Loading...
🎯 カスタマイズ可能で検出回避型のクラウドブラウザ。自社開発のChromiumを搭載し、ウェブクローラーやAIエージェント向けに設計されています。👉今すぐ試す
すべてのWebスクレイピング開発者向けに作成された最も包括的なガイド。
Scrapelessは、大手企業から信頼されるAIを搭載した堅牢でスケーラブルなWebスクレイピングと自動化サービスを提供します。 私たちのエンタープライズグレードのソリューションは、プロジェクトのニーズを満たすように調整されており、全体にわたって専用の技術サポートがあります。 強力な技術チームと柔軟な配達時間を使用すると、データを成功させるためにのみ請求し、制限をバイパスしながら効率的なデータ抽出を可能にします。
あなたのビジネスの成長を促進するために今すぐお問い合わせください。
連絡先の詳細を提供すると、すぐに製品のデモと紹介を提供します。 GDPR標準に準拠して、お客様の情報が機密のままであることを確認します。
Pythonのソケットとスレッディングモジュールを使用して、基本的なマルチスレッドHTTPプロキシサーバーを構築する方法を学びます。このガイドでは、ネットワークプログラミングの基本概念をカバーし、カスタムソリューションをScrapeless Proxiesのような商業サービスの堅牢な機能と比較します。

UDPプロキシの世界を探求しましょう。UDPプロキシとは何か、どのようにゲームやVoIPなどのリアルタイムアプリケーションのゲートウェイとして機能するのか、そしてHTTPやSOCKSプロキシとの違いについて学びましょう。データニーズに対してScrapelessのような専門的なプロキシソリューションを使用する利点を発見してください。

Node.jsで`node-fetch`ライブラリとプロキシエージェントパッケージを使用してHTTP/HTTPSおよびSOCKSプロキシを設定するためのステップバイステップガイド。匿名のウェブスクレイピングとデータ収集に不可欠です。Scrapeless Proxiesの機能があります。

IPv6に関する包括的なガイドであり、その128ビットの構造、IPv4に対する主要な利点(アドレス空間、セキュリティ、効率)およびウェブスクレイピングのためのスケーラブルでコスト効果の高いプロキシソリューションを提供する上での重要な役割について説明しています。

オープンプロキシとは何か、それらの利点、そしてそれがもたらす重大なセキュリティリスクについて理解しましょう。Scrapelessのようなプレミアムサービスが、匿名性とウェブスクレイピングにおいてより安全で信頼できる代替手段を提供する理由を学びましょう。

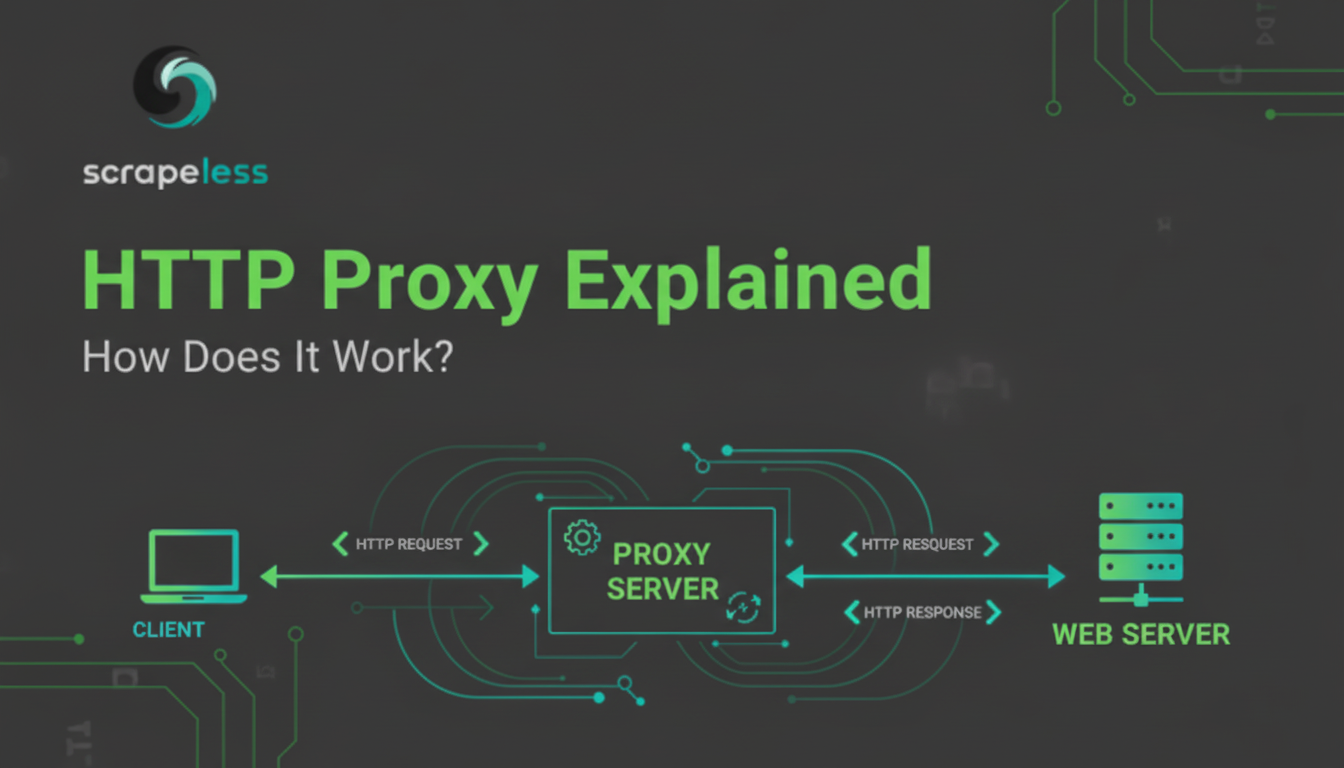
HTTPプロキシの詳細な説明であり、その機能、種類(フォワード、リバース、トランスペアレント)、利点(セキュリティ、キャッシング、匿名性)とウェブスクレイピングにおける重要な役割をカバーしています。Scrapeless Proxiesの特徴。
インターステラープロキシに関する包括的なガイドで、その機能、展開手順、そして信頼性の高い大規模データ操作にとってScrapeless Proxiesのようなプロフェッショナルソリューションがなぜ必須であるかについて説明します。

IPv4とIPv6の実際の速度とパフォーマンスを比較し、設計の違いやインフラへの影響、Scrapelessのようなデュアルプロトコルプロキシがデータスクレイピングやネットワーク操作をどのように最適化できるかを分析します。



