
Làm thế nào để lấy dữ liệu sản phẩm Naver bằng API Scrapeless Scraping?
Senior Web Scraping Engineer
Với sự gia tăng của mua sắm trực tuyến, 24% tổng doanh thu bán lẻ hiện nay đến từ các thị trường thương mại điện tử. Đến năm 2025, doanh thu bán lẻ thương mại điện tử toàn cầu dự kiến sẽ đạt $7.4 trillion.
Naver, công cụ tìm kiếm lớn nhất Hàn Quốc và gã khổng lồ công nghệ, là trái tim của đời sống số của đất nước. Từ thương mại điện tử và thanh toán kỹ thuật số đến webtoon, blog và nhắn tin di động, nó thu thập dữ liệu người dùng trong nhiều lĩnh vực hơn bất kỳ nền tảng nào khác.
Kiến trúc của Naver được thiết kế để phá vỡ các mô hình dự đoán, phát hiện sự không nhất quán và thích ứng nhanh chóng hơn hầu hết các hệ thống. Nếu chiến lược thu thập dữ liệu của bạn phụ thuộc vào các kịch bản tĩnh hoặc proxy tấn công brute-force, điều đó đã lỗi thời. Việc thu thập dữ liệu Naver Shop thành công không chỉ là vượt qua các lớp phòng thủ - nó yêu cầu phối hợp hành vi phiên, logic thời gian và đồng bộ với kỳ vọng của nền tảng.
Làm thế nào để bạn thu thập dữ liệu sản phẩm từ Naver Shop một cách nhanh chóng, quy mô lớn và với chi phí tối thiểu?
Hướng dẫn này dành cho các đội ngũ doanh nghiệp, chủ sở hữu dữ liệu và lãnh đạo đang đối mặt với những thách thức thu thập dữ liệu Naver hiện đại!
💼 Tại sao nên thu thập dữ liệu Naver?
- Chiến lược giá cạnh tranh: Sử dụng thu thập dữ liệu Naver Shopping để thu thập thông tin giá cả của đối thủ, giúp bạn giữ vị thế dẫn đầu trên thị trường.
- Tối ưu hóa tồn kho: Giám sát mức hàng tồn kho theo thời gian thực để giảm thiếu hụt và cải thiện hiệu suất.
- Phân tích xu hướng thị trường: Xác định các xu hướng nổi bật và sở thích của người tiêu dùng để điều chỉnh các sản phẩm của bạn.
- Cải thiện danh sách sản phẩm: Trích xuất các mô tả chi tiết, hình ảnh và thông số kỹ thuật để tạo ra các danh sách hấp dẫn.
- Giám sát và điều chỉnh giá: Theo dõi thay đổi giá và khuyến mãi để tối ưu hóa các chương trình khuyến mãi.
- Phân tích đối thủ: Phân tích các sản phẩm, giá cả và chương trình khuyến mãi của đối thủ để vượt trội hơn họ.
- Tiếp thị dựa trên dữ liệu: Thu thập thông tin về hành vi người tiêu dùng để thực hiện các chiến dịch mục tiêu.
- Cải thiện sự hài lòng của khách hàng: Giám sát đánh giá và xếp hạng để tinh chỉnh sản phẩm và tăng cường sự hài lòng.
💡 Dữ liệu sản phẩm nào chúng ta có thể trích xuất từ Naver?
Việc thu thập giá cả, tình trạng hàng tồn kho, mô tả, đánh giá và khuyến mãi đảm bảo dữ liệu toàn diện và cập nhật. Một công cụ thu thập dữ liệu Naver mạnh mẽ có thể trích xuất:
| Trường | Trường | Trường |
|---|---|---|
| ✅ Tên sản phẩm | ✅ Đánh giá của khách hàng | ✅ Khuyến mãi |
| ✅ Đặc điểm sản phẩm | ✅ Mô tả | ✅ Hình ảnh |
| ✅ Đánh giá | ✅ Tùy chọn giao hàng | ✅ Danh mục |
| ✅ Phân loại con | ✅ ID sản phẩm | ✅ Thương hiệu |
| ✅ Thời gian giao hàng | ✅ Chính sách hoàn trả | ✅ Tình trạng |
| ✅ Giá | ✅ Thông tin người bán | ✅ Ngày hết hạn |
| ✅ Địa điểm cửa hàng | ✅ Thành phần | ✅ Giá đã giảm |
| ✅ Giá gốc | ✅ Các gói ưu đãi | ✅ Lần cập nhật cuối |
| ✅ Mã hàng tồn kho (SKU) | ✅ Cân nặng/Thể tích | ✅ Tỷ lệ giảm giá |
| ✅ Giá đơn vị | ✅ Thông tin dinh dưỡng |
⚠️ Những khó khăn trong việc thu thập thông tin sản phẩm từ Naver là gì?
Trước khi xem xét cách thu thập dữ liệu từ Naver, mỗi công ty nên xem xét sáu thách thức lớn sau:
1. Thiếu điểm vào ổn định hoặc kiểm soát phiên
Việc thu thập dữ liệu ẩn danh là dấu hiệu đỏ. Naver yêu cầu hành vi người dùng nhất quán. Không có mô phỏng phiên phản ánh hoạt động của người dùng trong các khu vực được ủy quyền, hành động của bạn sẽ có vẻ nghi ngờ, yếu ớt và nhanh chóng bị từ chối.
2. Thách thức trong việc kết xuất JavaScript
JavaScript điều khiển nội dung và thời gian phản hồi quan trọng trên Naver. Nếu công cụ trích xuất của bạn không thể kết xuất chính xác JS hoặc phát hiện sự thay đổi sau khi tải, dữ liệu của bạn sẽ không đầy đủ, lỗi thời hoặc không thể nhìn thấy. Bỏ qua sự phức tạp này có thể dẫn đến các thất bại tiềm ẩn, làm sai lệch thông tin cho những người ra quyết định.
3. Xác thực phiên, khóa địa lý và nâng cấp CAPTCHA
Mỗi lớp tự động hóa đều mang một nguy cơ!
- Nếu một lớp gặp sự cố, phiên của bạn sẽ hết hạn.
- Nếu hai lớp gặp sự cố, nghi ngờ sẽ xuất hiện.
- Nếu ba lớp gặp sự cố, bạn sẽ bị đánh dấu và chặn lại.
Nếu không có một chiến lược mô phỏng phiên bền bỉ, xoay vòng địa chỉ IP khu vực và xử lý tự động các thách thức đối mặt với người dùng (bao gồm CAPTCHA), hạ tầng của bạn sẽ trở thành một ngôi nhà bằng lá bài.
4. Thay đổi bố cục và thiết kế giao diện trên Naver Shop
Sự thay đổi của Naver rất tinh vi, thường xuyên và khó dự đoán! Những gì hoạt động hôm qua có thể không hoạt động hôm nay. Những thay đổi trong logic phân trang, di chuyển thẻ hoặc cơ cấu tải có thể ảnh hưởng nghiêm trọng đến các công cụ thu thập dữ liệu của bạn. Đội ngũ của bạn sẽ phải đối mặt với công việc tái thực hiện liên tục, và hệ thống phải phát hiện, phản hồi và tự phục hồi—hoặc có nguy cơ kiệt quệ tài nguyên.
5. Giới Hạn Tốc Độ và Chặn
Khi thu thập dữ liệu quy mô lớn, hãy chú ý đến số lượng yêu cầu và khối lượng dữ liệu trong một khoảng thời gian ngắn. Các chuyên gia trích xuất dữ liệu thông minh luôn tập trung vào việc vận hành trang, mô phỏng hành vi và các giao thức truy cập đa dạng—đây là các cấu hình cơ bản cho việc thu thập dữ liệu khối lượng lớn.
6. Quy Định Pháp Lý và Bảo Mật Dữ Liệu Hàn Quốc
Một điểm mù duy nhất có thể khiến bạn mất hàng triệu! Việc thu thập dữ liệu Naver từ nước ngoài mà không hiểu biết về các yêu cầu thu thập dữ liệu địa phương và luật sở hữu trí tuệ sẽ khiến công ty bạn đối mặt với rủi ro về danh tiếng và pháp lý. Rất được khuyến nghị thực hiện nghiên cứu kỹ lưỡng trước khi thu thập dữ liệu.
🤔 Tại Sao Nên Sử Dụng Scrapeless Để Trích Xuất Dữ Liệu Sản Phẩm Naver?
Scrapeless áp dụng công nghệ thu thập dữ liệu web tiên tiến để đảm bảo việc trích xuất dữ liệu chất lượng cao và chính xác nhằm đáp ứng các nhu cầu kinh doanh đa dạng—từ phân tích thị trường và chiến lược giá cạnh tranh đến quản lý tồn kho và phân tích hành vi người tiêu dùng. Dịch vụ của chúng tôi cung cấp các giải pháp liền mạch cho các nhà bán lẻ, nền tảng thương mại điện tử và nhà phân tích thị trường, giúp họ có được cái nhìn sâu sắc về thị trường hàng tiêu dùng (FMCG) đang phát triển nhanh chóng.
Với API thu thập dữ liệu Naver của chúng tôi, bạn có thể dễ dàng theo dõi xu hướng thị trường, tối ưu hóa chiến lược giá và duy trì lợi thế cạnh tranh trong ngành công nghiệp thực phẩm tươi sống đang phát triển nhanh chóng. Hãy tin tưởng chúng tôi để cung cấp những hiểu biết thực tiễn thúc đẩy sự phát triển và đổi mới của doanh nghiệp bạn.
Tính Năng Chính
1️⃣ Cực nhanh và Tin cậy: Nhanh chóng thu thập dữ liệu mà không làm mất ổn định.
2️⃣ Trường Dữ Liệu Đầy Đủ: Bao gồm chi tiết sản phẩm, thông tin người bán, giá cả, đánh giá và nhiều hơn nữa.
3️⃣ Hệ Thống Chuyển Đổi Proxy Thông Minh: Tự động thay đổi địa chỉ IP proxy để vượt qua các hạn chế truy cập dựa trên IP.
4️⃣ Công Nghệ Dấu Vân Tay Tiên Tiến: Mô phỏng động các đặc điểm trình duyệt và mẫu tương tác người dùng để vượt qua các cơ chế chống thu thập tinh vi.
5️⃣ Giải Quyết CAPTCHA Tích Hợp: Tự động xử lý các thách thức reCAPTCHA và Cloudflare, đảm bảo việc thu thập dữ liệu diễn ra suôn sẻ.
6️⃣ Tự Động Hóa: Quy trình thu thập hoàn toàn tự động với phản ứng nhanh chóng trước các bản cập nhật.
⏯️ KẾ HOẠCH-A. Trích Xuất Dữ Liệu Sản Phẩm Naver Qua API
- Chỉ cần cấu hình ID Cửa Hàng và ID Sản Phẩm.
- API Naver của Scrapeless sẽ trích xuất dữ liệu sản phẩm chi tiết từ Naver Shop, bao gồm giá cả, thông tin người bán, đánh giá và nhiều hơn nữa.
- Bạn có thể tải xuống và phân tích dữ liệu.
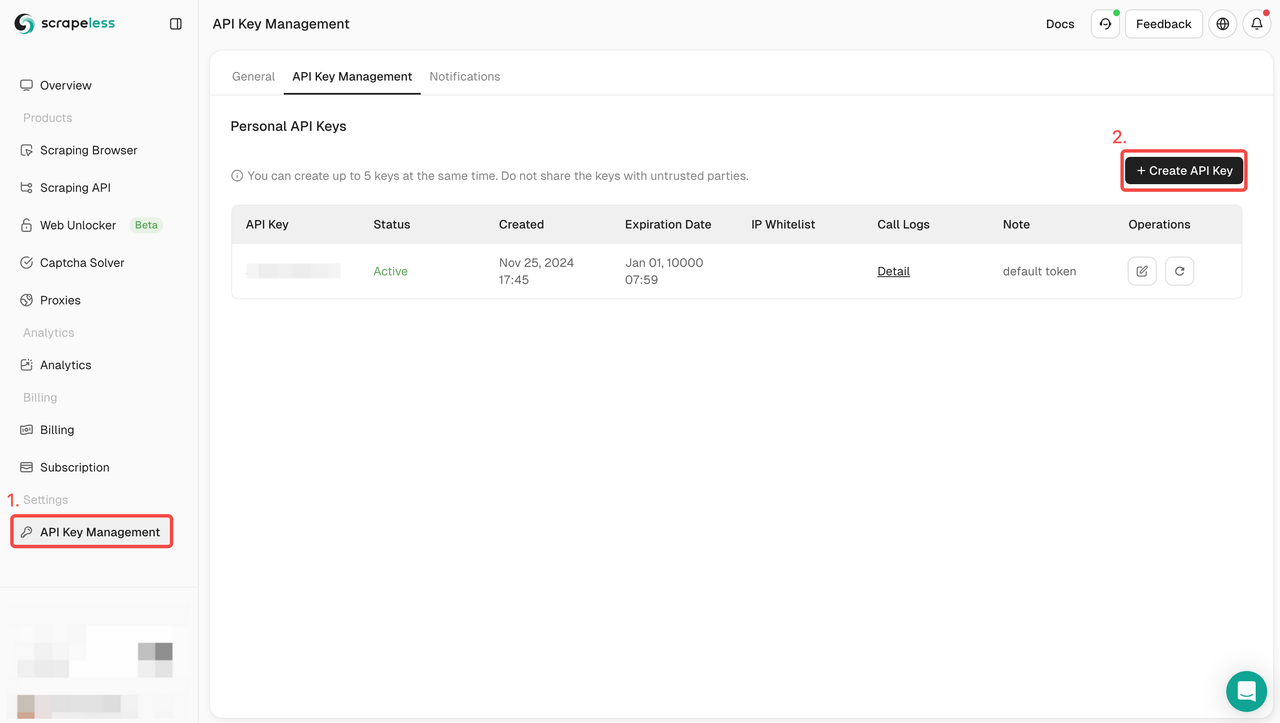
Bước 1: Tạo Mã API của bạn
Để bắt đầu, bạn cần lấy Mã API của mình từ Bảng Điều Khiển Scrapeless:
- Đăng nhập vào Bảng Điều Khiển Scrapeless.
- Chuyển đến Quản Lý Mã API.
- Nhấp vào Tạo để tạo Mã API duy nhất của bạn.
- Sau khi tạo xong, bạn có thể nhấp vào Mã API để sao chép nó.
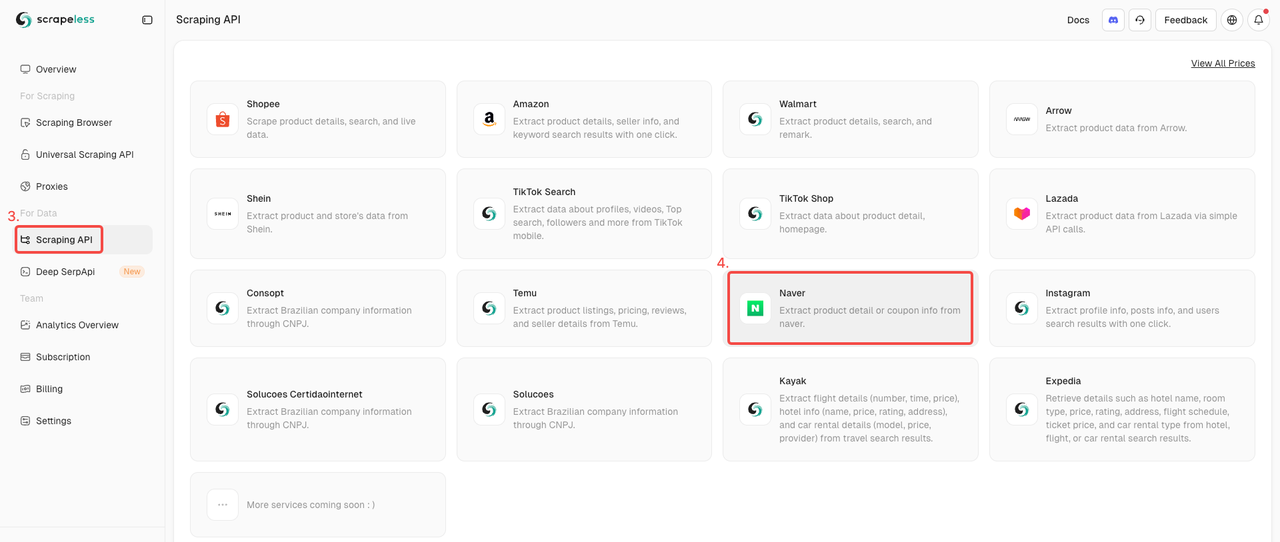
Bước 2. Khởi Động API Naver Shop
- Tìm API Thu Thập Dữ Liệu trong phần Thu Thập Dữ Liệu.
- Chỉ cần nhấp vào nhân tố Naver Shop để sẵn sàng thu thập dữ liệu sản phẩm.
Bước 3: Định Nghĩa Mục Tiêu Của Bạn
Để thu thập dữ liệu sản phẩm bằng API Thu Thập Dữ Liệu Naver, bạn phải cung cấp hai tham số bắt buộc: storeId và productId. Tham số channelUid là tùy chọn.
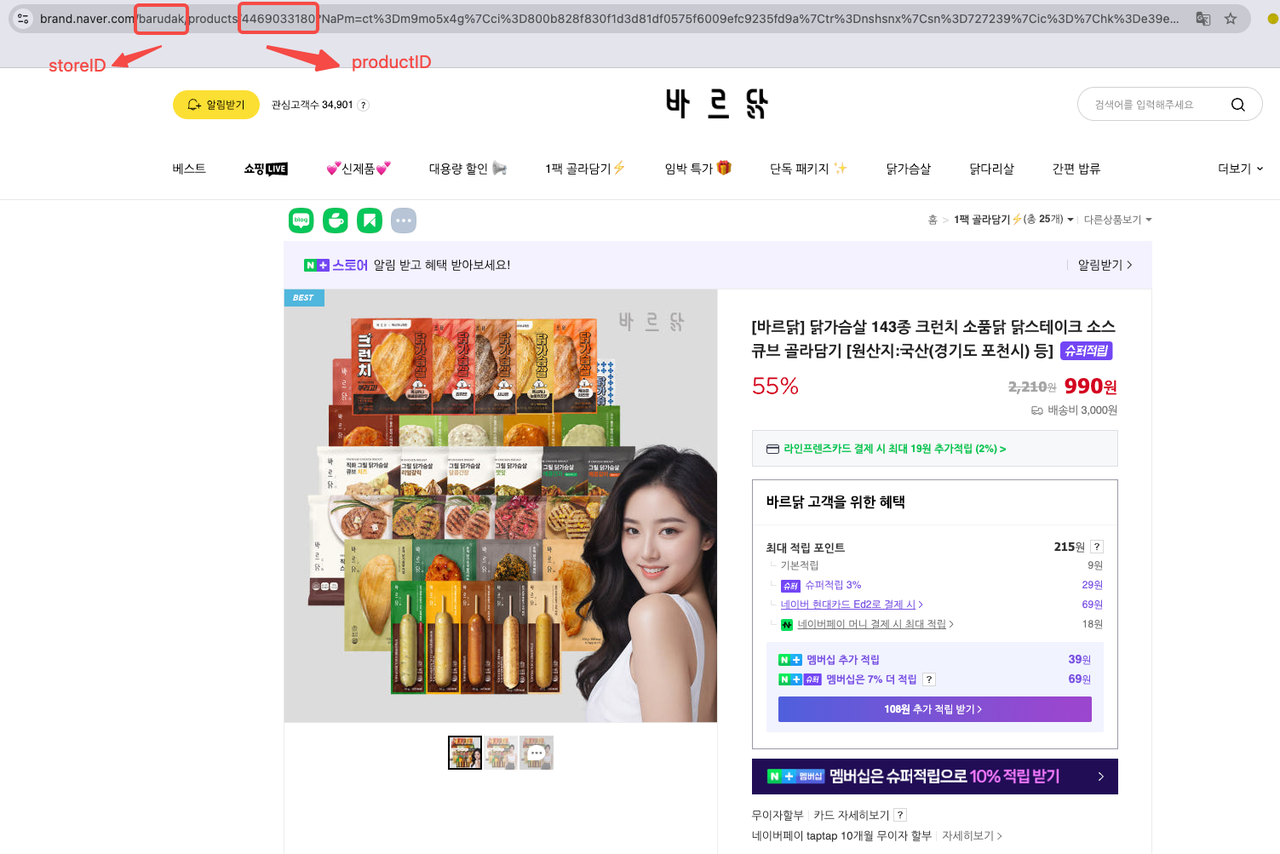
Bạn có thể tìm ID Sản Phẩm và ID Cửa Hàng trực tiếp trong URL sản phẩm. Ví dụ:
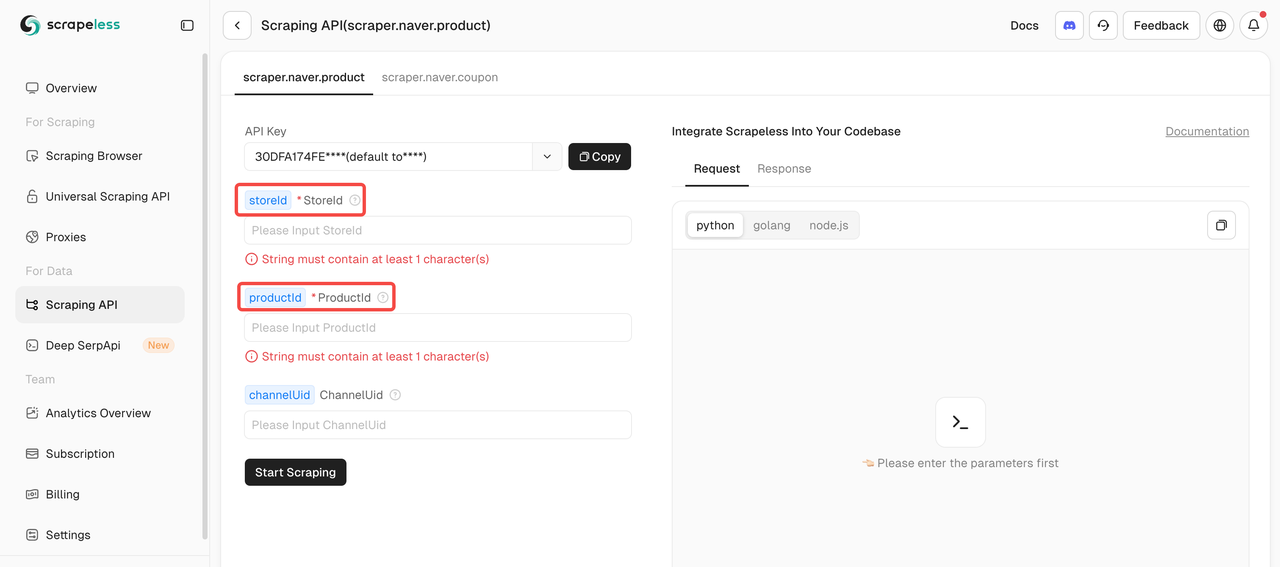
Bạn có thể tìm ID Sản Phẩm và ID Cửa Hàng trực tiếp trong URL sản phẩm. Hãy lấy [바르닭] 닭가슴살 143종 크런치 소품닭 닭스테이크 소스큐브 골라담기 [원산지:국산(경기도 포천시) 등] làm ví dụ:
- ID Cửa Hàng: barudak
- ID Sản Phẩm: 4469033180
Chúng tôi cam kết bảo vệ quyền riêng tư của trang web. Tất cả dữ liệu trong blog này là công khai và chỉ được sử dụng làm minh họa cho quy trình thu thập dữ liệu. Chúng tôi không lưu trữ bất kỳ thông tin và dữ liệu nào.
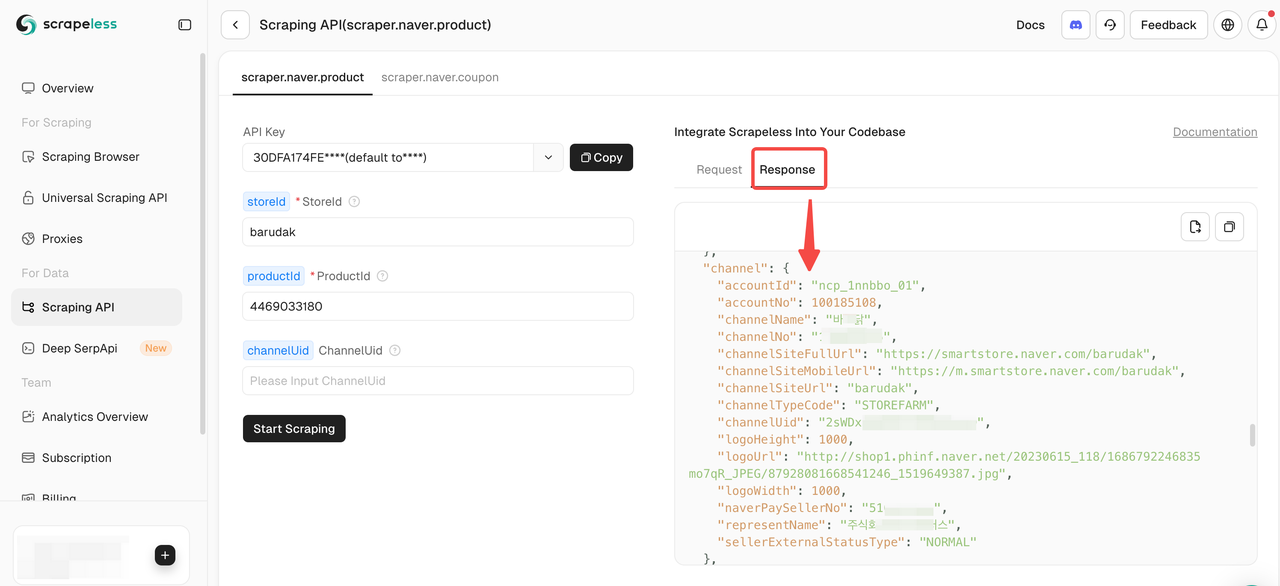
Bước 4: Bắt Đầu Thu Thập Dữ Liệu Sản Phẩm Naver
Một khi bạn đã điền đầy đủ các tham số cần thiết, chỉ cần nhấp vào Bắt Đầu Thu Thập để có được dữ liệu sản phẩm toàn diện.
Dưới đây là đoạn mã mẫu để trích xuất dữ liệu sản phẩm từ Naver. Chỉ cần thay thế YOUR_SCRAPELESS_API_TOKEN bằng khóa API thực tế của bạn:
Python
import json
import requests
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "YOUR_SCRAPELESS_API_TOKEN"
headers = {
"x-api-token": token
}
json_payload = json.dumps({
"actor": "scraper.naver.product",
"input": {
"storeId": "barudak",
"productId": "4469033180",
"channelUid": " " ## Tùy chọn
}
})
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Lỗi:", response.status_code, response.text)
return
print("nội dung", response.text)
if __name__ == "__main__":
send_request()⏯️ KẾ HOẠCH-B. Trích xuất dữ liệu sản phẩm Naver với Trình Duyệt Scraping
Nếu nhóm của bạn thích lập trình, Trình duyệt Scraping của Scrapeless Scraping Browser là một lựa chọn tuyệt vời. Nó đóng gói tất cả các thao tác phức tạp, đơn giản hóa quy trình trích xuất dữ liệu hiệu quả, quy mô lớn từ các trang web động. Nó tích hợp hoàn hảo với các công cụ phổ biến như Puppeteer và Playwright.
Bước 1: Tích hợp với Trình Duyệt Scraping của Scrapeless
Sau khi vào Trình Duyệt Scraping, chỉ cần điền các tham số cấu hình bên trái để tự động tạo ra một kịch bản scraping.
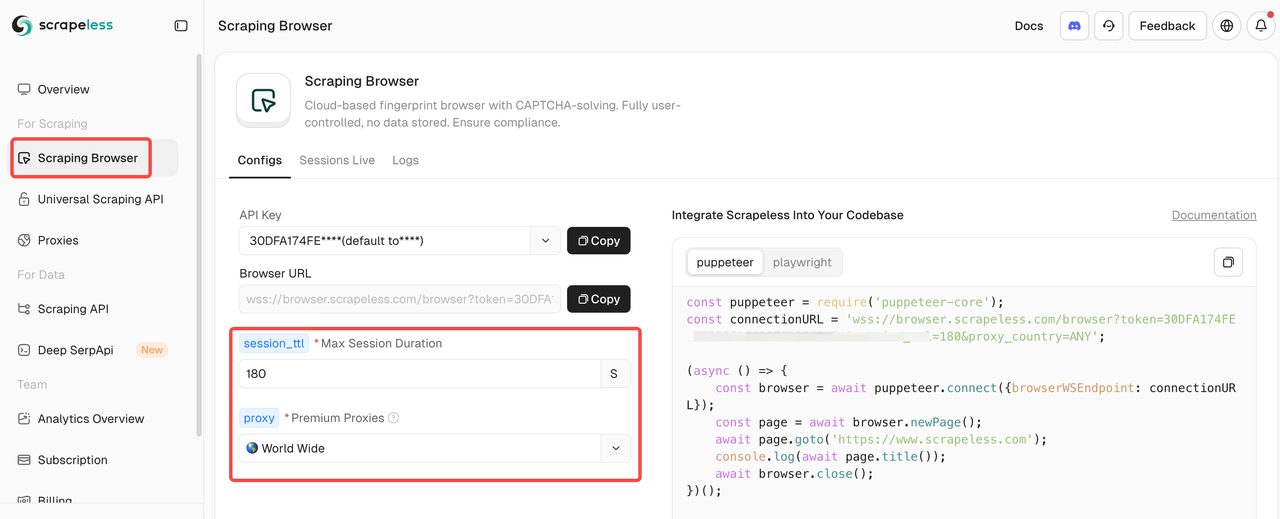
Dưới đây là mã tích hợp mẫu (JavaScript được khuyến nghị):
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=" YourAPIKey"&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Scrapeless tự động khớp proxy cho bạn, vì vậy không cần cấu hình bổ sung hoặc xử lý CAPTCHA. Kết hợp với xoay vòng proxy, quản lý dấu vết trình duyệt và khả năng scraping đồng thời mạnh mẽ, Scrapeless đảm bảo việc scraping quy mô lớn dữ liệu sản phẩm Naver mà không bị phát hiện, qua mặt hiệu quả các khối IP và thách thức CAPTCHA.
Bước 2: Đặt định dạng xuất
Bây giờ, bạn cần lọc và làm sạch dữ liệu đã được thu thập. Hãy xem xét xuất kết quả dưới dạng tệp CSV để phân tích dễ dàng hơn:
JavaScript
const csv = parse([productData]);
fs.writeFileSync('naver_product_data.csv', csv, 'utf-8');
console.log('Tệp CSV đã được lưu: naver_product_data.csv');
await browser.close();
})();Đọc thêm: Hướng dẫn chi tiết về Trình Duyệt Scraping của Scrapeless
Dưới đây là kịch bản scraping của chúng tôi, làm tài liệu tham khảo:
JavaScript
const puppeteer = require('puppeteer-core');
const fs = require('fs');
const { parse } = require('json2csv');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YourAPIKey&session_ttl=180&proxy_country=KR';
(async () => {
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL
});
const page = await browser.newPage();
// Thay thế bằng URL của trang sản phẩm Naver mà bạn thực sự muốn thu thập
const url = 'https://smartstore.naver.com/barudak/products/4469033180';
await page.goto(url, { waitUntil: 'networkidle2' });
// Ví dụ đơn giản: thu thập tiêu đề sản phẩm, giá cả, mô tả, v.v. (thích ứng theo cấu trúc trang thực tế)
const productData = await page.evaluate(() => {
const title = document.querySelector('h3._2Be85h')?.innerText || '';
const price = document.querySelector('span._1LY7DqCnwR')?.innerText || '';
const description = document.querySelector('div._2w4TxKo3Dx')?.innerText || '';
return {
title,
price,
description
};
});
console.log('Dữ liệu sản phẩm:', productData);
// Xuất ra CSV
const csv = parse([productData]);
fs.writeFileSync('naver_product_data.csv', csv, 'utf-8');
console.log('Tệp CSV đã được lưu: naver_product_data.csv');
await browser.close();
})();Chúc mừng, bạn đã hoàn thành toàn bộ quy trình thu thập dữ liệu sản phẩm Naver!
Những điều cốt yếu
Việc thu thập dữ liệu Naver là một khoản đầu tư chiến lược! Tuy nhiên, khi các nhóm sử dụng lập trình để thu thập dữ liệu, họ cần triển khai các hệ thống thích ứng, phối hợp hành vi phiên làm việc và tuân thủ nghiêm ngặt các quy định của nền tảng và luật dữ liệu Hàn Quốc. Cạnh tranh với kiến trúc động của Naver có nghĩa là cấu hình proxy, giải quyết CAPTCHA và giả lập hành vi của người dùng thực—tất cả đều là các nhiệm vụ tốn công sức.
Trên thực tế, chúng ta không cần phải dành nhiều thời gian cho việc bảo trì! Để đạt được điều này, chỉ cần tận dụng một công nghệ mạnh mẽ, bao gồm các công cụ tự động hóa trình duyệt và API, đảm bảo việc trích xuất dữ liệu sản phẩm Naver có thể mở rộng và tuân thủ ở bất kỳ quy mô nào mà không lo lắng về việc bị chặn web.
Bắt đầu dùng thử miễn phí ngay bây giờ! Chỉ với 3 đô la cho 1.000 yêu cầu, đây là mức giá thấp nhất trên mạng!
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


