
Cách vượt qua CAPTCHA khi quét web bằng Python
Advanced Bot Mitigation Engineer
Giới thiệu
Ít người biết dạng đầy đủ của CAPTCHA là gì.
Trên thực tế, CAPTCHA viết tắt là viết tắt của "Kiểm tra Turing công cộng hoàn toàn tự động để phân biệt máy tính và con người".
CAPTCHA được thiết kế để xác định những người dùng có vấn đề và các bot hiện đại bằng cách đưa ra các vấn đề khó giải quyết cho máy tính, giúp chủ sở hữu trang web ngăn chặn việc thu thập thông tin và thu thập dữ liệu. Do có số lượng lớn thư viện của bên thứ ba có thể đọc văn bản, tương tác với các biểu mẫu HTML và loại bỏ các cấu trúc HTML phức tạp, Python là một lựa chọn phổ biến để quét web. Vì vậy, trong bài viết này, chúng tôi sẽ giải thích cách khắc phục các sự cố CAPTCHA trong quá trình quét web bằng Python.
Ngoài việc thảo luận về các giải pháp chống CAPTCHA thực tế để kết hợp vào quy trình thu thập dữ liệu của bạn, chúng tôi sẽ đề cập đến các loại CAPTCHA khác nhau có thể tìm thấy trong môi trường trực tuyến ngày nay.
reCAPTCHA
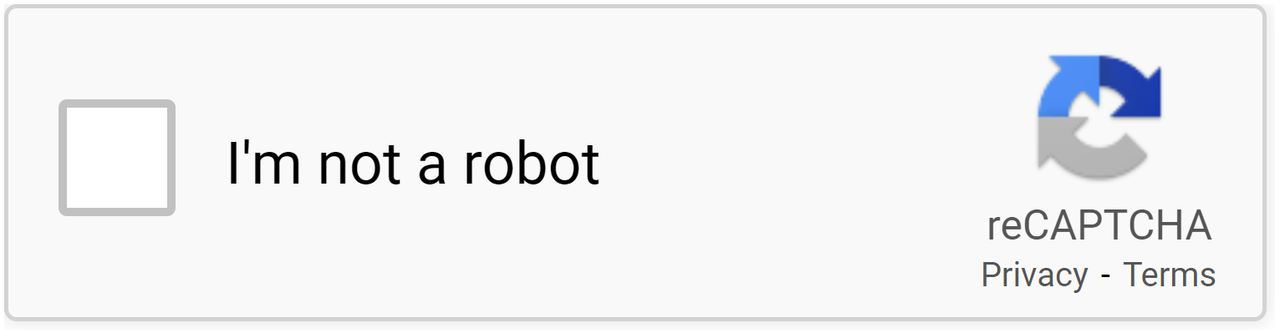
Đây là giải pháp CAPTCHA miễn phí do Google phát triển nhằm cung cấp khả năng bảo mật cho trang web, sử dụng các phương pháp tiên tiến để xác định hành vi giống bot, giống như hCAPTCHA. Google reCAPTCHA hiện có thể xác định người dùng mà không cần bất kỳ thông tin đầu vào nào từ người dùng. Nó chỉ sử dụng trải nghiệm trong quá khứ của người dùng với các trang web khác làm cơ sở để công nhận. Google Tìm kiếm, Maps, Play, Mua sắm và nhiều dịch vụ cũng như sản phẩm khác sử dụng reCAPTCHA một cách rộng rãi.
ImageToText CAPTCHA

Thông thường, ImageToText CAPTCHA là một tập hợp các chữ cái và ký tự không liên quan được hiển thị theo kiểu khó đọc, với các ký tự đã được xoay, thay đổi kích thước và biến dạng theo nhiều cách khác nhau.
Âm thanh CAPTCHA
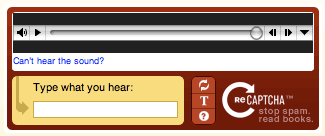
Còn được gọi là "CAPTCHA dựa trên âm thanh", nó yêu cầu người dùng nhập một loạt chữ cái hoặc số thông qua bản ghi âm. Để khiến mọi việc trở nên khó khăn hơn, âm thanh thường được bổ sung bằng tiếng ồn xung quanh.
##hCAPTCHA
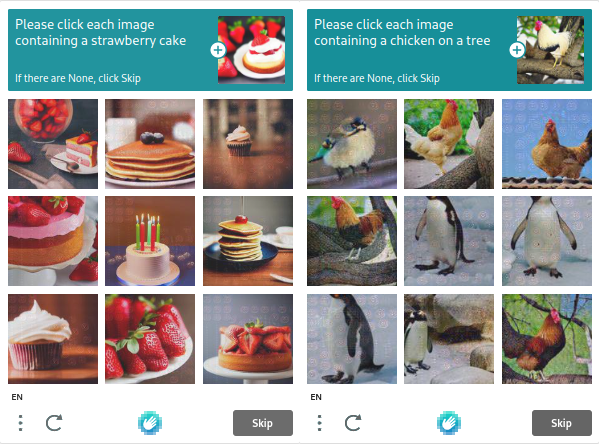
Intuition Machines là chủ sở hữu của hCaptcha, coi trọng quyền riêng tư của người dùng và không thu thập dữ liệu không cần thiết. Kết quả là, mức độ phổ biến của nó ngày càng tăng. Các tác vụ đánh giá bot tiêu chuẩn, chẳng hạn như kiểm tra hộp và nhận dạng hình ảnh, được thực hiện bằng hCaptcha. Các bài kiểm tra trong hCaptcha phức tạp hơn so với các bài kiểm tra trong reCAPTCHA, nhưng bạn có thể thay đổi các tham số để làm cho chúng khó hơn hoặc dễ hơn.
Quét web: Nó là gì?
Kỹ thuật lấy dữ liệu từ các trang web được gọi là quét web. Nó đòi hỏi việc sử dụng các thiết bị tự động để trích xuất dữ liệu từ các trang web, đôi khi được gọi là trình thu thập dữ liệu hoặc trình thu thập dữ liệu web. Các chương trình này di chuyển qua hệ thống phân cấp của trang web, lấy mã HTML và sau đó sử dụng các mẫu hoặc nguyên tắc được xác định trước để trích xuất dữ liệu cần thiết.
Có một số cách sử dụng để quét web, bao gồm:
- Phân tích đối thủ cạnh tranh: theo dõi sự hiện diện và chiến thuật internet của đối thủ
- Thu thập dữ liệu: Tổng hợp văn bản, hình ảnh và các nội dung media khác từ các trang web
- Giám sát giá: theo dõi và đối chiếu chi phí sản phẩm từ các nhà cung cấp dịch vụ trực tuyến khác nhau
- Tổng hợp tài liệu: Tạo cơ sở dữ liệu hoặc trang web hợp nhất bằng cách thu thập tài liệu từ nhiều nguồn
- Nghiên cứu thị trường: Để hiểu được động lực thị trường, xu hướng, phản hồi của người tiêu dùng và các dữ liệu thích hợp khác được phân tích.
Đáng chú ý là việc thu thập dữ liệu trên web, mặc dù là một công cụ hữu hiệu để thu thập dữ liệu, nhưng phải được thực hiện một cách có đạo đức và hợp pháp. Việc thu thập thông tin riêng tư hoặc nhạy cảm có thể là vi phạm pháp luật và một số trang web có quy định cấm rõ ràng đối với hành vi này trong điều khoản dịch vụ của họ. Khi tham gia các hoạt động thu thập dữ liệu trực tuyến, hãy đảm bảo rằng bạn luôn tuân thủ các điều kiện sử dụng của trang web và mọi luật hiện hành.
Ví dụ về Quét Web
Quét web là quá trình lấy dữ liệu từ các trang web, thường là tự động bằng cách sử dụng các công cụ hoặc tập lệnh lập trình. Đây là một ví dụ cơ bản sử dụng gói BeautifulSoup, một tùy chọn phổ biến cho các hoạt động quét web và Python.
Giả sử hiện tại chúng ta muốn lấy tên của các bài báo gần đây nhất từ một nguồn tin tức tưởng tượng. Cấu trúc của HTML có thể giống như sau:
language
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Sample News Website</title>
</head>
<body>
<div class="article">
<h2 class="title">Breaking News 1</h2>
<p class="content">This is the content of the first article.</p>
</div>
<div class="article">
<h2 class="title">Latest Update: Important Event</h2>
<p class="content">Details about the important event.</p>
</div>
</body>
</html>Bây giờ chúng ta hãy sử dụng BeautifulSoup và Python để lấy tiêu đề của các bài viết này:
language
import requests
from bs4 import BeautifulSoup
# URL of the sample news website
url = 'https://www.example-news-website.com'
# Send a GET request to the website
response = requests.get(url)
# Parse the HTML content of the page
soup = BeautifulSoup(response.text, 'html.parser')
# Find all div elements with the class 'article' and extract the titles
article_divs = soup.find_all('div', class_='article')
# Extract and print the titles
for article_div in article_divs:
title = article_div.find('h2', class_='title').text
print(f"Title: {title}")Để có được nội dung HTML, chúng tôi sử dụng thư viện yêu cầu để thực hiện yêu cầu GET tới trang web. Tiếp theo, BeautifulSoup được sử dụng để phân tích nội dung HTML ('html.parser' được sử dụng trong trường hợp này). Để khám phá mọi phần tử div có bài viết trong lớp, chúng tôi sử dụng find_all. Chúng tôi định vị phần tử h2 bằng tiêu đề lớp cho mỗi bài viết và truy xuất nội dung văn bản của nó.
Cách sử dụng Scrapeless để vượt qua CAPTCHA khi quét web
Bạn đã chán ngấy với các khối quét web liên tục và CAPTCHA?
Giới thiệu Scrapeless - giải pháp quét web tất cả trong một tối ưu!
Khai thác toàn bộ tiềm năng trích xuất dữ liệu của bạn bằng bộ công cụ mạnh mẽ của chúng tôi:
Trình giải CAPTCHA tốt nhất
Tự động giải mã CAPTCHA nâng cao, giúp quá trình quét của bạn diễn ra suôn sẻ và không bị gián đoạn.
Trải nghiệm sự khác biệt - dùng thử miễn phí!
Nhận xét kết luận
Một trong những trở ngại thường gặp nhất đối với việc thu thập dữ liệu công khai là CAPTCHA, do đó, điều quan trọng là phải tìm ra một phương pháp đáng tin cậy và ưu việt để vượt qua chúng. Bài viết này đề cập đến các loại CAPTCHA khác nhau hiện có và cung cấp một số giải pháp chống CAPTCHA mà bạn có thể thử sử dụng trong các hoạt động Quét Web của mình.
Vui lòng sử dụng Trang web chính thức của chúng tôi để liên hệ với chúng tôi nếu bạn có bất kỳ thắc mắc nào liên quan đến chủ đề này hoặc muốn biết thêm thông tin về các cách tốt nhất của Scrapeless để sử dụng CAPTCHA, chẳng hạn như Trình mở khóa web hoặc Trình giải mã CAPTCHA.
FAQ
Làm cách nào để tránh CAPTCHA khi Quét Web?
Khi thu thập dữ liệu web, có nhiều kỹ thuật để xử lý CAPTCHA. Một thủ thuật hữu ích là tinh chỉnh dấu vân tay của máy cạo bằng cách sửa đổi tiêu đề Tác nhân người dùng. Hơn nữa, bạn có thể muốn nghĩ đến việc sử dụng các chương trình tự động như WebUnlocker, chương trình này có thể giúp bạn giải quyết các vấn đề về CAPTCHA.
Tại sao chủ sở hữu trang web sử dụng CAPTCHA để ngăn chặn việc thu thập dữ liệu?
CAPTCHA được sử dụng trên các trang web để phân biệt giữa bot nguy hiểm và khách truy cập thực sự. Chúng đóng vai trò như một biện pháp an toàn để ngăn chặn hành vi thù địch hoặc có khả năng phá hoại của bot, chẳng hạn như gửi thư rác hoặc giao dịch gian lận.
Có phương pháp nào để vượt qua CAPTCHA khi quét web không?
Có, có rất nhiều dịch vụ hiện có trên thị trường được thiết kế đặc biệt để vượt qua CAPTCHA. Các ví dụ bao gồm Trình mở khóa web và trình giải mã CAPTCHA. Ví dụ: công cụ của Scrapeless chọn bộ tiêu đề, cookie, thuộc tính trình duyệt, v.v. thích hợp để xuất hiện với tư cách là người dùng hợp pháp và cuối cùng vượt qua tất cả các rào cản của trang web mục tiêu.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


