
Scrapeless वेब अनलॉकर से वेबसाइटों को अनब्लॉक कैसे करें?
Senior Web Scraping Engineer
वेब स्क्रैपिंग अब डेटा विश्लेषण और मार्केट रिसर्च, और निश्चित रूप से, प्रतियोगी विश्लेषण के लिए व्यापक रूप से उपयोग किया जाता है। हालाँकि, हम अनिवार्य रूप से कुछ क्रॉलिंग बाधाओं का सामना करेंगे, जैसे कि आईपी ब्लॉकिंग, जटिल जावास्क्रिप्ट रेंडरिंग और CAPTCHA सत्यापन। एक प्रमुख चिंता जो उपयोगकर्ता अक्सर उठाते हैं, वह यह है: क्या वेबसाइटों को स्क्रैप करना कानूनी है?
स्वचालित कार्य करते समय पता लगाए जाने और अवरुद्ध होने से कैसे बचें?
यह लेख आपको सबसे प्रभावी और समय की बचत करने वाले तरीके दिखाएगा।
अभी पढ़ना शुरू करें!
वेबसाइटों को स्क्रैप करते समय मुझे बार-बार ब्लॉक क्यों किया जा रहा है?
वेब स्क्रैपिंग युक्तियों में कूदने से पहले, सबसे पहले, आपको सामान्य एंटी-बॉट उपायों को जानना होगा जिनका आप वेब डेटा स्क्रैप करते समय सामना कर सकते हैं।
यदि आप हमेशा नेटवर्क ब्लॉक का सामना करते हैं, तो निम्नलिखित 8 पहलुओं की जाँच करें:
1️⃣ एक ही आईपी से अत्यधिक अनुरोध
वेबसाइटें ट्रैफ़िक पैटर्न की निगरानी करती हैं और उन आईपी पतों को ब्लॉक कर सकती हैं जो कम समय में बहुत अधिक अनुरोध करते हैं। यह अक्सर स्क्रैपिंग और दुरुपयोग को रोकने के लिए किया जाता है।
2️⃣ आईपी ब्लैकलिस्टिंग
यदि आपकी स्क्रैपिंग गतिविधि को संदिग्ध के रूप में चिह्नित किया गया है, तो वेबसाइट आपके आईपी को ब्लैकलिस्ट कर सकती है। ऐसा हो सकता है यदि आप बार-बार एक ही आईपी पते से साइट तक पहुँचते हैं या पहचान योग्य व्यवहार पैटर्न का उपयोग करते हैं जो किसी बॉट से मिलते-जुलते हैं।
3️⃣ कैप्चा का उपयोग
कई वेबसाइटें मानव उपयोगकर्ताओं और बॉट्स के बीच अंतर करने के लिए CAPTCHA चुनौतियों का उपयोग करती हैं। यदि आपका स्क्रैपर किसी CAPTCHA चुनौती को ट्रिगर करता है, तो उसे CAPTCHA हल होने तक ब्लॉक किया जा सकता है।
4️⃣ जावास्क्रिप्ट रेंडरिंग
जटिल जावास्क्रिप्ट वाली वेबसाइटें सामग्री को छिपा सकती हैं या गतिशील रूप से उत्पन्न कर सकती हैं। पारंपरिक स्क्रैपिंग विधियाँ इसके साथ संघर्ष करती हैं, जिसके परिणामस्वरूप अधूरा या विफल स्क्रैप होता है।
यह सबसे बुनियादी कारण है कि वेबसाइटें आपके स्क्रैपर को ब्लॉक करती हैं। JS रेंडर चुनौती को कैसे पार करें? चिंता मत करो। हम इसे बाद में हल कर सकते हैं।
5️⃣ उपयोगकर्ता-एजेंट पहचान
वेबसाइटें अक्सर यह देखने के लिए "उपयोगकर्ता-एजेंट" स्ट्रिंग की जांच करती हैं कि अनुरोध किसी वास्तविक ब्राउज़र से आ रहा है या किसी बॉट से। स्क्रैपिंग टूल जो किसी वास्तविक ब्राउज़र की सही नकल नहीं करते हैं, उन्हें पता लगाया और ब्लॉक किया जा सकता है।
6️⃣ दर सीमा और सत्र समाप्ति
वेबसाइटें आपके द्वारा किसी निश्चित समय सीमा के भीतर किए जा सकने वाले अनुरोधों की संख्या को सीमित कर सकती हैं, और आपका सत्र कुछ क्रियाओं की संख्या के बाद समाप्त हो सकता है। बार-बार वेबसाइट पर आने से अस्थायी या स्थायी अवरोध हो सकता है।
7️⃣ फिंगरप्रिंटिंग
आधुनिक वेबसाइटें स्वचालित स्क्रैपिंग का पता लगाने के लिए ब्राउज़र फिंगरप्रिंटिंग तकनीकों का उपयोग करती हैं। यह विधि स्क्रीन रिज़ॉल्यूशन, समय क्षेत्र और अन्य ब्राउज़र विशेषताओं जैसे अद्वितीय पैटर्न को ट्रैक करती है, जिससे वेबसाइटों के लिए स्क्रैपिंग टूल की पहचान करना और उन्हें ब्लॉक करना आसान हो जाता है।
8️⃣ भू-अवरुद्ध
कुछ वेबसाइटें आईपी पते के भौगोलिक स्थान के आधार पर पहुँच को प्रतिबंधित करती हैं। यदि आप किसी ऐसे क्षेत्र से स्क्रैप कर रहे हैं जहाँ पहुँच की अनुमति नहीं है, तो आप ब्लॉक का सामना कर सकते हैं।
स्क्रैपलेस वेब अनलॉकर - वेबसाइटों को स्क्रैप करने का सबसे अच्छा समाधान
स्क्रैपलेस न केवल एक प्रमुख वेबसाइट अनब्लॉकर है, बल्कि एक व्यापक वेब स्क्रैपिंग समाधान भी है।
एक शक्तिशाली वेब अनब्लॉकर के रूप में, स्क्रैपलेस उपयोगकर्ताओं को सरलीकृत और कुशल HTML निष्कर्षण सेवाएँ प्रदान करता है। अपनी उन्नत प्रॉक्सी चयन तकनीक और स्वचालित अनब्लॉकिंग तंत्र के साथ, स्क्रैपलेस आसानी से जटिल एंटी-क्रॉलर सुरक्षा को बायपास कर सकता है और उपयोगकर्ताओं को आवश्यक डेटा जल्दी से प्राप्त करने में मदद कर सकता है।
हमें स्क्रैपलेस वेब अनलॉकर क्यों चुनना चाहिए?
⚙️ कुशल जावास्क्रिप्ट रेंडरिंग (JSRender)
स्क्रैपलेस की JSRender तकनीक एक उन्नत ब्राउज़र सिमुलेशन रेंडरिंग इंजन का उपयोग करती है जो वास्तविक समय में वेब पेजों में गतिशील सामग्री लोडिंग को संभाल सकती है। यह आधुनिक वेबसाइटों के लिए विशेष रूप से उपयुक्त है जिनके लिए सामग्री उत्पन्न करने के लिए जावास्क्रिप्ट की आवश्यकता होती है, जैसे कि गतिशील पृष्ठ, सिंगल-पेज एप्लिकेशन (एसपीए), आदि।
पारंपरिक क्रॉलर टूल की तुलना में, स्क्रैपलेस का JSRender कम समय में जावास्क्रिप्ट द्वारा उत्पन्न जटिल डेटा को प्रस्तुत कर सकता है, जो ऐसी सामग्री को क्रॉल करने के लिए बहुत महत्वपूर्ण है जिसके लिए इंटरैक्शन या गतिशील अपडेट की आवश्यकता होती है (जैसे ई-कॉमर्स वेबसाइटों पर उत्पाद विवरण पृष्ठ)। उदाहरण के लिए, शॉपी, अमेज़ॅन और लाज़ादा से उत्पाद पृष्ठों को स्क्रैप करते समय, स्क्रैपलेस किसी भी महत्वपूर्ण जानकारी को छोड़े बिना सभी गतिशील डेटा (जैसे कीमत, इन्वेंट्री, समीक्षा, आदि) को लोड और निकाल सकता है।
- अमेज़ॅन उत्पाद डेटा, विक्रेता की जानकारी और खोज डेटा कैसे स्क्रैप करें?
- शॉपी से उत्पाद डेटा आसानी से स्क्रैप करें
- लाज़ादा उत्पाद विवरण 2025 को स्क्रैप करने के लिए पूरी गाइड
🧩 आईपी प्रतिबंधों को दरकिनार करना
स्क्रैपलेस एक अंतर्निहित बुद्धिमान प्रॉक्सी पूल प्रदान करता है जो एक स्थिर पहुँच अनुभव सुनिश्चित करने के लिए स्वचालित रूप से आईपी स्विच कर सकता है। प्रॉक्सी पूल बुद्धिमानी से उच्च-गुणवत्ता वाले आईपी संसाधनों का चयन करता है, ताकि बड़े पैमाने पर क्रॉलिंग में भी, यह वेबसाइट के आईपी ब्लॉकिंग और प्रतिबंधों को प्रभावी ढंग से बायपास कर सके, यह सुनिश्चित कर सके कि क्रॉलिंग कार्य सुचारू रूप से आगे बढ़े।
उपयोगकर्ताओं को कोई अतिरिक्त कॉन्फ़िगरेशन करने की आवश्यकता नहीं है। हम उच्चतम स्तर के स्वचालन को सुनिश्चित करते हैं, जिससे बहुत समय और प्रयास की बचत होती है। उपयोगकर्ता आईपी ब्लॉकिंग के बारे में चिंता किए बिना व्यावसायिक तर्क पर ध्यान केंद्रित कर सकते हैं।
⚔️ स्वचालित CAPTCHA सॉल्वर
स्क्रैपलेस में एक एकीकृत CAPTCHA सॉल्वर है जो इमेज CAPTCHA, टेक्स्ट CAPTCHA और Google reCAPTCHA चुनौतियों को संभालने में सक्षम है। यह बिना किसी मैन्युअल हस्तक्षेप के निर्बाध स्क्रैपिंग सत्र सुनिश्चित करता है।
जिन लोगों को आश्चर्य हो रहा है, क्या वेबसाइटों को स्क्रैप करना कानूनी है?—उत्तर वेबसाइट की सेवा की शर्तों और डेटा संग्रह की प्रकृति पर निर्भर करता है। जबकि सार्वजनिक रूप से उपलब्ध जानकारी अक्सर उचित खेल है, वेब स्क्रैपिंग करते समय नैतिक और कानूनी विचारों को हमेशा ध्यान में रखा जाना चाहिए।
स्क्रैपलेस बायपास तंत्र को स्वचालित करके प्रक्रिया को सरल बनाता है, जिससे व्यवसायों और डेवलपर्स को कुशलतापूर्वक मूल्यवान अंतर्दृष्टि निकालने पर ध्यान केंद्रित करने की अनुमति मिलती है।
स्क्रैपलेस वेब अनलॉकर का उपयोग कैसे करें?
- चरण 1। स्क्रैपलेस में लॉग इन करें।
- चरण 2। "वेब अनलॉकर" दर्ज करें।
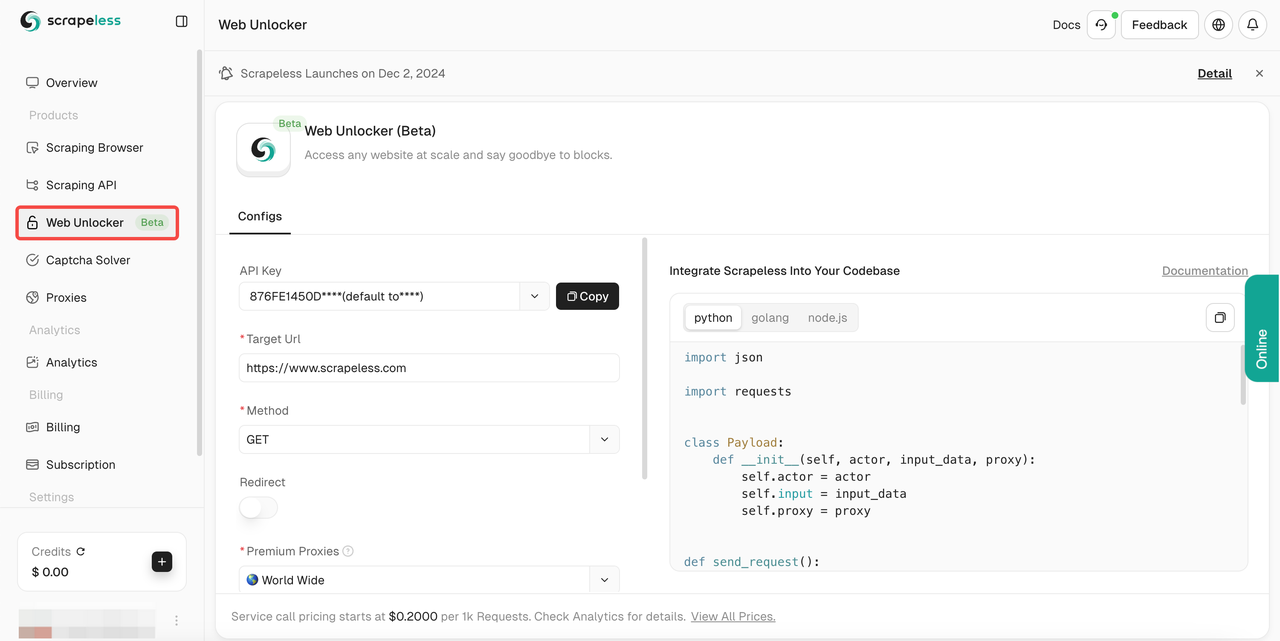
- चरण 3। अपनी आवश्यकताओं के अनुसार बाईं ओर संचालन पैनल को कॉन्फ़िगर करें:
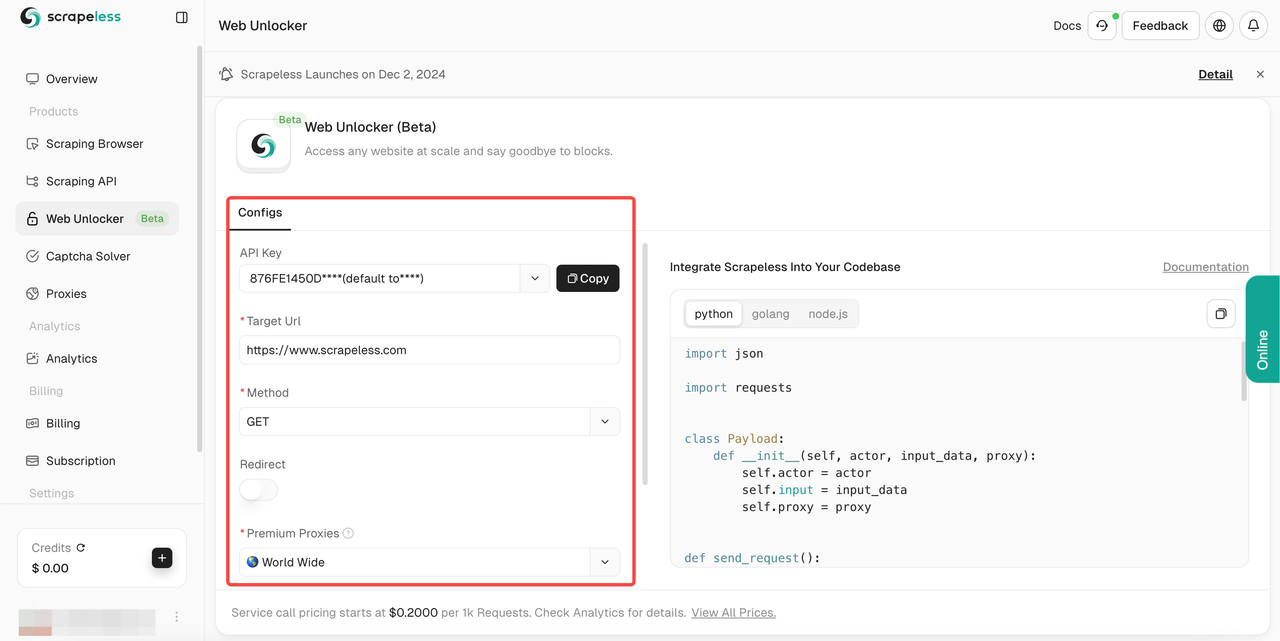
- चरण 4। अपना
लक्ष्य urlभरने के बाद, स्क्रैपलेस स्वचालित रूप से आपके लिए सामग्री क्रॉल करेगा। आप दाईं ओर परिणाम प्रदर्शन बॉक्स में क्रॉलिंग परिणाम देख सकते हैं। कृपया अपनी आवश्यक भाषा का चयन करें:Python,Golang, याnode.js, और अंत में परिणाम की प्रतिलिपि बनाने के लिए ऊपरी दाएँ कोने में लोगो पर क्लिक करें।
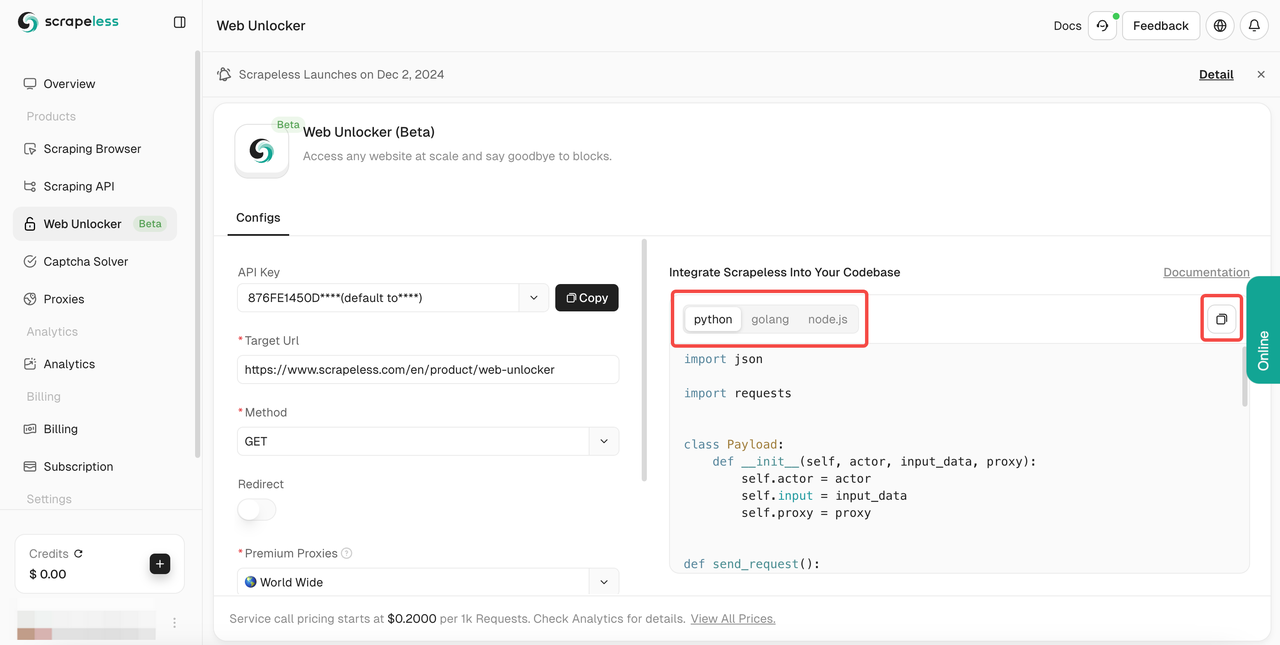
यह सुनिश्चित करता है कि आप बिना किसी रुकावट के किसी भी सार्वजनिक वेबसाइट तक पहुँच सकते हैं। यह विभिन्न क्रॉलिंग विधियों का समर्थन करता है, जावास्क्रिप्ट को प्रस्तुत करने में उत्कृष्टता प्राप्त करता है, और आपको वेब ब्राउज़ करने के लिए उपकरण प्रदान करने के लिए एंटी-क्रॉल तकनीक को लागू करता है।
या आप अपनी खुद की परियोजना में प्रभावी ढंग से एकीकृत करने के लिए नीचे दिए गए हमारे नमूना कोड का उपयोग कर सकते हैं:
- Url: लक्ष्य वेबसाइट
- Method: अनुरोध विधि
- Redirect: क्या पुनर्निर्देशन की अनुमति है
- Headers: कस्टम अनुरोध हेडर फ़ील्ड
Python:
Python
import requests
import json
url = "https://api.scrapeless.com/api/v1/unlocker/request"
payload = json.dumps({
"actor": "unlocker.webunlocker",
"input": {
"url": "https://httpbin.io/get",
"proxy_country": "US",
"type": "",
"redirect": False,
"method": "GET",
"request_id": "",
"extractor": ""
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)JavaScript:
JavaScript
var myHeaders = new Headers();
myHeaders.append("Content-Type", "application/json");
var raw = JSON.stringify({
"actor": "unlocker.webunlocker",
"input": {
"url": "https://httpbin.io/get",
"proxy_country": "US",
"type": "",
"redirect": false,
"method": "GET",
"request_id": "",
"extractor": ""
}
});
var requestOptions = {
method: 'POST',
headers: myHeaders,
body: raw,
redirect: 'follow'
};
fetch("https://api.scrapeless.com/api/v1/unlocker/request", requestOptions)
.then(response => response.text())
.then(result => console.log(result))
.catch(error => console.log('error', error));Go
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/unlocker/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://httpbin.io/get",
"proxy_country": "US",
"type": "",
"redirect": false,
"method": "GET",
"request_id": "",
"extractor": ""
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}अवरुद्ध हुए बिना वैकल्पिक समाधान
1. आईपी रोटेशन
पहला तरीका जिससे कोई स्क्रैपिंग वेबसाइट किसी वेब क्रॉलर का पता लगाती है, वह उसके आईपी पते की जाँच करके और वेबसाइट के साथ उसकी बातचीत को ट्रैक करके है। अगर सर्वर "उस उपयोगकर्ता" से व्यवहार का एक अजीब पैटर्न या असंभव अनुरोध आवृत्ति देखता है, तो सर्वर उस आईपी पते को फिर से वेबसाइट तक पहुँचने से रोक सकता है।
एक ही आईपी पते के माध्यम से सभी अनुरोध भेजने से बचने के लिए, आप अपने अनुरोधों को प्रॉक्सी के पूल के माध्यम से रूट करने के लिए एक आईपी रोटेशन सेवा (जैसे स्क्रैपलेस के घूमने वाले आवासीय प्रॉक्सी) का उपयोग कर सकते हैं, वेबसाइट को क्रॉल करते समय अपने वास्तविक आईपी पते को छिपा सकते हैं। यह आपको अधिकांश वेबसाइटों को बिना ब्लॉक किए क्रॉल करने की अनुमति देगा।
आवासीय प्रॉक्सी का उपयोग क्यों करें? क्योंकि सख्त ब्लॉकिंग आवश्यकताओं वाली कुछ वेबसाइटों पर, वे आपके प्रॉक्सी डिटेक्शन के बारे में अधिक सख्त होंगे। एक आवासीय प्रॉक्सी चुनने से आपके क्रॉलर की पहचान अधिक वास्तविक हो जाएगी, जिससे आपकी स्क्रैपिंग वेबसाइट के प्रयास अधिक स्थिर हो जाएँगे।
अंततः, आईपी रोटेशन का उपयोग करके, आपका क्रॉलर अनुरोधों को विभिन्न उपयोगकर्ताओं से आने वाले दिखा सकता है और ऑनलाइन ट्रैफ़िक के सामान्य व्यवहार की नकल कर सकता है।
स्क्रैपलेस प्रॉक्सी का उपयोग करते समय, हमारा बुद्धिमान आईपी रोटेशन सिस्टम डेटा सेंटर, आवासीय और मोबाइल प्रॉक्सी पूल से आवश्यकतानुसार अपने प्रॉक्सी को घुमाने के लिए वर्षों के सांख्यिकीय विश्लेषण और मशीन लर्निंग का लाभ उठाएगा ताकि 99.99% सफलता दर सुनिश्चित हो सके।
2. हेडलेस ब्राउज़र का उपयोग करें
सबसे कठिन स्क्रैपिंग वेबसाइटें वेब फ़ॉन्ट, एक्सटेंशन, ब्राउज़र कुकीज़ और जावास्क्रिप्ट निष्पादन जैसे सूक्ष्म संकेतों का पता लगा सकती हैं ताकि यह निर्धारित किया जा सके कि अनुरोध किसी वास्तविक उपयोगकर्ता से आ रहा है या नहीं।
इन वेबसाइटों को स्क्रैप करने के लिए, आपको अपना स्वयं का हेडलेस ब्राउज़र तैनात करना पड़ सकता है (या स्क्रैपलेस स्क्रैपिंग ब्राउज़र को आपके लिए यह करने देना होगा!)।
हेडलेस ब्राउज़र आपको एक वास्तविक वेब ब्राउज़र को नियंत्रित करने के लिए एक प्रोग्राम लिखने की अनुमति देते हैं जो वास्तविक उपयोगकर्ता द्वारा उपयोग किए जाने वाले ब्राउज़र के समान है ताकि पूरी तरह से पता लगाने से बचा जा सके।
3. CAPTCHA सॉल्वर प्रदाता
CAPTCHA सॉल्वर तृतीय-पक्ष सेवाएँ हैं जिनका हम अक्सर उपयोग करते हैं। वे ऑप्टिकल कैरेक्टर रिकॉग्निशन (OCR), मशीन लर्निंग, या तृतीय-पक्ष मानव सॉल्वर जैसी तकनीकों का उपयोग करके स्वचालित रूप से CAPTCHA चुनौतियों को मुफ्त में हल करते हैं, जिससे स्क्रैपिंग बॉट वेब ब्लॉक को बायपास कर सकते हैं।
ये उपकरण CAPTCHA सत्यापन के कारण होने वाले व्यवधानों को रोककर निरंतर, स्वचालित स्क्रैपिंग वेबसाइट गतिविधियों को सक्षम करते हैं। मानव जैसे व्यवहार की नकल करके या वास्तविक समय में CAPTCHA को हल करके, वे बॉट के रूप में पता लगाने से बचने और एक सहज स्क्रैपिंग प्रक्रिया बनाए रखने में मदद करते हैं।
हालांकि, ऐसे उपकरणों का उपयोग करने के नैतिक और कानूनी निहितार्थों पर विचार करना महत्वपूर्ण है, क्योंकि वे वेबसाइट की सेवा की शर्तों और गोपनीयता नीतियों का उल्लंघन कर सकते हैं। क्या वेबसाइटों को स्क्रैप करना कानूनी है? यह अधिकार क्षेत्र और वेबसाइट की शर्तों पर निर्भर करता है। हमेशा स्थानीय कानूनों और विनियमों का पालन सुनिश्चित करें। इसके अलावा, इन उपकरणों की कीमत आमतौर पर अधिक होती है।
4. वास्तविक उपयोगकर्ता एजेंट सेट करें
स्क्रैपिंग वेबसाइट गतिविधियों के दौरान पता लगाने से बचने के लिए एक वास्तविक उपयोगकर्ता-एजेंट सेट करना एक सामान्य तरीका है। वेबसाइटें अक्सर यह पहचानने के लिए अनुरोधों में उपयोगकर्ता-एजेंट हेडर का उपयोग करती हैं कि क्या वे किसी वास्तविक उपयोगकर्ता ब्राउज़र से या स्वचालित बॉट से आते हैं। उपयोगकर्ता-एजेंट को स्पूफिंग या रैंडमाइज़ करके, स्क्रैपिंग स्क्रिप्ट ऐसा प्रतीत हो सकता है जैसे वे किसी नियमित उपयोगकर्ता से आ रहे हैं, जिससे पता लगाए जाने की संभावना कम हो जाती है।
इसे कैसे लागू करें:
- किसी वास्तविक ब्राउज़र के उपयोगकर्ता-एजेंट को स्पूफ करें
वास्तविक उपयोगकर्ताओं के व्यवहार की नकल करने के लिए सामान्य ब्राउज़र उपयोगकर्ता-एजेंट स्ट्रिंग्स (जैसे क्रोम, फ़ायरफ़ॉक्स, सफ़ारी, आदि) का उपयोग करें। उदाहरण के लिए, पायथन में, आप requests लाइब्रेरी का उपयोग करके एक विशिष्ट ब्राउज़र उपयोगकर्ता-एजेंट हेडर सेट कर सकते हैं:
Python
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get('https://example.com', headers=headers)- गतिशील रूप से उपयोगकर्ता-एजेंट घुमाएँ
प्रॉक्सी पूल या एपीआई (जैसे random-user-agent) का उपयोग करके पता लगाने से बचने के लिए विभिन्न उपयोगकर्ता-एजेंट स्ट्रिंग्स को घुमाएँ। इससे वेबसाइटों के लिए एकल उपयोगकर्ता-एजेंट के आधार पर स्क्रैपिंग पैटर्न को पहचानना कठिन हो जाता है।
5. अन्य हेडर मिलाएँ
उपयोगकर्ता-एजेंट के अलावा, आप किसी वास्तविक ब्राउज़र के अनुरोध की और नकल करने के लिए अन्य हेडर (जैसे Referer, Accept-Language, आदि) को भी स्पूफ कर सकते हैं।
आमतौर पर, यह देखना सबसे अच्छा होता है कि यह Google से एक्सेस किया जा रहा है।
आप इसे एक हेडर के साथ कर सकते हैं: "Referer": "https://www.google.com/"
यह वेबसाइटों के लिए स्वचालित अनुरोधों और वास्तविक उपयोगकर्ता इंटरैक्शन के बीच अंतर करना और भी चुनौतीपूर्ण बना सकता है।
6. क्रॉलिंग अनुरोधों के बीच एक यादृच्छिक अंतराल सेट करें
वेबसाइटें अक्सर अनुरोधों की आवृत्ति और नियमितता के आधार पर स्क्रैपिंग गतिविधि का पता लगाती हैं। यदि अनुरोध बहुत जल्दी या किसी पूर्वानुमेय पैटर्न में आते हैं, तो वेबसाइटों के लिए स्क्रैपर की पहचान करना और उसे ब्लॉक करना आसान होता है। अनुरोधों के बीच यादृच्छिक देरी शुरू करके, आप अपने स्क्रैपिंग व्यवहार को अधिक स्वाभाविक दिखा सकते हैं।
आप अनुरोधों के बीच देरी शुरू करने के लिए पायथन में time.sleep() फ़ंक्शन का उपयोग कर सकते हैं। एक यादृच्छिक अंतराल सेट करके, आप प्रत्येक अनुरोध के बीच समय को बदल सकते हैं ताकि व्यवहार कम अनुमानित हो सके।
Python
import time
import random
import requests
# 1 से 3 सेकंड के बीच यादृच्छिक विलंब के साथ एक अनुरोध भेजें
headers = {'User-Agent': 'Mozilla/5.0'}
url = 'https://example.com'
for i in range(10):
response = requests.get(url, headers=headers)
print(f"Request {i+1} Status: {response.status_code}")
time.sleep(random.uniform(1, 3)) # 1 और 3 सेकंड के बीच यादृच्छिक नींद7. हनीपॉट ट्रैप से बचें
कई वेबसाइटें वेब क्रॉलर का पता लगाने के लिए अदृश्य लिंक का उपयोग करती हैं, क्योंकि केवल बॉट ही उनका पालन करेंगे।
पता लगाने से बचने के लिए, आपको यह जांचना चाहिए कि क्या किसी लिंक में CSS गुण "display: none" या "visibility: hidden." है। यदि कोई भी सेट है, तो लिंक पर न जाएँ! ऐसा करने में विफल रहने से आपके क्रॉलर का पता लगाया जा सकता है, जिससे सर्वर आपके अनुरोध विशेषताओं की पहचान कर सकता है और आपको ब्लॉक कर सकता है।
हनीपॉट वेबसाइटों द्वारा क्रॉलर को स्पॉट करने के लिए उपयोग की जाने वाली एक सामान्य विधि है, इसलिए हर पेज को स्क्रैप करने पर यह जांच करना सुनिश्चित करें।
इसके अलावा, कुछ उन्नत वेबमास्टर लिंक के रंग को सफेद (या पृष्ठभूमि के रंग से मेल खाते हुए) भी सेट कर सकते हैं, इसलिए यह "color: #fff;" या "color: #ffffff" जैसे गुणों की जांच करने लायक है यह सुनिश्चित करने के लिए कि लिंक अदृश्य बना रहे।
8. Google कैश हटाएँ
स्क्रैपिंग करते समय अवरुद्ध होने से बचने के लिए, Google के कैश को साफ़ करना या बायपास करना महत्वपूर्ण है, क्योंकि यह आपकी पिछली बातचीत को संग्रहीत कर सकता है और वेबसाइटों को संदिग्ध स्क्रैपिंग गतिविधि का पता लगाने में मदद कर सकता है। Google के कैश से निपटने के लिए यहां कुछ रणनीतियाँ दी गई हैं:
Puppeteer: स्क्रैपिंग सत्रों के बीच कुकीज़ और कैश को साफ़ करने के लिए Puppeteer में clearBrowserCookies() और clearBrowserCache() फ़ंक्शन का उपयोग करें:
JavaScript
cookies and cache between scraping sessions.
const browser = await puppeteer.launch();
const page = await browser.newPage();
// कैश और कुकीज़ साफ़ करें
await page.clearBrowserCache();
await page.clearBrowserCookies();क्रॉलिंग को सरल और कुशल बनाने का समय!
स्क्रैपलेस वेब अनलॉकर एक शक्तिशाली उपकरण है जो एक बुद्धिमान प्रॉक्सी पूल, कुशल जावास्क्रिप्ट रेंडरिंग (JSRender) और स्वचालित CAPTCHA प्रसंस्करण को एकीकृत करता है, जिसे वेबसाइटों को स्क्रैप करने में आम समस्याओं को हल करने के लिए डिज़ाइन किया गया है। स्क्रैपलेस जटिल स्क्रैपिंग कार्यों को सरल, कुशल और विश्वसनीय बनाता है।
यदि आप स्क्रैपिंग की सीमाओं को तोड़ना और दक्षता में सुधार करना चाहते हैं, चाहे वह जटिल गतिशील पृष्ठों या बड़े पैमाने पर स्क्रैपिंग कार्यों से निपटने का हो, स्क्रैपलेस वेब अनलॉकर आपका विश्वसनीय समाधान है।
अभी मुफ्त में स्क्रैपलेस का उपयोग शुरू करें और अद्वितीय स्क्रैपिंग प्रदर्शन का अनुभव करें और अपने डेटा संग्रह को आसान बनाएं!
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


