
7 phương pháp vượt qua CAPTCHA khi quét web
Web Data Collection Specialist
Bạn đang cố gắng thu thập một trang web nhưng CAPTCHA đang chặn bạn? Bất kỳ nỗ lực quét web nào cũng có thể bị cản trở bởi CAPTCHA, điều này ngày càng khó giải quyết hơn.
Rất may, có một số phương pháp để vượt qua CAPTCHA khi quét web và chúng ta sẽ xem xét 7 phương pháp đã được thử nghiệm trong bài viết này.
CAPTCHA: Nó là gì?
CAPTCHA là viết tắt của "Thử nghiệm Turing công khai hoàn toàn tự động để phân biệt máy tính và con người". Để bảo vệ các trang web khỏi những thiệt hại có thể xảy ra và các hành vi giống như bot như quét, nó cố gắng chặn các chương trình tự động truy cập chúng. Trước khi truy cập một trang web được bảo mật, người dùng thường phải hoàn thành bài kiểm tra được gọi là CAPTCHA.
Những người quét web gặp khó khăn khi vượt qua CAPTCHA vì chúng khó hiểu đối với robot nhưng con người lại dễ dàng vượt qua. Ví dụ: người dùng cần xác minh danh tính con người của mình bằng cách chọn hộp trong hình ảnh bên dưới. Lệnh này không thể được bot tuân theo bằng trực giác.
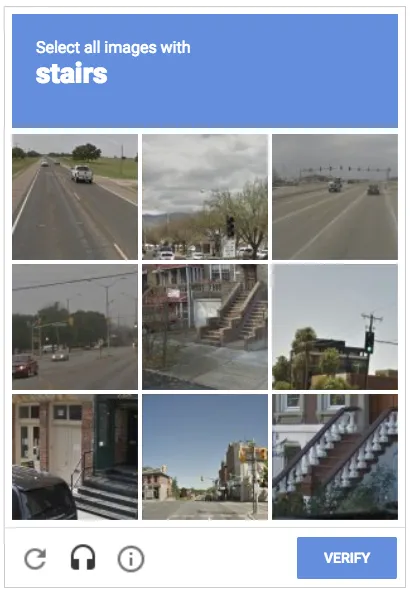
Làm thế nào việc quét web bị CAPTCHA chặn?
Việc triển khai một trang web sẽ xác định các hình dạng khác nhau của CAPTCHA. Một số luôn ở đó khi bạn truy cập một trang web, nhưng hầu hết là kết quả của các hành động tự động như quét web.
CAPTCHA có thể xuất hiện trong quá trình quét web vì bất kỳ lý do nào sau đây:
- Gửi một số truy vấn trong một khoảng thời gian ngắn từ cùng một IP
- Các hành động tự động được lặp lại, chẳng hạn như nhấp vào cùng một liên kết hoặc truy cập cùng một trang
- Các tương tác tự động đáng ngờ, bao gồm lướt nhanh nhiều trang mà không tương tác, nhấp nhanh hoặc hoàn thành biểu mẫu nhanh chóng
- Sử dụng các trang web bị cấm và bỏ qua tệp robots.txt.
Có thể vượt qua CAPTCHA không?
Mặc dù đây không phải là thao tác đơn giản nhưng bạn cũng có thể bỏ qua CAPTCHA. Bạn nên thử gửi lại yêu cầu nếu CAPTCHA bị chặn và tránh để nó xuất hiện ngay từ đầu.
Bạn cũng có thể trả lời CAPTCHA, nhưng làm như vậy sẽ khiến bạn tốn nhiều tiền hơn và tỷ lệ thành công thấp hơn nhiều. Hầu hết các dịch vụ giải CAPTCHA đều sử dụng bộ giải của con người để xử lý các truy vấn và sau đó đưa ra câu trả lời. Phương pháp này làm giảm đáng kể hiệu quả của máy cạo và làm chậm máy.
Việc bỏ qua CAPTCHA đáng tin cậy hơn vì cần có tất cả các biện pháp phòng ngừa cần thiết để ngăn chặn các hành vi tự động gây ra chúng. Chúng tôi sẽ giới thiệu các cách tốt nhất để vượt qua CAPTCHA khi tìm kiếm trên web bên dưới để bạn có thể truy xuất thông tin mình cần.
Cách vượt qua CAPTCHA khi quét web
Phần này sẽ hướng dẫn bảy phương pháp để vượt qua các rào cản CAPTCHA khó chịu khi quét web bằng Python.
Phương pháp 1. Xoay IP
Kỹ thuật đơn giản nhất để hệ thống phòng thủ ngăn chặn quyền truy cập khi phát triển trình thu thập thông tin cho URL và trích xuất dữ liệu là cấm IP. Nếu máy chủ nhận được nhiều yêu cầu từ cùng một địa chỉ IP trong một khoảng thời gian ngắn, họ sẽ gắn cờ địa chỉ đó.
Để tránh điều đó, sử dụng nhiều địa chỉ IP là giải pháp đơn giản nhất. Tuy nhiên, rất khó, nếu không nói là không thể, sửa đổi điều đó khi nói đến máy chủ. Do đó, bạn sẽ phải sử dụng máy chủ proxy để xử lý các yêu cầu của mình nhằm chuyển đổi IP. Với họ, các yêu cầu ban đầu của bạn sẽ không bị thay đổi nhưng máy chủ đích sẽ thấy địa chỉ IP của họ chứ không phải của bạn.
Phương pháp 2. Xoay tác nhân người dùng
Một chuỗi mà trình duyệt web của người dùng gửi đến máy chủ được gọi là Tác nhân người dùng (UA). Nó được tìm thấy trong tiêu đề HTTP và cung cấp thông tin về hệ điều hành cũng như loại và phiên bản của trình duyệt. được truy cập bằng trình điều hướng ở phía máy khách và JavaScript. Nội dung được máy chủ web từ xa xác định và hiển thị theo cách tuân thủ các thông số kỹ thuật của người dùng bằng cách sử dụng thuộc tính userAgent.
Mặc dù chúng bao gồm nhiều cấu trúc và dữ liệu khác nhau, phần lớn các trình duyệt web thường tuân theo cùng một định dạng:
(<system-information>) Mozilla/5.0 <extensions> <platform> (<platform-details>)
Ví dụ: đối với Chrome (Chromium), chuỗi tác nhân người dùng có thể là Mozilla/5.0 (Windows NT 10.0; Win64; x64). AppleWebKit/537.36 (tương tự Gecko trong KHTML) 109.0.0.0 Safari/537.36; Chrome. Phân tích nó, nó cho biết trình duyệt tên là gì (Chrome), nó đang chạy trên phiên bản nào (109.0.0.0) và nó đang chạy trên hệ điều hành nào (Windows NT 10.0, CPU 64-bit).
Việc sử dụng chuỗi UA để quét có thể giúp ngụy trang trình thu thập thông tin của bạn thành trình duyệt web vì chúng hỗ trợ máy chủ web xác định loại yêu cầu từ trình duyệt (và bot).
Hãy thận trọng: nếu bạn sử dụng tác nhân người dùng được cấu hình không chính xác, tập lệnh trích xuất dữ liệu của bạn sẽ bị dừng.
Phương pháp 3. Sử dụng Bộ giải CAPTCHA
Các dịch vụ được gọi là trình giải CAPTCHA cho phép bạn liên tục tìm kiếm các trang web bằng cách tự động giải CAPTCHA. Một ví dụ nổi tiếng là Scrapeless.
Bạn có mệt mỏi với CAPTCHA và các khối quét web liên tục không?
Không cần cạo: giải pháp cạo trực tuyến tất cả trong một tốt nhất hiện có!
Sử dụng bộ công cụ đáng gờm của chúng tôi để phát huy toàn bộ tiềm năng khai thác dữ liệu của bạn:
Trình giải CAPTCHA tốt nhất
Tự động phân giải các CAPTCHA phức tạp để đảm bảo quá trình trích xuất diễn ra suôn sẻ và liên tục.
Dùng thử miễn phí!
Phương pháp 4. Tránh bẫy ẩn
Bạn không hề biết rằng các trang web sử dụng những cái bẫy xảo quyệt để xác định bot. Ví dụ: bẫy honeypot đánh lừa máy móc tương tác với các tính năng bị ẩn, chẳng hạn như liên kết hoặc trường biểu mẫu vô hình.
Người dùng không thể nhìn thấy những cái bẫy này; chỉ có bot mới có thể nhìn thấy chúng. Khi người dùng tương tác với những cái bẫy này, trang web có thể xác định hoạt động bất thường và cảnh báo địa chỉ IP của bot.
Tuy nhiên, bạn có thể học cách nhận biết và vận hành những cái bẫy này. Một phương pháp là tìm kiếm các phần tử ẩn trong HTML của trang web và tránh xa các phần tử có tên hoặc giá trị kỳ lạ.
Phương pháp5. Mô phỏng hành vi của con người
Việc sao chép chính xác hành vi của con người là cần thiết để vượt qua CAPTCHA khi quét web. Ví dụ: việc gửi một số yêu cầu trong vài mili giây có thể dẫn đến hạn chế IP với giới hạn tốc độ.
Thêm thời gian giữa các yêu cầu để giảm tần suất truy vấn của bạn là một phương pháp bắt chước hành vi của con người. Để làm cho nó hợp lý hơn, bạn có thể thay đổi thời gian. Sử dụng thời gian chờ theo cấp số nhân là một chiến lược bổ sung để kéo dài thời gian chờ đợi sau mỗi yêu cầu không thành công.
Phương pháp6. Lưu Cookie
Lựa chọn vũ khí ẩn của bạn để quét web có thể là cookie. Những tệp nhỏ này chứa thông tin về cách bạn tương tác với một trang web, chẳng hạn như tùy chọn và trạng thái đăng nhập của bạn.
Cookie có thể hữu ích nếu bạn đang cố gắng đăng nhập vì chúng giúp bạn tránh khỏi rắc rối khi đăng nhập nhiều lần và giảm khả năng bạn bị phát hiện. Ngoài ra, cookie cho phép bạn tạm dừng hoặc tiếp tục phiên quét web sau đó.
Bằng cách sử dụng các trình duyệt không có giao diện người dùng như Selenium và ứng dụng khách HTTP như Yêu cầu, bạn có thể lưu và tải cookie cũng như truy xuất dữ liệu theo chương trình mà không bị chú ý.
Phương pháp 7. Ẩn chỉ báo tự động hóa
Ngay cả khi sử dụng trình duyệt không có giao diện người dùng, bạn cũng nên thận trọng vì các trang web có thể phát hiện lưu lượng truy cập tự động bằng cách quét để tìm các dấu hiệu tự động hóa, chẳng hạn như dấu vân tay của trình duyệt.
Mặt khác, các plugin như Selenium Stealth có thể được sử dụng để tự động hóa các chuyển động của chuột và bàn phím giống với chuyển động của một người mà không thu hút sự chú ý về phía bạn.
##Tóm lại
Mặc dù việc ngăn chặn CAPTCHA cản trở việc quét web là một nhiệm vụ khó khăn nhưng giờ đây bạn đã sở hữu những công cụ cần thiết để giải quyết vấn đề này. Tuy nhiên, các sáng kiến quy mô lớn có thể cần nhiều thời gian và công sức hơn để thực hiện đầy đủ các chiến lược nói trên.
Với Scrapeless, bạn có thể có được tất cả các công cụ cần thiết để xử lý CAPTCHA và các chương trình chống bot khác một cách hiệu quả.
Hãy tự mình khám phá bằng cách sử dụng Scrapeless miễn phí!
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


