
Python का उपयोग करके Lazada उत्पाद डेटा कैसे स्क्रैप करें?
Specialist in Anti-Bot Strategies
लाज़ादा उत्पाद स्क्रैपिंग क्या है?
लाज़ादा एक ऑनलाइन मार्केटप्लेस है जहाँ विभिन्न व्यापारी सामान बेचते हैं, और इस डेटा को स्क्रैप करना विभिन्न अनुप्रयोगों के लिए फायदेमंद है, जिसमें मूल्य निगरानी, बाजार अनुसंधान, इन्वेंट्री प्रबंधन और प्रतिस्पर्धी विश्लेषण शामिल हैं।
लाज़ादा विभिन्न सुविधाएँ प्रदान करता है जैसे सुरक्षित भुगतान विकल्प, ग्राहक समीक्षाएँ, और एक वितरण प्रणाली जो ग्राहक खरीद और घर-घर डिलीवरी की सुविधा प्रदान करती है।
लाज़ादा वेब स्क्रैपिंग स्वचालित उपकरणों या स्क्रिप्ट का उपयोग करके लाज़ादा वेबसाइट से डेटा प्राप्त करने की प्रक्रिया है।
स्क्रैपिंग लाज़ादा वेब पेजों से विशिष्ट जानकारी प्राप्त करने का अभ्यास है, जैसे उत्पाद विवरण (जैसे नाम, मूल्य, विवरण और फ़ोटो), विक्रेता की जानकारी, उपयोगकर्ता समीक्षाएँ और रेटिंग। हालाँकि, यह याद रखना महत्वपूर्ण है कि ऑनलाइन स्क्रैपिंग कानूनी मुद्दों के अधीन हो सकता है, और कुछ वेबसाइटों की सेवा की शर्तें बिना अनुमति के उनके डेटा को स्क्रैप करने पर प्रतिबंध लगाती हैं।
आपको लाज़ादा वेब क्रॉलिंग की आवश्यकता क्यों है?
- मूल्य निगरानी और तुलना। लाज़ादा पर उत्पाद डेटा क्रॉल करने से व्यवसायों या उपभोक्ताओं को मूल्य में उतार-चढ़ाव को ट्रैक करने, समान उत्पादों के मूल्य के रुझानों का विश्लेषण करने और खरीदने का सबसे अच्छा समय खोजने में मदद मिल सकती है।
- बाजार विश्लेषण। लाज़ादा के डेटा को क्रॉल करके व्यवसाय बाजार की गतिशीलता जैसे सबसे अधिक बिकने वाले उत्पाद, उपयोगकर्ता समीक्षा, उत्पाद रैंकिंग आदि प्राप्त कर सकते हैं। इससे बिक्री रणनीतियों को अनुकूलित करने, बाजार की मांग की भविष्यवाणी करने और अधिक सटीक मार्केटिंग योजनाएँ विकसित करने में मदद मिलती है।
- उत्पाद सूचना संग्रहण। ई-कॉमर्स कंपनियों या एजेंटों के लिए जिन्हें बड़े पैमाने पर उत्पाद कैटलॉग का प्रबंधन करने की आवश्यकता होती है, लाज़ादा के उत्पाद डेटा (जैसे उत्पाद का नाम, विवरण, मूल्य, इन्वेंट्री जानकारी, आदि) को क्रॉल करने से उत्पाद डेटा में प्रवेश और अपडेट करने और दक्षता में सुधार करने की गति तेज हो सकती है।
- प्रतिस्पर्धी विश्लेषण। लाज़ादा पर प्रतिस्पर्धियों की उत्पाद सूची, मूल्य निर्धारण रणनीतियों और प्रचारों को क्रॉल करके, कंपनियां अपने प्रतिस्पर्धियों के बाजार में स्थिति के बारे में जानकारी प्राप्त कर सकती हैं और अधिक प्रतिस्पर्धी व्यावसायिक योजनाएँ विकसित कर सकती हैं।
- टिप्पणी और रेटिंग विश्लेषण। उपयोगकर्ता टिप्पणियां और रेटिंग उपभोक्ता निर्णय लेने के महत्वपूर्ण आधार हैं। इस जानकारी को क्रॉल करके, कंपनियां उत्पादों पर उपभोक्ता प्रतिक्रिया का विश्लेषण कर सकती हैं, जिससे उत्पादों या सेवाओं में सुधार हो सकता है और उपयोगकर्ता अनुभव को बढ़ाया जा सकता है।
- एक उत्पाद मूल्य तुलना मंच बनाएँ। कुछ स्टार्टअप या प्रौद्योगिकी प्लेटफॉर्म को मूल्य तुलना वेबसाइट या एप्लिकेशन बनाने के लिए लाज़ादा के डेटा को क्रॉल करने की आवश्यकता होती है, जिससे उपयोगकर्ता विभिन्न प्लेटफार्मों पर आसानी से कीमतों और छूट की जानकारी की तुलना कर सकते हैं।
- स्वचालित इन्वेंट्री प्रबंधन। व्यापारियों के लिए, लाज़ादा के डेटा को क्रॉल करने से स्वचालित रूप से जांच की जा सकती है कि क्या किसी विशेष उत्पाद की इन्वेंट्री या कीमत में बदलाव आया है, ताकि वे समय पर अपनी उत्पाद रणनीतियों को समायोजित कर सकें।
- व्यावसायिक अवसरों का पता लगाएं। संभावित व्यावसायिक अवसरों की खोज करने और नए व्यावसायिक दिशानिर्देश खोलने में मदद करने के लिए लाज़ादा के सबसे अधिक बिकने वाले उत्पादों और अविकसित उत्पाद क्षेत्रों को क्रॉल करें।
लाज़ादा डेटा क्रॉल करने के लिए पायथन भाषा का चुनाव क्यों करें?
- शक्तिशाली क्रॉलर पारिस्थितिकी तंत्र
पायथन में क्रॉलर से संबंधित पुस्तकालयों और ढाँचों का खजाना है, जैसे:
requests: सरल और उपयोग में आसान, स्थिर वेब पेज डेटा प्राप्त करने के लिए HTTP अनुरोध भेजने के लिए उपयुक्त।BeautifulSoup: हल्का HTML पार्सिंग लाइब्रेरी, वेब पेज सामग्री को आसानी से निकालने के लिए।Scrapy: शक्तिशाली क्रॉलर ढांचा, कुशल वितरित क्रॉलिंग और डेटा प्रबंधन का समर्थन करता है।Selenium: गतिशील वेब पेज सामग्री को संसाधित करने के लिए उपयोग किया जाता है, स्वचालित ब्राउज़र संचालन का समर्थन करता है।
ये उपकरण लाज़ादा वेब क्रॉलिंग के विभिन्न परिदृश्यों के लिए आसानी से अनुकूल हो सकते हैं।
- समृद्ध डेटा प्रसंस्करण क्षमताएँ
पायथन शक्तिशाली डेटा प्रसंस्करण और विश्लेषण उपकरण प्रदान करता है, जैसे:
pandas: कुशल डेटा तालिका संचालन उपकरण, क्रॉल किए गए डेटा को संग्रहीत और संसाधित करना आसान है।csvऔरjson: सामान्य डेटा संग्रहण स्वरूपों के लिए अंतर्निहित समर्थन, परिणामों को आसानी से आउटपुट करना।NumPyऔरmatplotlib: डेटा के आँकड़ों और दृश्यीकरण के लिए शक्तिशाली उपकरण।
ये उपकरण डेटा क्रॉलिंग से लेकर विश्लेषण तक सब कुछ एक ही स्थान पर पूरा करना संभव बनाते हैं।
- गतिशील वेब पेज प्रसंस्करण क्षमताएँ
लाज़ादा की गतिशील रूप से लोड की गई सामग्री के लिए, सेलेनियम और प्लेराइट जैसे उपकरणों के साथ संयुक्त पायथन वास्तविक उपयोगकर्ता व्यवहार का अनुकरण कर सकता है और जावास्क्रिप्ट प्रतिपादन सीमाओं को दरकिनार कर सकता है। इसके अलावा, क्लाउड ब्राउज़र सेवाओं (जैसे ब्राउज़रलेस) के साथ, गतिशील वेब पेज प्रसंस्करण की दक्षता में और सुधार किया जा सकता है।
- अत्यधिक स्केलेबल
पायथन में अच्छी स्केलेबिलिटी है और इसे प्रॉक्सी पूल प्रबंधन उपकरणों (जैसे प्रॉक्सी-रोटेटर), CAPTCHA समाधान उपकरणों (जैसे एंटीकेप्टचा) और डेटा संग्रहण सेवाओं (जैसे MySQL और MongoDB) के साथ आसानी से एकीकृत किया जा सकता है ताकि बड़े पैमाने पर क्रॉलिंग आवश्यकताओं को पूरा किया जा सके।
क्या लाज़ादा उत्पाद को स्क्रैप करने का कोई आसान तरीका है?
अपना पायथन लाज़ादा स्क्रैपर बनाना हमेशा ब्लॉक होने से बचना चाहिए, जो सिरदर्द लगता था। सौभाग्य से, यहाँ बिना किसी कठिनाई के लाज़ादा उत्पाद को स्क्रैप करने का एक आसान तरीका है!
स्क्रैपलेस - सबसे अच्छा लाज़ादा स्क्रैपिंग एपीआई
स्क्रैपलेस एक उन्नत वेब स्क्रैपिंग प्लेटफ़ॉर्म है जिसे व्यवसायों और डेवलपर्स के लिए डिज़ाइन किया गया है, जिन्हें सटीक, सुरक्षित और स्केलेबल डेटा निष्कर्षण की आवश्यकता होती है। यह लाज़ादा और अमेज़ॅन जैसे ई-कॉमर्स प्लेटफ़ॉर्म सहित विभिन्न स्रोतों से डेटा एकत्र करने की प्रक्रिया को सरल बनाने के लिए उन्नत समाधान प्रदान करता है।
अपने शक्तिशाली डिज़ाइन के साथ, स्क्रैपलेस आपको अपने स्वयं के स्क्रैपिंग उपकरणों के निर्माण और रखरखाव की आवश्यकता को समाप्त करता है, और आसानी से CAPTCHA को हल करने, एंटी-बॉट सिस्टम और आईपी रोटेशन जैसी जटिल चुनौतियों को संभाल सकता है। चाहे आप उत्पाद विवरण, मूल्य रुझान या ग्राहक समीक्षा एकत्र करना चाहते हों, स्क्रैपलेस आपकी डेटा आवश्यकताओं को पूरा करने का एक विश्वसनीय और कुशल तरीका प्रदान करता है।
स्क्रैपलेस लाज़ादा स्क्रैपिंग एपीआई कैसे तैनात करें?
- चरण 1। स्क्रैपलेस में लॉग इन करें।
- चरण 2। "स्क्रैपिंग एपीआई" पर क्लिक करें
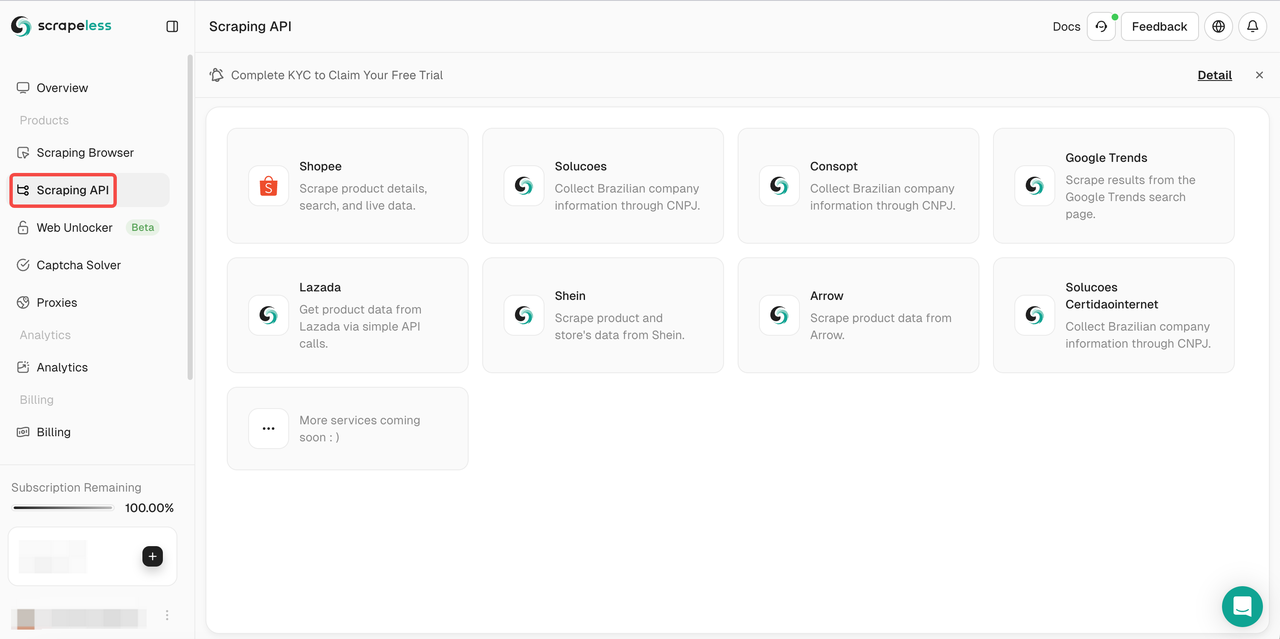
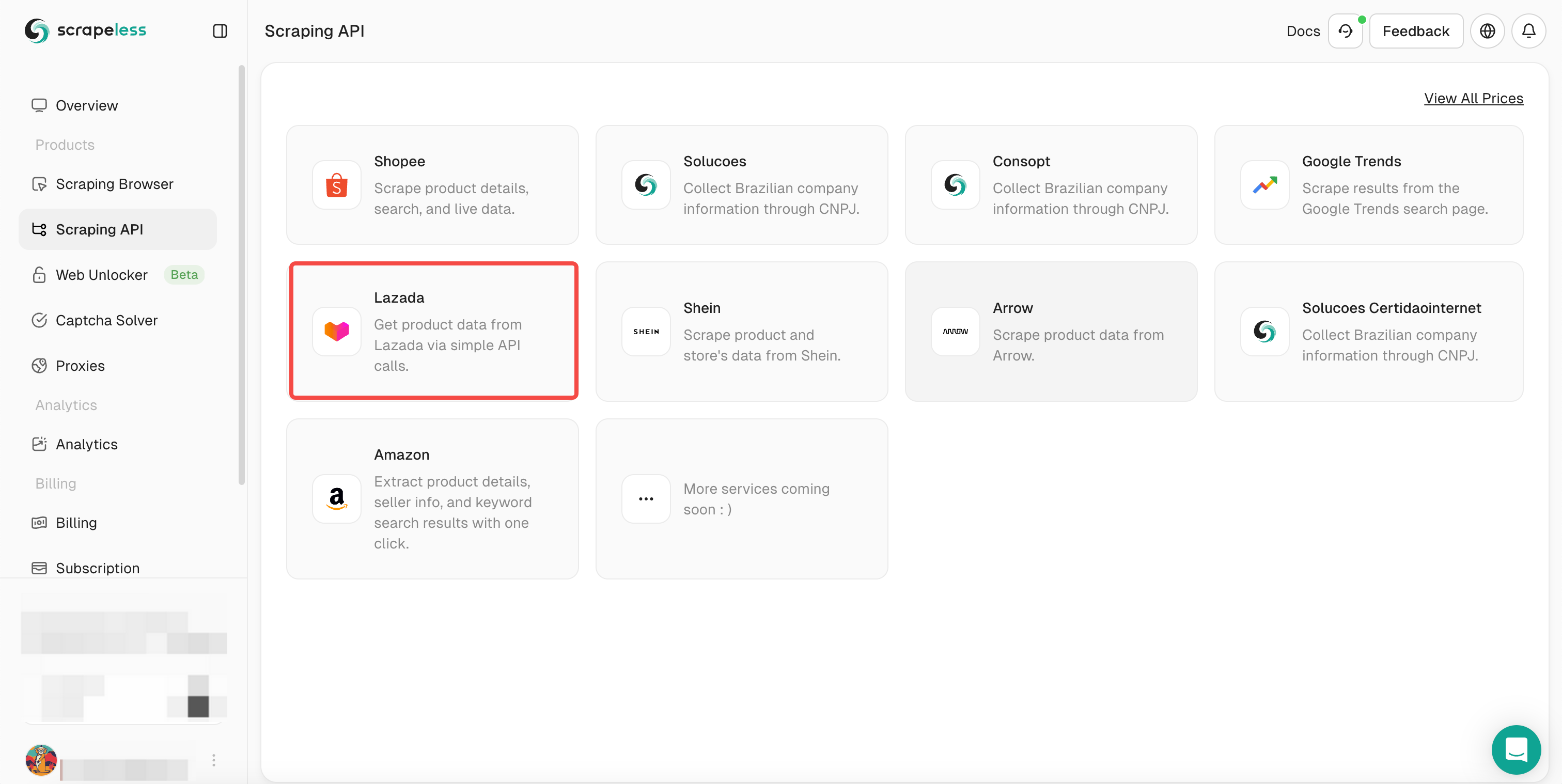
- चरण 3। लाज़ादा का चयन करें और लाज़ादा स्क्रैपिंग पृष्ठ दर्ज करें।
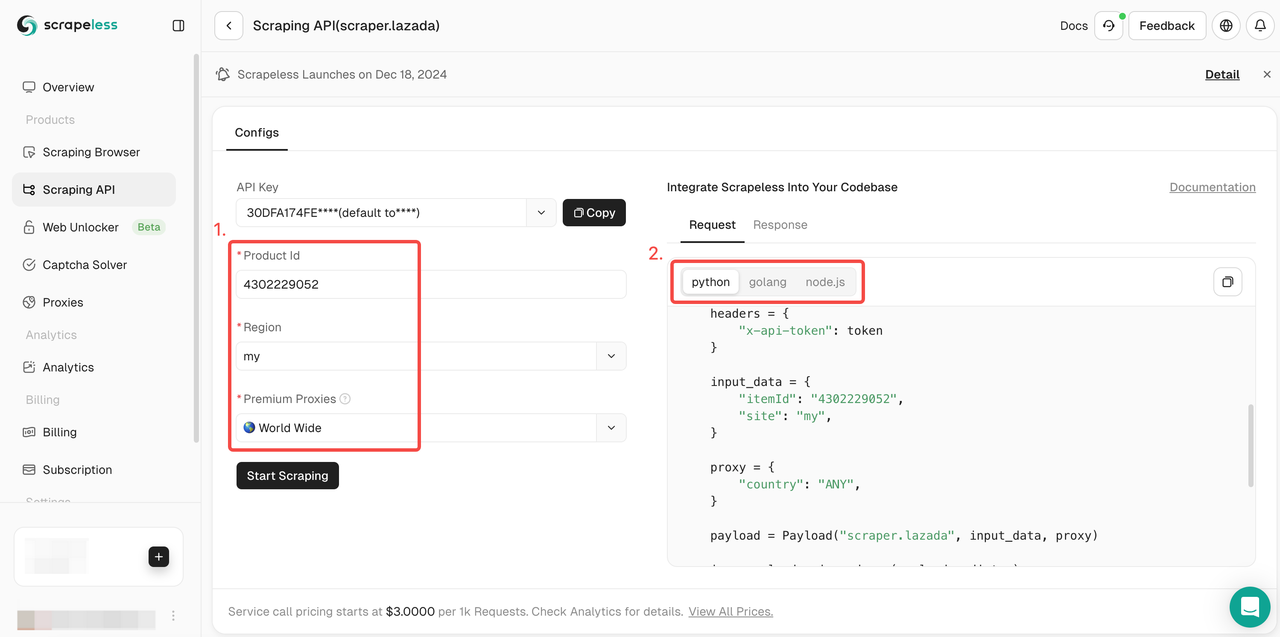
- चरण 4। क्रिया सूची को नीचे खींचें और क्रॉल की जाने वाली डेटा स्थिति सेटिंग्स का चयन करें। फिर स्क्रैपिंग प्रारंभ करें पर क्लिक करें।
- चरण 5। क्रॉल कुछ सेकंड में सफल हो जाएगा। संबंधित संरचित डेटा दाईं ओर प्रदर्शित होगा।
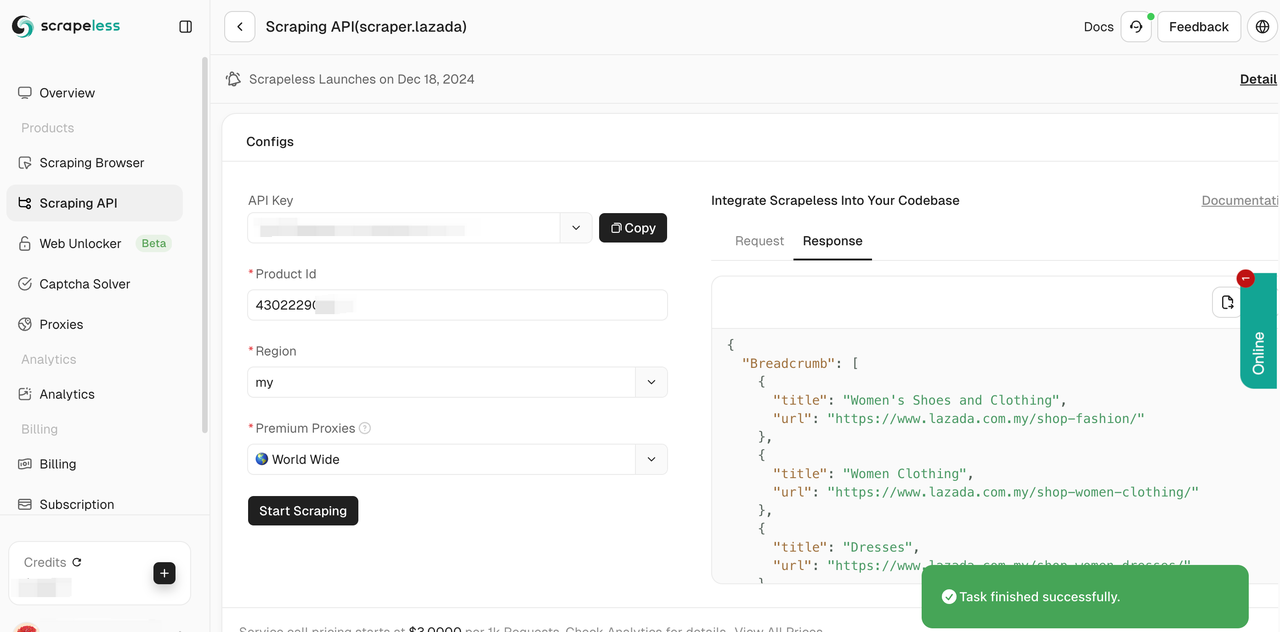
आप अपने प्रोजेक्ट में हमारे संदर्भ कोड को एकीकृत कर सकते हैं और अपने बड़े पैमाने पर डेटा स्क्रैपिंग को तैनात कर सकते हैं। यहाँ हम पायथन को एक उदाहरण के रूप में लेते हैं। आप हमारे क्लाइंट में गोलोंग और नोडजेएस का भी उपयोग कर सकते हैं।
- पायथन:
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = " " #आपका एपीआई टोकन
headers = {
"x-api-token": token
}
input_data = {
"itemId": " ", #उत्पाद आईडी इनपुट करें
"site": "my",
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.lazada", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("त्रुटि:", response.status_code, response.text)
return
print("बॉडी", response.text)
if __name__ == "__main__":
send_request()पायथन का उपयोग करके लाज़ादा उत्पाद डेटा कैसे निकालें?
चरण 1: पर्यावरण सेट करें
आवश्यक पायथन लाइब्रेरी स्थापित करें। आपको मुख्य रूप से HTTP अनुरोध भेजने के लिए requests और HTML को पार्स करने के लिए BeautifulSoup की आवश्यकता होगी। यदि साइट गतिशील सामग्री का उपयोग करती है, तो आप Selenium या Browserless जैसी क्लाउड ब्राउज़र सेवाओं का उपयोग कर सकते हैं। आवश्यक लाइब्रेरी इस प्रकार स्थापित करें:
Bash
pip install requests beautifulsoup4 seleniumचरण 2: लाज़ादा वेबसाइट का निरीक्षण करें
अपने ब्राउज़र में लाज़ादा खोलें और उस पृष्ठ का पता लगाएँ जिसे आप स्क्रैप करना चाहते हैं (जैसे, उत्पाद लिस्टिंग या खोज परिणाम)। पृष्ठ संरचना का निरीक्षण करने और उत्पाद डेटा जैसे नाम, मूल्य और लिंक के लिए टैग और कक्षाओं की पहचान करने के लिए डेवलपर टूल (F12) का उपयोग करें।
चरण 3: एक HTTP अनुरोध भेजें
स्थिर पृष्ठों के लिए, GET अनुरोध भेजने के लिए requests लाइब्रेरी का उपयोग करें। वास्तविक ब्राउज़र की नकल करने के लिए User-Agent जैसे शीर्षलेख शामिल करें।
Python
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
url = 'https://www.lazada.com.my/shop-mobiles/'
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())
else:
print(f" ")चरण 4: HTML सामग्री को पार्स करें
उपयुक्त HTML टैग और कक्षाओं की पहचान करके उत्पाद जानकारी निकालने के लिए BeautifulSoup का उपयोग करें।
Python
products = soup.find_all('div', class_='c16H9d') #वास्तविक वर्ग नामों से बदलें
for product in products:
name = product.text
print(f"उत्पाद का नाम: {name}")चरण 5: गतिशील सामग्री को संभालें
यदि पृष्ठ सामग्री को जावास्क्रिप्ट का उपयोग करके गतिशील रूप से लोड किया जाता है, तो पूरी सामग्री को प्रस्तुत करने के लिए सेलेनियम या क्लाउड ब्राउज़र का उपयोग करें।
Python
from selenium import webdriver
driver = webdriver.Chrome() # सुनिश्चित करें कि आपने ChromeDriver स्थापित किया है
driver.get('https://www.lazada.com.my/shop-mobiles/')
#सामग्री लोड होने और स्क्रैप करने की प्रतीक्षा करें
elements = driver.find_elements_by_class_name('c16H9d')
for element in elements:
print(f"उत्पाद का नाम: {element.text}")
driver.quit()चरण 6: एंटी-बॉट उपायों का प्रबंधन करें
लाज़ादा बॉट को ब्लॉक करने के लिए तकनीकों का उपयोग कर सकता है। पता लगाने से बचने के लिए निम्नलिखित रणनीतियों का उपयोग करें:
- प्रॉक्सी रोटेशन: IP प्रतिबंधों से बचने के लिए घूर्णन प्रॉक्सी का उपयोग करें।
- उपयोगकर्ता-एजेंट स्पूफिंग: शीर्षलेखों में उपयोगकर्ता-एजेंट को यादृच्छिक करें।
- क्लाउड ब्राउज़र: Browserless जैसी सेवाएँ उन्नत पता लगाने प्रणालियों को दरकिनार करने में मदद कर सकती हैं।
चरण 7: डेटा संग्रहीत करें
भविष्य के उपयोग के लिए स्क्रैप किए गए डेटा को CSV फ़ाइल या डेटाबेस में सहेजें।
Python
import csv
with open('lazada_products.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['उत्पाद का नाम', 'मूल्य', 'URL']) #उदाहरण शीर्षलेख
#यहाँ उत्पाद विवरण जोड़ेंनिचली पंक्तियाँ
लाज़ादा उत्पाद डेटा को स्क्रैप करने से ई-कॉमर्स स्पेस में व्यवसायों के लिए एक महत्वपूर्ण अवसर मिलता है। प्राप्त डेटा बाजार अनुसंधान, प्रतियोगी विश्लेषण, मूल्य अनुकूलन और अन्य विभिन्न डेटा-संचालित रणनीतिक पहलों के लिए एक मूल्यवान संसाधन है।
स्क्रैपलेस स्क्रैपिंग एपीआई लाज़ादा उत्पाद स्क्रैपिंग को सरल और कुशल बनाता है। CAPTCHA को दरकिनार करने और IP स्मार्ट रोटेशन के साथ, आप वेबसाइट ब्लॉकिंग से बच सकते हैं और आसानी से डेटा स्क्रैपिंग प्राप्त कर सकते हैं।
अभी साइन इन करें और निःशुल्क परीक्षण प्राप्त करें!
आगे पढ़ना:
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


