
वेब स्क्रैपिंग क्या है? किसी वेबसाइट से डेटा कैसे स्क्रैप करें?
Senior Web Scraping Engineer
वेब स्क्रैपिंग वेबसाइटों से डेटा निकालने की एक स्वचालित प्रक्रिया है, असंरचित या अर्ध-संरचित वेब डेटा को CSV या JSON जैसे संरचित स्वरूपों में बदलना।
विभिन्न उद्योगों में निर्णय लेने के लिए डेटा पर बढ़ती निर्भरता के कारण इस तकनीक ने महत्वपूर्ण ध्यान आकर्षित किया है, जिसमें ई-कॉमर्स, वित्त, विपणन और अनुसंधान शामिल हैं।
विश्वसनीय वेब स्क्रैपिंग सेवा का उपयोग करके डेटा निष्कर्षण प्रक्रिया की दक्षता को और बढ़ाया जा सकता है। यह बाजार अनुसंधान करने, बिक्री और विपणन टीमों के लिए लीड जेनरेशन को बढ़ावा देने और प्रतिस्पर्धी खुदरा और यात्रा व्यवसायों के लिए मूल्य निगरानी प्रदान करने के लिए विशेष रूप से महत्वपूर्ण है।
वेब स्क्रैपिंग क्या है और किसी वेबसाइट को सहज रूप से कैसे स्क्रैप करें?
इस लेख में विस्तृत मार्गदर्शिका प्राप्त करें!
वेब स्क्रैपिंग क्या है?
वेब स्क्रैपिंग में वेबसाइटों से जानकारी एकत्रित करने और संसाधित करने के लिए सॉफ़्टवेयर या स्क्रिप्ट का उपयोग शामिल है। मैनुअल डेटा संग्रह के विपरीत, वेब स्क्रैपिंग निष्कर्षण प्रक्रिया को स्वचालित करता है, जिससे यह अधिक कुशल और स्केलेबल हो जाता है। प्राथमिक लक्ष्य विश्लेषण, अनुसंधान या अनुप्रयोगों में एकीकरण के लिए क्रियायोग्य अंतर्दृष्टि या बड़े डेटासेट इकट्ठा करना है।
वेब स्क्रैपिंग मशीन लर्निंग मॉडल के लिए डेटा प्रदान करने में महत्वपूर्ण भूमिका निभाता है, जिससे कृत्रिम बुद्धिमत्ता तकनीक की उन्नति को और आगे बढ़ाया जाता है। डेटा संग्रह प्रक्रिया को स्वचालित करके और विभिन्न स्रोतों से जानकारी एकत्रित करने के लिए डेटा का विस्तार करके, वेब स्क्रैपिंग शक्तिशाली, सटीक और अच्छी तरह से प्रशिक्षित कृत्रिम बुद्धिमत्ता मॉडल बनाने में मदद करता है।
यदि आप जिस सार्वजनिक वेबसाइट से डेटा प्राप्त करना चाहते हैं, उसके पास कोई API नहीं है, या वेब डेटा तक केवल सीमित पहुँच प्रदान करता है, तो वेब स्क्रैपिंग विशेष रूप से उपयोगी है!
इस मामले में, पारंपरिक तरीके आवश्यकताओं को पूरा नहीं कर सकते हैं, और स्क्रैपलेस जैसी बाहरी वेब स्क्रैपिंग सेवाओं का लाभ उठाना एक रणनीतिक दृष्टिकोण हो सकता है। ये सेवाएँ अधिक कुशल और स्केलेबल समाधान प्रदान करती हैं। इसके अलावा, जो लोग उन्नत सुविधाओं की तलाश में हैं, उनके लिए स्क्रैपलेस के API और स्क्रैपिंग ब्राउज़र जैसे उपकरण व्यापक समाधान प्रदान करते हैं, जिसमें ब्लॉकिंग को संभालना, स्वचालित ब्राउज़र संचालन, सत्र और कुकी प्रबंधन और कुशल डेटा निष्कर्षण जैसी सुविधाएँ शामिल हैं।
और अन्य समान उत्पादों की तुलना में, स्क्रैपलेस उच्च स्थिरता सुनिश्चित करते हुए सस्ती कीमतें भी प्रदान करता है। यह उन कंपनियों के लिए लागत बोझ को कम करता है जिनके पास सीमित बजट लेकिन मजबूत आवश्यकताएँ हैं।
वेब स्क्रैपिंग कैसे काम करता है?
वेब स्क्रैपिंग असंरचित और संरचित डेटा के संग्रह को स्वचालित करने की प्रक्रिया है। इसे वेब डेटा निष्कर्षण या वेब डेटा स्क्रैपिंग के रूप में भी जाना जाता है।
वेब स्क्रैपिंग के कुछ प्रमुख उपयोग के मामलों में मूल्य निगरानी, मूल्य खुफिया, समाचार निगरानी, लीड जेनरेशन और बाजार अनुसंधान शामिल हैं, अन्य।
आम तौर पर, इसका उपयोग उन व्यक्तियों और व्यवसायों द्वारा किया जाता है जो सार्वजनिक रूप से उपलब्ध वेब डेटा का लाभ उठाकर मूल्यवान अंतर्दृष्टि उत्पन्न करना और बेहतर निर्णय लेना चाहते हैं।
मैन्युअल रूप से वेब स्क्रैपिंग
यदि आपने कभी किसी वेबसाइट से जानकारी कॉपी और पेस्ट की है, तो आपने किसी भी वेब स्क्रैपिंग टूल के समान कार्य किया है, सिवाय इसके कि आपने डेटा स्क्रैपिंग प्रक्रिया को मैन्युअल रूप से किया है:
- लक्षित वेबसाइट की पहचान करें
- लक्षित पृष्ठों के URL एकत्र करें
- पृष्ठ का HTML प्राप्त करने के लिए उन URL पर अनुरोध करें
- HTML में जानकारी खोजने के लिए लोकेटर का उपयोग करें
- डेटा को JSON या CSV फ़ाइल या अन्य संरचित प्रारूप के रूप में सहेजें
यह दैनिक वेब स्क्रैपिंग के लिए पर्याप्त लगता है। दुर्भाग्य से, यदि आपको बड़े पैमाने पर डेटा निकालने की आवश्यकता है, तो आपको काफी चुनौतियों का सामना करना पड़ता है।
उदाहरण के लिए, यदि वेबसाइट लेआउट बदलता है, तो डेटा निष्कर्षण उपकरण और वेब क्रॉलर बनाए रखें, प्रॉक्सी प्रबंधित करें, जावास्क्रिप्ट निष्पादित करें, या एंटी-बॉट को बायपास करें। ये तकनीकी समस्याएँ हैं जो आंतरिक संसाधनों का उपभोग करती हैं।
इस समय, हमें अधिक शक्तिशाली स्वचालन उपकरणों का उपयोग करने की आवश्यकता है - वेब स्क्रैपर
वेब स्क्रैपर
अपने आप डेटा निकालने की थकाऊ प्रक्रिया के विपरीत, वेब स्क्रैपिंग इंटरनेट से लाखों या अरबों निकाले गए डेटा बिंदुओं को पुनः प्राप्त करने के लिए मशीन लर्निंग और बुद्धिमान स्वचालन का उपयोग करता है।
- वेब स्क्रैपिंग किसी वेबसाइट पर HTTP अनुरोध भेजकर और उसकी HTML सामग्री प्राप्त करके काम करता है।
- स्क्रिप्ट तब टैग, विशेषताएँ या पैटर्न का उपयोग करके विशिष्ट डेटा बिंदुओं का पता लगाने और निकालने के लिए HTML संरचना को पार्स करता है।
- उन्नत तरीके पुपेटियर या सेलेनियम जैसे उपकरणों का उपयोग करके ब्राउज़र व्यवहार का अनुकरण करके जावास्क्रिप्ट के माध्यम से प्रदान की गई गतिशील सामग्री को संभाल सकते हैं।
चाहे आप स्वयं वेब स्क्रैपर लिखें या किसी शक्तिशाली वेब डेटा निष्कर्षण उपकरण का उपयोग करें, आपको वेब स्क्रैपिंग या वेब डेटा निष्कर्षण की मूल बातों के बारे में अधिक जानने की आवश्यकता है!
वेब स्क्रैपिंग और वेब क्रॉलिंग में अंतर
| विशेषताएँ | वेब स्क्रैपिंग | वेब क्रॉलिंग |
|---|---|---|
| लक्ष्य | विशिष्ट डेटा निकालें | वेब लिंक क्रॉल करें और सामग्री सूचकांक बनाएँ |
| क्षेत्र | कम संख्या में वेब पृष्ठों और विशिष्ट सामग्री पर ध्यान केंद्रित करें | बड़ी संख्या में वेब पृष्ठों को क्रॉल करें |
| तकनीकी जटिलता | मध्यम, मुख्य रूप से डेटा विश्लेषण के लिए उपयोग किया जाता है | उच्च, लिंक ट्रैकिंग और डुप्लिकेशन का प्रबंधन करने की आवश्यकता है |
| सामान्य उपकरण | BeautifulSoup, Puppeteer, Scrapy | Scrapy, Apache Nutch, Selenium |
| मुख्य अनुप्रयोग | डेटा विश्लेषण, ई-कॉमर्स मूल्य निगरानी | सर्च इंजन इंडेक्सिंग, एसईओ विश्लेषण |
वेब स्क्रैपिंग
वेब स्क्रैपिंग एक केंद्रित प्रक्रिया है जिसका उपयोग किसी वेब पेज से विशिष्ट डेटा निकालने और उसे CSV या JSON जैसे संरचित प्रारूप में बदलने के लिए किया जाता है। लक्ष्य सटीक जानकारी प्राप्त करना है, जैसे कि कीमतें, समीक्षाएँ या उत्पाद विवरण, विश्लेषण या आगे के उपयोग के लिए। स्क्रैपर वांछित डेटा को कुशलतापूर्वक खोजने और निकालने के लिए XPath, CSS चयनकर्ता या रेगेक्स जैसे उपकरणों का उपयोग करते हैं।
वेब क्रॉलिंग
वेब क्रॉलिंग, जिसे अक्सर "स्पाइडरिंग" कहा जाता है, लिंक का पालन करके वेब पेजों को अनुक्रमित करने और एकत्रित करने के लिए इंटरनेट ब्राउज़ करने की एक स्वचालित प्रक्रिया है। क्रॉलर आमतौर पर सर्च इंजन जैसे बड़े डेटासेट या इंडेक्स बनाने के लिए उपयोग किए जाते हैं। कुछ परियोजनाओं में, वेब क्रॉलिंग URL एकत्र करने का एक प्रारंभिक चरण है, जिसे बाद में विशिष्ट डेटा निकालने के लिए वेब स्क्रैपर द्वारा संसाधित किया जाता है।
किसी साइट को स्क्रैप करने के 2 लोकप्रिय वेब स्क्रैपिंग तरीके
आपको यह समझने में स्पष्टता प्रदान करने के लिए कि किसी वेबसाइट को कैसे स्क्रैप किया जाए, अब हम Google ट्रेंड को स्क्रैप करने के लिए 2 लोकप्रिय और शक्तिशाली क्रॉलिंग टूल का उपयोग करेंगे: स्क्रैपिंग API और स्क्रैपिंग ब्राउज़र।
स्क्रैपिंग API
उन्नत स्क्रैपिंग API के साथ, आप जटिल स्क्रैपिंग स्क्रिप्ट लिखे या बनाए रखे बिना आसानी से Google ट्रेंड डेटा तक पहुँच सकते हैं और उसे स्क्रैप कर सकते हैं। अपनी ज़रूरत की सारी जानकारी जल्दी से प्राप्त करने के लिए हमारे द्वारा प्रदान किए गए API को कॉल करें।
आप आसानी से Google ट्रेंड डेटा श्रेणियों को स्क्रैप कर सकते हैं जैसे:
- समय के साथ रुचि
- क्षेत्र के अनुसार तुलनात्मक विवरण
- उपक्षेत्र द्वारा रुचि
- संबंधित क्वेरी
- संबंधित विषय
आइए विस्तृत चरण देखें:
- चरण 1. स्क्रैपलेस में लॉग इन करें
- चरण 2. "स्क्रैपिंग API" पर क्लिक करें
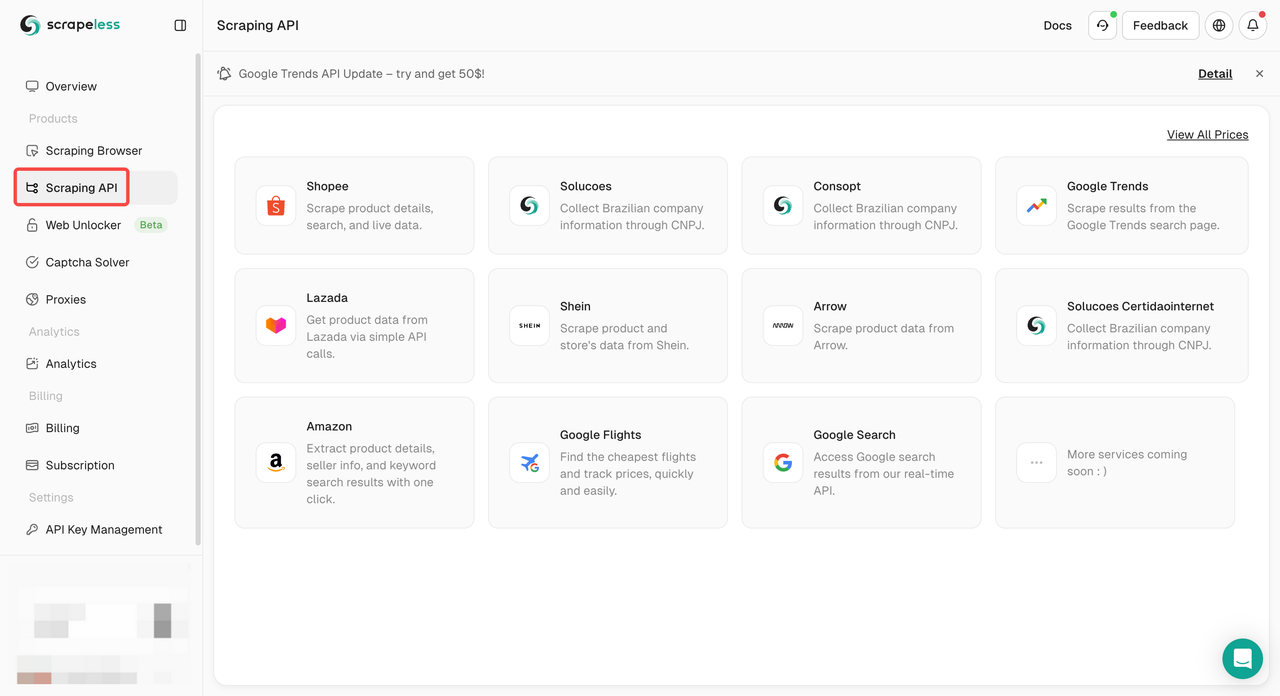
- चरण 3. हमारे "Google ट्रेंड" पैनल का पता लगाएँ और उसमें प्रवेश करें:
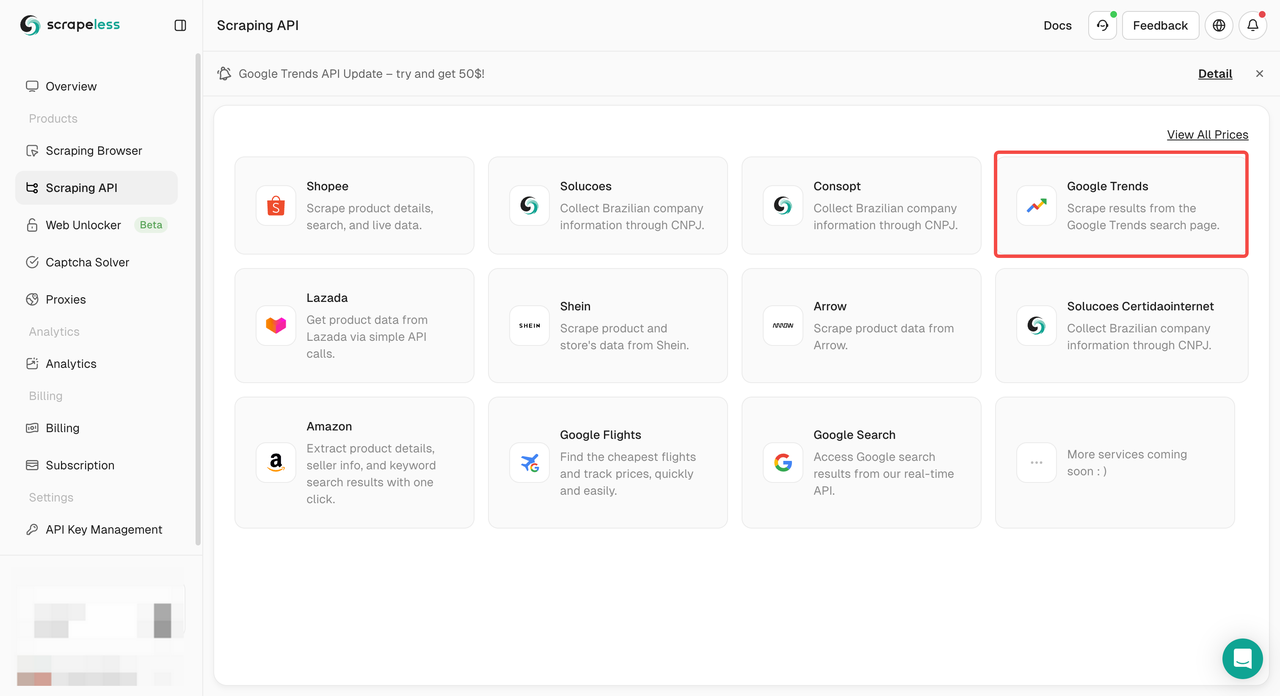
- चरण 4. बाएँ ऑपरेशन पैनल में अपना डेटा कॉन्फ़िगर करें:
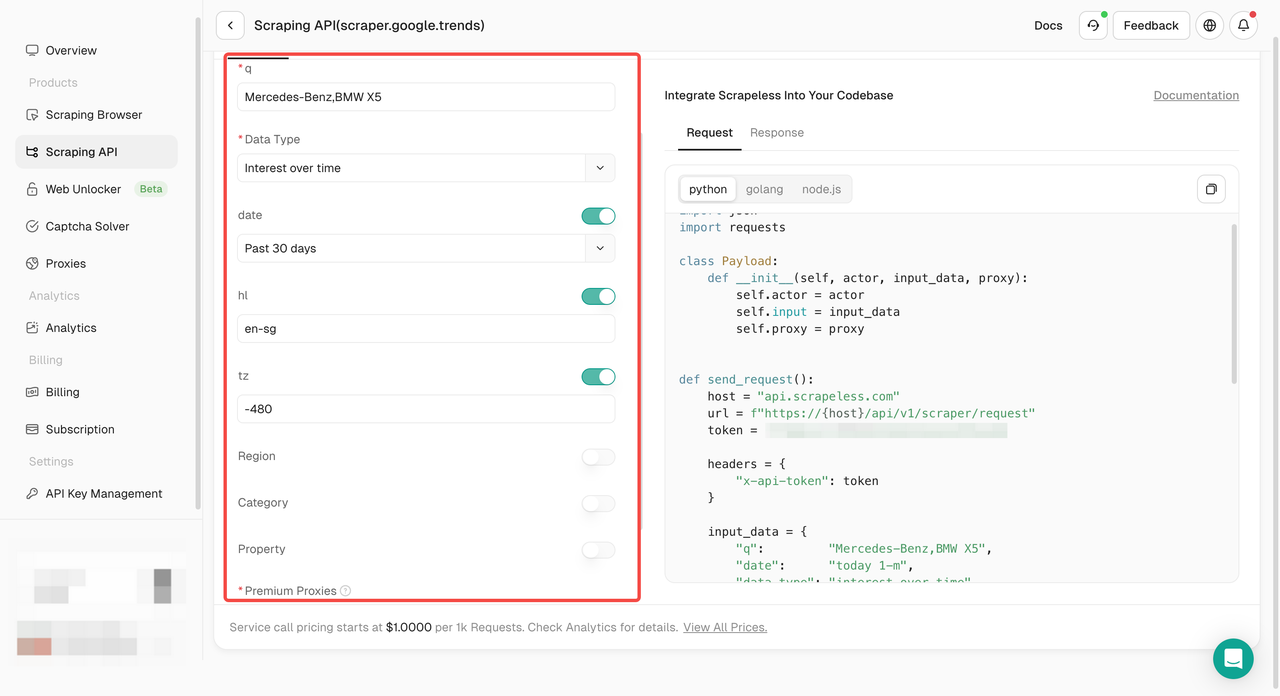
- चरण 5. "स्क्रैपिंग प्रारंभ करें" बटन पर क्लिक करें और फिर आप परिणाम प्राप्त कर सकते हैं:
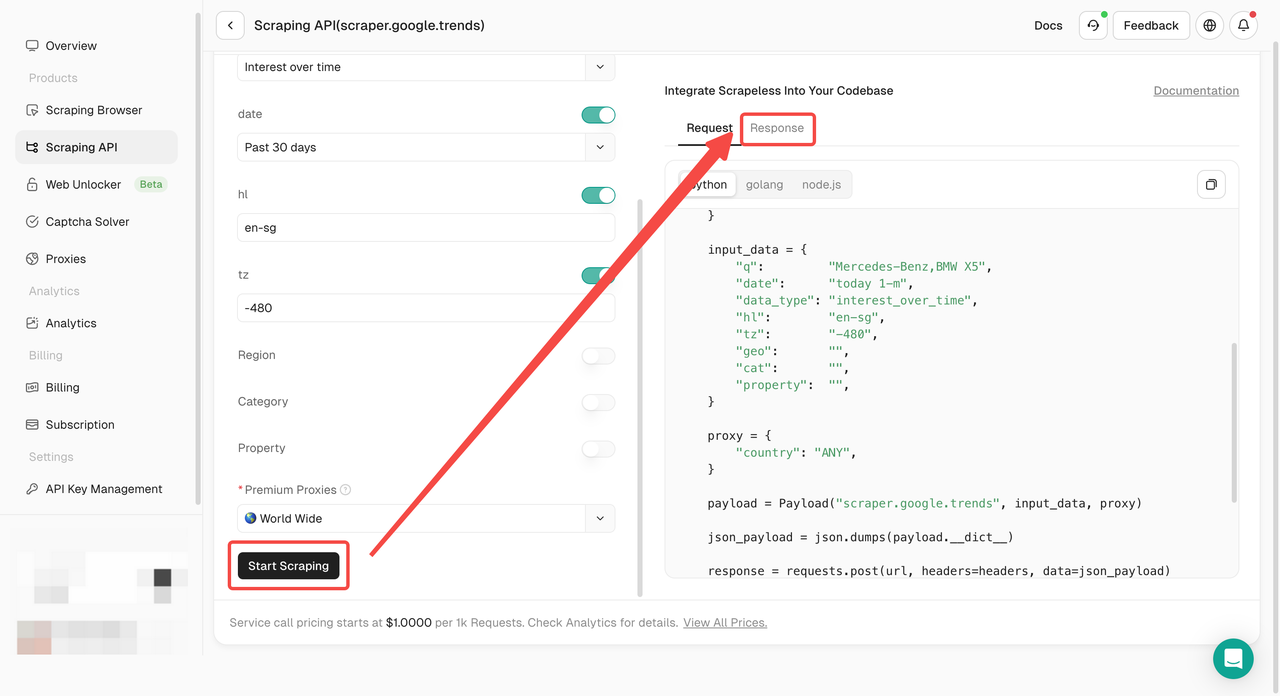
या आप अपनी खुद की परियोजना में हमारे API को तैनात कर सकते हैं जैसे:
- पाइथन
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.trends",
"input": {
"keywords": "Mercedes-Benz,BMW X5",
"geo": "",
"time": "today 1-m",
"category": "0",
"property": ""
},
"proxy": {
"country": "US"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- गोलैंग
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.trends",
"input": {
"data_type": "autocomplete",
"q": "Mercedes-Benz"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}स्क्रैपिंग ब्राउज़र
आवश्यकताएँ:
- Node.js: सुनिश्चित करें कि संस्करण 14 या उससे ऊपर स्थापित है।
- npm: निर्भरताओं को संभालने के लिए नोड पैकेज प्रबंधक।
- स्क्रैपलेस ब्राउज़रलेस सेवा: स्क्रैपलेस द्वारा प्रदान की गई ब्राउज़र सेवा का उपयोग करें।
फिर, कृपया स्क्रैपिंग ब्राउज़र डैशबोर्ड तक पहुँचें, "सेटिंग्स" टैब पर जाएँ, और अपनी API कुंजी पुनः प्राप्त करें।
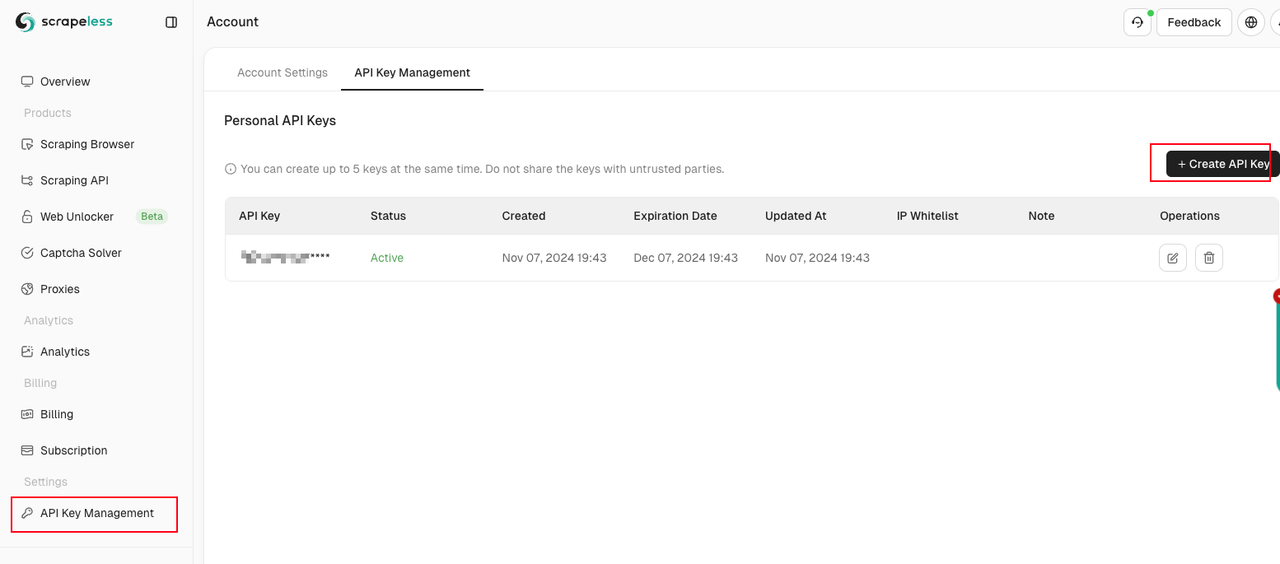
फिर, कृपया हमारे चरणों का पालन करें:
- उपयोग करके आवश्यक निर्भरताएँ स्थापित करें:
Bash
npm install- पर्यावरण चर सेट करें
प्रोजेक्ट रूट निर्देशिका में एक .env फ़ाइल बनाएँ और अपनी API कुंजी इस प्रकार जोड़ें:
Bash
API_KEY=your_scrapeless_api_key- स्क्रिप्ट पैरामीटर अनुकूलित करें
स्क्रिप्ट पिछले 7 दिनों में संयुक्त राज्य अमेरिका में "youtube" और "twitter" के लिए रुझान प्राप्त करने के लिए पूर्व-कॉन्फ़िगर किया गया है। आप निम्न सेटिंग्स को समायोजित कर सकते हैं:
- कीवर्ड: खोज शब्दों को बदलने के लिए
QUERY_PARAMSचर में q पैरामीटर को संशोधित करें। - भौगोलिक स्थान: वांछित स्थान सेट करने के लिए
geoपैरामीटर को अपडेट करें। - दिनांक सीमा: उस समय अवधि के आधार पर
dateपैरामीटर को समायोजित करें जिसका आप विश्लेषण करना चाहते हैं।
- कुकीज़ सेट करें
समय के साथ बदलते हितों से संबंधित डेटा को स्थिर करने के लिए, वेबसाइट पर जाने से पहले Puppeteer का उपयोग करके कुकीज़ कॉन्फ़िगर करें:
JavaScript
const cookies = JSON.parse(fs.readFileSync('./data/cookies.json', 'utf-8'));
await browser.setCookie(...cookies);cookies.json फ़ाइल उत्पन्न करने के लिए, अपने ब्राउज़र के माध्यम से Google ट्रेंड में लॉग इन करें और कुकीज़ को JSON प्रारूप में निर्यात करें। यदि आप यह नहीं जानते कि यह कैसे करना है, तो कुकी निर्यात के लिए डिज़ाइन किए गए ब्राउज़र एक्सटेंशन का उपयोग करने पर विचार करें।
- Node.js का उपयोग करके स्क्रिप्ट निष्पादित करें:
Bash
node index.jsवेब स्क्रैपिंग का उपयोग किस लिए किया जा सकता है?
मूल्य खुफिया
हाँ, मूल्य खुफिया वेब स्क्रैपिंग के लिए सबसे बड़ा उपयोग मामला है।
ई-कॉमर्स वेबसाइटों से उत्पाद और मूल्य निर्धारण की जानकारी निकालना और फिर उसे खुफिया जानकारी में बदलना आधुनिक ई-कॉमर्स कंपनियों का एक महत्वपूर्ण घटक है जो डेटा के आधार पर बेहतर मूल्य निर्धारण/विपणन निर्णय लेना चाहती हैं।
वेब मूल्य डेटा और मूल्य खुफिया के लाभ:
- गतिशील मूल्य निर्धारण
- राजस्व अनुकूलन
- प्रतियोगी निगरानी
- उत्पाद प्रवृत्ति निगरानी
- ब्रांड और MAP अनुपालन
बाजार अनुसंधान
बाजार अनुसंधान महत्वपूर्ण है और इसे सबसे सटीक जानकारी द्वारा संचालित किया जाना चाहिए। डेटा स्क्रैपिंग के साथ, आपको उच्च-गुणवत्ता, उच्च-मात्रा, उच्च-अंतर्दृष्टि वाले वेब स्क्रैप किए गए डेटा तक पहुँच प्राप्त होती है जो सभी आकारों और आकारों में है जो दुनिया भर में बाजार विश्लेषण और व्यावसायिक खुफिया जानकारी को चला रहा है।
- बाजार प्रवृत्ति विश्लेषण
- बाजार मूल्य निर्धारण
- प्रवेश बिंदुओं का अनुकूलन
- अनुसंधान और विकास
- प्रतियोगी निगरानी
वित्तीय वैकल्पिक डेटा
निवेशकों के लिए तैयार वेब डेटा के साथ शुरुआत से ही अल्फा का पता लगाएँ और मूल्य बनाएँ।
निर्णय लेना पहले कभी इतना स्मार्ट नहीं रहा और डेटा पहले कभी इतना व्यावहारिक नहीं रहा - वेब स्क्रैप किए गए डेटा का उपयोग दुनिया की अग्रणी कंपनियों द्वारा इसके अविश्वसनीय रणनीतिक मूल्य को देखते हुए तेजी से किया जा रहा है।
- SEC फाइलिंग से अंतर्दृष्टि निकालें
- कंपनी के मूल सिद्धांतों का आकलन करें
- सार्वजनिक भावना एकीकरण
- समाचार निगरानी
रियल एस्टेट
पिछले दो दशकों में रियल एस्टेट के डिजिटल परिवर्तन में पारंपरिक व्यवसायों को बाधित करने और उद्योग में शक्तिशाली नए खिलाड़ियों को जन्म देने की क्षमता है।
वेब से स्क्रैप किए गए रियल एस्टेट डेटा को दैनिक संचालन में शामिल करके, एजेंट और ब्रोकरेज शीर्ष-डाउन ऑनलाइन प्रतिस्पर्धा को रोक सकते हैं और बाजार में स्मार्ट निर्णय ले सकते हैं।
- संपत्ति के मूल्यों का आकलन करें
- रिक्ति दरों की निगरानी करें
- अनुमानित किराये की उपज
- बाजार की दिशा को समझें
समाचार और सामग्री निगरानी
आधुनिक मीडिया एक ही समाचार चक्र में आपके व्यवसाय के लिए उत्कृष्ट मूल्य या अस्तित्वगत खतरा पैदा कर सकता है।
यदि आपकी कंपनी समय पर समाचार विश्लेषण पर निर्भर करती है, या एक ऐसी कंपनी है जो अक्सर समाचारों में रहती है, तो वेब स्क्रैपिंग समाचार डेटा आपके उद्योग में सबसे महत्वपूर्ण समाचारों की निगरानी, संग्रह और पार्स करने का अंतिम समाधान है।
- निवेश निर्णय
- ऑनलाइन जनमत विश्लेषण
- प्रतियोगी निगरानी
- राजनीतिक अभियान
- भावना विश्लेषण
लीड जेनरेशन
लीड जेनरेशन सभी व्यवसायों के लिए एक महत्वपूर्ण मार्केटिंग/सेल्स गतिविधि है।
2024 की हबस्पॉट रिपोर्ट में, 65% इनबाउंड मार्केटर्स ने कहा कि ट्रैफ़िक और लीड उत्पन्न करना उनकी सबसे बड़ी चुनौती है। सौभाग्य से, वेब डेटा निष्कर्षण का उपयोग वेब से लीड की संरचित सूचियाँ प्राप्त करने के लिए किया जा सकता है।
ब्रांड निगरानी
आज के प्रतिस्पर्धी बाजार में, अपनी ऑनलाइन प्रतिष्ठा की रक्षा करना एक शीर्ष प्राथमिकता है।
चाहे आप ऑनलाइन उत्पाद बेचते हों और एक सख्त मूल्य निर्धारण नीति लागू करने की आवश्यकता हो, या आप केवल यह जानना चाहते हैं कि लोग ऑनलाइन आपके उत्पादों को कैसे देखते हैं, वेब स्क्रैपिंग का उपयोग करके ब्रांड निगरानी आपको वह जानकारी प्रदान कर सकती है।
व्यावसायिक स्वचालन
कुछ मामलों में, डेटा तक पहुँचना बोझिल हो सकता है। हो सकता है कि आपको अपनी या अपने भागीदारों की वेबसाइटों से डेटा को एक संरचित तरीके से निकालने की आवश्यकता हो।
लेकिन ऐसा करने का कोई आसान तरीका इन-हाउस नहीं है, इसलिए स्क्रैपिंग टूल बनाना और डेटा को सीधे स्क्रैप करना एक स्मार्ट कदम है। जटिल आंतरिक प्रणालियों के साथ इसका पता लगाने की कोशिश करने के बजाय।
MAP निगरानी
न्यूनतम विज्ञापित मूल्य (MAP) निगरानी यह सुनिश्चित करने के लिए एक मानक प्रथा है कि किसी ब्रांड की ऑनलाइन कीमतें उसकी मूल्य निर्धारण नीति के अनुरूप हैं।
बड़ी संख्या में डीलरों और वितरकों के कारण कीमतों की मैन्युअल निगरानी असंभव है।
यही कारण है कि वेब स्क्रैपिंग इतना सुविधाजनक है क्योंकि आप आसानी से अपने उत्पादों की कीमतों पर नज़र रख सकते हैं।
मुफ्त में वेबसाइट को कैसे स्क्रैप करें?
वेब से सामग्री को स्वचालित रूप से स्क्रैप करने और डेटा निकालने के लिए कई तरह के मुफ़्त वेब स्क्रैपिंग समाधान उपलब्ध हैं। ये समाधान गैर-पेशेवरों के लिए सरल पॉइंट-एंड-क्लिक स्क्रैपिंग समाधानों से लेकर व्यापक कॉन्फ़िगरेशन और प्रबंधन विकल्पों वाले अधिक शक्तिशाली, डेवलपर-केंद्रित अनुप्रयोगों तक हैं।
स्क्रैपिंग API और स्क्रैपिंग ब्राउज़र सबसे शक्तिशाली उपकरण बन जाएंगे जो इंटरनेट समाज के विकास के अनुरूप हैं। उनके पास अंतर्निहित वेब अनलॉकर, प्रॉक्सी और CAPTCHA आदि हैं, जो आपके वेब स्क्रैपिंग को अधिक सुविधाजनक और तेज बनाते हैं।
सबसे सटीक डेटा तुरंत प्राप्त करने के लिए केवल सरल कॉन्फ़िगरेशन संचालन की आवश्यकता होती है।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


