
Trình thu thập dữ liệu web bằng Golang: Hướng dẫn từng bước năm 2025
Senior Web Scraping Engineer
Hầu hết các dự án thu thập dữ liệu web lớn bằng Go đều bắt đầu bằng việc khám phá và sắp xếp URL bằng một trình thu thập dữ liệu web Golang. Công cụ này cho phép bạn điều hướng một miền đích ban đầu (còn được gọi là "URL hạt giống") và truy cập đệ quy các liên kết trên trang để khám phá thêm các liên kết.
Hướng dẫn này sẽ hướng dẫn bạn cách xây dựng và tối ưu hóa một trình thu thập dữ liệu web Golang bằng các ví dụ thực tế. Và, trước khi chúng ta đi sâu vào, bạn cũng sẽ nhận được một số thông tin bổ sung hữu ích.
Không cần nói thêm nữa, hãy xem những điều thú vị mà chúng ta có cho bạn hôm nay!
Thu thập dữ liệu web là gì?
Thu thập dữ liệu web, về cốt lõi của nó, liên quan đến việc điều hướng có hệ thống các trang web để trích xuất dữ liệu hữu ích. Một trình thu thập dữ liệu web (thường được gọi là spider) tìm nạp các trang web, phân tích nội dung của chúng và xử lý thông tin để đáp ứng các mục tiêu cụ thể, chẳng hạn như lập chỉ mục hoặc tổng hợp dữ liệu. Hãy cùng phân tích:
Trình thu thập dữ liệu web gửi các yêu cầu HTTP để truy xuất các trang web từ máy chủ và xử lý các phản hồi. Hãy nghĩ về nó như một cái bắt tay lịch sự giữa trình thu thập dữ liệu của bạn và trang web—“Chào, tôi có thể lấy dữ liệu của bạn để sử dụng không?”
Sau khi tìm nạp trang, trình thu thập dữ liệu trích xuất dữ liệu có liên quan bằng cách phân tích cú pháp HTML. Cấu trúc DOM giúp chia trang thành các phần dễ quản lý và bộ chọn CSS hoạt động như một cặp nhíp chính xác, nhặt ra các phần tử bạn cần.
Hầu hết các trang web phân phối dữ liệu của họ trên nhiều trang. Trình thu thập dữ liệu cần điều hướng mê cung phân trang này, đồng thời tôn trọng giới hạn tốc độ để tránh trông giống như một bot đói dữ liệu.
Tại sao Golang hoàn hảo để thu thập dữ liệu web vào năm 2025
Nếu thu thập dữ liệu web là một cuộc đua, thì Golang sẽ là chiếc xe thể thao mà bạn muốn trong ga-ra của mình. Các tính năng độc đáo của nó làm cho nó trở thành ngôn ngữ được sử dụng nhiều nhất cho các trình thu thập dữ liệu web hiện đại.
- Đồng thời: Các goroutine của Golang cho phép bạn thực hiện nhiều yêu cầu đồng thời, thu thập dữ liệu nhanh hơn bạn có thể nói "xử lý song song".
- Đơn giản: Cú pháp rõ ràng và thiết kế tối giản của ngôn ngữ giúp cho cơ sở mã của bạn dễ quản lý, ngay cả khi giải quyết các dự án thu thập dữ liệu phức tạp.
- Hiệu suất: Golang được biên dịch, có nghĩa là nó chạy rất nhanh—lý tưởng để xử lý các tác vụ thu thập dữ liệu web quy mô lớn mà không gặp khó khăn.
- Thư viện chuẩn mạnh mẽ: Với hỗ trợ tích hợp cho các yêu cầu HTTP, phân tích cú pháp JSON, và hơn thế nữa, thư viện chuẩn của Golang trang bị cho bạn mọi thứ bạn cần để xây dựng một trình thu thập dữ liệu từ đầu.
Tại sao phải vật lộn với các công cụ cồng kềnh khi bạn có thể bay qua dữ liệu như một Gopher dùng cafein? Golang kết hợp tốc độ, sự đơn giản và sức mạnh, làm cho nó trở thành lựa chọn tối ưu để thu thập dữ liệu web một cách hiệu quả và hiệu quả.
Thu thập dữ liệu trang web có hợp pháp không?
Tính hợp pháp của việc thu thập dữ liệu web không phải là một tình huống phù hợp với tất cả. Nó phụ thuộc vào cách, nơi và lý do bạn đang thu thập dữ liệu. Mặc dù việc thu thập dữ liệu công khai nói chung là được phép, nhưng việc vi phạm điều khoản dịch vụ hoặc bỏ qua các biện pháp chống thu thập dữ liệu có thể dẫn đến rắc rối pháp lý.
Để giữ đúng pháp luật, đây là một vài quy tắc vàng:
- Tôn trọng các chỉ thị robots.txt.
- Tránh thu thập thông tin nhạy cảm hoặc bị hạn chế.
- Xin phép nếu bạn không chắc chắn về chính sách của trang web.
Cách xây dựng trình thu thập dữ liệu web Golang đầu tiên của bạn?
Điều kiện tiên quyết
- Hãy chắc chắn rằng bạn đã cài đặt phiên bản Go mới nhất. Bạn có thể tải xuống gói cài đặt từ trang web chính thức của Golang và làm theo hướng dẫn để cài đặt nó.
- Chọn IDE ưa thích của bạn. Hướng dẫn này sử dụng Goland làm trình chỉnh sửa.
- Chọn một thư viện thu thập dữ liệu web Go mà bạn cảm thấy thoải mái. Trong ví dụ này, chúng ta sẽ sử dụng chromedp.
Để xác minh cài đặt Go của bạn, hãy nhập lệnh sau vào thiết bị đầu cuối:
PowerShell
go versionNếu cài đặt thành công, bạn sẽ thấy kết quả sau:
PowerShell
go version go1.23.4 windows/amd64Tạo thư mục làm việc của bạn và khi đã ở bên trong, hãy nhập các lệnh sau:
- Khởi tạo
go mod:
PowerShell
go mod init crawl- Cài đặt phụ thuộc
chromedp:
PowerShell
go get github.com/chromedp/chromedp- Tạo tệp
crawl.go.
Bây giờ chúng ta có thể bắt đầu viết mã trình thu thập dữ liệu web của bạn.
Lấy các phần tử trang
Truy cập Lazada, và sử dụng công cụ dành cho nhà phát triển của trình duyệt (F12) để dễ dàng xác định các phần tử và bộ chọn trang bạn cần.
- Lấy trường nhập và nút tìm kiếm bên cạnh nó:
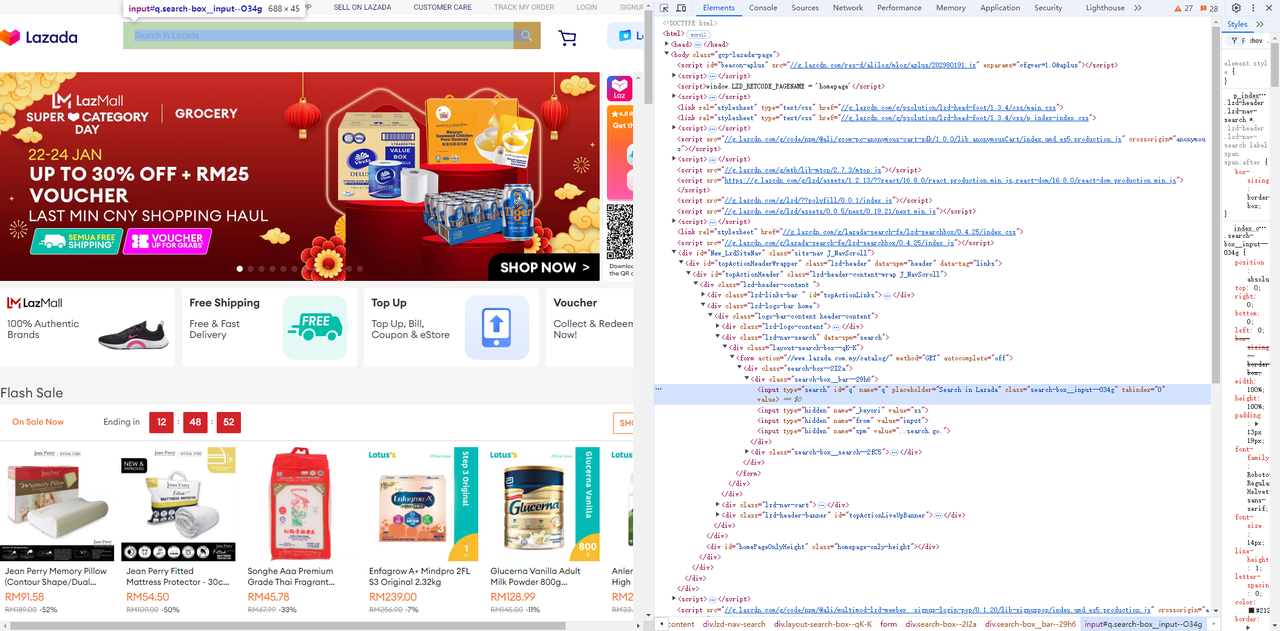
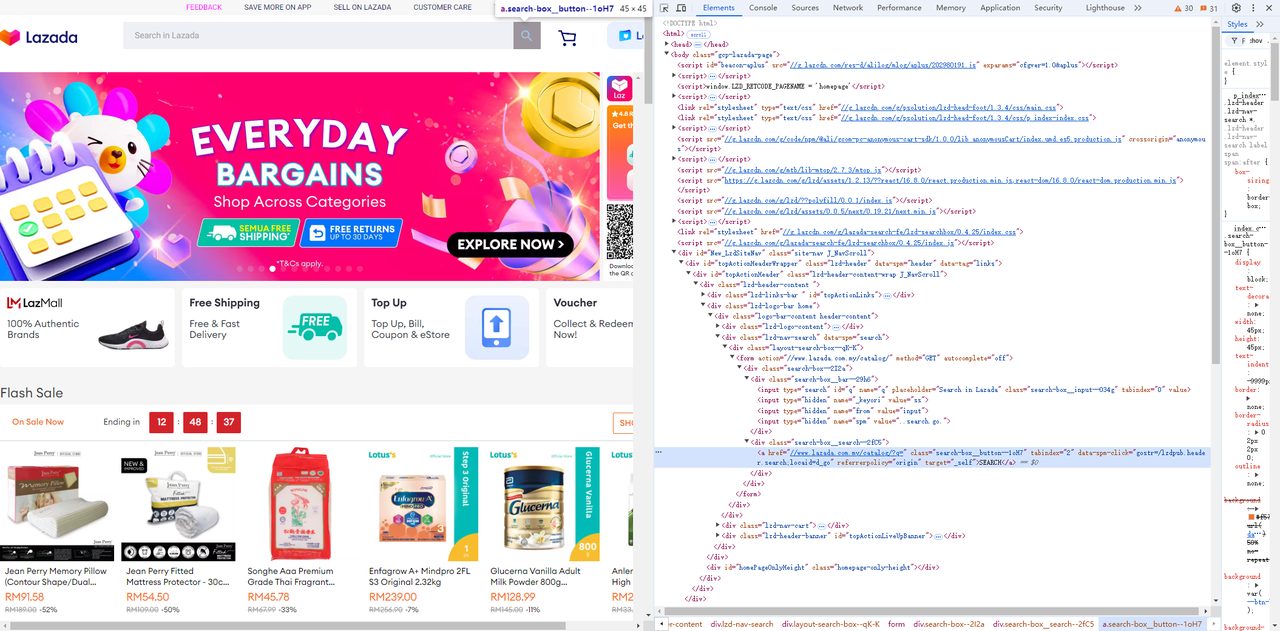
Go
func searchProduct(keyword string) chromedp.Tasks {
return chromedp.Tasks{
// chờ phần tử đầu vào hiển thị
chromedp.WaitVisible(`input[type=search]`, chromedp.ByQuery),
// Nhập sản phẩm được tìm kiếm.
chromedp.SendKeys("input[type=search]", keyword, chromedp.ByQuery),
// Nhấp vào tìm kiếm
chromedp.Click(".search-box__button--1oH7", chromedp.ByQuery),
}
}- Lấy các phần tử giá, tiêu đề và hình ảnh từ danh sách sản phẩm:
-
Danh sách sản phẩm
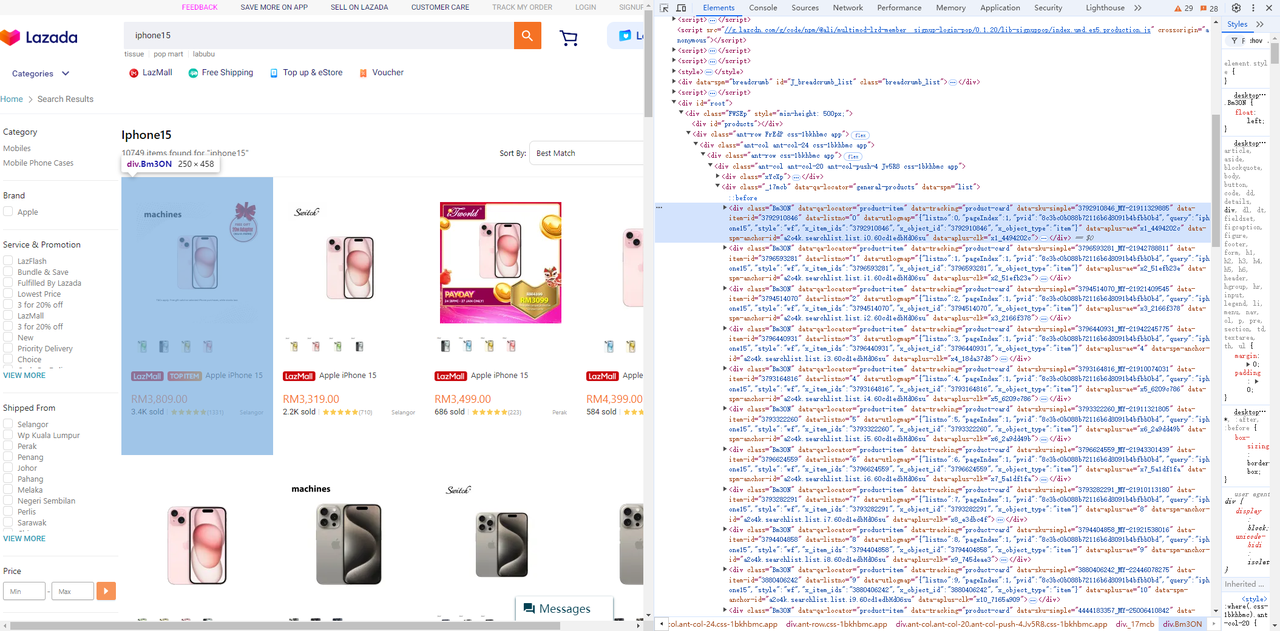
-
Phần tử hình ảnh
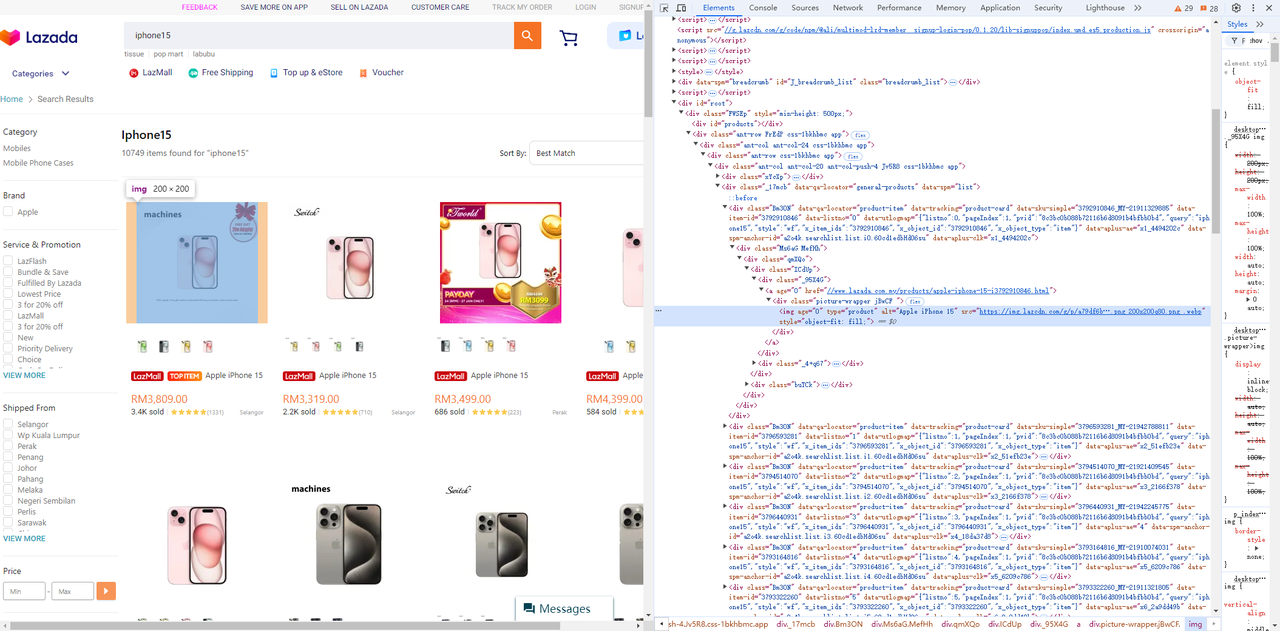
-
Phần tử tiêu đề
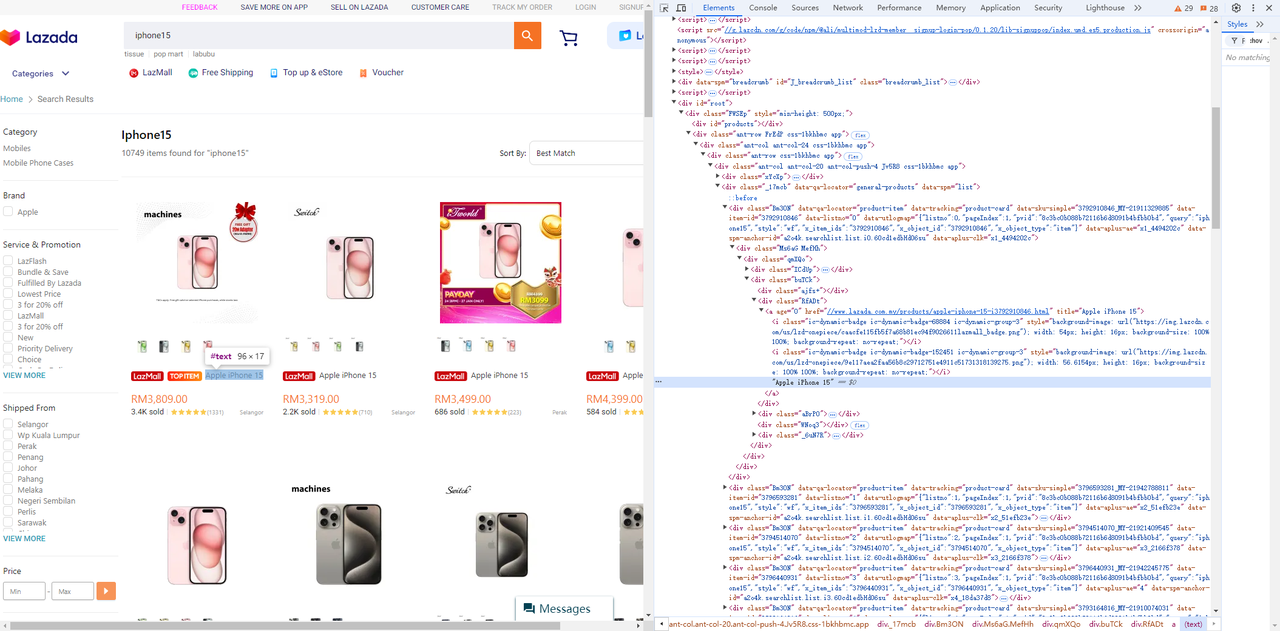
-
Phần tử giá
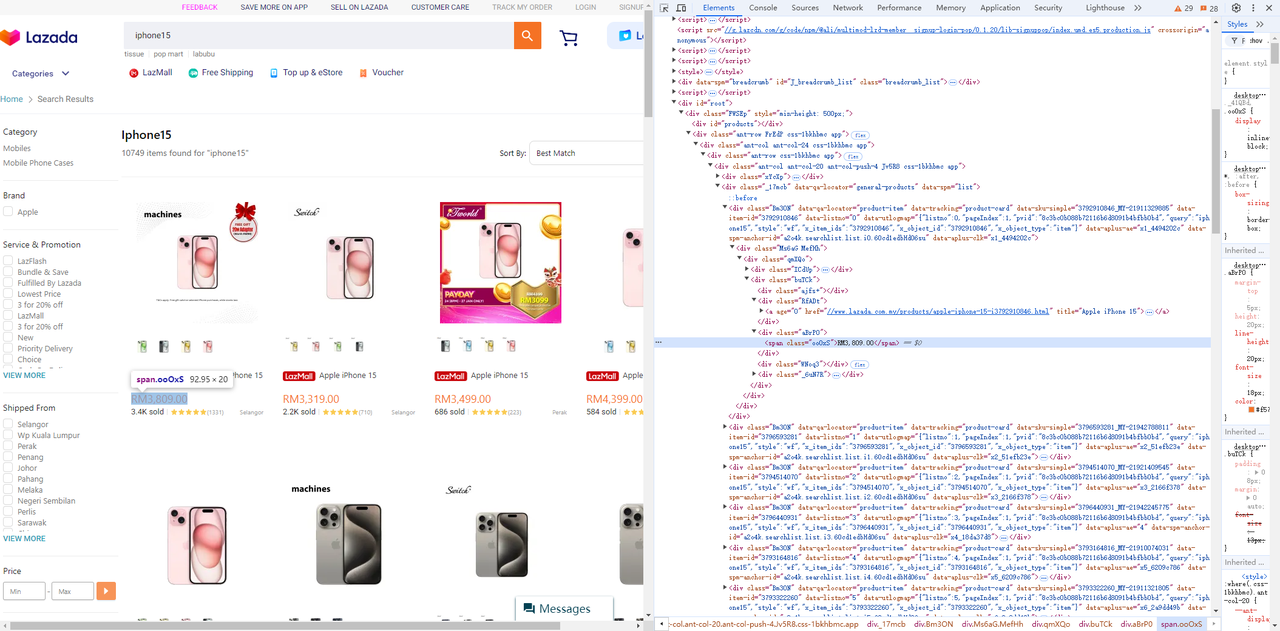
Go
func getNodes(nodes *[]*cdp.Node) chromedp.Tasks {
return chromedp.Tasks{
chromedp.WaitReady(`div[data-spm=list] .Bm3ON`, chromedp.ByQuery),
scrollToBottom(), // Cuộn xuống cuối để đảm bảo rằng tất cả các phần tử trang đều được hiển thị.
chromedp.Nodes("div[data-spm=list] .Bm3ON", nodes, chromedp.ByQueryAll),
}
}
func scrollToBottom() chromedp.Action {
return chromedp.ActionFunc(func(ctx context.Context) error {
for i := 0; i < 4; i++ { // Cuộn lặp lại để đảm bảo rằng tất cả các hình ảnh đều được tải.
_ = chromedp.Evaluate("window.scrollBy(0, window.innerHeight);", nil).Do(ctx)
time.Sleep(1 * time.Second)
}
return nil
})
}
func getProductData(ctx context.Context, node *cdp.Node) (*Product, error) {
product := new(Product)
err := chromedp.Run(ctx,
chromedp.WaitVisible(".Bm3ON img[type=product]", chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON img[type=product]", "src", &product.Img, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON .RfADt a", "title", &product.Title, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.TextContent(".Bm3ON .aBrP0 span", &product.Price, chromedp.ByQuery, chromedp.FromNode(node)),
)
if err != nil {
return nil, err
}
return product, nil
}Thiết lập môi trường Chrome
Để dễ gỡ lỗi hơn, chúng ta có thể khởi chạy trình duyệt Chrome trong PowerShell và chỉ định cổng gỡ lỗi từ xa.
PowerShell
chrome.exe --remote-debugging-port=9223Chúng ta có thể truy cập http://localhost:9223/json/list để truy xuất địa chỉ gỡ lỗi từ xa được hiển thị của trình duyệt, webSocketDebuggerUrl.
PowerShell
[
{
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=localhost:9223/devtools/page/85CE4D807D11D30D5F22C1AA52461080",
"id": "85CE4D807D11D30D5F22C1AA52461080",
"title": "localhost:9223/json/list",
"type": "page",
"url": "http://localhost:9223/json/list",
"webSocketDebuggerUrl": "ws://localhost:9223/devtools/page/85CE4D807D11D30D5F22C1AA52461080"
}
]Chạy mã
Toàn bộ mã như sau:
Go
package main
import (
"context"
"encoding/json"
"flag"
"log"
"time"
"github.com/chromedp/cdproto/cdp"
"github.com/chromedp/chromedp"
)
type Product struct {
ID string `json:"id"`
Img string `json:"img"`
Price string `json:"price"`
Title string `json:"title"`
}
func main() {
product := flag.String("product", "iphone15", "từ khóa sản phẩm của bạn")
url := flag.String("webSocketDebuggerUrl", "", "url websocket của bạn")
flag.Parse()
var baseCxt context.Context
if *url != "" {
baseCxt, _ = chromedp.NewRemoteAllocator(context.Background(), *url)
} else {
baseCxt = context.Background()
}
ctx, cancel := chromedp.NewContext(
baseCxt,
)
defer cancel()
var nodes []*cdp.Node
err := chromedp.Run(ctx,
chromedp.Navigate(`https://www.lazada.com.my/`),
searchProduct(*product),
getNodes(&nodes),
)
products := make([]*Product, 0, len(nodes))
for _, v := range nodes {
product, err := getProductData(ctx, v)
if err != nil {
log.Println("lỗi chạy tác vụ nút: ", err)
continue
}
products = append(products, product)
}
if err != nil {
log.Fatal(err)
}
jsonData, _ := json.Marshal(products)
log.Println(string(jsonData))
}
func searchProduct(keyword string) chromedp.Tasks {
return chromedp.Tasks{
// chờ phần tử đầu vào hiển thị
chromedp.WaitVisible(`input[type=search]`, chromedp.ByQuery),
// Nhập sản phẩm được tìm kiếm.
chromedp.SendKeys("input[type=search]", keyword, chromedp.ByQuery),
// Nhấp vào tìm kiếm
chromedp.Click(".search-box__button--1oH7", chromedp.ByQuery),
}
}
func getNodes(nodes *[]*cdp.Node) chromedp.Tasks {
return chromedp.Tasks{
chromedp.WaitReady(`div[data-spm=list] .Bm3ON`, chromedp.ByQuery),
scrollToBottom(), // Cuộn xuống cuối để đảm bảo rằng tất cả các phần tử trang đều được hiển thị.
chromedp.Nodes("div[data-spm=list] .Bm3ON", nodes, chromedp.ByQueryAll),
}
}
func scrollToBottom() chromedp.Action {
return chromedp.ActionFunc(func(ctx context.Context) error {
for i := 0; i < 4; i++ { // Cuộn lặp lại để đảm bảo rằng tất cả các hình ảnh đều được tải.
_ = chromedp.Evaluate("window.scrollBy(0, window.innerHeight);", nil).Do(ctx)
time.Sleep(1 * time.Second)
}
return nil
})
}
func getProductData(ctx context.Context, node *cdp.Node) (*Product, error) {
product := new(Product)
err := chromedp.Run(ctx,
chromedp.WaitVisible(".Bm3ON img[type=product]", chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON img[type=product]", "src", &product.Img, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON .RfADt a", "title", &product.Title, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.TextContent(".Bm3ON .aBrP0 span", &product.Price, chromedp.ByQuery, chromedp.FromNode(node)),
)
if err != nil {
return nil, err
}
product.ID = node.AttributeValue("data-item-id")
return product, nil
}Bằng cách chạy lệnh sau, bạn sẽ nhận được kết quả dữ liệu đã thu thập:
PowerShell
go run .\crawl.go -product="TỪ KHÓA CỦA BẠN"-webSocketDebuggerUrl="WEBSOCKETDEBUGGERURL CỦA BẠN"
JSON
[
{
"id": "3792910846",
"img": "https://img.lazcdn.com/g/p/a79df6b286a0887038c16b7600e38f4f.png_200x200q75.png_.webp",
"price": "RM3,809.00",
"title": "Apple iPhone 15"
},
{
"id": "3796593281",
"img": "https://img.lazcdn.com/g/p/627828b5fa28d708c5b093028cd06069.png_200x200q75.png_.webp",
"price": "RM3,319.00",
"title": "Apple iPhone 15"
},
{
"id": "3794514070",
"img": "https: //img.lazcdn.com/g/p/6f4ddc2693974398666ec731a713bcfd.jpg_200x200q75.jpg_.webp",
"price": "RM3,499.00",
"title": "Apple iPhone 15"
},
{
"id": "3796440931",
"img": "https://img.lazcdn.com/g/p/8df101af902d426f3e3a9748bafa7513.jpg_200x200q75.jpg_.webp",
"price": "RM4,399.00",
"title": "Apple iPhone 15"
},
......
{
"id": "3793164816",
"img": "https://img.lazcdn.com/g/p/b6c3498f75f1215f24712a25799b0d19.png_200x200q75.png_.webp",
"price": "RM3,799.00",
"title": "Apple iPhone 15"
},
{
"id": "3793322260",
"img": "https: //img.lazcdn.com/g/p/67199db1bd904c3b9b7ea0ce32bc6ace.png_200x200q75.png_.webp",
"price": "RM5,644.00",
"title": "[Ready Stock] Apple iPhone 15 Pro"
},
{
"id": "3796624559",
"img": "https://img.lazcdn.com/g/p/81a814a9c829afa200fbc691c9a0c30c.png_200x200q75.png_.webp",
"price": "RM6,679.00",
"title": "Apple iPhone 15 Pro (1TB)"
}
]Các kỹ thuật nâng cao để mở rộng trình thu thập dữ liệu web của bạn
Trình thu thập dữ liệu web của bạn cần được cải tiến! Để thu thập dữ liệu hiệu quả mà không bị chặn hoặc quá tải, bạn phải triển khai các kỹ thuật cân bằng tốc độ, độ tin cậy và tối ưu hóa tài nguyên.
Hãy cùng khám phá một số chiến lược nâng cao để đảm bảo trình thu thập dữ liệu của bạn hoạt động tốt hơn dưới tải trọng lớn.
Duy trì yêu cầu và phiên của bạn
Khi thu thập dữ liệu web, việc ném bom máy chủ bằng quá nhiều yêu cầu trong thời gian ngắn là một cách chắc chắn để bị phát hiện và cấm. Các trang web thường theo dõi tần suất yêu cầu từ cùng một máy khách và sự gia tăng đột ngột có thể kích hoạt các cơ chế chống bot.
Go
package main
import (
"fmt"
"io/ioutil"
"net/http"
"time"
)
func main() {
// Tạo một máy khách HTTP có thể tái sử dụng
client := &http.Client{}
// URL để thu thập dữ liệu
urls := []string{
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3",
}
// Khoảng thời gian giữa các yêu cầu (ví dụ: 2 giây)
requestInterval := 2 * time.Second
for _, url := range urls {
// Tạo một yêu cầu HTTP mới
req, _ := http.NewRequest("GET", url, nil)
req.Header.Set("User-Agent", "Mozilla/5.0 (compatible; WebCrawler/1.0)")
// Gửi yêu cầu
resp, err := client.Do(req)
if err != nil {
fmt.Println("Lỗi:", err)
continue
}
// Đọc và in phản hồi
body, _ := ioutil.ReadAll(resp.Body)
fmt.Printf("Phản hồi từ %s:\n%s\n", url, body)
resp.Body.Close()
// Chờ trước khi gửi yêu cầu tiếp theo
time.Sleep(requestInterval)
}
}Tránh các liên kết trùng lặp
Không có gì tệ hơn việc lãng phí tài nguyên để thu thập cùng một URL hai lần. Triển khai một hệ thống loại bỏ trùng lặp mạnh mẽ bằng cách duy trì một tập hợp URL (ví dụ: bản đồ băm hoặc cơ sở dữ liệu Redis) để theo dõi các trang đã truy cập. Điều này không chỉ tiết kiệm băng thông mà còn đảm bảo trình thu thập dữ liệu của bạn hoạt động hiệu quả và không bỏ lỡ các trang mới.
Quản lý proxy để tránh bị cấm IP.
Thu thập dữ liệu quy mô lớn thường kích hoạt các biện pháp chống bot, dẫn đến việc cấm IP. Để tránh điều này, hãy tích hợp luân phiên proxy vào trình thu thập dữ liệu của bạn.
- Sử dụng nhóm proxy để phân phối yêu cầu trên nhiều IP.
- Luân phiên proxy một cách động để làm cho các yêu cầu của bạn xuất hiện như thể chúng bắt nguồn từ các người dùng và vị trí khác nhau.
Ưu tiên các trang cụ thể
Ưu tiên các trang cụ thể giúp sắp xếp hợp lý quá trình thu thập dữ liệu của bạn và cho phép bạn tập trung vào việc thu thập các liên kết hữu ích. Trong trình thu thập dữ liệu hiện tại, chúng ta sử dụng bộ chọn CSS để chỉ nhắm mục tiêu các liên kết phân trang và trích xuất thông tin sản phẩm có giá trị.
Tuy nhiên, nếu bạn quan tâm đến tất cả các liên kết trên một trang và muốn ưu tiên phân trang, bạn có thể duy trì một hàng đợi riêng biệt và xử lý các liên kết phân trang trước.
Go
package main
import (
"fmt"
"github.com/gocolly/colly"
)
// ...
// tạo biến để tách các liên kết phân trang khỏi các liên kết khác
var paginationURLs = []string{}
var otherURLs = []string{}
func main() {
// ...
}
func crawl (currenturl string, maxdepth int) {
// ...
// ----- tìm và truy cập tất cả các liên kết ---- //
// chọn thuộc tính href của tất cả các thẻ neo
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
// lấy URL tuyệt đối
link := e.Request.AbsoluteURL(e.Attr("href"))
// kiểm tra xem URL hiện tại đã được truy cập chưa
if link != "" && !visitedurls[link] {
// thêm URL hiện tại vào visitedURLs
visitedurls[link] = true
if e.Attr("class") == "page-numbers" {
paginationURLs = append(paginationURLs, link)
} else {
otherURLs = append(otherURLs, link)
}
}
})
// ...
// xử lý các liên kết phân trang trước
for len(paginationURLs) > 0 {
nextURL := paginationURLs[0]
paginationURLs = paginationURLs[1:]
visitedurls[nextURL] = true
err := c.Visit(nextURL)
if err != nil {
fmt.Println("Lỗi khi truy cập trang:", err)
}
}
// xử lý các liên kết khác
for len(otherURLs) > 0 {
nextURL := otherURLs[0]
otherURLs = otherURLs[1:]
visitedurls[nextURL] = true
err := c.Visit(nextURL)
if err != nil {
fmt.Println("Lỗi khi truy cập trang:", err)
}
}
}API thu thập dữ liệu Scrapeless: Công cụ thu thập dữ liệu hiệu quả
Tại sao API thu thập dữ liệu Scrapeless lại lý tưởng hơn?
API thu thập dữ liệu Scrapeless được thiết kế để đơn giản hóa quá trình trích xuất dữ liệu từ các trang web và nó có thể điều hướng các môi trường web phức tạp nhất, quản lý hiệu quả nội dung động và kết xuất JavaScript.
Bên cạnh đó, API thu thập dữ liệu Scrapeless tận dụng mạng lưới toàn cầu trải rộng 195 quốc gia, được hỗ trợ bởi quyền truy cập vào hơn 70 triệu IP dân cư. Với thời gian hoạt động 99,9% và tỷ lệ thành công vượt trội, Scrapeless dễ dàng vượt qua các thách thức như chặn IP và CAPTCHA, làm cho nó trở thành giải pháp mạnh mẽ cho tự động hóa web phức tạp và thu thập dữ liệu do AI điều khiển.
Với API thu thập dữ liệu nâng cao của chúng tôi, bạn có thể truy cập dữ liệu bạn cần mà không cần phải viết hoặc duy trì các tập lệnh thu thập dữ liệu phức tạp!
Ưu điểm của API thu thập dữ liệu
Scrapeless hỗ trợ kết xuất JavaScript hiệu năng cao, cho phép nó xử lý nội dung động (chẳng hạn như dữ liệu được tải qua AJAX hoặc JavaScript) và thu thập dữ liệu các trang web hiện đại dựa vào JS để phân phối nội dung.
- Giá cả phải chăng: Scrapeless được thiết kế để cung cấp giá trị vượt trội.
- Ổn định và đáng tin cậy: Với lịch sử đã được chứng minh, Scrapeless cung cấp phản hồi API ổn định, ngay cả dưới tải trọng cao.
- Tỷ lệ thành công cao: Hãy tạm biệt việc trích xuất thất bại và Scrapeless hứa hẹn 99,99% truy cập thành công vào dữ liệu Google SERP.
- Khả năng mở rộng: Xử lý hàng nghìn truy vấn dễ dàng, nhờ cơ sở hạ tầng mạnh mẽ đằng sau Scrapeless.
Nhận API thu thập dữ liệu Scrapeless giá rẻ và mạnh mẽ ngay bây giờ!
Scrapeless cung cấp một nền tảng thu thập dữ liệu web đáng tin cậy và có khả năng mở rộng với giá cả cạnh tranh, đảm bảo giá trị tuyệt vời cho người dùng của mình:
- Trình duyệt thu thập dữ liệu: Từ 0,09 đô la một giờ
- API thu thập dữ liệu: Từ 1,00 đô la cho 1k URL
- Công cụ mở khóa web: 0,20 đô la cho 1k URL
- Bộ giải CAPTCHA: Từ 0,80 đô la cho 1k URL
- Proxy: 2,80 đô la cho 1 GB
Bằng cách đăng ký, bạn có thể tận hưởng giảm giá lên đến 20% trên mỗi dịch vụ. Bạn có yêu cầu cụ thể? Liên hệ với chúng tôi ngay hôm nay, và chúng tôi sẽ cung cấp mức tiết kiệm lớn hơn nữa phù hợp với nhu cầu của bạn!
Cách sử dụng API thu thập dữ liệu Scrapeless?
Sử dụng API thu thập dữ liệu Scrapeless để thu thập dữ liệu Lazada rất dễ dàng. Bạn chỉ cần một yêu cầu đơn giản để có được tất cả dữ liệu bạn muốn. Làm thế nào để gọi API scrapeless nhanh chóng? Vui lòng làm theo các bước của tôi:
- Bước 1. Đăng nhập vào Scrapeless
- Bước 2. Nhấp vào "API thu thập dữ liệu"
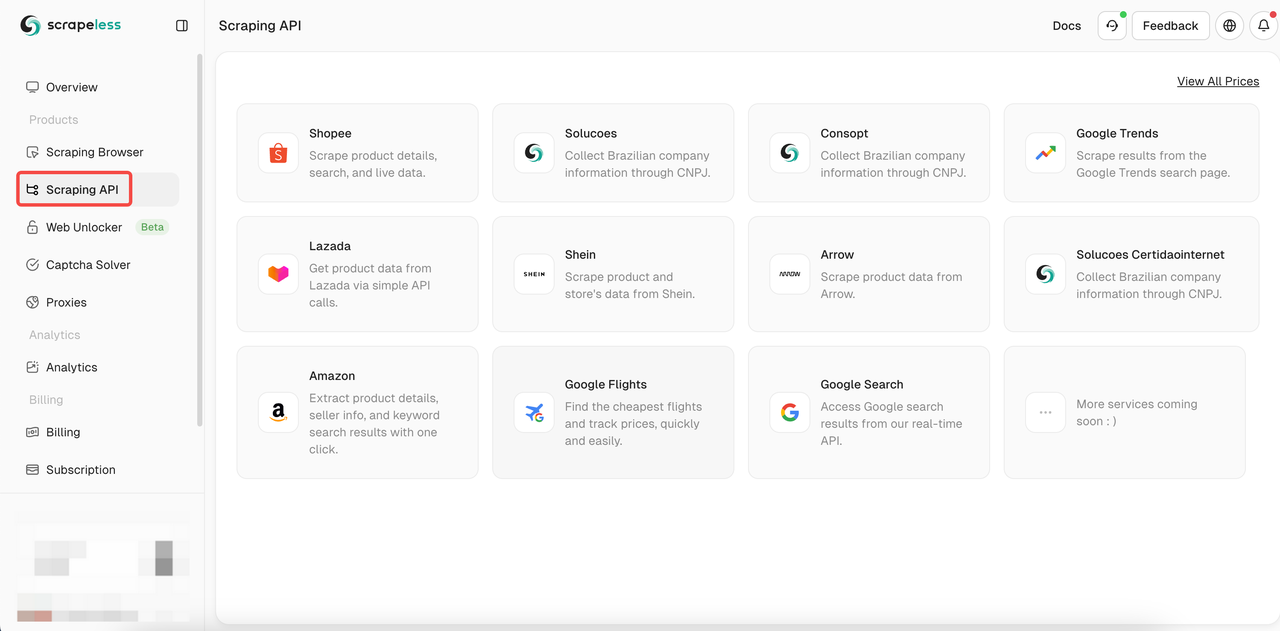
- Bước 3. Tìm API "Lazada" của chúng tôi và nhập nó:
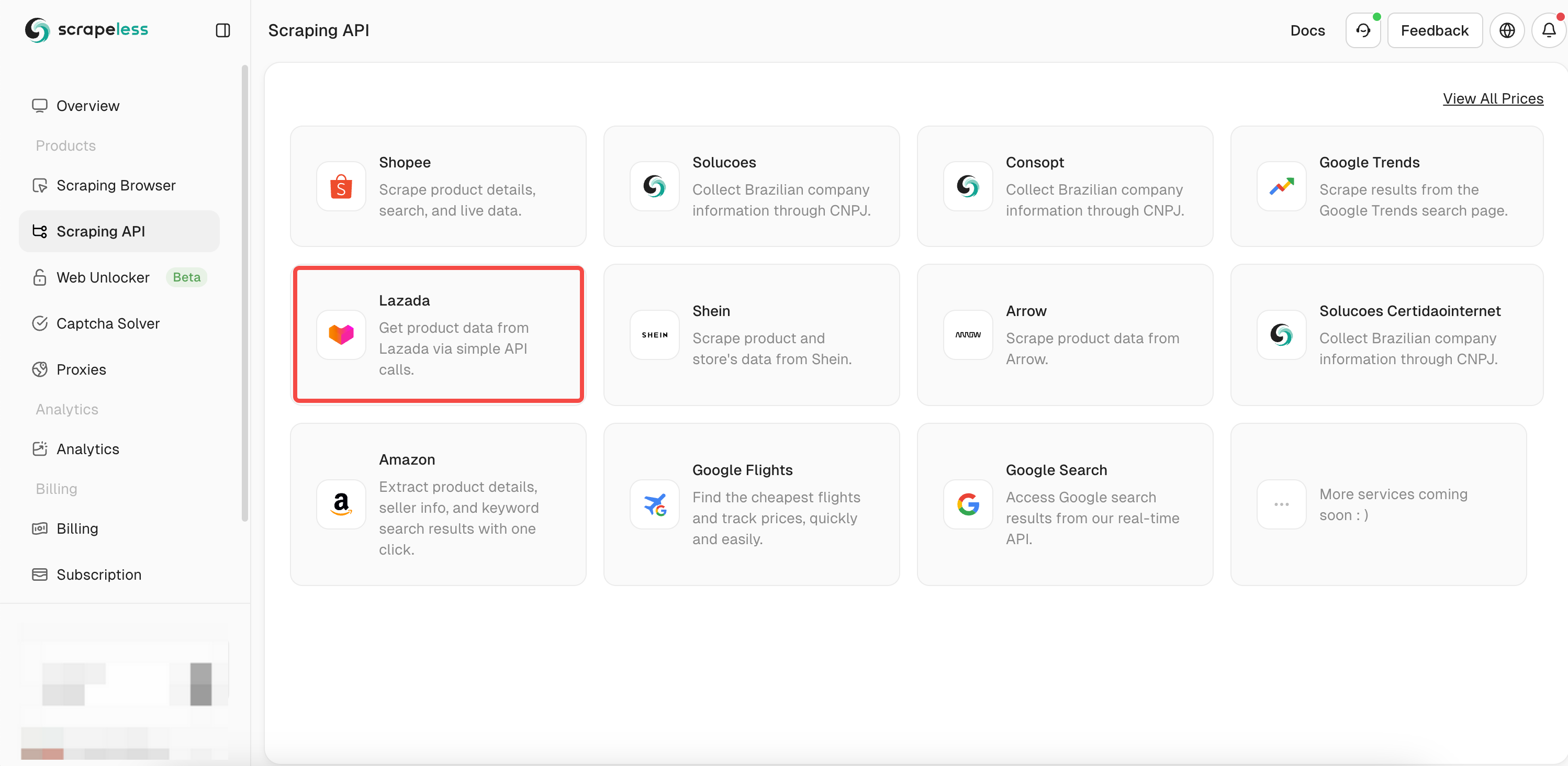
- Bước 4. Điền đầy đủ thông tin của sản phẩm bạn muốn thu thập trong hộp thao tác bên trái. Khi bạn sử dụng
chromedpđể thu thập dữ liệu, bạn đã có được ID của sản phẩm đã thu thập. Bây giờ bạn chỉ cần thêm ID vào tham số itemId để có được dữ liệu chi tiết hơn về sản phẩm. Sau đó, chọn ngôn ngữ biểu thức bạn muốn:
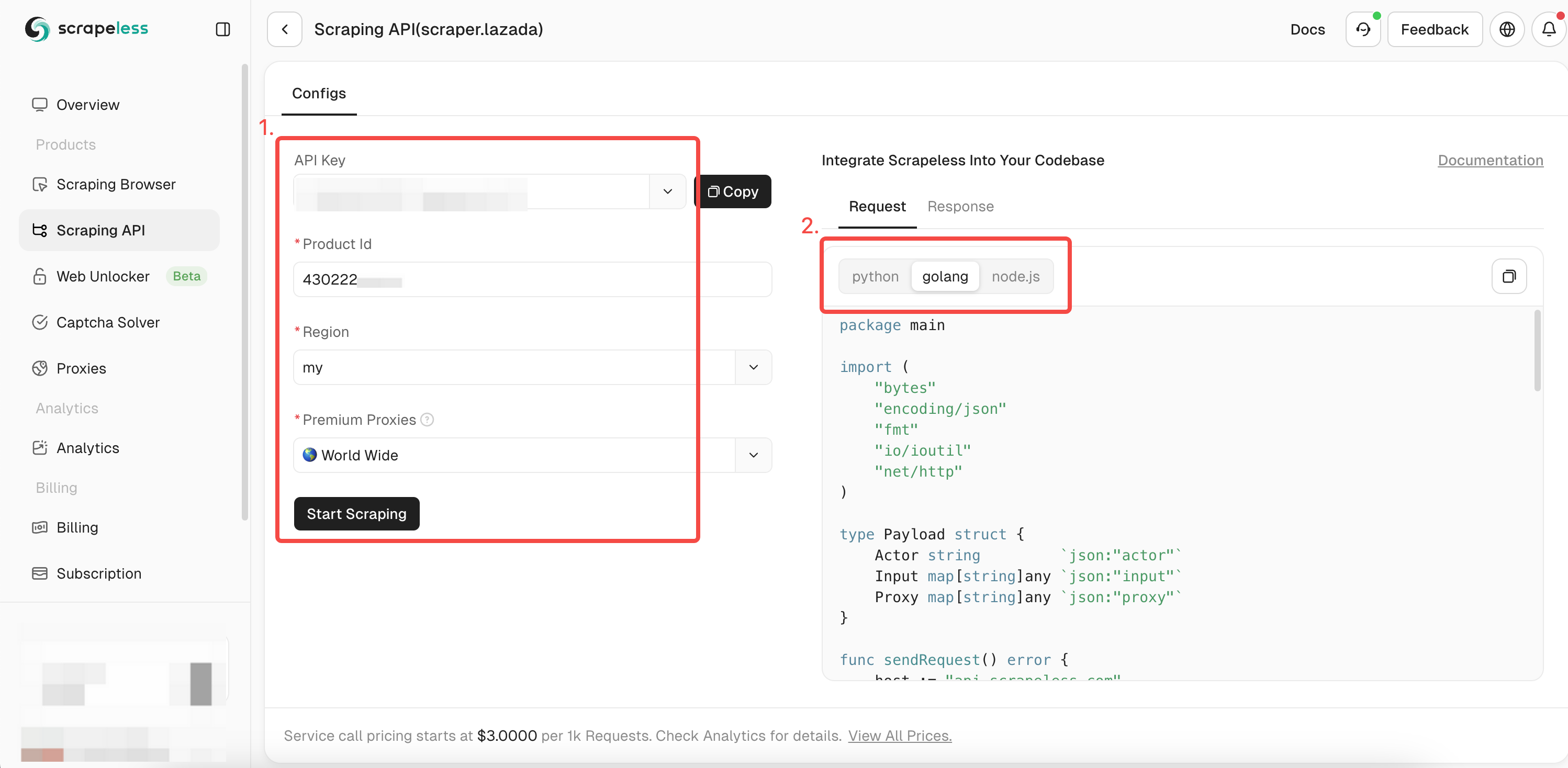
- Bước 5. Nhấp vào "Bắt đầu thu thập dữ liệu", và kết quả thu thập dữ liệu sản phẩm sẽ xuất hiện trong hộp xem trước bên phải:
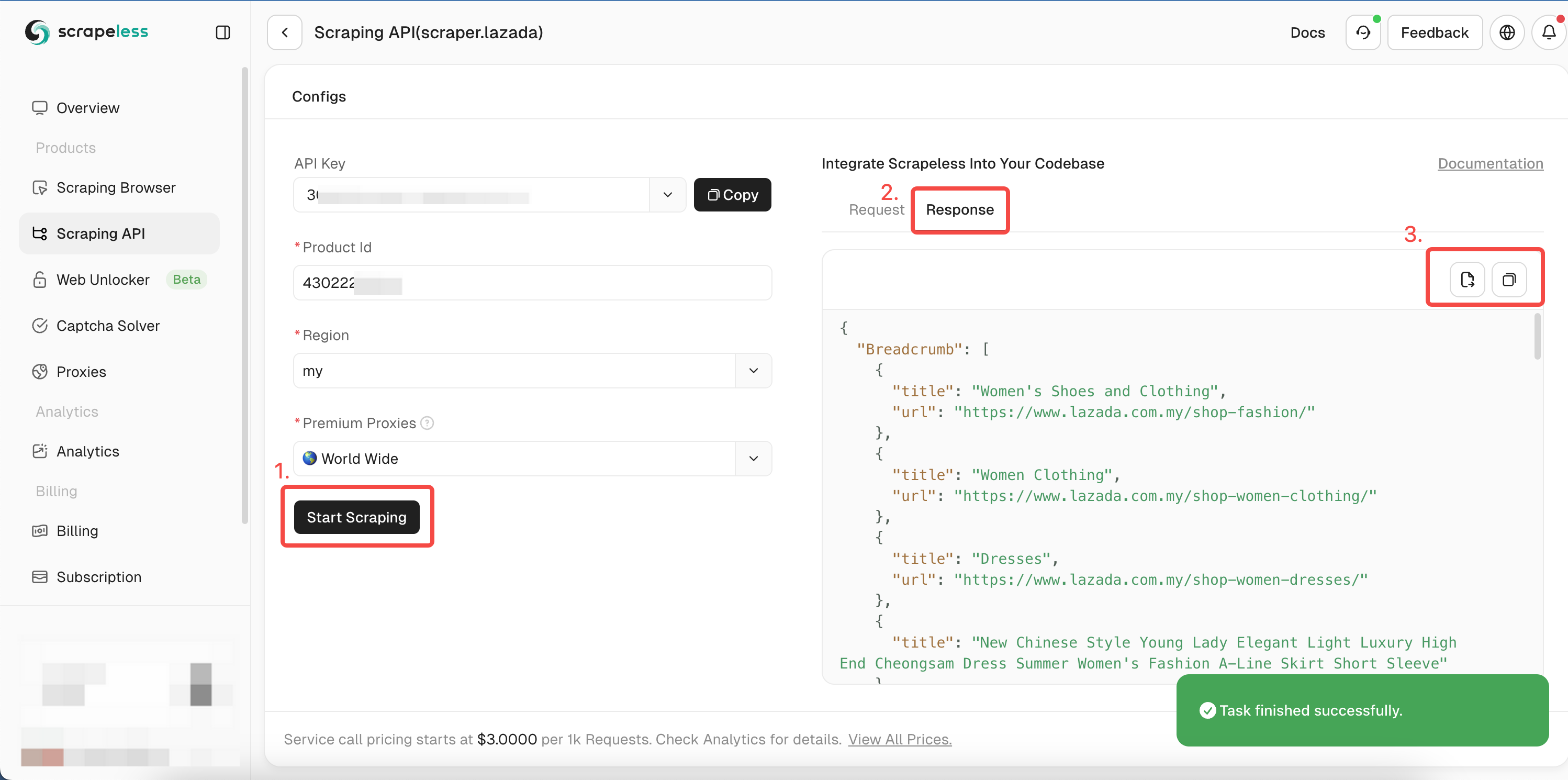
Bạn có thể tham khảo mã mẫu Golang của chúng tôi hoặc truy cập tài liệu API của chúng tôi cho các ngôn ngữ khác.
Go
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
type Payload struct {
Actor string `json:"actor"`
Input map[string]any `json:"input"`
Proxy map[string]any `json:"proxy"`
}
func sendRequest() error {
host := "api.scrapeless.com"
url := fmt.Sprintf("https://%s/api/v1/scraper/request", host)
token := "TOKEN_CỦA_BẠN"
headers := map[string]string{"x-api-token": token}
inputData := map[string]any{
"itemId": "3792910846", // Thay thế bằng itemId bạn muốn lấy.
"site": "my",
}
proxy := map[string]any{
"country": "BẤT_KỲ",
}
payload := Payload{
Actor: "scraper.lazada",
Input: inputData,
Proxy: proxy,
}
jsonPayload, err := json.Marshal(payload)
if err != nil {
return err
}
req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonPayload))
if err != nil {
return err
}
for key, value := range headers {
req.Header.Set(key, value)
}
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
fmt.Printf("body %s\n", string(body))
return nil
}
func main() {
err := sendRequest()
if err != nil {
fmt.Println("Lỗi:", err)
return
}
}Sau khi chạy, bạn sẽ nhận được dữ liệu chi tiết sau. Bao gồm các liên kết, hình ảnh, SKU, Đánh giá, Cùng người bán, v.v.
Do hạn chế về không gian, chúng tôi chỉ hiển thị một phần kết quả thu thập ở đây. Bạn có thể truy cập vào Bảng điều khiển của chúng tôi và nhận dùng thử miễn phí để thu thập nhanh chóng và nhận được kết quả thu thập đầy đủ!
JSON
{
"Breadcrumb": [
{
"title": "Điện thoại di động & Máy tính bảng",
"url": "https://www.lazada.com.my/shop-mobiles-tablets/"
},
{
"title": "Smartphones",
"url": "https://www.lazada.com.my/shop-mobiles/"
},
{
"title": "Apple iPhone 15"
}
],
"deliveryOptions": {
"21911329880": [
{
"badge": false,
"dataType": "delivery",
"deliveryWorkTimeMax": "2025-01-27T23:27+08:00[GMT+08:00]",
"deliveryWorkTimeMin": "2025-01-24T23:27+08:00[GMT+08:00]",
"description": "Đối với các mặt hàng nội địa, bạn có thể nhận được hàng trong vòng 2-4 ngày làm việc. <br/>Phí vận chuyển được xác định bởi tổng kích thước/cân nặng của các sản phẩm mua từ người bán.<br/><br/><a href=\"https://www.lazada.com.my/helpcenter/shipping_delivery/#answer-faq-whatisshippingfee-ans\" target=\"_blank\">Tìm hiểu thêm</a>",
"duringTime": "Đảm bảo từ 24-27 tháng 1",
"fee": "RM4.90",
"feeValue": 4.9,
"hasTip": true,
"title": "Giao hàng tiêu chuẩn",
"type": "standard"
},
{
"badge": true,
"dataType": "service",
"description": "",
"feeValue": 0,
"hasTip": true,
"title": "Thanh toán khi nhận hàng không khả dụng",
"type": "noCOD"
}
],
"21911329881": [
{
"badge": false,
"dataType": "delivery",
"deliveryWorkTimeMax": "2025-01-27T23:27+08:00[GMT+08:00]",
"deliveryWorkTimeMin": "2025-01-24T23:27+08:00[GMT+08:00]",
"description": "Đối với các mặt hàng nội địa, bạn có thể nhận được hàng trong vòng 2-4 ngày làm việc. <br/>Phí vận chuyển được xác định bởi tổng kích thước/cân nặng của các sản phẩm mua từ người bán.<br/><br/><a href=\"https://www.lazada.com.my/helpcenter/shipping_delivery/#answer-faq-whatisshippingfee-ans\" target=\"_blank\">Tìm hiểu thêm</a>",
"duringTime": "Đảm bảo từ 24-27 tháng 1",
"fee": "RM4.90",
"feeValue": 4.9,
"hasTip": true,
"title": "Giao hàng tiêu chuẩn",
"type": "standard"
},
{
"badge": true,
"dataType": "service",
"description": "",
"feeValue": 0,
"hasTip": true,
"title": "Thanh toán khi nhận hàng không khả dụng",
"type": "noCOD"
}
],
...Đọc thêm
- Các bước đầy đủ để thu thập dữ liệu chi tiết sản phẩm Shopee
- Làm thế nào để thu thập dữ liệu Xu hướng Google một cách nhanh chóng và dễ dàng?
- Nhận các bước để theo dõi các chuyến bay giá rẻ bằng API chuyến bay của Google!
Các thực tiễn tốt nhất và điều cần xem xét khi thu thập dữ liệu Golang
Thu thập dữ liệu song song và đồng thời
Thu thập dữ liệu nhiều trang đồng bộ có thể dẫn đến thiếu hiệu quả vì chỉ có một goroutine có thể xử lý các tác vụ một cách chủ động tại bất kỳ thời điểm nào. Trình thu thập dữ liệu web của bạn dành phần lớn thời gian để chờ phản hồi và xử lý dữ liệu trước khi chuyển sang tác vụ tiếp theo
Tuy nhiên, tận dụng khả năng đồng thời của Go để thử thu thập dữ liệu đồng thời có thể giảm đáng kể tổng thời gian thu thập dữ liệu của bạn!
Tuy nhiên, bạn phải quản lý đồng thời một cách thích hợp để tránh làm quá tải máy chủ đích và kích hoạt các hạn chế chống bot.
Quét các trang được render bằng JavaScript trong Go
Mặc dù Colly là một công cụ quét web tuyệt vời với nhiều tính năng tích hợp, nhưng nó không thể quét các trang được render bằng JavaScript (nội dung động). Nó chỉ có thể lấy và phân tích HTML tĩnh, và nội dung động không tồn tại trong HTML tĩnh của một website.
Tuy nhiên, bạn có thể tích hợp với một trình duyệt không giao diện người dùng hoặc một công cụ JavaScript engine để quét nội dung động.
Những suy nghĩ cuối cùng
Bạn đã học cách xây dựng một công cụ quét web bằng Golang sử dụng lập trình nâng cao. Hãy nhớ rằng, mặc dù việc xây dựng một web scraper để duyệt web là một bước khởi đầu tuyệt vời, bạn cần phải vượt qua các biện pháp chống bot để truy cập các website hiện đại.
Thay vì vật lộn với cấu hình thủ công có thể thất bại, hãy cân nhắc sử dụng Scrapeless Scraping API, giải pháp đáng tin cậy nhất để vượt qua bất kỳ hệ thống chống bot nào.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


