
Làm thế nào để triển khai Scrapeless và sử dụng Trình duyệt một cách tốt nhất?
Senior Web Scraping Engineer
Trình duyệt Scraping đã trở thành công cụ chính cho việc thu thập dữ liệu và tự động hóa hàng ngày. Bằng cách tích hợp Browser-Use với Scrapeless Scraping Browser, bạn có thể vượt qua những hạn chế của tự động hóa trình duyệt và tránh bị chặn.
Trong bài viết này, chúng ta sẽ xây dựng một công cụ AI Agent tự động hóa bằng cách sử dụng Browser-Use và Scraping Browser của Scrapeless để thực hiện việc thu thập dữ liệu tự động. Bạn sẽ thấy điều này giúp tiết kiệm thời gian và công sức, khiến các nhiệm vụ tự động hóa trở nên dễ dàng hơn!
Bạn sẽ học được:
- Browser-Use là gì, và nó giúp xây dựng AI Agent như thế nào?
- Tại sao Scraping Browser có thể vượt qua hiệu quả những hạn chế của Browser-Use?
- Cách xây dựng một AI Agent không bị chặn bằng cách sử dụng Browser-Use và Scraping Browser?
Browser-Use là gì?
Browser-Use là một thư viện tự động hóa trình duyệt AI sử dụng Python được thiết kế để cung cấp cho AI Agent khả năng tự động hóa trình duyệt tiên tiến. Nó có thể nhận diện tất cả các yếu tố tương tác trên một trang web và cho phép các agent tương tác với trang theo cách lập trình—thực hiện các tác vụ thông thường như tìm kiếm, nhấp chuột, nhập dữ liệu và thu thập dữ liệu. Ở cốt lõi, Browser-Use chuyển đổi các trang web thành văn bản có cấu trúc và hỗ trợ các công cụ trình duyệt như Playwright, làm đơn giản hóa tương tác với web.
Khác với các công cụ tự động hóa truyền thống, Browser-Use kết hợp giữa hiểu biết hình ảnh và phân tích cấu trúc HTML, cho phép AI Agent điều khiển trình duyệt bằng các chỉ dẫn ngôn ngữ tự nhiên. Điều này giúp AI thông minh hơn trong việc nhận biết nội dung trang và thực hiện nhiệm vụ một cách hiệu quả. Thêm vào đó, nó hỗ trợ quản lý nhiều tab, theo dõi tương tác với các yếu tố, xử lý hành động tùy chỉnh, và các cơ chế khôi phục lỗi tích hợp để đảm bảo tính ổn định và nhất quán của quy trình tự động hóa.
Quan trọng hơn, Browser-Use tương thích với tất cả các mô hình ngôn ngữ lớn chính (như GPT-4, Claude 3, Llama 2). Với sự tích hợp của LangChain, người dùng chỉ cần mô tả nhiệm vụ bằng ngôn ngữ tự nhiên, và AI Agent sẽ hoàn thành các thao tác web phức tạp. Đối với những người dùng đang tìm kiếm tự động hóa tương tác web dựa trên AI, đây là một công cụ mạnh mẽ và đầy hứa hẹn.
Hạn chế của Browser-Use trong phát triển AI Agent
Như đã đề cập ở trên, Browser-Use không hoạt động như một cây đũa thần từ Harry Potter. Thay vào đó, nó kết hợp đầu vào hình ảnh với kiểm soát AI để tự động hóa trình duyệt bằng cách sử dụng Playwright.
Browser-Use không thể tránh khỏi một số nhược điểm, nhưng những hạn chế này không xuất phát từ chính khung tự động hóa. Thay vào đó, chúng phát sinh từ các trình duyệt mà nó điều khiển. Các công cụ như Playwright khởi động trình duyệt với các cấu hình và công cụ cụ thể cho tự động hóa, mà cũng có thể bị phát hiện bởi các hệ thống chặn bot.
Kết quả là, AI Agent của bạn có thể thường xuyên gặp phải các thách thức CAPTCHA hoặc các trang bị chặn như “Xin lỗi, đã có sự cố xảy ra.” Để mở khóa toàn bộ tiềm năng của Browser-Use, cần có những điều chỉnh cẩn thận. Mục tiêu cuối cùng là tránh kích hoạt các hệ thống chống bot để đảm bảo tự động hóa AI của bạn hoạt động trơn tru.
Sau khi thử nghiệm rộng rãi, chúng tôi có thể tự tin nói rằng: Scraping Browser là giải pháp hiệu quả nhất.
Scrapeless Scraping Browser là gì?
Scraping Browser là một công cụ tự động hóa trình duyệt không cần máy chủ dựa trên đám mây, được thiết kế để giải quyết ba vấn đề cốt lõi trong việc thu thập dữ liệu web động: bottlenecks đồng thời cao, lẩn tránh bot, và kiểm soát chi phí.
-
Nó cung cấp môi trường trình duyệt không có đầu ra cao đồng thời, không bị chặn để giúp các nhà phát triển dễ dàng thu thập nội dung động.
-
Nó đi kèm với một bể IP proxy toàn cầu và công nghệ xác thực, có khả năng tự động giải quyết CAPTCHA và vượt qua các cơ chế chặn.
Được xây dựng đặc biệt cho các nhà phát triển AI, Scrapeless Scraping Browser có một lõi Chromium được tùy chỉnh sâu và một mạng lưới proxy phân phối toàn cầu. Người dùng có thể chạy và quản lý nhiều phiên bản trình duyệt không có đầu ra để xây dựng các ứng dụng và agent AI tương tác với web. Nó loại bỏ các hạn chế của cơ sở hạ tầng địa phương và các bottlenecks về hiệu suất, cho phép bạn hoàn toàn tập trung vào việc xây dựng giải pháp của mình.
Browser-Use và Scraping Browser hoạt động cùng nhau như thế nào?
Khi kết hợp, các nhà phát triển có thể sử dụng Browser-Use để điều phối các hoạt động trình duyệt trong khi dựa vào dịch vụ đám mây ổn định của Scrapeless và khả năng chống chặn mạnh mẽ để thu thập dữ liệu web đáng tin cậy.
Browser-Use cung cấp các API đơn giản cho phép AI Agent “hiểu” và tương tác với nội dung web. Ví dụ, nó có thể sử dụng các mô hình ngôn ngữ lớn như OpenAI hoặc Anthropic để diễn giải các chỉ dẫn nhiệm vụ và hoàn thành các hành động như tìm kiếm hoặc nhấp vào liên kết trong trình duyệt thông qua Playwright.
Trình duyệt Scraping của Scrapeless bổ sung cho thiết lập này bằng cách giải quyết những điểm yếu của nó. Khi xử lý các trang web lớn với các biện pháp chống bot nghiêm ngặt, sự hỗ trợ proxy đồng thời cao, giải quyết CAPTCHA và cơ chế mô phỏng trình duyệt của nó đảm bảo việc scraping ổn định.
Tóm lại, Browser-Use xử lý thông tin và điều phối nhiệm vụ, trong khi Scrapeless cung cấp một nền tảng scraping vững chắc, giúp các tác vụ trình duyệt tự động trở nên hiệu quả và đáng tin cậy hơn.
Cách tích hợp Trình duyệt Scraping với Browser-Use?
Bước 1. Nhận Khóa API Scrapeless
- Đăng ký và đăng nhập vào Bảng điều khiển Scrapeless.
- Điều hướng đến "Cài đặt".
- Nhấp vào "Quản lý Khóa API".
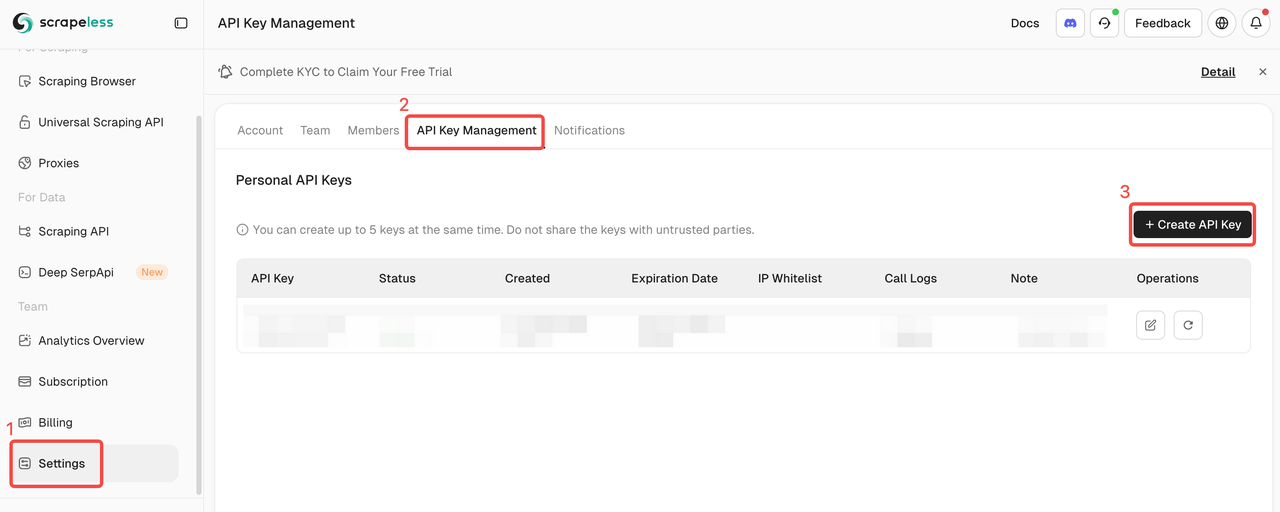
Sau đó sao chép và thiết lập biến môi trường SCRAPELESS_API_KEY trong tệp .env của bạn.
Để kích hoạt các tính năng AI trong Browser-Use, bạn cần một khóa API hợp lệ từ nhà cung cấp AI bên ngoài. Trong ví dụ này, chúng tôi sẽ sử dụng OpenAI. Nếu bạn chưa tạo khóa API, hãy làm theo hướng dẫn chính thức của OpenAI để tạo một cái.
Các biến môi trường OPENAI_API_KEY trong tệp .env của bạn cũng cần thiết.
Tuyên bố miễn trừ trách nhiệm: Các bước bên dưới tập trung vào cách tích hợp OpenAI, nhưng bạn có thể điều chỉnh các bước sau theo nhu cầu của bạn, chỉ cần đảm bảo sử dụng bất kỳ công cụ AI nào khác được hỗ trợ bởi Browser-Use.
.evn
OPENAI_API_KEY=your-openai-api-key
SCRAPELESS_API_KEY=your-scrapeless-api-key💡Nhớ thay thế khóa API mẫu bằng khóa API thực tế của bạn
Tiếp theo, nhập ChatOpenAI vào chương trình của bạn: langchain_openaiagent.py
Plain Text
from langchain_openai import ChatOpenAILưu ý rằng Browser-Use dựa vào LangChain để xử lý tích hợp AI. Do đó, ngay cả khi bạn chưa cài đặt rõ ràng langchain_openai trong dự án của mình, nó vẫn có sẵn để sử dụng.
gpt-4o thiết lập tích hợp OpenAI với mô hình sau:
Plain Text
llm = ChatOpenAI(model="gpt-4o")Không yêu cầu cấu hình bổ sung. Điều này là bởi vì langchain_openai tự động đọc khóa API từ biến môi trường OPENAI_API_KEY.
Đối với việc tích hợp với các mô hình hoặc nhà cung cấp AI khác, xem tài liệu chính thức Browser-Use.
Bước 2. Cài đặt Browser Use
Sử dụng pip (Python ít nhất v.3.11):
Shell
pip install browser-useĐối với chức năng bộ nhớ (cần Python<3.13 do tính tương thích với PyTorch):
Shell
pip install "browser-use[memory]"Bước 3. Thiết lập Trình duyệt và Cấu hình Đại lý
Đây là cách để cấu hình trình duyệt và tạo một đại lý tự động hóa:
Python
from dotenv import load_dotenv
import os
import asyncio
from urllib.parse import urlencode
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from pydantic import SecretStr
task = "Đi đến Google, tìm kiếm 'Scrapeless', nhấp vào bài viết đầu tiên và quay trở lại tiêu đề"
SCRAPELESS_API_KEY = os.environ.get("SCRAPELESS_API_KEY")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
async def setup_browser() -> Browser:
scrapeless_base_url = "wss://browser.scrapeless.com/browser"
query_params = {
"token": SCRAPELESS_API_KEY,
"session_ttl": 1800,
"proxy_country": "ANY"
}
browser_ws_endpoint = f"{scrapeless_base_url}?{urlencode(query_params)}"
config = BrowserConfig(cdp_url=browser_ws_endpoint)
browser = Browser(config)
return browser
async def setup_agent(browser: Browser) -> Agent:
llm = ChatOpenAI(
model="gpt-4o", # Hoặc chọn mô hình bạn muốn sử dụng
api_key=SecretStr(OPENAI_API_KEY),
)
return Agent(
task=task,
llm=llm,
browser=browser,
)Bước 4. Tạo Hàm Chính
Đây là hàm chính để kết hợp mọi thứ lại với nhau:
Python
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
await browser.close()
asyncio.run(main())Bước 5. Chạy script của bạn
Chạy script của bạn:
Shell
python run main.pyBạn sẽ thấy phiên Scrapeless của bạn bắt đầu trong Bảng điều khiển Scrapeless.
Ngoài ra, Scrapeless hỗ trợ phát lại phiên, cho phép trực quan hóa chương trình. Trước khi chạy chương trình, hãy đảm bảo bạn đã bật chức năng Ghi Web. Khi phiên hoàn tất, bạn có thể xem bản ghi trực tiếp trên Bảng điều khiển để giúp bạn nhanh chóng khắc phục sự cố.
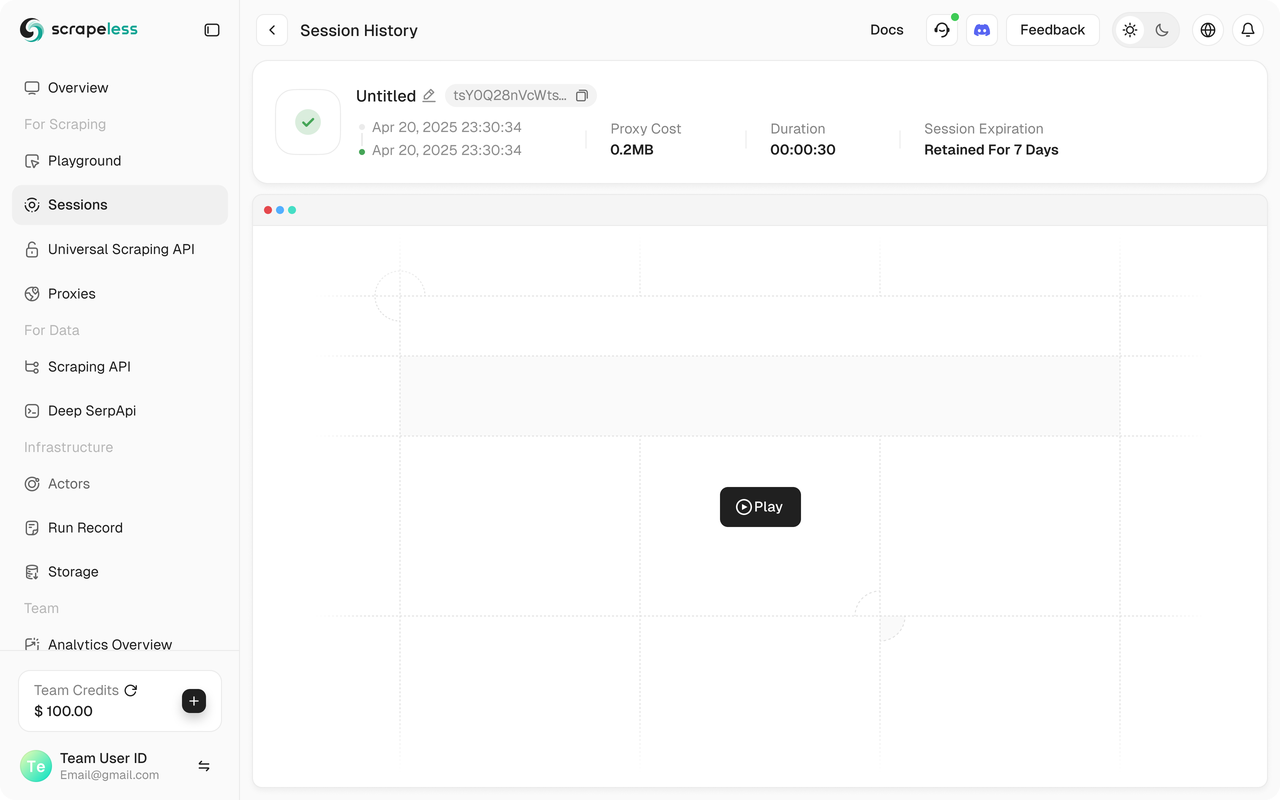
Mã Nguồn Đầy Đủ
Python
from dotenv import load_dotenv
import os
import asyncio
from urllib.parse import urlencode
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from pydantic import SecretStr
task = "Đi đến Google, tìm kiếm 'Scrapeless', nhấp vào bài viết đầu tiên và trả về tiêu đề"
SCRAPELESS_API_KEY = os.environ.get("SCRAPELESS_API_KEY")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
async def setup_browser() -> Browser:
scrapeless_base_url = "wss://browser.scrapeless.com/browser"
query_params = {
"token": SCRAPELESS_API_KEY,
"session_ttl": 1800,
"proxy_country": "ANY"
}
browser_ws_endpoint = f"{scrapeless_base_url}?{urlencode(query_params)}"
config = BrowserConfig(cdp_url=browser_ws_endpoint)
browser = Browser(config)
return browser
async def setup_agent(browser: Browser) -> Agent:
llm = ChatOpenAI(
model="gpt-4o", # Hoặc chọn mô hình mà bạn muốn sử dụng
api_key=SecretStr(OPENAI_API_KEY),
)
return Agent(
task=task,
llm=llm,
browser=browser,
)
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
await browser.close()
asyncio.run(main())💡Sử dụng Trình Duyệt hiện chỉ hỗ trợ Python.
💡Bạn có thể sao chép URL trong phiên trực tiếp để theo dõi tiến trình của phiên trong thời gian thực, và bạn cũng có thể xem lại phiên trong lịch sử phiên.
Bước 6. Kết Quả Chạy
JavaScript
{
"done": {
"text": "Tiêu đề của kết quả tìm kiếm đầu tiên được nhấp vào là: 'Công Cụ Web Scraping Không Tốn Công - Scrapeless'.",
"success": True,
}
}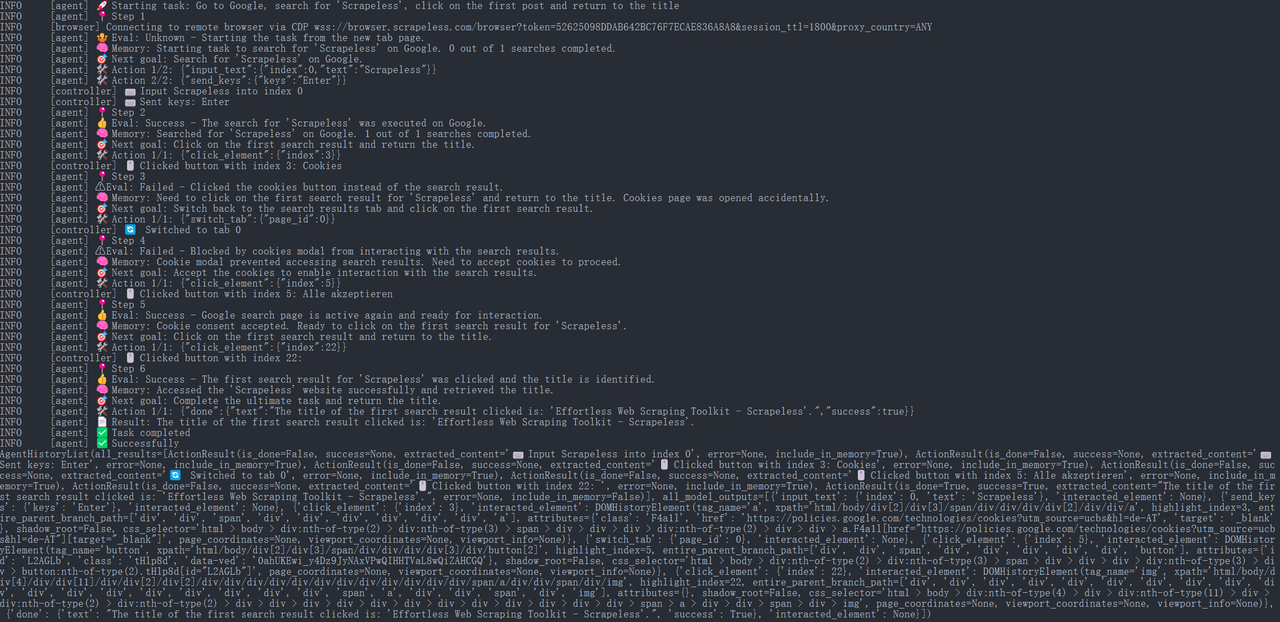
Sau đó, Đại diện Sử Dụng Trình Duyệt sẽ tự động mở URL và in tiêu đề trang: “Scrapeless: Công Cụ Web Scraping Không Tốn Công” (đây là một ví dụ về tiêu đề trên trang chủ chính thức của Scrapeless).
Toàn bộ quá trình thực thi có thể được xem trong bảng điều khiển Scrapeless dưới trang "Bảng Điều Khiển" → "Phiên" → "Lịch Sử Phiên", nơi bạn sẽ thấy chi tiết của phiên đã được thực hiện gần đây.
Bước 7. Xuất Kết Quả
Để chia sẻ và lưu trữ cho đội ngũ, chúng ta có thể lưu thông tin đã thu thập vào tệp JSON hoặc CSV. Ví dụ, đoạn mã sau đây cho thấy cách ghi kết quả tiêu đề vào một tệp:
Python
import json
from pathlib import Path
def save_to_json(obj, filename):
path = Path(filename)
path.parent.mkdir(parents=True, exist_ok=True)
with path.open('w', encoding='utf-8') as f:
json.dump(obj, f, ensure_ascii=False, indent=4)
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
save_to_json(result.model_dump(), "scrapeless_update_report.json")
await browser.close()
asyncio.run(main())Mã trên trình bày cách mở một tệp và ghi nội dung ở định dạng JSON, bao gồm các từ khóa tìm kiếm, liên kết và tiêu đề trang. Tệp được tạo scrapeless_update_report.json có thể được chia sẻ nội bộ qua cơ sở tri thức của công ty hoặc nền tảng hợp tác, giúp các thành viên trong nhóm dễ dàng xem kết quả thu thập thông tin. Đối với định dạng văn bản thuần, bạn chỉ cần thay đổi phần mở rộng thành .txt và sử dụng các phương pháp xuất ra văn bản cơ bản.
Tổng Kết
Bằng cách sử dụng dịch vụ Trình Duyệt Thu Thập Dữ Liệu của Scrapeless kết hợp với đại diện AI Sử Dụng Trình Duyệt, chúng ta có thể dễ dàng xây dựng một hệ thống tự động để thu thập và báo cáo thông tin.
- Scrapeless cung cấp một giải pháp thu thập dữ liệu dựa trên đám mây ổn định và hiệu quả có thể xử lý các cơ chế chống thu thập dữ liệu phức tạp.
- Sử dụng Trình Duyệt cho phép đại diện AI kiểm soát thông minh trình duyệt để thực hiện các tác vụ như tìm kiếm, nhấp và trích xuất.
Sự tích hợp này cho phép các nhà phát triển chuyển giao các tác vụ thu thập dữ liệu trên web tẻ nhạt cho các đại lý tự động, cải thiện đáng kể hiệu quả nghiên cứu trong khi đảm bảo độ chính xác và kết quả thời gian thực.
Trình Duyệt Thu Thập Dữ Liệu của Scrapeless giúp AI tránh các khối mạng trong khi thu thập dữ liệu tìm kiếm thời gian thực và đảm bảo sự ổn định trong hoạt động. Kết hợp với động cơ chiến lược linh hoạt của Trình Duyệt Sử Dụng, chúng tôi có thể xây dựng một công cụ nghiên cứu tự động hóa AI mạnh mẽ hơn, cung cấp hỗ trợ mạnh mẽ cho quyết định kinh doanh thông minh. Bộ công cụ này cho phép các đại lý AI "truy vấn" nội dung web như thể họ đang tương tác với một cơ sở dữ liệu, giảm thiểu chi phí theo dõi đối thủ bằng tay và cải thiện hiệu quả của các đội R&D và tiếp thị.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


