
Crawl4AI को Scrapeless Cloud ब्राउजर के साथ कैसे बढ़ाएं
Advanced Data Extraction Specialist
इस ट्यूटोरियल में, आप सीखेंगे:
- Crawl4AI क्या है और यह वेब स्क्रैपिंग के लिए क्या पेशकश करता है
- Scrapeless ब्राउज़र के साथ Crawl4AI को कैसे एकीकृत करें
आइए शुरू करते हैं!
भाग 1: Crawl4AI क्या है?
अवलोकन
Crawl4AI एक ओपन-सोर्स वेब क्रॉलिंग और स्क्रैपिंग उपकरण है जिसे बड़े भाषा मॉडल (LLMs), एआई एजेंटों और डेटा पाइपलाइनों के साथ सहजता से एकीकृत करने के लिए डिज़ाइन किया गया है। यह उच्च गति, वास्तविक समय में डेटा निकालने की अनुमति देता है जबकि यह लचीला और तैनात करने में आसान भी है।
एआई-संचालित वेब स्क्रैपिंग के लिए प्रमुख विशेषताएँ:
- LLMs के लिए निर्मित: पुनः प्राप्ति-इजाफा पीढ़ी (RAG) और फाइन-ट्यूनिंग के लिए अनुकूलित संरचित मार्कडाउन उत्पन्न करता है।
- लचीला ब्राउज़र नियंत्रण: सत्र प्रबंधन, प्रॉक्सी उपयोग और कस्टम हुक का समर्थन करता है।
- ह्यूरिस्टिक बुद्धिमत्ता: डेटा पार्सिंग (data parsing) को अनुकूलित करने के लिए स्मार्ट एल्गोरिदम का उपयोग करता है।
- पूर्णतः ओपन-सोर्स: कोई एपीआई कुंजी की आवश्यकता नहीं; डॉकर और क्लाउड प्लेटफ़ॉर्म के माध्यम से तैनात किया जा सकता है।
आधिकारिक दस्तावेज़ीकरण में और जानें।
उपयोग के मामले
Crawl4AI बड़े पैमाने पर डेटा निकालने के कार्यों के लिए आदर्श है जैसे कि बाजार अनुसंधान, न्यूज़ एग्रीगेशन और ई-कॉमर्स उत्पाद संग्रहण। यह गतिशील, जावास्क्रिप्ट-भारी वेबसाइटों को संभाल सकता है और एआई एजेंटों और स्वचालित डेटा पाइपलाइनों के लिए एक विश्वसनीय डेटा स्रोत के रूप में कार्य करता है।
भाग 2: Scrapeless ब्राउज़र क्या है?
Scrapeless ब्राउज़र एक क्लाउड-आधारित, सर्वर रहित ब्राउज़र स्वचालन उपकरण है। इसे गहराई से अनुकूलित क्रोमियम कर्नेल पर बनाया गया है, जिसका समर्थन वैश्विक स्तर पर वितरित सर्वरों और प्रॉक्सी नेटवर्क द्वारा किया जाता है। यह उपयोगकर्ताओं को कई हेडलेस ब्राउज़र इंस्टेंस को सुचारू रूप से चलाने और प्रबंधित करने की अनुमति देता है, जिससे एआई अनुप्रयोगों और एआई एजेंटों का निर्माण करना आसान हो जाता है जो वेब के साथ बड़े पैमाने पर इंटरैक्ट करते हैं।
भाग 3: Scrapeless को Crawl4AI के साथ क्यों जोड़े?
Crawl4AI संरचित वेब डेटा निकालने में उत्कृष्ट है और LLM-चालित पार्सिंग और पैटर्न-आधारित स्क्रैपिंग का समर्थन करता है। हालांकि, यह उन्नत एंटी-बॉट तंत्रों के साथ काम करते समय चुनौतियों का सामना कर सकता है, जैसे:
- स्थानीय ब्राउज़र को क्लाउडफ्लेयर, AWS WAF या reCAPTCHA द्वारा अवरुद्ध किया जाना
- बड़े पैमाने पर समवर्ती क्रॉलिंग के दौरान प्रदर्शन की बाधाएँ, धीमी ब्राउज़र प्रारंभ
- जटिल डिबगिंग प्रक्रियाएँ जो समस्या ट्रैकिंग को कठिन बना देती हैं
Scrapeless क्लाउड ब्राउज़र इन पीड़ा बिंदुओं को पूरी तरह से हल करता है:
- एक-क्लिक एंटी-बॉट बायपास: अपने आप reCAPTCHA, क्लाउडफ्लेयर टर्नस्टाइल/चुनौती, AWS WAF, और अधिक को संभालता है। Crawl4AI की संरचित निकासी शक्ति के साथ मिलकर, यह सफलता दर को काफी बढ़ाता है।
- असीमित समवर्ती स्केलिंग: कुछ सेकंड के भीतर प्रत्येक कार्य के लिए 50–1000+ ब्राउज़र इंस्टेंस लॉन्च करें, स्थानीय क्रॉलिंग प्रदर्शन सीमाओं को हटाते हुए और Crawl4AI की दक्षता को अधिकतम करते हुए।
- 40%–80% लागत में कमी: समान क्लाउड सेवाओं की तुलना में, कुल लागत केवल 20%–60% गिर जाती है। पे-एज़-यू-गो मूल्य निर्धारण इसे छोटे पैमाने पर परियोजनाओं के लिए भी सस्ती बनाता है।
- दृश्य डिबगिंग उपकरण: Crawl4AI कार्यों को वास्तविक समय में देखने के लिए सत्र पुनर्प्राप्ति और सीधे यूआरएल निगरानी का उपयोग करें, तेजी से विफलता के कारणों की पहचान करें, और डिबगिंग ओवरहेड को कम करें।
- शून्य लागत एकीकरण: Playwright (जो Crawl4AI द्वारा उपयोग किया जाता है) के साथ स्वाभाविक रूप से संगत, Crawl4AI को क्लाउड से जोड़ने के लिए केवल एक पंक्ति का कोड आवश्यक — कोई कोड पुनर्गठन की आवश्यकता नहीं।
- एज नोड सेवा (ENS): कई वैश्विक नोड्स प्रारंभिक गति और स्थिरता 2–3x तेजी से प्रदान करते हैं, Crawl4AI निष्पादन को तेज करते हैं।
- अलग वातावरण और स्थायी सत्र: प्रत्येक Scrapeless प्रोफ़ाइल अपने स्वयं के वातावरण में चलती है जिसमें स्थायी लॉगिन और पहचान अलगाव होता है, सत्र हस्तक्षेप से रोकता है और बड़े पैमाने पर स्थिरता में सुधार करता है।
- लचीला फिंगरप्रिंट प्रबंधन: Scrapeless यादृच्छिक ब्राउज़र फिंगरप्रिंट उत्पन्न कर सकता है या कस्टम कॉन्फ़िगरेशन का उपयोग कर सकता है, प्रभावी ढंग से पहचान जोखिमों को कम करता है और Crawl4AI की सफलता दर को बढ़ाता है।
भाग 4: Crawl4AI में Scrapeless का उपयोग कैसे करें?
Scrapeless एक क्लाउड ब्राउज़र सेवा प्रदान करता है जो आमतौर पर एक CDP_URL लौटाता है। Crawl4AI सीधे इस URL का उपयोग करके क्लाउड ब्राउज़र से कनेक्ट कर सकता है, बिना स्थानीय रूप से ब्राउज़र लॉन्च किए।
नीचे दिया गया उदाहरण Crawl4AI को Scrapeless क्लाउड ब्राउज़र के साथ सुचारू रूप से एकीकृत करने का प्रदर्शन करता है, जबकि स्वचालित प्रॉक्सी घुमाव, कस्टम फिंगरप्रिंट, और प्रोफ़ाइल पुन: उपयोग का समर्थन करता है।
अपना Scrapeless टोकन प्राप्त करें
Scrapeless में लॉग इन करें और अपना API टोकन प्राप्त करें।
1. त्वरित प्रारंभ
नीचे दिया गया उदाहरण Crawl4AI को Scrapeless Cloud Browser से त्वरित और आसान तरीके से कनेक्ट करने का तरीका दिखाता है:
अधिक सुविधाओं और विस्तृत निर्देशों के लिए, परिचय देखें।
scrapeless_params = {
"token": "अपना टोकन प्राप्त करें https://www.scrapeless.com से",
"sessionName": "Scrapeless ब्राउज़र",
"sessionTTL": 1000,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url
)
)कॉन्फ़िगरेशन के बाद, Crawl4AI CDP (Chrome DevTools Protocol) मोड के माध्यम से Scrapeless Cloud Browser से कनेक्ट होता है, जो बिना स्थानीय ब्राउज़र वातावरण के वेब स्क्रैपिंग को सक्षम बनाता है। उपयोगकर्ता प्रॉक्सी, फिंगरप्रिंट, सत्र पुनरुपयोग और उच्च-संयोग और जटिल एंटी-बॉट परिदृश्यों की मांगों को पूरा करने के लिए अन्य सुविधाओं को और कॉन्फ़िगर कर सकते हैं।
2. वैश्विक स्वचालित प्रॉक्सी रोटेशन
Scrapeless 195 देशों में आवासीय आईपी का समर्थन करता है। उपयोगकर्ता proxycountry का उपयोग करके लक्षित क्षेत्र को कॉन्फ़िगर कर सकते हैं, जिससे विशेष स्थानों से अनुरोध भेजे जा सकें। आईपी को स्वचालित रूप से घुमाया जाता है, जिससे ब्लॉकों से प्रभावी ढंग से बचा जा सकता है।
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "आपका टोकन",
"sessionTTL": 1000,
"sessionName": "प्रॉक्सी डेमो",
# प्रॉक्सी के लिए लक्षित देश/क्षेत्र सेट करता है, उस क्षेत्र के आईपी पते के माध्यम से अनुरोध भेजता है। आप एक देश कोड निर्दिष्ट कर सकते हैं (जैसे, अमेरिका के लिए US, यूनाइटेड किंगडम के लिए GB, किसी भी देश के लिए ANY)। सभी समर्थित विकल्पों के लिए देश कोड देखें।
"proxyCountry": "ANY",
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'स्थिति कोड: {result.status_code}')
print("-" * 20)
print(f'शीर्षक: {result.metadata["title"]}')
print(f'विवरण: {result.metadata["description"]}')
print("-" * 20)
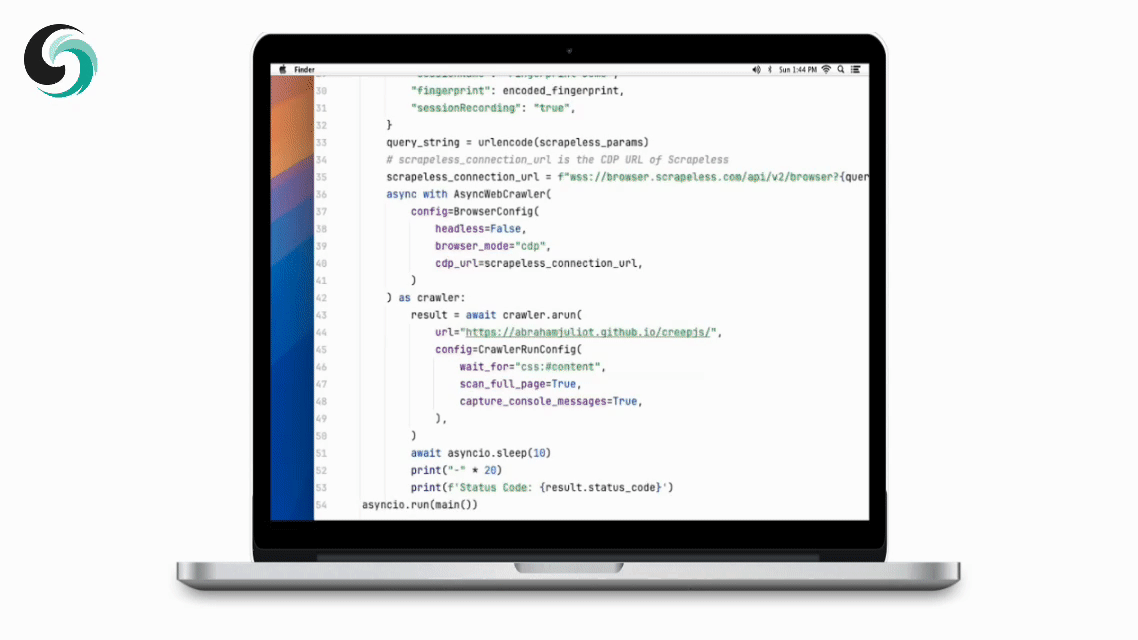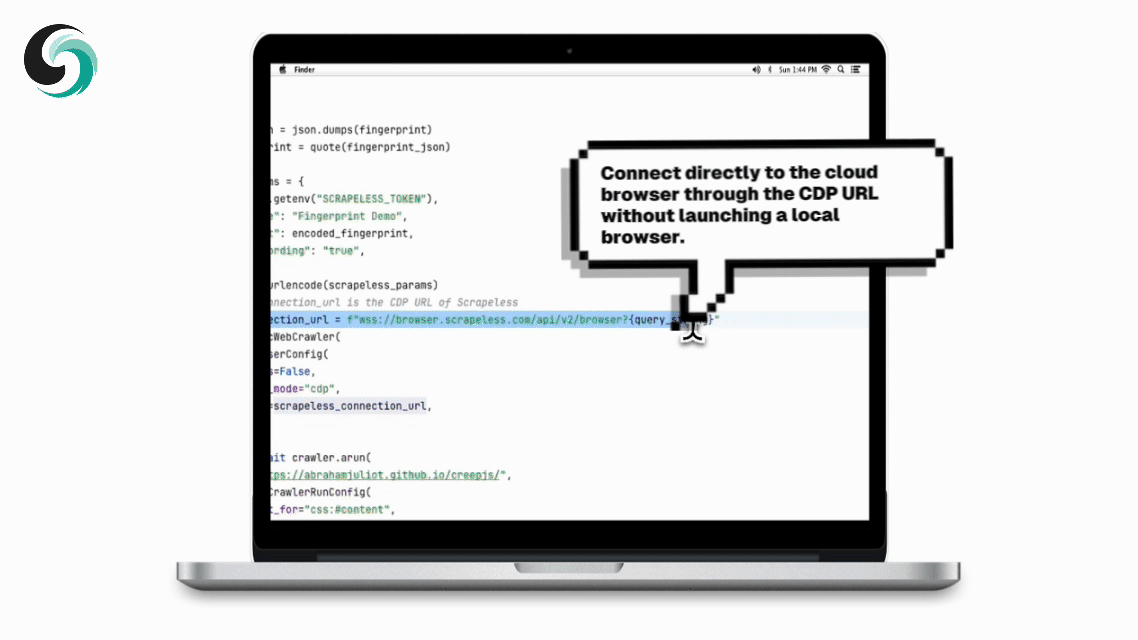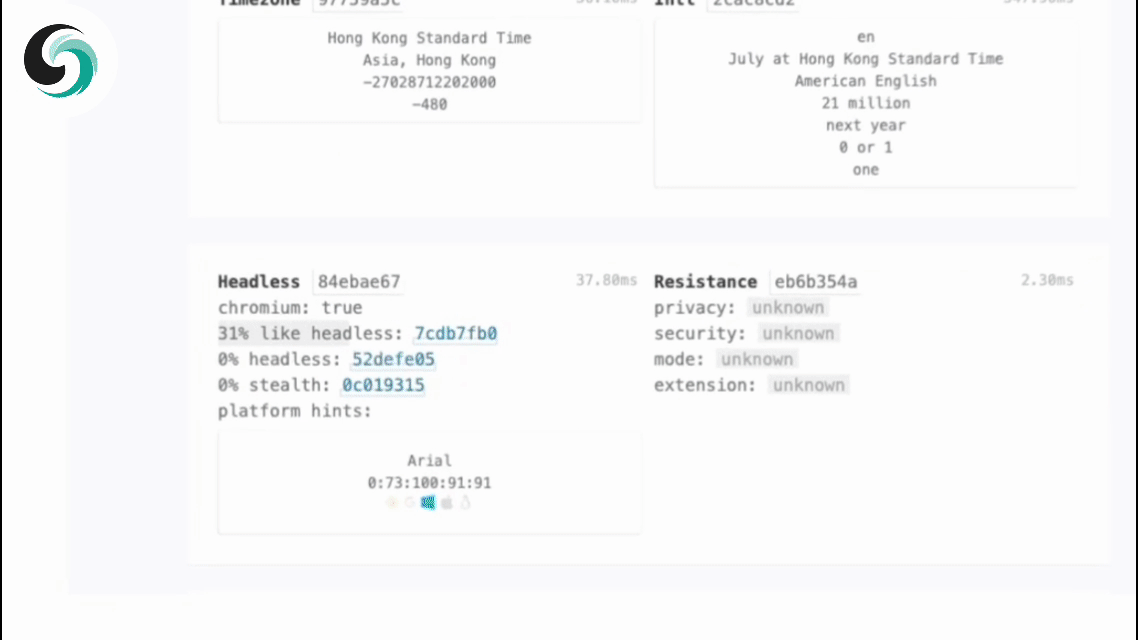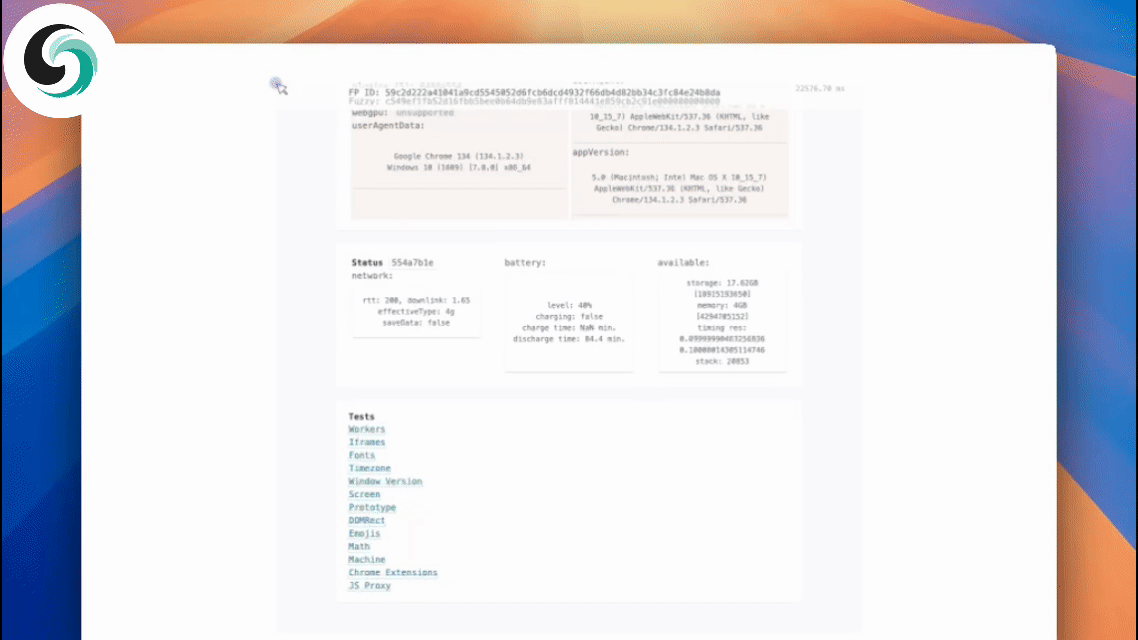
asyncio.run(main())3. कस्टम ब्राउज़र फिंगरप्रिंट्स
वास्तविक उपयोगकर्ता व्यवहार की नकल करने के लिए, Scrapeless यादृच्छिक रूप से उत्पन्न ब्राउज़र फिंगरप्रिंट्स का समर्थन करता है और कस्टम फिंगरप्रिंट पैरामीटर भी अनुमति देता है। यह प्रभावी रूप से लक्षित वेबसाइटों द्वारा पकड़े जाने के जोखिम को कम करता है।
import json
import asyncio
from urllib.parse import quote, urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
# ब्राउज़र फिंगरप्रिंट को अनुकूलित करें
fingerprint = {
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36",
"platform": "Windows",
"screen": {
"width": 1280, "height": 1024
},
"localization": {
"languages": ["zh-HK", "en-US", "en"], "timezone": "Asia/Hong_Kong",
}
}
fingerprint_json = json.dumps(fingerprint)
encoded_fingerprint = quote(fingerprint_json)
scrapeless_params = {
"token": "आपका टोकन",
"sessionTTL": 1000,
"sessionName": "फिंगरप्रिंट डेमो",
"fingerprint": encoded_fingerprint,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'स्थिति कोड: {result.status_code}')
print("-" * 20)
print(f'शीर्षक: {result.metadata["title"]}')
print(f'विवरण: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())4. प्रोफ़ाइल पुनरुपयोग
Scrapeless प्रत्येक प्रोफ़ाइल को अपनी स्वतंत्र ब्राउज़र वातावरण सौंपता है, जिससे लगातार लॉगिन और पहचान अलगाव संभव होता है। उपयोगकर्ता बस profileId प्रदान कर सकते हैं ताकि वे पिछले सत्र का पुनः उपयोग कर सकें।
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "आपका टोकन",
"sessionTTL": 1000,
"sessionName": "प्रोफ़ाइल डेमो",
"profileId": "आपका profileId", # scrapeless पर प्रोफ़ाइल बनाएं
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'स्थिति कोड: {result.status_code}')
print("-" * 20)
print(f'Title: {result.metadata["title"]}')
print(f'विवरण: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())वीडियो
अक्सर पूछे जाने वाले प्रश्न
Q: मैं ब्राउज़र निष्पादन प्रक्रिया को कैसे रिकॉर्ड और देख सकता हूँ?
A: बस sessionRecording पैरामीटर को "true" पर सेट करें। संपूर्ण ब्राउज़र निष्पादन स्वचालित रूप से रिकॉर्ड किया जाएगा। सत्र समाप्त होने के बाद, आप क्लिक, स्क्रॉलिंग, पृष्ठ लोडिंग और अन्य विवरणों के साथ सत्र इतिहास सूची में पूर्ण गतिविधि को पुनः चलाकर और समीक्षा कर सकते हैं। डिफ़ॉल्ट मान "false" है।
scrapeless_params = {
# ...
"sessionRecording": "true",
}Q: मैं यादृच्छिक फिंगरप्रिंट कैसे उपयोग कर सकता हूँ?
A: Scrapeless ब्राउज़र सेवा प्रत्येक सत्र के लिए स्वचालित रूप से एक यादृच्छिक ब्राउज़र फिंगरप्रिंट उत्पन्न करती है। उपयोगकर्ता fingerprint क्षेत्र का उपयोग करके एक कस्टम फिंगरप्रिंट भी सेट कर सकते हैं।
Q: मैं एक कस्टम प्रॉक्सी कैसे सेट कर सकता हूँ?
A: हमारा अंतर्निर्मित प्रॉक्सी नेटवर्क 195 देशों/क्षेत्रों का समर्थन करता है। यदि उपयोगकर्ता अपनी स्वयं की प्रॉक्सी का उपयोग करना चाहते हैं, तो proxyURL पैरामीटर का उपयोग करके प्रॉक्सी URL निर्दिष्ट किया जा सकता है, उदाहरण के लिए: http://user:pass@ip:port।
(नोट: कस्टम प्रॉक्सी कार्यक्षमता वर्तमान में केवल एंटरप्राइज और एंटरप्राइज प्लस ग्राहकों के लिए उपलब्ध है।)
scrapeless_params = {
# ...
"proxyURL": "proxyURL",
}सारांश
Scrapeless क्लाउड ब्राउज़र को Crawl4AI के साथ जोड़ने से डेवलपर्स को एक स्थिर और स्केलेबल वेब स्क्रैपिंग वातावरण मिलता है:
- स्थानीय क्रोम इंस्टेंस को स्थापित या बनाए रखने की आवश्यकता नहीं; सभी कार्य सीधे क्लाउड में चलते हैं।
- प्रतिबंधों और CAPTCHA बाधाओं के जोखिम को कम करता है, क्योंकि प्रत्येक सत्र अलग-थलग होता है और यादृच्छिक या कस्टम फिंगरप्रिंट का समर्थन करता है।
- स्वचालित सत्र रिकॉर्डिंग और पुनरावृत्ति का समर्थन करने के साथ डिबगिंग और पुनरुत्पादन में सुधार करता है।
- 195 देशों/क्षेत्रों के बीच स्वचालित प्रॉक्सी रोटेशन का समर्थन करता है।
- वैश्विक एज नोड सेवा का उपयोग करता है, जो अन्य समान सेवाओं की तुलना में तेज़ प्रारंभ गति प्रदान करता है।
यह सहयोग Scrapeless और Crawl4AI के लिए वेब डेटा स्क्रैपिंग क्षेत्र में एक महत्वपूर्ण मील का पत्थर है। आगे बढ़ते हुए, Scrapeless क्लाउड ब्राउज़र तकनीक पर ध्यान केंद्रित करेगा, उद्यम ग्राहकों को कुशल, स्केलेबल डेटा निकालने, स्वचालन और एआई एजेंट अवसंरचना समर्थन प्रदान करेगा। अपनी शक्तिशाली क्लाउड क्षमताओं का लाभ उठाते हुए, Scrapeless उद्योगों जैसे वित्त, रिटेल, ई-कॉमर्स, SEO, और मार्केटिंग के लिए अनुकूलित और परिदृश्य-आधारित समाधान प्रदान करना जारी रखेगा, जिससे व्यवसायों को डेटा बुद्धिमत्ता के युग में सच्ची स्वचालित वृद्धि प्राप्त हो सके।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


