
सर्वश्रेष्ठ AI स्क्रैपिंग ब्राउज़र: किसी भी वेबसाइट से डेटा स्क्रैप करें और मॉनिटर करें
Specialist in Anti-Bot Strategies
वेब स्क्रैपिंग आपके व्यवसाय या उत्पाद को पीछे नहीं छूटने देने के लिए आवश्यक है। वेब डेटा आपको संभावित उपभोक्ताओं के बारे में लगभग सब कुछ बता सकता है, औसत मूल्य से लेकर इस समय की सबसे ज़रूरी सुविधाओं तक।
आप क्रॉलिंग के बोझ को कैसे कम कर सकते हैं और अपने काम को और अधिक कुशल बना सकते हैं?
उच्च-गुणवत्ता वाला डेटा प्राप्त करने के लिए सर्वोत्तम वेब स्क्रैपिंग टूल का उपयोग करना आवश्यक है, इसलिए आपको यह सुनिश्चित करने की आवश्यकता है कि आपको काम के लिए सर्वोत्तम टूल मिलें।
वेब स्क्रैपिंग के बारे में सब कुछ जानने और सर्वश्रेष्ठ स्क्रैपिंग ब्राउज़र प्राप्त करने के लिए अभी यह लेख पढ़ना शुरू करें!
डेटा स्क्रैपिंग क्यों आवश्यक है?
पुरानी जानकारी के कारण कंपनियों को संसाधनों का अकुशलतापूर्वक आवंटन करना पड़ सकता है या नवीनतम धन-उत्पादक अवसरों से चूकना पड़ सकता है। अगले महीने के लिए मूल्य निर्धारण तैयार करने के लिए आपको छुट्टियों से एक सप्ताह पहले उपभोक्ता वस्तुओं के मूल्य डेटा पर निर्भर रहने की आवश्यकता है।
वेब डेटा बिक्री और उत्पादकता को काफी हद तक बढ़ाने में मदद कर सकता है। आधुनिक इंटरनेट अत्यंत जीवंत है - उपयोगकर्ता हर दिन 2.5 क्विंटिलियन बाइट डेटा उत्पन्न करते हैं। चाहे आप एक स्टार्टअप हों या दशकों के इतिहास वाली एक बड़ी कंपनी, इंटरनेट डेटा में उपयोगी जानकारी आपको प्रतिस्पर्धियों से संभावित ग्राहकों को आकर्षित करने और उन्हें आपके उत्पादों के लिए भुगतान करने में मदद कर सकती है।
हालांकि, संभावित ग्राहक डेटा की विशाल मात्रा का मतलब है कि आप डेटा को मैन्युअल रूप से निकालने में जीवन भर बिता सकते हैं और कभी नहीं पकड़ सकते। और मैन्युअल डेटा निष्कर्षण विभिन्न चुनौतियों का भी सामना करता है!
डेटा को स्क्रैप करते और मॉनिटर करते समय चुनौतियाँ
1. एंटी-स्क्रैपिंग उपाय
कई वेबसाइट स्क्रैपिंग गतिविधियों का पता लगाने और उन्हें ब्लॉक करने के लिए विभिन्न तकनीकों को तैनात करती हैं। इन उपायों को उनके डेटा की सुरक्षा और दुरुपयोग को रोकने के लिए रखा गया है।
- CAPTCHA: ये पहेलियाँ हैं जो मानव और बॉट गतिविधि के बीच अंतर करने के लिए डिज़ाइन की गई हैं। CAPTCHA के सामान्य रूपों में विकृत पाठ, छवि पहचान कार्य या क्लिक-टू-चयन क्रियाएँ शामिल हैं।
- रेट लिमिटिंग: वेबसाइटें किसी दिए गए समय अवधि में एक ही IP पते से अनुरोधों की संख्या को सीमित कर सकती हैं ताकि उनके सर्वरों पर अतिभार को रोका जा सके। यदि थोड़े समय में बहुत अधिक अनुरोध भेजे जाते हैं, तो आपका IP ब्लॉक किया जा सकता है।
- IP ब्लॉकिंग: वेबसाइटें अक्सर उन IP पतों पर नज़र रखती हैं जिनसे अनुरोध किए जाते हैं। यदि वे स्क्रैपिंग व्यवहार का पता लगाते हैं, तो वे उस IP से पहुँच को ब्लॉक या कम कर सकते हैं।
- जावास्क्रिप्ट रेंडरिंग: कई आधुनिक वेबसाइटें सामग्री को गतिशील रूप से लोड करने के लिए जावास्क्रिप्ट का उपयोग करती हैं। पारंपरिक स्क्रैपिंग विधियाँ (जैसे, Requests या BeautifulSoup जैसी लाइब्रेरी के साथ) इस तरह की सामग्री को स्क्रैप करने में संघर्ष कर सकती हैं।
- ब्राउज़र फ़िंगरप्रिंटिंग: वेबसाइटें ब्राउज़र व्यवहार और फ़िंगरप्रिंट का विश्लेषण करके गैर-मानव ट्रैफ़िक का पता लगा सकती हैं, जैसे स्क्रीन रिज़ॉल्यूशन, इंस्टॉल किए गए प्लगइन्स और अन्य विशेषताएँ।
क्या CAPTCHA और एंटी-बॉट डिटेक्शन द्वारा ब्लॉक किए जाने से निराश हैं?
Scrapeless 99.9% वेबसाइटों को अनलॉक करता है
इसे मुफ़्त में आज़माएँ!
2. गतिशील और जटिल वेबसाइट संरचनाएँ
वेबसाइटें अक्सर ऐसे ढाँचों का उपयोग करके बनाई जाती हैं जो जावास्क्रिप्ट के माध्यम से डेटा को गतिशील रूप से लोड करते हैं। ये गतिशील वेबसाइटें पृष्ठ के लोड होने के बाद सामग्री को अंदर खींचने के लिए अक्सर AJAX अनुरोधों का उपयोग करती हैं, जिससे पारंपरिक विधियों का उपयोग करके स्क्रैप करना मुश्किल हो जाता है।
- जावास्क्रिप्ट-भारी साइटें: समाचार आउटलेट या सोशल मीडिया प्लेटफ़ॉर्म जैसी वेबसाइटों से सामग्री को स्क्रैप करने के लिए अक्सर जावास्क्रिप्ट को प्रस्तुत करने की क्षमता की आवश्यकता होती है। इसके बिना, सामग्री पृष्ठ के HTML स्रोत कोड में उपलब्ध नहीं हो सकती है।
- अनंत स्क्रॉलिंग: अनंत स्क्रॉलिंग वाली वेबसाइटें (जैसे, सोशल मीडिया या ई-कॉमर्स साइटें) उपयोगकर्ता के नीचे स्क्रॉल करने पर अधिक सामग्री लोड करती हैं। यह यह निर्धारित करने में चुनौतियाँ प्रस्तुत करता है कि सभी आवश्यक डेटा लोड हो गया है और इसे कुशलतापूर्वक कैसे निकाला जाए।
- जटिल HTML संरचना: जटिल HTML संरचनाओं वाली वेबसाइटें (जैसे, नेस्टेड तत्व, अनियमित टैग नाम या असंगत लेआउट) सामग्री को पार्स करना मुश्किल बना सकती हैं।
3. एंटी-बॉट समाधान
वेबसाइटें अपने डेटा की सुरक्षा के लिए तेजी से परिष्कृत एंटी-बॉट समाधान तैनात करती हैं, जिससे स्क्रैपिंग करना अधिक कठिन काम हो सकता है।
- डिवाइस फ़िंगरप्रिंटिंग: वेबसाइटें बॉट जैसे व्यवहारों का पता लगाने के लिए उन्नत तकनीकों का उपयोग कर सकती हैं, जैसे कि आपके ब्राउज़र के फ़िंगरप्रिंट, नेटवर्क कॉन्फ़िगरेशन या आपके माउस आंदोलनों का विश्लेषण करना।
- व्यवहारिक विश्लेषण: कुछ वेबसाइटें बॉट व्यवहार का पता लगाने के लिए आपकी बातचीत (जैसे, माउस आंदोलन, क्लिक और स्क्रॉल व्यवहार) को ट्रैक करती हैं। यदि स्क्रैपर गैर-मानवीय तरीके से व्यवहार करता है, तो यह एंटी-बॉट उपायों को ट्रिगर कर सकता है।
स्क्रैपिंग ब्राउज़र कैसे काम करता है?
चरण 1. HTTP अनुरोध भेजना
चरण 2. वेब पेज रेंडर करना
चरण 3. वेब पेज पर नेविगेट करना
चरण 4. डेटा निकालना
चरण 5. गतिशील सामग्री को संभालना
चरण 6. सत्रों और कुकीज़ का प्रबंधन करना
चरण 7. एंटी-स्क्रैपिंग तंत्र से निपटना
चरण 8. त्रुटियों और विफलताओं को संभालना
चरण 9. डेटा को संग्रहीत करना और आउटपुट करना
स्क्रैपिंग ब्राउज़र चुनौतियों को कैसे दरकिनार कर सकता है?
स्क्रैपिंग ब्राउज़र वेबसाइट की निगरानी और ब्लॉकिंग को प्रभावी ढंग से टाल सकते हैं, मुख्य रूप से निम्नलिखित प्रमुख तकनीकों पर निर्भर करते हुए:
1. अंतर्निहित CAPTCHA सॉल्वर
एक स्क्रैपिंग ब्राउज़र CAPTCHA सॉल्विंग-सेवाओं को एकीकृत करता है, जो स्वचालित रूप से वेबसाइट की CAPTCHA चुनौतियों की पहचान और समाधान कर सकता है।
2. IP रोटेशन
IP रोटेशन के माध्यम से, स्क्रैपिंग ब्राउज़र अनुरोध स्रोत के IP पते को बार-बार बदल सकता है, जो एक ही IP पते को कम समय में बड़ी संख्या में अनुरोध करने से रोक सकता है। घूर्णन प्रॉक्सी का उपयोग करके, प्रत्येक अनुरोध एक अलग IP पते का उपयोग कर सकता है और फिर IP ब्लॉकिंग को दरकिनार कर सकता है।
3. उपयोगकर्ता-एजेंट यादृच्छिकरण
उपयोगकर्ता-एजेंट यादृच्छिकरण के माध्यम से, स्क्रैपिंग ब्राउज़र विभिन्न ब्राउज़रों, उपकरणों और ऑपरेटिंग सिस्टम से अनुरोधों का अनुकरण कर सकते हैं, क्रॉलर के रूप में पहचाने जाने के जोखिम को कम कर सकते हैं। उपयोगकर्ता-एजेंट स्ट्रिंग को लगातार बदलकर, क्रॉलर अनुरोधों को इस तरह दिखा सकते हैं जैसे वे एक एकल स्वचालित उपकरण के बजाय विभिन्न उपयोगकर्ताओं से आते हैं।
4. वास्तविक फ़िंगरप्रिंटिंग
स्क्रैपिंग ब्राउज़र वास्तविक उपयोगकर्ता के ब्राउज़र फ़िंगरप्रिंट का अनुकरण करता है, बजाय पहचान से बचने के लिए फ़िंगरप्रिंट को बदलने या बनाने के। वास्तविक फ़िंगरप्रिंट क्रॉलर को एक सामान्य उपयोगकर्ता की तरह व्यवहार करने में सक्षम बनाते हैं, ठीक उसी तरह जैसे अन्य उपयोगकर्ता समान डिवाइस और ब्राउज़र का उपयोग करके वेबसाइट पर जाते हैं।
आपको यह भी पसंद आ सकता है: 5 सर्वश्रेष्ठ स्क्रैपिंग ब्राउज़र 2025
सर्वश्रेष्ठ AI स्क्रैपिंग ब्राउज़र - Scrapeless
Scrapeless स्क्रैपिंग ब्राउज़र एक उच्च-प्रदर्शन सर्वरलेस प्लेटफ़ॉर्म प्रदान करता है। यह गतिशील वेबसाइटों से डेटा निकालने की प्रक्रिया को प्रभावी ढंग से सरल करता है। डेवलपर्स समर्पित सर्वरों के बिना हेडलेस ब्राउज़र चला सकते हैं, प्रबंधित कर सकते हैं और उनकी निगरानी कर सकते हैं, जिससे कुशल वेब ऑटोमेशन और डेटा संग्रह सक्षम हो जाता है।
वेब स्क्रैपिंग के लिए Scrapeless विशेष क्यों है?
Scrapeless स्क्रैपिंग ब्राउज़र में 195 देशों और 70 मिलियन से अधिक आवासीय IP पतों को कवर करने वाला एक वैश्विक नेटवर्क, एक शक्तिशाली वेब अनलॉकर और एक अत्यधिक स्थिर कैप्चा सॉल्वर है। यह उन उपयोगकर्ताओं के लिए आदर्श है जिन्हें विश्वसनीय और स्केलेबल वेब स्क्रैपिंग समाधान की आवश्यकता होती है।
Scrapeless स्क्रैपिंग ब्राउज़र का उपयोग कैसे करें?
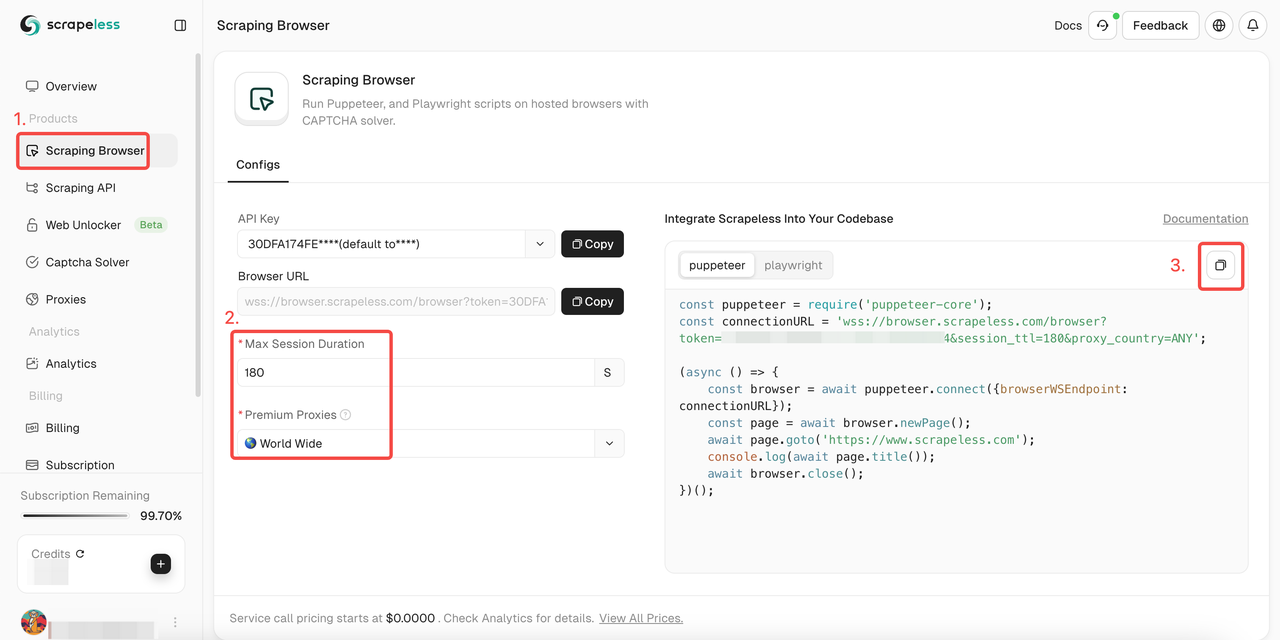
- चरण 1. साइन इन करें Scrapeless
- चरण 2. "स्क्रैपिंग ब्राउज़र" दर्ज करें
- चरण 3. अपनी आवश्यकताओं के अनुसार पैरामीटर सेट करें
- चरण 4. अपनी परियोजना में एकीकृत करने के लिए नमूना कोड कॉपी करें:
Puppeteer
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //input API token
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Playwright
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //input API token
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();अधिक विवरण प्राप्त करना चाहते हैं? हमारा दस्तावेज़ आपको बहुत मदद करेगा!
Puppeteer:
चरण 1. आवश्यक लाइब्रेरी स्थापित करें
सबसे पहले, puppeteer-core स्थापित करें, जो Puppeteer का एक हल्का संस्करण है जिसे मौजूदा ब्राउज़र इंस्टेंस से कनेक्ट करने के लिए डिज़ाइन किया गया है:
Bash
npm install puppeteer-coreचरण 2. स्क्रैपिंग ब्राउज़र से कनेक्ट करने के लिए कोड लिखें
अपने Puppeteer कोड में, निम्न विधि का उपयोग करके स्क्रैपिंग ब्राउज़र से कनेक्ट करें:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();इस तरह, आप स्क्रैपिंग ब्राउज़र इन्फ्रास्ट्रक्चर का लाभ उठा सकते हैं, जिसमें स्केलेबिलिटी, IP रोटेशन और वैश्विक पहुँच शामिल है।
उदाहरण:
स्क्रैपिंग ब्राउज़र के साथ एकीकरण के बाद यहाँ कुछ सामान्य Puppeteer संचालन दिए गए हैं:
- नेविगेशन और पृष्ठ सामग्री निष्कर्षण
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- स्क्रीनशॉट
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- कस्टम स्क्रिप्ट चलाएँ
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();Playwright:
चरण 1. आवश्यक लाइब्रेरी स्थापित करें
सबसे पहले, playwright-core स्थापित करें, जो Playwright का एक हल्का संस्करण है जो मौजूदा ब्राउज़र इंस्टेंस से जुड़ता है:
Bash
npm install playwright-coreचरण 2. स्क्रैपिंग ब्राउज़र से कनेक्ट करने के लिए कोड लिखें
Playwright कोड में, निम्न विधि का उपयोग करके स्क्रैपिंग ब्राउज़र से कनेक्ट करें:
JavaScript
const { chromium } = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();यह आपको स्क्रैपिंग ब्राउज़र के इन्फ्रास्ट्रक्चर का लाभ उठाने की अनुमति देता है, जिसमें स्केलेबिलिटी, IP रोटेशन और वैश्विक पहुँच शामिल है।
उदाहरण
स्क्रैपिंग ब्राउज़र के साथ एकीकरण के बाद यहाँ कुछ सामान्य Playwright संचालन दिए गए हैं:
- नेविगेशन और पृष्ठ सामग्री निष्कर्षण
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- स्क्रीनशॉट
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- कस्टम स्क्रिप्ट चलाएँ
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();वेब स्क्रैपर चुनते समय 8 कारक माने जाने चाहिए
- डेटा निष्कर्षण क्षमताएँ: एक अच्छा वेब स्क्रैपिंग टूल विभिन्न प्रकार के डेटा स्वरूपों का समर्थन करता है और विभिन्न प्रकार की वेब पेज संरचनाओं से सामग्री निकाल सकता है, जिसमें स्थिर HTML पृष्ठ और जावास्क्रिप्ट का उपयोग करके गतिशील वेबसाइटें शामिल हैं।
- उपयोग में आसानी: टूल के लर्निंग कर्व, यूजर इंटरफेस और उपलब्ध दस्तावेज़ीकरण का मूल्यांकन करें। टूल का उपयोग करने वाले लोगों को टूल की जटिलता को समझना चाहिए।
- स्केलेबिलिटी: बड़े पैमाने पर डेटा निष्कर्षण को संभालने की टूल की क्षमता पर विचार करें। प्रदर्शन के संदर्भ में स्केलेबिलिटी और बढ़ती मात्रा में डेटा या अनुरोधों को समायोजित करने की क्षमता महत्वपूर्ण है।
- स्वचालन क्षमताएँ: उपलब्ध स्वचालन की डिग्री की जाँच करें। शेड्यूलिंग क्षमताओं, CAPTCHA के स्वचालित संचालन और कुकीज़ और सत्रों को स्वचालित रूप से प्रबंधित करने की क्षमता देखें।
- IP रोटेशन और प्रॉक्सी समर्थन: टूल को ब्लॉक किए जाने से बचने के लिए मजबूत IP रोटेशन और प्रॉक्सी प्रबंधन समर्थन प्रदान करना चाहिए।
- त्रुटि संचालन और पुनर्प्राप्ति: जांचें कि टूल त्रुटियों का प्रबंधन कैसे करता है, जैसे कि कनेक्शन छोड़ना या अप्रत्याशित साइट परिवर्तन।
- अन्य प्रणालियों के साथ एकीकरण: निर्धारित करें कि क्या टूल अन्य प्रणालियों और प्लेटफार्मों के साथ मूल रूप से एकीकृत होता है, जैसे कि डेटाबेस, क्लाउड सेवाएँ या डेटा विश्लेषण उपकरण। एपीआई के साथ संगतता भी एक महत्वपूर्ण लाभ है।
- डेटा सफाई और प्रसंस्करण: कच्चे डेटा से उपयोगी जानकारी तक वर्कफ़्लो को सुव्यवस्थित करने के लिए अंतर्निहित या आसानी से एकीकृत डेटा सफाई और प्रसंस्करण क्षमताओं की तलाश करें।
समापन विचार
वेब स्क्रैपिंग रोबोट को वेबसाइटों द्वारा आसानी से पहचाना जाता है और वे ब्लॉकिंग की ओर ले जाते हैं! एक सहज डेटा निष्कर्षण प्रक्रिया कैसे प्राप्त करें?
Scrapeless स्क्रैपिंग ब्राउज़र में अंतर्निहित वेब अनब्लॉकर, CAPTCHA सॉल्वर, घूर्णन IP और बुद्धिमान प्रॉक्सी आपको वेबसाइट ब्लॉकिंग से आसानी से बचने और डेटा स्क्रैपिंग प्राप्त करने में मदद कर सकते हैं!
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


