
हेडलेस ब्राउज़र क्या है और स्क्रैपिंग के लिए सबसे अच्छा हेडलेस ब्राउज़र कौन सा है
Specialist in Anti-Bot Strategies
इस लेख में, आप सीखेंगे कि हेडलेस ब्राउज़र क्या है, इसका उपयोग किस लिए किया जाता है, हेडलेस क्रोम क्या है, और हेडलेस मोड में कौन से अन्य ब्राउज़र सबसे लोकप्रिय हैं। हम हेडलेस ब्राउज़र परीक्षण की मुख्य सीमाओं पर भी चर्चा करेंगे।
अब स्क्रॉल करते रहें!
20 मिलियन डेवलपर्स द्वारा हमें क्यों भरोसा किया जाता है?
आप हेडलेस ब्राउज़र की जटिल दुनिया में कैसे नेविगेट करते हैं? आपको एक अनुभवी गाइड की आवश्यकता है जिसने कई चुनौतियों का सामना किया हो और जीता हो। यहीं पर हम काम आते हैं!
Scrapeless में, हम वर्षों से वेब स्क्रैपिंग और ऑटोमेशन तकनीकों का पता लगा रहे हैं। हमारी टीम ने पुराने समाधानों जैसे PhantomJS से लेकर नए समाधानों जैसे Playwright तक, विभिन्न हेडलेस ब्राउज़र समाधानों पर 15,000 से अधिक घंटे शोध किए हैं।
हमने प्रत्यक्ष रूप से देखा है कि कैसे एक हेडलेस ब्राउज़र किसी प्रोजेक्ट को सफल या असफल बना सकता है। हमने अनगिनत समस्याओं का डिबगिंग और समाधान किया है, बड़े पैमाने पर स्क्रैपिंग संचालन के लिए प्रदर्शन को अनुकूलित किया है, और ऑफ-द-शेल्फ विकल्पों के काम न करने पर कस्टम समाधान भी विकसित किए हैं।
चाहे आप ऑटोमेशन टेस्टिंग करना चाहते हों, बड़े पैमाने पर डेटा स्क्रैप करना चाहते हों, या केवल हेडलेस ब्राउज़िंग की बारीकियों को सीखना चाहते हों, हम आपकी मदद कर सकते हैं!
हेडलेस ब्राउज़र क्या है?
आइए पहले समझते हैं कि ये अदृश्य पॉवरहाउस क्या हैं और ये कैसे काम करते हैं!
एक हेडलेस ब्राउज़र वेब दुनिया का एक निंजा है - चुपके से, कुशल और शक्तिशाली। अनिवार्य रूप से, यह एक वेब ब्राउज़र है जो एक ग्राफिकल यूज़र इंटरफ़ेस (GUI) से सुसज्जित नहीं है। यह मुख्य रूप से सॉफ़्टवेयर परीक्षण इंजीनियरों द्वारा उपयोग किया जाता है क्योंकि GUI के बिना एक ब्राउज़र को दृश्य सामग्री खींचने की आवश्यकता नहीं होती है और इसलिए यह तेज़ी से चलता है। हेडलेस ब्राउज़र के सबसे बड़े लाभों में से एक यह है कि वे GUI समर्थन के बिना सर्वर पर चल सकते हैं।
Chrome या Firefox की कल्पना करें, लेकिन आप पृष्ठ डेटा लोडिंग और प्रदर्शित होने को बिल्कुल नहीं देख सकते हैं, आप इसे पूरी तरह से कोड या कमांड लाइन इंटरफ़ेस के माध्यम से नियंत्रित करते हैं।
क्या आपने कभी ऐसे ब्राउज़र की शक्ति पर संदेह किया है? अब और भ्रमित न हों! वे पारंपरिक ब्राउज़र के लगभग सभी कार्यों को कर सकते हैं:
- वेब पेज रेंडर करें
- जावास्क्रिप्ट निष्पादित करें
- कुकीज़ और सत्रों का प्रबंधन करें
- नेटवर्क अनुरोधों को संभालें
एकमात्र अंतर यह है: वे यह सब स्क्रीन पर कुछ भी प्रदर्शित किए बिना करते हैं। यह उन्हें ऑटोमेशन, परीक्षण और डेटा निष्कर्षण कार्यों के लिए एकदम सही बनाता है।
हेडलेस ब्राउज़र के प्रमुख घटक
नोट: हेडलेस ब्राउज़र का उपयोग करते समय, जावास्क्रिप्ट इंजन पर विशेष ध्यान दें। JS इंजनों में अंतर कभी-कभी अप्रत्याशित व्यवहार को जन्म दे सकता है, खासकर आधुनिक वेब अनुप्रयोगों से निपटते समय।
- ब्राउज़र इंजन: कोर घटक जो HTML, CSS और जावास्क्रिप्ट की व्याख्या करता है। सामान्य इंजनों में ब्लिंक (क्रोम), गेको (फ़ायरफ़ॉक्स) और वेबकिट (सफ़ारी) शामिल हैं।
- जावास्क्रिप्ट इंजन: जावास्क्रिप्ट कोड को निष्पादित करने के लिए ज़िम्मेदार। उदाहरणों में V8 (क्रोम) और स्पाइडरमंकी (फ़ायरफ़ॉक्स) शामिल हैं।
- रेंडरिंग इंजन: हेडलेस ब्राउज़र में, यह घटक अभी भी पेज लेआउट को संभालता है, लेकिन दृश्य आउटपुट नहीं बनाता है।
- नेटवर्क स्टैक: सभी नेटवर्क संचारों को संभालता है, जिसमें HTTP अनुरोध और प्रतिक्रियाएं शामिल हैं।
- API या कमांड इंटरफ़ेस: हेडलेस ब्राउज़र GUI प्रदान नहीं करते हैं, बल्कि नियंत्रण और बातचीत के लिए एक API या कमांड लाइन इंटरफ़ेस प्रदान करते हैं।
- DOM (डॉक्यूमेंट ऑब्जेक्ट मॉडल): वेब पेज की संरचना का एक प्रोग्रामेटिक प्रतिनिधित्व।
हेडलेस ब्राउज़र के मुख्य उपयोग
- वेब क्रॉलिंग: गतिशील सामग्री और उन पृष्ठों को क्रॉल करने के लिए उपयोग किया जाता है जिन्हें जावास्क्रिप्ट रेंडरिंग को निष्पादित करने की आवश्यकता होती है। उदाहरण के लिए: उत्पाद जानकारी, गतिशील रूप से उत्पन्न कीमतें आदि को क्रॉल करना।
- स्वचालित परीक्षण: वेब अनुप्रयोगों के उपयोगकर्ता इंटरफ़ेस व्यवहार का परीक्षण करना, लेकिन वास्तविक विंडो खोले बिना। फ्रंट-एंड कार्यों को सत्यापित करने के लिए CI/CD प्रक्रियाओं में आमतौर पर उपयोग किया जाता है।
- प्रदर्शन निगरानी: वेब पेज लोडिंग समय, रेंडरिंग प्रदर्शन आदि का पता लगाना।
- स्क्रीनशॉट जेनरेशन और PDF एक्सपोर्ट: वेब पेजों के स्क्रीनशॉट उत्पन्न करना या उन्हें PDF में बदलना।
- वेबसाइट निगरानी: यह पता लगाना कि क्या वेबसाइट अपेक्षा के अनुसार चल रही है, और क्या कोई त्रुटि या परिवर्तन हैं।
नुकसान और सीमाएँ
- डीबगिंग चुनौतियाँ: दृश्य प्रतिक्रिया की कमी से कुछ समस्याओं का निदान करना कठिन हो सकता है। मुख्यधारा के ब्राउज़रों की तुलना में एक अलग डिबगिंग दृष्टिकोण की आवश्यकता होती है।
- संसाधन तीव्रता: पूर्ण ब्राउज़रों की तुलना में अधिक कुशल होने के बावजूद, वे बड़े पैमाने पर संचालन के लिए अभी भी संसाधन-गहन हो सकते हैं।
- अपूर्ण रेंडरिंग: कुछ जटिल दृश्य तत्व या एनिमेशन सही ढंग से रेंडर नहीं हो सकते हैं।
- वेबसाइटों द्वारा पता लगाना: उन्नत वेबसाइट हेडलेस ब्राउज़र का पता लगा सकती हैं और उन्हें ब्लॉक कर सकती हैं। "वास्तविक" ब्राउज़र के व्यवहार की नकल करने के लिए अतिरिक्त तकनीक की आवश्यकता होती है।
- सीखने की अवस्था: वेब तकनीकों के प्रोग्रामिंग ज्ञान और समझ की आवश्यकता होती है। प्रत्येक हेडलेस ब्राउज़र समाधान का अपना API और सुविधाएँ हैं जिन्हें महारत हासिल करने की आवश्यकता है।
हेडलेस ब्राउज़र नियमित ब्राउज़र से कैसे भिन्न हैं: 5 प्रमुख अंतर
| विशेषता | हेडलेस ब्राउज़र | नियमित ब्राउज़र |
|---|---|---|
| यूज़र इंटरफ़ेस | कोई यूज़र इंटरफ़ेस नहीं (अदृश्य) | पूर्ण यूज़र इंटरफ़ेस (विंडोज़, मेनू, आदि) |
| इंटरैक्टिविटी | माउस या कीबोर्ड के माध्यम से सीधे बातचीत नहीं की जा सकती | उपयोगकर्ता सीधे संचालित कर सकते हैं (क्लिक करें, टाइप करें, आदि) |
| प्रदर्शन | हल्का क्योंकि यह ग्राफिक्स रेंडर नहीं करता है या पृष्ठ सामग्री प्रदर्शित नहीं करता है | भारी क्योंकि यह पृष्ठ ग्राफिक्स और एनिमेशन रेंडर करता है |
| उपयोग के मामले | स्वचालित परीक्षण, वेब स्क्रैपिंग, निगरानी, आदि। | रोज़मर्रा का ब्राउज़िंग, संचालन और इंटरैक्शन |
| संसाधन खपत | अपेक्षाकृत कम, सर्वर या स्क्रिप्ट वातावरण के लिए उपयुक्त | अपेक्षाकृत अधिक, अधिक सिस्टम संसाधनों की आवश्यकता है |
5 लोकप्रिय हेडलेस ब्राउज़र
शीर्ष 1. स्क्रैपलेस स्क्रैपिंग ब्राउज़र - सर्वश्रेष्ठ हेडलेस ब्राउज़र 2025
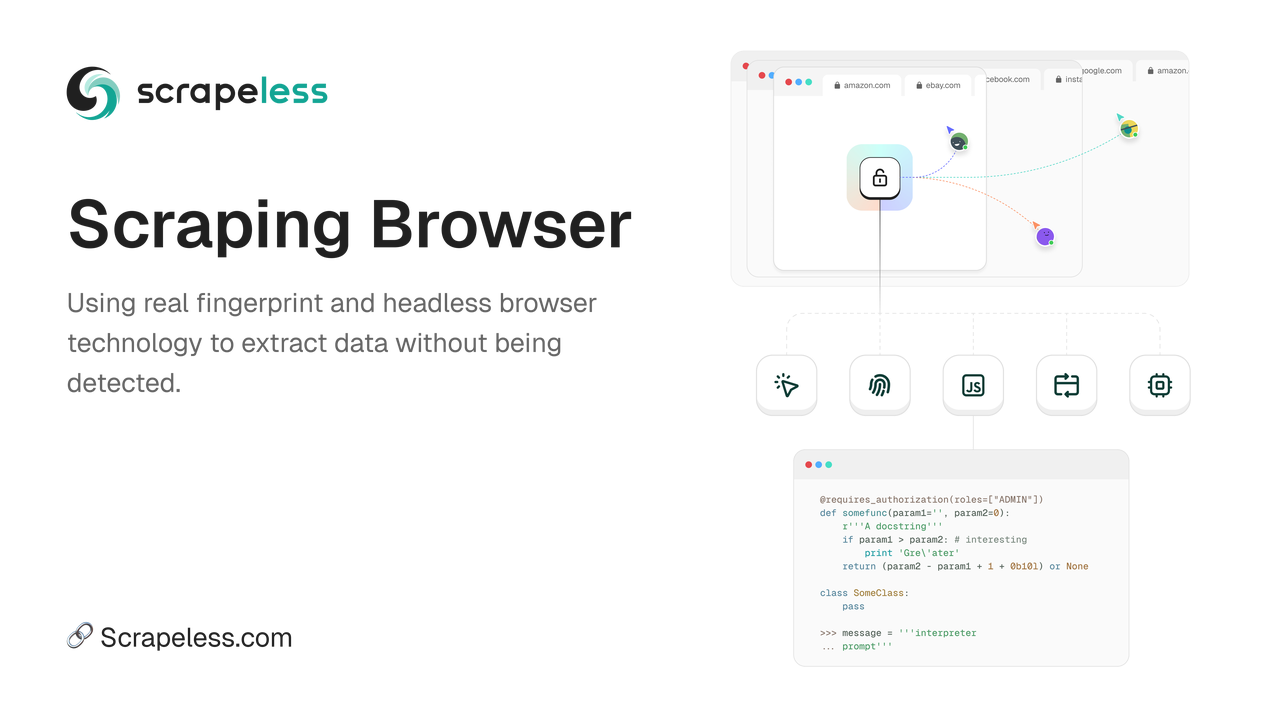
स्क्रैपलेस स्क्रैपिंग ब्राउज़र गतिशील वेबसाइटों से डेटा निकालने की प्रक्रिया को कारगर बनाने के लिए डिज़ाइन किया गया एक उच्च-प्रदर्शन हेडलेस ब्राउज़र है। यह डेवलपर्स को समर्पित सर्वर की आवश्यकता के बिना कुशलतापूर्वक हेडलेस ब्राउज़र को संचालित करने और देखने में सक्षम बनाता है, जिससे वेब ऑटोमेशन और डेटा संग्रह अधिक सुलभ हो जाता है।
चरणों का उपयोग करना:
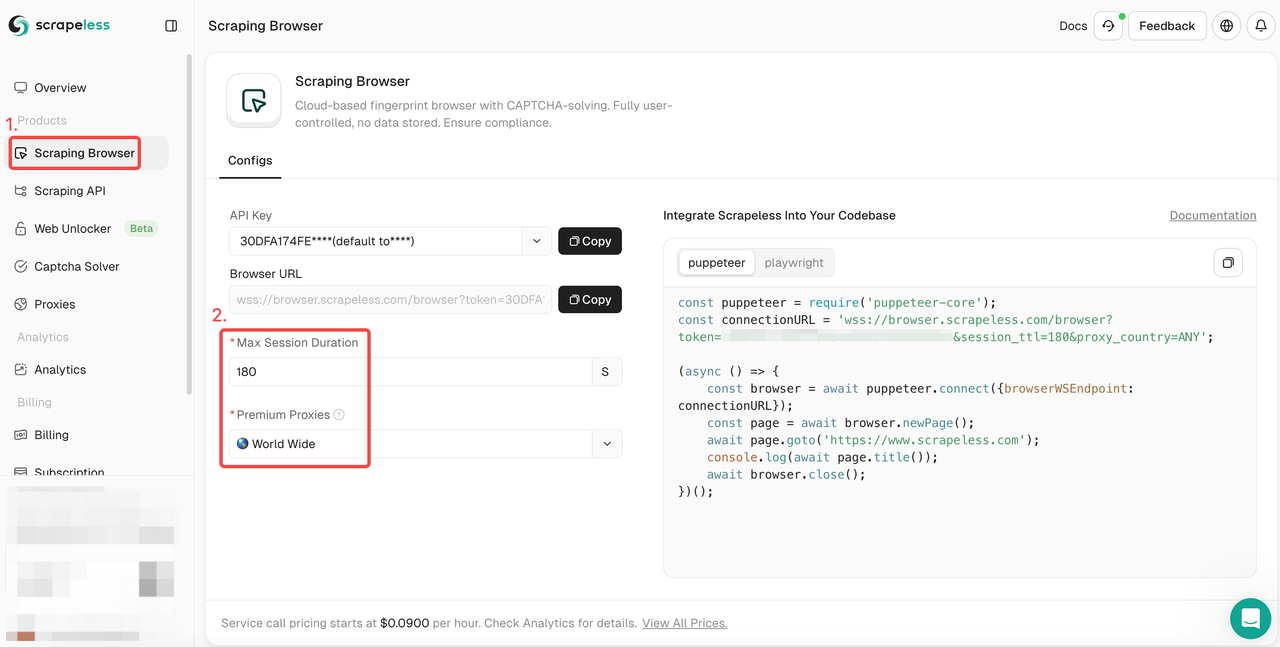
- चरण 1. स्क्रैपलेस में साइन इन करें
- चरण 2. "स्क्रैपिंग ब्राउज़र" दर्ज करें
- चरण 3. अपनी आवश्यकताओं के अनुसार पैरामीटर सेट करें।
- चरण 4. अपनी परियोजना में एकीकृत करने के लिए नमूना कोड कॉपी करें:
पुपेटियर
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //API टोकन इनपुट करें
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();प्लेराइट
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //API टोकन इनपुट करें
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();अधिक विवरण प्राप्त करना चाहते हैं? हमारा दस्तावेज़ीकरण आपको बहुत मदद करेगा:
पुपेटियर:
- आवश्यक पुस्तकालय स्थापित करें
सबसे पहले, puppeteer-core स्थापित करें, जो Puppeteer का एक हल्का संस्करण है जिसे मौजूदा ब्राउज़र इंस्टेंस से कनेक्ट करने के लिए डिज़ाइन किया गया है:
Bash
npm install puppeteer-core- स्क्रैपिंग ब्राउज़र से कनेक्ट करने के लिए कोड लिखें
अपने Puppeteer कोड में, निम्न विधि का उपयोग करके स्क्रैपिंग ब्राउज़र से कनेक्ट करें:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();इस तरह, आप स्क्रैपिंग ब्राउज़र के बुनियादी ढाँचे का लाभ उठा सकते हैं, जिसमें स्केलेबिलिटी, आईपी रोटेशन और वैश्विक पहुँच शामिल है।
- उदाहरण:
यहाँ स्क्रैपिंग ब्राउज़र के साथ एकीकरण के बाद कुछ सामान्य Puppeteer संचालन दिए गए हैं:
- नेविगेशन और पृष्ठ सामग्री निष्कर्षण
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- स्क्रीनशॉट
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- कस्टम स्क्रिप्ट चलाएँ
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();प्लेराइट:
- आवश्यक पुस्तकालय स्थापित करें
सबसे पहले, playwright-core स्थापित करें, जो Playwright का एक हल्का संस्करण है जो मौजूदा ब्राउज़र इंस्टेंस से कनेक्ट होता है:
Bash
npm install playwright-core- स्क्रैपिंग ब्राउज़र से कनेक्ट करने के लिए कोड लिखें
Playwright कोड में, निम्न विधि का उपयोग करके स्क्रैपिंग ब्राउज़र से कनेक्ट करें:
JavaScript
const { chromium } = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();यह आपको स्क्रैपिंग ब्राउज़र के बुनियादी ढाँचे का लाभ उठाने की अनुमति देता है, जिसमें स्केलेबिलिटी, आईपी रोटेशन और वैश्विक पहुँच शामिल है।
- उदाहरण
यहाँ स्क्रैपिंग ब्राउज़र के साथ एकीकरण के बाद कुछ सामान्य Playwright संचालन दिए गए हैं:
- नेविगेशन और पृष्ठ सामग्री निष्कर्षण
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- स्क्रीनशॉट
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- कस्टम स्क्रिप्ट चलाएँ
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();संबंधित लेख: किसी भी वेबसाइट से डेटा स्क्रैप और मॉनिटर करने के लिए सर्वश्रेष्ठ AI स्क्रैपिंग ब्राउज़र
शीर्ष 2. प्लेराइट
Microsoft द्वारा विकसित, Playwright Chromium, Firefox और WebKit पर आधारित ब्राउज़रों के प्रबंधन के लिए एक एकल API प्रदान करता है। इसका उपयोग उच्च-स्तरीय API के साथ कई ब्राउज़रों को स्वचालित करने के लिए किया जा सकता है। हेडलेस ब्राउज़र परीक्षण के लिए Playwright सेट करने से पहले, सुनिश्चित करें कि आपके सिस्टम पर Node.JS और npm का नवीनतम संस्करण स्थापित है।
Playwright ने ऑटोमेशन समुदाय में तेज़ी से कर्षण प्राप्त किया है, जो बड़े पैमाने पर इसकी अनूठी विशेषताओं के कारण है:
- क्रॉस-ब्राउज़र समर्थन (क्रोम, फ़ायरफ़ॉक्स, सफ़ारी)।
- शक्तिशाली स्वचालित प्रतीक्षा तंत्र।
- शक्तिशाली नेटवर्क अवरोधन क्षमताएँ।
- कई भाषाओं (जावास्क्रिप्ट, पायथन, .NET, जावा) के लिए समर्थन।
शीर्ष 3. पुपेटियर
Google द्वारा विकसित, Puppeteer DevTools प्रोटोकॉल के माध्यम से Chrome या Chromium को नियंत्रित करने के लिए एक उच्च-स्तरीय API प्रदान करता है। यह कई जावास्क्रिप्ट डेवलपर्स की पसंदीदा पसंद है।
- क्रोम/क्रोमियम के साथ गहरा एकीकरण
- ब्राउज़र नियंत्रण के लिए व्यापक API
- PDF और स्क्रीनशॉट उत्पन्न करने के लिए अंतर्निहित समर्थन
शीर्ष 4. सेलेनियम
सेलेनियम एक मुफ़्त, ओपन-सोर्स उपकरण है जो ऑटोमेशन के लिए बहुत अच्छा है। यह विभिन्न ऑपरेटिंग सिस्टम पर चलने वाले विभिन्न ब्राउज़रों का समर्थन करता है। सेलेनियम वेब ड्राइवर गतिशील वेब पेजों के लिए उन्नत समर्थन प्रदान करता है, जो सेलेनियम हेडलेस का उपयोग करके उत्कृष्ट परिणाम प्रदान कर सकता है। इसके अलावा, आप हेडलेस क्रोम या हेडलेस फ़ायरफ़ॉक्स का उपयोग हेडलेस ब्राउज़र सेलेनियम करने के लिए कर सकते हैं।
- कई प्रोग्रामिंग भाषाओं के लिए समर्थन
- विभिन्न ब्राउज़रों के साथ संगत (क्रोम, फ़ायरफ़ॉक्स, सफ़ारी, एज)
- उपकरणों और एक्सटेंशन का विशाल पारिस्थितिकी तंत्र
शीर्ष 5. साइप्रस
साइप्रस वेब अनुप्रयोगों के एंड-टू-एंड परीक्षण में उत्कृष्टता प्राप्त करता है, खासकर सिंगल-पेज अनुप्रयोगों में। हालाँकि Cypress मुख्य रूप से एंड-टू-एंड परीक्षण पर केंद्रित है, लेकिन यह इसके डेवलपर-अनुकूल दृष्टिकोण और शक्तिशाली डिबगिंग क्षमताओं के लिए लोकप्रिय है।
- लाइव रिलोड
- समय यात्रा डीबगिंग
- DOM और नेटवर्क परत तक मूल पहुँच का उपयोग करें
हेडलेस क्रोम परीक्षण क्या है?
यदि आप एक डेवलपर हैं, तो आप UI-संचालित परीक्षण से परिचित हैं, जो यह सुनिश्चित करता है कि अनुप्रयोग समय के साथ सही ढंग से कार्य करते हैं। हालाँकि, UI-संचालित परीक्षण के साथ एक प्रमुख चुनौती स्थिरता है—खासकर जब परीक्षण ब्राउज़र के साथ लगातार बातचीत करने में विफल होते हैं।
हेडलेस ब्राउज़र परीक्षण इस समस्या का समाधान प्रदान करता है। UI-संचालित परीक्षण के विपरीत, यह अनुप्रयोग के यूज़र इंटरफ़ेस को लोड किए बिना एंड-टू-एंड परीक्षण की अनुमति देता है। यह दृष्टिकोण न केवल परीक्षण प्रक्रिया को गति देता है बल्कि पृष्ठ के साथ सीधी बातचीत भी सुनिश्चित करता है, जिससे अस्थिरता कम हो जाती है। परिणामस्वरूप, परीक्षण तेज़, अधिक विश्वसनीय और अत्यधिक कुशल हो जाते हैं।
आपको हेडलेस ब्राउज़र परीक्षण का उपयोग कब करना चाहिए?
हेडलेस ब्राउज़र परीक्षण उन परिदृश्यों में विशेष रूप से उपयोगी है जहाँ संसाधन कम हैं या जब स्वचालन कार्यों को कुशलतापूर्वक निष्पादित करने की आवश्यकता होती है। यहाँ कुछ सामान्य उपयोग के मामले दिए गए हैं:
- स्वचालित HTML इंटरैक्शन
फ़ॉर्म सबमिशन, बटन क्लिक और ड्रॉपडाउन मेनू चयन जैसे उपयोगकर्ता कार्यों का अनुकरण करें। हेडलेस ब्राउज़र आपको इन इंटरैक्शन के प्रति प्रतिक्रियाओं को प्रभावी ढंग से सत्यापित करने की अनुमति देते हैं। - जावास्क्रिप्ट निष्पादन परीक्षण
गतिशील सामग्री को मान्य करने के लिए वेब पेजों में जावास्क्रिप्ट के निष्पादन का परीक्षण करें। यह व्यापक क्लाइंट-साइड रेंडरिंग वाले अनुप्रयोगों के लिए विशेष रूप से उपयोगी है। - वेब स्क्रैपिंग
मूल एंटी-स्क्रैपिंग उपायों को दरकिनार करें, गतिशील सामग्री लोड करें और वेब पेजों से डेटा निकालें। जटिल फ्रंट-एंड रेंडरिंग वाले स्क्रैपिंग कार्यों के लिए हेडलेस ब्राउज़र आदर्श हैं। - नेटवर्क निगरानी और प्रदर्शन परीक्षण
नेटवर्क अनुरोधों की निगरानी करें, लोड समय का विश्लेषण करें और प्रदर्शन की बाधाओं की पहचान करें, जिससे यह वेबसाइट प्रदर्शन अनुकूलन के लिए मूल्यवान हो जाता है। - Ajax अनुरोधों को संभालना
यह सुनिश्चित करें कि डेटा लोडिंग के लिए Ajax पर निर्भर करने वाले पृष्ठ इन अनुरोधों को कैप्चर और प्रोसेस करके सही ढंग से प्रदर्शित होते हैं। - वेब पेज स्क्रीनशॉट उत्पन्न करना
परीक्षण के दौरान लेआउट या सामग्री के मुद्दों की पहचान करने, दस्तावेज़ीकरण उत्पन्न करने या वेब पेजों की दृश्य जाँच करने के लिए स्क्रीनशॉट बनाएँ।
निचली रेखाएँ
क्या शानदार दिन! जैसे ही हमने हेडलेस ब्राउज़िंग शिप को डॉक किया, यह स्पष्ट हो गया कि हम वेब ऑटोमेशन और डेटा निष्कर्षण में क्रांति के सबसे आगे थे।
हेडलेस ब्राउज़र परीक्षण ब्राउज़र पर वेब अनुप्रयोगों का परीक्षण करने का एक तेज़, अधिक विश्वसनीय और अधिक कुशल तरीका है। हालाँकि, जब आप वास्तविक डेस्कटॉप ब्राउज़र से परीक्षण करते हैं, तो यह आपकी वेबसाइट का एक सही प्रतिनिधित्व प्रदान करता है।
क्या आप एक ही समय में हेडलेस और वास्तविक हो सकते हैं? ज़रूर! स्क्रैपलेस स्क्रैपिंग ब्राउज़र दोनों दुनिया के सर्वश्रेष्ठ को जोड़ता है। यह आपको वेब पेजों को आसानी से स्वचालित करने की अनुमति देता है।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


