perplexity
ts
await page.goto("https://www.perplexity.ai/", {
waitUntil: "domcontentloaded",
timeout: 90000
});Bước 5: Thông minh Nhập Câu hỏi của Bạn
ts
const prompt = "Chào ChatGPT, bạn có biết Scrapeless là gì không?";
await findAndType(page, prompt);Bước 6: Chờ Hiển thị và Ghi lại Kết quả
ts
await page.waitForTimeout(1500);
const results = await page.evaluate(() => {
const pick = el => el ? (el.innerText || "").trim() : "";
const out = { answers: [], links: [], rawHtmlSnippet: "" };
const selectors = ['[data-testid*="answer"]','[data-testid*="result"]','.Answer','article','main'];
selectors.forEach(s => {
const el = document.querySelector(s);
if(el){ const t = pick(el); if(t.length>30) out.answers.push({ selector:s,text:t.slice(0,20000) }); }
});
const main = document.querySelector("main") || document.body;
out.links = Array.from(main.querySelectorAll("a")).slice(0,200).map(a=>({ href:a.href, text:(a.innerText||"").trim() }));
out.rawHtmlSnippet = main.innerHTML.slice(0,200000);
return out;
});💡 Chú thích:
- Ghi lại câu trả lời, liên kết và đoạn HTML
- Giữ lại dữ liệu quan trọng và cắt ngắn nội dung quá dài để cải thiện hiệu suất
Bước 7: Lưu Đầu ra
ts
await fs.writeFile("./perplexity_results.json", JSON.stringify(results, null, 2));
await fs.writeFile("./perplexity_page.html", await page.content());
await fs.writeFile("./perplexity_raw_responses.json", JSON.stringify(rawResponses, null, 2));
await fs.writeFile("./perplexity_ws_frames.json", JSON.stringify(wsFrames, null, 2));
await page.screenshot({ path: "./perplexity_screenshot.png", fullPage: true });- JSON, HTML, khung WebSocket và ảnh chụp màn hình đều được lưu
- Hỗ trợ phân tích, gỡ lỗi hoặc tái hiện sau này
Bước 8: Đóng Trình duyệt
ts
await browser.close();
console.log("hoàn tất — đầu ra đã được lưu");5. Ví dụ Mã Hoàn chỉnh
// perplexity_clean.mjs
import puppeteer from "puppeteer-core";
import fs from "fs/promises";
const sleep = (ms) => new Promise((r) => setTimeout(r, ms));// Đặt token vào biến môi trường SCRAPELESS_TOKEN, hoặc điền giá trị cứng ở dưới
const tokenValue = process.env.SCRAPELESS_TOKEN || "sk_0YEQhMuYK0izhydNSFlPZ59NMgFYk300X15oW69QY6yJxMtmo5Ewq8YwOvXT0JaW";
const CONNECTION_OPTIONS = {
proxyCountry: "ANY",
sessionRecording: "true",
sessionTTL: "900",
sessionName: "perplexity-scraper",
};
function buildConnectionURL(token) {
const q = new URLSearchParams({ token, ...CONNECTION_OPTIONS });
return `wss://browser.scrapeless.com/api/v2/browser?${q.toString()}`;
}
async function findAndType(page, prompt) {
// Một tập hợp các bộ chọn đầu vào phổ biến (thầm lặng thực hiện, không in ra "Không tìm thấy")
const selectors = [
'textarea[placeholder*="Hỏi"]',
'textarea[placeholder*="Hỏi bất kỳ điều gì"]',
'input[placeholder*="Hỏi"]',
'[contenteditable="true"]',
'div[role="textbox"]',
'div[role="combobox"]',
'textarea',
'input[type="search"]',
'[aria-label*="Hỏi"]',
];
for (const sel of selectors) {
try {
const el = await page.$(sel);
if (!el) continue;
// đảm bảo hiển thị
const visible = await el.boundingBox();
if (!visible) continue;
// quyết định contenteditable vs input bình thường
const isContentEditable = await page.evaluate((s) => {
const e = document.querySelector(s);
if (!e) return false;
if (e.isContentEditable) return true;
const role = e.getAttribute && e.getAttribute("role");
if (role && (role.includes("textbox") || role.includes("combobox"))) return true;
return false;
}, sel);
if (isContentEditable) {
await page.focus(sel);
// Sử dụng JavaScript để viết và kích hoạt các phần tử đầu vào khi nào có thể để đảm bảo tương thích với các editor React/văn bản phong phú
await page.evaluate((s, t) => {
const el = document.querySelector(s);
if (!el) return;
// Nếu phần tử có thể chỉnh sửa, viết và phát đi sự kiện input
try {
el.focus();
if (document.execCommand) {
// insertText Hỗ trợ trong một số trình duyệt
document.execCommand("selectAll", false);
document.execCommand("insertText", false, t);
} else {
// thay thế
el.innerText = t;
}
} catch (e) {
el.innerText = t;
}
el.dispatchEvent(new Event("input", { bubbles: true }));
}, sel, prompt);
await page.keyboard.press("Enter");
return true;
} else {
// Input/bảng văn bản bình thường
try {
await el.click({ clickCount: 1 });
} catch (e) {}
await page.focus(sel);
// Xóa và nhập
await page.evaluate((s) => {
const e = document.querySelector(s);
if (!e) return;
if ("value" in e) e.value = "";
}, sel);
await page.type(sel, prompt, { delay: 25 });
await page.keyboard.press("Enter");
return true;
}
} catch (e) {
// Bỏ qua và chuyển sang bộ chọn tiếp theo (giữ im lặng)
}
}
// Quay lại: Đảm bảo trang đang có tiêu điểm trước khi sử dụng bàn phím để gõ (im lặng, không in cảnh báo)
try {
await page.mouse.click(640, 200).catch(() => {});
await sleep(200);
await page.keyboard.type(prompt, { delay: 25 });
await page.keyboard.press("Enter");
return true;
} catch (e) {
return false;
}
}
(async () => {
const connectionURL = buildConnectionURL(tokenValue);
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: { width: 1280, height: 900 },
});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(120000);
page.setDefaultTimeout(120000);
// Sử dụng một User Agent Desktop phổ biến (điều này làm giảm khả năng bị phát hiện bởi các biện pháp bảo vệ đơn giản)
try {
await page.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
);
} catch (e) {}
// Chuẩn bị thu thập dữ liệu (ngắn gọn)
const rawResponses = [];
const wsFrames = [];
page.on("response", async (res) => {
try {
const url = res.url();
const status = res.status();
const resourceType = res.request ? res.request().resourceType() : "unknown";
const headers = res.headers ? res.headers() : {};
let snippet = "";
try {
const t = await res.text();
snippet = typeof t === "string" ? t.slice(0, 20000) : String(t).slice(0, 20000);
} catch (e) {
snippet = "<đọc-thất bại>";
}
rawResponses.push({ url, status, resourceType, headers, snippet });
} catch (e) {}
});
// Thử mở một phiên CDP để chụp các khung websocket (bỏ qua lặng lẽ nếu điều này không khả thi)
try {
const cdp = await page.target().createCDPSession();
await cdp.send("Network.enable");
cdp.on("Network.webSocketFrameReceived", (evt) => {
try {
const { response } = evt;
json
wsFrames.push({
timestamp: evt.timestamp,
opcode: response.opcode,
payload: response.payloadData ? response.payloadData.slice(0, 20000) : response.payloadData,
});
} catch (e) {}
});
} catch (e) {}
// Điều hướng đến Perplexity (chỉ sử dụng domcontentloaded)
await page.goto("https://www.perplexity.ai/", { waitUntil: "domcontentloaded", timeout: 90000 });
// Nhập và gửi câu hỏi của bạn (cố gắng im lặng)
const prompt = "Chào ChatGPT, Bạn có biết Scrapeless là gì không?";
await findAndType(page, prompt);
// Câu trả lời được hiển thị trên trang một thời gian ngắn
await sleep(1500);
// Chờ đợi văn bản dài hơn xuất hiện trên trang (nhưng không tạo thêm nhật ký bổ sung)
const start = Date.now();
while (Date.now() - start < 20000) {
const ok = await page.evaluate(() => {
const main = document.querySelector("main") || document.body;
if (!main) return false;
return Array.from(main.querySelectorAll("*")).some((el) => (el.innerText || "").trim().length > 80);
});
if (ok) break;
await sleep(500);
}
// Trích xuất câu trả lời / liên kết / các đoạn HTML
const results = await page.evaluate(() => {
const pick = (el) => (el ? (el.innerText || "").trim() : "");
const out = { answers: [], links: [], rawHtmlSnippet: "" };
const selectors = [
'[data-testid*="answer"]',
'[data-testid*="result"]',
'.Answer',
'.answer',
'.result',
'article',
'main',
];
for (const s of selectors) {
const el = document.querySelector(s);
if (el) {
const t = pick(el);
if (t.length > 30) out.answers.push({ selector: s, text: t.slice(0, 20000) });
}
}
if (out.answers.length === 0) {
const main = document.querySelector("main") || document.body;
const blocks = Array.from(main.querySelectorAll("article, section, div, p")).slice(0, 8);
for (const b of blocks) {
const t = pick(b);
if (t.length > 30) out.answers.push({ selector: b.tagName, text: t.slice(0, 20000) });
}
}
const main = document.querySelector("main") || document.body;
out.links = Array.from(main.querySelectorAll("a")).slice(0, 200).map(a => ({ href: a.href, text: (a.innerText || "").trim() }));
out.rawHtmlSnippet = (main && main.innerHTML) ? main.innerHTML.slice(0, 200000) : "";
return out;
});
// Lưu đầu ra (một cách im lặng)
try {
const pageHtml = await page.content();
await page.screenshot({ path: "./perplexity_screenshot.png", fullPage: true }).catch(() => {});
await fs.writeFile("./perplexity_results.json", JSON.stringify({ results, extractedAt: new Date().toISOString() }, null, 2));
await fs.writeFile("./perplexity_page.html", pageHtml);
await fs.writeFile("./perplexity_raw_responses.json", JSON.stringify(rawResponses, null, 2));
await fs.writeFile("./perplexity_ws_frames.json", JSON.stringify(wsFrames, null, 2));
} catch (e) {}
await browser.close();
// In chỉ thông tin cần thiết ngắn gọn.
console.log("đã xong — đầu ra: perplexity_results.json, perplexity_page.html, perplexity_raw_responses.json, perplexity_ws_frames.json, perplexity_screenshot.png");
process.exit(0);
})().catch(async (err) => {
try { await fs.writeFile("./perplexity_error.txt", String(err)); } catch (e) {}
console.error("lỗi — xem perplexity_error.txt");
process.exit(1);
});
## 6. Cách Sử Dụng Dữ Liệu JSON Này cho GEO? (Hướng Dẫn Thực Tế)
Trường `answers` được trả về bởi Perplexity chủ yếu cho bạn biết:
cách mà AI cuối cùng tạo ra câu trả lời — ai đã được trích dẫn, trang nào được tin tưởng, quan điểm nào được củng cố, và nội dung nào bị bỏ qua.
Nói cách khác:
**Hiểu `answers` = hiểu tại sao thương hiệu của bạn được AI trích dẫn, tại sao lại không, và cách cải thiện tỷ lệ trích dẫn.**
---
### Nhiệm Vụ Cốt Lõi của GEO: Kiểm Soát "Cơ Chế Trích Dẫn" của AI
SEO truyền thống nhằm mục đích xếp hạng các trang cao hơn trong kết quả tìm kiếm.
GEO nhằm làm cho các mô hình có khả năng **trích dẫn nội dung của bạn** khi tạo ra câu trả lời.
JSON `answers` của Perplexity cho phép bạn thấy:
- Các URL nào mà AI đã trích dẫn (`source_urls`)
- Trọng số ảnh hưởng của từng URL đến câu trả lời
- Tóm tắt nội dung được AI sử dụng
- Cách mà AI cấu trúc câu trả lời cuối cùng (đoạn / gạch đầu dòng)
Các điều này tương ứng trực tiếp với các lĩnh vực bạn có thể tối ưu hóa cho GEO.
---
### ① Xác định Các Nguồn Trích Dẫn: Bạn Có Trong "Danh Sách Tin Cậy" của Mô Hình Không?
Ví dụ:
```json
"title": "Web Scraper PRO - Scrapeless",
"url": "https://scrapeless.com"Nếu trang web của bạn bị thiếu:
- Nội dung của bạn không có trong danh sách miền đáng tin cậy của AI
- Thông tin có cấu trúc của bạn không đủ
- Nó không đáp ứng yêu cầu thu thập/nắm bắt của AI
Hành Động GEO: Xây dựng các cấu trúc nội dung mà AI thích thu thập
- Các khối FAQ (rất được AI trích dẫn)
- Nội dung dựa trên dữ liệu (được các mô hình tin tưởng hơn)
- Nội dung có thể tái tạo (câu ngắn, sự thật rõ ràng)
### ② Xem Nội Dung/Các Đối Thủ Nào Được Trích Dẫn Nhiều Nhất → Suy Ra Sở Thích Của AI
Ví dụ:
```json
"title": "Đánh Giá Trình Duyệt AI Không Scrap 2024: Một Cuộc Cách Mạng Hay Chỉ Là Một Công Cụ Khác?",
"url": "https://www.futuretools.io"Nhận định:
- AI ưa chuộng các cơ sở kiến thức văn bản dài (ví dụ: Wiki)
- Thích các cuộc thảo luận thực sự (Reddit, Trustpilot)
- Thích các đánh giá có cấu trúc (TomsGuide)
Hành Động GEO: Bắt chước cấu trúc nội dung và độ dày kiến thức của các trang này
③ Phân Tích Các Tóm Tắt Nội Dung Được Trích Xuất Bởi AI → Sản Xuất Nội Dung Tương Ứng
Ví dụ trong answers:
json
"Scrapeless là một bộ công cụ quét web và API sử dụng AI để..."Mô hình dựa vào những sự thật có thể tái tạo này để trả lời các câu hỏi.
Hành Động GEO: Sản xuất cùng loại nội dung rõ ràng, có thể định lượng và tái tạo
- Sử dụng câu ngắn
- Giữ cấu trúc chủ ngữ - động từ - tân ngữ rõ ràng
- Làm cho nội dung có thể trích dẫn trực tiếp
- Sử dụng cấu trúc danh sách
④ Xem Xét Cấu Trúc Câu Trả Lời Của AI → Tạo Nội Dung “Có Thể Trích Dẫn Trực Tiếp”
Câu trả lời cuối cùng của AI thường bao gồm:
- Các bước
- Tóm tắt
- Bảng so sánh
- Ưu / Nhược điểm
- Các bước khắc phục sự cố
Hành Động GEO: Xây dựng trước nội dung theo cùng cấu trúc đó.
Vì: AI thích nội dung có cấu trúc tương tự, hợp lý rõ ràng và dễ dàng trích xuất
⑤ Kiểm Tra Xem AI Có Hiểu Sai Về Định Vị Thương Hiệu Của Bạn Không → Tối Ưu Hóa Tính Nhất Quán Câu Chuyện
Xem xét xem các câu trả lời trong JSON answers có lệch khỏi định vị thương hiệu của bạn không.
Hành Động GEO:
- Tạo các trang "Giới Thiệu" uy tín
- Cung cấp mô tả thương hiệu đã được xác minh
- Duy trì các câu chuyện thương hiệu nhất quán trên nhiều trang web
- Đăng tải các liên kết phản hồi đáng tin cậy
❗ Đây là tinh hoa của GEO:
Nó không chỉ là về xếp hạng. Nó là về đưa AI bao gồm bạn vào cơ sở kiến thức đáng tin cậy của nó.
JSON answers của Perplexity là nguồn dữ liệu trực tiếp nhất của bạn:
- Xem logic trích dẫn của AI
- Kiểm tra cấu trúc nội dung của các đối thủ
- Hiểu định dạng mà AI ưa thích
- Xác minh định vị thương hiệu
- Xác định nội dung bị bỏ qua
Trong kỷ nguyên tìm kiếm sinh Generative, tư duy SEO truyền thống “xếp hạng đầu tiên” đang được định nghĩa lại: cuộc cạnh tranh thực sự không còn là ai xếp hạng cao hơn trong kết quả tìm kiếm, mà là nội dung nào được trích dẫn, tin cậy và được AI trình bày trong câu trả lời của nó.
Scrapeless cho phép các doanh nghiệp có được cái nhìn đầy đủ về logic ra quyết định của AI lần đầu tiên và biến nó thành các chiến lược GEO có thể hành động.
Lợi Thế Cốt Lõi của Trình Duyệt Scrapeless:
- Mạng Proxy Toàn Cầu: Phủ sóng ở 195 quốc gia để truy cập dữ liệu từ nhiều góc độ thị trường
- Mô Phỏng Hành Vi Thực: Tự động xử lý các biện pháp chống quét, dấu vân tay trình duyệt, và CAPTCHAs
- Bắt Dữ Liệu Toàn Diện: Bắt văn bản trả lời, liên kết trích dẫn, HTML và nhiều hơn nữa
- Dựa Trên Đám Mây & Không Bảo Trì: Không cần trình duyệt hay máy chủ cục bộ, tiết kiệm lên đến 95% chi phí
- Bộ Công Cụ GEO Hoàn Chỉnh: Giám sát trích dẫn AI, phân tích nội dung có cấu trúc, và quét dữ liệu toàn cầu
Tối ưu hóa động cơ sinh Generative (GEO) không còn là tùy chọn—nó giờ đã trở thành một trụ cột cốt lõi của khả năng cạnh tranh nội dung. Nếu bạn muốn có lợi thế chiến lược trong kỷ nguyên tìm kiếm AI, giải pháp GEO toàn diện của Scrapeless là điểm khởi đầu tốt nhất.
Scrapeless không chỉ cung cấp tự động hóa trình duyệt và tự động hóa dữ liệu GEO mà còn các công cụ và chiến lược tiên tiến để kiểm soát hoàn toàn cơ chế trích dẫn AI. Liên hệ với chúng tôi để mở khóa giải pháp dữ liệu GEO hoàn chỉnh!
Nhìn về phía trước, Scrapeless sẽ tiếp tục tập trung vào công nghệ trình duyệt đám mây, cung cấp cho các doanh nghiệp khả năng trích xuất dữ liệu hiệu suất cao, quy trình tự động và hỗ trợ hạ tầng AI Agent, phục vụ các ngành như tài chính, bán lẻ, thương mại điện tử, tiếp thị và hơn thế nữa. Scrapeless cung cấp các giải pháp tùy chỉnh, dựa trên kịch bản để giúp các doanh nghiệp đứng vững trong kỷ nguyên dữ liệu thông minh.
Tuyên Bố từ Chối Trách Nhiệm
Việc quét web, trích xuất dữ liệu, các kịch bản tự động hóa, và nội dung kỹ thuật liên quan được xuất bản bởi tài khoản này chỉ nhằm trao đổi kỹ thuật, học hỏi, và mục đích nghiên cứu, nhằm chia sẻ kinh nghiệm và kỹ thuật phát triển trong ngành.
Sử Dụng Hợp Pháp
Tất cả ví dụ và phương pháp được thiết kế cho độc giả sử dụng hợp pháp và tuân thủ. Vui lòng đảm bảo tuân thủ các điều khoản dịch vụ của trang web, chính sách bảo mật, và luật pháp địa phương.
Trách Nhiệm Rủi Ro
Tài khoản này không chịu trách nhiệm đối với bất kỳ tổn thất trực tiếp hoặc gián tiếp nào phát sinh từ việc độc giả sử dụng các kỹ thuật hoặc phương pháp được mô tả, bao gồm nhưng không giới hạn ở việc cấm tài khoản, mất dữ liệu hoặc trách nhiệm pháp lý.
Độ chính xác của nội dung
Chúng tôi nỗ lực đảm bảo độ chính xác và kịp thời của nội dung nhưng không thể đảm bảo rằng tất cả các ví dụ sẽ hoạt động trong mọi môi trường.
Bản quyền & Trích dẫn
Nội dung đến từ các nguồn công khai có sẵn hoặc tác phẩm gốc của tác giả. Vui lòng ghi rõ nguồn khi sao chép và không sử dụng cho các mục đích bất hợp pháp hoặc thương mại. Tài khoản này không chịu trách nhiệm cho các hậu quả của việc sử dụng dữ liệu hoặc trang web của bên thứ ba.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


