
Cách thu thập dữ liệu tự động trên Make?
Senior Web Scraping Engineer
Chúng tôi vừa ra mắt một tích hợp chính thức trên Make, hiện có sẵn như một ứng dụng công khai. Hướng dẫn này sẽ cho bạn biết cách tạo một quy trình làm việc tự động mạnh mẽ kết hợp API Tìm kiếm Google của chúng tôi với Web Unlocker để trích xuất dữ liệu từ các kết quả tìm kiếm, xử lý nó bằng Claude AI và gửi đến một webhook.
Chúng Ta Sẽ Xây Dựng Gì
Trong hướng dẫn này, chúng ta sẽ tạo một quy trình làm việc với:
- Tự động kích hoạt mỗi ngày bằng cách sử dụng lập lịch tích hợp
- Tìm kiếm Google cho các truy vấn cụ thể bằng cách sử dụng API Tìm Kiếm Google của Scrapeless
- Xử lý từng URL một cách riêng lẻ với Iterator
- Trích xuất nội dung từ mỗi URL với Scrapeless WebUnlocker
- Phân tích nội dung với Anthropic Claude AI
- Gửi dữ liệu đã xử lý đến một webhook (Discord, Slack, cơ sở dữ liệu, v.v.)
Điều Kiện Đầu Vào
- Tài khoản Make.com
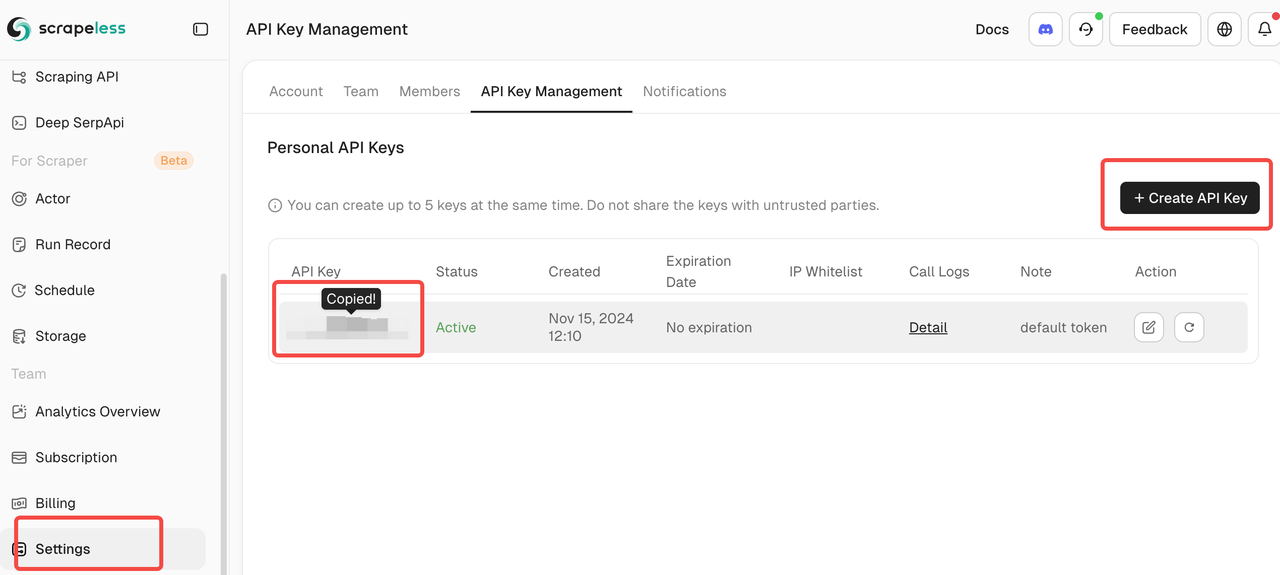
- Một khóa API Scrapeless (nhận một cái tại scrapeless.com)
- Một khóa API Anthropic Claude
- Một điểm cuối webhook (webhook Discord, Zapier, điểm cuối cơ sở dữ liệu, v.v.)
- Hiểu biết cơ bản về quy trình làm việc của Make.com
Tổng Quan Quy Trình Làm Việc Hoàn Chỉnh
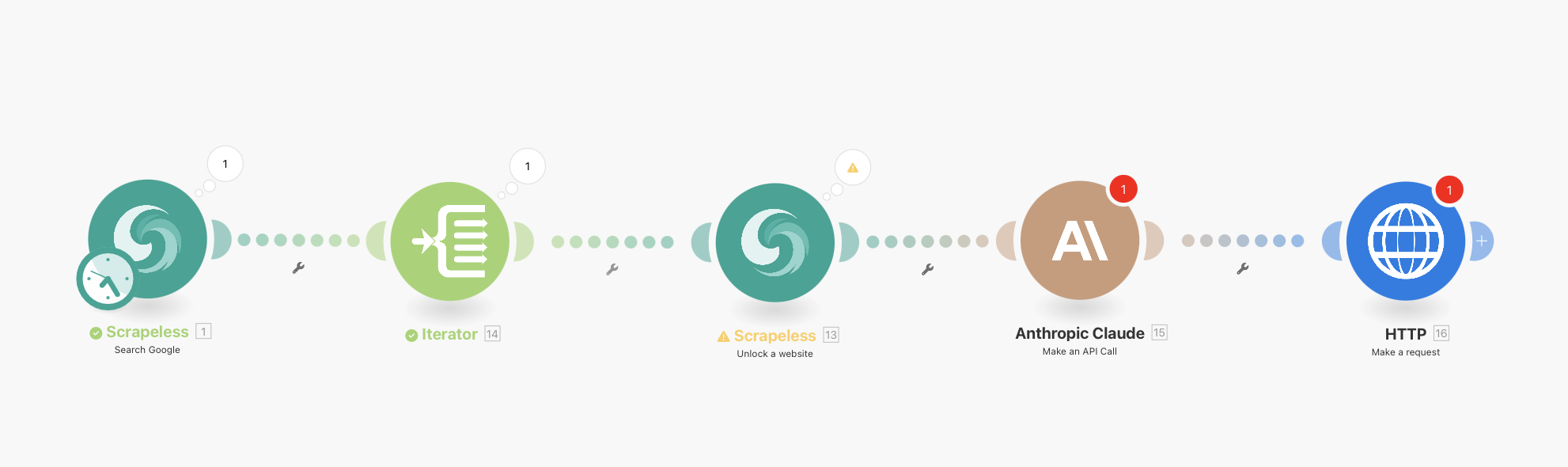
Quy trình làm việc cuối cùng của bạn sẽ trông như thế này:
Tìm Kiếm Google Scrapeless (với lập lịch tích hợp) → Iterator → WebUnlocker Scrapeless → Anthropic Claude → HTTP Webhook
Bước 1: Thêm Tìm Kiếm Google Scrapeless với Lập Lịch Tích Hợp
Chúng ta sẽ bắt đầu bằng cách thêm mô-đun Tìm Kiếm Google Scrapeless với lập lịch tích hợp sẵn.
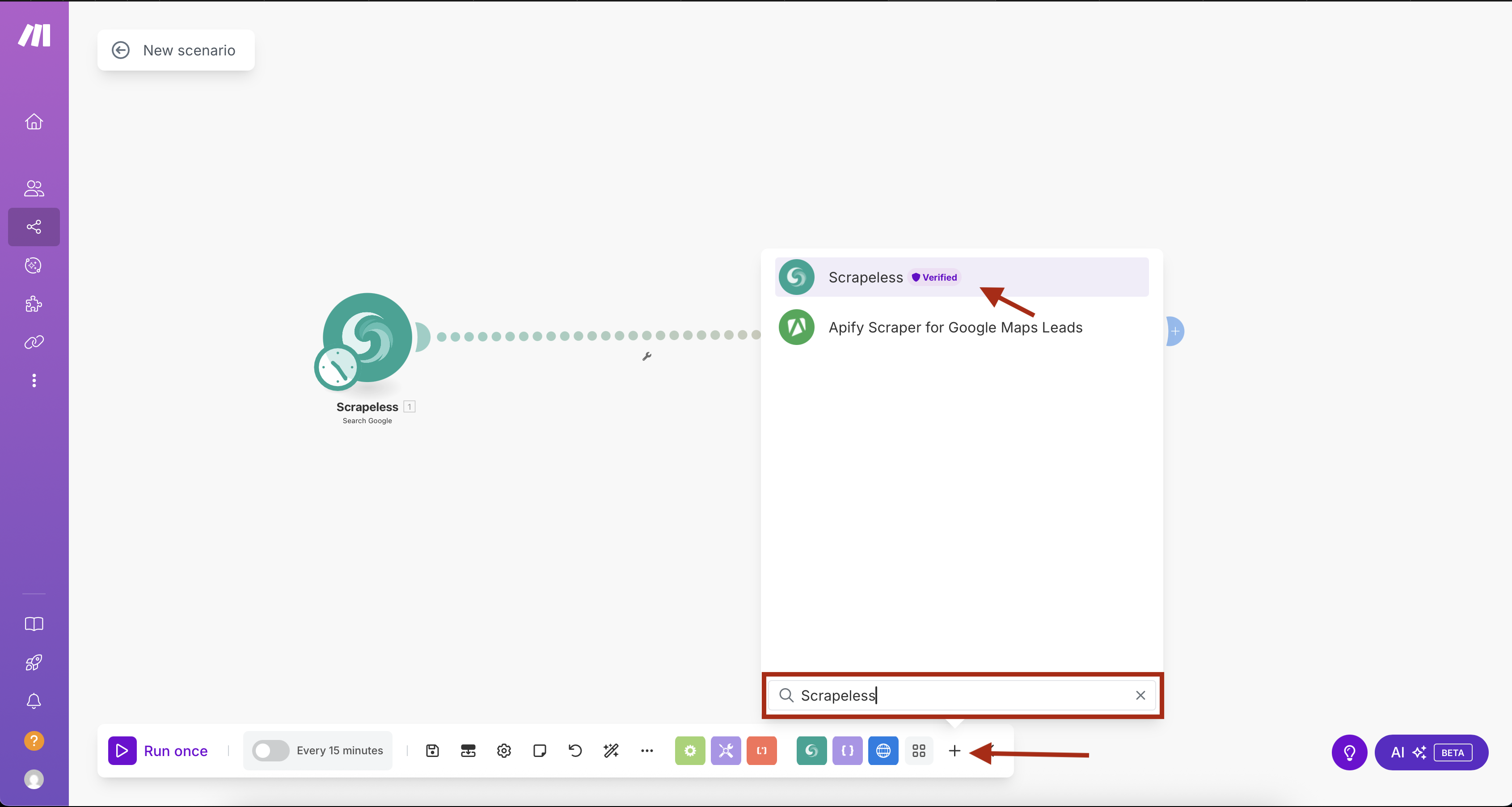
- Tạo một kịch bản mới trong Make.com
- Nhấp vào nút "+" để thêm mô-đun đầu tiên
- Tìm kiếm "Scrapeless" trong thư viện mô-đun
- Chọn Scrapeless và chọn hành động Search Google
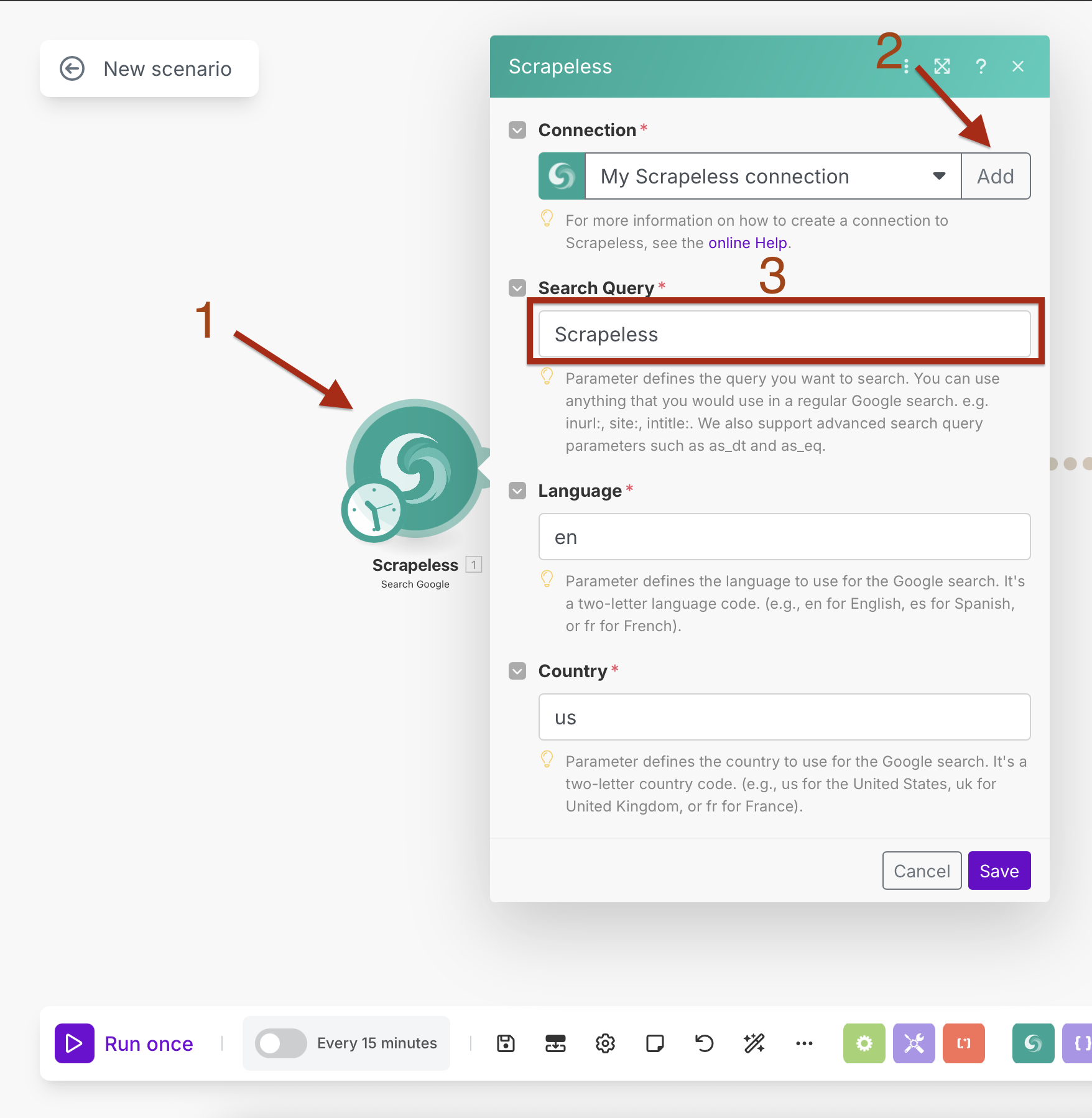
Cấu Hình Tìm Kiếm Google với Lập Lịch
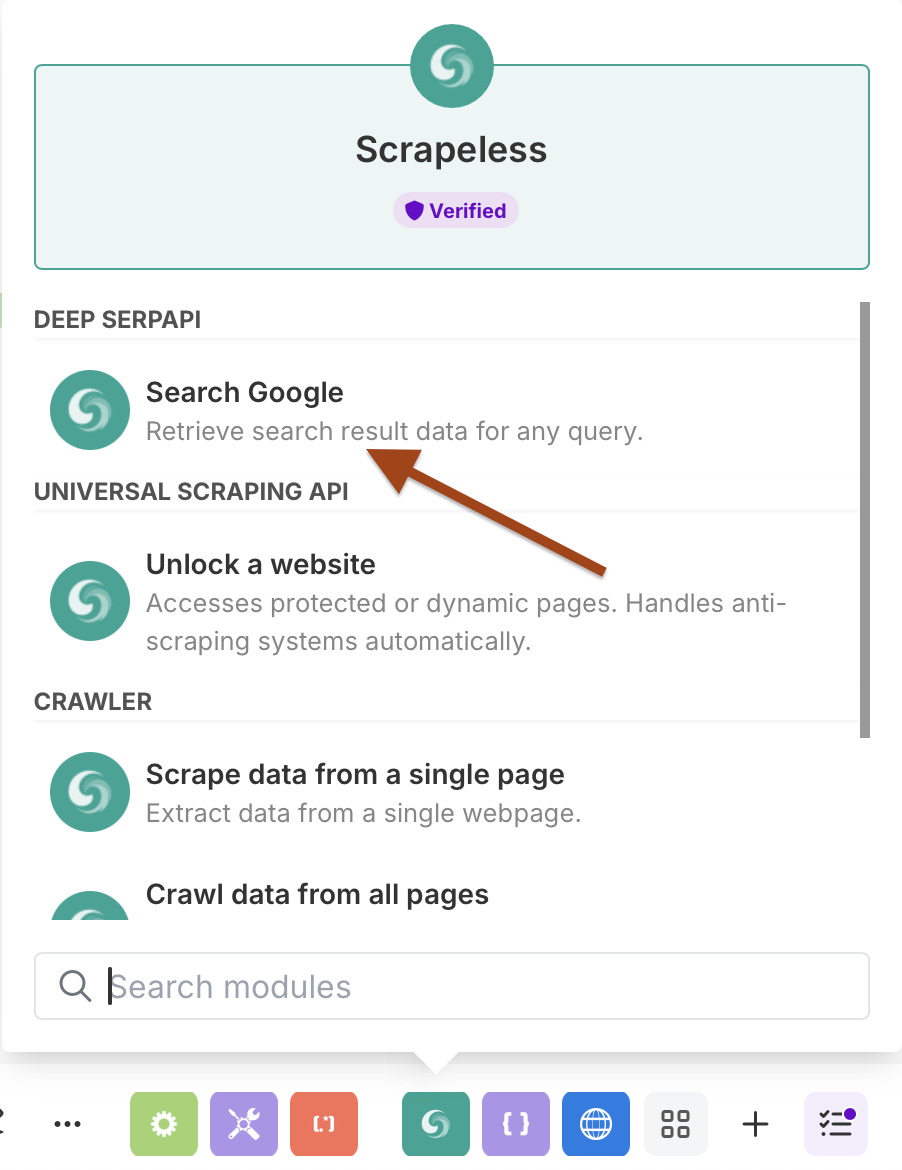
Cài Đặt Kết Nối:
- Tạo một kết nối bằng cách nhập khóa API Scrapeless của bạn
- Nhấp vào "Thêm" và làm theo quy trình cài đặt kết nối
Thông Số Tìm Kiếm:
- Tìm Kiếm Truy Vấn: Nhập truy vấn mục tiêu của bạn (ví dụ: "tin tức trí tuệ nhân tạo")
- Ngôn Ngữ:
en(Tiếng Anh) - Quốc Gia:
US(Hoa Kỳ)
Cài Đặt Lập Lịch:
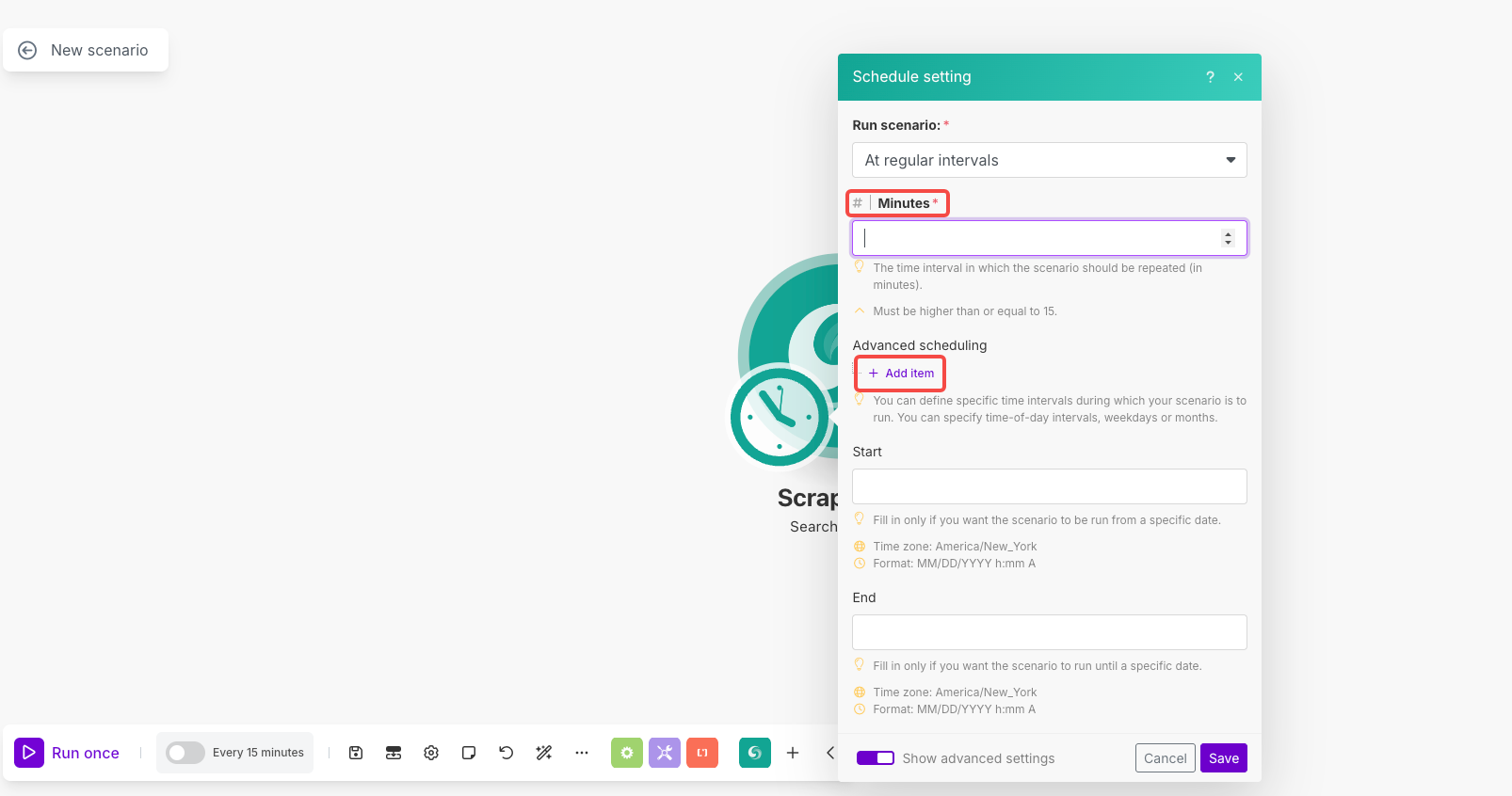
- Nhấp vào biểu tượng đồng hồ trên mô-đun để mở lập lịch
- Chạy kịch bản: Chọn "Theo khoảng thời gian đều đặn"
- Phút: Đặt thành
1440(cho việc thực hiện hàng ngày) hoặc khoảng thời gian bạn thích - Lập lịch nâng cao: Sử dụng "Thêm mục" để đặt thời gian/ngày cụ thể nếu cần
Bước 2: Xử Lý Kết Quả với Iterator
Tìm kiếm trên Google trả về nhiều URL trong một mảng. Chúng ta sẽ sử dụng Iterator để xử lý từng kết quả một cách riêng lẻ.
- Thêm một mô-đun Iterator sau Tìm Kiếm Google
- Cấu hình trường Mảng để xử lý các kết quả tìm kiếm
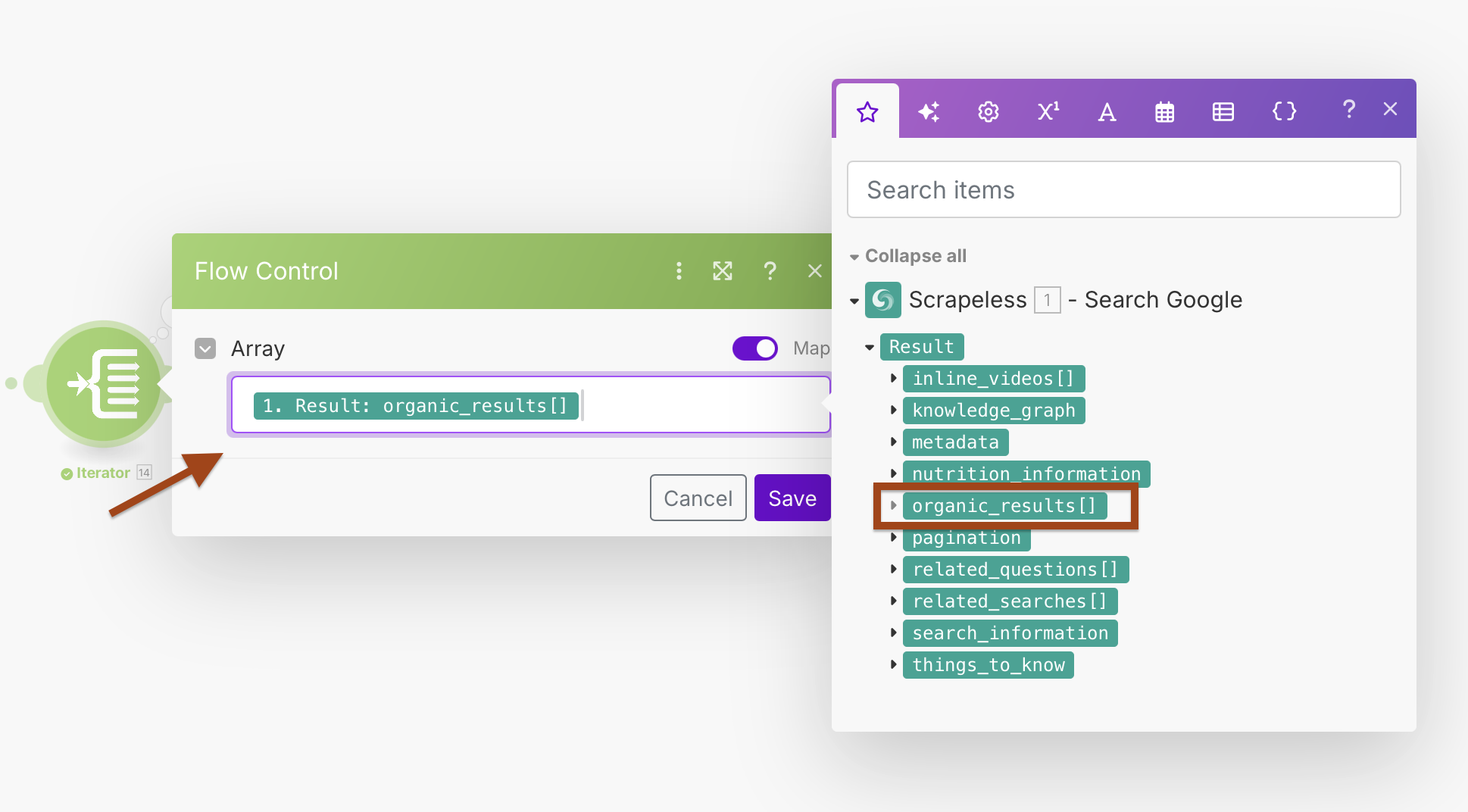
Cấu Hình Iterator:
- Mảng:
{{1.result.organic_results}}
Điều này sẽ tạo ra một vòng lặp xử lý từng kết quả tìm kiếm một cách riêng biệt, cho phép xử lý lỗi tốt hơn và xử lý riêng lẻ.
Bước 3: Thêm WebUnlocker Scrapeless
Bây giờ chúng ta sẽ thêm mô-đun WebUnlocker để trích xuất nội dung từ mỗi URL.
- Thêm một mô-đun Scrapeless khác
- Chọn hành động Scrape URL (WebUnlocker)
- Sử dụng cùng một kết nối Scrapeless
Cấu Hình WebUnlocker:
- Kết nối: Sử dụng kết nối Scrapeless hiện có của bạn
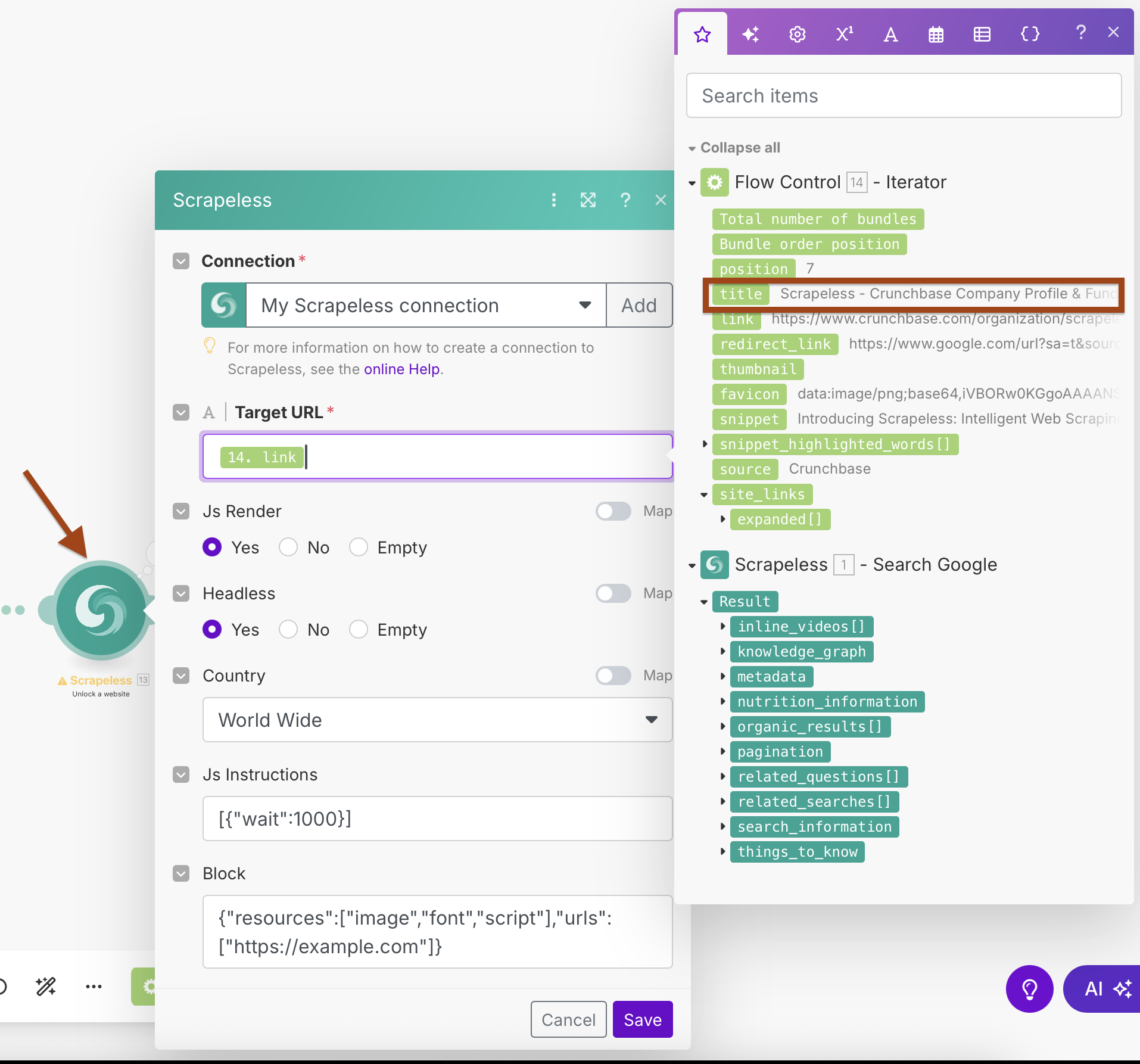
- Địa Chỉ URL Mục Tiêu:
{{2.link}}(được ánh xạ từ đầu ra của Iterator) - Js Render: Có
- Headless: Có
- Quốc Gia: Toàn Cầu
- Hướng Dẫn Js:
[{"wait":1000}](chờ tải trang) - Chặn: Cấu hình để chặn các tài nguyên không cần thiết để tăng tốc độ trích xuất
Bước 4: Xử Lý AI với Anthropic Claude
Thêm Claude AI để phân tích và tóm tắt nội dung đã trích xuất.
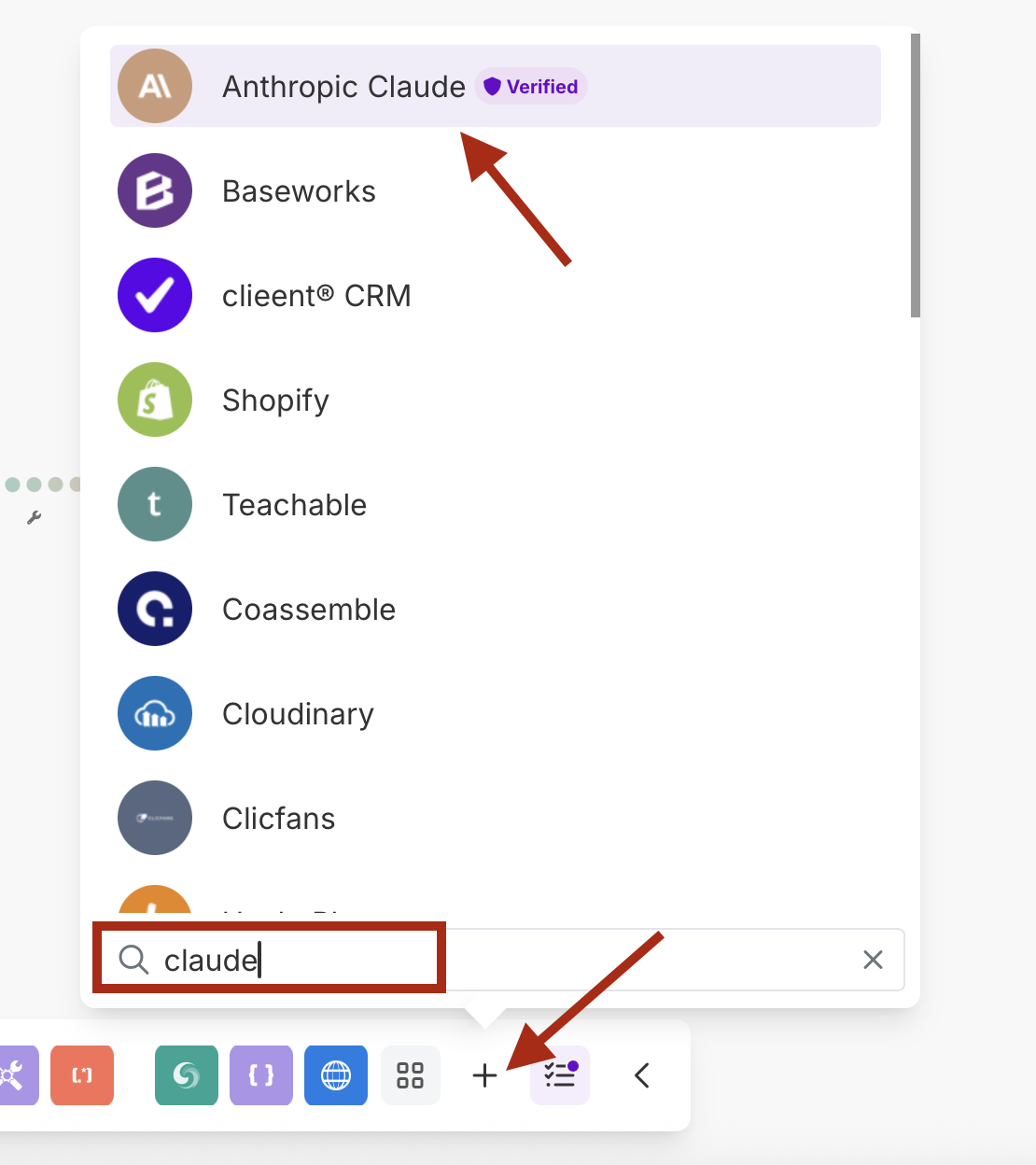
- Thêm một mô-đun Anthropic Claude
- Chọn hành động Make an API Call
- Tạo một kết nối mới với khóa API Claude của bạn
Cấu Hình Claude:
- Kết nối: Tạo kết nối với khóa API Anthropic của bạn
- Lời nhắc: Cấu hình để phân tích nội dung đã được lấy
- Mô hình: claude-3-sonnet-20240229 / claude-3-opus-20240229 hoặc mô hình bạn ưa thích
- Tối đa Từ: 1000-4000 tùy theo nhu cầu của bạn
URL
/v1/messagesTiêu đề 1
Khóa : Content-TypeGiá trị : application/json
Tiêu đề 2
Khóa : anthropic-versionGiá trị : 2023-06-01
Ví dụ Lời nhắc sao chép dán vào nội dung:
{
"model": "claude-3-sonnet-20240229",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": "Phân tích nội dung web này và cung cấp một bản tóm tắt bằng tiếng Anh với các điểm chính:\n\nTiêu đề: {{14.title}}\nURL: {{14.link}}\nMô tả: {{14.snippet}}\nNội dung: {{13.content}}\n\nTruy vấn Tìm kiếm: {{1.result.search_information.query_displayed}}"
}
]
}- Đừng quên thay đổi số
14bằng số mô-đun của bạn.
Bước 5: Tích hợp Webhook
Cuối cùng, gửi dữ liệu đã xử lý đến điểm cuối webhook của bạn.
- Thêm một mô-đun HTTP
- Cấu hình nó để gửi một yêu cầu POST đến webhook của bạn
Cấu hình HTTP:
- URL: Điểm cuối webhook của bạn (Discord, Slack, cơ sở dữ liệu, v.v.)
- Phương thức: POST
- Tiêu đề:
Content-Type: application/json - Loại Nội dung: Thô (JSON)
Ví dụ Payload Webhook:
{
"embeds": [
{
"title": "{{14.title}}",
"description": "*{{15.body.content[0].text}}*",
"url": "{{14.link}}",
"color": 3447003,
"footer": {
"text": "Phân tích hoàn tất"
}
}
]
}Kết quả Chạy
Tham khảo Mô-đun và Luồng Dữ liệu
Luồng Dữ liệu Qua Các Mô-đun:
- Mô-đun 1 (Tìm kiếm Google không có Scrapeless): Trả về
result.organic_results[] - Mô-đun 14 (Bộ lặp): Xử lý từng kết quả, xuất các mục riêng lẻ
- Mô-đun 13 (WebUnlocker): Lấy dữ liệu
{{14.link}}, trả về nội dung - Mô-đun 15 (Claude AI): Phân tích
{{13.content}}, trả về tóm tắt - Mô-đun 16 (Webhook HTTP): Gửi dữ liệu đã định hình cuối cùng
Bản đồ Quan trọng:
- Mảng Bộ lặp:
{{1.result.organic_results}} - URL WebUnlocker:
{{14.link}} - Nội dung Claude:
{{13.content}} - Dữ liệu Webhook: Kết hợp của tất cả các mô-đun trước đó
Kiểm tra Quy trình của Bạn
- Chạy một lần để kiểm tra toàn bộ kịch bản
- Kiểm tra từng mô-đun:
- Tìm kiếm Google trả về kết quả hữu cơ
- Bộ lặp xử lý từng kết quả một cách riêng lẻ
- WebUnlocker lấy nội dung thành công
- Claude cung cấp phân tích có ý nghĩa
- Webhook nhận dữ liệu có cấu trúc
- Xác minh chất lượng dữ liệu ở đích đến webhook của bạn
- Kiểm tra lịch trình - đảm bảo nó chạy theo khoảng thời gian bạn ưa thích
Mẹo Cấu hình Nâng cao
Xử lý Lỗi
- Thêm các tuyến Xử lý Lỗi sau mỗi mô-đun
- Sử dụng Bộ lọc để bỏ qua các URL không hợp lệ hoặc nội dung trống
- Đặt logic Thử lại cho các lỗi tạm thời
Lợi ích của Quy trình này
- Tự động hoàn toàn: Chạy hàng ngày mà không cần can thiệp thủ công
- Tăng cường AI: Nội dung được phân tích và tóm tắt tự động
- Đầu ra Linh hoạt: Webhook có thể tích hợp với bất kỳ hệ thống nào
- Có thể mở rộng: Xử lý nhiều URL một cách hiệu quả
- Kiểm soát Chất lượng: Nhiều bước lọc và xác minh
- Thông báo Thời gian thực: Gửi ngay đến nền tảng bạn ưa thích
Trường hợp Sử dụng
Hoàn hảo cho:
- Giám sát Nội dung: Theo dõi đề cập đến thương hiệu hoặc đối thủ cạnh tranh của bạn
- Tổng hợp Tin tức: Tóm tắt tin tức tự động về các chủ đề cụ thể
- Nghiên cứu Thị trường: Theo dõi xu hướng và phát triển trong ngành
- Tìm kiếm Khách hàng Tiềm năng: Tìm và phân tích cơ hội kinh doanh tiềm năng
- Giám sát SEO: Theo dõi thay đổi kết quả tìm kiếm cho từ khóa mục tiêu
- Tự động hóa Nghiên cứu: Thu thập và tóm tắt nội dung học thuật hoặc công nghiệp
Kết luận
Quy trình làm việc tự động này kết hợp sức mạnh của Tìm kiếm Google của Scrapeless và WebUnlocker với khả năng phân tích của Claude AI, tất cả được tổ chức qua giao diện hình ảnh của Make. Kết quả là một hệ thống phát hiện nội dung thông minh tự động chạy và cung cấp dữ liệu được phân tích, làm giàu trực tiếp đến nền tảng bạn ưa thích qua webhook.
Quy trình làm việc sẽ chạy theo lịch trình của bạn, tự động khám phá, lấy dữ liệu, phân tích và cung cấp các thông tin nội dung liên quan mà không cần sự can thiệp thủ công.
Đã đến lúc xây dựng Ajent AI đầu tiên của bạn trên Make sử dụng Scrapeless!
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


