
Cách Scrape Kết Quả Tìm Kiếm Google Bằng Python - Công Cụ Scrape Google Tốt Nhất?
Specialist in Anti-Bot Strategies
Google SERP là gì?
Bất cứ khi nào thảo luận về việc trích xuất dữ liệu web từ kết quả tìm kiếm của Google, bạn rất có thể sẽ bắt gặp từ viết tắt "SERP". SERP là viết tắt của Search Engine Results Page (Trang Kết Quả Tìm Kiếm). Đó là trang bạn nhận được sau khi nhập truy vấn vào thanh tìm kiếm.
Trước đây, Google trả về một danh sách liên kết cho truy vấn của bạn. Ngày nay, nó trông hoàn toàn khác - SERP bao gồm nhiều tính năng và yếu tố giúp trải nghiệm tìm kiếm của bạn nhanh chóng và thuận tiện.
Thông thường, trang bao gồm:
- Kết quả tìm kiếm tự nhiên
- Kết quả tìm kiếm trả phí
- Đoạn trích nổi bật
- Đồ thị kiến thức
- Các yếu tố khác: Chẳng hạn như bản đồ, hình ảnh hoặc tin tức xuất hiện dựa trên truy vấn.
Có hợp pháp khi trích xuất dữ liệu từ kết quả tìm kiếm của Google không?
Trước khi trích xuất dữ liệu từ kết quả tìm kiếm của Google, điều cần thiết là phải hiểu các hệ quả pháp lý. Điều khoản dịch vụ của Google cấm việc trích xuất dữ liệu từ kết quả tìm kiếm của họ, như đã nêu trong chính sách của họ:
"Bạn không được phép trích xuất dữ liệu, thu thập dữ liệu hoặc sử dụng bất kỳ phương tiện tự động nào để truy cập Dịch vụ cho bất kỳ mục đích nào."
Vi phạm các điều khoản này có thể dẫn đến bị cấm IP hoặc thậm chí bị Google kiện. Tuy nhiên, tính hợp pháp của việc trích xuất dữ liệu phụ thuộc vào khu vực pháp lý, dữ liệu bạn đang trích xuất và cách bạn sử dụng nó.
Các giải pháp thay thế cho việc trích xuất dữ liệu Google:
- Google Custom Search API: Google cung cấp một API chính thức để truy xuất kết quả tìm kiếm, cung cấp một cách hợp pháp và có cấu trúc để truy cập dữ liệu mà không vi phạm chính sách của họ.
- Các API tìm kiếm khác: Nếu bạn không nhất thiết phải sử dụng Google, có các công cụ tìm kiếm và dịch vụ khác cung cấp API để truy cập kết quả tìm kiếm, chẳng hạn như Bing và Scrapeless.
4 khó khăn chính để trích xuất dữ liệu Google SERP
Việc trích xuất dữ liệu từ Google SERP đặt ra một số thách thức, đó là lý do tại sao nó được coi là khó khăn. Bao gồm:
- Phát hiện Bot: Google sử dụng một số kỹ thuật để phát hiện và chặn bot, bao gồm:
- CAPTCHA
- Chặn IP
- Giới hạn tốc độ
- Nội dung động: Kết quả tìm kiếm của Google thường được tạo động bằng JavaScript, điều này có thể làm phức tạp việc trích xuất dữ liệu. Nội dung có thể tải sau khi tải trang ban đầu, yêu cầu các công cụ như Selenium để hiển thị đầy đủ trang.
- Thay đổi cấu trúc HTML: Google thường xuyên thay đổi bố cục và cấu trúc kết quả tìm kiếm của mình, có nghĩa là người trích xuất dữ liệu cần nhanh chóng thích ứng để tránh làm hỏng mã.
- Dữ liệu phức tạp: SERP bao gồm nhiều yếu tố phức tạp như quảng cáo, hình ảnh, video và đoạn trích phong phú, làm cho việc trích xuất dữ liệu có ý nghĩa một cách nhất quán trở nên khó khăn.
Mặc dù có những thách thức này, việc trích xuất dữ liệu từ kết quả tìm kiếm của Google vẫn có thể thực hiện được với các kỹ thuật và công cụ phù hợp.
Hãy phân tích quy trình thành các bước sau để trích xuất dữ liệu kết quả tìm kiếm của Google bằng Python:
Làm thế nào để trích xuất dữ liệu kết quả tìm kiếm của Google bằng Python?
Bước 1: Gửi yêu cầu đến Google
Trước khi bạn bắt đầu trích xuất dữ liệu, bạn cần gửi yêu cầu đến trang tìm kiếm của Google. Vì Google chặn hầu hết các yêu cầu từ bot, nên điều cần thiết là phải mô phỏng người dùng thực bằng cách đặt tiêu đề User-Agent thích hợp.
Python
import requests
from fake_useragent import UserAgent
# Tạo một user-agent ngẫu nhiên
ua = UserAgent()
headers = {'User-Agent': ua.random}
# Truy vấn tìm kiếm Google
query = "How to scrape Google search results with Python"
url = f"https://www.google.com/search?q={query}"
# Gửi yêu cầu GET
response = requests.get(url, headers=headers)
# Kiểm tra xem yêu cầu có thành công không
if response.status_code == 200:
print(response.text)
else:
print("Không thể truy xuất trang")Bước 2: Phân tích nội dung HTML
Sau khi bạn có nội dung HTML của Google SERP, bạn có thể sử dụng BeautifulSoup để trích xuất dữ liệu bạn cần.
Python
from bs4 import BeautifulSoup
# Phân tích nội dung trang
soup = BeautifulSoup(response.text, 'html.parser')
# Tìm tất cả các vùng chứa kết quả tìm kiếm
search_results = soup.find_all('div', class_='BVG0Nb')
for result in search_results:
title = result.text
link = result.find('a')['href']
print(f"Tiêu đề: {title}")
print(f"Liên kết: {link}\n")Bước 3: Xử lý JavaScript (Sử dụng Selenium)
Selenium là một công cụ tuyệt vời để xử lý các trang dựa vào JavaScript để hiển thị nội dung. Nó tự động hóa trình duyệt và mô phỏng tương tác của người dùng, làm cho nó lý tưởng để trích xuất dữ liệu từ nội dung được tạo động.
Python
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# Thiết lập Selenium WebDriver
driver = webdriver.Chrome(ChromeDriverManager().install())
# Mở Google và thực hiện tìm kiếm
driver.get("https://www.google.com/")
search_box = driver.find_element(By.NAME, 'q')
search_box.send_keys("How to scrape Google search results with Python")
search_box.submit()
# Chờ kết quả tải và trích xuất các liên kết
driver.implicitly_wait(5)
# Lấy kết quả tìm kiếm
search_results = driver.find_elements(By.CLASS_NAME, 'BVG0Nb')
for result in search_results:
title = result.text
link = result.find_element(By.TAG_NAME, 'a').get_attribute('href')
print(f"Tiêu đề: {title}")
print(f"Liên kết: {link}\n")
driver.quit()Bước 4: Tránh bị phát hiện
Để giảm thiểu khả năng bị phát hiện và chặn bởi Google, bạn nên:
- Xoay vòng User Agents: Sử dụng các user agent khác nhau để mô phỏng yêu cầu từ nhiều trình duyệt khác nhau.
- Thêm độ trễ: Thêm độ trễ ngẫu nhiên giữa các yêu cầu để bắt chước hành vi duyệt web giống như con người.
- Sử dụng Proxy: Xoay vòng địa chỉ IP để phân phối các yêu cầu của bạn và tránh bị phát hiện.
- Tôn trọng Robots.txt: Luôn kiểm tra tệp robots.txt của Google và tuân theo các thực tiễn trích xuất dữ liệu có đạo đức.
API trích xuất dữ liệu Google Search tốt nhất - Scrapeless
Mặc dù việc trích xuất dữ liệu Google trực tiếp là có thể, nhưng nó có thể tốn thời gian và dễ xảy ra lỗi, và thường dẫn đến bị chặn. Đây là lúc Scrapeless xuất hiện. Với bộ giải CAPTCHA mạnh mẽ, xoay vòng IP, proxy thông minh và công cụ mở khóa web, Scrapeless là một API mạnh mẽ được thiết kế đặc biệt để giúp người dùng trích xuất dữ liệu kết quả tìm kiếm mà không bị chặn.
Tại sao nên chọn Scrapeless?
- Tính hợp pháp: Scrapeless cung cấp một cách hợp pháp và tuân thủ để truy cập kết quả tìm kiếm.
- Độ tin cậy: API sử dụng các kỹ thuật tinh vi để tránh bị phát hiện, đảm bảo thu thập dữ liệu không bị gián đoạn.
- Dễ sử dụng: Scrapeless cung cấp một API đơn giản dễ dàng tích hợp với Python, làm cho nó lý tưởng cho các nhà phát triển cần truy cập nhanh vào dữ liệu kết quả tìm kiếm.
- Có thể tùy chỉnh: Bạn có thể điều chỉnh kết quả theo nhu cầu của mình, chẳng hạn như chỉ định loại nội dung (ví dụ: danh sách tự nhiên, quảng cáo, v.v.).
API trích xuất dữ liệu tìm kiếm Google của Scrapeless - sử dụng các bước:
Để làm cho dữ liệu được nhắm mục tiêu và cụ thể, chúng tôi thu thập xu hướng tìm kiếm của Google trong bài viết này làm ví dụ.
Mệt mỏi vì bị chặn web và trích xuất dữ liệu tìm kiếm của Google?
Tham gia Cộng đồng của chúng tôi và nhận được giải pháp hiệu quả với Phiên bản dùng thử miễn phí!
Bước 1. Đăng nhập vào Bảng điều khiển Scrapeless và đi đến "Google Search API".
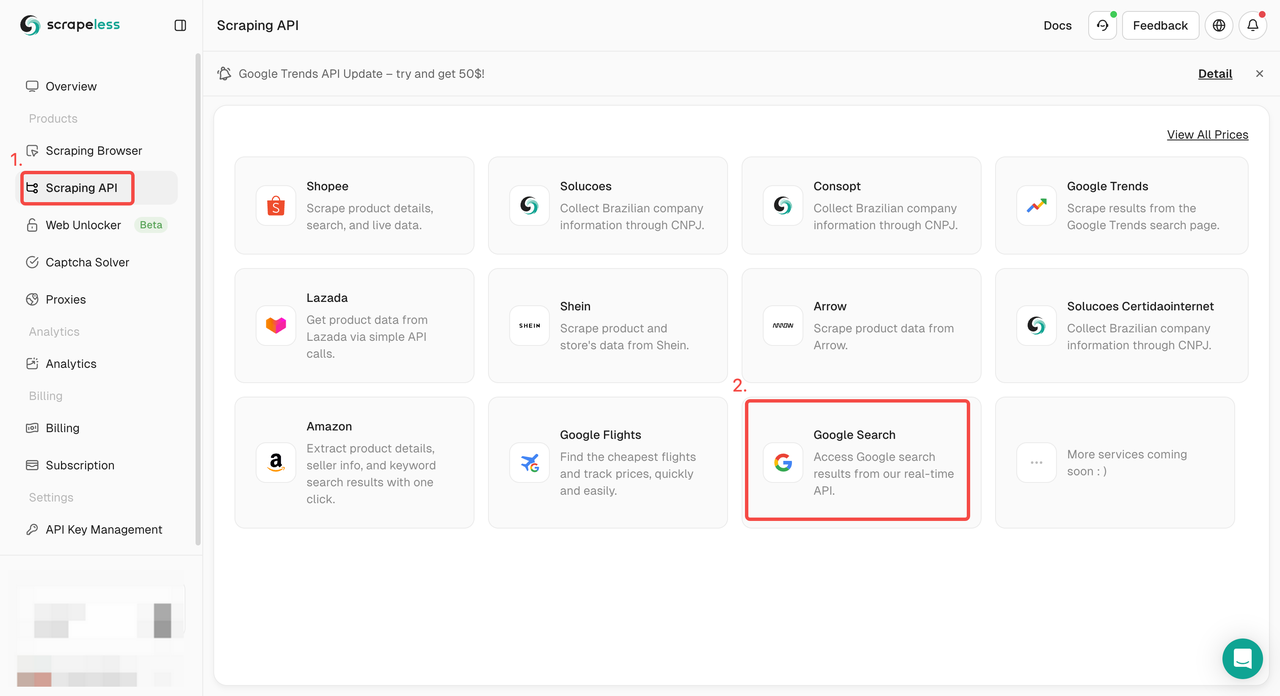
Bước 2. Cấu hình từ khóa, khu vực, ngôn ngữ, proxy và các thông tin khác bạn cần ở bên trái. Sau khi đảm bảo mọi thứ đều ổn, hãy nhấp vào "Bắt đầu trích xuất dữ liệu".
q: Tham số xác định truy vấn bạn muốn tìm kiếm.gl: Tham số xác định quốc gia sử dụng cho tìm kiếm Google.hl: Tham số xác định ngôn ngữ sử dụng cho tìm kiếm Google.
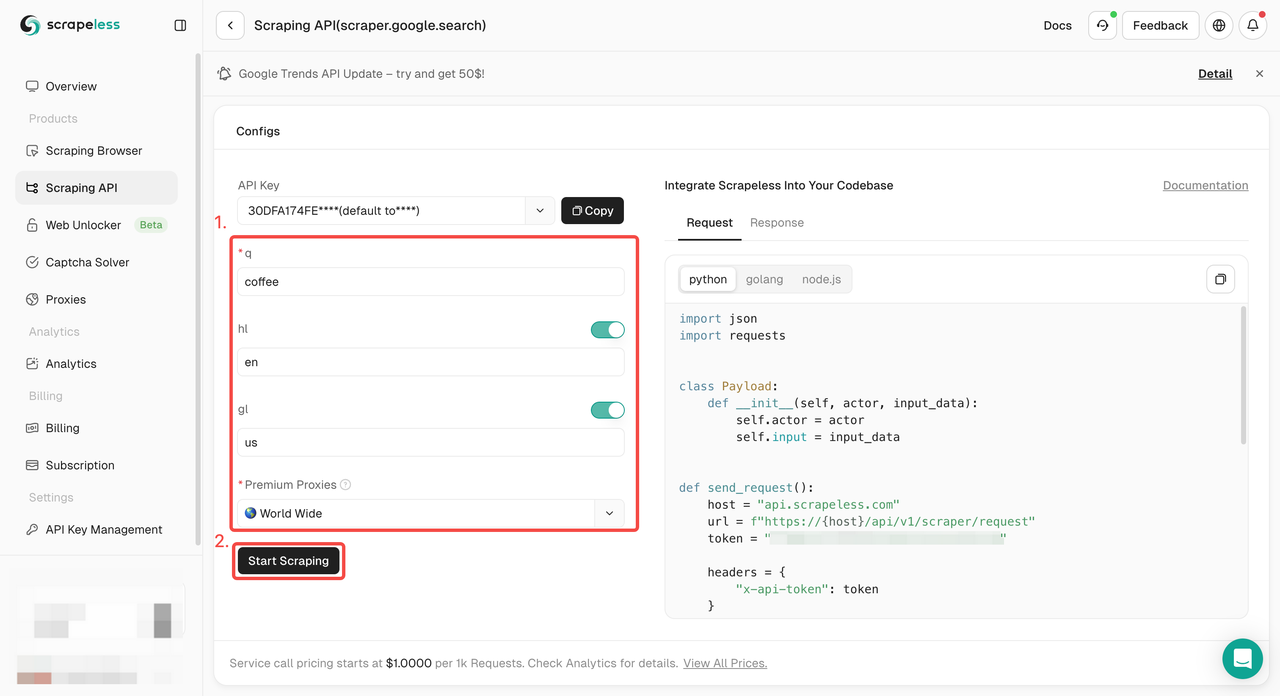
Bước 3. Nhận kết quả thu thập dữ liệu và xuất chúng.
Chỉ cần mã mẫu để tích hợp vào dự án của bạn? Chúng tôi đã hỗ trợ bạn! Hoặc bạn có thể truy cập tài liệu API của chúng tôi cho bất kỳ ngôn ngữ nào bạn cần.
- Python:
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}Lời kết
Việc trích xuất dữ liệu từ kết quả tìm kiếm của Google có thể khó khăn, nhưng với các công cụ và kỹ thuật phù hợp, nó chắc chắn có thể đạt được! Chỉ cần nhớ: không phải tất cả là về việc viết mã — đó là về việc biết cách tránh bị phát hiện, tôn trọng các ranh giới pháp lý và tìm các giải pháp thay thế khi cần thiết.
API trích xuất dữ liệu Scrapeless có thể chỉ là người bạn tốt nhất của bạn trong thế giới trích xuất dữ liệu kết quả tìm kiếm của Google!
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


