
Node Unblocker đủ để vượt qua những thách thức khi thu thập dữ liệu web không?
Expert Network Defense Engineer
Trình chặn Node có thể được tùy chỉnh để bao gồm các tính năng như luân phiên IP, tùy chỉnh tiêu đề và mã hóa. Vì vậy, chúng tôi đã quen với việc xây dựng trình chặn Node để bỏ qua việc chặn trang web.
Một trình chặn Node rất xuất sắc trong việc bỏ qua các thách thức của trang web, nhưng trong thực tế, chúng tôi thấy rằng chúng tôi vẫn cần phải đối phó với một số rắc rối vốn có của nó.
Làm thế nào để làm cho trình chặn Node của bạn mạnh mẽ hơn? Có phương pháp hoặc công cụ nào có thể hoàn toàn khắc phục các thách thức của trang web trực tiếp không?
Đã đến lúc tìm ra câu trả lời tốt nhất từ bài viết này!
Trình chặn Node là gì?
Trình chặn Node là một công cụ proxy web được xây dựng bằng Node.js giúp bỏ qua các hạn chế về mạng hoặc giới hạn truy cập trang web. Nó hoạt động như một trung gian giữa người dùng và trang web đích, cho phép người dùng tương tác với nội dung có thể bị chặn do các hạn chế về địa lý, bộ lọc mạng hoặc tường lửa.
Trình chặn thực hiện việc này bằng cách định tuyến yêu cầu của người dùng đến máy chủ Node.js, máy chủ này sẽ tìm nạp nội dung mong muốn và trả lại cho người dùng. Nó thường hỗ trợ xử lý nội dung động, làm cho nó phù hợp với các ứng dụng web hiện đại.
Cách sử dụng Trình chặn Node?
Đầu tiên, chúng ta sẽ tạo một dịch vụ Node.js cơ bản. Sau đó, chúng ta sẽ thảo luận về cách sử dụng Trình chặn Node để tạo middleware, cho phép tích hợp nó vào dịch vụ Node của chúng ta. Để biết thêm chi tiết, bạn có thể truy cập trực tiếp tài liệu Trình chặn Node.
Điều kiện tiên quyết
Trước khi bắt đầu, bạn cần cài đặt Node.js. Bạn có thể tải xuống Node.js ở đây.
Bây giờ chúng ta hãy bắt đầu bằng cách tạo một dịch vụ Node.js cơ bản.
- Khởi tạo một dự án Node.js mới. Nếu bạn chưa có dự án, hãy tạo một dự án bằng các lệnh sau:
Bash
mkdir node-unblocker-tutorial- Điều hướng đến thư mục dự án, khởi tạo dự án và cài đặt các phụ thuộc cần thiết:
Bash
cd node-unblocker-tutorial
npm init -y
pnpm add express unblocker- Bây giờ, hãy tạo một tệp mới, index.js, để sắp xếp mã của bạn:
Bash
touch index.jsThiết lập dịch vụ Node.js cơ bản
- Nhập các mô-đun cần thiết,
expressvàunblocker:
JavaScript
import express from 'express';
import unblocker from 'unblocker';- Tiếp theo, hãy tạo một ứng dụng Express:
JavaScript
const app = express();- Khởi tạo một phiên bản Unblocker và đặt tiền tố proxy của nó:
JavaScript
const unblocker = new Unblocker({
prefix: '/proxy/'
});Hãy chắc chắn tích hợp phiên bản Unblocker với ứng dụng Express bằng phương pháp app.use():
JavaScript
app.use(unblocker());- Định nghĩa một cổng và khởi động dịch vụ Node.js bằng phương pháp
app.listen():
JavaScript
const PORT = process.env.PORT || 9090;
app.listen(PORT, () => {
console.log(`Server started on port ${PORT}`);
});- Dưới đây là mã hoàn chỉnh để thiết lập:
JavaScript
import express from 'express';
import Unblocker from 'unblocker';
const app = express();
const unblocker = new Unblocker({ prefix: '/proxy/' });
app.use(unblocker);
const PORT = process.env.PORT || 9090;
app
.listen(PORT, () => {
console.log(`Server started on port ${PORT}`);
})
.on('upgrade', unblocker.onUpgrade);Chạy dịch vụ
Chạy tệp index.js bằng Node để khởi động máy chủ trên cổng 9090. Kiểm tra proxy bằng cách nối URL đích vào tiền tố proxy. Đối với ví dụ này, chúng ta sẽ sử dụng https://ident.me/ làm trang đích. Mở liên kết sau trong trình duyệt của bạn sau khi chạy dịch vụ:
node index.js
Bạn sẽ thấy một trang hiển thị địa chỉ IP của dịch vụ hiện tại, cho thấy việc thiết lập đang hoạt động chính xác:

5 Hạn chế của Trình chặn Node
- Sự cố tắc nghẽn hiệu suất
Vì Trình chặn Node xử lý các yêu cầu và phản hồi web trong thời gian thực, nên nó có thể trở thành một điểm nghẽn hiệu suất khi xử lý một lượng lớn yêu cầu đồng thời hoặc lưu lượng truy cập lớn.
- Tiêu thụ tài nguyên
Trình chặn Node yêu cầu tài nguyên máy chủ để xử lý các yêu cầu, đặc biệt là khi xử lý các tệp lớn, nội dung đa phương tiện hoặc các trang web động mạnh. Điều này có thể dẫn đến tăng sử dụng CPU và bộ nhớ.
- Khả năng bỏ qua bị hạn chế
Mặc dù Trình chặn Node có thể bỏ qua một số hạn chế cơ bản, nhưng nó lại gặp khó khăn với các hệ thống chống bot nâng cao như CAPTCHA, dấu vân tay JavaScript hoặc cơ chế giới hạn tốc độ dựa trên IP.
- Thách thức khả năng mở rộng
Trình chặn Node không được xây dựng sẵn cho các thiết lập phân tán hoặc khả năng mở rộng cao, điều này làm cho nó ít phù hợp hơn với các ứng dụng cấp doanh nghiệp hoặc quy mô lớn mà không cần tùy chỉnh đáng kể.
- Thiếu khả năng kiểm tra HTTPS
Trình chặn Node không giải mã hoặc kiểm tra lưu lượng truy cập HTTPS, điều này hạn chế khả năng sửa đổi hoặc phân tích dữ liệu được mã hóa trong quá trình proxy.
Một số thực tiễn tốt nhất khi sử dụng Trình chặn Node là gì?
1. Luân phiên tiêu đề user-agent
Để làm cho các hoạt động thu thập dữ liệu web của bạn xuất hiện như thể chúng xuất phát từ những người dùng khác nhau, điều cần thiết là phải luân phiên các tiêu đề User-Agent. Thực tiễn này làm giảm đáng kể khả năng một trang web phát hiện các yêu cầu của bạn là tự động.
2. Thực hiện luân phiên IP
Việc dựa vào một IP proxy duy nhất gần như rủi ro như truy cập trực tiếp vào một trang web, vì nó làm tăng khả năng IP của bạn bị gắn cờ hoặc bị chặn. Việc thực hiện luân phiên IP giúp bạn tránh bị phát hiện và đảm bảo truy cập liền mạch để thu thập dữ liệu web cần thiết.
3. Giới hạn tần suất yêu cầu
Giới hạn tốc độ là một biện pháp quan trọng để ngăn chặn IP của bạn bị gắn cờ. Việc gửi nhiều yêu cầu từ cùng một IP trong một khoảng thời gian ngắn có thể kích hoạt các biện pháp bảo vệ chống bot của một trang web, có khả năng dẫn đến bị cấm. Bằng cách kết hợp độ trễ trong mã thu thập dữ liệu của bạn, bạn có thể giảm thiểu những rủi ro này và duy trì hoạt động trơn tru.
4. Xử lý lỗi
Xử lý lỗi hiệu quả là rất quan trọng đối với việc thu thập dữ liệu web thành công. Kết hợp các cơ chế trong mã của bạn để giải quyết các trường hợp mà trang web đích không trả về phản hồi mong muốn, đảm bảo quá trình thu thập dữ liệu của bạn vẫn mạnh mẽ và hiệu quả.
Tích hợp Scrapeless Web Unlocker để có các tính năng nâng cao
Tại sao Scrapeless hiệu quả trong việc tránh bị chặn?
Scrapeless Web Unlocker tận dụng một mạng lưới toàn cầu trải rộng 195 quốc gia, được hỗ trợ bởi quyền truy cập vào hơn 70 triệu IP dân cư. Với thời gian hoạt động 99,9% và tỷ lệ thành công vượt trội, Scrapeless dễ dàng vượt qua các thách thức như chặn IP và CAPTCHA, làm cho nó trở thành một giải pháp mạnh mẽ cho tự động hóa web phức tạp và thu thập dữ liệu dựa trên AI.
Scrapeless có tốn kém không?
Scrapeless cung cấp một nền tảng thu thập dữ liệu web đáng tin cậy và có khả năng mở rộng với giá cả cạnh tranh, đảm bảo giá trị tuyệt vời cho người dùng của mình:
- Trình duyệt Scraping: Từ 0,09 đô la mỗi giờ
- API Scraping: Từ 1,00 đô la cho 1k URL
- Web Unlocker: 0,20 đô la cho 1k URL
- Bộ giải quyết CAPTCHA: Từ 0,80 đô la cho 1k URL
- Proxy: 2,80 đô la mỗi GB
Bằng cách đăng ký, bạn có thể tận hưởng giảm giá lên đến 20% cho mỗi dịch vụ. Bạn có yêu cầu cụ thể? Liên hệ với chúng tôi ngay hôm nay, và chúng tôi sẽ cung cấp khoản tiết kiệm lớn hơn nữa phù hợp với nhu cầu của bạn!
Các bước chi tiết để Tích hợp Scrapeless vào Dự án của bạn
Điều kiện tiên quyết
Trước khi bắt đầu, bạn cần đăng ký tài khoản Scrapeless. Bạn cũng có thể điều hướng đến trang web chính thức để tìm hiểu thêm về Scrapeless.
Sau khi đăng ký, hãy điều hướng đến Bảng điều khiển Scrapeless và nhấp vào menu Web Unlocker ở bảng điều khiển bên trái. Ở đây, bạn sẽ tìm thấy nhiều tùy chọn cấu hình, bao gồm Proxy, JS Render, Phương thức yêu cầu và Hướng dẫn JS. Các tính năng này giải quyết một số hạn chế của Trình chặn Node và bạn có thể tùy chỉnh chúng theo yêu cầu của mình.
Nếu bạn không quen thuộc với các tùy chọn cấu hình này, bạn có thể tham khảo tài liệu chi tiết bằng cách nhấp vào liên kết "Tài liệu" trên trang.
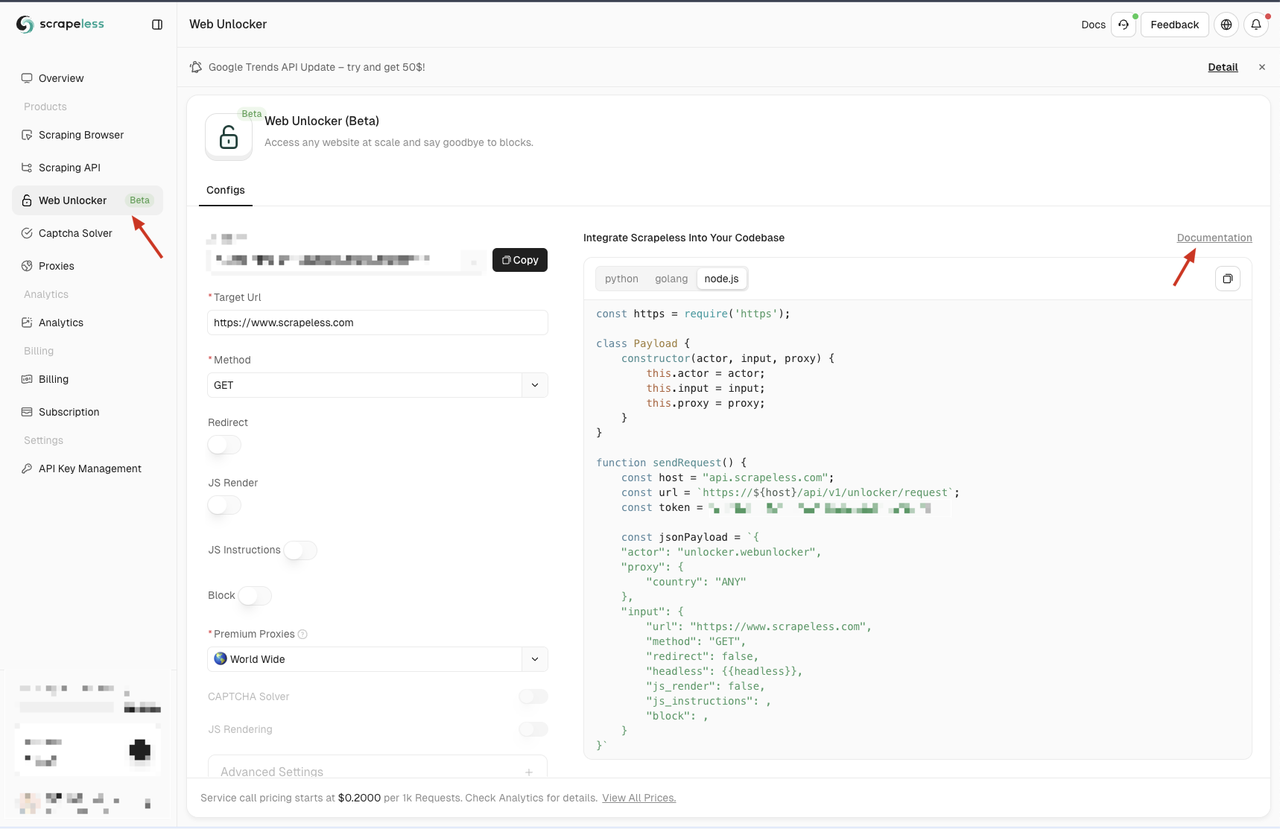
Scrapeless cũng cung cấp các mẫu mã bằng ba ngôn ngữ lập trình — Python, Node.js và Golang. Bạn có thể chọn ngôn ngữ phù hợp với nhu cầu của mình để tích hợp. Trong ví dụ này, chúng ta sẽ sử dụng Node.js.
Bỏ qua CAPTCHA
Scrapeless Web Unlocker tự động kích hoạt chức năng bỏ qua CAPTCHA, loại bỏ mối lo ngại về các thách thức CAPTCHA. Để xác minh điều này, trước tiên, hãy sử dụng Curl để gửi yêu cầu đến một trang web yêu cầu xác minh, chẳng hạn như:
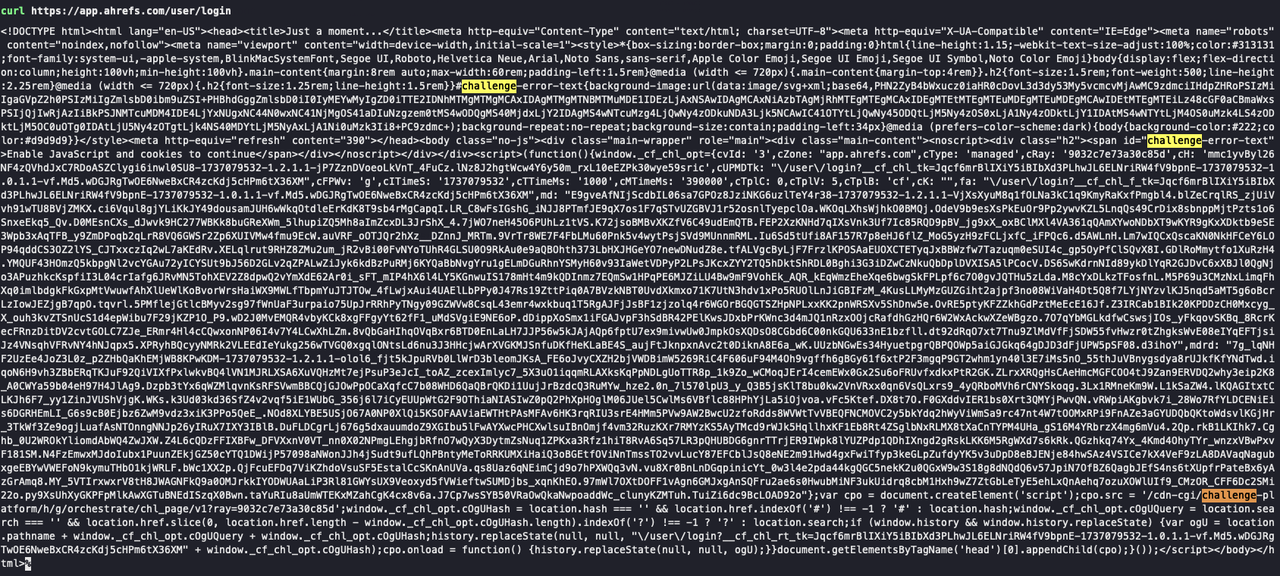
Bash
curl https://app.ahrefs.com/user/loginTrong ảnh chụp màn hình bên dưới, yêu cầu Curl trả về một trang xác minh CAPTCHA. Bạn có thể thấy chi tiết xác minh Cloudflare trong phản hồi:
Bây giờ, sử dụng Scrapeless Web Unlocker để yêu cầu cùng một trang web, hãy làm theo các bước sau:
- Tạo một tệp scrapeless-web-unlocker.js với mã sau:
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input, proxy) {
this.actor = actor;
this.input = input;
this.proxy = proxy;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/unlocker/request`;
const token = ''; // token của bạn
const inputData = {
url: 'https://app.ahrefs.com/user/login',
method: 'GET',
redirect: false,
};
const proxy = {
country: 'ANY',
};
const payload = new Payload('unlocker.webunlocker', inputData, proxy);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();- Chạy mã bằng
node scrapeless-web-unlocker.js.
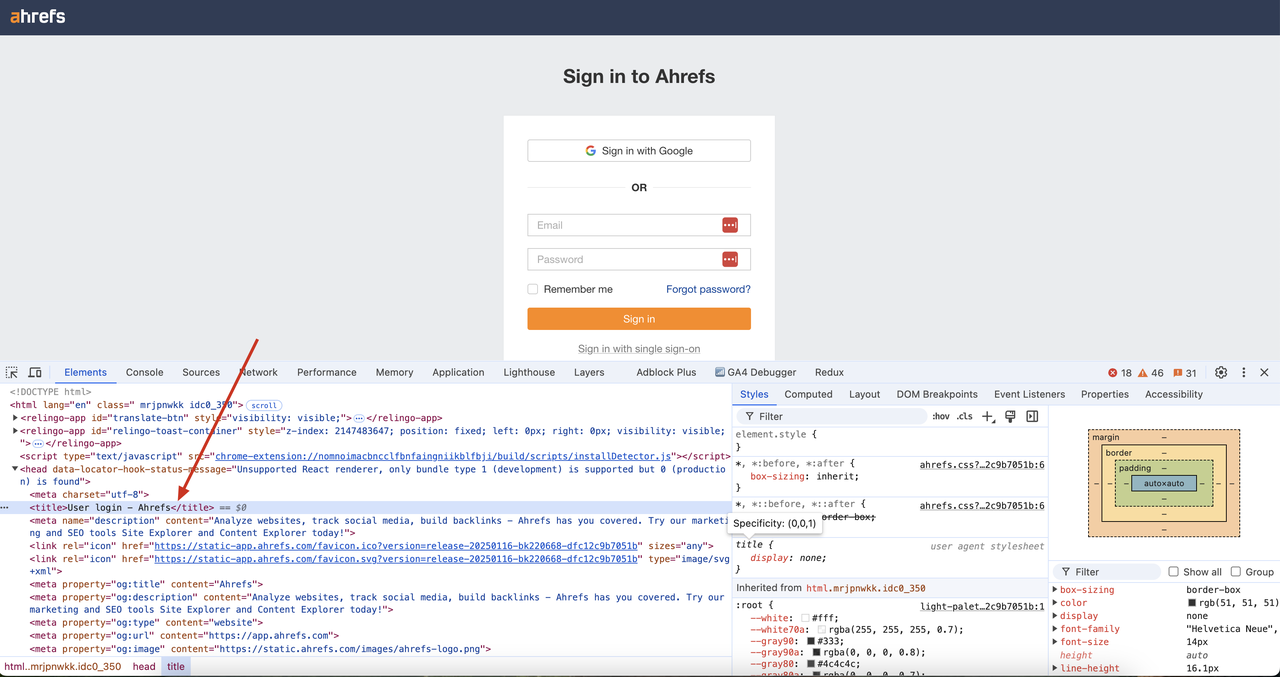
Chúng ta có thể thấy rằng việc xác minh CAPTCHA đã được bỏ qua thành công trong kết quả trả về và nội dung DOM của trang đã được lấy. Ngoài ra, tiêu đề "Đăng nhập người dùng - Ahrefs" trong mã trang cũng có thể được lấy thành công trong kết quả của chúng ta.

Hiển thị JavaScript
Việc hiển thị JavaScript có thể xử lý nội dung được tải động và các ứng dụng trang đơn (SPA). Nó cho phép một môi trường trình duyệt đầy đủ và hỗ trợ các tương tác và yêu cầu hiển thị trang phức tạp hơn. Dịch vụ Web Unlocker của Scrapeless có thể giải quyết vấn đề mà Trình chặn Node không thể thực thi JavaScript. Chúng ta có thể bật chức năng Hiển thị JavaScript trong Web Unlocker của Scrapeless để chúng ta có thể lấy nội dung trang được hiển thị bằng JavaScript.
Chúng ta có thể tìm thấy một trang web sử dụng việc hiển thị JavaScript, chẳng hạn như trang đăng nhập Bảng điều khiển của Cloudflare. Chúng ta có thể thấy rằng công nghệ khung mà nó sử dụng là React.js và React.js là một khung ứng dụng trang đơn và nội dung của nó được hiển thị bằng JavaScript.
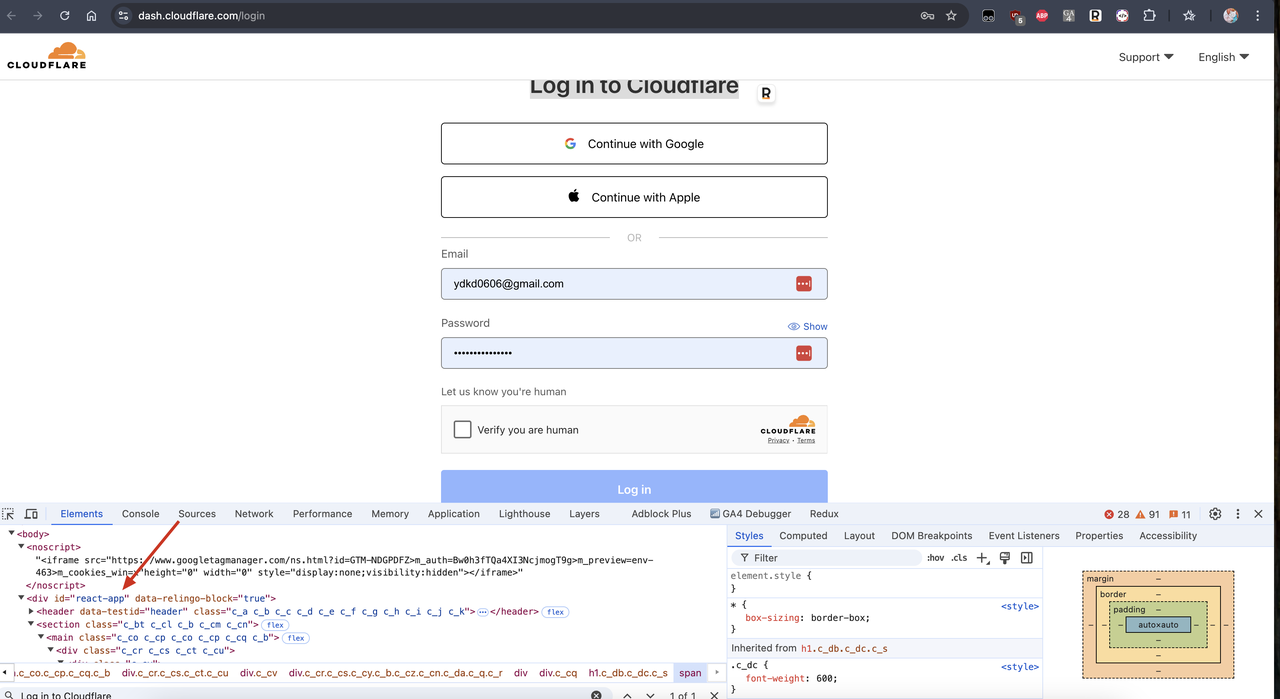
Bây giờ, hãy sửa đổi mã trước đó một chút để xem liệu chúng ta có thể lấy nội dung của trang đăng nhập Bảng điều khiển của Cloudflare mà không cần bật Hiển thị JavaScript hay không. Sửa đổi mã như sau:
JavaScript
...
url: 'https://dash.cloudflare.com/login',
...Chúng ta có thể thấy rằng div có id="react-app" trong kết quả trả về là trống, điều này có nghĩa là chúng ta đã không nhận được nội dung trang sau khi hiển thị JavaScript:
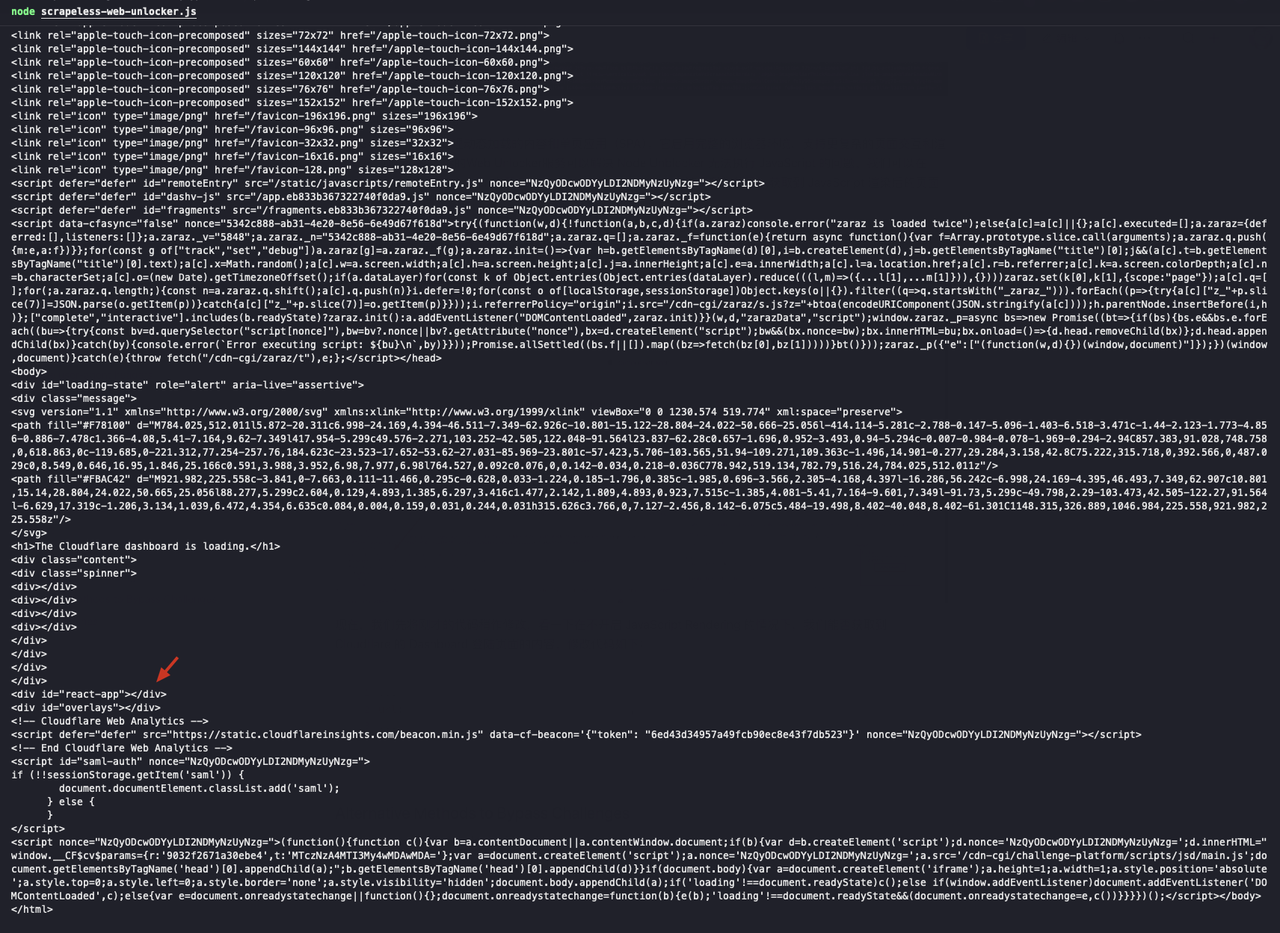
Tiếp theo, chúng ta bật chức năng Hiển thị JavaScript và sửa đổi mã như sau:
JavaScript
const inputData = {
url: 'https://dash.cloudflare.com/login',
method: 'GET',
redirect: false,
js_render: true, // tùy chọn mới
js_instructions: [ // tùy chọn mới
{
wait: 20000,
},
],
};Trong mã trên, chúng ta đã thêm hai tùy chọn cấu hình mới, js_render và js_instructions. Để biết thêm tham chiếu hướng dẫn, vui lòng tham khảo Tài liệu Scrapeless:
js_renderđược sử dụng để bật chức năng Hiển thị JavaScriptjs_instructionsđược sử dụng để đặt các hướng dẫn cho việc Hiển thị JavaScript. Ở đây, chúng ta đặt một hướng dẫn chờ 20 giây để trả về kết quả sau khi trang được tải.
Lưu ý: Hiện nay nhiều trang web có quá trình tải mặc định, vì vậy chúng ta cần chờ một lúc để đảm bảo trang đã được tải trước khi trả về kết quả
Bây giờ, chúng ta chạy mã lại và chúng ta có thể thấy rằng nội dung của trang đăng nhập Bảng điều khiển của Cloudflare đã được lấy thành công trong kết quả trả về. Bằng cách lấy văn bản của "Đăng nhập vào Cloudflare", chúng ta có thể thấy rằng chúng ta đã lấy được nội dung trang được hiển thị bằng JavaScript.
Bash
node scrapeless-web-unlocker.js
Kết luận
Những thách thức ngày càng tăng về việc truy cập nội dung web đòi hỏi các giải pháp mới. Trong bài viết này, chúng ta đã xem xét Trình chặn Node, một thư viện NodeJS cung cấp proxy web xử lý dữ liệu và chuyển tiếp nó đến máy khách.
Tuy nhiên, những hạn chế của nó ngăn cản nó trở thành một giải pháp thu thập dữ liệu web hiệu quả về chi phí. Vì vậy, cần một giải pháp hiệu quả hơn và rẻ hơn. Như mọi người đều đồng ý — Scrapeless là người chiến thắng rõ ràng với các dịch vụ toàn diện vượt trội và giá cả thấp hơn.
Bạn có thể đăng ký ngay bây giờ để nhận Web Unlocker miễn phí của mình!
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


