Loading...
🎯 カスタマイズ可能で検出回避型のクラウドブラウザ。自社開発のChromiumを搭載し、ウェブクローラーやAIエージェント向けに設計されています。👉今すぐ試す
すべてのWebスクレイピング開発者向けに作成された最も包括的なガイド。
Scrapelessは、大手企業から信頼されるAIを搭載した堅牢でスケーラブルなWebスクレイピングと自動化サービスを提供します。 私たちのエンタープライズグレードのソリューションは、プロジェクトのニーズを満たすように調整されており、全体にわたって専用の技術サポートがあります。 強力な技術チームと柔軟な配達時間を使用すると、データを成功させるためにのみ請求し、制限をバイパスしながら効率的なデータ抽出を可能にします。
あなたのビジネスの成長を促進するために今すぐお問い合わせください。
連絡先の詳細を提供すると、すぐに製品のデモと紹介を提供します。 GDPR標準に準拠して、お客様の情報が機密のままであることを確認します。
Python と Node.js で Playwright ステルスパッケージを使用して、ブラウザーフィンガープリンツを修正し、プロキシを管理し、ウェブスクレイピングのためにボット検出を回避する方法を学びましょう。

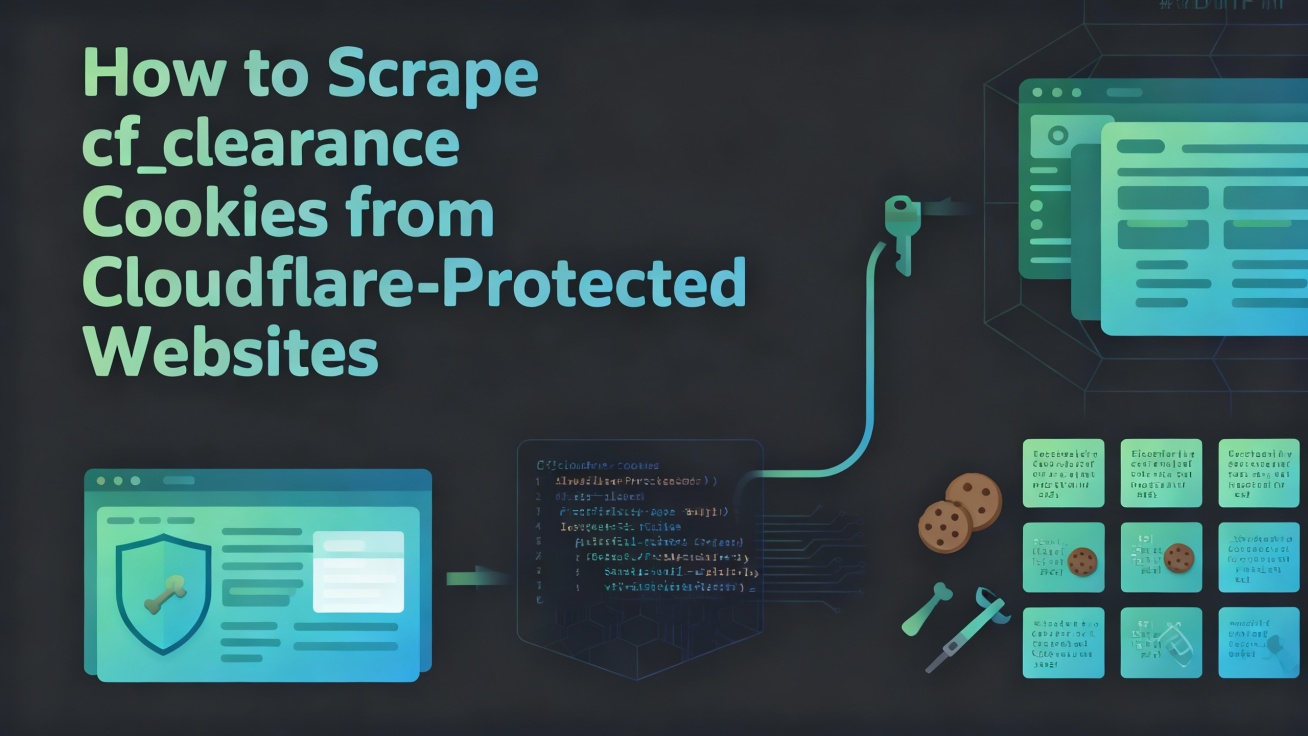
Cloudflareのcf_clearanceクッキーがどのように機能するか、クリアランスレベル、および手動トークン管理なしで持続的なスクレイピングセッションを維持する方法を学びましょう。
C++は優れたパーサーですが、使いにくいスクレイピングクライアントです。libcurlを使ってレンダリングAPIを通じて取得し、libxml2で解析します — g++の1行で、20のタイトルを解析し、ライブで検証しました。

ニュースクロールは2つのクリーンなループです:記事のリンクを発見し、次に各ストーリーを取得して抽出します。発見と40段落の記事が確認済みで生配信されます。

4つのページネーションタイプ、4つの停止条件。URLを推測するのではなく、サイト自身の次/もっと読み込むコントロールに従ってください—次ボタンの歩行は10ページ、100アイテムで確認済みです。

Instagramは独自のJSON APIからレンダリングを行います。したがって、x-ig-app-idヘッダーを使用して温かいセッションから直接呼び出してください。プロフィールの抽出はライブで確認されました。

src属性は、画像を見つけるための最も信頼性の低い場所です。まずスクロールし、currentSrcを読み取り、メタデータを保持し、セッションを通じてバイトを取得します— 20枚の画像がライブで確認されました。

信頼性のあるフォーム提出は、入力、送信、待機です — そして送信/待機はPromise.allでなければなりません。ログインとライブエンドポイントに対して検証されたマルチフィールドフォームです。



