
Xây dựng Trợ lý Nghiên cứu sử dụng AI với Linear + Scrapeless + Claude
Advanced Data Extraction Specialist
Các đội ngũ hiện đại cần truy cập ngay lập tức vào dữ liệu đáng tin cậy để đưa ra quyết định thông minh. Dù bạn đang nghiên cứu đối thủ, phân tích xu hướng hay thu thập thông tin thị trường, việc thu thập dữ liệu thủ công sẽ làm chậm tiến độ làm việc của bạn và cản trở đà phát triển.
Bằng cách kết hợp nền tảng quản lý dự án Linear với các API trích xuất dữ liệu mạnh mẽ của Scrapeless và khả năng phân tích của Claude AI, bạn có thể tạo ra một trợ lý nghiên cứu thông minh phản hồi các lệnh đơn giản trực tiếp trong các vấn đề của bạn trên Linear.
Sự tích hợp này biến không gian làm việc Linear của bạn thành một trung tâm chỉ huy thông minh, nơi gõ /search phân tích đối thủ hoặc /trends AI thị trường sẽ tự động kích hoạt việc thu thập dữ liệu toàn diện và phân tích thông minh - tất cả đều được trả lại dưới dạng các bình luận có cấu trúc trong các vấn đề Linear của bạn.
Tại sao chọn Linear + Scrapeless + Claude?
Linear: Không Gian Phát Triển Hiện Đại
Linear cung cấp giao diện hoàn hảo cho sự hợp tác của đội ngũ và quản lý công việc:
- Quy trình làm việc dựa trên vấn đề: Tích hợp tự nhiên với các quy trình phát triển
- Cập nhật theo thời gian thực: Thông báo ngay lập tức và giao tiếp đồng bộ trong đội
- Webhooks & API: Khả năng tự động hóa mạnh mẽ với công cụ bên ngoài
- Theo dõi dự án: Phân tích và giám sát tiến độ tích hợp sẵn
- Hợp tác đội ngũ: Tính năng bình luận và thảo luận liền mạch
Scrapeless: Trích Xuất Dữ Liệu Đẳng Cấp Doanh Nghiệp
Scrapeless cung cấp khả năng trích xuất dữ liệu đáng tin cậy, mở rộng từ nhiều nguồn:
- Tìm kiếm Google: Cho phép trích xuất toàn diện dữ liệu SERP Google trên tất cả các loại kết quả.
- Xu hướng Google: Thu thập dữ liệu xu hướng từ Google, bao gồm độ phổ biến theo thời gian, mối quan tâm theo khu vực và các tìm kiếm liên quan.
- API Trích Xuất Toàn Cầu: Truy cập và trích xuất dữ liệu từ các trang web JS-Render thường chặn bot.
- Crawl: Lập chỉ mục một trang web và các trang liên kết của nó để trích xuất dữ liệu toàn diện.
- Scrape: Trích xuất thông tin từ một trang web duy nhất.
Claude AI: Phân Tích Dữ Liệu Thông Minh
Claude AI biến dữ liệu thô thành những cái nhìn có thể hành động:
- Lý luận nâng cao: Phân tích tinh vi và nhận diện mẫu
- Đầu ra có cấu trúc: Phản hồi sạch sẽ, định dạng hoàn hảo cho các bình luận Linear
- Nhận thức ngữ cảnh: Hiểu ngữ cảnh kinh doanh và ý định của người dùng
- Những cái nhìn có thể hành động: Cung cấp khuyến nghị và bước tiếp theo
- Tổng hợp dữ liệu: Kết hợp nhiều nguồn dữ liệu thành phân tích hợp nhất
Các Trường Hợp Sử Dụng
Trung Tâm Thông Tin Cạnh Tranh
Nghiên cứu Đối Thủ Ngay Lập Tức
- Phân tích Vị trí Thị Trường: Tự động thu thập dữ liệu và phân tích trang web đối thủ
- Theo dõi Xu Hướng: Theo dõi sự nhắc đến đối thủ và những thay đổi trong cảm nhận thương hiệu
- Phát hiện Khởi đầu Sản Phẩm: Xác định khi nào đối thủ giới thiệu tính năng mới
- Những Cái Nhìn Chiến Lược: Phân tích vị trí cạnh tranh dựa trên AI
Ví dụ Lệnh:
/search "ra mắt sản phẩm đối thủ" 2024
/trends tên-thương-hiệu-đối-thủ
/crawl https://competitor.com/productsTự Động Hóa Nghiên Cứu Thị Trường
Thông Tin Thị Trường Theo Thời Gian Thực
- Phân Tích Xu Hướng Ngành: Theo dõi tự động xu hướng Google cho các phân khúc thị trường
- Cảm Nhận Người Tiêu Dùng: Phân tích xu hướng tìm kiếm cho các danh mục sản phẩm
- Xác Định Cơ Hội Thị Trường: Phân tích khoảng trống thị trường dựa trên AI
- Nghiên Cứu Đầu Tư: Phân tích xu hướng tài trợ cho các startup và ngành
Ví dụ Lệnh:
/trends "thị trường trí tuệ nhân tạo"
/search "tài trợ cho startup SaaS 2024"
/crawl https://techcrunch.com/category/startupsNghiên Cứu Phát Triển Sản Phẩm
Nghiên Cứu & Xác Thực Tính Năng
- Phân Tích Nhu Cầu Người Dùng: Phân tích xu hướng tìm kiếm cho các tính năng sản phẩm
- Nghiên Cứu Công Nghệ: Tài liệu và nghiên cứu API tự động
- Khám Phá Thực Tiễn Tốt Nhất: Thu thập dữ liệu từ các lãnh đạo ngành về các mẫu thực hiện
- Xác Thực Thị Trường: Phân tích xu hướng cho đánh giá phù hợp giữa sản phẩm và thị trường
Ví dụ Lệnh:
/search "thực tiễn tốt nhất xác thực người dùng"
/trends "tính năng ứng dụng di động"
/crawl https://docs.stripe.com/apiHướng Dẫn Triển Khai
Bước 1: Thiết Lập Không Gian Làm Việc Linear
Chuẩn Bị Môi Trường Linear của Bạn
-
Truy Cập Không Gian Làm Việc Linear của Bạn
- Di chuyển đến linear.app và đăng nhập vào không gian làm việc của bạn
- Đảm bảo bạn có quyền quản trị cho việc cấu hình webhook
- Tạo hoặc chọn một dự án cho tự động hóa nghiên cứu
-
Tạo Mã Token API Linear
- Truy cập Cài Đặt Linear > API > Mã thông báo API cá nhân
- Nhấp "Tạo token" với các quyền thích hợp
- Sao chép mã token để sử dụng trong cấu hình n8n
Bước 2: Thiết Lập Quy Trình n8n
Tạo Môi Trường Tự Động Hóa n8n của Bạn
- Thiết Lập Instance n8n
- Sử dụng n8n cloud hoặc tự-host (lưu ý: việc tự-host yêu cầu thiết lập ngrok; trong hướng dẫn này, chúng ta sẽ sử dụng n8n cloud)
- Tạo một luồng công việc mới cho tích hợp Linear
- Nhập JSON luồng công việc đã cung cấp
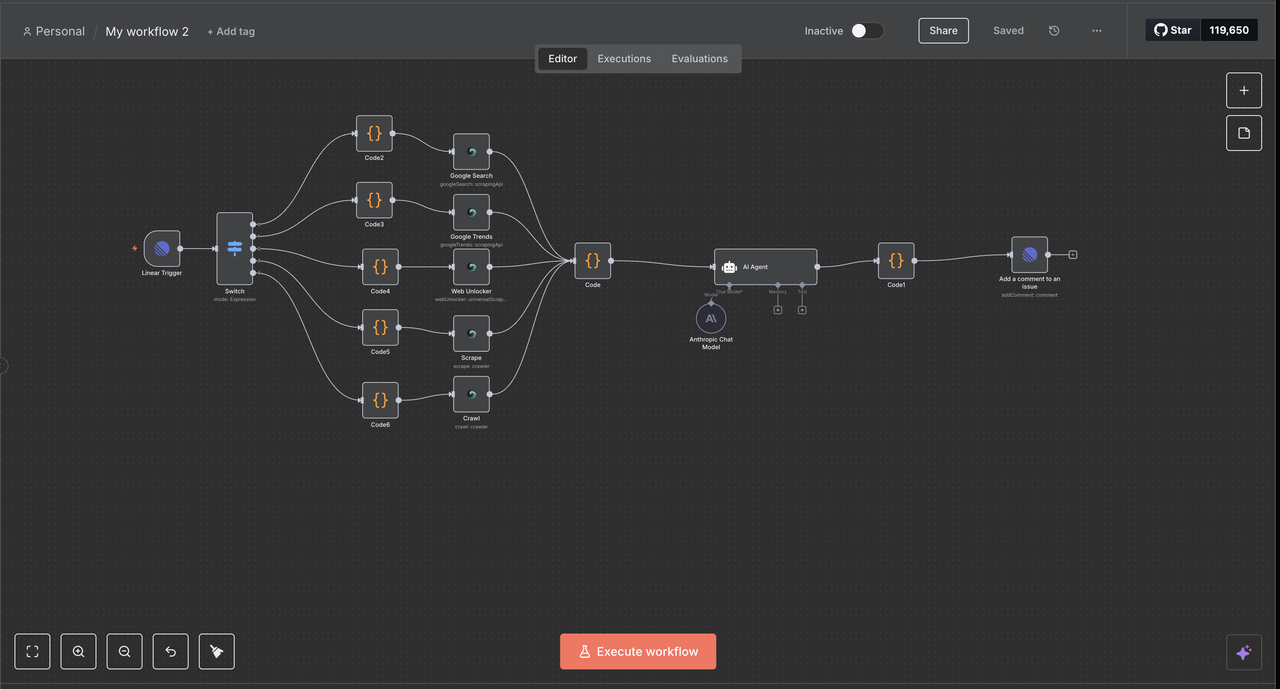
- Cấu Hình Kích Hoạt Linear
- Thêm thông tin xác thực Linear sử dụng mã thông báo API của bạn
- Thiết lập một webhook để lắng nghe sự kiện vấn đề
- Cấu hình ID đội và áp dụng bộ lọc tài nguyên khi cần
Bước 3: Thiết Lập Tích Hợp Scrapeless
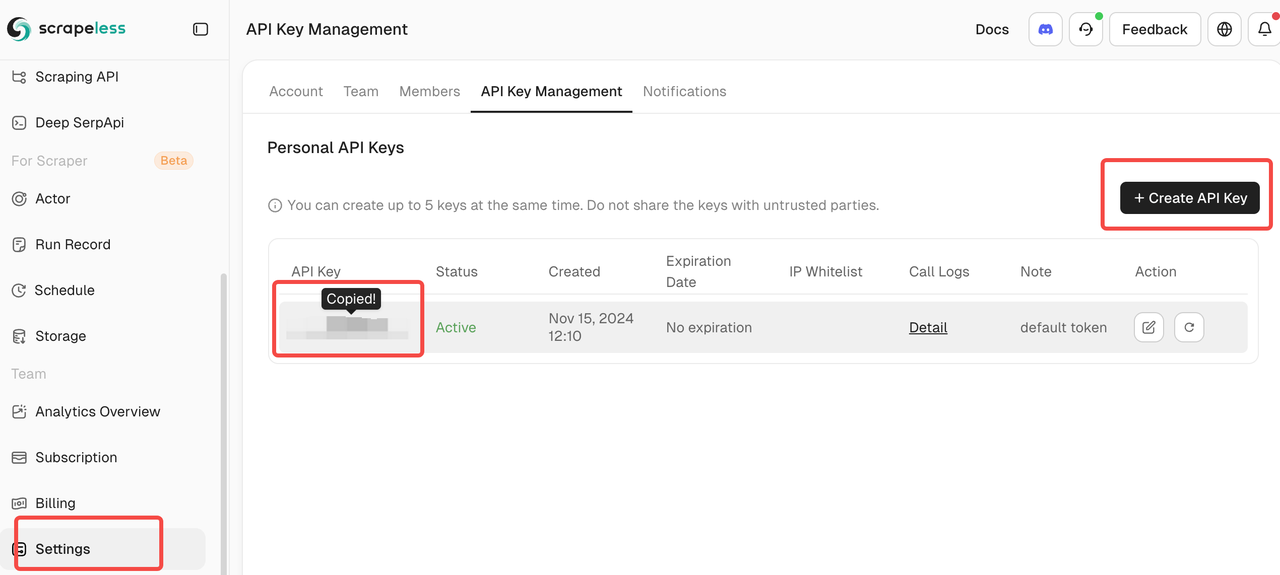
Kết Nối Tài Khoản Scrapeless Của Bạn
- Lấy Thông Tin Xác Thực Scrapeless
- Đăng ký tại scrapeless.com
- Điều hướng đến Bảng Điều Khiển > Khóa API
- Sao chép mã thông báo API của bạn để cấu hình n8n
Hiểu Về Kiến Trúc Luồng Công Việc
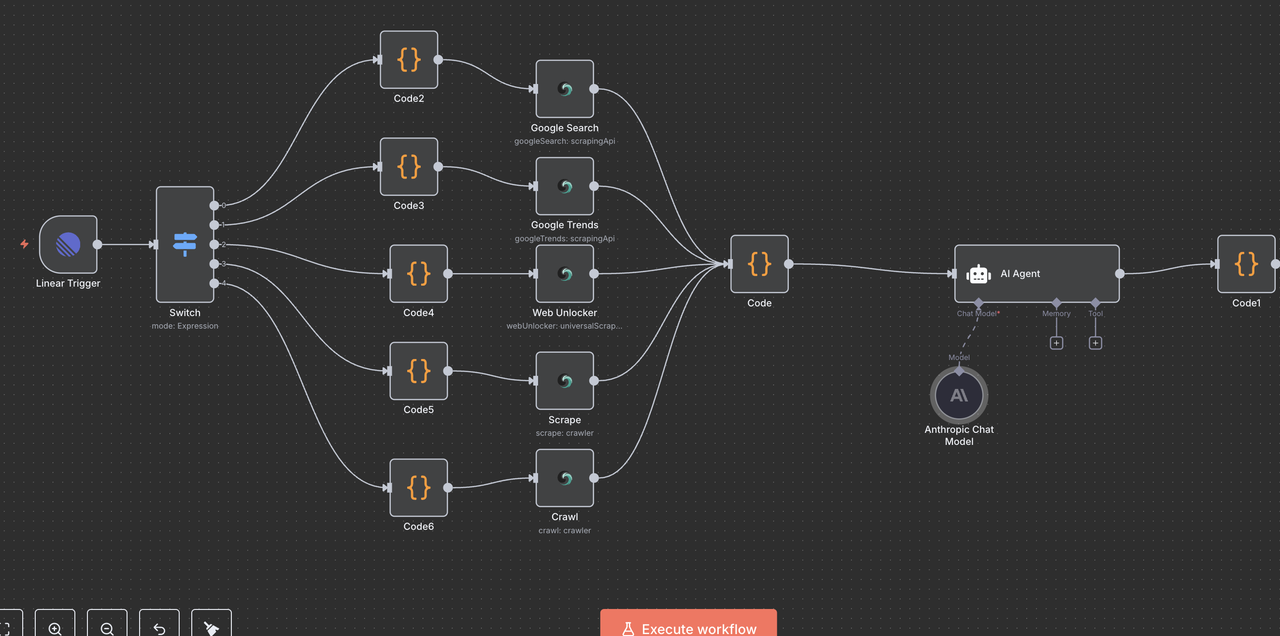
Hãy cùng đi qua từng thành phần của luồng công việc từng bước một, giải thích những gì mỗi nút thực hiện và cách chúng hoạt động cùng nhau.
Bước 4: Nút Kích Hoạt Linear (Điểm Bắt Đầu)
Điểm Bắt Đầu: Kích Hoạt Linear
Kích Hoạt Linear là điểm vào của luồng công việc của chúng tôi. Nút này:
Chức năng:
- Lắng nghe các sự kiện webhook từ Linear mỗi khi vấn đề được tạo hoặc cập nhật
- Ghi lại dữ liệu vấn đề đầy đủ bao gồm tiêu đề, mô tả, ID đội và các siêu dữ liệu khác
- Chỉ kích hoạt khi các sự kiện cụ thể xảy ra (ví dụ: Vấn đề được tạo, Vấn đề được cập nhật, Bình luận được tạo)
Chi tiết cấu hình:
- ID đội: Liên kết đến đội làm việc Linear cụ thể của bạn
- Tài nguyên: Được thiết lập để theo dõi sự kiện
issue,commentvàreaction - URL webhook: Tự động được tạo bởi n8n và phải được thêm vào cài đặt webhook của Linear
Tại sao nó quan trọng:
Nút này biến các vấn đề của bạn trong Linear thành các kích hoạt tự động.
Ví dụ, khi ai đó gõ /search phân tích đối thủ trong tiêu đề vấn đề, webhook sẽ gửi dữ liệu đó đến n8n theo thời gian thực.
Bước 5: Nút Chuyển Đổi (Bộ Lập Lệnh)
Phát Hiện và Chuyển Hướng Lệnh Thông Minh
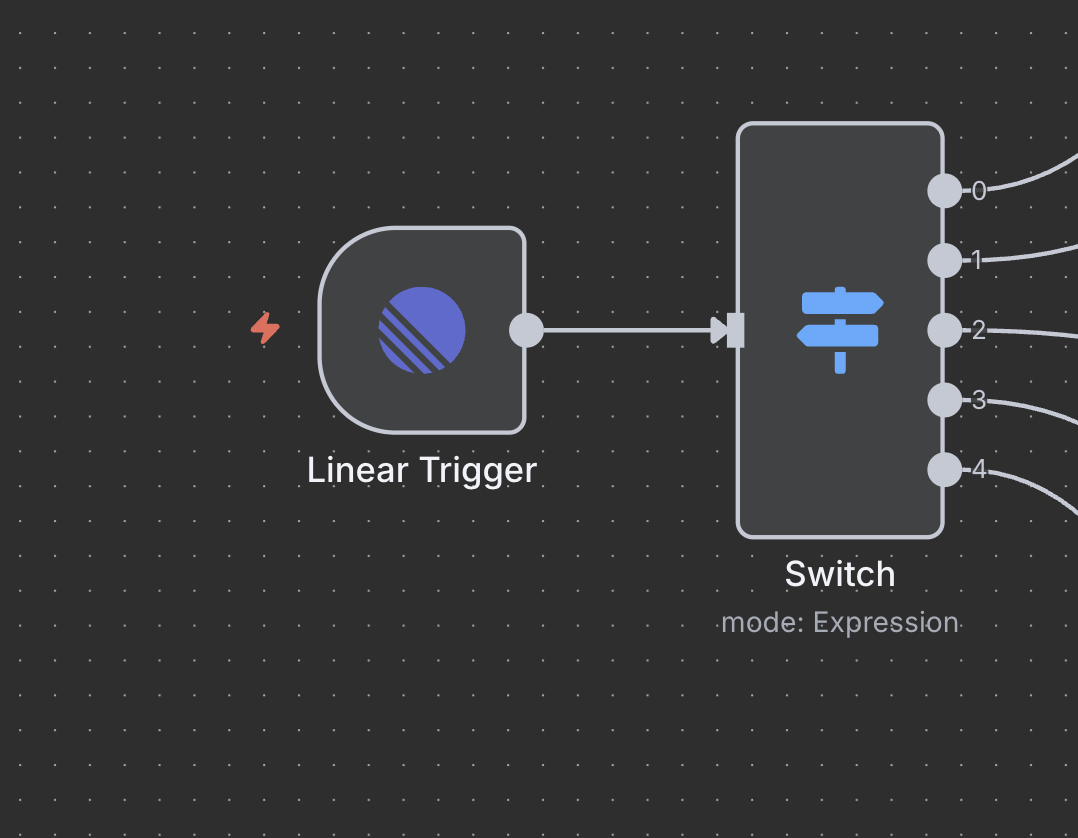
Nút Chuyển Đổi đóng vai trò là “bộ não” xác định loại nghiên cứu nào sẽ thực hiện dựa trên lệnh trong tiêu đề vấn đề.
Cách thức hoạt động:
// Logic phát hiện và chuyển hướng lệnh
{
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/search') ? 0 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/trends') ? 1 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/unlock') ? 2 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/scrape') ? 3 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/crawl') ? 4 :
-1
}Giải Thích Lộ Trình
- Đầu Ra 0 (
/search): Chuyển hướng đến API Tìm Kiếm Google để lấy kết quả tìm kiếm trên web - Đầu Ra 1 (
/trends): Chuyển hướng đến API Xu Hướng Google để phân tích xu hướng - Đầu Ra 2 (
/unlock): Chuyển hướng đến Web Unlocker để truy cập nội dung bị bảo vệ - Đầu Ra 3 (
/scrape): Chuyển hướng đến Scraper để lấy nội dung từ một trang đơn - Đầu Ra 4 (
/crawl): Chuyển hướng đến Crawler để thu thập dữ liệu trên nhiều trang web - Đầu Ra -1: Không phát hiện lệnh, luồng công việc kết thúc tự động
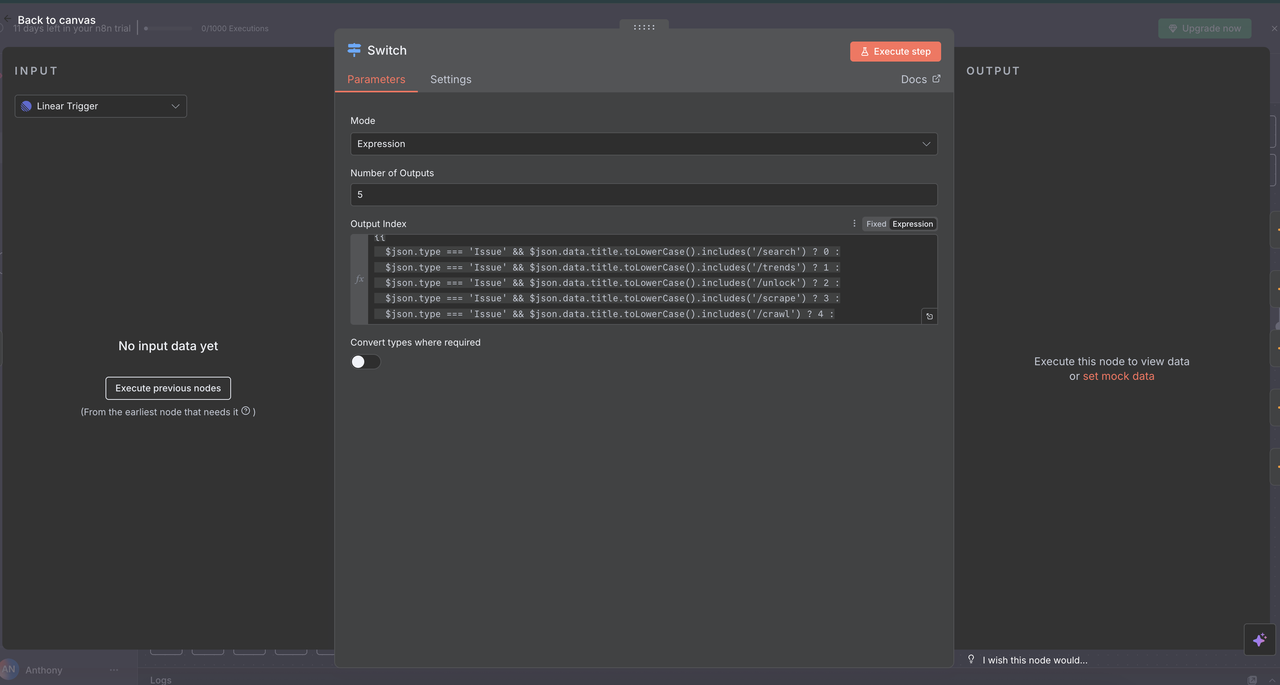
Cấu Hình Nút Chuyển Đổi
- Chế Độ: Được thiết lập thành
"Expression"để chuyển hướng động - Số Lượng Đầu Ra:
5(một cho mỗi loại lệnh) - Biểu Thức: Mã JavaScript xác định logic chuyển hướng
Bước 6: Nút Mã Làm Sạch Tiêu Đề
Chuẩn bị Lệnh cho Xử lý API
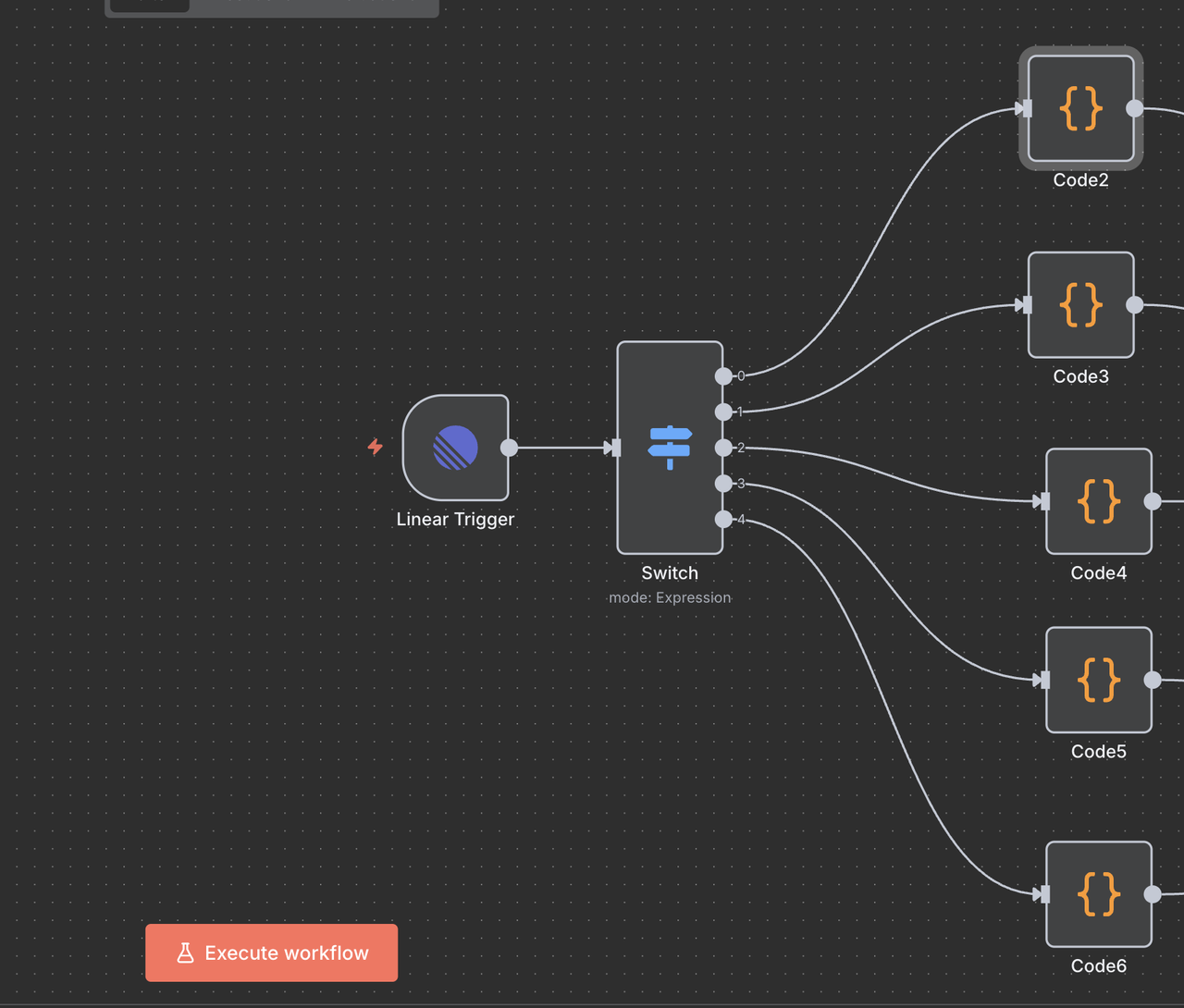
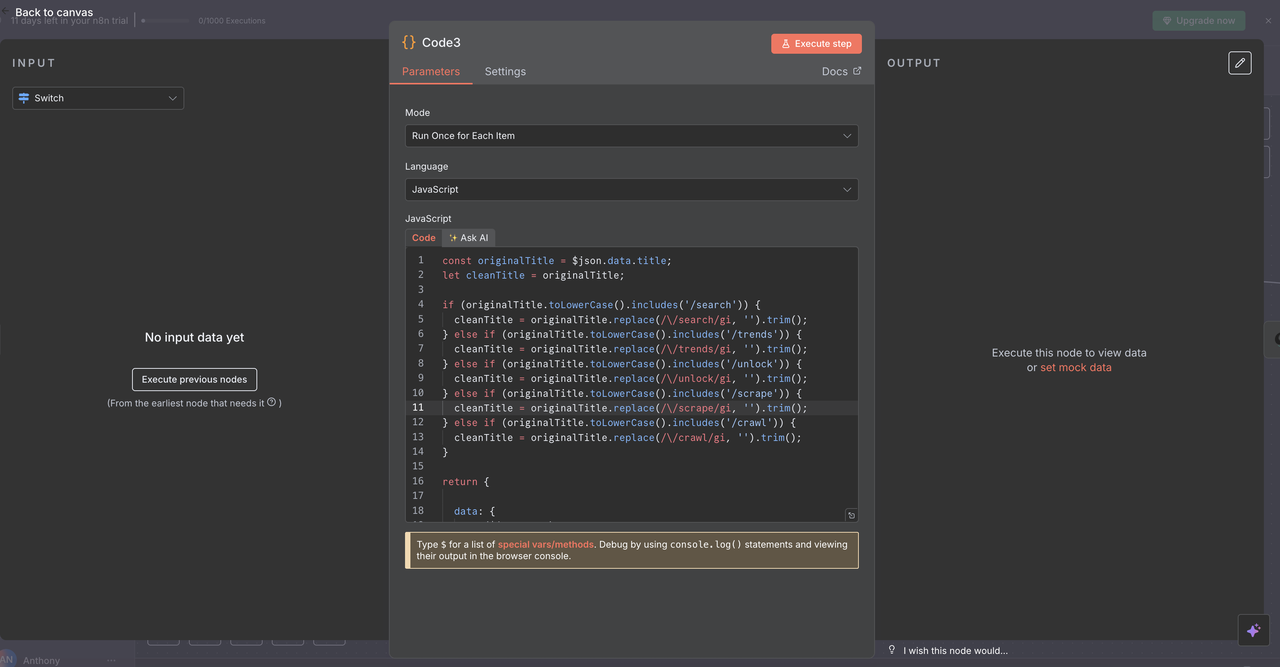
Mỗi route bao gồm một Node Mã để làm sạch lệnh từ tiêu đề vấn đề trước khi gọi các API của Scrapeless.
Những gì mỗi Node Mã làm:
js
// Làm sạch lệnh từ tiêu đề để xử lý API
const originalTitle = $json.data.title;
let cleanTitle = originalTitle;
// Xóa các tiền tố lệnh dựa trên lệnh được phát hiện
if (originalTitle.toLowerCase().includes('/search')) {
cleanTitle = originalTitle.replace(/\/search/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/trends')) {
cleanTitle = originalTitle.replace(/\/trends/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/unlock')) {
cleanTitle = originalTitle.replace(/\/unlock/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/scrape')) {
cleanTitle = originalTitle.replace(/\/scrape/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/crawl')) {
cleanTitle = originalTitle.replace(/\/crawl/gi, '').trim();
}
return {
data: {
...($json.data),
title: cleanTitle
}
};
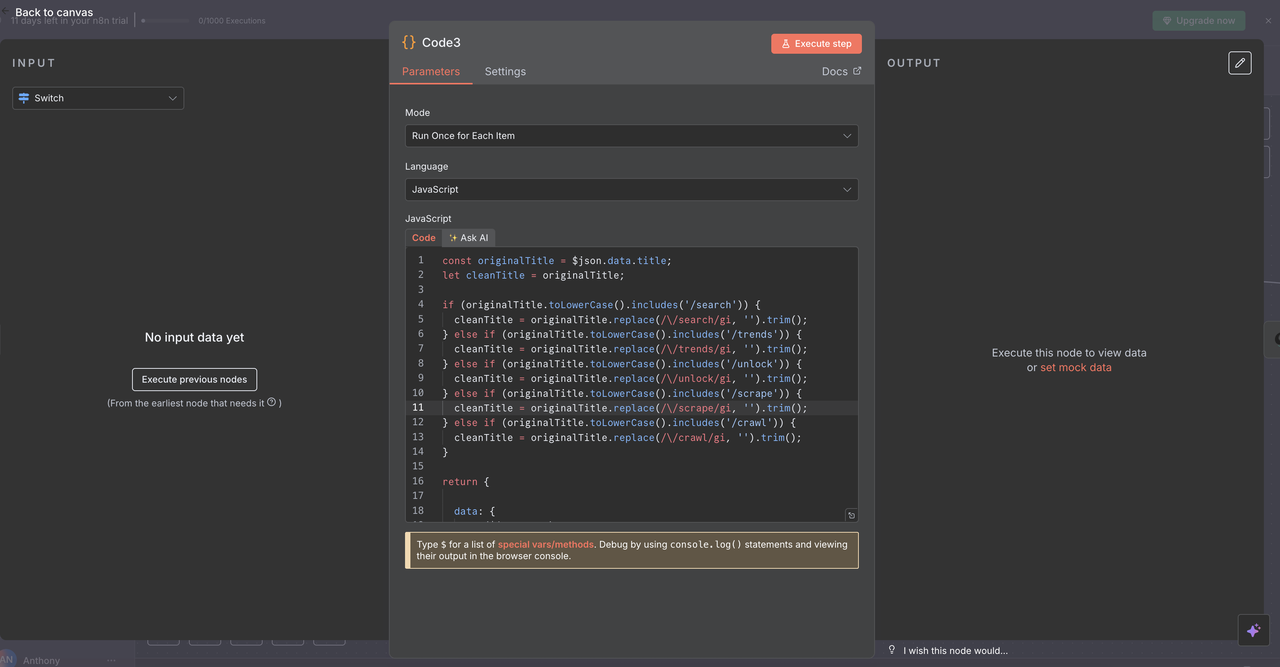
Ví dụ Chuyển đổi
/search phân tích đối thủ→phân tích đối thủ/trends tăng trưởng thị trường AI→tăng trưởng thị trường AI/unlock https://example.com→https://example.com
Tại sao bước này quan trọng
Các API của Scrapeless cần các truy vấn sạch sẽ không có tiền tố lệnh để hoạt động chính xác.
Điều này đảm bảo rằng dữ liệu được gửi đến các API là chính xác và có thể hiểu được, cải thiện độ tin cậy của tự động hóa.
Bước 7: Các Node Hoạt động của Scrapeless
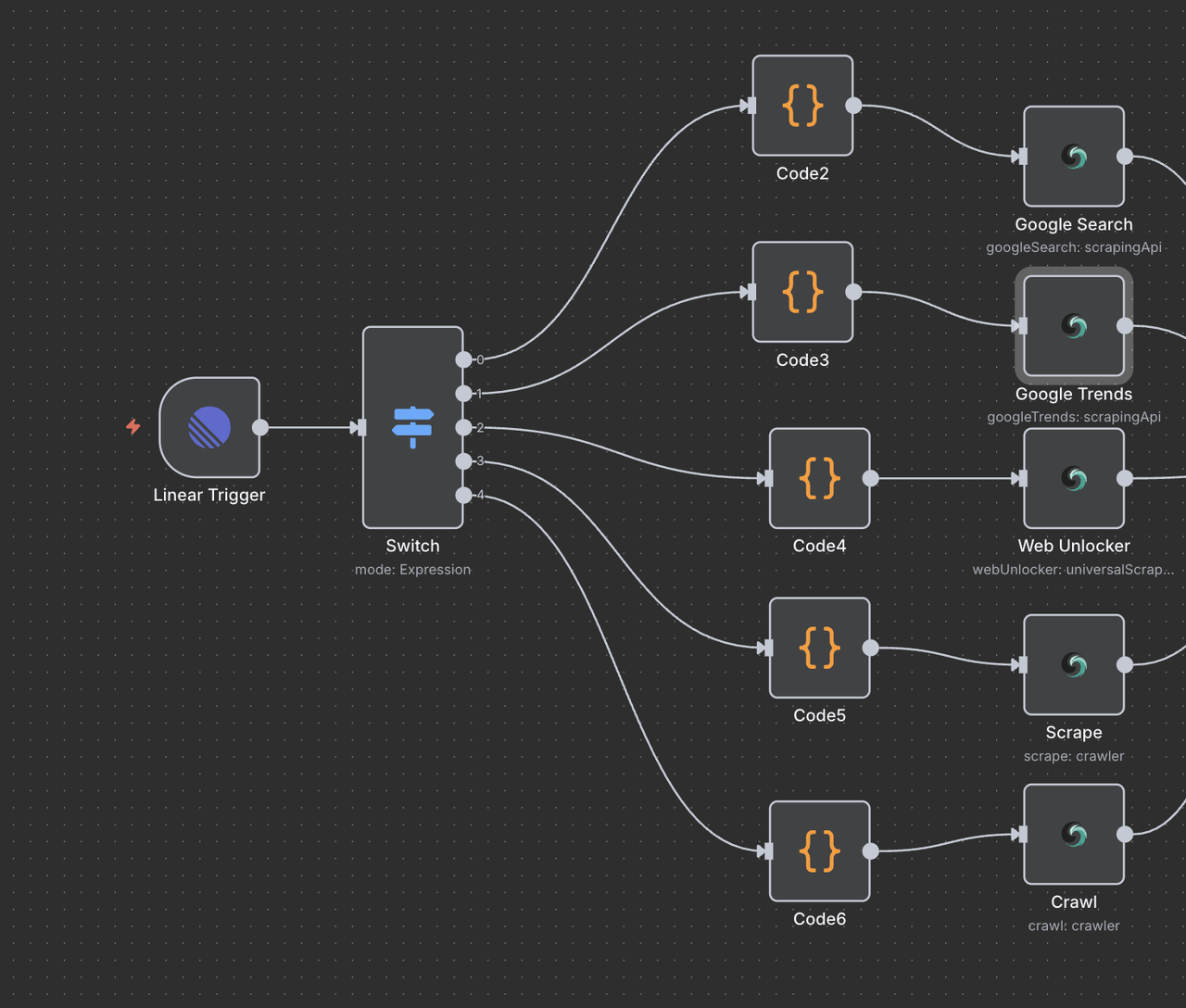
Phần này hướng dẫn từng node hoạt động của Scrapeless và giải thích chức năng của nó.
7.1 Node Tìm kiếm Google (/search lệnh)
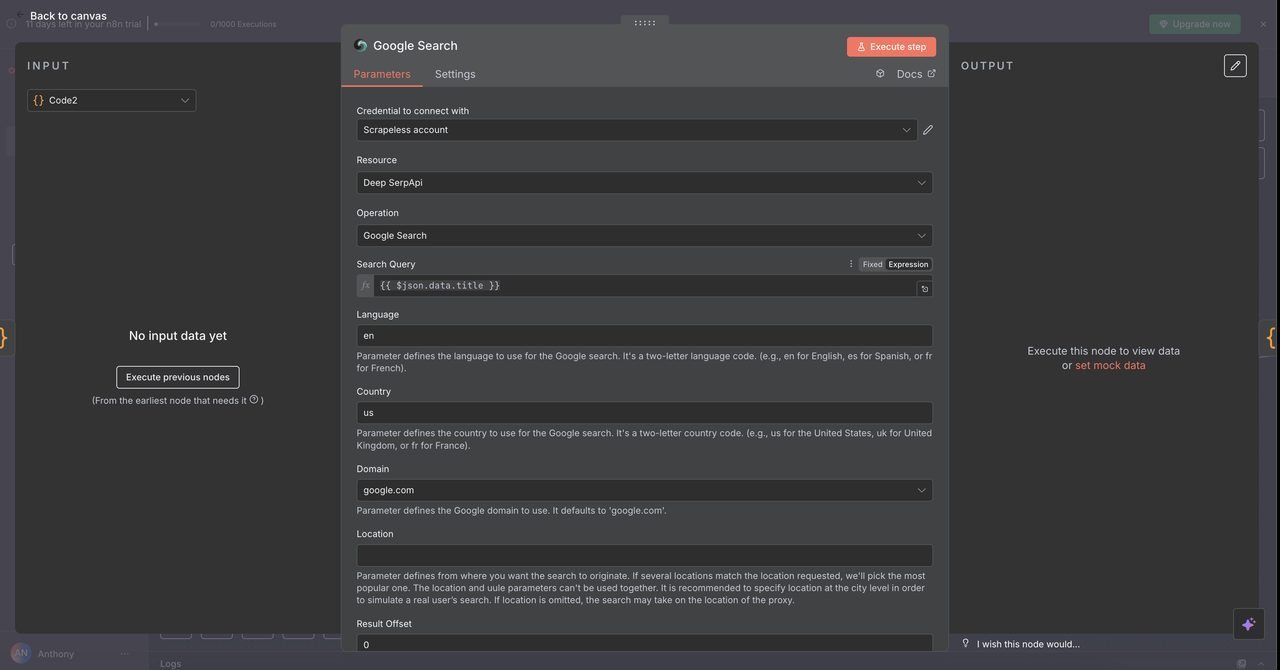
Mục đích:
Thực hiện tìm kiếm web Google và trả về kết quả tìm kiếm tự nhiên.
Cấu hình:
- Hoạt động:
Tìm kiếm Google(mặc định) - Truy vấn:
{{ $json.data.title }}(tiêu đề đã được làm sạch từ bước trước) - Quốc gia:
"US"(có thể tùy chỉnh theo địa phương) - Ngôn ngữ:
"en"(Tiếng Anh)
Những gì nó trả về:
- Kết quả tìm kiếm tự nhiên: Tiêu đề, URL, và đoạn trích
- Các câu hỏi liên quan "Người khác cũng hỏi"
- Siêu dữ liệu: Số lượng kết quả ước tính, thời gian tìm kiếm
Trường hợp sử dụng:
- Nghiên cứu sản phẩm đối thủ
/search chiến lược định giá đối thủ
- Tìm báo cáo ngành
/search báo cáo thị trường SaaS 2024
- Khám phá các phương pháp tốt nhất
/search các phương pháp bảo mật API
7.2 Node Xu hướng Google (/trends lệnh)
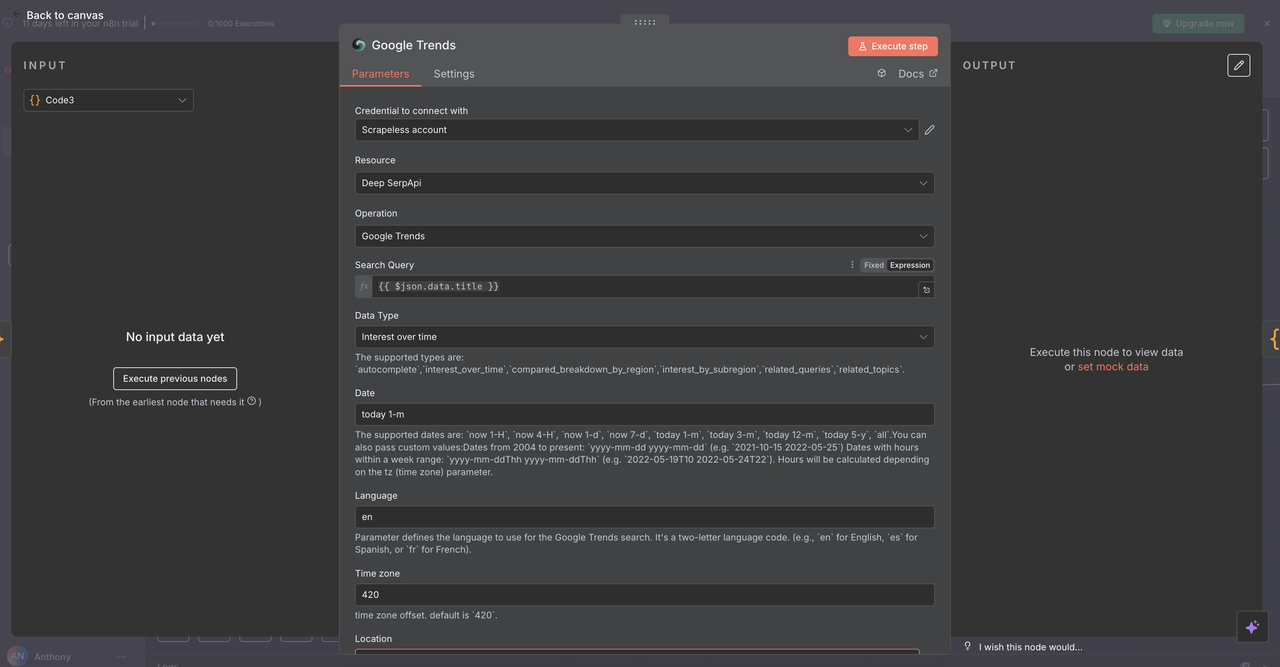
Mục đích:
Phân tích dữ liệu xu hướng tìm kiếm và mức độ quan tâm theo thời gian cho các từ khóa cụ thể.
Cấu hình:
- Hoạt động:
Google Trends - Truy vấn:
{{ $json.data.title }}(từ khóa hoặc cụm từ đã được làm sạch) - Thời gian: Chọn từ các tùy chọn như 1 tháng, 3 tháng, 1 năm
- Địa lý: Đặt là
Toàn cầuhoặc chỉ định một khu vực
Những gì nó trả về:
- Biểu đồ mức độ quan tâm theo thời gian (thang 0–100)
- Các truy vấn liên quan và chủ đề đang xu hướng
- Phân bố địa lý của mức độ quan tâm
- Phân loại theo ngữ cảnh xu hướng
Trường hợp sử dụng:
- Xác thực thị trường
/trends sự chấp nhận xe điện - Phân tích theo mùa
/trends các xu hướng mua sắm kỳ nghỉ - Giám sát thương hiệu
/trends đề cập đến tên công ty
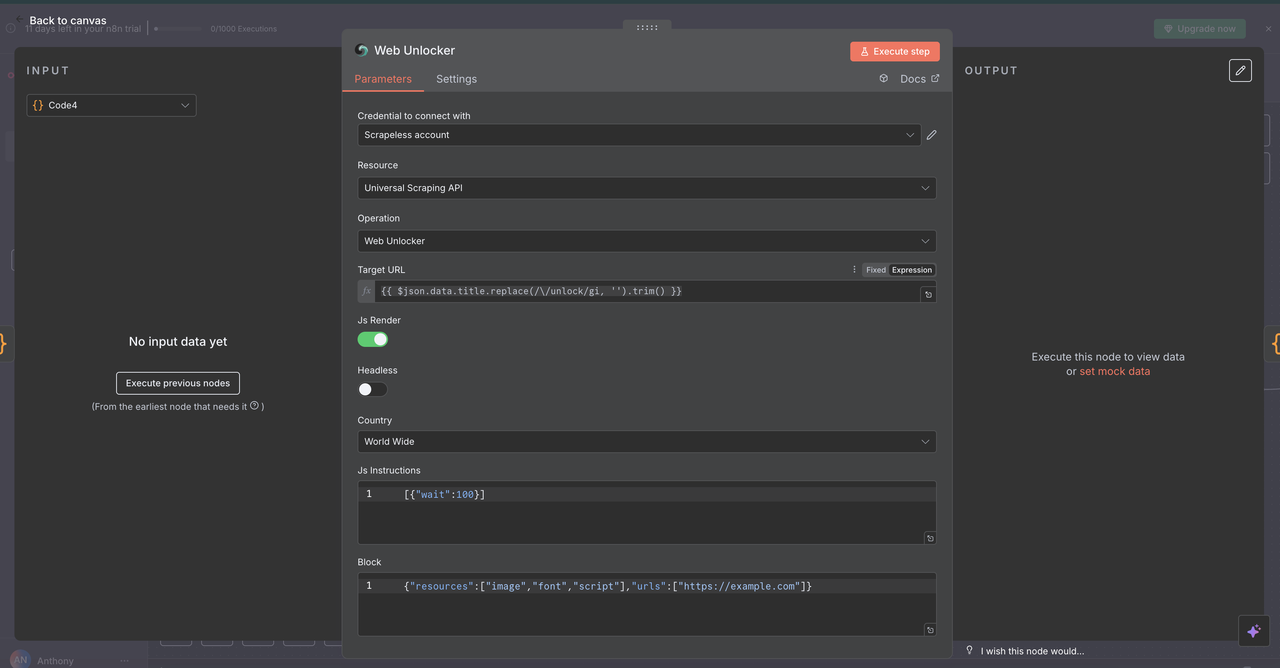
7.3 Node Mở khóa Web (/unlock lệnh)
Mục đích:
Truy cập nội dung từ các trang web được bảo vệ bởi cơ chế chống bot hoặc tường thu phí.
Cấu hình:
- Tài nguyên:
API thu thập dữ liệu phổ quát - URL:
{{ $json.data.title }}(phải chứa một URL hợp lệ) - Không giao diện:
false(để tương thích tốt hơn với chống bot) - Kết xuất JavaScript:
enabled(để tải nội dung động hoàn chỉnh)
Những gì nó trả về:
- Nội dung HTML hoàn chỉnh của trang
- Nội dung cuối được kết xuất bằng JavaScript
- Khả năng vượt qua các biện pháp bảo vệ chống bot phổ biến
Trường hợp sử dụng:
- Phân tích giá cả đối thủ
/unlock https://competitor.com/pricing - Truy cập nghiên cứu bị rào
/unlock https://research-site.com/report - Thu thập dữ liệu từ ứng dụng động
/unlock https://spa-application.com/data
7.4 Node Thu thập dữ liệu (/scrape lệnh)
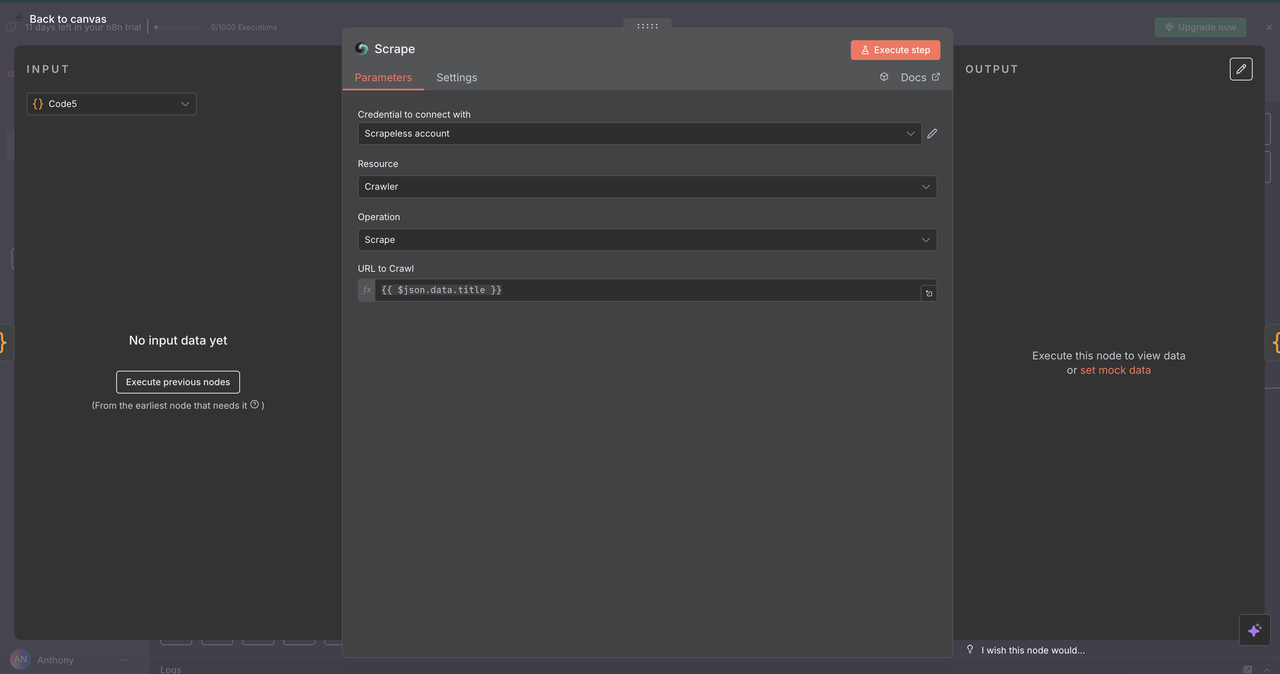
Mục đích:
Trích xuất nội dung có cấu trúc từ một trang web duy nhất bằng cách sử dụng các bộ chọn hoặc phân tích mặc định.
Cấu hình:
- Tài nguyên:
Crawler(được sử dụng ở đây cho việc thu thập dữ liệu trên một trang) - URL:
{{ $json.data.title }}(trang web mục tiêu) - Định dạng: Chọn đầu ra là
HTML,Text, hoặcMarkdown - Bộ chọn: Bộ chọn CSS tùy chọn để nhắm mục tiêu nội dung cụ thể
Kết quả trả về:
- Văn bản có cấu trúc, sạch sẽ từ trang
- Siêu dữ liệu trang (tiêu đề, mô tả, v.v.)
- Mặc định không bao gồm điều hướng/quảng cáo
Trường hợp sử dụng:
- Trích xuất bài báo tin tức
/scrape https://news-site.com/article - Phân tích tài liệu API
/scrape https://api-docs.com/endpoint - Thu thập thông tin sản phẩm
/scrape https://product-page.com/item
7.5 Nút Crawler (/crawl command)
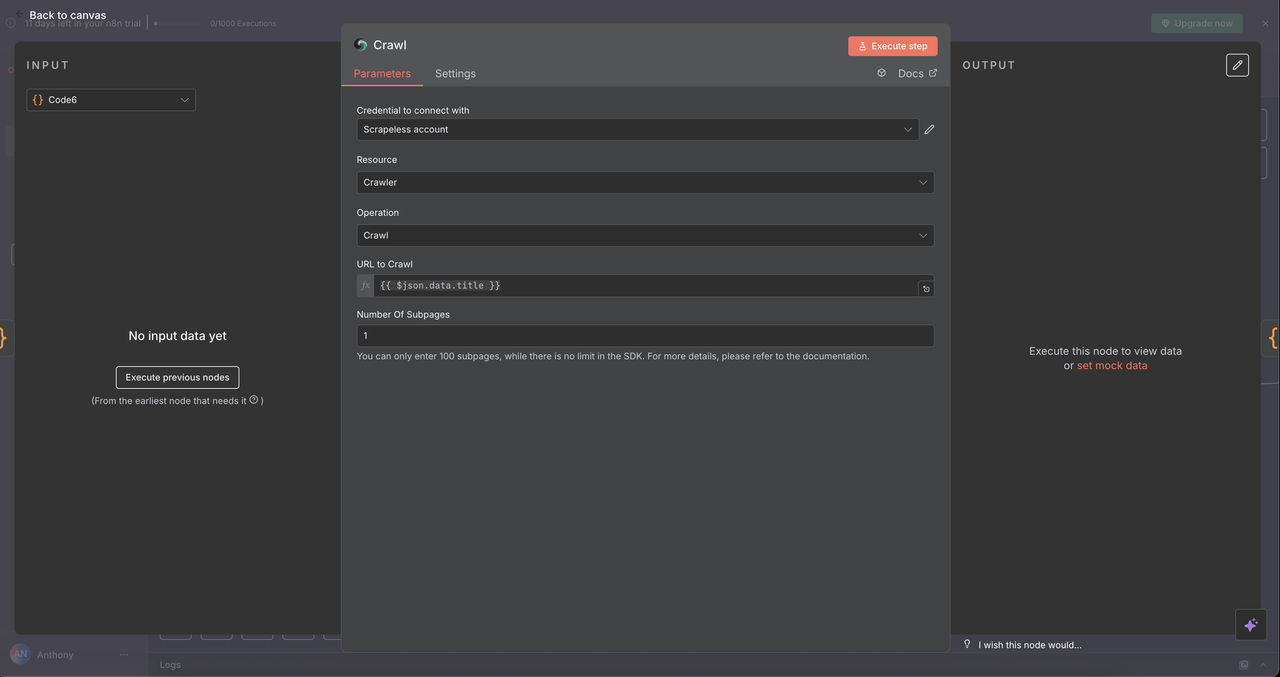
Mục đích:
Crawl có hệ thống nhiều trang của một trang web để trích xuất dữ liệu toàn diện.
Cấu hình:
- Tài nguyên:
Crawler - Hoạt động:
Crawl - URL:
{{ $json.data.title }}(URL bắt đầu) - Giới hạn số trang Crawl: Giới hạn tùy chọn, ví dụ 5–10 trang để tránh quá tải
- Mẫu Bao gồm/Loại trừ: Bộ lọc regex hoặc chuỗi để tinh chỉnh phạm vi crawl
Kết quả trả về:
- Nội dung từ nhiều trang liên quan
- Cấu trúc điều hướng của trang web
- Bộ dữ liệu phong phú trên miền/tên miền mục tiêu
Trường hợp sử dụng:
-
Nghiên cứu đối thủ
/crawl https://competitor.com
(ví dụ: giá cả, tính năng, trang giới thiệu) -
Lập bản đồ tài liệu
/crawl https://docs.api.com
(crawl toàn bộ tài liệu API hoặc tài liệu dành cho nhà phát triển) -
Kiểm toán nội dung
/crawl https://blog.company.com
(lập bản đồ bài viết, danh mục, thẻ để xem xét SEO)
Bước 8: Hội tụ và Xử lý Dữ liệu
Tổng hợp tất cả kết quả Scrapeless
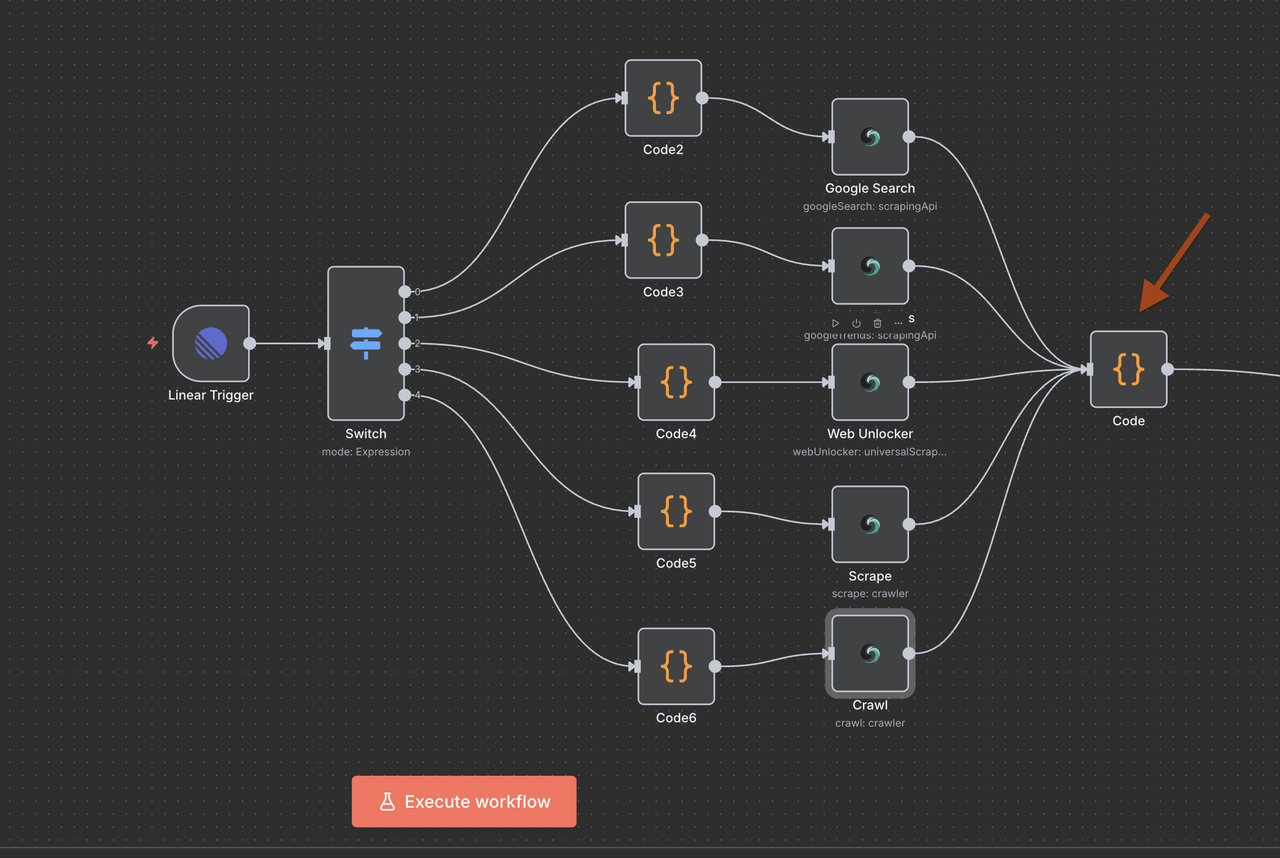
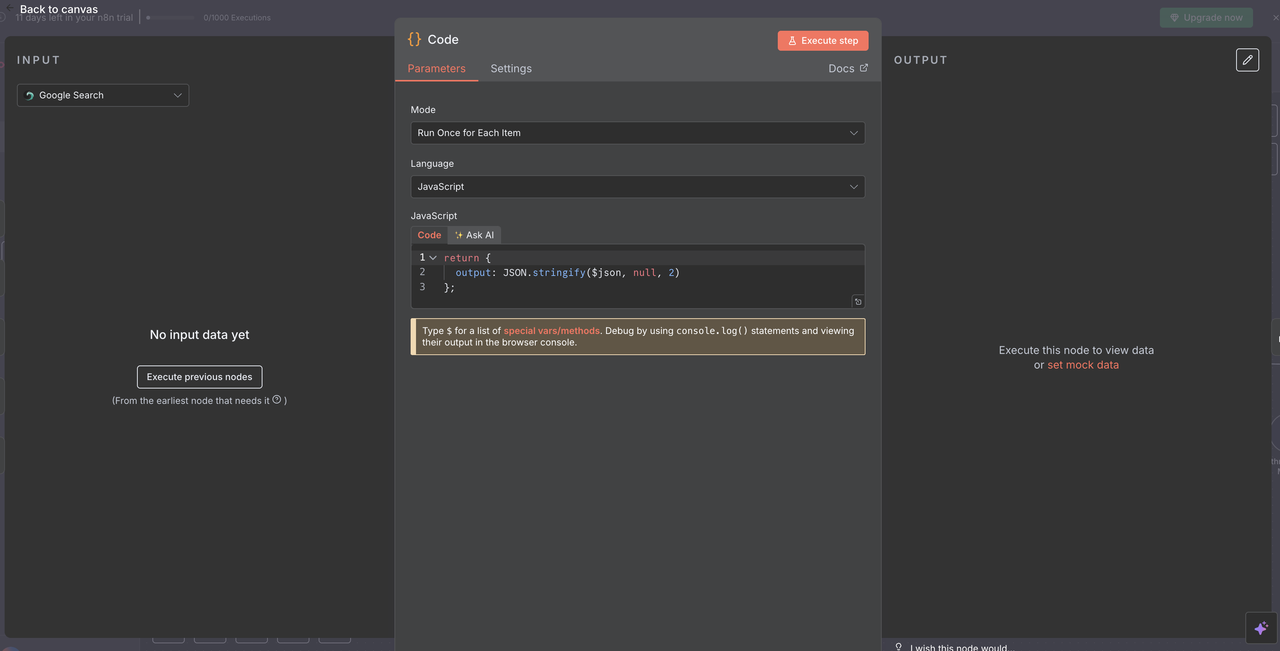
Sau khi thực hiện một trong 5 nhánh thao tác Scrapeless, một Nút Code duy nhất được sử dụng để chuẩn hóa phản hồi cho quá trình xử lý AI.
Mục đích của Nút Code Hội tụ:
- Tổng hợp đầu ra từ bất kỳ nút Scrapeless nào
- Chuẩn hóa định dạng dữ liệu trên tất cả các lệnh
- Chuẩn bị tải trọng cuối cùng cho Claude hoặc đầu vào của mô hình AI khác
Cấu hình Code:
javascript
// Chuyển đổi phản hồi Scrapeless sang định dạng có thể đọc bởi AI
return {
output: JSON.stringify($json, null, 2)
};
Bước 9: Công cụ Phân tích AI Claude
Phân tích Dữ liệu Thông minh và Tạo ra Insight
9.1 Thiết lập Nút Đại diện AI
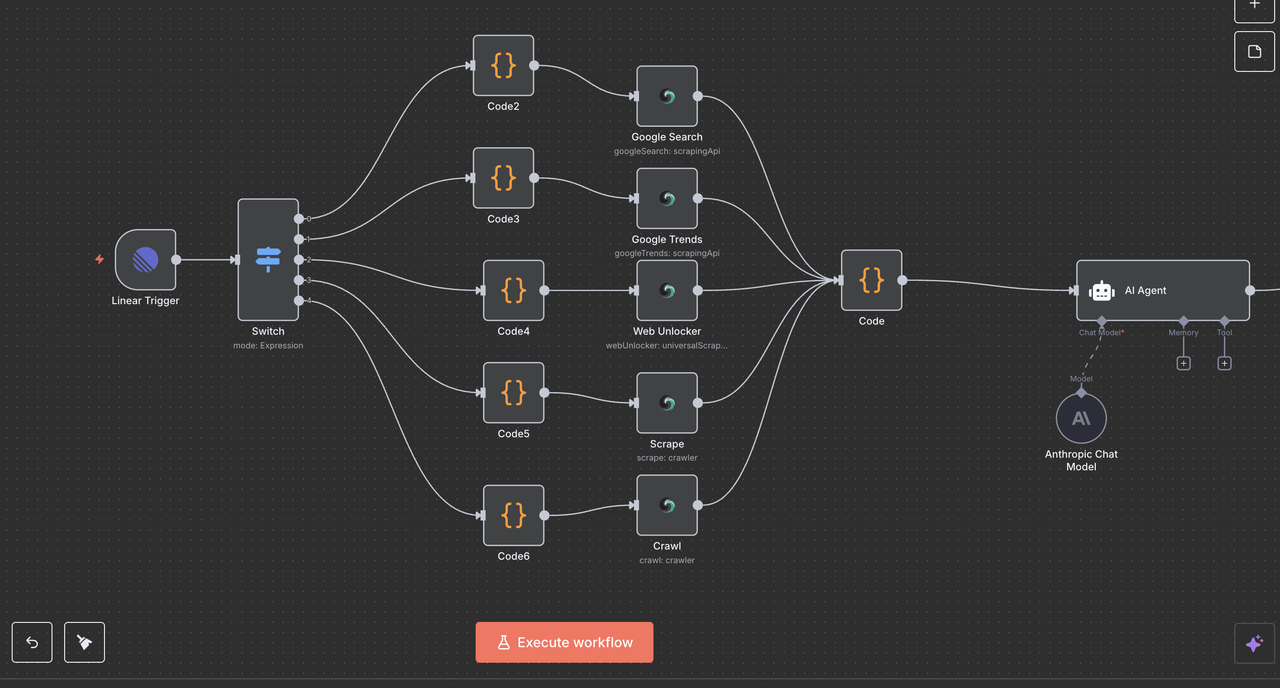
⚠️ Đừng quên thiết lập khóa API cho Claude.
Nút Đại diện AI là nơi mà sự kỳ diệu xảy ra — nó lấy đầu ra chuẩn hóa từ Scrapeless và biến nó thành những hiểu biết rõ ràng, có thể hành động phù hợp để sử dụng trong các nhận xét Linear hoặc các công cụ báo cáo khác.
Chi tiết cấu hình:
- Loại Đề xuất:
Định nghĩa - Nhập văn bản:
{{ $json.output }}(chuỗi JSON đã xử lý từ nút hội tụ) - Tin nhắn Hệ thống: Thiết lập tông, vai trò và nhiệm vụ cho Claude
Đề xuất Phân tích AI:
Bạn là một nhà phân tích dữ liệu. Tóm tắt kết quả tìm kiếm/thu thập dữ liệu một cách ngắn gọn. Cung cấp thông tin và ngắn gọn. Định dạng cho các nhận xét Linear.
Phân tích dữ liệu được cung cấp và tạo ra một tóm tắt có cấu trúc bao gồm:
- Những phát hiện và hiểu biết chính
- Nguồn dữ liệu và đánh giá độ tin cậy
- Các khuyến nghị có thể hành động
- Các số liệu và xu hướng liên quan
- Các bước tiếp theo cho nghiên cứu thêm
Định dạng phản hồi của bạn với tiêu đề rõ ràng và dấu đầu dòng để dễ đọc trong Linear.
Tại sao đề xuất này hiệu quả
- Sự cụ thể: Nói rõ cho Claude biết loại phân tích nào cần thực hiện
- Cấu trúc: Yêu cầu đầu ra có tổ chức với các phần rõ ràng
- Bối cảnh: Tối ưu hóa cho định dạng nhận xét Linear
- Có thể hành động: Tập trung vào những hiểu biết mà các nhóm có thể hành động
9.2 Cấu hình Mô hình Claude
Nút Mô hình Chat của Anthropic kết nối Đại diện AI với khả năng xử lý ngôn ngữ mạnh mẽ của Claude.
Lựa chọn Mô hình và Tham số
- Mô hình:
claude-3-7-sonnet-20250219(Claude Sonnet 3.7) - Nhiệt độ:
0.3(cân bằng giữa sự sáng tạo và tính nhất quán) - Số lượng tối đa token:
4000(đủ cho các phản hồi toàn diện)
Tại Sao Những Cài Đặt Này
- Claude Sonnet 3.7: Cân bằng mạnh mẽ giữa trí tuệ, hiệu suất và chi phí hiệu quả
- Nhiệt độ thấp (0.3): Đảm bảo các phản hồi chính xác, có thể lặp lại
- 4000 token: Đủ để tạo ra cái nhìn sâu sắc mà không tốn kém quá nhiều
Bước 10: Xử Lý và Dọn Dẹp Phản Hồi
Chuẩn Bị Đầu Ra của Claude cho Các Bình Luận Theo Dòng
10.1 Mã Dọn Dẹp Phản Hồi
Nút mã sau khi Claude dọn dẹp phản hồi AI để hiển thị đúng cách trong các bình luận theo dòng.
Mã Dọn Dẹp Phản Hồi:
// Dọn dẹp phản hồi AI của Claude cho các bình luận theo dòng
return {
output: $json.output
.replace(/\\n/g, '\n')
.replace(/\\\"/g, '"')
.replace(/\\\\/g, '\\')
.trim()
};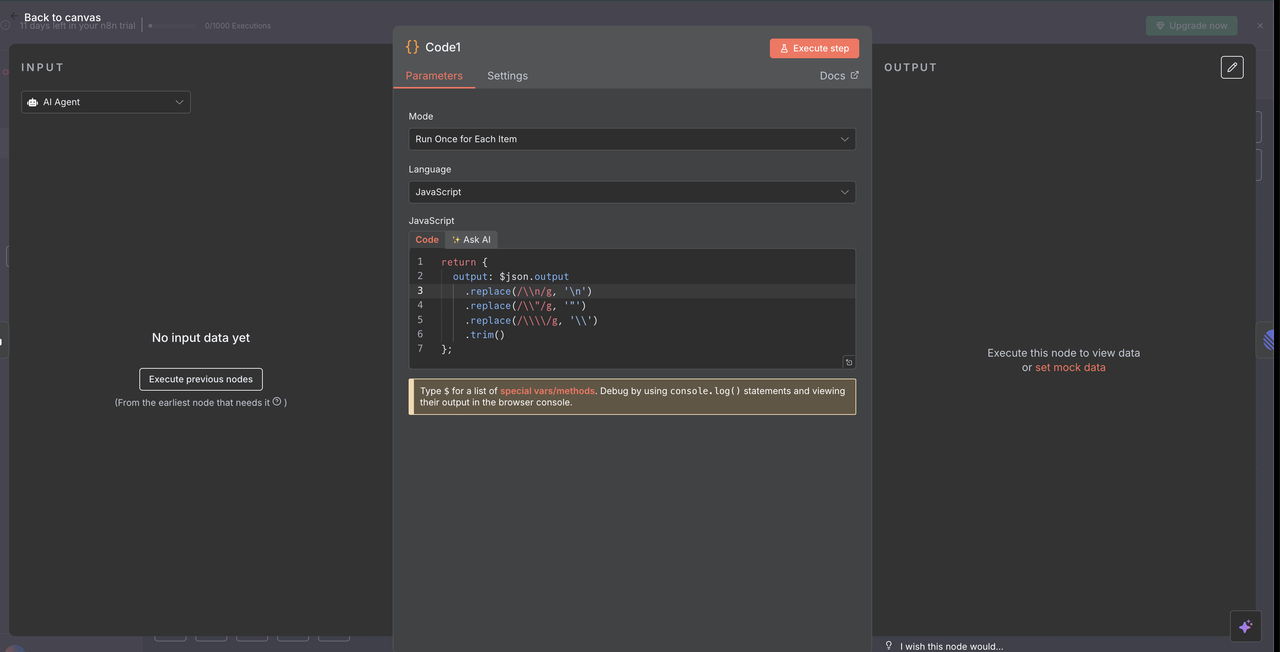
Những Gì Dọn Dẹp Này Đạt Được
- Gỡ bỏ Ký Tự Escape: Loại bỏ ký tự escape JSON mà nếu không sẽ hiển thị không chính xác
- Sửa Lỗi Ngắt Dòng: Chuyển đổi các chuỗi
\nthành các ngắt dòng thực sự - Chuẩn Hóa Dấu Nháy: Đảm bảo dấu nháy hiển thị đúng trong các bình luận theo dòng
- Cắt Bỏ Khoảng Trắng: Loại bỏ các khoảng trắng không cần thiết ở đầu và cuối
Tại Sao Việc Dọn Dẹp Là Cần Thiết
- Đầu ra của Claude được cung cấp dưới dạng JSON, điều này gán các ký tự đặc biệt
- Bộ định dạng markdown của Linear yêu cầu văn bản thuần túy được định dạng đúng
- Nếu không có bước dọn dẹp này, phản hồi sẽ hiển thị các ký tự escape thô, ảnh hưởng đến khả năng đọc
10.2 Giao Hàng Bình Luận Theo Dòng
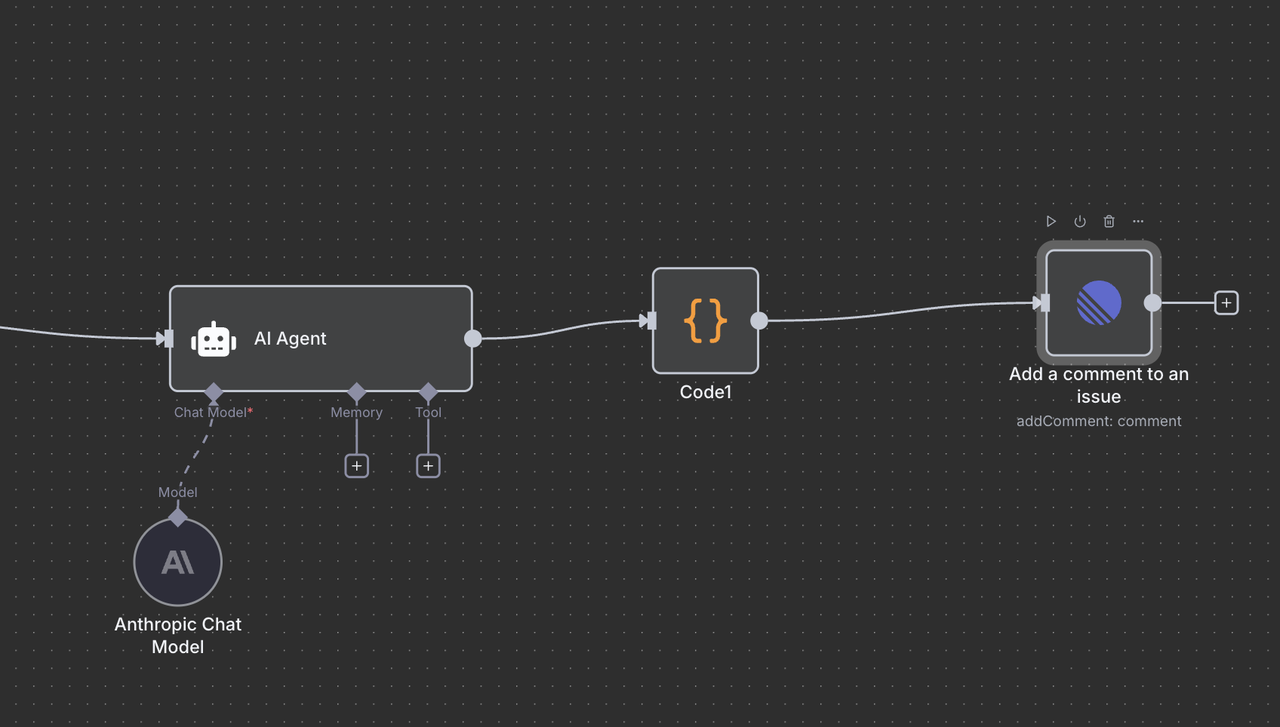
Nút Linear Cuối Cùng đăng tải phân tích do AI tạo ra dưới dạng bình luận trở lại vấn đề ban đầu.
Chi Tiết Cấu Hình:
- Tài Nguyên: Đặt thành thao tác
"Comment" - ID Vấn Đề:
{{ $('Linear Trigger').item.json.data.id }} - Bình Luận:
{{ $json.output }} - Trường Thêm: Có thể bao gồm siêu dữ liệu hoặc tùy chọn định dạng
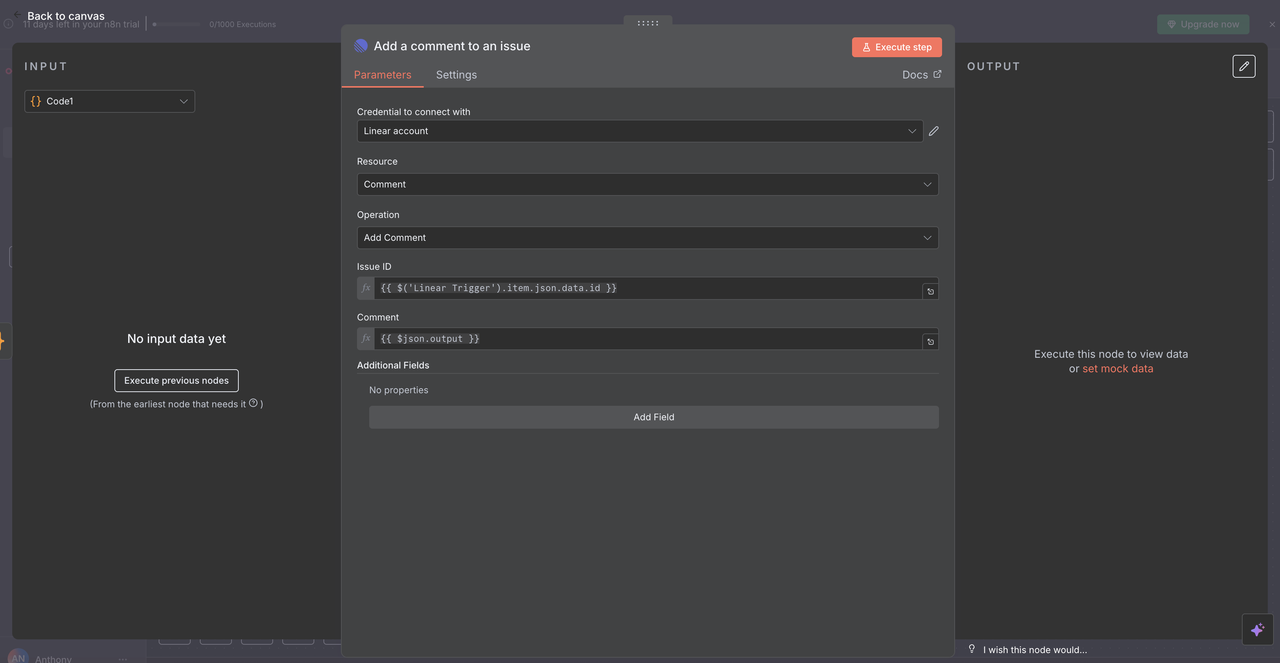
Cách ID Vấn Đề Hoạt Động
- Tham chiếu đến nút Linear Trigger ban đầu
- Sử dụng chính xác ID vấn đề từ webhook đã khởi động quy trình làm việc
- Đảm bảo phản hồi AI xuất hiện trên vấn đề Linear đúng
Vòng Tròn Hoàn Chỉnh
- Người dùng tạo một vấn đề với
/search competitive analysis - Quy trình làm việc xử lý lệnh và thu thập dữ liệu
- Claude phân tích kết quả đã thu thập
- Phân tích được đăng trở lại dưới dạng bình luận trên cùng một vấn đề
- Nhóm thấy những cái nhìn nghiên cứu trực tiếp trong ngữ cảnh
Bước 11: Kiểm Tra Trợ Lý Nghiên Cứu Của Bạn
Xác Nhận Quy Trình Làm Việc Hoàn Chỉnh
Bây giờ mà tất cả các nút đã được cấu hình, hãy kiểm tra từng loại lệnh để đảm bảo chức năng đúng cách.
11.1 Kiểm Tra Từng Loại Lệnh
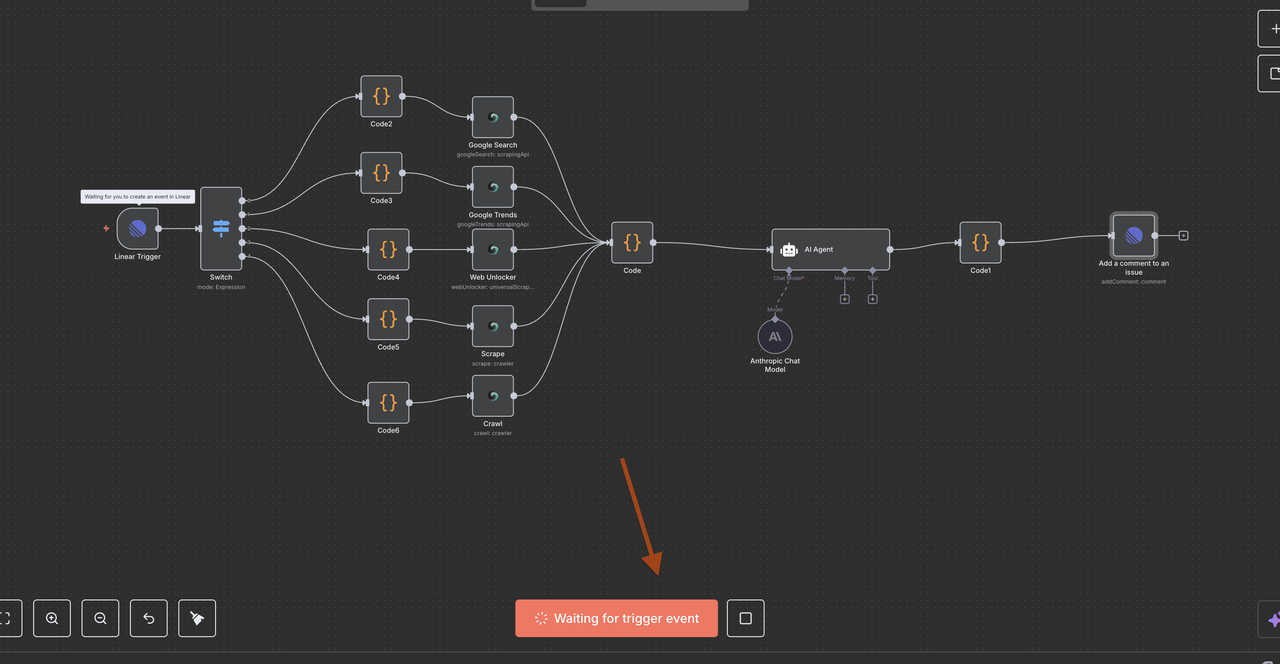
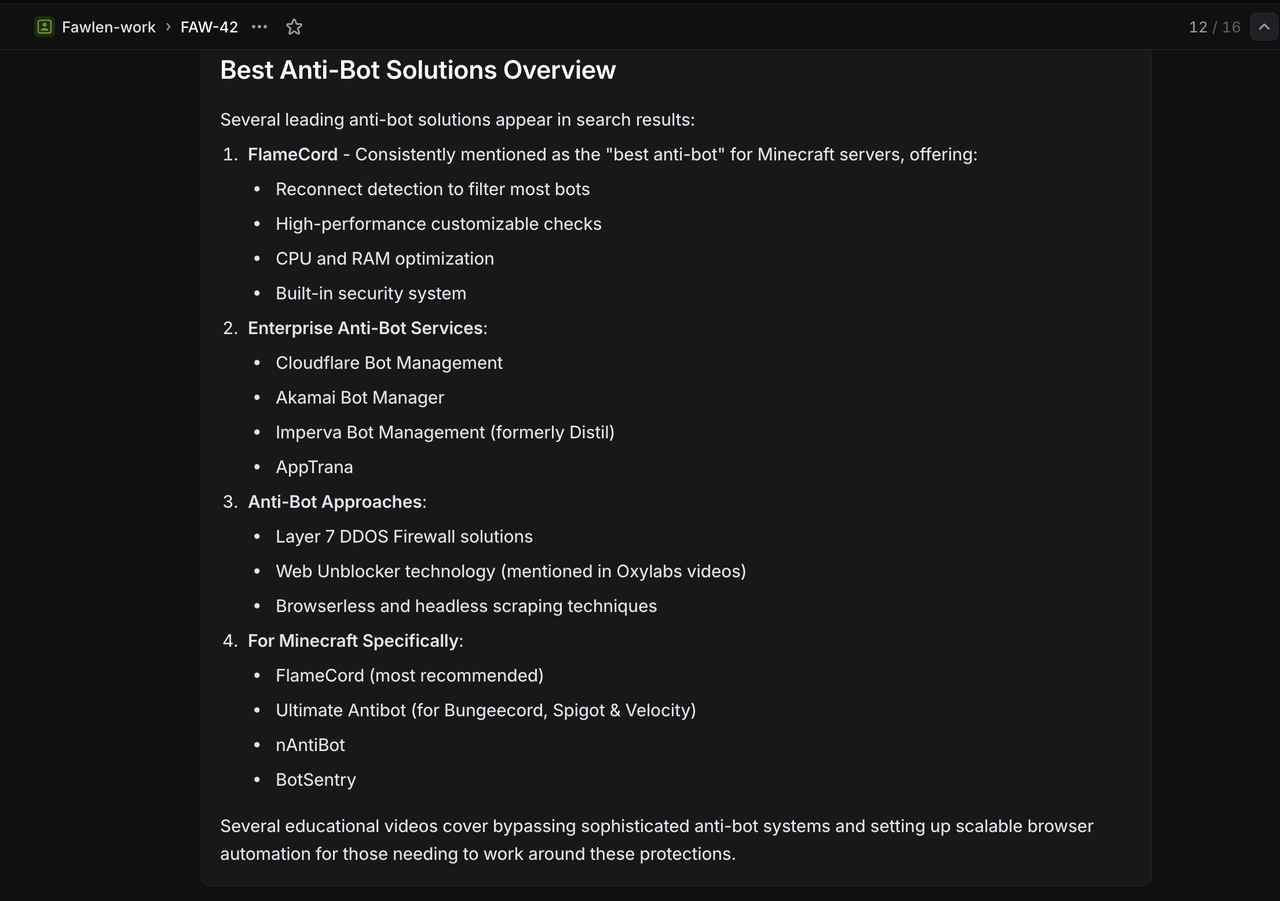
Tạo Các Vấn Đề Kiểm Tra Trong Linear với Những Tiêu Đề Cụ Thể Này:
Kiểm Tra Tìm Kiếm Google:
`/search competitive analysis for SaaS platforms` Kết Quả Mong Đợi: Trả về kết quả tìm kiếm Google về phân tích cạnh tranh trong SaaS
Kiểm Tra Xu Hướng Google:
`/trends artificial intelligence adoption` Kết Quả Mong Đợi: Trả về dữ liệu xu hướng cho thấy sự quan tâm đến việc áp dụng AI theo thời gian
Kiểm Tra Mở Khóa Web:
`/unlock https://competitor.com/pricing` Kết Quả Mong Đợi: Trả về nội dung từ một trang định giá được bảo vệ hoặc trang nặng JavaScript
Kiểm Tra Chương Trình Quét:
`/scrape https://news.ycombinator.com` Kết Quả Mong Đợi: Trả về nội dung có cấu trúc từ trang chính của Hacker News
Kiểm Tra Dò Sát:
`/crawl https://docs.anthropic.com` Kết Quả Mong Đợi: Trả về nội dung từ nhiều trang trong tài liệu của Anthropic
Hướng Dẫn Xử Lý Sự Cố
Vấn Đề Webhook Linear
- Vấn Đề: Webhook không kích hoạt
- Giải Pháp: Xác minh URL webhook và quyền Linear
- Kiểm Tra: Tình trạng điểm cuối webhook n8n
Lỗi API Scrapeless
- Vấn Đề: Lỗi xác thực
- Giải Pháp: Xác minh khóa API và giới hạn tài khoản
- Kiểm Tra: Bảng điều khiển Scrapeless để theo dõi mức sử dụng
Vấn đề Phản hồi AI Claude
- Vấn đề: Phân tích kém hoặc chưa đầy đủ
- Giải pháp: Cải thiện yêu cầu hệ thống và ngữ cảnh
- Kiểm tra: Chất lượng và định dạng dữ liệu đầu vào
Định dạng Nhận xét Tuyến tính
- Vấn đề: Markdown hoặc định dạng bị hỏng
- Giải pháp: Cập nhật mã làm sạch phản hồi
- Kiểm tra: Xử lý ký tự đặc biệt
Kết luận
Sự kết hợp của không gian làm việc cộng tác của Linear, tính năng trích xuất dữ liệu đáng tin cậy của Scrapeless, và phân tích thông minh của Claude AI tạo ra một hệ thống tự động hóa nghiên cứu mạnh mẽ, biến đổi cách đội ngũ thu thập và xử lý thông tin.
Tích hợp này loại bỏ sự cản trở giữa việc xác định nhu cầu nghiên cứu và thu thập thông tin có thể hành động. Chỉ với việc nhập lệnh trong các vấn đề của Linear, đội ngũ của bạn có thể kích hoạt các quy trình thu thập và phân tích dữ liệu toàn diện, điều mà trước đây sẽ yêu cầu hàng giờ làm việc thủ công.
Lợi ích Chính
- ⚡ Nghiên cứu Nhanh chóng: Từ câu hỏi đến thông tin trong chưa đầy 60 giây
- 🎯 Bảo tồn Ngữ cảnh: Nghiên cứu vẫn liên kết với các thảo luận dự án
- 🧠 Tăng cường AI: Dữ liệu thô trở thành thông tin có thể hành động tự động
- 👥 Hiệu quả Đội ngũ: Nghiên cứu chia sẻ có sẵn cho toàn bộ đội ngũ
- 📊 Bao phủ Toàn diện: Nhiều nguồn dữ liệu trong quy trình làm việc thống nhất
Biến đổi khả năng nghiên cứu của đội ngũ bạn từ phản ứng thành chủ động. Với Linear, Scrapeless và Claude làm việc cùng nhau, bạn không chỉ thu thập dữ liệu—bạn đang xây dựng một lợi thế trí tuệ cạnh tranh phát triển cùng doanh nghiệp của bạn.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


