
n8nは、ユーザーがさまざまなアプリケーション、サービス、およびAPIを視覚的かつカスタマイズ可能な方法で接続・統合できるオープンソースのワークフロー自動化ツールです。ZapierやMake(旧Integromat)などのツールと似て、n8nは技術者と非技術者の両方が、反復的な手作業なしに自動化ワークフロー(「オートメーション」または「フロー」とも呼ばれる)を作成できるようにします。
Scrapelessは、n8nで以下のモジュールを提供しています:
- Google検索 – Googleからリッチな検索データに簡単にアクセスして取得します。
- ウェブサイトのアンロック – 通常はボットをブロックするJSレンダリングされたウェブサイトからデータにアクセスし、抽出します。
- 単一ページからデータをスクレイピング – 単一のウェブページから情報を抽出します。
- すべてのページからデータをクロール – ウェブサイトとそのリンクされたページをクロールして包括的なデータを抽出します。
n8nでScrapelessを使用する理由は?
Scrapelessとn8nを統合することで、コードを記述せずに高度で堅牢なウェブスクレイパーを作成できます。利点には以下が含まれます:
- Deep SerpApiにアクセスして、単一のリクエストでGoogle SERPデータを取得・抽出します。
- Universal Scraping APIを使用して制限を回避し、任意のウェブサイトにアクセスします。
- Crawler Scrapeを使用して個々のページの詳細なスクレイピングを行います。
- Crawler Crawlを使用して再帰的にクロールし、すべてのリンクされたページからデータを取得します。
- n8nの350以上のサポートサービス(Google Sheets、Airtable、Notionなど)にデータを連結します。
プロキシインフラを持たないチームやプレミアム/アンチボットドメインをスクレイピングするチームにとって、この統合はゲームチェンジャーです。
n8nでScrapelessサービスに接続する方法
ステップ1. Scrapeless APIキーを取得する
- アカウントを作成し、Scrapelessダッシュボードにログインします。 2,500の無料APIコールを取得できます。
- Scrapeless APIキーを生成します。
ステップ2. トリガー条件を設定し、Scrapelessに接続する
-
n8nの概要ページに移動し、「ワークフローを作成」をクリックします。
-
空のワークフローエディタが表示され、最初のステップを追加できます。 自動化を開始するトリガーでワークフローを開始する必要があります。「手動でトリガー」を選択します。
-
Scrapelessコミュニティノードを追加します。 まだインストールしていない場合は、クリックしてインストールします。その後、「Google検索」を選択します。
-
「新しい資格情報を作成」をクリックします。 Scrapeless APIキーを貼り付けます。
-
検索クエリを構成します。「B2B営業自動化トレンド分析」を検索します。
-
Runアイコンをクリックして、構成が成功したかどうかをテストします。 テストが正しい場合は、Discordを構成する必要があります。
ステップ3. クロールされた結果をJSON形式に変換する
次に、前のステップでクロールされた結果をJSON形式に変換するだけです。 変換ファイルを構成する必要があります。
「+」ボタンをクリックして「JSONに変換」を追加します。その後、以下のように構成してください。
ステップ4. Discordに接続してメッセージを受け取る
-
「+」をクリックしてDiscordを追加します。
-
接続タイプに「Webhook」を選択します。
-
次に、情報を受け取るために使用するDiscordコミュニティのWebhookリンクを構成する必要があります。 DiscordのWebhookリンクを貼り付けます。
-
その後、メッセージ内でデータがどこから来るかを定義できます。 このオプションを設定する必要はありません。
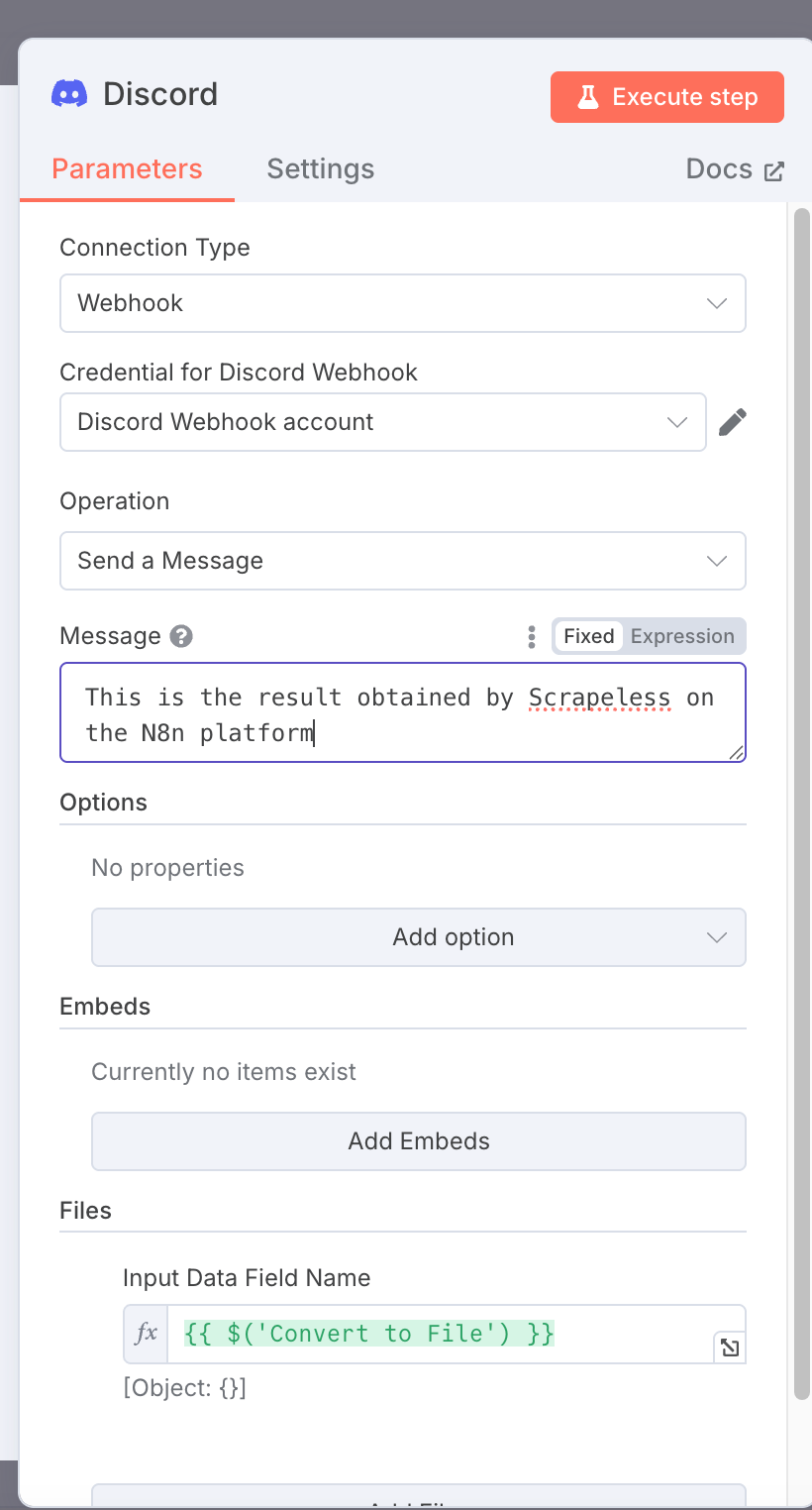
-
最後のステップでは、「ファイル」にある「ファイルに変換」を選択する必要があります。
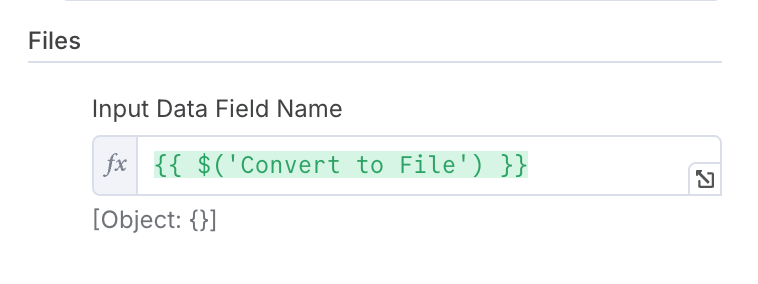
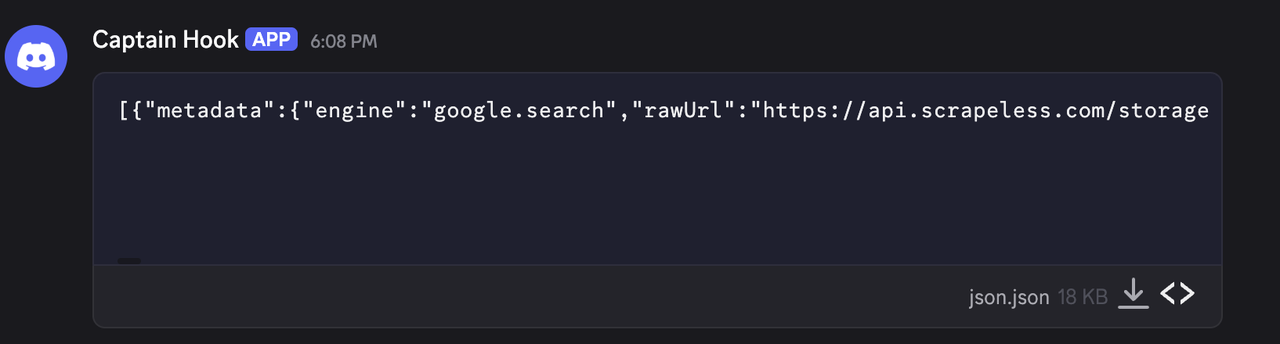
ステップ5. 構造化されたファイルを取得するために実行
このワークフローを実行するためにクリックすると、対応する構造化されたファイルが取得でき、それを直接ダウンロードして利用できます。
Scrapelessを使用した最初のn8n自動化を構築しよう
現在、Scrapelessとn8nの統合を試してみることをお勧めします。フィードバックや使用事例を共有してください。APIキーはScrapelessダッシュボードから取得し、n8nにアクセスして無料アカウントを作成し、自分のウェブデータ自動化ワークフローを構築し始めましょう!
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。
このページで