
Cách vượt qua bảo vệ Cloudflare và Turnstile bằng Scrapeless | Hướng dẫn hoàn chỉnh
Advanced Data Extraction Specialist
Giới thiệu
Việc thu thập dữ liệu web ngày càng khó khăn hơn do các cơ chế bảo mật nâng cao như Bảo vệ Cloudflare và Cloudflare Turnstile. Những thách thức này được thiết kế để chặn quyền truy cập tự động và khiến các bot khó lấy dữ liệu. Tuy nhiên, với Trình duyệt Scrapeless Scraping, bạn có thể bỏ qua các hạn chế này một cách hiệu quả và tiếp tục thu thập dữ liệu mà không bị gián đoạn.
Trong hướng dẫn này, chúng ta sẽ đề cập đến ba khía cạnh chính của việc bỏ qua các thách thức Cloudflare:
- Cách bỏ qua Bảo vệ Cloudflare bằng Trình duyệt Scrapeless – Tìm hiểu cách bỏ qua các biện pháp bảo mật như CAPTCHA và phát hiện bot.
- Cách lấy và sử dụng Cookie cf_clearance và Tiêu đề Yêu cầu – Hiểu cách trích xuất và sử dụng cookie cf_clearance để duy trì tính nhất quán của phiên.
- Cách bỏ qua Cloudflare Turnstile bằng Trình duyệt Scrapeless – Khám phá cách bỏ qua thách thức Turnstile và tự động hóa các tác vụ thu thập dữ liệu của bạn.
Đến cuối hướng dẫn này, bạn sẽ có một chiến lược hoàn chỉnh để xử lý bảo vệ Cloudflare một cách hiệu quả. Hãy bắt đầu thôi!
Phần 1: Cách bỏ qua Bảo vệ Cloudflare bằng Scrapeless
Hướng dẫn này sẽ chỉ cho bạn cách sử dụng Scrapeless và Puppeteer-core để bỏ qua bảo vệ Cloudflare trên các trang web.
Bước 1: Chuẩn bị
1.1 Tạo một thư mục Dự án
-
Tạo một thư mục mới cho dự án, ví dụ: scrapeless-bypass.
-
Điều hướng đến thư mục trong thiết bị đầu cuối của bạn:
cd path/to/scrapeless-bypass1.2 Khởi tạo một Dự án Node.js
Chạy lệnh sau để tạo tệp package.json:
npm init -y1.3 Cài đặt các Phụ thuộc cần thiết
Cài đặt Puppeteer-core, cho phép kết nối từ xa với một phiên bản trình duyệt:
npm install puppeteer-coreNếu Puppeteer chưa được cài đặt trên hệ thống của bạn, hãy cài đặt phiên bản đầy đủ:
npm install puppeteer puppeteer-coreBước 2: Lấy Khóa API Scrapeless
2.1 Đăng ký trên Scrapeless
-
Truy cập Scrapeless và tạo một tài khoản.
-
Điều hướng đến phần Quản lý Khóa API.
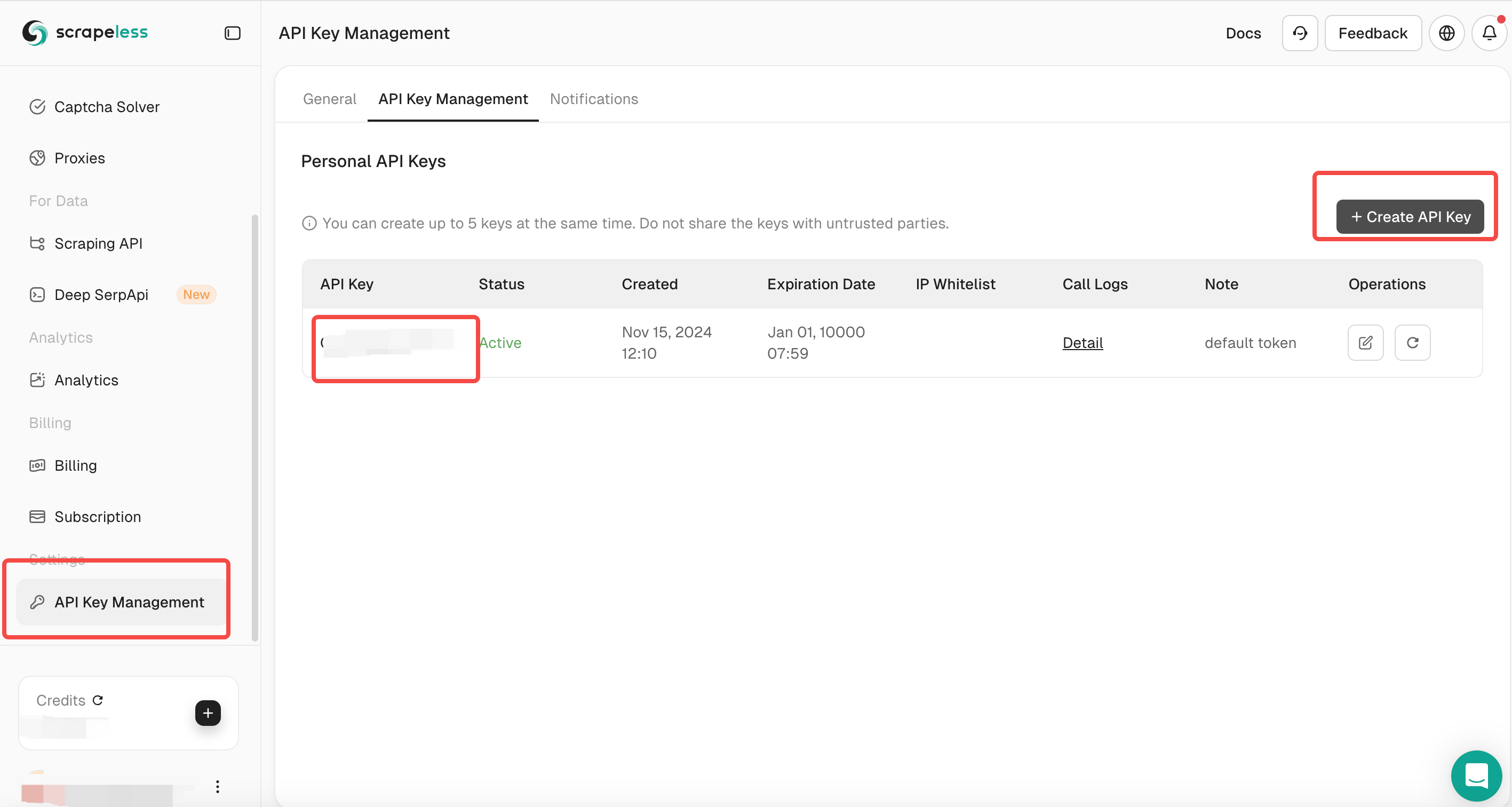
- Tạo một Khóa API mới và sao chép nó.
🚀 Sẵn sàng để tìm hiểu sâu hơn về việc bỏ qua các biện pháp bảo vệ Cloudflare?
👉 Đăng nhập ngay để truy cập các tính năng và hướng dẫn nâng cao!
🔒 Cần thêm sự trợ giúp? Tham gia cộng đồng Discord của chúng tôi để được hỗ trợ và cập nhật theo thời gian thực!
📈 Bắt đầu thu thập dữ liệu thông minh hơn với Trình duyệt Scrapeless ngay hôm nay!
Bước 3: Kết nối với Scrapeless Browserless
3.1 Lấy URL Kết nối WebSocket
Scrapeless cung cấp một URL kết nối WebSocket cho Puppeteer để tương tác với trình duyệt dựa trên đám mây.
Định dạng là:
wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANYThay thế APIKey bằng Khóa API Scrapeless thực tế của bạn.
3.2 Thiết lập Tham số Kết nối
-
token: Khóa API Scrapeless của bạn
-
session_ttl: Thời lượng phiên trình duyệt tính bằng giây (ví dụ: 180 giây)
-
proxy_country: Mã quốc gia cho máy chủ proxy (ví dụ: GB cho Vương quốc Anh, US cho Hoa Kỳ)
Bước 4: Viết tập lệnh Puppeteer
4.1 Tạo tệp Tập lệnh
Bên trong thư mục dự án của bạn, tạo một tệp JavaScript mới có tên bypass-cloudflare.js.
4.2 Kết nối với Scrapeless và Khởi chạy Puppeteer
Thêm mã sau vào bypass-cloudflare.js:
javascript
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'; // Thay thế bằng Khóa API thực tế của bạn
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180', // Thời lượng phiên trình duyệt tính bằng giây
proxy_country: 'GB', // Mã quốc gia Proxy
proxy_session_id: 'test_session', // ID phiên Proxy (giữ cùng IP)
proxy_session_duration: '5' // Thời lượng phiên Proxy tính bằng phút
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Kết nối với Scrapeless');4.3 Mở một Trang Web và Bỏ qua Cloudflare
Mở rộng tập lệnh để mở một trang mới và điều hướng đến một trang web được bảo vệ bởi Cloudflare:
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });4.4 Chờ các Phần tử Trang được tải
Đảm bảo rằng bảo vệ Cloudflare đã bị bỏ qua trước khi tiếp tục:
javascript
await page.waitForSelector('main.page-content .challenge-info', { timeout: 30000 }); // Điều chỉnh bộ chọn nếu cần4.5 Chụp ảnh màn hình
Để xác minh việc bỏ qua bảo vệ Cloudflare thành công, hãy chụp ảnh màn hình trang:
javascript
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('Ảnh chụp màn hình được lưu dưới dạng challenge-bypass.png');4.6 Tập lệnh hoàn chỉnh
Đây là toàn bộ tập lệnh:
javascript
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'; // Thay thế bằng Khóa API thực tế của bạn
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180',
proxy_country: 'GB',
proxy_session_id: 'test_session',
proxy_session_duration: '5'
}).toString();
const connectionURL = `${host}/browser?${query}`;
(async () => {
try {
// Kết nối với Scrapeless
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Kết nối với Scrapeless');
// Mở một trang mới và điều hướng đến trang web mục tiêu
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });
// Chờ trang tải hoàn toàn
await page.waitForTimeout(5000); // Điều chỉnh độ trễ nếu cần
await page.waitForSelector('main.page-content', { timeout: 30000 });
// Chụp ảnh màn hình
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('Ảnh chụp màn hình được lưu dưới dạng challenge-bypass.png');
// Đóng trình duyệt
await browser.close();
console.log('Trình duyệt đã đóng');
} catch (error) {
console.error('Lỗi:', error);
}
})();Bước 5: Chạy tập lệnh
5.1 Lưu tập lệnh
Đảm bảo tập lệnh được lưu dưới dạng bypass-cloudflare.js.
5.2 Thực thi tập lệnh
Chạy tập lệnh bằng Node.js:
node bypass-cloudflare.js5.3 Đầu ra dự kiến
Nếu mọi thứ được thiết lập chính xác, thiết bị đầu cuối sẽ hiển thị:
Kết nối với Scrapeless
Ảnh chụp màn hình được lưu dưới dạng challenge-bypass.png
Trình duyệt đã đóngTệp challenge-bypass.png sẽ xuất hiện trong thư mục dự án của bạn, xác nhận rằng bảo vệ Cloudflare đã bị bỏ qua thành công.
🌟 Muốn bỏ qua bảo vệ Cloudflare một cách dễ dàng?
🔑 Đăng nhập tại đây và bắt đầu tận dụng các công cụ mạnh mẽ của Trình duyệt Scrapeless ngay hôm nay!
🚀 Cần hướng dẫn chuyên gia? Tham gia cộng đồng Discord của chúng tôi để có những lời khuyên và hỗ trợ khắc phục sự cố độc quyền!
💡 Vươn lên trong việc thu thập dữ liệu web với Trình duyệt Scrapeless—an toàn, nhanh chóng và đáng tin cậy!
Bước 6: Những cân nhắc bổ sung
6.1 Sử dụng Khóa API
-
Đảm bảo Khóa API của bạn hợp lệ và chưa vượt quá hạn ngạch yêu cầu.
-
Không bao giờ để lộ Khóa API của bạn trong các kho lưu trữ công khai (ví dụ: GitHub). Sử dụng biến môi trường để đảm bảo an ninh.
6.2 Cài đặt Proxy
-
Điều chỉnh tham số proxy_country để chọn một vị trí khác (ví dụ: US cho Hoa Kỳ, DE cho Đức).
-
Sử dụng proxy_session_id nhất quán để duy trì cùng một địa chỉ IP trong các yêu cầu.
6.3 Bộ chọn Trang
-
Cấu trúc của các trang web mục tiêu có thể khác nhau, yêu cầu điều chỉnh waitForSelector().
-
Sử dụng page.evaluate() để kiểm tra cấu trúc trang và cập nhật bộ chọn cho phù hợp.
Hướng dẫn này đã cung cấp một phương pháp từng bước để sử dụng Scrapeless và Puppeteer-core để bỏ qua bảo vệ Cloudflare. Bằng cách tận dụng kết nối WebSocket, cài đặt proxy và giám sát phần tử, bạn có thể tự động hóa việc thu thập dữ liệu web một cách hiệu quả mà không bị Cloudflare chặn.
Phần 2: Cách lấy và sử dụng Cookie cf_clearance và Tiêu đề Yêu cầu
Sau khi bỏ qua thách thức Cloudflare thành công, bạn có thể lấy tiêu đề yêu cầu và cookie cf_clearance từ phản hồi trang thành công. Những yếu tố này rất quan trọng để duy trì tính nhất quán của phiên và tránh các thách thức lặp lại.
1. Lấy Cookie cf_clearance
javascript
const cookies = await browser.cookies();
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.value;Mục đích:
-
Mã này lấy tất cả cookie, bao gồm cf_clearance, được Cloudflare cấp sau khi vượt qua thách thức bảo mật của nó.
-
Cookie cf_clearance cho phép các yêu cầu tiếp theo bỏ qua bảo vệ của Cloudflare, giảm nhu cầu về các thách thức lặp lại.
2. Bật chặn Yêu cầu và Chụp Tiêu đề
javascript
await page.setRequestInterception(true);
page.on('request', request => {
// Phù hợp với các yêu cầu trang sau khi vượt qua thách thức Cloudflare
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});Mục đích:
-
Bật chặn yêu cầu (setRequestInterception(true)) để theo dõi và sửa đổi các yêu cầu mạng.
-
Lắng nghe các sự kiện yêu cầu, kích hoạt bất cứ khi nào Puppeteer gửi một yêu cầu mạng.
-
Xác định các yêu cầu thách thức Cloudflare:
-
request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') đảm bảo chỉ có các yêu cầu có liên quan mới bị chặn.
-
request.headers()?.['origin'] giúp xác minh quyền truy cập hợp lệ.
-
Trích xuất và in tiêu đề yêu cầu, sau này có thể được sử dụng để mô phỏng các yêu cầu trình duyệt thực.
-
Tiếp tục yêu cầu (request.continue()) để ngăn chặn gián đoạn trong quá trình tải trang.
🔍 Muốn chụp và sử dụng cookie cf_clearance của Cloudflare một cách hiệu quả?
💪 Đăng nhập ngay để truy cập tất cả các tính năng nâng cao để thu thập dữ liệu mượt mà hơn.
3. Tại sao phải lấy cf_clearance và Tiêu đề?
- Tính nhất quán của Phiên:
-
Cookie cf_clearance cho phép các yêu cầu HTTP tiếp theo bỏ qua các thách thức Cloudflare.
-
Cookie này có thể được sử dụng lại trong nhiều yêu cầu, giảm thiểu các lời nhắc xác minh.
- Mô phỏng các Yêu cầu Trình duyệt Thực:
-
Cloudflare kiểm tra các tiêu đề yêu cầu như User-Agent, Referer và Origin.
-
Việc chụp các tiêu đề từ một yêu cầu thành công đảm bảo rằng các yêu cầu trong tương lai có thể bắt chước lưu lượng truy cập hợp pháp, giảm nguy cơ bị phát hiện.
- Hiệu quả thu thập dữ liệu nâng cao:
- Những chi tiết này có thể được lưu trữ trong cơ sở dữ liệu hoặc tệp và được sử dụng lại, ngăn chặn các thách thức không cần thiết và tối ưu hóa tỷ lệ thành công của yêu cầu.
Bằng cách thực hiện các kỹ thuật này, bạn có thể cải thiện độ tin cậy và hiệu quả của việc thu thập dữ liệu web, bỏ qua các biện pháp bảo mật của Cloudflare một cách hiệu quả. 🚀
Phần 3: Cách bỏ qua Cloudflare Turnstile bằng Trình duyệt Scrapeless
Trong phần này của hướng dẫn, chúng ta sẽ tìm hiểu cách bỏ qua bảo vệ Cloudflare Turnstile bằng Trình duyệt Scrapeless với Puppeteer. Cloudflare Turnstile là một cơ chế bảo mật nâng cao hơn được sử dụng để chặn bot và thu thập dữ liệu tự động. Với sự trợ giúp của Trình duyệt Scrapeless, chúng ta có thể bỏ qua biện pháp bảo vệ này để tương tác với trang web như thể chúng ta là người dùng thực.
Lưu ý:
"Bỏ qua Bảo vệ Cloudflare" và "Bỏ qua Cloudflare Turnstile" nhắm mục tiêu vào các cơ chế bảo mật khác nhau.
- Bỏ qua Bảo vệ Cloudflare bao gồm việc bỏ qua các biện pháp bảo mật Cloudflare chung như CAPTCHA, kiểm tra JavaScript và giới hạn tốc độ IP.
- Bỏ qua Cloudflare Turnstile cụ thể nhắm mục tiêu vào Cloudflare Turnstile, một thách thức chống bot duy nhất đảm bảo sự tương tác của con người, mà không dựa vào CAPTCHA truyền thống. Việc bỏ qua Turnstile đánh bại cơ chế bảo mật cụ thể này.
Bước 1: Mở trang Mục tiêu
Chúng ta sẽ bắt đầu bằng cách mở một trang web được bảo vệ bởi Cloudflare Turnstile, thường yêu cầu xác minh của con người. Dưới đây là mã mở trang web.
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });Mã này sử dụng page.goto() để điều hướng đến trang và chờ cho đến khi nội dung DOM được tải.
Bước 2: Điền thông tin Đăng nhập
Sau khi trang được tải, chúng ta có thể tự động hóa quá trình điền thông tin đăng nhập (như tên người dùng và mật khẩu) để vượt qua trang đăng nhập.
javascript
await page.locator('input[type="email"]').fill('admin@example.com');
await page.locator('input[type="password"]').fill('password');Bước 3: Chờ Turnstile được Mở khóa
Cloudflare Turnstile hoạt động bằng cách đảm bảo rằng chỉ người dùng là người mới có thể tiến hành. Trong bước này, chúng ta sẽ chờ Turnstile được mở khóa bằng cách kiểm tra xem có nhận được phản hồi từ quá trình xác minh Turnstile hay không.
javascript
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});Dòng mã này chờ phản hồi từ window.turnstile.getResponse(), cho biết rằng việc xác minh Turnstile đã được bỏ qua thành công.
💥 Mở khóa nội dung phía sau Cloudflare Turnstile một cách dễ dàng.
🔓 Đăng nhập để có quyền truy cập vào các tính năng thu thập dữ liệu mạnh mẽ.
💬 Tham gia cộng đồng Discord của chúng tôi để được hỗ trợ cá nhân, lời khuyên và hiểu biết của người dùng!
🚀 Tối ưu hóa việc thu thập dữ liệu web của bạn với Trình duyệt Scrapeless—vượt qua mọi rào cản, bao gồm cả những thách thức khó khăn nhất của Cloudflare!
Bước 4: Chụp ảnh màn hình để Xác minh
Để xác nhận rằng việc bỏ qua đã thành công, chúng ta có thể chụp ảnh màn hình trang. Điều này giúp chúng ta xác minh rằng Turnstile đã bị bỏ qua thành công.
javascript
await page.screenshot({ path: 'challenge-bypass-success.png' });Bước 5: Nhấp vào nút Đăng nhập
Sau khi bỏ qua thách thức Turnstile thành công, chúng ta có thể mô phỏng người dùng nhấp vào nút đăng nhập để gửi biểu mẫu.
javascript
await page.locator('button[type="submit"]').click();
await page.waitForNavigation();Mã này nhấp vào nút gửi và chờ trang điều hướng đến trang tiếp theo sau khi đăng nhập.
Bước 6: Chụp ảnh màn hình của Trang tiếp theo
Cuối cùng, sau khi đăng nhập, chúng ta sẽ chụp thêm một ảnh màn hình để xác nhận rằng việc điều hướng đến trang tiếp theo đã thành công.
javascript
await page.screenshot({ path: 'next-page.png' });Ví dụ mã hoàn chỉnh
Đây là mã hoàn chỉnh kết hợp tất cả các bước được nêu ở trên:
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com');
await page.locator('input[type="password"]').fill('password');
// Chờ Turnstile được mở khóa thành công
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
// Chụp ảnh màn hình sau khi bỏ qua
await page.screenshot({ path: 'challenge-bypass-success.png' });
// Nhấp vào nút đăng nhập
await page.locator('button[type="submit"]').click();
await page.waitForNavigation();
// Chụp ảnh màn hình của trang tiếp theo
await page.screenshot({ path: 'next-page.png' });Bằng cách làm theo hướng dẫn này, bạn đã tìm hiểu thành công cách bỏ qua bảo vệ Cloudflare Turnstile bằng Trình duyệt Scrapeless và Puppeteer. Phương pháp này cho phép bạn tương tác với trang web, điền vào biểu mẫu đăng nhập và điều hướng qua nội dung trong khi bỏ qua các cơ chế bảo mật của Cloudflare. Bạn có thể mở rộng kỹ thuật này để hoạt động với các trang web khác được bảo vệ bởi Turnstile.
Sẵn sàng để làm chủ việc Bỏ qua Cloudflare và Thu thập dữ liệu Web với Trình duyệt Scrapeless?
🚀 Mở khóa toàn bộ sức mạnh của Trình duyệt Scrapeless ngay hôm nay và bắt đầu bỏ qua bảo vệ Cloudflare, lấy cookie và tiêu đề, và bỏ qua các thách thức Turnstile một cách dễ dàng!
🔑 Đăng nhập tại đây để truy cập các tính năng độc quyền và bắt đầu thu thập dữ liệu một cách tự tin.
💬 Tham gia cộng đồng Discord của chúng tôi để kết nối với các chuyên gia thu thập dữ liệu khác, nhận được sự trợ giúp khắc phục sự cố và cập nhật với những lời khuyên và thủ thuật mới nhất.
💡 Đừng bỏ lỡ các công cụ và hiểu biết mạnh mẽ để đưa việc thu thập dữ liệu web của bạn lên cấp độ tiếp theo với Trình duyệt Scrapeless.
Kết luận
Việc bỏ qua bảo mật Cloudflare thành công đòi hỏi các công cụ và chiến lược phù hợp. Với Trình duyệt Scrapeless, bạn có thể dễ dàng điều hướng các biện pháp phòng thủ của Cloudflare, lấy cookie và tiêu đề cần thiết và vượt qua thách thức Turnstile mà không cần can thiệp thủ công.
🔑 Đăng ký ngay và đưa việc thu thập dữ liệu web của bạn lên cấp độ tiếp theo!
💬 Cần trợ giúp? Tham gia cộng đồng Discord của chúng tôi để nhận được những hiểu biết chuyên gia, hỗ trợ khắc phục sự cố và luôn đi trước các kỹ thuật thu thập dữ liệu web mới nhất.
Đừng để Cloudflare làm chậm bạn lại—mở khóa việc thu thập dữ liệu liền mạch ngay hôm nay!
Câu hỏi thường gặp: Bỏ qua Cloudflare, Cookie cf_clearance và Thách thức Turnstile
1. Bảo vệ Cloudflare là gì và tại sao nó chặn các chương trình thu thập dữ liệu web?
Bảo vệ Cloudflare là một dịch vụ bảo mật phát hiện và giảm thiểu lưu lượng truy cập tự động. Nó sử dụng các kỹ thuật như CAPTCHA, thách thức JavaScript và giới hạn tốc độ IP để ngăn chặn bot truy cập nội dung được bảo vệ.
2. cf_clearance là gì và nó giúp bỏ qua Cloudflare như thế nào?
Cookie cf_clearance được cấp sau khi vượt qua một thách thức Cloudflare thành công. Nó cho phép một phiên trình duyệt duy trì xác minh trong một khoảng thời gian cụ thể, ngăn chặn các thách thức tiếp theo. Bằng cách lấy và sử dụng lại cookie này, các chương trình thu thập dữ liệu có thể duy trì quyền truy cập không bị gián đoạn.
3. Cloudflare Turnstile khác với bảo vệ Cloudflare tiêu chuẩn như thế nào?
Cloudflare Turnstile là một thách thức nâng cao được thiết kế để xác minh sự hiện diện của con người mà không cần CAPTCHA truyền thống. Nó sử dụng phân tích hành vi và các kỹ thuật xác minh khác để chặn bot. Việc bỏ qua Turnstile đòi hỏi các quy trình tự động hóa bắt chước sự tương tác của người dùng thực.
4. Sử dụng Trình duyệt Scrapeless để bỏ qua Cloudflare có hợp pháp không?
Tính hợp pháp của việc bỏ qua Cloudflare phụ thuộc vào điều khoản dịch vụ và quy định địa phương của trang web. Luôn đảm bảo rằng hoạt động thu thập dữ liệu của bạn tuân thủ chính sách của trang web và luật hiện hành.
5. Làm thế nào để tôi bắt đầu sử dụng Trình duyệt Scrapeless để bỏ qua Cloudflare?
Bạn có thể bắt đầu bằng cách đăng nhập vào Trình duyệt Scrapeless và làm theo các bước trong hướng dẫn này để triển khai các giải pháp bỏ qua tự động.
6. Tôi có thể nhận được hỗ trợ cho Trình duyệt Scrapeless ở đâu?
Tham gia cộng đồng Discord của chúng tôi để kết nối với các nhà phát triển khác, nhận được sự trợ giúp khắc phục sự cố và cập nhật với các tính năng và phương pháp tốt nhất mới.
Tài nguyên khác
Cách bỏ qua Cloudflare bằng Puppeteer
Tìm hiểu cách sử dụng Puppeteer để bỏ qua các biện pháp bảo vệ của Cloudflare và truy cập nội dung web mà không kích hoạt các thách thức bảo mật.
Cách sử dụng Undetected ChromeDriver để thu thập dữ liệu Web
Khám phá các kỹ thuật sử dụng một phiên bản Undetected ChromeDriver để tránh bị phát hiện trong khi thu thập dữ liệu các trang web.
Cách thu thập dữ liệu Giá khách sạn Google bằng Node.js
Hướng dẫn từng bước về việc thu thập dữ liệu giá khách sạn Google bằng Node.js và xử lý các cơ chế chống bot một cách hiệu quả.
Cách thu thập dữ liệu Báo giá cổ phiếu Google Finance bằng Python
Một hướng dẫn dựa trên Python về việc trích xuất báo giá cổ phiếu Google Finance, bao gồm cả việc xử lý dữ liệu được hiển thị bằng JavaScript.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


