
स्टेबल प्रॉक्सी के साथ एंटी-बॉट डिटेक्शन को कैसे बायपास करें?
Expert Network Defense Engineer
कई वेबसाइटों ने एंटी बॉट सुरक्षा उपायों को लागू करना शुरू कर दिया है क्योंकि वेब स्क्रैपिंग अधिक सामान्य हो गया है। इनमें जटिल तकनीकें शामिल हैं जो स्वचालित सॉफ़्टवेयर को उनकी जानकारी प्राप्त करने से रोकती हैं। एक वेबसाइट उन अनुरोधों की मात्रा को सीमित कर सकती है जो आपकी वेब स्क्रैपर को बनाने की अनुमति है या यदि इसे पता चलता है तो इसे पूरी तरह से रोक सकती है।
आप एंटी-बॉट द्वारा आपको पहचानने के सबसे लोकप्रिय तरीकों को ढूंढ सकते हैं और इसे बायपास करने के तरीके को सीख सकते हैं।
अब स्क्रॉल करना शुरू करें!
एंटी बॉट सत्यापन क्या है?
एंटी-बॉट सत्यापन तकनीक उन प्रणालियों और तकनीकों को संदर्भित करती है जो स्वचालित गतिविधियों की पहचान और अवरुद्ध करती हैं जो बॉट द्वारा की जाती हैं। एक बॉट ऐसा सॉफ़्टवेयर है जो स्वायत्त रूप से ऑनलाइन कार्यों को करने के लिए बनाया गया है। हालांकि "बॉट" नाम नकारात्मकता का संकेत देता है, लेकिन उनमें से सभी ऐसे नहीं होते। उदाहरण के लिए, गूगल क्रॉलर्स भी बॉट हैं!
इस बीच, दुर्भावनापूर्ण बॉट्स का वैश्विक ऑनलाइन ट्रैफ़िक में कम से कम 27.7% हिस्सा है। वे साइबर अपराध जैसे DDoS हमले, स्पैमिंग, और पहचान की चोरी करते हैं। उपयोगकर्ता की गोपनीयता को सुरक्षित रखने और उपयोगकर्ता अनुभव को बढ़ाने के प्रयास में, वेबसाइटें उनसे बचने का प्रयास कर रही हैं, और वे आपके वेब स्क्रैपर को भी प्रतिबंधित कर सकती हैं।
एंटी-बॉट फ़िल्टर वास्तविक उपयोगकर्ताओं और स्वचालित कार्यक्रमों के बीच अंतर करने के लिए HTTP हेडर मान्यता, फ़िंगरप्रिंटिंग और CAPTCHA जैसी विभिन्न तकनीकों का उपयोग करते हैं।
वेबसाइटें एंटी-बॉट उपाय क्यों लागू करती हैं?
वेबसाइट मालिकों के लिए, एंटी-बॉट तकनीक उन्हें अधिकांश बाधाओं और चुनौतियों से छुटकारा पाने में मदद कर सकती है:
- डेटा सुरक्षा: एंटी-बॉट उपाय संवेदनशील या स्वामित्व वाली जानकारी की अनुमति के बिना स्क्रैपिंग को रोकते हैं।
- सेवा की विश्वसनीयता: बॉट अधिक सर्वर संसाधनों का उपभोग कर सकते हैं और उपयोगकर्ता अनुभव को कम कर सकते हैं, और एंटी-बॉट सिस्टम ऐसे जोखिमों को कम कर सकते हैं।
- धोखाधड़ी रोकथाम: एंटी-बॉट जांच प्रणालियाँ नकली खाता निर्माण, टिकट स्केलिंग, और विज्ञापन धोखाधड़ी जैसी गतिविधियों का मुकाबला करती हैं।
- उपयोगकर्ता गोपनीयता: unauthorized बॉट्स को अवरुद्ध करके, ये प्रणालियाँ उपयोगकर्ता डेटा को शोषण से बचाने में मदद करती हैं।
एंटी-बॉट तकनीक कैसे काम करती है?
एंटी-बॉट सिस्टम स्वचालित गतिविधियों का पता लगाने और बाधित करने के लिए कई तकनीकों का संयोजन करते हैं:
हेडर मान्यता
हेडर मान्यता एक सामान्य एंटी-बॉट सुरक्षा तकनीक है। यह आने वाले HTTP अनुरोधों के हेडर का विश्लेषण करता है ताकि असामान्यताओं और संदिग्ध पैटर्न की तलाश की जा सके। यदि सिस्टम को कोई असामान्यताएँ मिलती हैं, तो यह अनुरोधों को बॉट से आने जैसे चिह्नित करता है और उन्हें अवरुद्ध करता है।
सभी ब्राउज़र अनुरोध बहुत सारे डेटा के साथ हेडर में भेजे जाते हैं। यदि इनमें से कुछ फ़ील्ड गायब हैं, सही मान नहीं रखते या गलत क्रम में हैं, तो एंटी बॉट चेक सिस्टम अनुरोध को अवरुद्ध कर देगा।
व्यवहारात्मक विश्लेषण
एंटी-बॉट सत्यापन तंत्र उपयोगकर्ता इंटरैक्शन का विश्लेषण करते हैं, जैसे माउस mouvements, कीस्ट्रोक्स, और ब्राउज़िंग पैटर्न। अस्वाभाविक या अत्यधिक दोहराए जाने वाले व्यवहार बॉट गतिविधि का संकेत दे सकते हैं।
आईपी पता निगरानी
कई वेबसाइटें स्थान-आधारित ब्लॉकिंग का उपयोग करती हैं, जिसमें कुछ भौगोलिक क्षेत्रों से अनुरोधों को अवरुद्ध करना शामिल है, ताकि उनकी सामग्री तक पहुँच केवल चयनित देशों तक सीमित हो। सरकारें इसी तरह की रणनीति का उपयोग करती हैं ताकि अपने देश में कुछ वेबसाइटों को निषिद्ध किया जा सके।
भौगोलिक प्रतिबंध DNS या ISP स्तर पर लागू किया जाता है।
उपयोगकर्ता के स्थान का निर्धारण करने और यह तय करने के लिए कि क्या उन्हें अवरुद्ध करना है, ये सिस्टम उपयोगकर्ता के आईपी पते की जांच करते हैं। इसलिए, स्थान-प्रतिबंधित लक्ष्यों को स्क्रैप करने के लिए, आपको अनुमत राष्ट्रों में से एक का आईपी पता चाहिए।
स्थान-आधारित ब्लॉकिंग नीतियों से निपटने के लिए, आपको एक प्रॉक्सी सर्वर की आवश्यकता है, और प्रीमियम प्रॉक्सी आमतौर पर आपको यह चयन करने देती हैं कि सर्वर किस देश में स्थित है। इस तरह, वेब स्क्रैपर के प्रश्न सही स्थान से आएंगे।
क्या आप लगातार वेब स्क्रैपिंग ब्लॉकों से थक गए हैं?
Scrapeless Rotate Proxy IP प्रतिबंधों से बचने में मदद करता है।
अब मुफ्त ट्रायल प्राप्त करें!
ब्राउज़र फ़िंगरप्रिंटिंग
ब्राउज़र फ़िंगरप्रिंटिंग उपयोगकर्ता उपकरण डेटा एकत्रित करके वेब क्लाइंट की पहचान करने की प्रक्रिया है। यह कई कारकों को देखने के द्वारा पहचान सकता है कि अनुरोध एक वैध उपयोगकर्ता से आता है या एक स्क्रैपर से, जैसे स्थापित फ़ॉन्ट, ब्राउज़र प्लगइन्स, स्क्रीन रिज़ॉल्यूशन, और अन्य।
ब्राउज़र फ़िंगरप्रिंटिंग कार्यान्वयन रणनीतियों का अधिकांश भाग उपयोगकर्ता डेटा एकत्रित करने के लिए क्लाइंट-साइड तकनीक का उपयोग करता है।
ऊपर दिया गया स्क्रिप्ट उपयोगकर्ता डेटा एकत्र करता है ताकि इसे फ़िंगरप्रिंट किया जा सके।
यह एंटी-बॉट सॉफ़्टवेयर प्रायः यह मानता है कि अनुरोध ब्राउज़रों से आते हैं। इसे बायपास करने के लिए आपको एक हेडलेस ब्राउज़र की आवश्यकता है; वरना, आपको बॉट के रूप में पहचाना जाएगा।
CAPTCHA चुनौतियाँ
वेबसाइटें यह निर्धारित करने के लिए चुनौती-प्रतिक्रिया परीक्षण, या CAPTCHAs का उपयोग करती हैं कि क्या उपयोगकर्ता मानव है। एंटी-बॉट समाधान इन तकनीकों का उपयोग करते हैं ताकि स्क्रैपर को एक वेबसाइट तक पहुँच से रोका जा सके या कुछ कार्य करने से रोका जा सके, क्योंकि मनुष्यों के लिए इस समस्या को हल करना आसान है, लेकिन बॉट के लिए यह कठिन है।
एक उपयोगकर्ता को CAPTCHA का उत्तर देने के लिए एक पृष्ठ पर एक निश्चित गतिविधि पूरी करनी होती है, जैसे विकृत चित्र में दिखाई देने वाली संख्या को दर्ज करना या छवियों के समूह का चयन करना।
TLS फ़िंगरप्रिंटिंग
TLS हैंडशेक के दौरान स्थानांतरित किए गए मापदंडों की जांच करना TLS फ़िंगरप्रिंटिंग के रूप में जाना जाता है। एंटी-बॉट सत्यापन प्रणाली अनुरोध को एक बॉट के रूप में पहचानती है और यदि ये उस अनुरोध से मेल नहीं खाते जो वहाँ होना चाहिए, तो उसे रोक देती है।
अनुरोध प्रमाणीकरण
एंटी-बॉट सत्यापन प्रणाली HTTP अनुरोधों की प्रामाणिकता को सत्यापित करती है। संदिग्ध हेडर, अमान्य यूजर-एजन्ट स्ट्रिंग या गायब कुकीज़ बॉट ट्रैफ़िक को इंगित कर सकती हैं।
एंटी-बॉट्स पहचान से बचने के 5 तरीके
एंटी बॉट चेक सिस्टम को बायपास करना सरल नहीं हो सकता, लेकिन कुछ तरीके हैं जिनका आप प्रयास कर सकते हैं। विचार करने के लिए रणनीतियों की सूची निम्नलिखित है:
1. स्क्रैपलेस घुमाती प्रॉक्सीज़
स्क्रैपलेस प्रीमियम वैश्विक क्लीन आईपी प्रॉक्सी सेवाएँ प्रदान करता है, जो डायनेमिक आवासीय IPv4 प्रॉक्सीज़ में विशेषज्ञता रखता है।
195 देशों में 70 मिलियन से अधिक आईपी के साथ, स्क्रैपलेस आवासीय प्रॉक्सी नेटवर्क आपके व्यापार की वृद्धि को चलाने के लिए व्यापक वैश्विक प्रॉक्सी समर्थन प्रदान करता है।
हम वेब स्क्रैपिंग, बाजार अनुसंधान, एसईओ निगरानी, मूल्य तुलना, सोशल मीडिया मार्केटिंग, विज्ञापन सत्यापन, और ब्रांड सुरक्षा सहित उपयोग के मामलों की एक विस्तृत श्रृंखला का समर्थन करते हैं, जिससे आप वैश्विक बाजारों में अपने व्यवसाय को सहजता से चला सकें।
आप अपनी विशेष प्रॉक्सीज़ कैसे प्राप्त कर सकते हैं? कृपया मेरे चरणों का पालन करें:
- चरण 1. स्क्रैपलेस में साइन इन करें।
- चरण 2. "प्रॉक्सीज़" पर क्लिक करें, और एक चैनल बनाएं।
- चरण 3. बाईं ऑपरेशन बॉक्स में आपको जो जानकारी चाहिए उसे भरें। फिर "जनरेट" पर क्लिक करें। थोड़ी देर बाद, आप दाईं ओर वह घुमाती प्रॉक्सी देख सकते हैं जो हमने आपके लिए जनरेट की है। अब बस इसे प्रयोग करने के लिए "कॉपी" पर क्लिक करें।
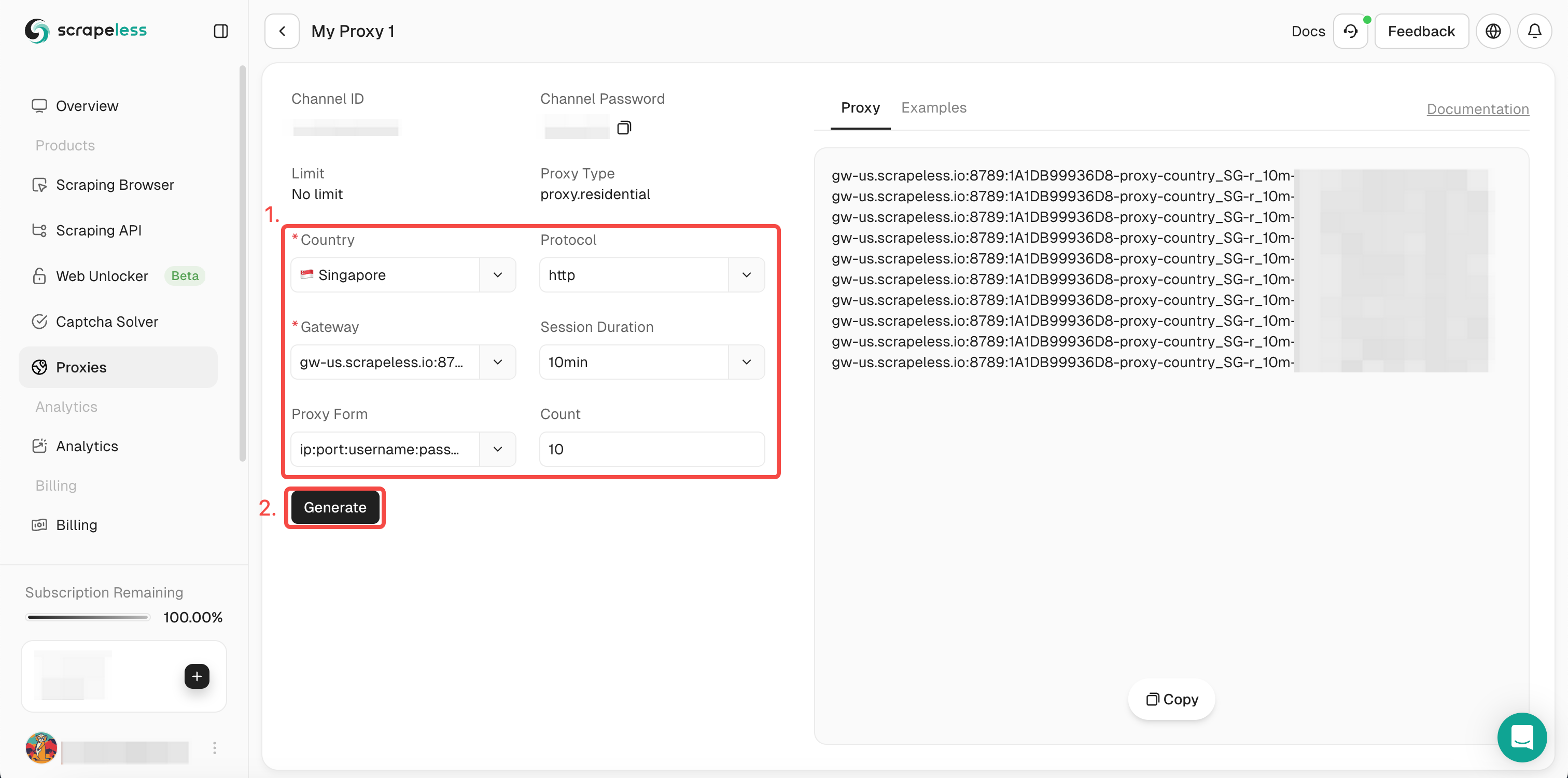
या आप हमारे प्रॉक्सी कोड को अपने प्रोजेक्ट में एकीकृत कर सकते हैं:
- कोड:
C
curl --proxy host:port --proxy-user username:password API_URL- ब्राउज़र:
- सेलेनियम
Python
from seleniumbase import Driver
proxy = 'username:password@gw-us.scrapeless.com:8789'
driver = Driver(browser="chrome", headless=False, proxy=proxy)
driver.get("API_URL")
driver.quit()- पपेटीयर
JavaScript
const puppeteer =require('puppeteer');
(async() => {
const proxyUrl = 'http://gw-us.scrapeless.com:8789';
const username = 'username';
const password = 'password';
const browser = await puppeteer.launch({
args: [`--proxy-server=${proxyUrl}`],
headless: false
});
const page = await browser.newPage();
await page.authenticate({ username, password });
await page.goto('API_URL');
await browser.close();
})();2. कृपया robots.txt का पालन करें
यह फ़ाइल वेबसाइटों के लिए मानक के रूप में कार्य करती है कि क्या फ़ाइलें या पृष्ठ बॉट्स के लिए सुलभ या असुलभ हैं। वेब स्क्रैपर्स निर्दिष्ट मानदंडों का पालन करके एंटी-बॉट उपायों को सक्रिय होने से रोक सकते हैं। वेब स्क्रैपिंग के उद्देश्यों के लिए robots.txt फ़ाइलों को पढ़ने के बारे में अधिक जानें।
समान आईपी पते से किए गए प्रश्नों की संख्या को सीमित करें: वेब स्क्रैपर्स कभी-कभी जल्दी से एक वेबसाइट पर कई अनुरोध करते हैं। आप विचार कर सकते हैं कि समान आईपी पते से आने वाले प्रश्नों की संख्या को कम करें, क्योंकि यह व्यवहार एंटी-बॉट सिस्टम को सक्रिय कर सकता है। वेब स्क्रैपिंग करते समय दर सीमित करने के तरीकों की जांच करें।
3. अपने यूज़र-एजन्ट को अनुकूलित करें
यूज़र-एजन्ट के लिए HTTP हेडर में एक स्ट्रिंग होती है जो दर्शाती है कि अनुरोध किस ब्राउज़र और ऑपरेटिंग सिस्टम से उत्पन्न हुआ है। चूंकि इस हेडर को संशोधित किया गया है, इसलिए अनुरोध नियमित उपयोगकर्ता के रूप में दिखाई देते हैं। वेब स्क्रैपिंग के लिए सबसे लोकप्रिय यूज़र-एजन्ट्स की सूची देखें।
4. बिना हेड वाले ब्राउज़र का उपयोग करें
बिना ग्राफिकल यूजर इंटरफ़ेस के, एक हेडलेस ब्राउज़र फिर भी नियंत्रित किया जा सकता है। ऐसे उपकरण का उपयोग करके, आप अपने स्क्रैपर को बॉट के रूप में पहचाने जाने से रोक सकते हैं, जिससे यह एक मानव उपयोगकर्ता की तरह व्यवहार करता है—यानी, स्क्रॉल करके। हेडलेस ब्राउज़रों और यह जानने के बारे में अधिक जानें कि कौन से वेब स्क्रैपिंग के लिए उपयुक्त हैं।
5. ऑनलाइन स्क्रैपिंग एपीआई के साथ प्रक्रिया को सरल बनाएं
सरल एपीआई कॉल का उपयोग करके, वेब स्क्रैपिंग एपीआई उपयोगकर्ताओं को एंटी-बॉट सिस्टम द्वारा पहचाने बिना वेबसाइटों को स्क्रैप करने की अनुमति देती हैं। इस कारण से, वेब स्क्रैपिंग तीव्र, सरल और प्रभावी है।
देखें कि सबसे शक्तिशाली वेब स्क्रैपिंग एपीआई क्या पेश करती है, इसे आज़माने के लिए स्क्रैपलेस स्क्रैपिंग एपीआई का निःशुल्क परीक्षण करें।
सारांश
इस ट्यूटोरियल में, आपने एंटी बॉट पहचान के बारे में बहुत कुछ सीखा है। आपके लिए एंटी-बॉट पहचान को बायपास करना बस एक साधारण कार्य है।
ब्लॉक होने से बचने का सबसे अच्छा तरीका कौन सा है?
स्क्रेपलेस के साथ, एक ऑनलाइन स्क्रैपिंग उपकरण जिसमें एक उन्नत CAPTCHA हल करने वाला, अंतर्निहित IP घुमाने की क्षमता, हेडलेस ब्राउज़र क्षमता, और वेब अनलॉकर है, आप उनसे सभी से बच सकते हैं!
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


