
Cách Xây Dựng Quy Trình Tạo Dẫn B2B Thông Minh với n8n và Scrapeless
Advanced Data Extraction Specialist
Chuyển đổi công việc tìm kiếm khách hàng của bạn với một quy trình tự động hóa tìm, đủ điều kiện và làm giàu các khách hàng tiềm năng B2B bằng cách sử dụng Google Search, Crawler và phân tích AI Claude. Hướng dẫn này sẽ hướng dẫn bạn cách tạo một hệ thống tạo khách hàng tiềm năng mạnh mẽ bằng cách sử dụng n8n và Scrapeless.
Những gì chúng ta sẽ xây dựng
Trong hướng dẫn này, chúng ta sẽ tạo ra một quy trình tạo khách hàng tiềm năng B2B thông minh mà:
- Tự động kích hoạt theo lịch trình hoặc thủ công
- Tìm kiếm trên Google các công ty trong thị trường mục tiêu của bạn bằng Scrapeless
- Xử lý từng URL công ty một cách riêng biệt với Danh sách Mục
- Thu thập thông tin chi tiết từ các trang web công ty
- Sử dụng AI Claude để đủ điều kiện và cấu trúc dữ liệu khách hàng tiềm năng
- Lưu trữ các khách hàng tiềm năng đủ điều kiện trong Google Sheets
- Gửi thông báo tới Discord (có thể điều chỉnh cho Slack, email, v.v.)
Điều kiện tiên quyết
- Một实例 n8n (đám mây hoặc tự lưu trữ)
- Một khóa API Scrapeless (nhận một cái tại scrapeless.com)
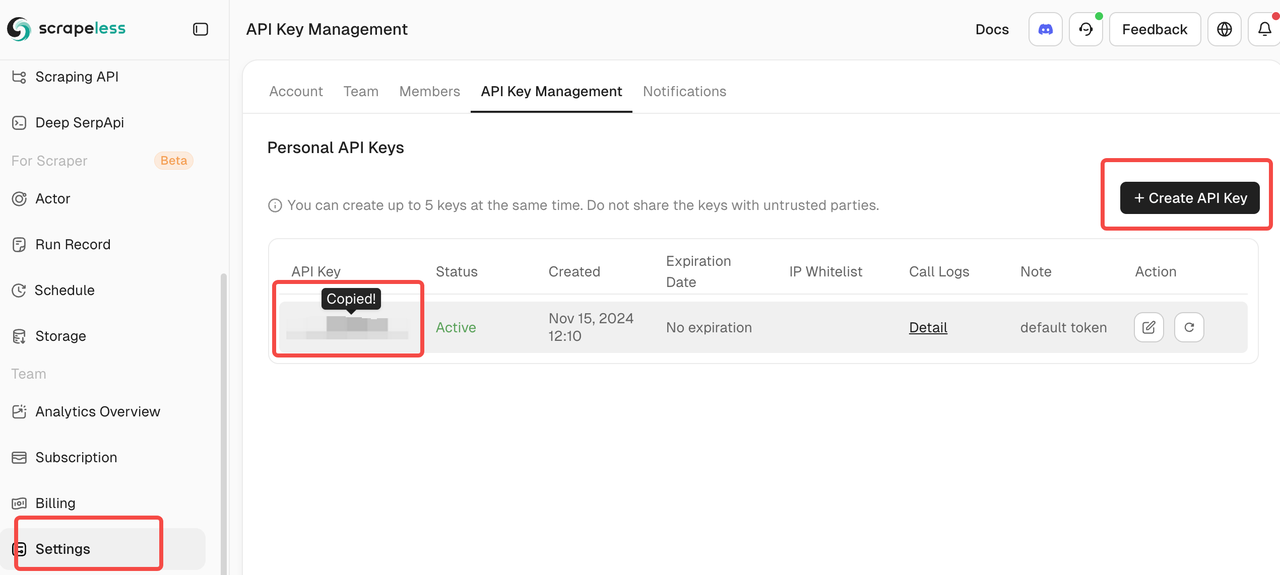
Bạn chỉ cần đăng nhập vào Bảng Điều Khiển Scrapeless và làm theo hình ảnh dưới đây để nhận KHÓA API của bạn. Scrapeless sẽ cung cấp cho bạn một quy mô dùng thử miễn phí.
- Khóa API Claude từ Anthropic
- Quyền truy cập Google Sheets
- URL webhook Discord (hoặc dịch vụ thông báo tùy chọn của bạn)
- Hiểu biết cơ bản về quy trình làm việc n8n
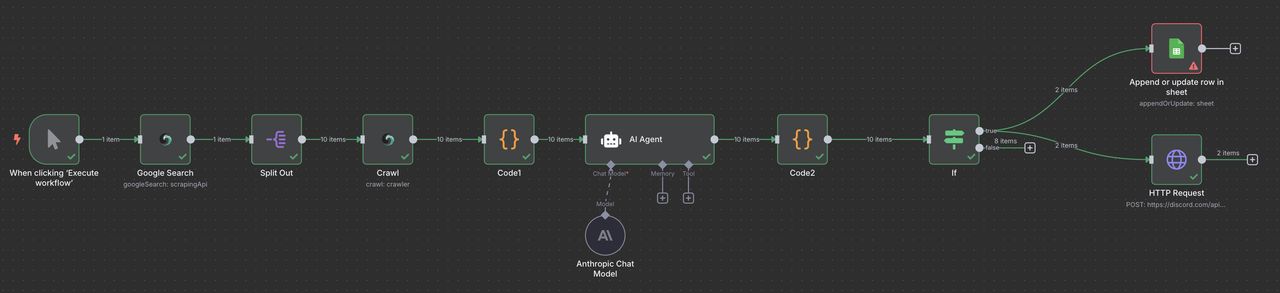
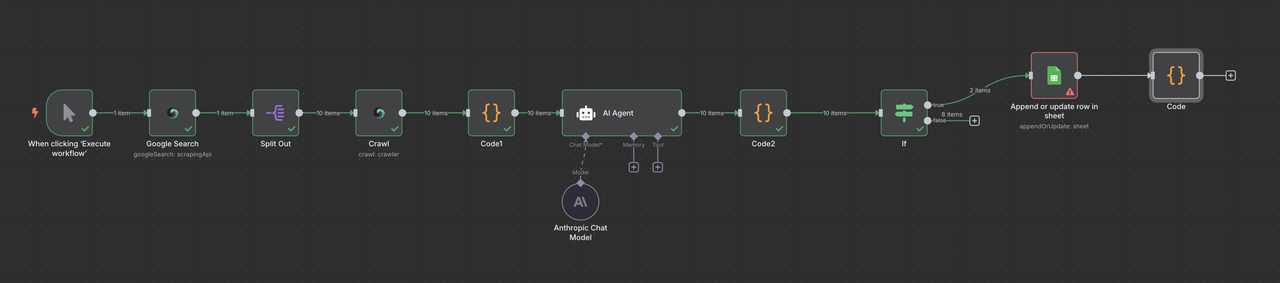
Tổng quan quy trình hoàn chỉnh
Quy trình n8n cuối cùng của bạn sẽ trông như thế này:
Kích hoạt Thủ công → Tìm kiếm Google Scrapeless → Danh sách Mục → Crawler Scrapeless → Mã (Xử lý Dữ liệu) → AI Claude → Mã (Phân tích Phản hồi) → Bộ lọc → Google Sheets hoặc/ và Webhook Discord
Bước 1: Thiết lập Kích hoạt Thủ công
Chúng ta sẽ bắt đầu với một kích hoạt thủ công để thử nghiệm, sau đó thêm lịch trình sau.
- Tạo một quy trình làm việc mới trong n8n
- Thêm một nút Kích hoạt Thủ công làm điểm khởi đầu của bạn
- Điều này cho phép bạn thử nghiệm quy trình trước khi tự động hóa nó
Tại sao lại bắt đầu thủ công?
- Kiểm tra và gỡ lỗi từng bước
- Xác minh chất lượng dữ liệu trước khi tự động hóa
- Điều chỉnh các tham số dựa trên kết quả ban đầu
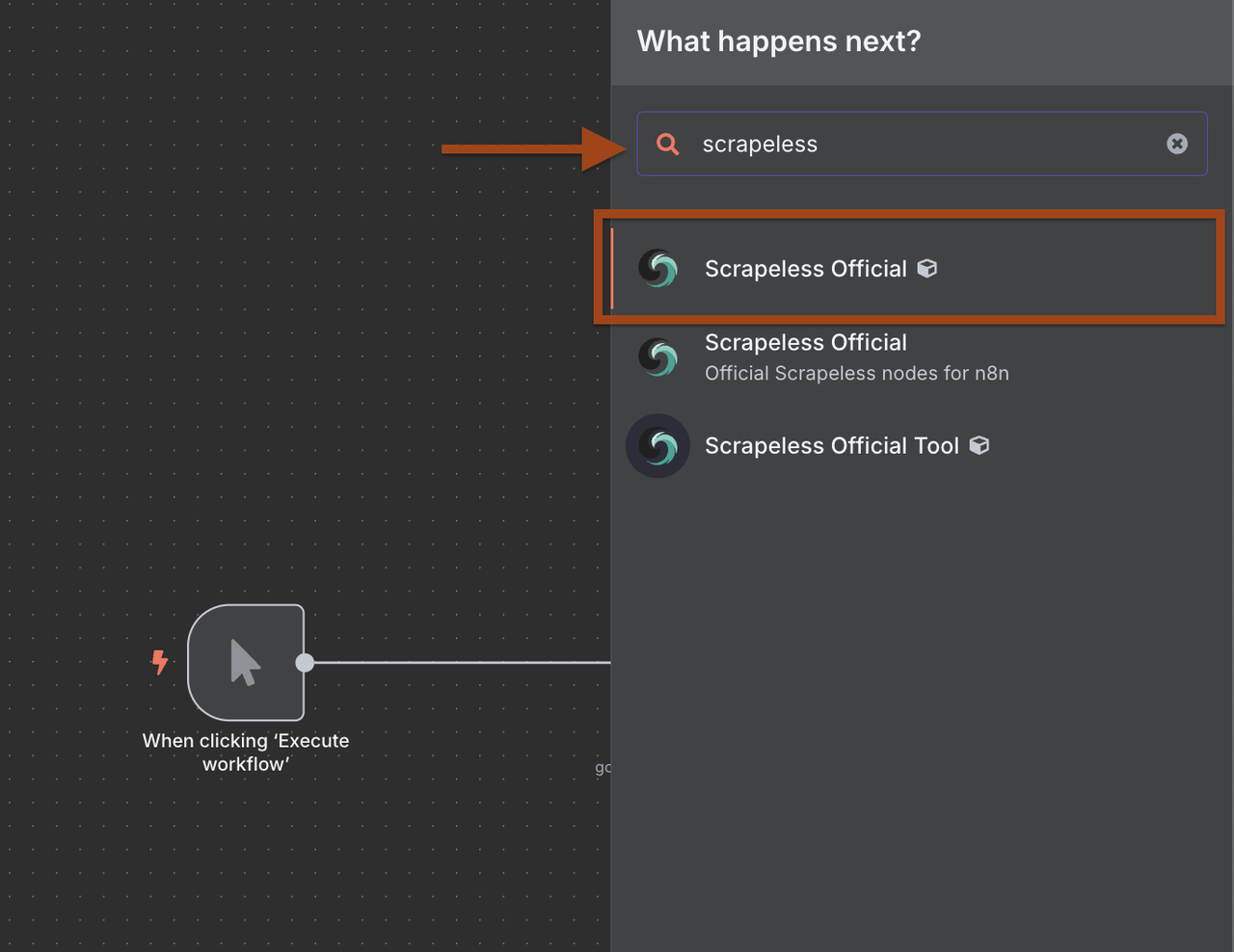
Bước 2: Thêm Tìm kiếm Google Scrapeless
Bây giờ chúng ta sẽ thêm nút Tìm kiếm Google Scrapeless để tìm các công ty mục tiêu.
- Nhấp vào + để thêm một nút mới sau khi kích hoạt
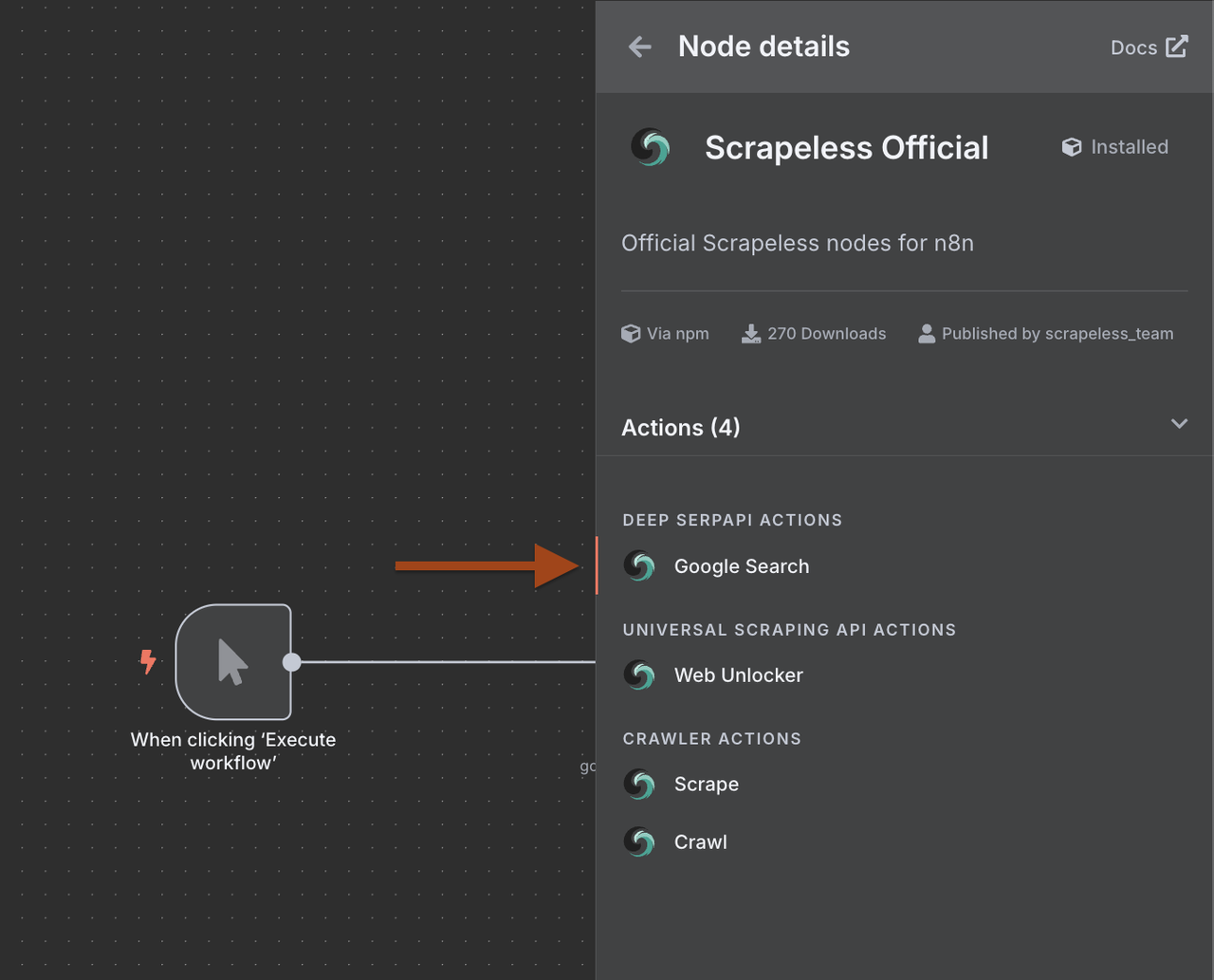
- Tìm Scrapeless trong thư viện nút
- Chọn Scrapeless và chọn thao tác Tìm kiếm Google
1. Tại sao nên sử dụng Scrapeless với n8n?
Tích hợp Scrapeless với n8n cho phép bạn tạo ra những trình thu thập dữ liệu web tiên tiến, linh hoạt mà không cần viết mã.
Lợi ích bao gồm:
- Truy cập Deep SerpApi để lấy và trích xuất dữ liệu SERP Google với một yêu cầu duy nhất.
- Sử dụng Universal Scraping API để vượt qua các hạn chế và truy cập bất kỳ trang web nào.
- Sử dụng Crawler Scrape để thực hiện việc thu thập chi tiết các trang riêng lẻ.
- Sử dụng Crawler Crawl để thu thập dữ liệu một cách đệ quy và truy xuất dữ liệu từ tất cả các trang liên kết.
Các tính năng này cho phép bạn xây dựng các luồng dữ liệu từ đầu đến cuối liên kết Scrapeless với hơn 350 dịch vụ được hỗ trợ bởi n8n, bao gồm Google Sheets, Airtable, Notion, Slack và nhiều hơn nữa.
2. Cấu hình Nút Tìm kiếm Google
Tiếp theo, chúng ta cần cấu hình Nút Tìm kiếm Google Scrapeless
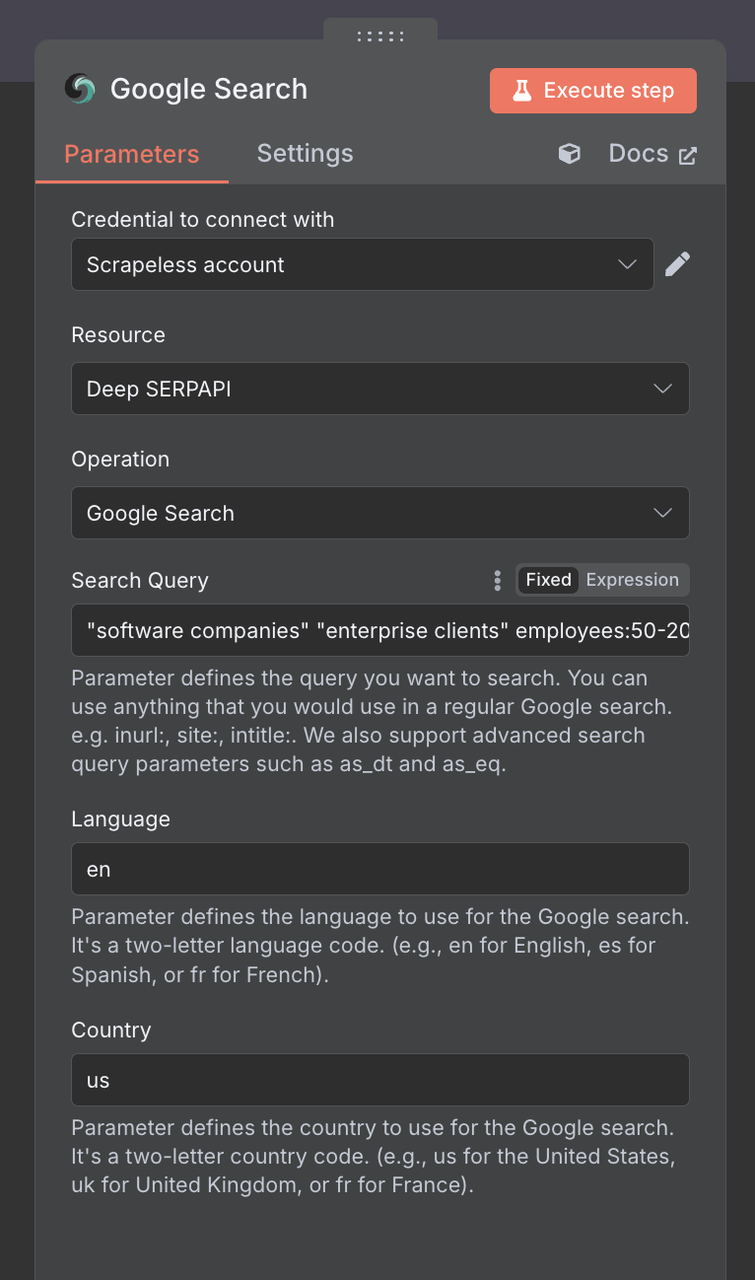
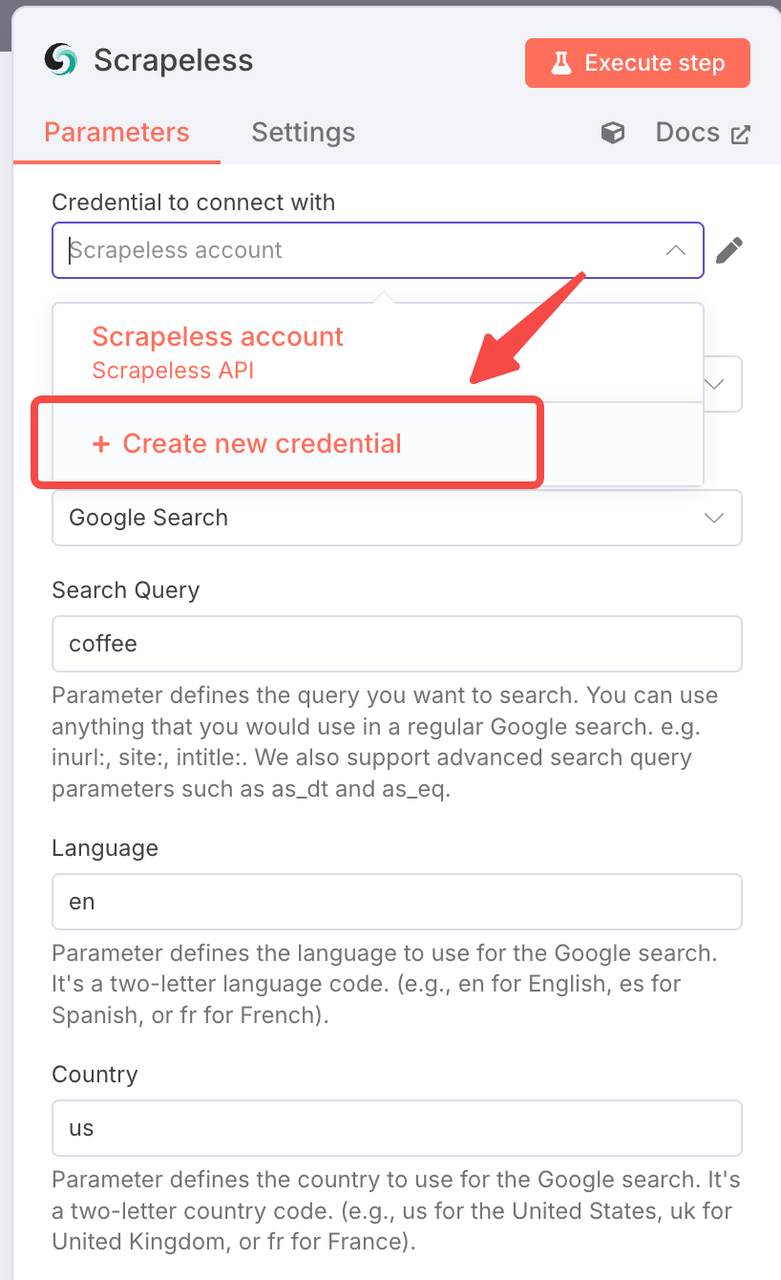
Thiết lập Kết nối:
- Tạo một kết nối với khóa API Scrapeless của bạn
- Nhấp vào "Thêm" và nhập thông tin xác thực của bạn
Tham số Tìm kiếm:
Câu truy vấn tìm kiếm: Sử dụng các thuật ngữ tìm kiếm tập trung vào B2B:
"Các công ty phần mềm" "khách hàng doanh nghiệp" nhân viên:50-200
"Các công ty marketing" "dịch vụ B2B" "chuyển đổi số"
"Các công ty khởi nghiệp SaaS" "Series A" "được đầu tư mạo hiểm"
"Các công ty sản xuất" "giải pháp số" ISOQuốc gia: Mỹ (hoặc thị trường mục tiêu của bạn)
Ngôn ngữ: en
Chiến lược Tìm kiếm B2B Chuyên nghiệp:
- Nhắm mục tiêu kích thước công ty: nhân viên:50-200, "trung bình - thị trường"
- Giai đoạn tài trợ: "Series A", "được đầu tư mạo hiểm", "tự tài trợ"
- Ngành cụ thể: "fintech", "healthtech", "edtech"
- Địa lý: "New York", "San Francisco", "London"
Bước 3: Xử lý Kết quả với Danh sách Mục
Tìm kiếm Google trả về một mảng kết quả. Chúng ta cần xử lý từng công ty một cách riêng biệt.
- Thêm một nút Danh sách Mục sau tìm kiếm Google
- Điều này sẽ tách các kết quả tìm kiếm thành các mục riêng lẻ
Tips : Chạy nút Tìm kiếm Google
1. Cấu hình Danh sách Mục:
- Tác vụ: "Tách Mục"
- Trường để Tách: organic_results - Liên kết
- Bao gồm Dữ liệu Nhị phân: sai
Điều này tạo ra một nhánh thực hiện riêng biệt cho mỗi kết quả tìm kiếm, cho phép xử lý song song.
Bước 4: Thêm Trình thu thập thông tin Scrapeless
Bây giờ chúng ta sẽ thu thập từng trang web công ty để trích xuất thông tin chi tiết.
- Thêm một nút Scrapeless khác
- Chọn tác vụ Thu thập (không phải WebUnlocker)
Sử dụng Trình thu thập để thu thập lặp lại và lấy dữ liệu từ tất cả các trang liên kết.
- Cấu hình để trích xuất dữ liệu công ty
1. Cấu hình Trình thu thập
- Kết nối: Sử dụng cùng một kết nối Scrapeless
- URL: {{ $json.link }}
- Độ sâu thu thập: 2 (trang chính + một cấp độ sâu)
- Số trang tối đa: 5 (giới hạn để xử lý nhanh hơn)
- Bao gồm Mẫu: about|contact|team|company|services
- Loại trừ Mẫu: blog|news|careers|privacy|terms
- Định dạng: markdown (dễ dàng cho việc xử lý AI)
2. Tại sao sử dụng Trình thu thập so với Web Unlocker?
- Trình thu thập lấy nhiều trang và dữ liệu có cấu trúc
- Tốt hơn cho B2B nơi thông tin liên hệ có thể xuất hiện trên các trang /about hoặc /contact
- Thông tin công ty toàn diện hơn
- Theo dõi cấu trúc trang web một cách thông minh
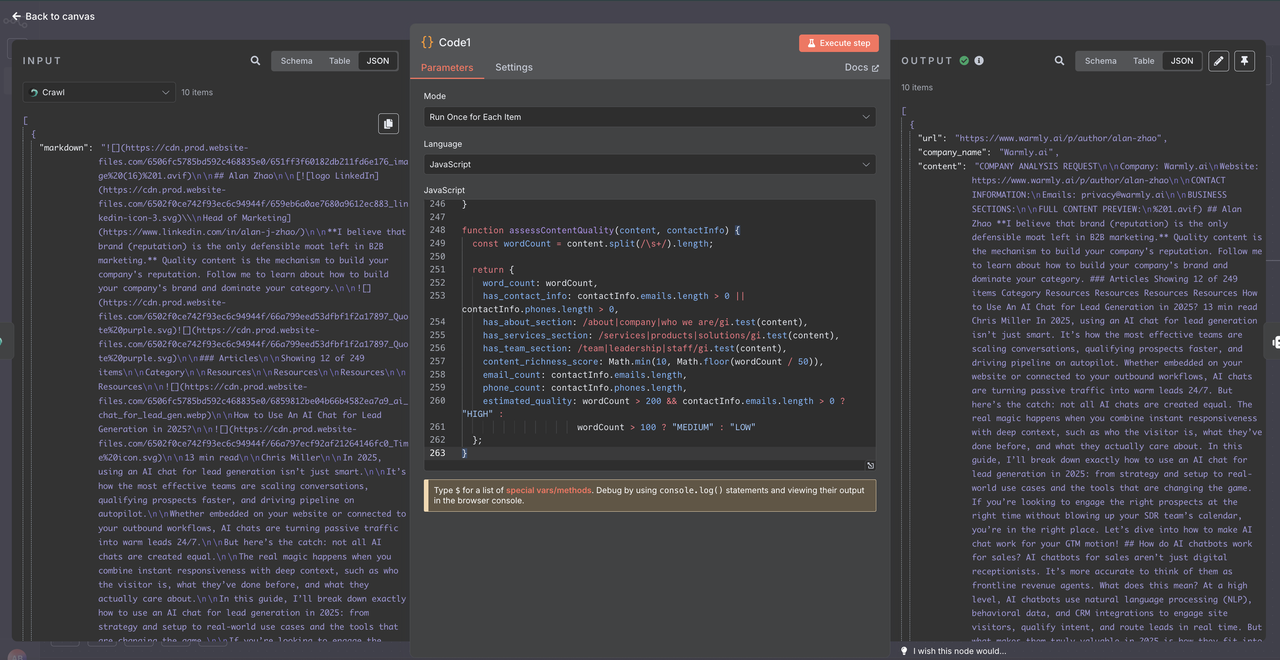
Bước 5: Xử lý Dữ liệu với Nút Mã
Trước khi gửi dữ liệu đã thu thập cho Claude AI, chúng ta cần làm sạch và cấu trúc nó một cách hợp lý. Trình thu thập thông tin Scrapeless trả về dữ liệu ở định dạng cụ thể yêu cầu việc phân tích tỉ mỉ.
- Thêm một nút Mã sau Trình thu thập Scrapeless
- Sử dụng JavaScript để phân tích và làm sạch dữ liệu thu thập thô
- Điều này đảm bảo chất lượng dữ liệu nhất quán cho phân tích AI
1. Hiểu cấu trúc dữ liệu của Trình thu thập Scrapeless
Trình thu thập Scrapeless trả về dữ liệu dưới dạng mảng các đối tượng, không phải là một đối tượng đơn:
[
{
"markdown": "# Trang Chủ Công Ty\n\nChào mừng đến với công ty của chúng tôi...",
"metadata": {
"title": "Tên Công Ty - Trang Chủ",
"description": "Mô tả công ty",
"sourceURL": "https://company.com"
}
}
]2. Cấu hình Nút Mã
console.log("=== ĐANG XỬ LÝ DỮ LIỆU TRÌNH THU THẬP SCRAPELESS ===");
try {
// Dữ liệu đến dưới dạng một mảng
const crawlerDataArray = $json;
console.log("Loại dữ liệu:", typeof crawlerDataArray);
console.log("Có phải là mảng:", Array.isArray(crawlerDataArray));
console.log("Độ dài mảng:", crawlerDataArray?.length || 0);
// Kiểm tra xem mảng có rỗng không
if (!Array.isArray(crawlerDataArray) || crawlerDataArray.length === 0) {
console.log("❌ Dữ liệu thu thập rỗng hoặc không hợp lệ");
return {
url: "không xác định",
company_name: "Không có Dữ liệu",
content: "",
error: "Phản hồi thu thập rỗng",
processing_failed: true,
skip_reason: "Không có dữ liệu được trả về từ trình thu thập"
};
}
// Lấy phần tử đầu tiên từ mảng
const crawlerResponse = crawlerDataArray[0];
// Trích xuất nội dung markdown
const markdownContent = crawlerResponse?.markdown || "";
// Trích xuất metadata (nếu có)
const metadata = crawlerResponse?.metadata || {};
// Thông tin cơ bản
const sourceURL = metadata.sourceURL || metadata.url || extractURLFromContent(markdownContent);
const companyName = metadata.title || metadata.ogTitle || extractCompanyFromContent(markdownContent);
const description = metadata.description || metadata.ogDescription || "";
console.log(`Đang xử lý: ${companyName}`);
console.log(`URL: ${sourceURL}`);
console.log(`Độ dài nội dung: ${markdownContent.length} ký tự`);
// Xác minh chất lượng nội dung
vi
if (!markdownContent || markdownContent.length < 100) {
return {
url: sourceURL,
company_name: companyName,
content: "",
error: "Nội dung từ trình thu thập không đủ",
processing_failed: true,
raw_content_length: markdownContent.length,
skip_reason: "Nội dung quá ngắn hoặc trống"
};
}
// Làm sạch và cấu trúc nội dung markdown
let cleanedContent = cleanMarkdownContent(markdownContent);
// Trích xuất thông tin liên hệ
const contactInfo = extractContactInformation(cleanedContent);
// Trích xuất các phần quan trọng của doanh nghiệp
const businessSections = extractBusinessSections(cleanedContent);
// Xây dựng nội dung cho Claude AI
const contentForAI = buildContentForAI({
companyName,
sourceURL,
description,
businessSections,
contactInfo,
cleanedContent
});
// Đánh giá chất lượng nội dung
const contentQuality = assessContentQuality(cleanedContent, contactInfo);
const result = {
url: sourceURL,
company_name: companyName,
content: contentForAI,
raw_content_length: markdownContent.length,
processed_content_length: contentForAI.length,
extracted_emails: contactInfo.emails,
extracted_phones: contactInfo.phones,
content_quality: contentQuality,
metadata_info: {
has_title: !!metadata.title,
has_description: !!metadata.description,
site_name: metadata.ogSiteName || "",
page_title: metadata.title || ""
},
processing_timestamp: new Date().toISOString(),
processing_status: "THÀNH CÔNG"
};
console.log(`✅ Xử lý thành công ${companyName}`);
return result;
} catch (error) {
console.error("❌ Lỗi khi xử lý dữ liệu từ trình thu thập:", error);
return {
url: "không xác định",
company_name: "Lỗi xử lý",
content: "",
error: error.message,
processing_failed: true,
processing_timestamp: new Date().toISOString()
};
}
// ========== CÁC HÀM TIỆN ÍCH ==========
function extractURLFromContent(content) {
// Cố gắng trích xuất URL từ nội dung markdown
const urlMatch = content.match(/https?:\/\/[^\s\)]+/);
return urlMatch ? urlMatch[0] : "không xác định";
}
function extractCompanyFromContent(content) {
// Cố gắng trích xuất tên công ty từ nội dung
const titleMatch = content.match(/^#\s+(.+)$/m);
if (titleMatch) return titleMatch[1];
// Tìm kiếm email để trích xuất miền
const emailMatch = content.match(/@([a-zA-Z0-9.-]+\.[a-zA-Z]{2,})/);
if (emailMatch) {
const domain = emailMatch[1].replace('www.', '');
return domain.split('.')[0].charAt(0).toUpperCase() + domain.split('.')[0].slice(1);
}
return "Công ty không xác định";
}
function cleanMarkdownContent(markdown) {
return markdown
// Xóa các phần tử điều hướng
.replace(/^\[Bỏ qua nội dung\].*$/gmi, '')
.replace(/^\[.*\]\(#.*\)$/gmi, '')
// Xóa các liên kết markdown nhưng giữ lại văn bản
.replace(/\[([^\]]+)\]\([^)]+\)/g, '$1')
// Xóa hình ảnh và base64
.replace(/!\[([^\]]*)\]\([^)]*\)/g, '')
.replace(/<Base64-Image-Removed>/g, '')
// Xóa các đề cập đến cookie/riêng tư
.replace(/.*?(cookie|chính sách bảo mật|điều khoản dịch vụ).*?\n/gi, '')
// Làm sạch các khoảng trắng
.replace(/\s+/g, ' ')
// Xóa nhiều dòng trống
.replace(/\n\s*\n\s*\n/g, '\n\n')
.trim();
}
function extractContactInformation(content) {
// Regex để tìm email
const emailRegex = /[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}/g;
// Regex để tìm số điện thoại (hỗ trợ quốc tế)
const phoneRegex = /(?:\+\d{1,3}\s?)?\d{3}\s?\d{3}\s?\d{3,4}|\(\d{3}\)\s?\d{3}-?\d{4}/g;
const emails = [...new Set((content.match(emailRegex) || [])
.filter(email => !email.includes('example.com'))
.slice(0, 3))];
const phones = [...new Set((content.match(phoneRegex) || [])
.filter(phone => phone.replace(/\D/g, '').length >= 9)
.slice(0, 2))];
return { emails, phones };
}
function extractBusinessSections(content) {
const sections = {};
// Tìm kiếm các phần quan trọng
const lines = content.split('\n');
let currentSection = '';
let currentContent = '';
for (let i = 0; i < lines.length; i++) {
const line = lines[i].trim();
// Phát hiện tiêu đề
if (line.startsWith('#')) {
// Lưu phần trước đó
if (currentSection && currentContent) {
sections[currentSection] = currentContent.trim().substring(0, 500);
}
// Phần mới
const title = line.replace(/^#+\s*/, '').toLowerCase();
if (title.includes('giới thiệu') || title.includes('dịch vụ') ||
title.includes('liên hệ') || title.includes('công ty')) {
currentSection = title.includes('giới thiệu') ? 'about' :
title.includes('dịch vụ') ? 'services' :
title.includes('liên hệ') ? 'contact' : 'company';
currentContent = '';
} else {
currentSection = '';
}
} else if (currentSection && line) {
currentContent += line + '\n';
}
json
}
// Lưu phần cuối cùng
nếu (currentSection && currentContent) {
sections[currentSection] = currentContent.trim().substring(0, 500);
}
return sections;
}
function buildContentForAI({ companyName, sourceURL, description, businessSections, contactInfo, cleanedContent }) {
let aiContent = `YÊU CẦU PHÂN TÍCH CÔNG TY\n\n`;
aiContent += `Công ty: ${companyName}\n`;
aiContent += `Trang web: ${sourceURL}\n`;
nếu (description) {
aiContent += `Mô tả: ${description}\n`;
}
aiContent += `\nTHÔNG TIN LIÊN HỆ:\n`;
nếu (contactInfo.emails.length > 0) {
aiContent += `Email: ${contactInfo.emails.join(', ')}\n`;
}
nếu (contactInfo.phones.length > 0) {
aiContent += `Số điện thoại: ${contactInfo.phones.join(', ')}\n`;
}
aiContent += `\nCÁC PHẦN KINH DOANH:\n`;
cho (const [section, content] of Object.entries(businessSections)) {
nếu (content) {
aiContent += `\n${section.toUpperCase()}:\n${content}\n`;
}
}
// Thêm nội dung chính (giới hạn)
aiContent += `\nXEM TRƯỚC NỘI DUNG ĐẦY ĐỦ:\n`;
aiContent += cleanedContent.substring(0, 2000);
// Giới hạn cuối cùng cho API Claude
return aiContent.substring(0, 6000);
}
function assessContentQuality(content, contactInfo) {
const wordCount = content.split(/\s+/).length;
return {
word_count: wordCount,
has_contact_info: contactInfo.emails.length > 0 || contactInfo.phones.length > 0,
has_about_section: /about|company|who we are/gi.test(content),
has_services_section: /services|products|solutions/gi.test(content),
has_team_section: /team|leadership|staff/gi.test(content),
content_richness_score: Math.min(10, Math.floor(wordCount / 50)),
email_count: contactInfo.emails.length,
phone_count: contactInfo.phones.length,
estimated_quality: wordCount > 200 && contactInfo.emails.length > 0 ? "CAO" :
wordCount > 100 ? "TRUNG BÌNH" : "THẤP"
};
}3. Tại sao cần thêm bước xử lý mã?
- Thích ứng cấu trúc dữ liệu: Chuyển đổi định dạng mảng Scrapeless thành cấu trúc thân thiện với Claude
- Tối ưu hóa nội dung: Trích xuất và ưu tiên các phần liên quan đến kinh doanh
- Khám phá liên hệ: Tự động xác định email và số điện thoại
- Đánh giá chất lượng: Đánh giá độ phong phú và độ hoàn chỉnh của nội dung
- Hiệu quả theo token: Giảm kích thước nội dung trong khi bảo tồn thông tin quan trọng
- Xử lý lỗi: Quản lý các lần thu thập không thành công và nội dung không đủ một cách nhẹ nhàng
- Hỗ trợ gỡ lỗi: Ghi chép toàn diện để khắc phục sự cố
4. Cấu trúc đầu ra mong đợi
Sau khi xử lý, mỗi khách hàng tiềm năng sẽ có định dạng cấu trúc này:
{
"url": "https://company.com",
"company_name": "Tên Công Ty",
"content": "YÊU CẦU PHÂN TÍCH CÔNG TY\n\nCông ty: ...",
"raw_content_length": 50000,
"processed_content_length": 2500,
"extracted_emails": ["contact@company.com"],
"extracted_phones": ["+1-555-123-4567"],
"content_quality": {
"word_count": 5000,
"has_contact_info": true,
"estimated_quality": "CAO",
"content_richness_score": 10
},
"processing_status": "THÀNH CÔNG"
}
Điều này giúp xác minh định dạng dữ liệu và khắc phục bất kỳ vấn đề xử lý nào.
5. Lợi ích của nút mã
- Tiết kiệm chi phí: Nội dung nhỏ hơn, sạch hơn = ít token của API Claude hơn
- Kết quả tốt hơn: Nội dung tập trung cải thiện độ chính xác phân tích của AI
- Khôi phục lỗi: Xử lý các phản hồi trống và thu thập không thành công
- Linh hoạt: Dễ dàng điều chỉnh logic phân tích dựa trên kết quả
- Đánh giá chất lượng: Đánh giá độ hoàn chỉnh của dữ liệu khách hàng tiềm năng đã được tích hợp
Bước 6: Phân loại Khách Hàng Tiềm Năng bằng AI với Claude
Sử dụng Claude AI để trích xuất và phân loại thông tin khách hàng tiềm năng từ nội dung đã được thu thập và cấu trúc bởi Nút mã của chúng tôi.
- Thêm nút đại lý AI sau nút Mã
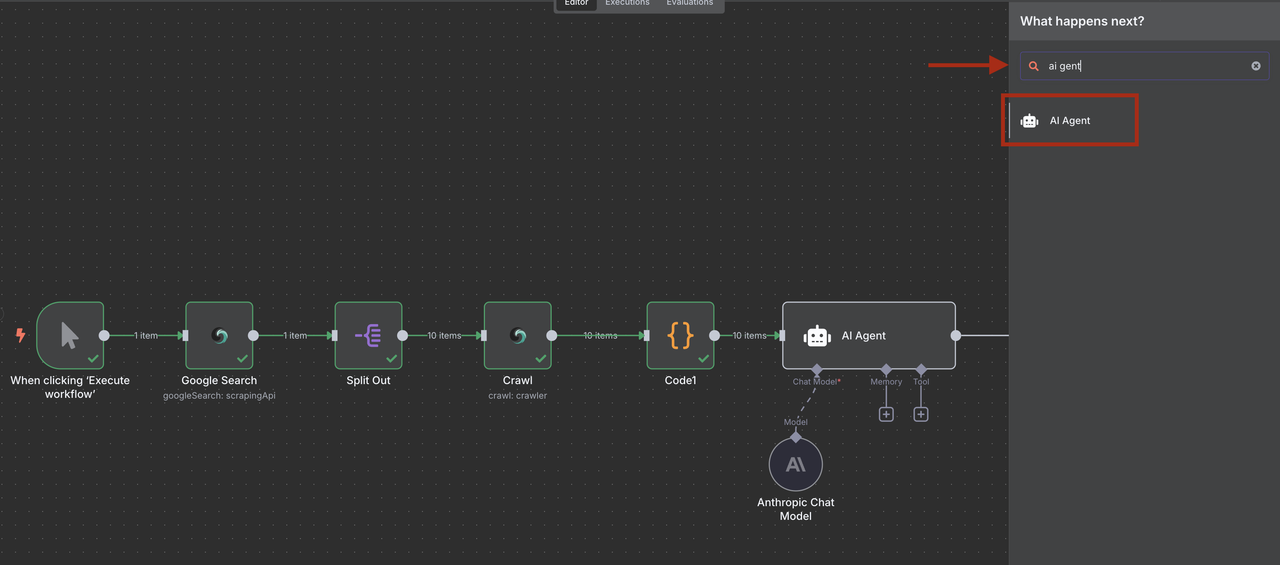
- Thêm nút Anthropic Claude và cấu hình để phân tích khách hàng tiềm năng
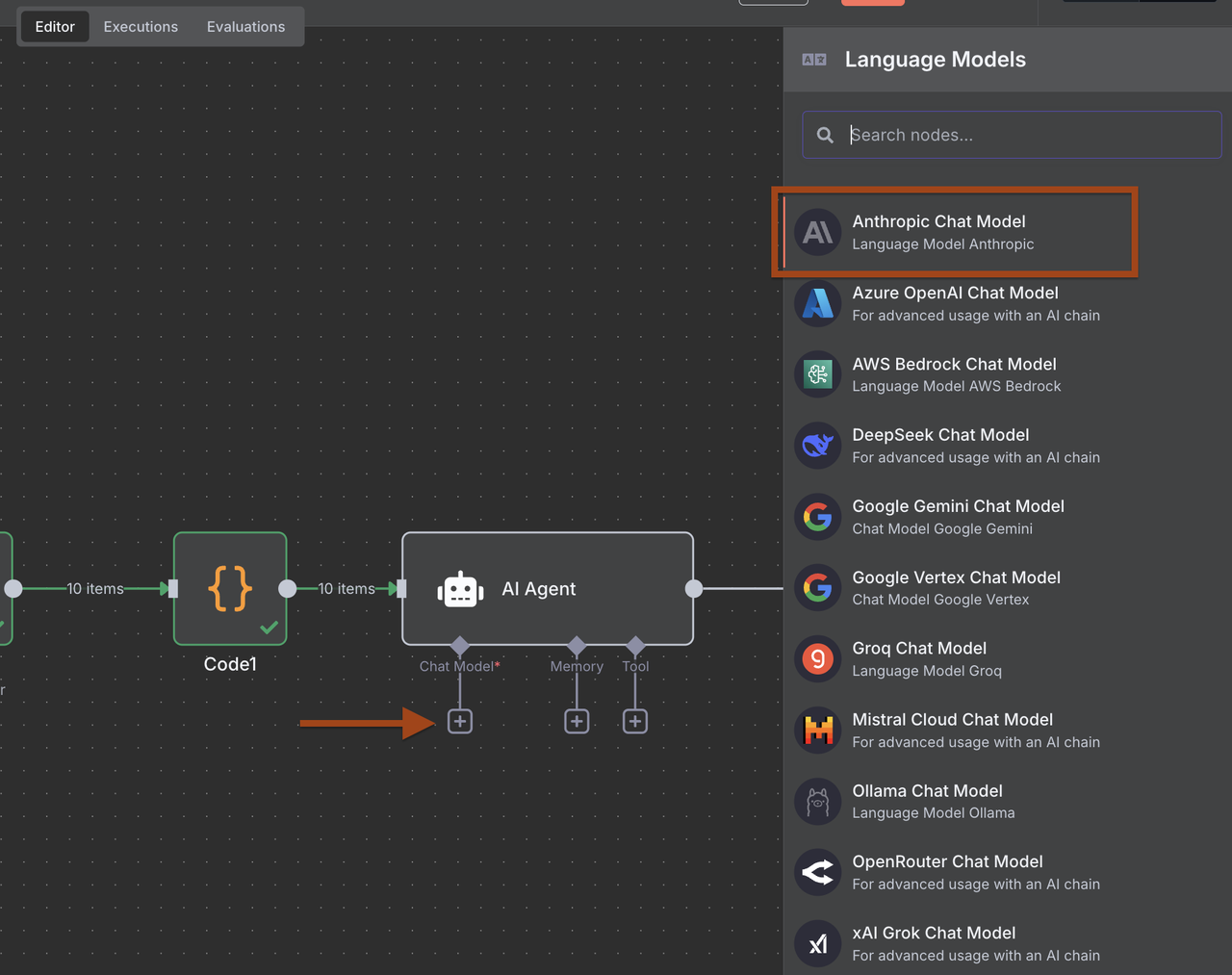
- Cấu hình các gợi ý để trích xuất dữ liệu khách hàng B2B có cấu trúc
Nhấp vào đại lý AI -> thêm tùy chọn -> Tin nhắn Hệ thống và dán thông điệp bên dưới
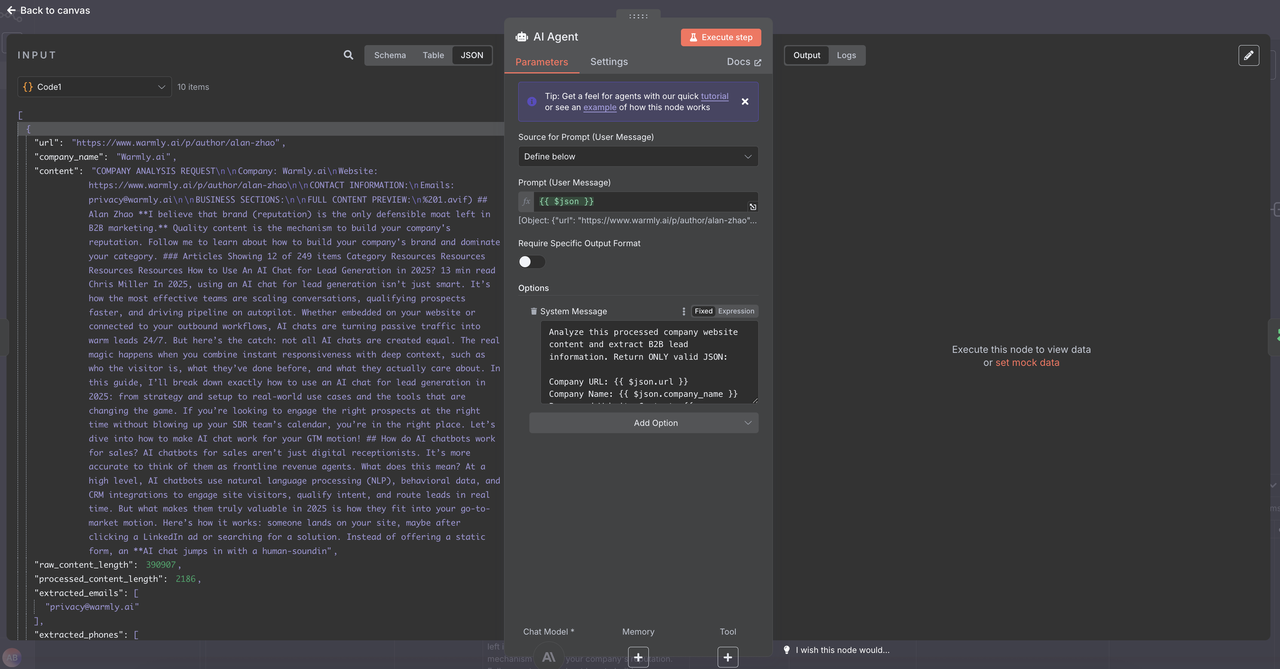
Gợi ý Trích xuất Khách Hàng Hệ thống:
Phân tích nội dung trang web công ty đã được xử lý này và trích xuất thông tin khách hàng B2B. Trả về CHỈ mã JSON hợp lệ:
URL Công ty: {{ $json.url }}
Tên Công Ty: {{ $json.company_name }}
Nội dung Trang Web Đã Được Xử Lý: {{ $json.content }}
Đánh giá Chất lượng Nội dung: {{ $json.content_quality }}
Thông tin liên hệ đã được trích xuất trước:
Email: {{ $json.extracted_emails }}
Số điện thoại: {{ $json.extracted_phones }}
Thông tin Metadata: {{ $json.metadata_info }}Chi tiết xử lý:
Độ dài nội dung thô: {{ $json.raw_content_length }} ký tự
Độ dài nội dung đã xử lý: {{ $json.processed_content_length }} ký tự
Trạng thái xử lý: {{ $json.processing_status }}
Dựa trên dữ liệu có cấu trúc này, hãy trích xuất và đủ điều kiện cho khách hàng tiềm năng B2B này. Chỉ trả về JSON hợp lệ:
{
"company_name": "Tên công ty chính thức từ nội dung",
"industry": "Ngành/ngành chính xác định",
"company_size": "Số lao động hoặc danh mục kích thước (khởi nghiệp/SMB/thị trường trung gian/doanh nghiệp)",
"location": "Địa điểm trụ sở hoặc thị trường chính",
"contact_email": "Email chung hoặc bán hàng tốt nhất từ các email đã trích xuất",
"phone": "Số điện thoại chính từ các số điện thoại đã trích xuất",
"key_services": ["Các dịch vụ/sản phẩm chính được cung cấp dựa trên nội dung"],
"target_market": "Ai là khách hàng phục vụ (B2B/B2C, SMB/Doanh nghiệp, các ngành cụ thể)",
"technologies": ["Ngăn xếp công nghệ, nền tảng hoặc công cụ được đề cập"],
"funding_stage": "Giai đoạn tài trợ nếu được đề cập (vòng hạt/series A/B/C/công khai/tư nhân)",
"business_model": "Mô hình doanh thu (SaaS/tư vấn/sản phẩm/thị trường)",
"social_presence": {
"linkedin": "URL công ty LinkedIn nếu được tìm thấy trong nội dung",
"twitter": "Tên tài khoản Twitter nếu tìm thấy"
},
"lead_score": 8.5,
"qualification_reasons": ["Các lý do cụ thể tại sao khách hàng tiềm năng này đủ điều kiện hoặc không"],
"decision_makers": ["Tên và chức danh của các liên hệ chính được tìm thấy"],
"next_actions": ["Chiến lược theo dõi được khuyến nghị dựa trên hồ sơ công ty"],
"content_insights": {
"website_quality": "Chuyên nghiệp/Cơ bản/Kém dựa trên sự phong phú của nội dung",
"recent_activity": "Bất kỳ tin tức, tài trợ hoặc cập nhật gần đây nào được đề cập",
"competitive_positioning": "Cách họ định vị so với đối thủ"
}
}
Tiêu chí số điểm nâng cao (1-10):
9-10: Phù hợp ICP hoàn hảo + thông tin liên hệ đầy đủ + tín hiệu tăng trưởng cao + nội dung chuyên nghiệp
7-8: Phù hợp ICP tốt + một số thông tin liên hệ + công ty ổn định + nội dung chất lượng
5-6: Phù hợp trung bình + thông tin liên hệ hạn chế + nội dung cơ bản + cần nghiên cứu
3-4: Phù hợp kém + thông tin tối thiểu + nội dung chất lượng thấp + sai thị trường mục tiêu
1-2: Không đủ điều kiện + không có thông tin liên hệ + xử lý thất bại + không liên quan
Các yếu tố để xem xét điểm số:
Điểm chất lượng nội dung: {{ $json.content_quality.content_richness_score }}/10
Thông tin liên hệ: {{ $json.content_quality.email_count }} email, {{ $json.content_quality.phone_count }} điện thoại
Tính đầy đủ của nội dung: {{ $json.content_quality.has_about_section }}, {{ $json.content_quality.has_services_section }}
Thành công trong xử lý: {{ $json.processing_status }}
Thể tích nội dung: {{ $json.content_quality.word_count }} từ
Hướng dẫn:
Chỉ sử dụng thông tin liên hệ đã được trích xuất từ extracted_emails và extracted_phones
Dựa trên company_name dựa trên trường company_name đã xử lý, không phải nội dung thô
Xem xét các chỉ số chất lượng nội dung khi xác định lead_score
Nếu processing_status không phải là "THÀNH CÔNG", hãy giảm điểm số đáng kể
Sử dụng null cho bất kỳ thông tin nào bị thiếu - không tưởng tượng dữ liệu
Hãy thận trọng với điểm số - tốt hơn là thấp hơn là cao hơn
Tập trung vào sự liên quan B2B và phù hợp ICP dựa trên nội dung có cấu trúc đã cung cấp
Cấu trúc yêu cầu giúp việc lọc trở nên đáng tin cậy hơn vì Claude giờ nhận đầu vào có cấu trúc nhất quán. Điều này dẫn đến các điểm số dẫn đầu chính xác hơn và quyết định đủ điều kiện tốt hơn trong bước tiếp theo của quy trình làm việc của bạn.
## Bước 7: Phân tích phản hồi AI Claude
Trước khi lọc các khách hàng tiềm năng, chúng ta cần phân tích phản hồi JSON của Claude AI, có thể được bọc trong định dạng markdown.
1. Thêm một nút Code sau AI Agent (Claude)
2. Cấu hình để phân tích và làm sạch phản hồi JSON của Claude
### Cấu hình Nút Code// Mã để phân tích phản hồi JSON của Claude AI
console.log("=== PHÂN TÍCH PHẢN HỒI AI CLAUDE ===");
try {
// Phản hồi của Claude đến trong trường "output"
const claudeOutput = $json.output || "";
console.log("Độ dài đầu ra của Claude:", claudeOutput.length);
console.log("Xem trước đầu ra của Claude:", claudeOutput.substring(0, 200));
// Trích xuất JSON từ phản hồi markdown của Claude
let jsonString = claudeOutput;
// Loại bỏ dấu nháy markdown nếu có
if (jsonString.includes('json')) {
const jsonMatch = jsonString.match(/json\s*([\s\S]?)\s/);
if (jsonMatch && jsonMatch[1]) {
jsonString = jsonMatch[1].trim();
}
} else if (jsonString.includes('')) {
// Phương án thay thế cho các trường hợp chỉ có
const jsonMatch = jsonString.match(/\s*([\s\S]?)\s```/);
if (jsonMatch && jsonMatch[1]) {
jsonString = jsonMatch[1].trim();
}
}
// Làm sạch bổ sung
jsonString = jsonString.trim();
console.log("Chuỗi JSON đã trích xuất:", jsonString.substring(0, 300));
// Phân tích JSON
const leadData = JSON.parse(jsonString);
console.log("Đã phân tích dữ liệu khách hàng tiềm năng thành công cho:", leadData.company_name);
console.log("Điểm dẫn đầu:", leadData.lead_score);
```javascript
console.log("Email liên hệ:", leadData.contact_email);
// Xác thực và làm sạch dữ liệu
const cleanedLead = {
company_name: leadData.company_name || "Không xác định",
industry: leadData.industry || null,
company_size: leadData.company_size || null,
location: leadData.location || null,
contact_email: leadData.contact_email || null,
phone: leadData.phone || null,
key_services: Array.isArray(leadData.key_services) ? leadData.key_services : [],
target_market: leadData.target_market || null,
technologies: Array.isArray(leadData.technologies) ? leadData.technologies : [],
funding_stage: leadData.funding_stage || null,
business_model: leadData.business_model || null,
social_presence: leadData.social_presence || { linkedin: null, twitter: null },
lead_score: typeof leadData.lead_score === 'number' ? leadData.lead_score : 0,
qualification_reasons: Array.isArray(leadData.qualification_reasons) ? leadData.qualification_reasons : [],
decision_makers: Array.isArray(leadData.decision_makers) ? leadData.decision_makers : [],
next_actions: Array.isArray(leadData.next_actions) ? leadData.next_actions : [],
content_insights: leadData.content_insights || {},
// Thông tin meta để lọc
is_qualified: leadData.lead_score >= 6 && leadData.contact_email !== null,
has_contact_info: !!(leadData.contact_email || leadData.phone),
processing_timestamp: new Date().toISOString(),
claude_processing_status: "THÀNH CÔNG"
};
console.log(✅ Dẫn đầu đã được xử lý: ${cleanedLead.company_name} (Điểm: ${cleanedLead.lead_score}, Đủ điều kiện: ${cleanedLead.is_qualified}));
return cleanedLead;
} catch (error) {
console.error("❌ Lỗi phân tích phản hồi Claude:", error);
console.error("Đầu ra thô:", $json.output);
// Phản hồi lỗi có cấu trúc
return {
company_name: "Lỗi phân tích Claude",
industry: null,
company_size: null,
location: null,
contact_email: null,
phone: null,
key_services: [],
target_market: null,
technologies: [],
funding_stage: null,
business_model: null,
social_presence: { linkedin: null, twitter: null },
lead_score: 0,
qualification_reasons: [Lỗi phân tích Claude: ${error.message}],
decision_makers: [],
next_actions: ["Sửa lỗi phân tích phản hồi Claude", "Kiểm tra định dạng JSON"],
content_insights: {},
is_qualified: false,
has_contact_info: false,
processing_timestamp: new Date().toISOString(),
claude_processing_status: "THẤT BẠI",
parsing_error: error.message,
raw_claude_output: $json.output || "Không nhận được đầu ra"
};
}
// Tại sao thêm phân tích phản hồi Claude?
- Xử lý Markdown: Loại bỏ định dạng json từ phản hồi của Claude
- Kiểm tra dữ liệu: Đảm bảo tất cả các trường có kiểu và giá trị mặc định đúng
- Khôi phục lỗi: Xử lý lỗi phân tích JSON một cách nhẹ nhàng
- Chuẩn bị lọc: Thêm các trường được tính toán để dễ dàng lọc
- Hỗ trợ gỡ lỗi: Ghi lại toàn diện cho việc xử lý sự cố
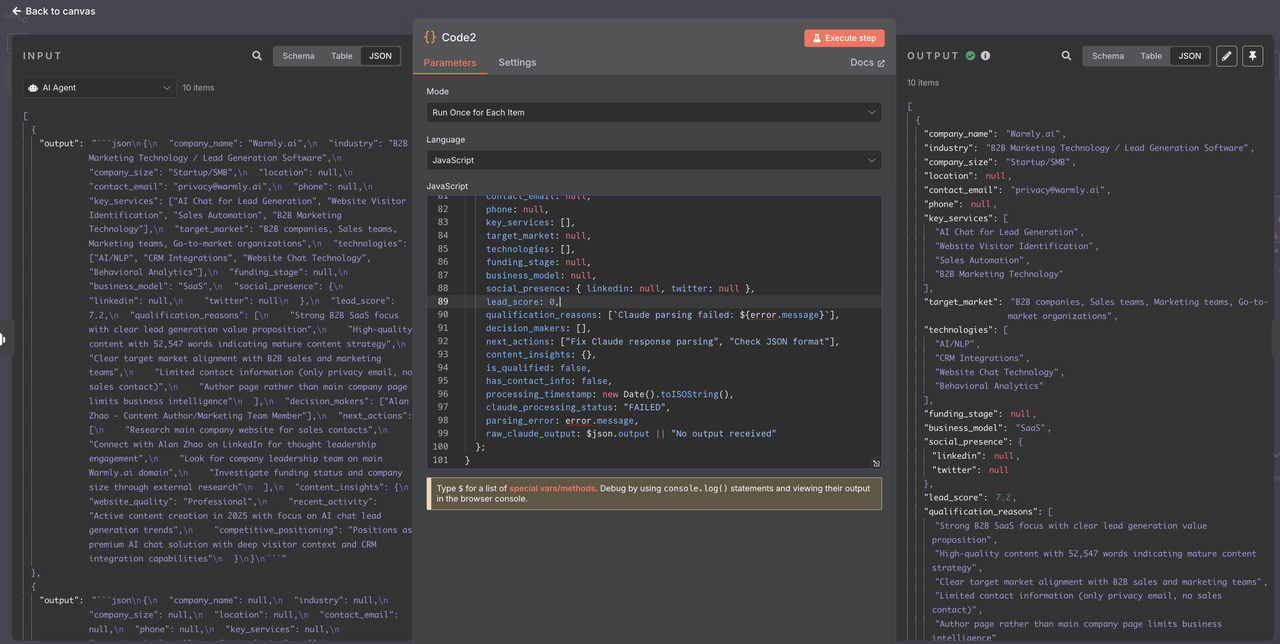
## Bước 8: Lọc và Kiểm soát Chất lượng Dẫn đầu
Lọc các dẫn đầu dựa trên điểm số đủ điều kiện và tính đầy đủ của dữ liệu sử dụng dữ liệu đã phân tích và xác thực.
1. Thêm một nút IF sau bộ phân tích phản hồi Claude
2. Thiết lập tiêu chí đủ điều kiện được cải tiến
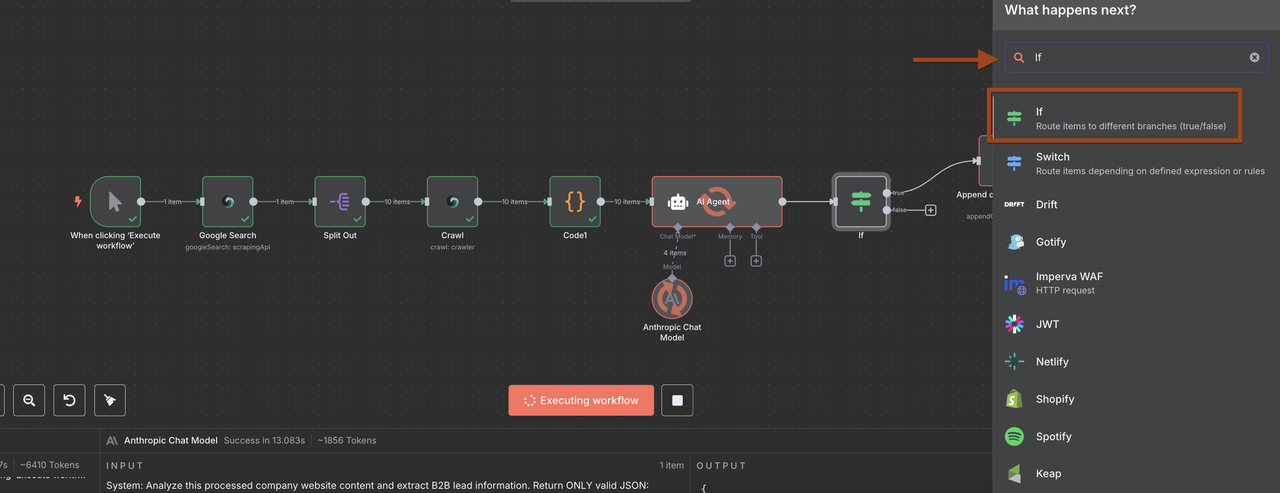
### Cấu hình nút IF mới
Bây giờ dữ liệu đã được phân tích đúng cách, hãy sử dụng các điều kiện này trong nút IF:
**1: Thêm nhiều điều kiện**
**Điều kiện 1:**
- Trường: {{ $json.lead_score }}
- Toán tử: bằng hoặc lớn hơn
- Giá trị: 6
**Điều kiện 2:**
- Trường: {{ $json.claude_processing_status }}
- Toán tử: bằng với
- Giá trị: THÀNH CÔNG
Tùy chọn: Chuyển đổi kiểu khi cần thiết
- ĐÚNG
### Lợi ích của việc lọc
- Đảm bảo chất lượng: Chỉ những dẫn đầu đủ điều kiện mới tiến tới lưu trữ
- Tối ưu hóa chi phí: Ngăn chặn việc xử lý các dẫn đầu có chất lượng thấp
- Tính toàn vẹn của dữ liệu: Đảm bảo dữ liệu đã được phân tích là hợp lệ trước khi lưu trữ
- Khả năng gỡ lỗi: Việc phân tích thất bại được phát hiện và ghi lại
## Bước 9: Lưu trữ Dẫn đầu trong Google Sheets
Lưu trữ các dẫn đầu đủ điều kiện trong cơ sở dữ liệu Google Sheets để dễ dàng truy cập và quản lý.
1. Thêm một nút Google Sheets sau bộ lọc
2. Cấu hình để thêm dẫn đầu mới
Tuy nhiên, bạn có thể chọn quản lý dữ liệu theo cách bạn muốn.
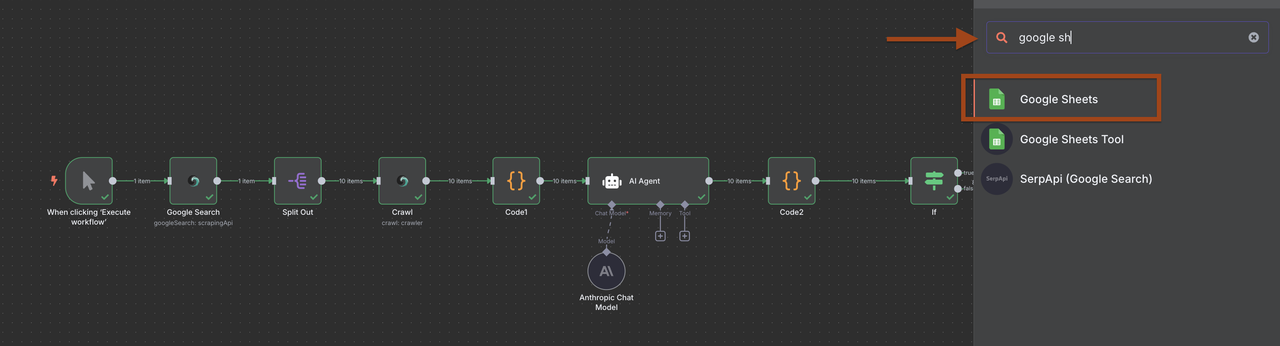
**Cài đặt Google Sheets:**- Tạo một bảng tính có tên "Cơ sở dữ liệu Khách hàng B2B"
- Thiết lập các cột:
- Tên Công ty
- Ngành nghề
- Kích thước Công ty
- Địa điểm
- Email Liên hệ
- Điện thoại
- Trang web
- Điểm Khách hàng
- Ngày Thêm
- Ghi chú Xác minh
- Hành động Tiếp theo
Về phần của tôi, tôi chọn sử dụng trực tiếp webhook Discord
Bước 9-2: Thông báo Discord (Có thể điều chỉnh cho các dịch vụ khác)
Gửi thông báo theo thời gian thực cho các khách hàng tiềm năng đã đủ điều kiện mới.
- Thêm một nút Yêu cầu HTTP cho webhook Discord
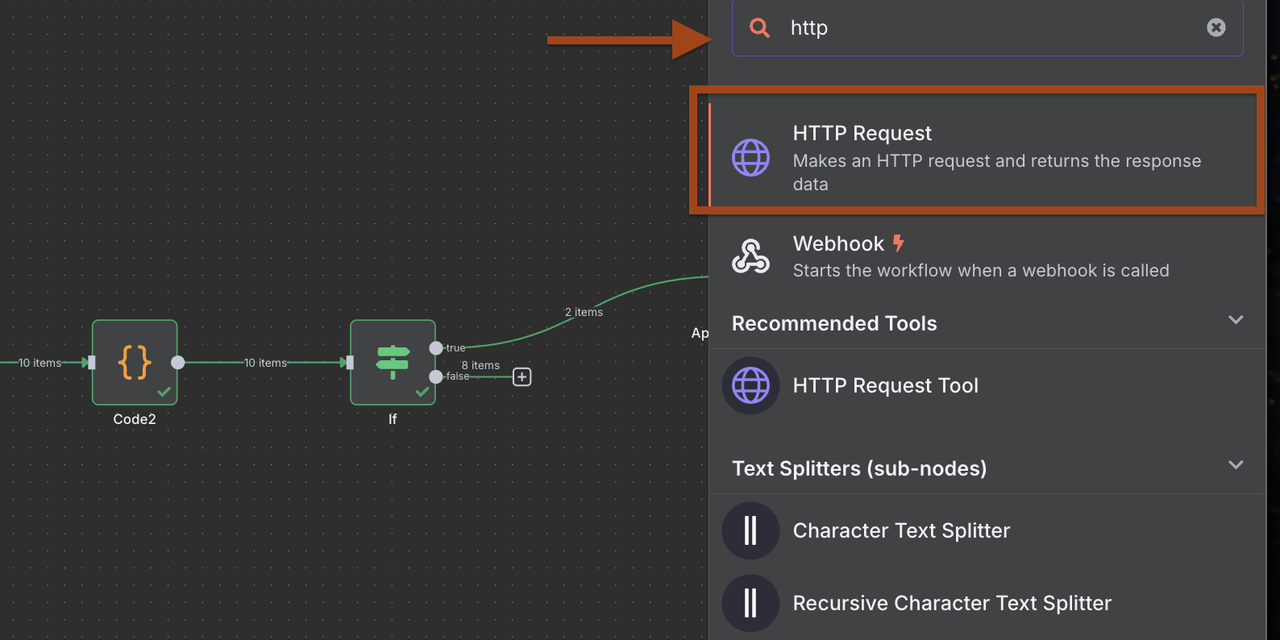
- Cấu hình định dạng payload đặc biệt cho Discord
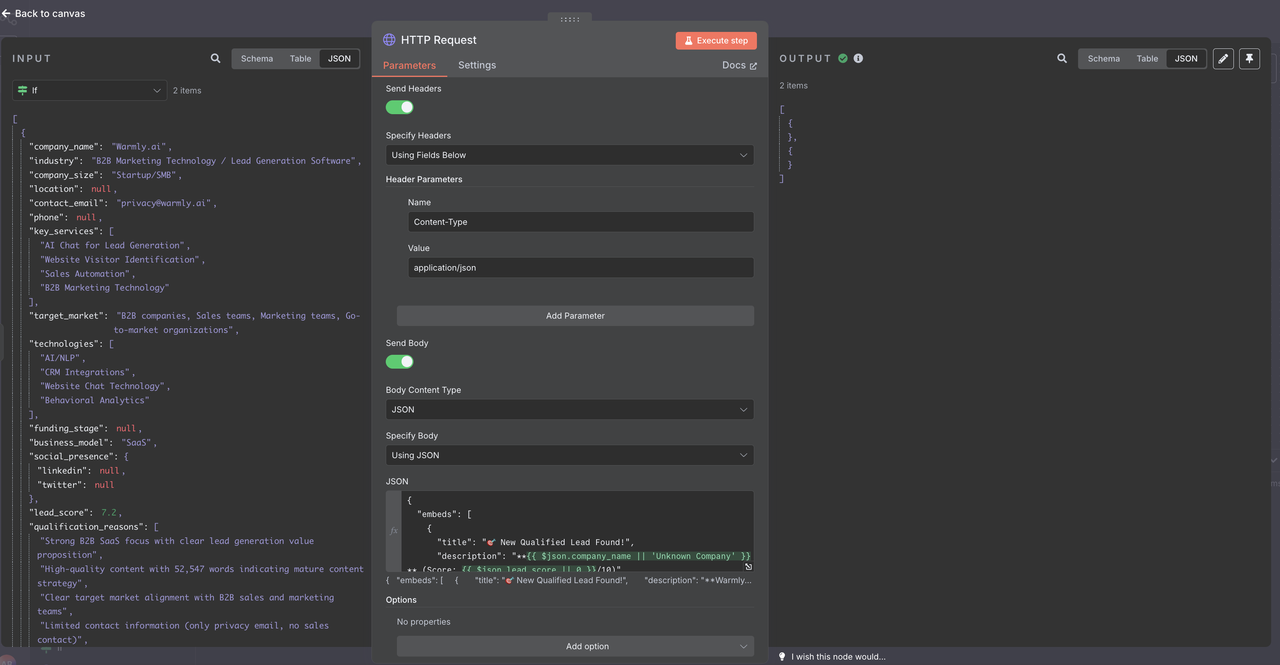
Cấu hình Webhook Discord:
- Phương thức: POST
- URL: URL webhook Discord của bạn
- Headers: Content-Type: application/json
Payload Tin nhắn Discord:
{
"embeds": [
{
"title": "🎯 Đã tìm thấy Khách hàng Tiềm năng Đủ điều kiện Mới!",
"description": "**{{ $json.company_name || 'Công ty Không rõ' }}** (Điểm: {{ $json.lead_score || 0 }}/10)",
"color": 3066993,
"fields": [
{
"name": "Ngành nghề",
"value": "{{ $json.industry || 'Không được chỉ định' }}",
"inline": true
},
{
"name": "Kích thước",
"value": "{{ $json.company_size || 'Không được chỉ định' }}",
"inline": true
},
{
"name": "Địa điểm",
"value": "{{ $json.location || 'Không được chỉ định' }}",
"inline": true
},
{
"name": "Liên hệ",
"value": "{{ $json.contact_email || 'Không tìm thấy email' }}",
"inline": false
},
{
"name": "Điện thoại",
"value": "{{ $json.phone || 'Không tìm thấy điện thoại' }}",
"inline": false
},
{
"name": "Dịch vụ",
"value": "{{ $json.key_services && $json.key_services.length > 0 ? $json.key_services.slice(0, 3).join(', ') : 'Không được chỉ định' }}",
"inline": false
},
{
"name": "Trang web",
"value": "[Truy cập Trang web]({{ $node['Code2'].json.url || '#' }})",
"inline": false
},
{
"name": "Tại sao Đủ điều kiện",
"value": "{{ $json.qualification_reasons && $json.qualification_reasons.length > 0 ? $json.qualification_reasons.slice(0, 2).join(' • ') : 'Đã đáp ứng các tiêu chí đủ điều kiện tiêu chuẩn' }}",
"inline": false
}
],
"footer": {
"text": "Được tạo bởi Quy trình Tạo Khách hàng tiềm năng n8n"
},
"timestamp": ""
}
]
}Kết quả
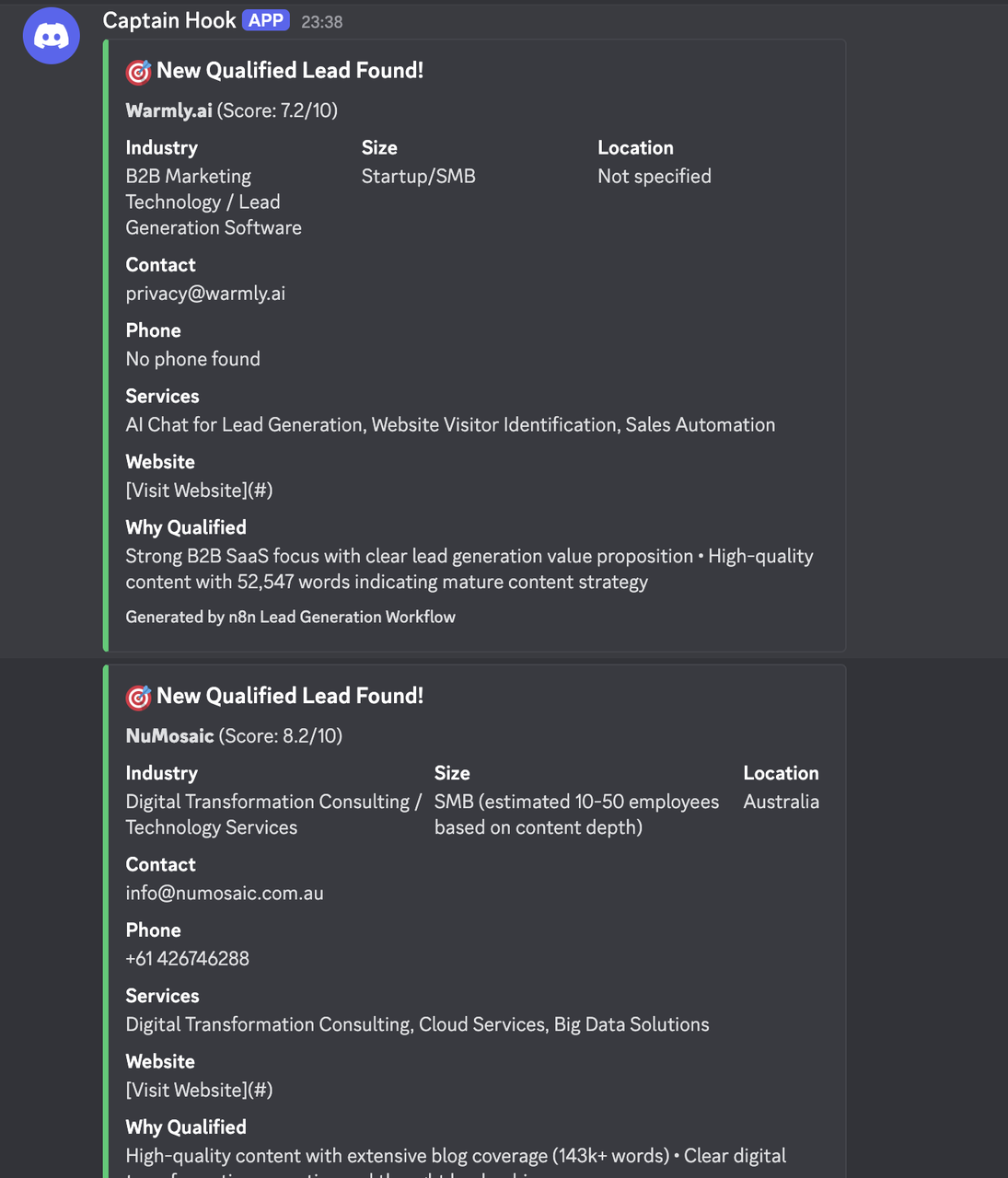
Cấu hình Đặc thù Ngành nghề
Các công ty SaaS/Phần mềm
Câu truy vấn Tìm kiếm:
"Các công ty SaaS" "phần mềm B2B" "phần mềm doanh nghiệp"
"phần mềm đám mây" "API" "nhà phát triển" "mô hình đăng ký"
"phần mềm như một dịch vụ" "nền tảng" "tích hợp"Tiêu chí Xác minh:
- Số lượng nhân viên: 20-500
- Sử dụng công nghệ hiện đại
- Có tài liệu API
- Hoạt động trên GitHub/nội dung kỹ thuật
Các cơ quan Tiếp thị
Câu truy vấn Tìm kiếm:
"cơ quan tiếp thị kỹ thuật số" "tiếp thị B2B" "khách hàng doanh nghiệp"
"tự động hóa tiếp thị" "tạo nhu cầu" "tạo khách hàng tiềm năng"
"cơ quan tiếp thị nội dung" "tiếp thị tăng trưởng" "tiếp thị hiệu suất"Tiêu chí Xác minh:
- Các nghiên cứu trường hợp khách hàng có sẵn
- Kích thước nhóm: 10-100
- Chuyên về B2B
- Tiếp thị nội dung tích cực
Thương mại điện tử/Bán lẻ
Câu truy vấn Tìm kiếm:
"các công ty thương mại điện tử" "bán lẻ trực tuyến" "thương hiệu D2C"
"Cửa hàng Shopify" "WooCommerce" "nền tảng thương mại điện tử"
"thị trường trực tuyến" "thương mại kỹ thuật số" "công nghệ bán lẻ"Tiêu chí Xác minh:
- Chỉ số doanh thu
- Sự hiện diện đa kênh
- Nền tảng công nghệ được đề cập
- Tín hiệu tăng trưởng
Quản lý và Phân tích Dữ liệu
Sơ đồ Cơ sở Dữ liệu Khách hàng tiềm năng
Cấu trúc Google Sheets của bạn để tối đa hóa tính hữu dụng:
Thông tin Khách hàng tiềm năng cốt lõi:
- Tên Công ty, Ngành nghề, Kích thước, Địa điểm
- Email Liên hệ, Điện thoại, Trang web
- Điểm Khách hàng, Ngày Thêm, Truy vấn Nguồn
Dữ liệu Xác minh:
- Lý do Xác minh, Người ra quyết định
- Hành động Tiếp theo, Ngày Theo dõi
- Đại diện Bán hàng Được phân công, Tình trạng Khách hàng tiềm năng
Các trường Tăng cường:
- URL LinkedIn, Sự hiện diện trên mạng xã hội
- Công nghệ đã sử dụng, Giai đoạn tài trợ
- Đối thủ cạnh tranh, Tin tức gần đây
Phân tích và Báo cáo
Theo dõi hiệu suất quy trình làm việc với các bảng tính bổ sung:
Bảng Tổng hợp Hằng ngày:
- Số Khách hàng tiềm năng Đã tạo Mỗi Ngày
- Điểm Khách hàng Trung bình
- Ngành nghề Hàng đầu Đã tìm thấy
- Tỷ lệ Chuyển đổi
Hiệu suất Tìm kiếm:
- Câu truy vấn Có Hiệu suất Tốt Nhất
- Phân bổ Địa lý
- Phân tích Kích thước Công ty
- Tỷ lệ Thành công theo Ngành nghề
Theo dõi ROI:
- Chi phí Mỗi Khách hàng tiềm năng (chi phí API)
- Thời gian Liên hệ
- Chuyển đổi thành Cơ hội
- Ghi nhận Doanh thu
Kết luận
Quy trình tạo khách hàng tiềm năng B2B thông minh này chuyển đổi việc tìm kiếm khách hàng bán hàng của bạn bằng cách tự động hóa quá trình khám phá, đủ điều kiện và tổ chức khách hàng tiềm năng. Bằng cách kết hợp Tìm kiếm Google với crawling thông minh và phân tích AI, bạn tạo ra một cách tiếp cận có hệ thống để xây dựng đường ống bán hàng của mình.
Quy trình này thích ứng với ngành nghề cụ thể của bạn, mục tiêu về quy mô công ty và tiêu chí đủ điều kiện trong khi vẫn duy trì chất lượng dữ liệu cao thông qua phân tích do AI hỗ trợ. Với thiết lập và giám sát đúng cách, hệ thống này trở thành nguồn cung cấp khách hàng tiềm năng đủ điều kiện cho đội ngũ bán hàng của bạn.
Sự tích hợp với Google Sheets cung cấp một cơ sở dữ liệu dễ dàng truy cập cho các đội ngũ bán hàng, trong khi thông báo trên Discord đảm bảo sự nhận thức ngay lập tức về những khách hàng tiềm năng có giá trị cao. Thiết kế mô-đun cho phép dễ dàng điều chỉnh cho các dịch vụ thông báo khác nhau, hệ thống CRM và giải pháp lưu trữ dữ liệu.
Scrapeless hoàn toàn tuân thủ các luật và quy định hiện hành, chỉ truy cập dữ liệu công khai theo các điều khoản dịch vụ và chính sách quyền riêng tư của trang web. Giải pháp này được thiết kế cho mục đích thông tin doanh nghiệp hợp pháp và tối ưu hóa marketing.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


