
Googleの求人公開検索結果をスクレイピングする方法[無料かつ簡単]
Advanced Data Extraction Specialist
オンラインには何百万もの求人情報がありますが、Google Jobsを手動で閲覧するのは時間がかかり非効率です。Google Jobsの結果をスクレイピングすることで、このプロセスを自動化し、貴重な時間を節約し、最新の求人情報に迅速にアクセスできます。採用担当者、開発者、または関連データの収集を希望する求職者のいずれであっても、このガイドでは、Google Jobsの結果を効果的かつ責任ある方法でスクレイピングする方法をステップバイステップで説明します。始めましょう!
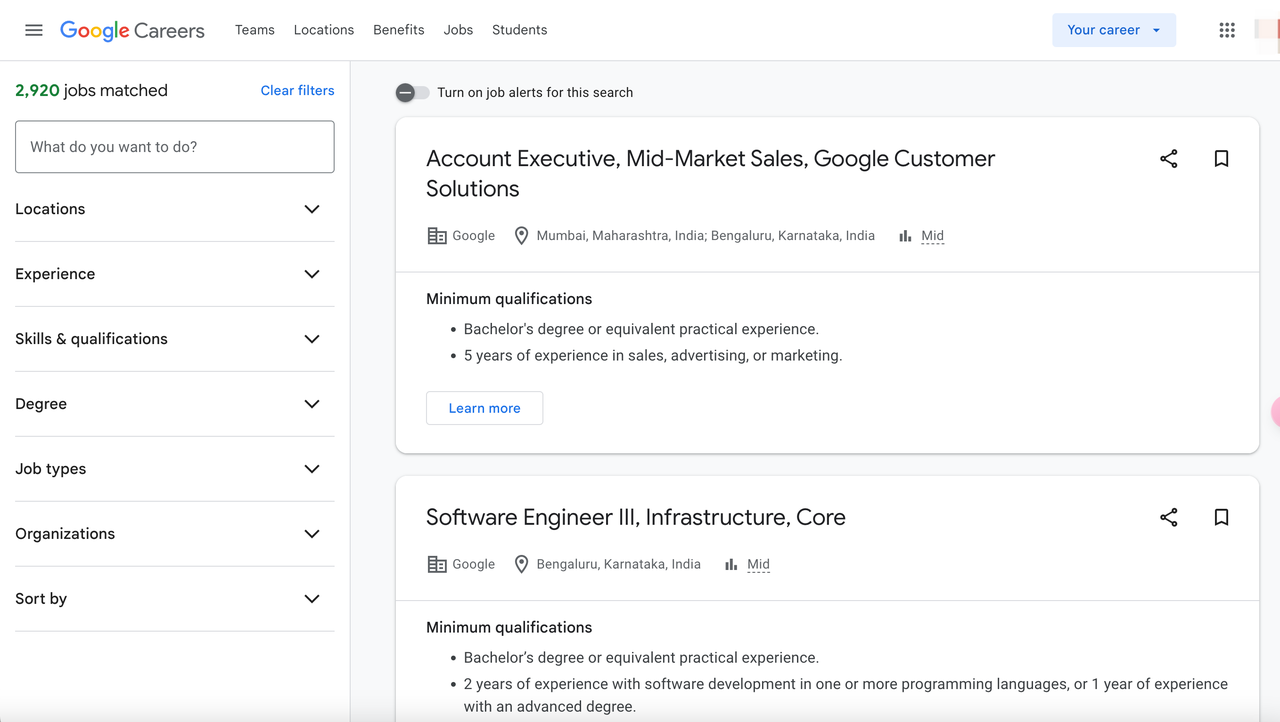
なぜGoogle Jobsをスクレイピングするのか?
Google Jobsは、求人サイト、企業ウェブサイト、人材派遣会社など、複数の情報源から求人情報を集約しています。Google Jobsのスクレイピングにより、以下のデータを取得できます。
- 労働市場の動向:需要の高いスキル、給与レンジ、職種を追跡します。
- 競合分析:競合他社の求人情報を分析します。
- 採用に関する洞察:リアルタイムデータに基づいて採用戦略を改善します。
Google Jobsは幅広い求職者と雇用主にサービスを提供しているため、このデータをスクレイピングすることで、求人サイト、人材紹介会社、人事部、市場調査担当者にとって大きなメリットがあります。
Google Jobsスクレイピングの課題
Google Jobsのスクレイピングは非常に価値がありますが、課題もあります。
- 反スクレイピング技術:Googleは、ボットによるデータのスクレイピングを防ぐために、CAPTCHA、IPブロック、レート制限などの技術を採用しています。
- HTMLの頻繁な変更:GoogleはWeb構造を頻繁に更新するため、スクレイパーは継続的に適応する必要があります。
- 法的懸念事項:Google JobsのスクレイピングはGoogleの利用規約に違反する可能性があるため、注意深く進めることが重要です。
つまり、適切なツールを使用すれば、これらの障壁を回避し、Google Jobsの結果を効果的にスクレイピングできます。
推奨ツール:Scrapelessを使用したGoogle Jobsのスクレイピング
Scrapeless Google Job Scraping APIは、Google Jobs検索エンジンから求人データを取得するためのツールです。ユーザーは、職種、会社名、勤務地、掲載日、職務内容など、特定の求人検索に関連する構造化データを、シンプルなAPI呼び出しを通じて取得できます。このAPIはデータ収集プロセスを簡素化するために設計されており、ユーザーはWebスクレイピングやパースの複雑さに取り組むことなく、データの分析と活用に集中できます。
Scrapeless Google Job Scraping API は、ユーザーが特定のニーズに応じて検索リクエストをカスタマイズできるさまざまなパラメーターを提供します。
一般的に使用されるパラメーターを以下に示します。
| パラメーター | 必須 | 説明 |
|---|---|---|
| engine | TRUE | Google Jobs APIエンジンを使用するには、パラメーターをgoogle_jobsに設定します。 |
| q | TRUE | 検索するクエリを定義するパラメーターです。 |
| uule | FALSE | 検索に使用するGoogleでエンコードされた場所です。uuleとlocationパラメーターを同時に使用することはできません。 |
| google_domain | FALSE | 使用するGoogleドメインを定義するパラメーターです。デフォルトはgoogle.comです。サポートされているGoogleドメインの完全なリストについては、Googleドメインページを参照してください。 |
| gl | FALSE | Google検索に使用する国を定義するパラメーターです。2文字の国コードです(例:米国はus、英国はuk、フランスはfr)。サポートされているGoogle国の完全なリストについては、Google国ページを参照してください。 |
| hl | FALSE | Google Jobs検索に使用する言語を定義するパラメーターです。2文字の言語コードです(例:英語はen、スペイン語はes、フランス語はfr)。サポートされているGoogle言語の完全なリストについては、Google言語ページを参照してください。 |
| next_page_token | FALSE | 次のページトークンを定義するパラメーターです。結果の次のページを取得するために使用されます。ページごとに最大10個の結果が返されます。次のページトークンは、SerpApi JSONレスポンスのpagination -> next_page_tokenにあります。 |
| lrad | TRUE | 検索半径をキロメートル単位で定義します。半径を厳密に制限するものではありません。 |
| ltype | TRUE | 在宅勤務による結果をフィルタリングします。 |
| uds | TRUE | 検索をフィルタリングするために使用します。Googleがフィルターとして提供する文字列です。uds値は、各フィルターに提供されるuds、q、link値を含むセクション「フィルター」の下に提供されます。 |
主な機能:
- 効率的な求人データクロール:リアルタイムでGoogle Jobsデータを取得し、構造化された求人情報を返し、分析と使用を容易にします。
- 容易な統合:複数のプログラミング言語(Python、JavaScriptなど)をサポートし、APIはJSON形式を返すため、統合と分析が容易です。
- 反クロール技術のバイパス:CAPTCHAと反クロール対策を自動的に処理し、IPブロックを心配することなく安定したクロールを保証します。
- 多次元フィルタリングとカスタム検索:職種、勤務地、給与などでフィルタリングでき、カスタムクエリを使用してニーズに正確に合わせることができます。
- ページングのサポート:手動でのページング処理を回避するために、複数のページの求人情報を自動的にクロールします。
- グローバルカバレッジ:クロスリージョンでのクロールをサポートし、多言語環境に適応し、グローバルな求人データを提供します。
- 分析とレポート:クロールされたデータは採用トレンド分析に使用でき、詳細なクロールレポートと統計情報を提供します。
- 信頼できる技術サポート:24時間365日のカスタマーサービスサポートを提供し、開発者が迅速に開始できるよう、詳細なドキュメントと例を提供します。
無料トライアルにサインアップして10万回の無料リクエストを取得しましょう!効率的なWebスクレイピングを今すぐ体験し、Google Jobsなどのデータを簡単に取得して、プロジェクトの迅速な開始を支援しましょう!この機会をお見逃しなく、今すぐ始めましょう!
Scrapelessを使用したGoogle Jobsの結果のスクレイピング方法
Scrapeless Google Job Scraping APIの使用は非常に簡単です。次の手順に従ってください。
1. ScrapelessアカウントにサインアップしてAPIキーを取得します。
開始するには、ScrapelessダッシュボードからAPIキーを取得する必要があります。
- Scrapelessダッシュボードにログインします。
- APIキー管理に移動します。
- 作成をクリックして、独自のAPIキーを生成します。
- 生成されたら、APIキーをクリックしてコピーします。

2. 必要なパラメーターを含むAPIリクエストURLを構築します。
- APIドキュメントにアクセスします。
- 目的のエンドポイントで「試してみる」をクリックします。
- 「認証」フィールドにAPIキーを入力します。
- パラメーター設定に必要なパラメーターを入力します。(ここでは、barista new yorkを例として使用します)
リクエストの例を以下に示します。
import requests
import json
url = "https://api.scrapeless.com/api/v1/scraper/request"
payload = json.dumps({
"actor": "scraper.google.jobs",
"input": {
"engine": "google_jobs",
"q": "barista new york"
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)3. APIエンドポイントにHTTPリクエストを送信します。
4. APIから返されたJSON形式のデータのパースを行います。
結果の例を以下に示します。APIドキュメントを通じて、具体的な情報を確認できます。
{
"filters": [
{
"name": "Salary",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=Barista+new+york+salary&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRh8EK4tyFmWRymX9upubXBbjB9KOIUC88GpIatv-n-DLX9TtKJXNMMIdYO2nQxb4xNzjttr0Uu43Lm-GmXHPL687fgvBmKH8qj2H7a2iTdJo0v3e37tUrY02SF9SsGMZ3e6PQT6rfudnU2eFoPJICzOXs6zcIod6Pfwk5wDtpqw_NEY9J&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQxKsJegQIDRAB&ictx=0",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRh8EK4tyFmWRymX9upubXBbjB9KOIUC88GpIatv-n-DLX9TtKJXNMMIdYO2nQxb4xNzjttr0Uu43Lm-GmXHPL687fgvBmKH8qj2H7a2iTdJo0v3e37tUrY02SF9SsGMZ3e6PQT6rfudnU2eFoPJICzOXs6zcIod6Pfwk5wDtpqw_NEY9J",
"q": "Barista new york salary"
}
},
{
"name": "Remote",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista%2Bnew%2Byork+remote&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RR9uegVYgQNm0A_FIwPHdCgp6BeV4cyixUjw1hgRDJQE5JaCKrpdXj8qAqGf0tBZYFos3UXw0dnkvxmLPGYpQ1yE9796a05FNrMXiTref7_yMgP5WfYbP3wPdvk9Hpbv8q3y-R1UTsn-dAlNF5N6OicWqVsFU&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQxKsJegQICxAB&ictx=0",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RR9uegVYgQNm0A_FIwPHdCgp6BeV4cyixUjw1hgRDJQE5JaCKrpdXj8qAqGf0tBZYFos3UXw0dnkvxmLPGYpQ1yE9796a05FNrMXiTref7_yMgP5WfYbP3wPdvk9Hpbv8q3y-R1UTsn-dAlNF5N6OicWqVsFU",
"q": "barista+new+york remote"
}
},
{
"name": "Date posted",
"options": [
{
"name": "Yesterday",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york since yesterday&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRnjGLk826jw_-m_gI8QkMG3DU62Ft1lBDpjQtJxI9n5nlvphZ_FhozuiZa-pL3OlfNFOvId9p73T3jFBmYJw05hbE-N1E2J12Se4S2XNj_H36-FruHX4cIe_j8ucbIbgQDsccD5Ht0tt1_fw91zMseXuY-BwyvhnOJiTzcgUbCOHZIRrKI_unZuhz8K9n1iIpXWV3AWpk95QNoL9B0qFURXiTlhykG63NrQz80D-aaM61vCTXQbTneARk4u1P870m6qmrYlxzFIesLLxnrvkOGKouA-AdW2wQ-2NEBupAK1JbQkL9sm7bwG6gYn0jjt-9oEOUaw&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQkbEKegQIDhAC",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRnjGLk826jw_-m_gI8QkMG3DU62Ft1lBDpjQtJxI9n5nlvphZ_FhozuiZa-pL3OlfNFOvId9p73T3jFBmYJw05hbE-N1E2J12Se4S2XNj_H36-FruHX4cIe_j8ucbIbgQDsccD5Ht0tt1_fw91zMseXuY-BwyvhnOJiTzcgUbCOHZIRrKI_unZuhz8K9n1iIpXWV3AWpk95QNoL9B0qFURXiTlhykG63NrQz80D-aaM61vCTXQbTneARk4u1P870m6qmrYlxzFIesLLxnrvkOGKouA-AdW2wQ-2NEBupAK1JbQkL9sm7bwG6gYn0jjt-9oEOUaw",
"q": "barista new york since yesterday"
}
},
{
"name": "Last 3 days",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york in the last 3 days&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRd1B6K-OJf2BQH1wRTP-WvlEGmt8-DwYPt192b7rPO2QTcWR6ib4kDRMCnL5tVQO8zO8RIE3h2OD731flcyiUpJA7ZkSb5ZOOKftaPnoXuSflVkzggT4i1-LmAD9fzly5xZp6y4SnVxMgTtvd2-WpYQVk-HlJi9DiLqRclx-08Fctyj76ilhCrPNTcmeYWmuT3xuop_zwqsM1_UfNSL0c8bLdkX1nPpadMD-n5uhcQ4y6Rbc4e50nyyw5-sVgk4XWD1razm6vSiNlcXlYeWYJ3osuWXRrHChhUVY3tXnTCv8I1_94wzPzrFNfwp_-qsGrzzJMWg&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQkbEKegQIDhAD",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRd1B6K-OJf2BQH1wRTP-WvlEGmt8-DwYPt192b7rPO2QTcWR6ib4kDRMCnL5tVQO8zO8RIE3h2OD731flcyiUpJA7ZkSb5ZOOKftaPnoXuSflVkzggT4i1-LmAD9fzly5xZp6y4SnVxMgTtvd2-WpYQVk-HlJi9DiLqRclx-08Fctyj76ilhCrPNTcmeYWmuT3xuop_zwqsM1_UfNSL0c8bLdkX1nPpadMD-n5uhcQ4y6Rbc4e50nyyw5-sVgk4XWD1razm6vSiNlcXlYeWYJ3osuWXRrHChhUVY3tXnTCv8I1_94wzPzrFNfwp_-qsGrzzJMWg",
"q": "barista new york in the last 3 days"
}
},
{
"name": "Last week",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york in the last なぜScrapelessがGoogle Jobsのスクレイピングに最適なのか?
- CAPTCHAなし:ScrapelessはCAPTCHAをバイパスしますため、スムーズなスクレイピングプロセスが保証されます。
- 自動プロキシ管理:このサービスはIPアドレスをローテーションしますし、プロキシを管理するため、Googleによってブロックされることはありません。
- 高い成功率:ScrapelessはGoogleの反ボット対策を効果的に処理するように構築されており、スクレイピングの高い成功率を提供します。
- 構造化データ:Scrapelessはデータを整理された形式で返すため、分析してワークフローに簡単に統合できます。
さらに、Scrapeless SERP APIは、Google Maps、Google Flights、Google Trends、Google検索結果ページなどからのデータ抽出もサポートしています。
Google Jobsスクレイピングのベストプラクティス
スクレイピングは効果的ですが、問題を避けるためにベストプラクティスに従うことが重要です。
- **Googleの利用規約を尊重する:**Google Jobsのスクレイピングは利用規約に違反する可能性があるため、常に責任あるスクレイピングを行い、潜在的な法的リスクを理解してください。
- **リクエストを調整する:**短時間でGoogleに過剰なリクエストを送信しないでください。検出を避けるために、レート制限やランダムな遅延などの機能を使用してください。
- **スクレイピングのパフォーマンスを監視する:**スクレイピングツールの性能を定期的に監視し、期待通りに動作していることと、データが正確であることを確認してください。
Google Jobsスクレイパーに関するFAQ
1. Google Jobsスクレイパーとは何ですか?
Google Jobsスクレイパーは、Google Jobsから求人情報を抽出するために設計されたツールです。職種、会社名、勤務地、給与、職務内容などの貴重なデータの収集に役立ちます。
2. Google Mapsのスクレイピングは合法ですか?
公開されているデータを倫理的な理由でスクレイピングすることは、法律に違反しません。
まとめ
Google Jobsの結果をスクレイピングすることで、労働市場に関する貴重な洞察を得て、採用戦略を最適化し、企業の競争力を維持することができます。Scrapelessは、CAPTCHA、IPブロック、複雑なコーディングの問題に煩わされることなく、Googleから求人情報をスクレイピングするための優れたソリューションを提供します。Scrapelessを使用することで、構造化された求人データを迅速に収集し、市場調査や採用活動に活用できます。
データアナリスト、採用担当者、または採用トレンドを理解したい企業のいずれであっても、ScrapelessはGoogle Jobsデータにアクセスするためのシンプルで信頼性が高く、効果的な方法を提供します。
今すぐScrapelessを使用し、スクレイピング効率を向上させましょう!サインアップするだけで10万回の無料リクエストを取得でき、Discordコミュニティに参加してアクティビティに参加して無料クレジットを獲得できます!
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


