
Cách thực hiện yêu cầu HTTP trong Node.js với API Node-Fetch?
Specialist in Anti-Bot Strategies
Trang web hiện tại của chúng ta thường dựa vào hàng chục nguồn khác nhau, chẳng hạn như một bộ sưu tập hình ảnh, CSS, phông chữ, JavaScript, dữ liệu JSON, v.v. khổng lồ. Tuy nhiên, trang web đầu tiên trên thế giới chỉ được viết bằng HTML.
JavaScript, với tư cách là một ngôn ngữ kịch bản phía máy khách tuyệt vời, đã đóng một vai trò quan trọng trong sự phát triển của các trang web. Với sự trợ giúp của các đối tượng XMLHttpRequest hoặc XHR, JavaScript có thể thực hiện giao tiếp giữa máy khách và máy chủ mà không cần tải lại trang.
Tuy nhiên, quá trình động này đang bị thách thức bởi Fetch API. Fetch API là gì? Làm thế nào để sử dụng Fetch API trong Node.js? Tại sao Fetch API là lựa chọn tốt hơn?
Bắt đầu nhận câu trả lời từ bài viết này ngay bây giờ!
Yêu cầu HTTP trong Node.js là gì?
Trong Node.js, các yêu cầu HTTP là một phần cơ bản trong việc xây dựng các ứng dụng web hoặc tương tác với các dịch vụ web. Chúng cho phép máy khách (như trình duyệt hoặc ứng dụng khác) gửi dữ liệu đến máy chủ hoặc yêu cầu dữ liệu từ máy chủ. Các yêu cầu này sử dụng Giao thức truyền tải siêu văn bản (HTTP), là nền tảng của giao tiếp dữ liệu trên web.
- Yêu cầu HTTP: Một yêu cầu HTTP được gửi bởi máy khách đến máy chủ, thường để lấy dữ liệu (như trang web hoặc phản hồi API) hoặc gửi dữ liệu đến máy chủ (như gửi biểu mẫu).
- Phương thức HTTP: Yêu cầu HTTP thường bao gồm một phương thức, cho biết hành động mà máy khách muốn máy chủ thực hiện. Các phương thức HTTP phổ biến bao gồm:
- GET: Yêu cầu dữ liệu từ máy chủ.
- POST: Gửi dữ liệu đến máy chủ (ví dụ: gửi biểu mẫu).
- PUT: Cập nhật dữ liệu hiện có trên máy chủ.
- DELETE: Xóa dữ liệu khỏi máy chủ.
- Mô-đun HTTP của Node.js: Node.js cung cấp một mô-đun http tích hợp để xử lý các yêu cầu HTTP. Mô-đun này cho phép bạn tạo một máy chủ HTTP, lắng nghe các yêu cầu và trả lời chúng.
Tại sao Node.js là lý tưởng cho việc thu thập dữ liệu web và tự động hóa?
Node.js đã trở thành một trong những công nghệ được sử dụng nhiều nhất cho các tác vụ thu thập dữ liệu web và tự động hóa nhờ các đặc điểm độc đáo, hệ sinh thái mạnh mẽ và kiến trúc không đồng bộ, không chặn.
Tại sao Node.js là lý tưởng cho việc thu thập dữ liệu web và tự động hóa? Hãy cùng tìm hiểu!
- I/O không đồng bộ và không chặn
- Tốc độ và hiệu quả
- Hệ sinh thái phong phú các thư viện và khung
- Xử lý nội dung động với trình duyệt không đầu
- Khả năng tương thích đa nền tảng
- Xử lý dữ liệu thời gian thực
- Cú pháp đơn giản để phát triển nhanh chóng
- Hỗ trợ luân chuyển proxy và chống phát hiện
Node-Fetch API là gì?
Node-fetch là một mô-đun nhẹ mang Fetch API đến môi trường Node.js. Nó đơn giản hóa quá trình thực hiện các yêu cầu HTTP và xử lý các phản hồi.
Fetch API được xây dựng dựa trên Promises và rất phù hợp với các hoạt động không đồng bộ như thu thập dữ liệu từ trang web, tương tác với API RESTful hoặc tự động hóa các tác vụ.
Làm thế nào để sử dụng Fetch API trong Node.JS?
Fetch API là một giao diện hiện đại dựa trên Promise được thiết kế để xử lý các yêu cầu mạng một cách hiệu quả và linh hoạt hơn so với đối tượng XMLHttpRequest truyền thống.
Nó được hỗ trợ sẵn trong các trình duyệt hiện đại, có nghĩa là không cần thư viện hoặc plugin bổ sung. Trong hướng dẫn này, chúng ta sẽ tìm hiểu cách sử dụng Fetch API để thực hiện các yêu cầu GET và POST, cũng như cách quản lý các phản hồi và lỗi một cách hiệu quả.
💬 Lưu ý: Nếu Node.js chưa được cài đặt trên máy tính của bạn, bạn cần cài đặt nó trước. Bạn có thể tải xuống gói cài đặt Node.js phù hợp với hệ điều hành của mình tại đây. Phiên bản Node.js được khuyến nghị là 18 trở lên.
Bước 1. Khởi tạo dự án Node.js của bạn
Nếu bạn chưa tạo dự án, bạn có thể tạo một dự án mới với lệnh sau:
Bash
mkdir fetch-api-tutorial
cd fetch-api-tutorial
npm init -yMở tệp package.json, thêm trường type và đặt nó thành module:
JSON
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}Bước 2. Tải xuống và cài đặt thư viện node-fetch
Đây là thư viện để sử dụng Fetch API trong Node.js. Bạn có thể cài đặt thư viện node-fetch bằng lệnh sau:
Bash
npm install node-fetchSau khi tải xuống hoàn tất, chúng ta có thể bắt đầu sử dụng Fetch API để gửi các yêu cầu mạng. Tạo một tệp mới index.js trong thư mục gốc của dự án và thêm mã sau:
JavaScript
import fetch from 'node-fetch';
fetch('https://jsonplaceholder.typicode.com/posts')
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));Thực hiện lệnh sau để chạy mã:
Bash
node index.jsChúng ta sẽ thấy đầu ra sau:
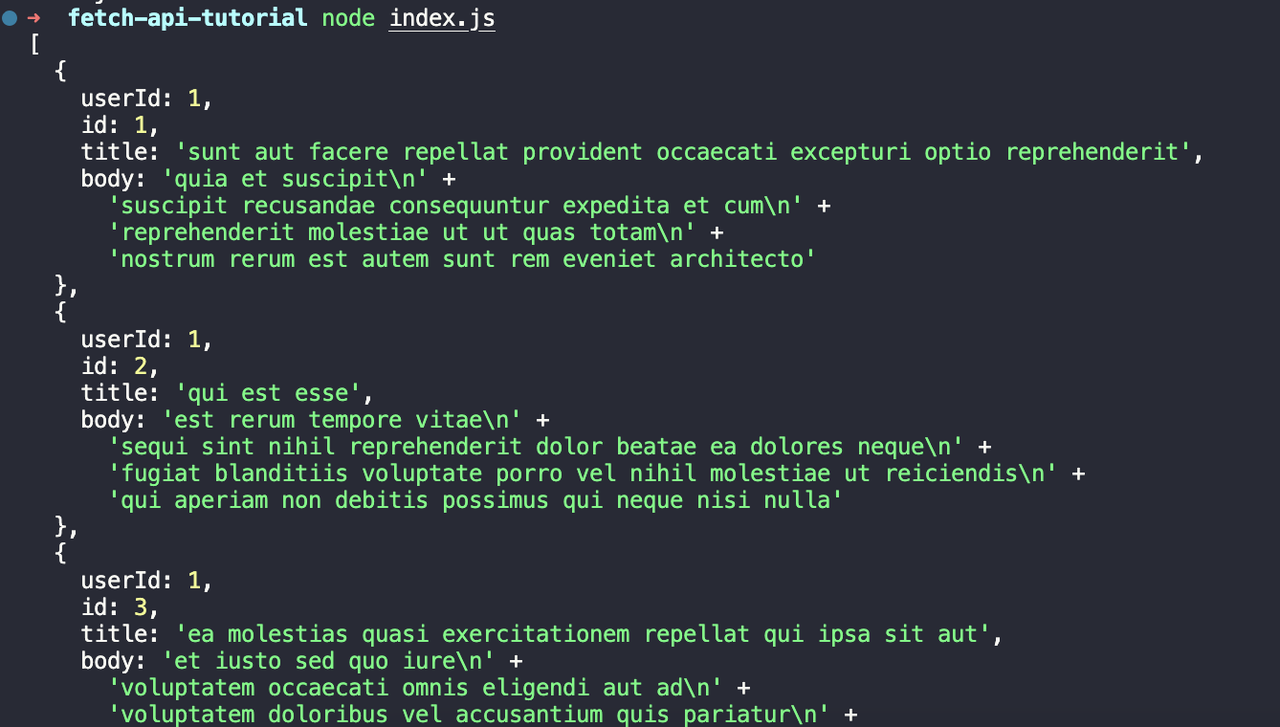
Bước 3. Sử dụng Fetch API để gửi yêu cầu POST
Làm thế nào để sử dụng Fetch API để gửi yêu cầu POST? Vui lòng tham khảo phương pháp sau. Tạo một tệp mới post.js trong thư mục gốc của dự án và thêm mã sau:
JavaScript
import fetch from 'node-fetch';
const postData = {
title: 'foo',
body: 'bar',
userId: 1,
};
fetch('https://jsonplaceholder.typicode.com/posts', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(postData),
})
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));Hãy phân tích mã này:
- Đầu tiên, chúng ta định nghĩa một đối tượng có tên là
postData, chứa dữ liệu mà chúng ta muốn gửi. - Sau đó, chúng ta sử dụng hàm
fetchđể gửi một yêu cầu POST đếnhttps://jsonplaceholder.typicode.com/posts, truyền một đối tượng cấu hình làm tham số thứ hai. - Đối tượng cấu hình chứa
method,headersvàbodycủa yêu cầu.
Thực hiện lệnh sau để chạy mã:
Bash
node post.jsĐầu ra bạn có thể thấy:

Bước 4. Xử lý kết quả và lỗi phản hồi Fetch API
Chúng ta cần tạo một tệp mới response.js trong thư mục gốc của dự án và thêm mã sau:
JavaScript
import fetch from 'node-fetch';
fetch('https://jsonplaceholder.typicode.com/posts-response')
.then((response) => {
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
return response.json();
})
.then((data) => console.log(data))
.catch((error) => console.error(error));Trong mã trên, đầu tiên chúng ta điền vào một địa chỉ URL không chính xác để kích hoạt lỗi HTTP. Sau đó, chúng ta kiểm tra mã trạng thái của phản hồi kết quả trong phương thức then và ném lỗi nếu mã trạng thái không phải là 200. Cuối cùng, chúng ta bắt lỗi trong phương thức catch và in nó ra.
Thực hiện lệnh sau để chạy mã:
Bash
node response.jsSau khi mã được thực hiện, bạn sẽ thấy đầu ra sau:

3 Thách thức phổ biến trong thu thập dữ liệu web
1. CAPTCHA
CAPTCHA (Completely Automated Public Turing tests to tell Computers and Humans Apart) được thiết kế để ngăn chặn các hệ thống tự động, như các chương trình thu thập dữ liệu web, truy cập vào các trang web. Chúng thường yêu cầu người dùng chứng minh họ là người bằng cách giải các câu đố, xác định các đối tượng trong hình ảnh hoặc nhập các ký tự bị biến dạng.
2. Nội dung động
Nhiều trang web hiện đại sử dụng các khung JavaScript như React, Angular hoặc Vue.js để tải nội dung một cách động. Điều này có nghĩa là nội dung bạn nhìn thấy trong trình duyệt thường được hiển thị sau khi trang tải xong, khiến việc thu thập dữ liệu bằng các phương pháp truyền thống dựa trên HTML tĩnh trở nên khó khăn.
3. Chặn IP
Các trang web thường thực hiện các biện pháp để phát hiện và chặn các hoạt động thu thập dữ liệu, một trong những phương pháp phổ biến nhất là chặn IP. Điều này xảy ra khi quá nhiều yêu cầu được gửi từ cùng một địa chỉ IP trong một thời gian ngắn, khiến trang web gắn cờ và chặn địa chỉ IP đó.
Bộ công cụ thu thập dữ liệu Scrapeless - Công cụ thu thập dữ liệu hiệu quả
Scrapeless là một trong những công cụ thu thập dữ liệu toàn diện tốt nhất nhờ khả năng bỏ qua các khối trang web trong thời gian thực, bao gồm chặn IP, thách thức CAPTCHA và hiển thị JavaScript. Nó hỗ trợ các tính năng nâng cao như luân phiên IP, quản lý dấu vân tay TLS và giải quyết CAPTCHA, làm cho nó trở nên lý tưởng cho việc thu thập dữ liệu web quy mô lớn.
Scrapeless nâng cao các dự án thu thập dữ liệu web Node.js như thế nào?
Việc tích hợp dễ dàng với Node.js và tỷ lệ thành công cao trong việc tránh phát hiện làm cho Scrapeless trở thành lựa chọn đáng tin cậy và hiệu quả để bỏ qua các biện pháp phòng chống bot hiện đại, đảm bảo hoạt động thu thập dữ liệu mượt mà và không bị gián đoạn.
Ưu điểm của việc sử dụng bộ công cụ thu thập dữ liệu như Scrapeless so với thu thập dữ liệu thủ công
- Xử lý hiệu quả các khối trang web: Scrapeless có thể bỏ qua các biện pháp chống thu thập dữ liệu phổ biến như chặn IP, CAPTCHA và hiển thị JavaScript trong thời gian thực, điều mà thu thập dữ liệu thủ công không thể xử lý hiệu quả.
- Độ tin cậy và tỷ lệ thành công: Scrapeless sử dụng các tính năng nâng cao như luân phiên IP và quản lý dấu vân tay TLS để tránh phát hiện, đảm bảo tỷ lệ thành công cao hơn và thu thập dữ liệu không bị gián đoạn so với thu thập dữ liệu thủ công.
- Tích hợp và tự động hóa dễ dàng: Tích hợp liền mạch với Node.js và tự động hóa toàn bộ quy trình thu thập dữ liệu, giúp tiết kiệm thời gian và giảm lỗi do con người so với việc thu thập dữ liệu thủ công.
Chỉ cần làm theo một vài bước đơn giản, bạn có thể tích hợp Scrapeless vào dự án Node.js của mình.
Đã đến lúc tiếp tục cuộn! Những điều sau đây sẽ tuyệt vời hơn!
Tích hợp Bộ công cụ thu thập dữ liệu Scrapeless vào dự án Node.js của bạn
Trước khi bắt đầu, bạn cần đăng ký tài khoản Scrapeless. Bạn cũng có thể tham khảo trang web chính thức để tìm hiểu thêm về Scrapeless.
Bước 1. Truy cập API thu thập dữ liệu Scrapeless trong Node.js
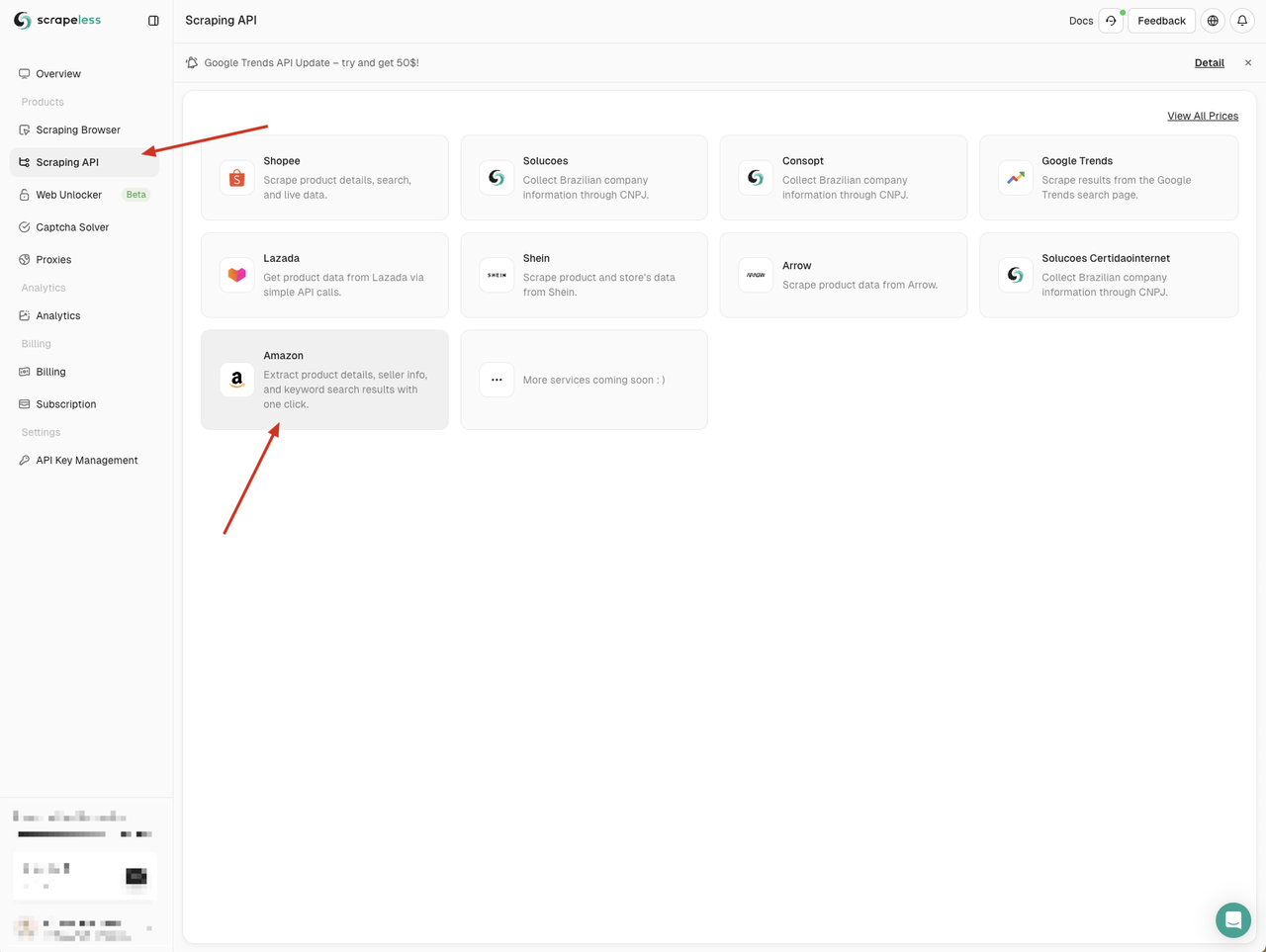
Chúng ta cần đến Bảng điều khiển của Scrapeless, nhấp vào menu "Scraping API" ở bên trái, và sau đó chọn dịch vụ bạn muốn sử dụng.
Ở đây chúng ta có thể sử dụng dịch vụ "Amazon"
Nhập trang API của Amazon, chúng ta có thể thấy rằng Scrapeless đã cung cấp cho chúng ta các tham số mặc định và ví dụ mã ở ba ngôn ngữ:
- Python
- Go
- Node.js
Ở đây chúng ta chọn Node.js và sao chép ví dụ mã vào dự án của mình:
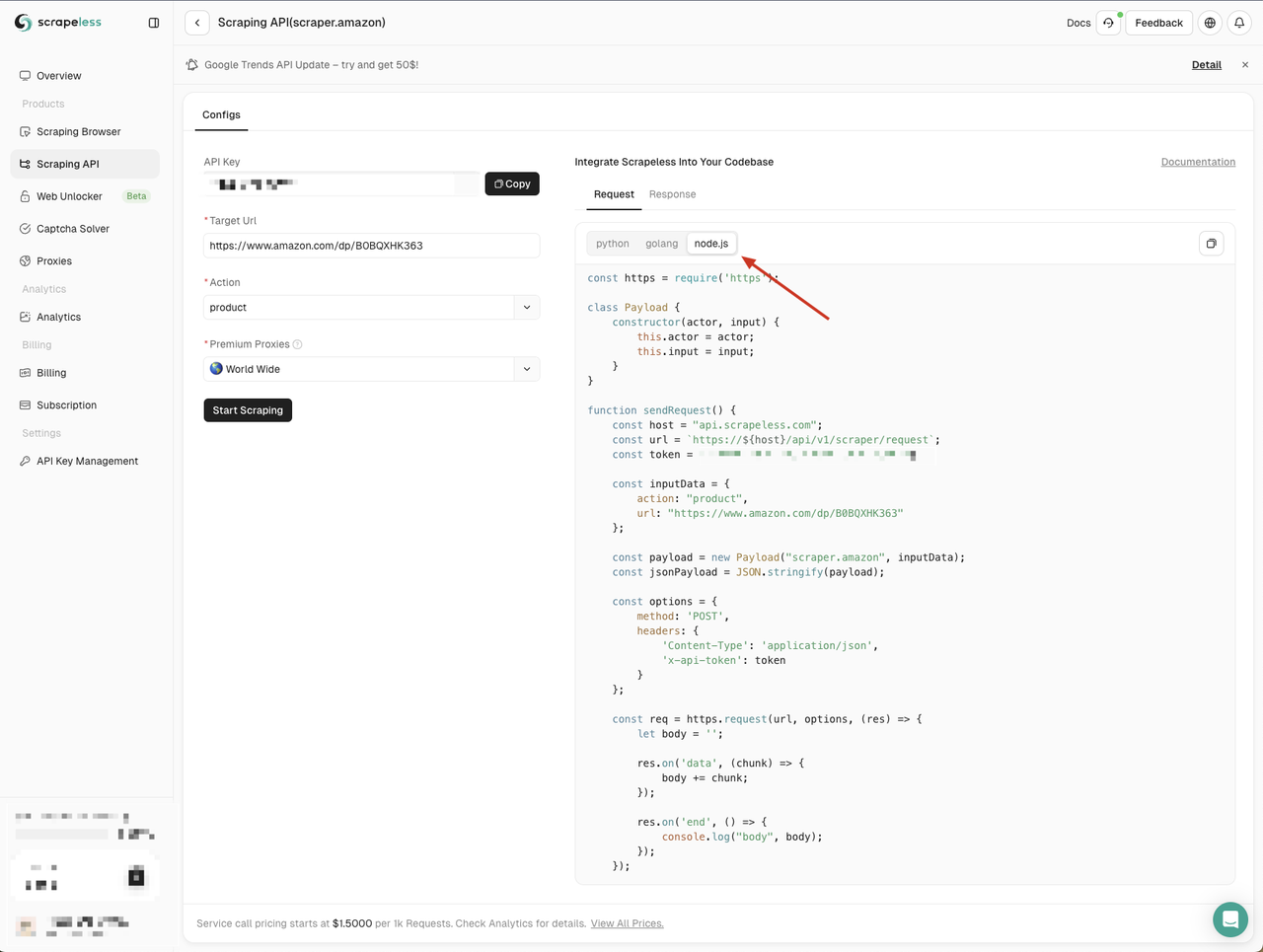
Các ví dụ mã Node.js của Scrapeless sử dụng mô-đun http theo mặc định. Chúng ta có thể sử dụng mô-đun node-fetch để thay thế mô-đun http, để chúng ta có thể sử dụng Fetch API để gửi các yêu cầu mạng.
Đầu tiên, tạo một tệp scraping-api-amazon.js trong dự án của chúng ta, và sau đó thay thế các ví dụ mã do Scrapeless cung cấp bằng các ví dụ mã sau:
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input) {
this.actor = actor;
this.input = input;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/scraper/request`;
const token = ''; // Token API của bạn
const inputData = {
action: 'product',
url: 'https://www.amazon.com/dp/B0BQXHK363',
};
const payload = new Payload('scraper.amazon', inputData);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`HTTP Error: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();Chạy mã bằng cách thực hiện lệnh sau:
Bash
node scraping-api-amazon.js Chúng ta sẽ thấy kết quả được trả về bởi API Scrapeless. Ở đây chúng ta chỉ đơn giản in chúng ra. Bạn có thể xử lý các kết quả được trả về theo nhu cầu của mình.
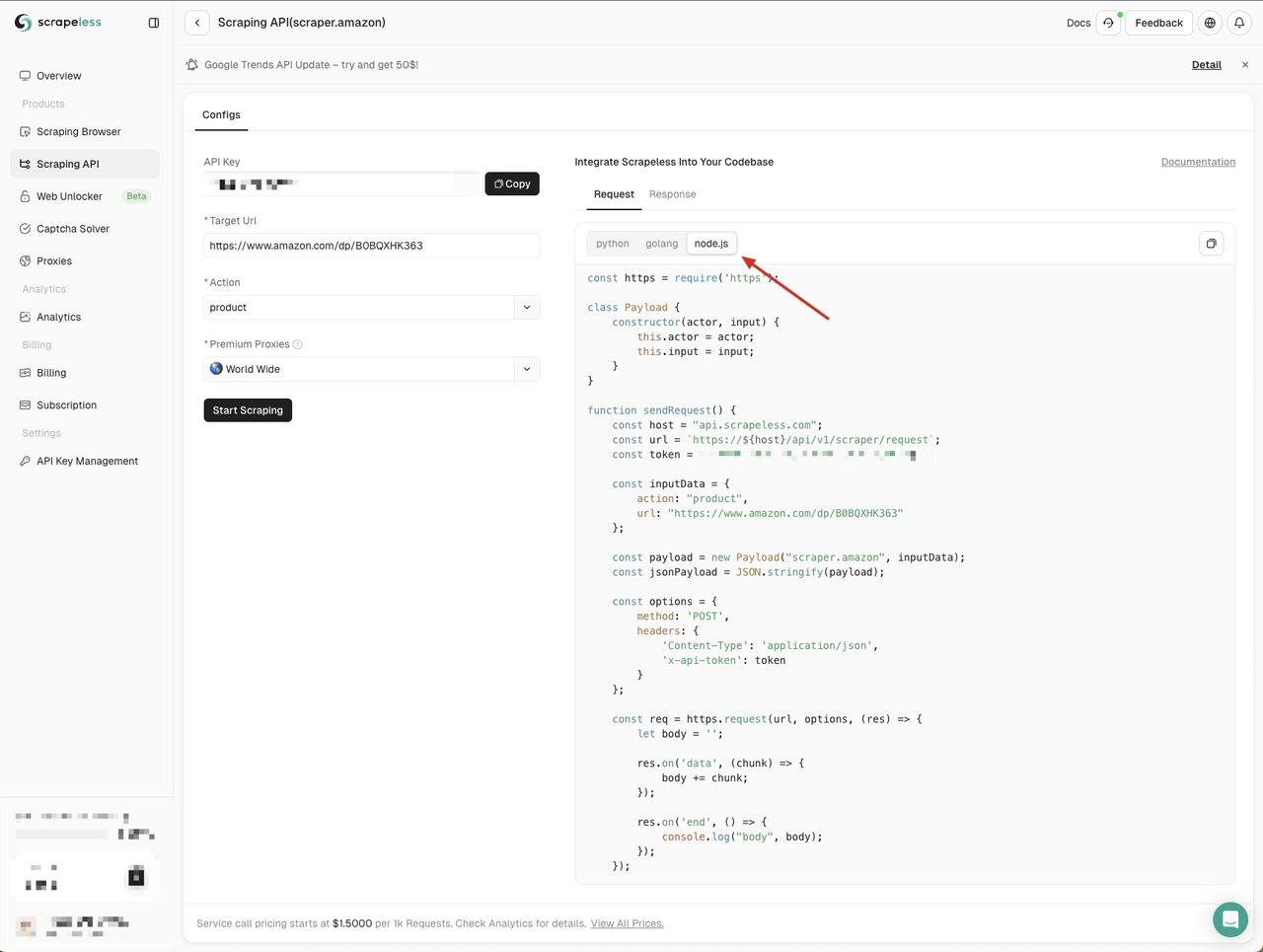
Bước 2. Tận dụng Web Unlocker để bỏ qua các biện pháp chống thu thập dữ liệu phổ biến
Scrapeless cung cấp dịch vụ Web unlocker có thể giúp bạn bỏ qua các biện pháp chống thu thập dữ liệu phổ biến, chẳng hạn như bỏ qua CAPTCHA, chặn IP, v.v. Dịch vụ Web unlocker có thể giúp bạn giải quyết một số vấn đề thu thập dữ liệu phổ biến và làm cho các tác vụ thu thập dữ liệu của bạn mượt mà hơn.
Để kiểm tra hiệu quả của dịch vụ Web unlocker, trước tiên chúng ta có thể sử dụng lệnh curl để truy cập một trang web yêu cầu CAPTCHA, và sau đó sử dụng dịch vụ Web unlocker của Scrapeless để truy cập cùng một trang web để xem liệu CAPTCHA có được bỏ qua thành công hay không.
- Sử dụng lệnh curl để truy cập một trang web yêu cầu mã xác minh, chẳng hạn như
https://identity.getpostman.com/login:
Bash
curl https://identity.getpostman.com/loginBằng cách xem kết quả được trả về, chúng ta có thể thấy rằng trang web này được kết nối với cơ chế xác minh Cloudflare, và chúng ta cần nhập mã xác minh để tiếp tục truy cập trang web.

- Chúng ta sử dụng dịch vụ Web unlocker của Scrapeless để truy cập cùng một trang web:
- Truy cập Bảng điều khiển Scrapeless
- Nhấp vào menu Web unlocker ở bên trái
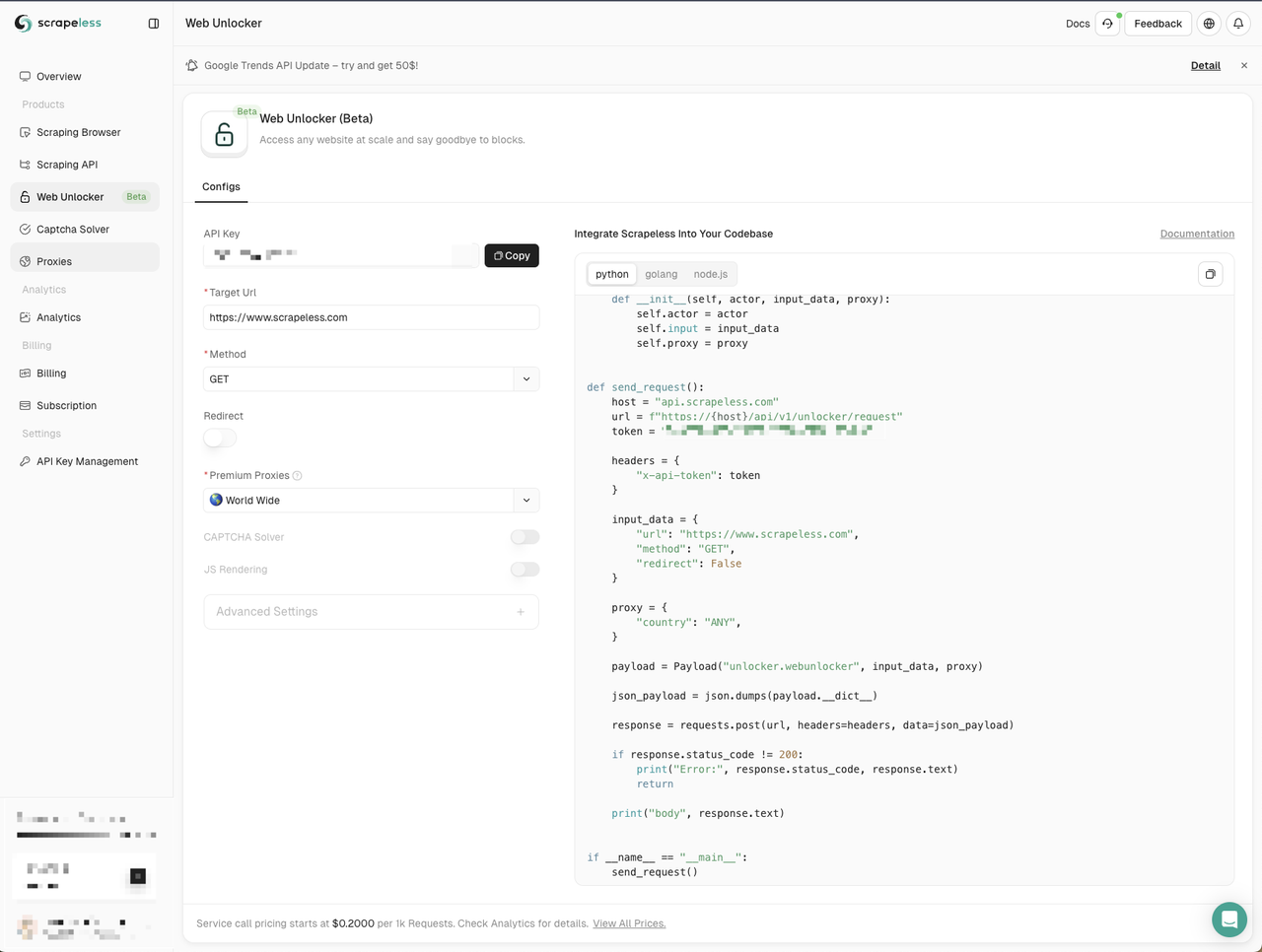
- Sao chép ví dụ mã Node.js vào dự án của chúng ta
Ở đây chúng ta tạo một tệp web-unlocker.js mới. Chúng ta vẫn cần sử dụng mô-đun node-fetch để gửi các yêu cầu mạng, vì vậy chúng ta cần thay thế mô-đun http trong ví dụ mã do Scrapeless cung cấp bằng mô-đun node-fetch:
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input, proxy) {
this.actor = actor;
this.input = input;
this.proxy = proxy;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/unlocker/request`;
const token = ''; // Token API của bạn
const inputData = {
url: 'https://identity.getpostman.com/login',
method: 'GET',
redirect: false,
};
const proxy = {
country: 'ANY',
};
const payload = new Payload('unlocker.webunlocker', inputData, proxy);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();Thực hiện lệnh sau để chạy script:
JavaScript
web-unlocker.js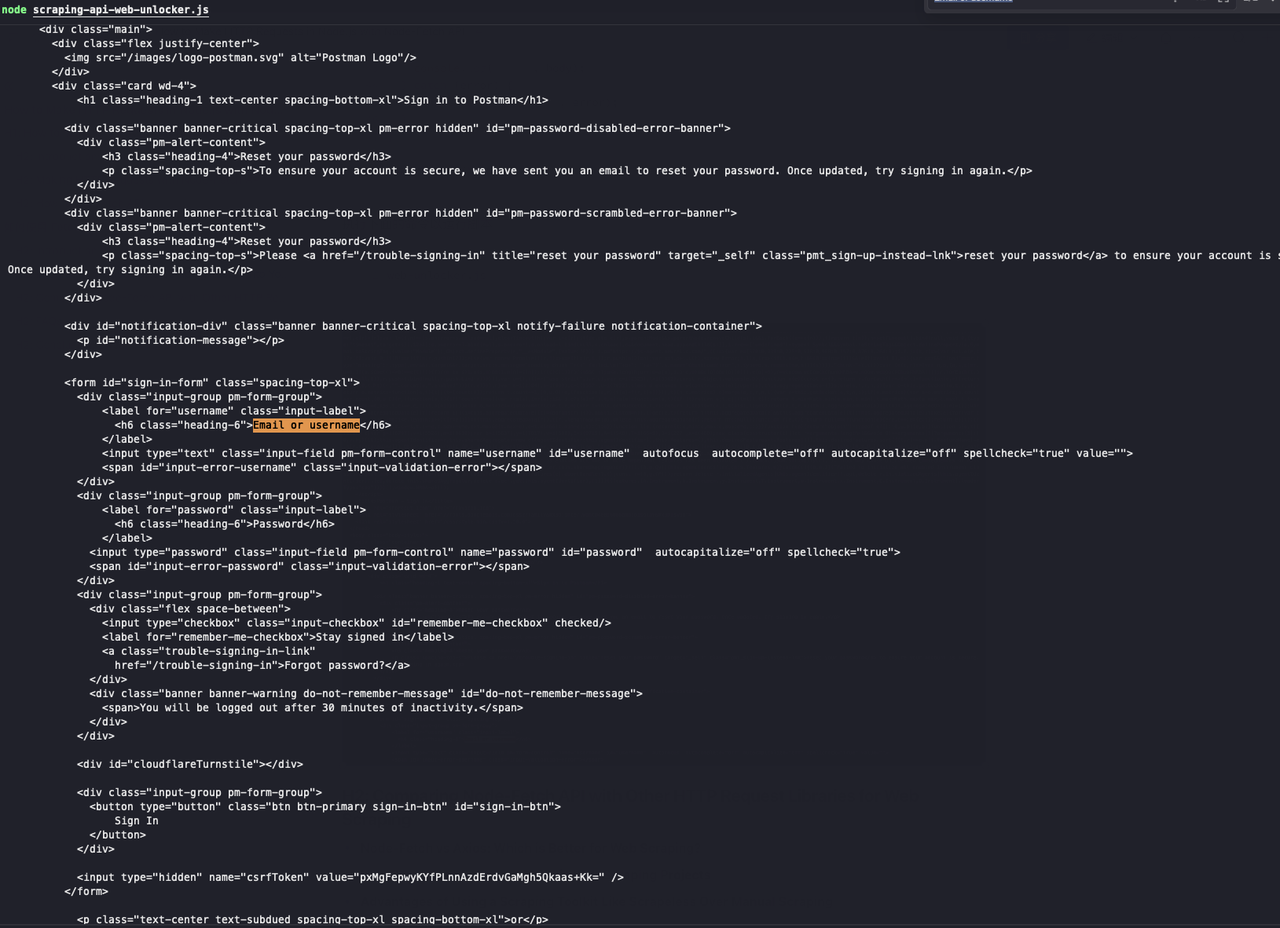
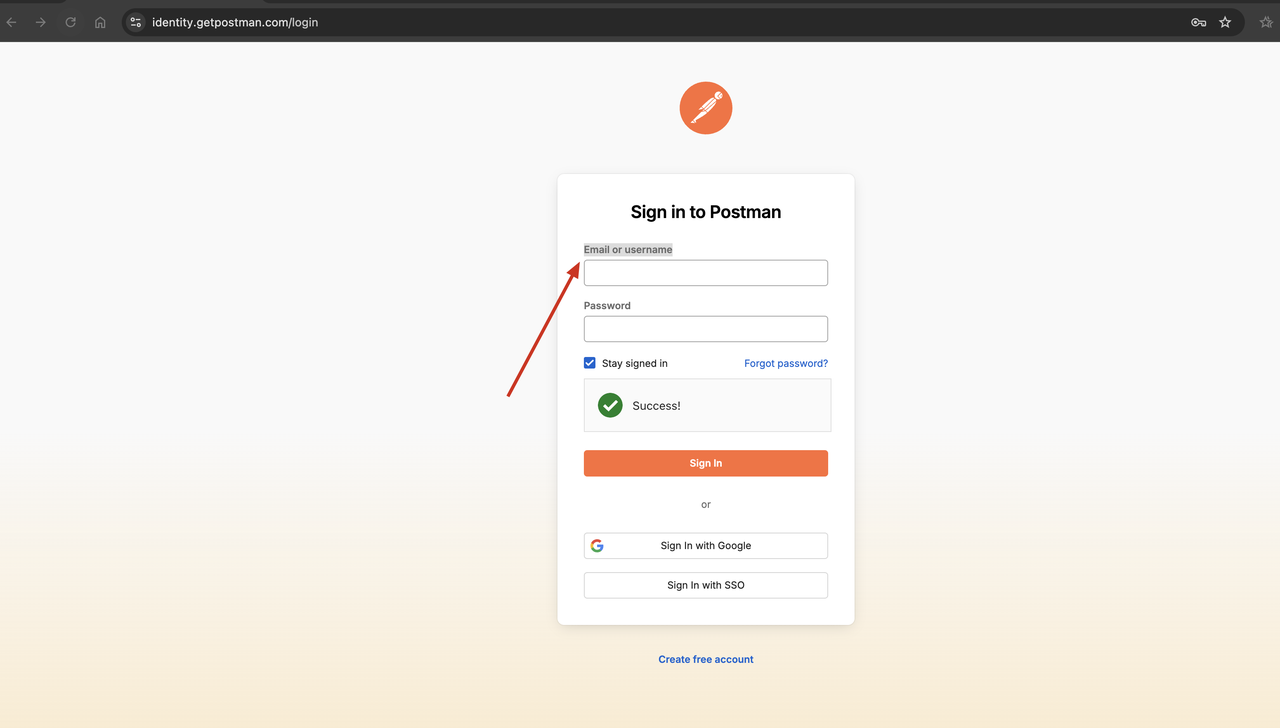
Nhìn xem! Scrapeless Web unlocker đã bỏ qua mã xác minh thành công, và chúng ta có thể thấy rằng kết quả được trả về chứa nội dung trang web mà chúng ta cần.
Câu hỏi thường gặp
Câu 1. Node-Fetch so với Axios: cái nào tốt hơn cho việc thu thập dữ liệu web?
Để giúp bạn dễ dàng lựa chọn, Axios và Fetch API có những khác biệt sau:
- Fetch API sử dụng thuộc tính body của yêu cầu, trong khi Axios sử dụng thuộc tính data.
- Với Axios, bạn có thể gửi dữ liệu JSON trực tiếp, trong khi Fetch API cần được chuyển đổi thành chuỗi.
- Axios có thể xử lý JSON trực tiếp. Fetch API yêu cầu gọi phương thức response.json() trước để nhận phản hồi ở định dạng JSON.
- Đối với Axios, tên biến dữ liệu phản hồi phải là data; đối với Fetch API, tên biến dữ liệu phản hồi có thể là bất cứ thứ gì.
- Axios cho phép giám sát và cập nhật tiến độ dễ dàng bằng các sự kiện tiến độ. Không có phương pháp trực tiếp trong Fetch API.
- Fetch API không hỗ trợ interceptor, trong khi Axios thì có.
- Fetch API cho phép phản hồi luồng, trong khi Axios thì không.
Câu 2. Node fetch có ổn định không?
Tính năng đáng chú ý nhất của Node. js v21 là việc ổn định hóa Fetch API.
Câu 3. Fetch API có tốt hơn AJAX không?
Đối với các dự án mới, nên sử dụng Fetch API vì các tính năng hiện đại và sự đơn giản của nó. Tuy nhiên, nếu bạn cần hỗ trợ các trình duyệt rất cũ hoặc đang duy trì mã cũ, thì Ajax vẫn có thể cần thiết.
Kết luận
Việc bổ sung Fetch API trong Node.js là một tính năng được mong đợi từ lâu. Sử dụng Fetch API trong Node.js có thể đảm bảo rằng công việc thu thập dữ liệu của bạn được thực hiện dễ dàng. Tuy nhiên, việc gặp phải các lệnh cấm mạng nghiêm trọng khi sử dụng Node Fetch API là không thể tránh khỏi.
Muốn giải quyết hoàn toàn việc cấm IP và CAPTCHA? Hãy chắc chắn sử dụng Scrapeless để dễ dàng bỏ qua việc giám sát trang web và chặn IP.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


