
Người viết blog được hỗ trợ bởi trí tuệ nhân tạo sử dụng Scrapeless và cơ sở dữ liệu Pinecone.
Senior Web Scraping Engineer
Bạn phải là một nhà tạo nội dung có kinh nghiệm. Là một nhóm khởi nghiệp, nội dung được cập nhật hàng ngày của sản phẩm rất phong phú. Không chỉ cần tạo ra một số lượng lớn blog thu hút để tăng nhanh lượng truy cập website, bạn cũng cần chuẩn bị 2-3 blog mỗi tuần nhằm quảng bá cập nhật sản phẩm.
So với việc chi tiêu nhiều tiền để tăng ngân sách đấu thầu của quảng cáo trả tiền đổi lấy vị trí hiển thị cao hơn và nhiều sự tiếp cận hơn, tiếp thị nội dung vẫn có những lợi thế không thể thay thế: phạm vi nội dung rộng, chi phí thử nghiệm thu hút khách hàng thấp, hiệu suất đầu ra cao, đầu tư năng lượng tương đối thấp, cơ sở kiến thức kinh nghiệm phong phú trong lĩnh vực, v.v.
Tuy nhiên, kết quả của một lượng lớn tiếp thị nội dung là gì?
Thật không may, nhiều bài viết bị chôn sâu trên trang 10 của tìm kiếm Google.
Có cách nào tốt để tránh tác động mạnh của các bài viết "ít lưu lượng" càng nhiều càng tốt không?
Bạn có bao giờ muốn tạo ra một nhà viết SEO tự cập nhật, sao chép kiến thức từ các blog hiệu suất cao và tạo ra nội dung mới theo quy mô không?
Trong hướng dẫn này, chúng tôi sẽ hướng dẫn bạn xây dựng một quy trình tạo nội dung SEO hoàn toàn tự động sử dụng n8n, Scrapeless, Gemini (Bạn có thể chọn một số cái khác như Claude/OpenRouter nếu muốn) và Pinecone.
Quy trình này sử dụng hệ thống Tạo hình Tăng cường Thu hồi (RAG) để thu thập, lưu trữ và tạo nội dung dựa trên các blog có lưu lượng truy cập cao tồn tại.
Hướng dẫn YouTube: https://www.youtube.com/watch?v=MmitAOjyrT4
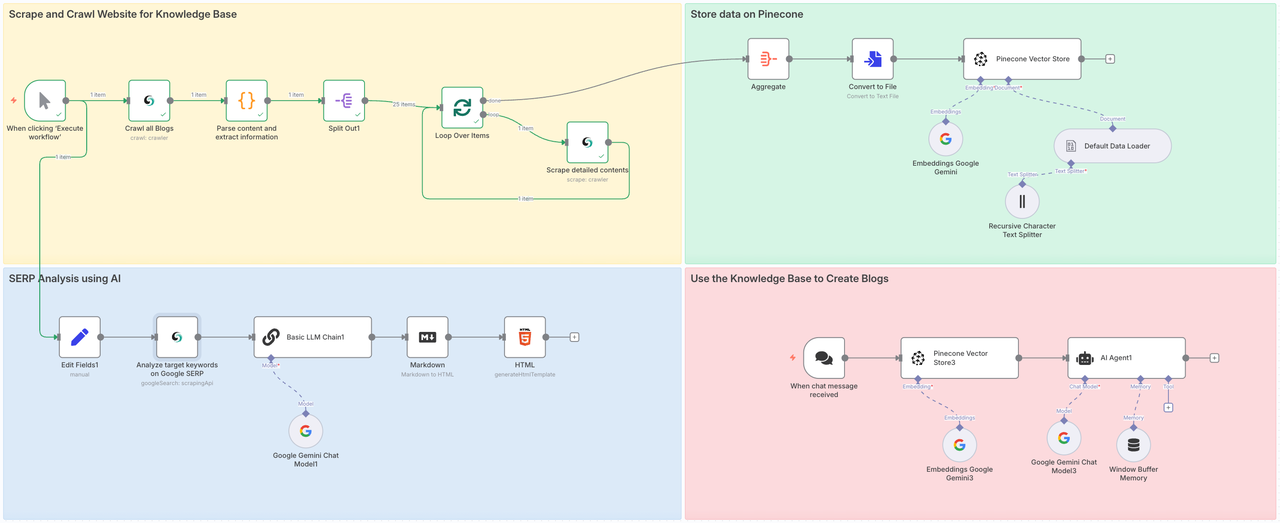
Quy trình này làm gì?
Quy trình này sẽ liên quan đến bốn bước:
- Phần 1: Gọi Scrapeless Crawl để thu thập tất cả các trang con của website mục tiêu, và sử dụng Scrape để phân tích sâu toàn bộ nội dung của mỗi trang.
- Phần 2: Lưu trữ dữ liệu thu thập được vào Kho Vector Pinecone.
- Phần 3: Sử dụng nút Tìm kiếm Google của Scrapeless để phân tích toàn bộ giá trị của chủ đề hoặc từ khóa mục tiêu.
- Phần 4: Truyền chỉ dẫn đến Gemini, tích hợp nội dung ngữ cảnh từ cơ sở dữ liệu đã chuẩn bị thông qua RAG và tạo ra các blog mục tiêu hoặc trả lời câu hỏi.
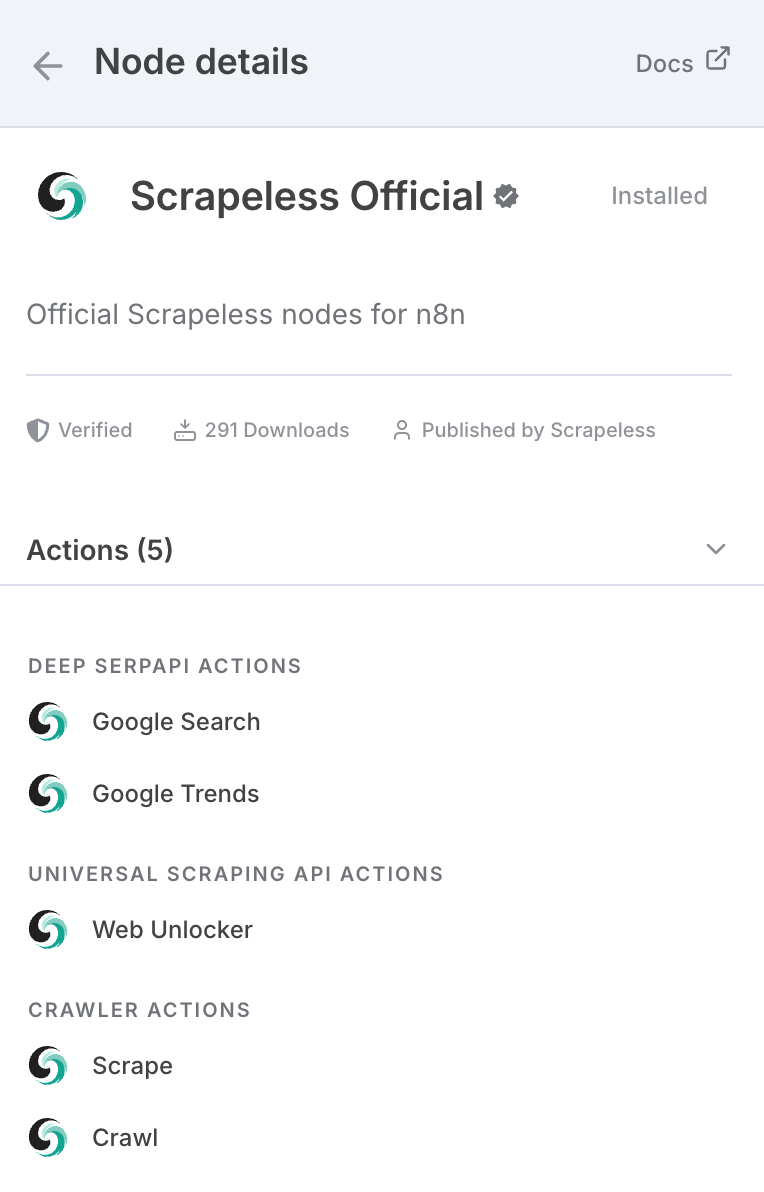
Nếu bạn chưa nghe về Scrapeless, đây là một công ty hạ tầng hàng đầu tập trung vào việc cung cấp các tác nhân AI, quy trình tự động hóa và thu thập dữ liệu web. Scrapeless cung cấp các khối xây dựng thiết yếu cho phép các nhà phát triển và doanh nghiệp tạo ra các hệ thống thông minh, tự động một cách hiệu quả.
Tại cốt lõi, Scrapeless cung cấp các công cụ cấp trình duyệt và API dựa trên giao thức—như trình duyệt đám mây không đầu, API Deep SERP và API Thu thập Dữ liệu Tổng hợp—để phục vụ như một nền tảng đơn giản và mô-đun cho các tác nhân AI và nền tảng tự động hóa.
Nó thực sự được xây dựng cho các ứng dụng AI vì các mô hình AI không phải lúc nào cũng cập nhật được với nhiều thứ, dù là sự kiện hiện tại hay công nghệ mới.
Ngoài n8n, nó cũng có thể được gọi thông qua API, và có các nút trên các nền tảng chính như Make:
Bạn cũng có thể sử dụng nó trực tiếp trên trang web chính thức.
Để sử dụng Scrapeless trong n8n:
- Đi tới Cài đặt > Nút Cộng đồng
- Tìm kiếm n8n-nodes-scrapeless và cài đặt nó
Chúng ta cần cài đặt nút cộng đồng Scrapeless trên n8n trước:
Kết nối Thông tin xác thực
Khóa API Scrapeless
Trong hướng dẫn này, chúng tôi sẽ sử dụng dịch vụ Scrapeless. Vui lòng đảm bảo bạn đã đăng ký và có được Khóa API.
- Đăng ký trên trang web Scrapeless để nhận khóa API của bạn và nhận thử nghiệm miễn phí.
- Sau đó, bạn có thể mở nút Scrapeless, dán khóa API của bạn vào phần thông tin xác thực và kết nối nó.
Chỉ số Pinecone và Khóa API
Sau khi thu thập dữ liệu, chúng tôi sẽ tích hợp và xử lý nó và thu thập tất cả dữ liệu vào cơ sở dữ liệu Pinecone. Chúng tôi cần chuẩn bị Khóa API và Chỉ số Pinecone trước.
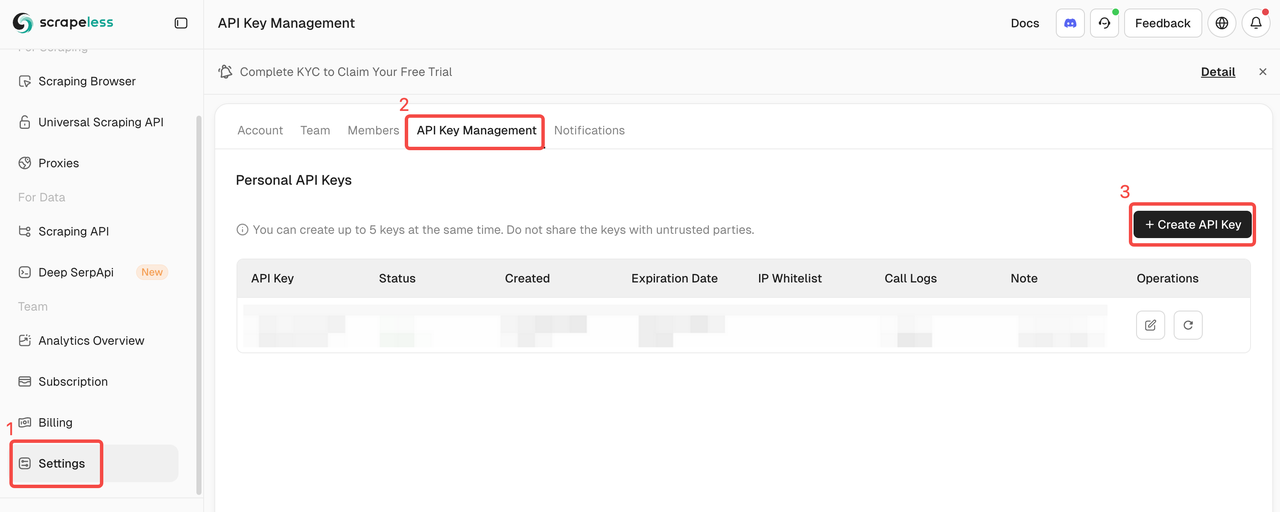
Tạo Khóa API
Sau khi đăng nhập, nhấp vào Khóa API → Nhấp vào Tạo Khóa API → Bổ sung tên khóa API của bạn → Tạo khóa. Giờ đây, bạn có thể thiết lập trong thông tin xác thực n8n.
⚠️ Sau khi việc tạo hoàn tất, vui lòng sao chép và lưu lại Khóa API của bạn. Vì lý do bảo mật dữ liệu, Pinecone sẽ không còn hiển thị khóa API đã tạo.
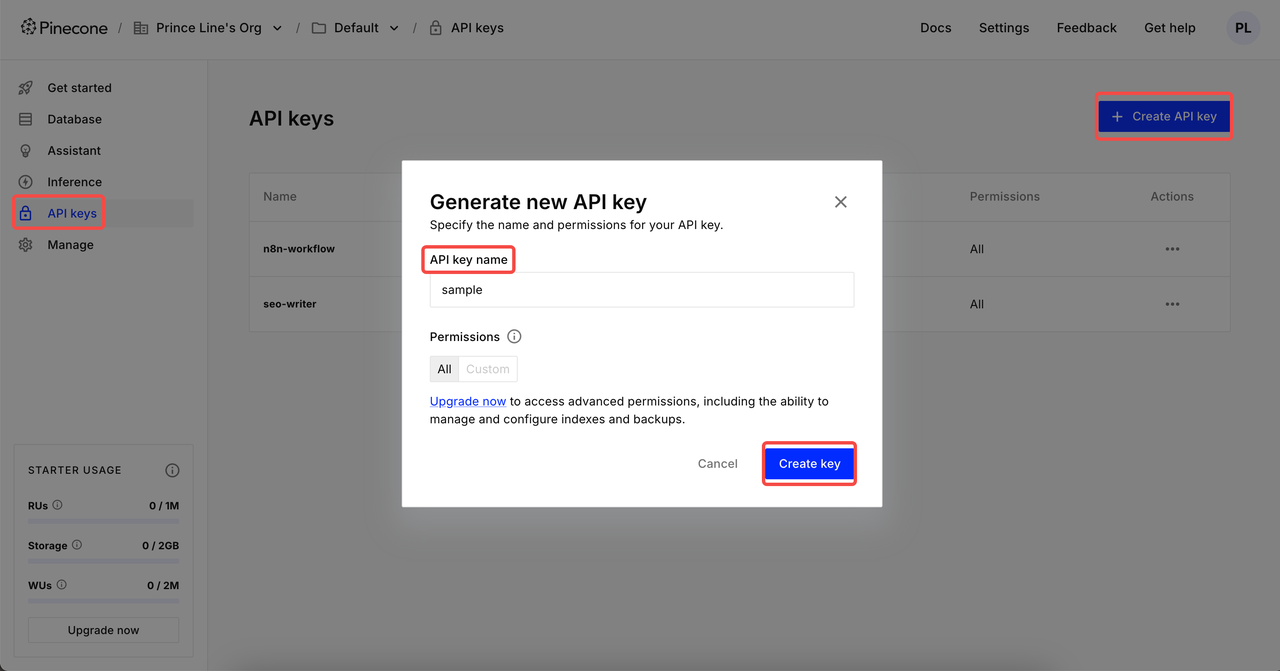
Tạo Chỉ số
Nhấp vào Chỉ mục và vào trang tạo. Đặt Tên chỉ mục → Chọn mô hình cho Cấu hình → Đặt Kích thước phù hợp → Tạo chỉ mục.
2 cài đặt kích thước phổ biến:
- Google Gemini Embedding-001 → 768 kích thước
- OpenAI's text-embedding-3-small → 1536 kích thước
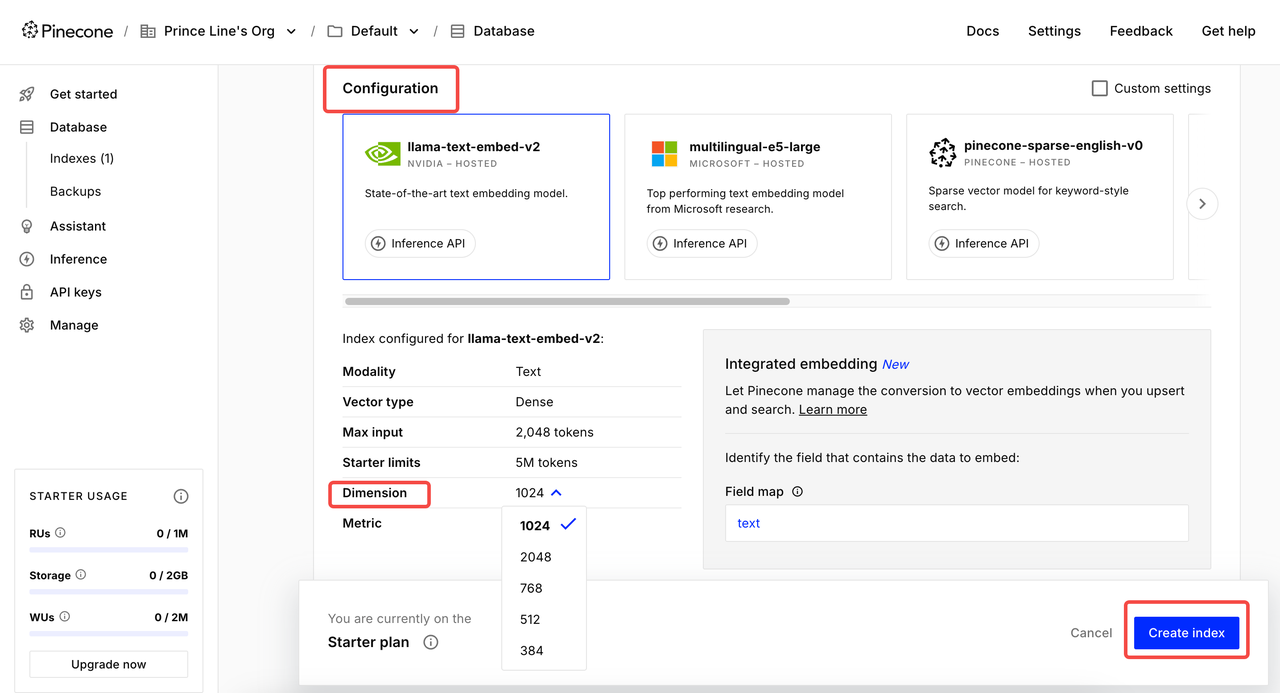
Giai đoạn 1: Thu thập và Quét Các Trang Web cho Cơ Sở Kiến Thức
Giai đoạn đầu tiên là tổng hợp trực tiếp tất cả nội dung blog. Quét nội dung từ một khu vực lớn cho phép tác nhân AI của chúng tôi thu thập các nguồn dữ liệu từ tất cả các lĩnh vực, từ đó đảm bảo chất lượng của các bài viết cuối cùng.
- Nút Scrapeless quét trang bài viết và thu thập tất cả các URL bài đăng blog.
- Sau đó, nó lặp qua từng URL, thu thập nội dung blog và tổ chức dữ liệu.
- Mỗi bài viết blog được chèn vào sử dụng mô hình AI của bạn và lưu trữ trong Pinecone.
- Trong trường hợp của chúng tôi, chúng tôi đã thu thập 25 bài viết blog chỉ trong vài phút — mà không cần phải làm gì.
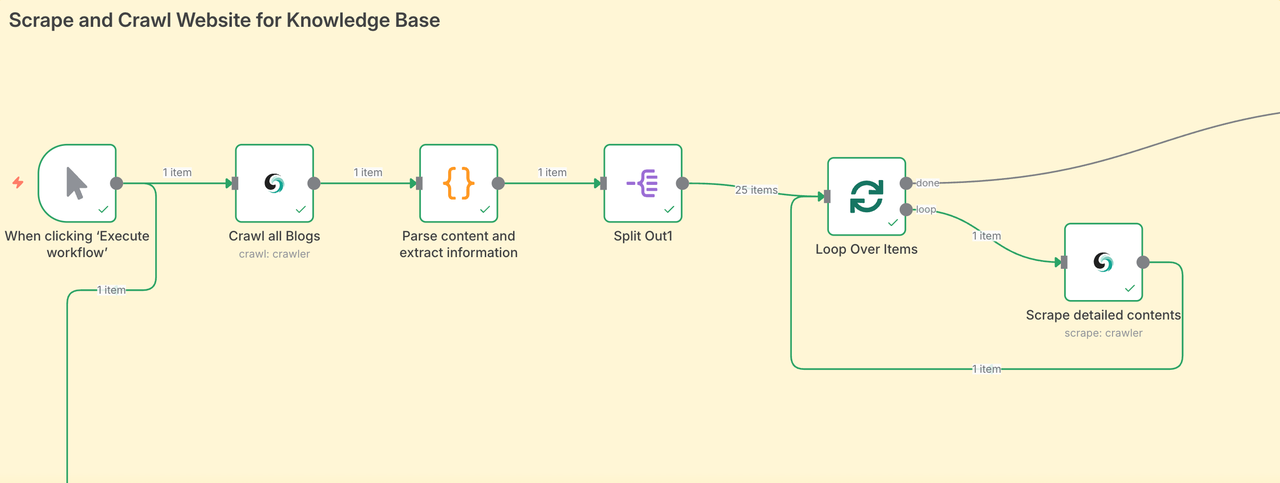
Nút Quét Scrapeless
Nút này được sử dụng để quét tất cả nội dung của trang web blog mục tiêu bao gồm dữ liệu Meta, nội dung trang con và xuất nó dưới định dạng Markdown. Đây là một hoạt động quét nội dung quy mô lớn mà chúng tôi không thể nhanh chóng đạt được thông qua lập trình thủ công.
Cấu hình:
- Kết nối khóa API Scrapeless của bạn
- Tài nguyên:
Crawler - Hoạt động:
Crawl - Nhập trang web quét mục tiêu của bạn. Ở đây, chúng tôi sử dụng https://www.scrapeless.com/vi/blog làm tham khảo.
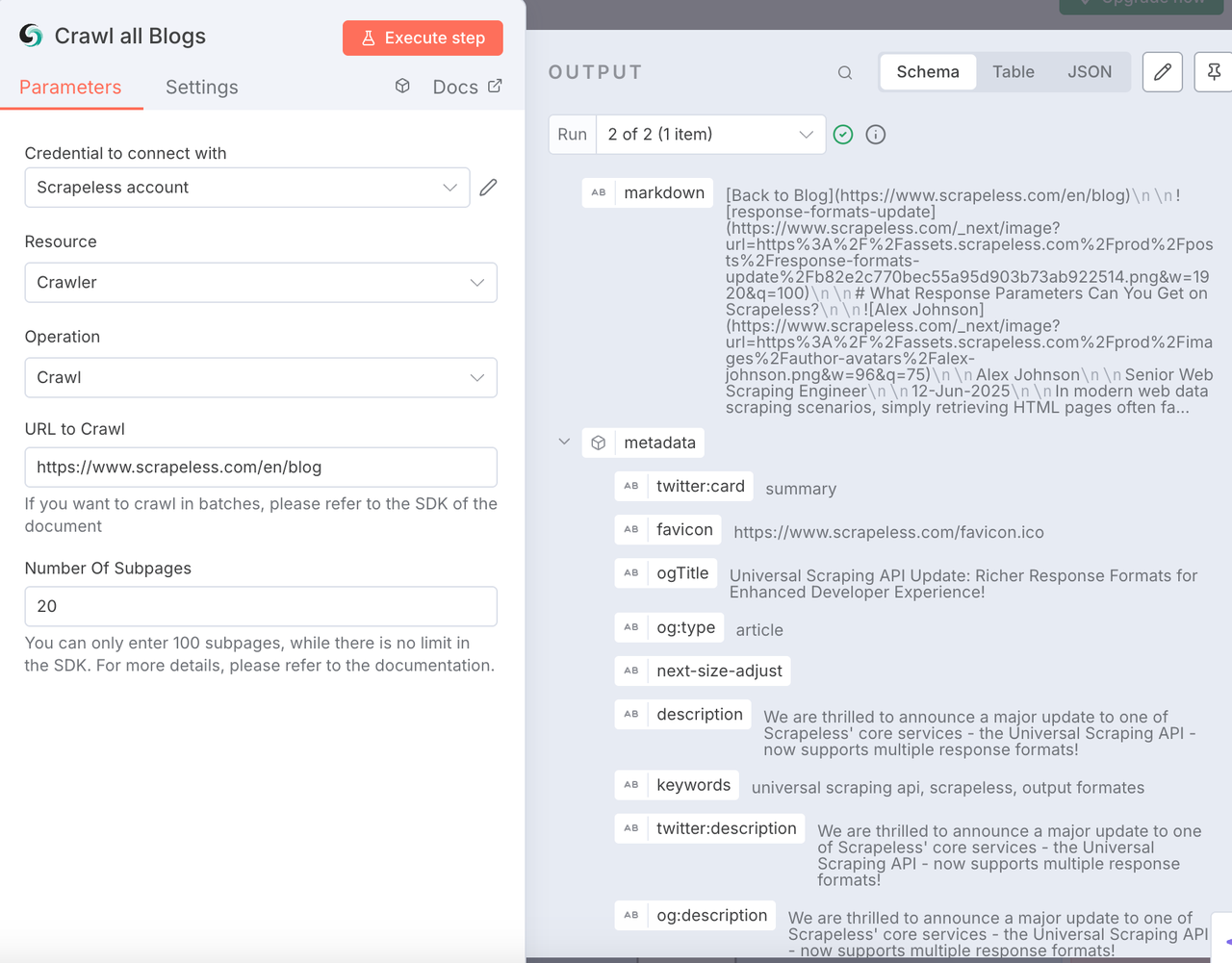
Nút Mã
Sau khi có dữ liệu blog, chúng ta cần phân tích dữ liệu và trích xuất thông tin có cấu trúc cần thiết từ đó.
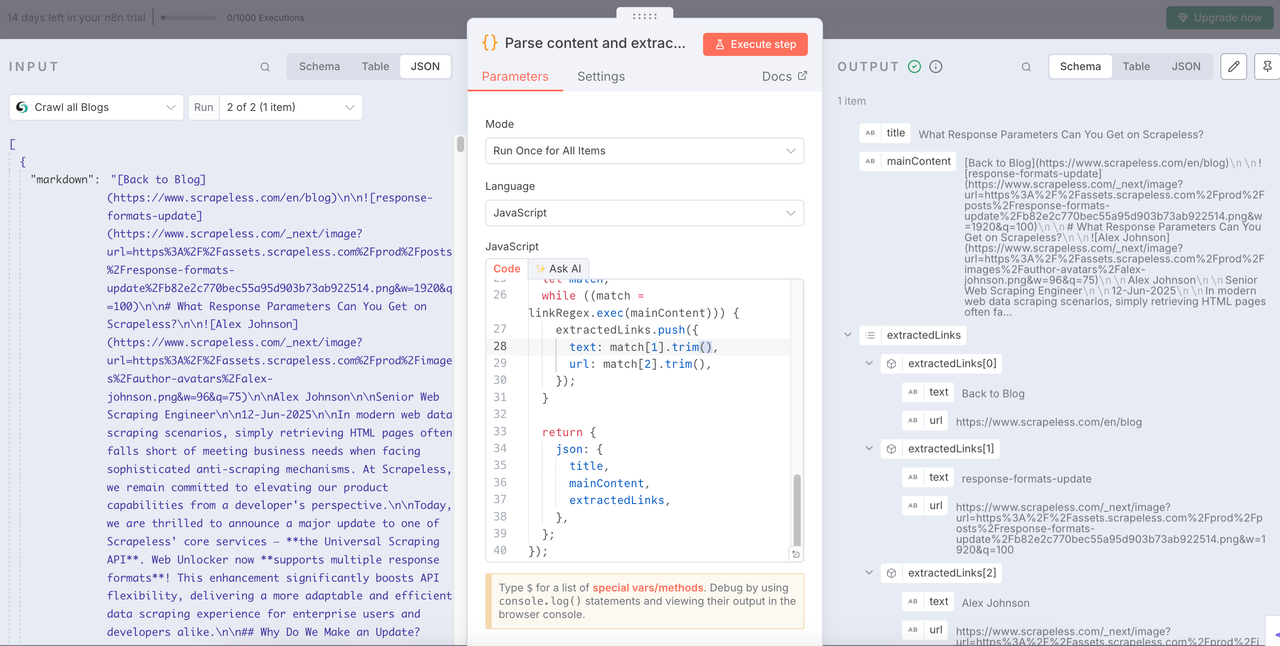
Dưới đây là mã mà tôi đã sử dụng. Bạn có thể tham khảo trực tiếp:
JavaScript
return items.map(item => {
const md = $input.first().json['0'].markdown;
if (typeof md !== 'string') {
console.warn('Nội dung Markdown không phải là chuỗi:', md);
return {
json: {
title: '',
mainContent: '',
extractedLinks: [],
error: 'Nội dung Markdown không phải là chuỗi'
}
};
}
const articleTitleMatch = md.match(/^#\s*(.*)/m);
const title = articleTitleMatch ? articleTitleMatch[1].trim() : 'Không tìm thấy tiêu đề';
let mainContent = md.replace(/^#\s*.*(\r?\n)+/, '').trim();
const extractedLinks = [];
// Sự tránh nhìn tiêu cực `(?!#)` đảm bảo rằng '#' không được khớp sau URL cơ sở,
// hoặc một cách chắc chắn hơn là dừng lại trước '#'
const linkRegex = /\[([^\]]+)\]\((https?:\/\/[^\s#)]+)\)/g;
let match;
while ((match = linkRegex.exec(mainContent))) {
extractedLinks.push({
text: match[1].trim(),
url: match[2].trim(),
});
}
return {
json: {
title,
mainContent,
extractedLinks,
},
};
});Nút: Tách ra
Nút Tách ra có thể giúp chúng tôi tích hợp dữ liệu đã được làm sạch và trích xuất các URL và nội dung văn bản cần thiết.
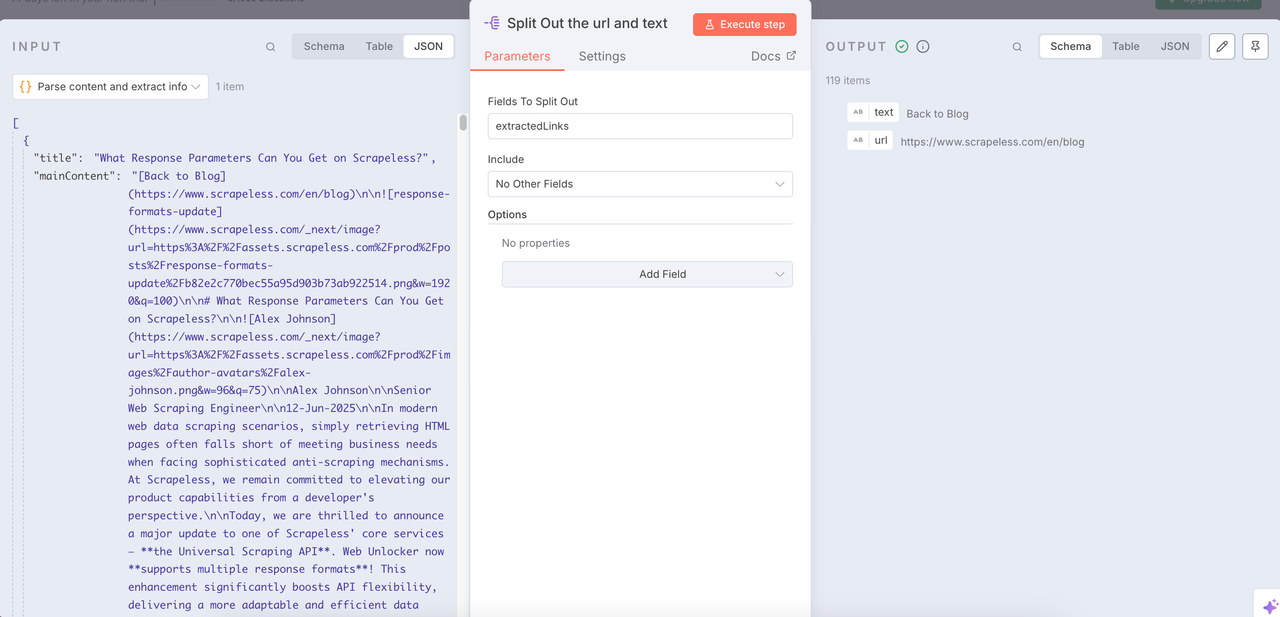
Lặp qua các Mục + Quét Scrapeless
Lặp qua các Mục
Sử dụng nút Lặp qua thời gian với Quét Scrapeless để thực hiện các nhiệm vụ quét lặp đi lặp lại và phân tích sâu tất cả các mục đã thu được trước đó.
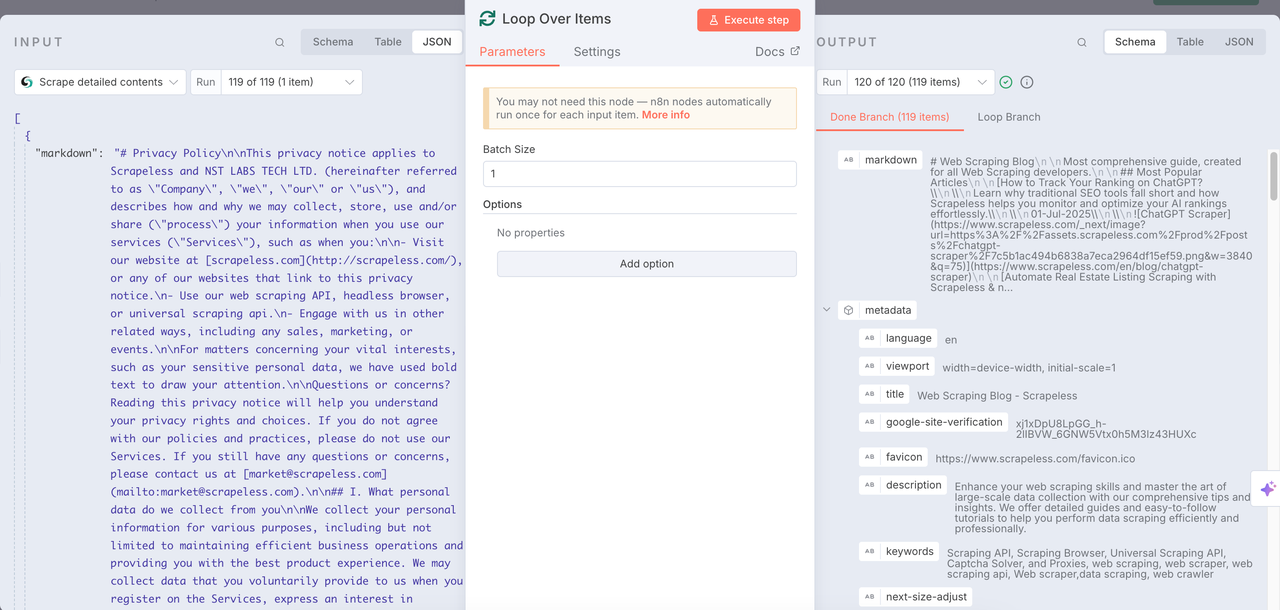
Quét Scrapeless
Nút Quét được sử dụng để quét tất cả nội dung có trên URL đã thu được trước đó. Bằng cách này, mỗi URL có thể được phân tích sâu. Định dạng markdown được trả về và dữ liệu meta và thông tin khác được tích hợp.

Giai đoạn 2. Lưu trữ dữ liệu trên Pinecone
Chúng ta đã thành công trong việc trích xuất toàn bộ nội dung của trang blog Scrapeless. Bây giờ chúng ta cần truy cập vào Pinecone Vector Store để lưu trữ thông tin này để chúng ta có thể sử dụng nó sau này.
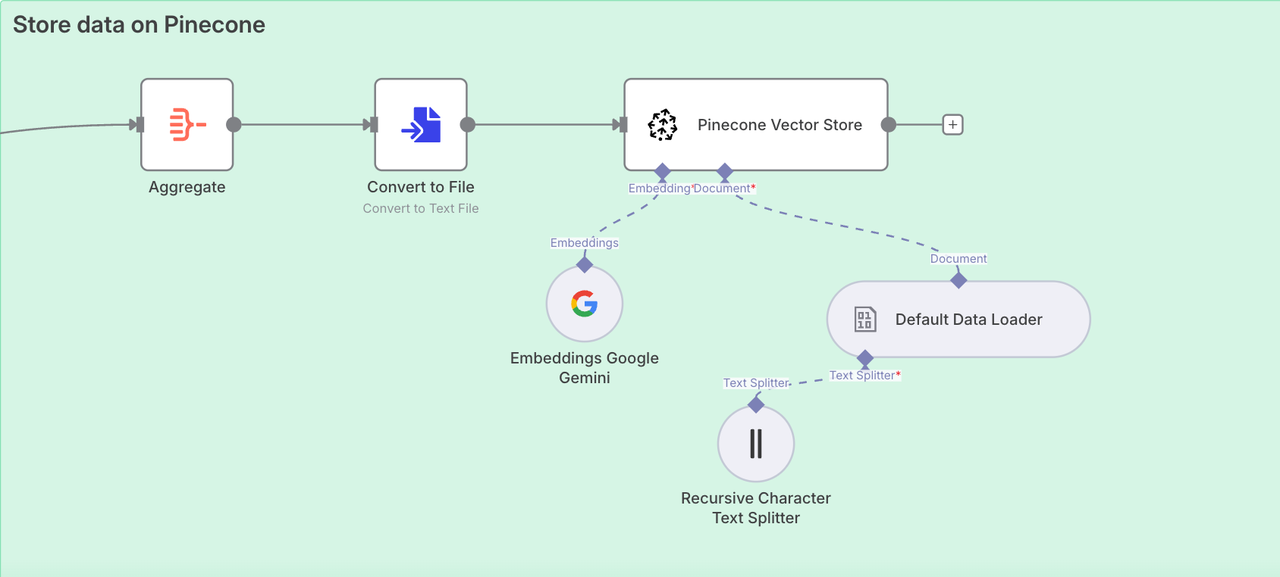
Nút: Tổng hợp
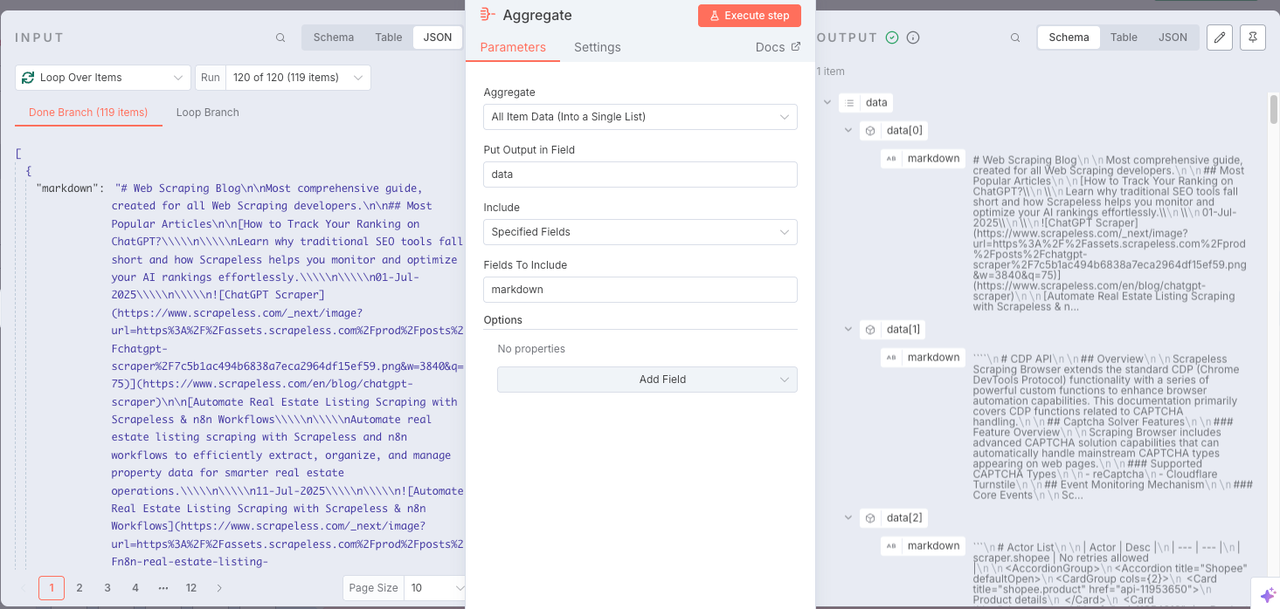
Để lưu trữ dữ liệu trong cơ sở kiến thức một cách thuận tiện, chúng ta cần sử dụng nút Tổng hợp để tích hợp tất cả nội dung.
- Tổng hợp:
Tất cả Dữ liệu Mục (Vào một Danh sách Đơn) - Đặt Đầu ra vào Trường:
data - Bao gồm:
Tất cả Các Trường
Nút: Chuyển đổi thành Tệp
Tuyệt vời! Tất cả dữ liệu đã được tích hợp thành công. Bây giờ chúng ta cần chuyển đổi dữ liệu thu được thành định dạng văn bản có thể đọc trực tiếp bởi Pinecone. Để làm điều này, chỉ cần thêm một Chuyển đổi thành Tệp.
Node: Cửa hàng Vector Pinecone
Bây giờ chúng ta cần cấu hình cơ sở dữ liệu kiến thức. Các node được sử dụng là:
Cửa hàng Vector PineconeGoogle GeminiTrình tải dữ liệu mặc địnhBộ phân tách văn bản ký tự đệ quy
Bốn node trên sẽ tích hợp và thu thập dữ liệu chúng ta đã thu được một cách đệ quy. Sau đó, tất cả đều được tích hợp vào cơ sở dữ liệu kiến thức Pinecone.
Giai đoạn 3. Phân tích SERP bằng AI
Để đảm bảo bạn đang viết nội dung có thứ hạng, chúng tôi thực hiện phân tích SERP trực tiếp:
- Sử dụng Scrapeless Deep SerpApi để lấy kết quả tìm kiếm cho từ khóa bạn đã chọn
- Nhập cả từ khóa và nên tìm kiếm (ví dụ: Scraping, xu hướng Google, API)
- Kết quả được phân tích bởi một LLM và tóm tắt thành một báo cáo HTML
Node: Chỉnh sửa trường
Cơ sở dữ liệu kiến thức đã sẵn sàng! Bây giờ là lúc xác định các từ khóa mục tiêu của chúng ta. Điền vào các từ khóa mục tiêu trong hộp nội dung và thêm ý định.
Node: Tìm kiếm Google
Node Tìm kiếm Google gọi Deep SerpApi của Scrapeless để lấy các từ khóa mục tiêu.
Node: Chuỗi LLM
Xây dựng Chuỗi LLM với Gemini có thể giúp chúng tôi phân tích dữ liệu thu được trong các bước trước và giải thích cho LLM đầu vào và ý định tham khảo mà chúng tôi cần sử dụng để LLM có thể tạo ra phản hồi tốt hơn đáp ứng nhu cầu.
Node: Markdown
Vì LLM thường xuất kiểu định dạng Markdown, với tư cách là người dùng, chúng tôi không thể trực tiếp lấy dữ liệu cần thiết một cách rõ ràng nhất, vì vậy vui lòng thêm một node Markdown để chuyển đổi kết quả do LLM trả về thành HTML.
Node: HTML
Bây giờ chúng ta cần sử dụng node HTML để chuẩn hóa kết quả - sử dụng định dạng Blog/Báo cáo để hiển thị trực quan nội dung liên quan.
- Hoạt động:
Tạo mẫu HTML
Mã sau là cần thiết:
XML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Tóm tắt báo cáo</title>
<link href="https://fonts.googleapis.com/css2?family=Inter:wght@400;600;700&display=swap" rel="stylesheet">
<style>
body {
margin: 0;
padding: 0;
font-family: 'Inter', sans-serif;
background: #f4f6f8;
display: flex;
align-items: center;
justify-content: center;
min-height: 100vh;
}
.container {
background-color: #ffffff;
max-width: 600px;
width: 90%;
padding: 32px;
border-radius: 16px;
box-shadow: 0 10px 30px rgba(0, 0, 0, 0.1);
text-align: center;
}
h1 {
color: #ff6d5a;
font-size: 28px;
font-weight: 700;
margin-bottom: 12px;
}
h2 {
color: #606770;
font-size: 20px;
font-weight: 600;
margin-bottom: 24px;
}
.content {
color: #333;
font-size: 16px;
line-height: 1.6;
white-space: pre-wrap;
}
@media (max-width: 480px) {
.container {
padding: 20px;
}
h1 {
font-size: 24px;
}
h2 {
font-size: 18px;
}
}
</style>
</head>
<body>
<div class="container">
<h1>Báo cáo Dữ liệu</h1>
<h2>Xử lý qua Tự động hóa</h2>
<div class="content">{{ $json.data }}</div>
</div>
<script>
console.log("Xin chào thế giới!");
</script>
</body>
</html>Báo cáo này bao gồm:
- Các từ khóa xếp hạng hàng đầu và các cụm từ đuôi dài
- Xu hướng ý định tìm kiếm của người dùng
- Tiêu đề và góc độ blog được đề xuất
- Phân cụm từ khóa
Giai đoạn 4. Tạo Blog bằng AI + RAG
Bây giờ bạn đã thu thập và lưu trữ kiến thức cũng như nghiên cứu từ khóa của mình, đã đến lúc tạo blog của bạn.
- Xây dựng một prompt sử dụng những hiểu biết từ báo cáo SERP
- Gọi một đại lý AI (ví dụ: Claude, Gemini, hoặc OpenRouter)
- Mô hình lấy ngữ cảnh liên quan từ Pinecone và viết một bài blog hoàn chỉnh.
Những Suy Nghĩ Cuối Cùng
Cỗ máy nội dung SEO toàn diện này thể hiện sức mạnh của n8n + Scrapeless + Cơ sở Dữ liệu Vector + LLMs.
Bạn có thể:
- Thay thế Trang Blog Scrapeless bằng bất kỳ blog nào khác
- Hoán đổi Pinecone với các kho vector khác
- Sử dụng OpenAI, Claude hoặc Gemini làm động cơ viết của bạn
- Xây dựng các quy trình xuất bản tùy chỉnh (ví dụ: tự động đăng lên CMS hoặc Notion)
👉 Bắt đầu ngay hôm nay bằng cách cài đặt node cộng đồng Scrapeless và bắt đầu tạo blog quy mô lớn — không cần lập trình.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


