
Golang में वेब क्रॉलर: चरण-दर-चरण ट्यूटोरियल 2025
Senior Web Scraping Engineer
अधिकांश बड़े वेब स्क्रैपिंग प्रोजेक्ट Go में एक Golang वेब क्रॉलर का उपयोग करके URL को खोजने और व्यवस्थित करने से शुरू होते हैं। यह टूल आपको एक प्रारंभिक लक्ष्य डोमेन (जिसे "सीड URL" भी कहा जाता है) को नेविगेट करने और अधिक लिंक खोजने के लिए पृष्ठ पर लिंक को पुनरावर्ती रूप से देखने देता है।
यह मार्गदर्शिका आपको वास्तविक दुनिया के उदाहरणों का उपयोग करके Golang वेब क्रॉलर को बनाने और अनुकूलित करने का तरीका सिखाएगी। और, इससे पहले कि हम इसमें तल्लीन हों, आपको कुछ उपयोगी पूरक जानकारी भी मिलेगी।
बिना किसी और देरी के, आइए देखें कि आज आपके लिए क्या मज़ेदार चीजें हैं!
वेब क्रॉलिंग क्या है?
वेब क्रॉलिंग, अपने मूल में, उपयोगी डेटा निकालने के लिए वेबसाइटों को व्यवस्थित रूप से नेविगेट करने में शामिल है। एक वेब क्रॉलर (जिसे अक्सर स्पाइडर कहा जाता है) वेब पेज प्राप्त करता है, उनकी सामग्री को पार्स करता है और विशिष्ट लक्ष्यों, जैसे अनुक्रमण या डेटा एकत्रीकरण को पूरा करने के लिए जानकारी को संसाधित करता है। आइए इसे तोड़ दें:
वेब क्रॉलर सर्वर से वेब पेज पुनः प्राप्त करने और प्रतिक्रियाओं को संसाधित करने के लिए HTTP अनुरोध भेजते हैं। इसे आपके क्रॉलर और वेबसाइट के बीच एक विनम्र हाथ मिलाने की तरह सोचें—"नमस्ते, क्या मैं आपके डेटा को घुमाने के लिए ले सकता हूँ?"
एक बार पेज प्राप्त हो जाने के बाद, क्रॉलर HTML को पार्स करके प्रासंगिक डेटा निकालता है। DOM संरचनाएँ पृष्ठ को प्रबंधनीय भागों में तोड़ने में मदद करती हैं, और CSS चयनकर्ता एक सटीक जोड़ी चिमटी की तरह काम करते हैं, जिन तत्वों की आपको आवश्यकता होती है उन्हें चुनते हैं।
अधिकांश वेबसाइट अपने डेटा को कई पृष्ठों पर फैलाती हैं। क्रॉलर को पृष्ठांकन के इस भूलभुलैया को नेविगेट करने की आवश्यकता होती है, जबकि डेटा-भूखे बॉट की तरह दिखने से बचने के लिए दर सीमाओं का सम्मान करते हैं।
2025 में वेब क्रॉलिंग के लिए Golang क्यों परफेक्ट है
अगर वेब क्रॉलिंग एक दौड़ होती, तो Golang वह स्पोर्ट्स कार होती जिसे आप अपने गैरेज में रखना चाहेंगे। इसकी अनूठी विशेषताएँ इसे आधुनिक वेब क्रॉलर के लिए सबसे उपयुक्त भाषा बनाती हैं।
- समांतरता: Golang के goroutines आपको एक साथ कई अनुरोध करने की अनुमति देते हैं, "समानांतर प्रसंस्करण" कहने से पहले ही डेटा को स्क्रैप करते हैं।
- सरलता: भाषा का स्पष्ट सिंटैक्स और न्यूनतम डिज़ाइन आपके कोडबेस को प्रबंधनीय बनाए रखता है, भले ही जटिल क्रॉलिंग प्रोजेक्ट से निपटा जा रहा हो।
- प्रदर्शन: Golang संकलित है, जिसका अर्थ है कि यह बहुत तेज़ी से चलता है—बड़े पैमाने पर वेब क्रॉलिंग कार्यों को बिना किसी परेशानी के संभालने के लिए आदर्श।
- मज़बूत मानक पुस्तकालय: HTTP अनुरोधों, JSON पार्सिंग और बहुत कुछ के लिए अंतर्निहित समर्थन के साथ, Golang का मानक पुस्तकालय आपको शुरुआत से ही एक क्रॉलर बनाने के लिए आवश्यक हर चीज से लैस करता है।
जब आप कैफीन पर एक गोफर की तरह डेटा के माध्यम से उड़ान भर सकते हैं, तो अटपटे टूल से जूझने की क्या ज़रूरत है? Golang गति, सरलता और शक्ति को जोड़ता है, जिससे यह कुशलतापूर्वक और प्रभावी ढंग से वेब क्रॉल करने के लिए अंतिम विकल्प बन जाता है।
क्या क्रॉलिंग वेबसाइटें कानूनी हैं?
वेब क्रॉलिंग की वैधता एक आकार-फिट-सभी स्थिति नहीं है। यह इस बात पर निर्भर करता है कि आप कैसे, कहाँ और क्यों क्रॉल कर रहे हैं। जबकि सार्वजनिक डेटा को स्क्रैप करना आम तौर पर अनुमेय है, सेवा की शर्तों का उल्लंघन करना या एंटी-स्क्रैपिंग उपायों को दरकिनार करना कानूनी परेशानियों का कारण बन सकता है।
कानून के सही पक्ष में बने रहने के लिए, यहाँ कुछ सुनहरे नियम दिए गए हैं:
- robots.txt निर्देशों का सम्मान करें।
- संवेदनशील या प्रतिबंधित जानकारी को स्क्रैप करने से बचें।
- यदि आप किसी वेबसाइट की नीति के बारे में अनिश्चित हैं, तो अनुमति लें।
अपना पहला Golang वेब क्रॉलर कैसे बनाएँ?
पूर्वापेक्षाएँ
- सुनिश्चित करें कि आपके पास Go का नवीनतम संस्करण स्थापित है। आप आधिकारिक Golang वेबसाइट से स्थापना पैकेज डाउनलोड कर सकते हैं और इसे स्थापित करने के निर्देशों का पालन कर सकते हैं।
- अपना पसंदीदा IDE चुनें। यह ट्यूटोरियल Goland को संपादक के रूप में उपयोग करता है।
- एक Go वेब स्क्रैपिंग लाइब्रेरी चुनें जिससे आप सहज हों। इस उदाहरण में, हम chromedp का उपयोग करेंगे।
अपने Go इंस्टॉलेशन को सत्यापित करने के लिए, टर्मिनल में निम्न कमांड दर्ज करें:
PowerShell
go versionयदि स्थापना सफल होती है, तो आपको निम्न परिणाम दिखाई देगा:
PowerShell
go version go1.23.4 windows/amd64अपनी कार्य निर्देशिका बनाएँ, और एक बार अंदर जाने के बाद, निम्न कमांड दर्ज करें:
go modको इनिशियलाइज़ करें:
PowerShell
go mod init crawlchromedpनिर्भरता स्थापित करें:
PowerShell
go get github.com/chromedp/chromedpcrawl.goफ़ाइल बनाएँ।
अब हम आपका वेब स्क्रैपर कोड लिखना शुरू कर सकते हैं।
पृष्ठ तत्व प्राप्त करें
Lazada पर जाएँ, और पृष्ठ तत्वों और चयनकर्ताओं की आसानी से पहचान करने के लिए ब्राउज़र के डेवलपर टूल (F12) का उपयोग करें जिनकी आपको आवश्यकता है।
- इनपुट फ़ील्ड और उसके बगल में स्थित खोज बटन प्राप्त करें:
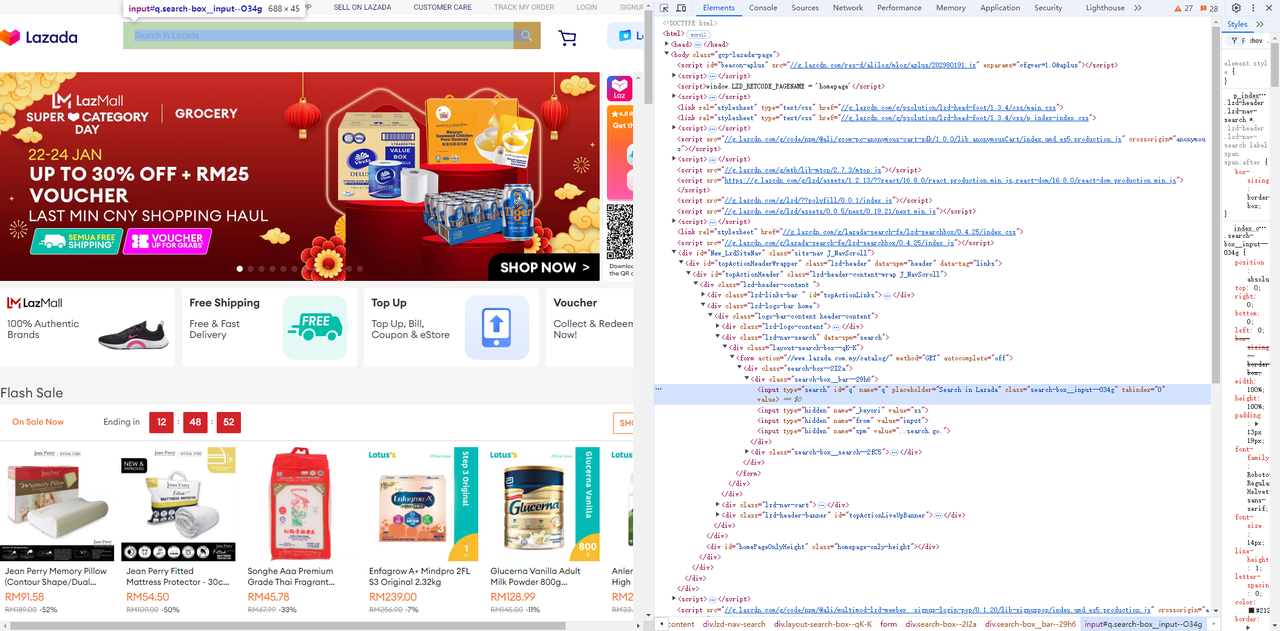
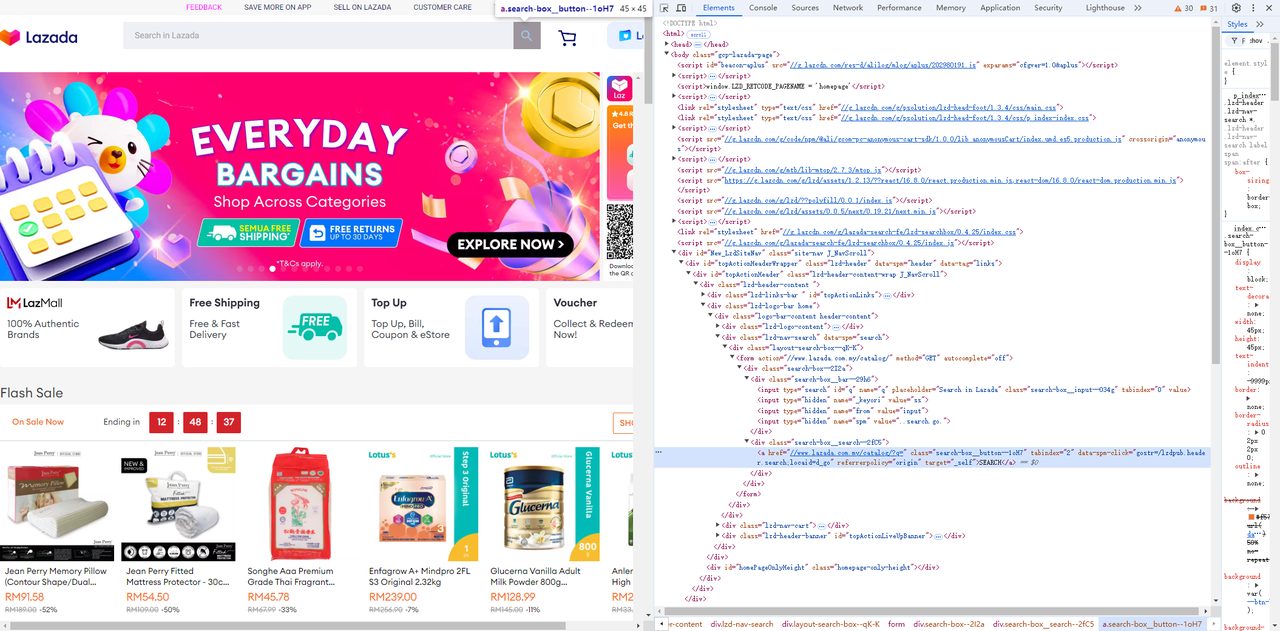
Go
func searchProduct(keyword string) chromedp.Tasks {
return chromedp.Tasks{
// wait for input element is visible
chromedp.WaitVisible(`input[type=search]`, chromedp.ByQuery),
// Enter the searched product.
chromedp.SendKeys("input[type=search]", keyword, chromedp.ByQuery),
// Click search
chromedp.Click(".search-box__button--1oH7", chromedp.ByQuery),
}
}- उत्पाद सूची से मूल्य, शीर्षक और छवि तत्व प्राप्त करें:
-
उत्पाद सूची
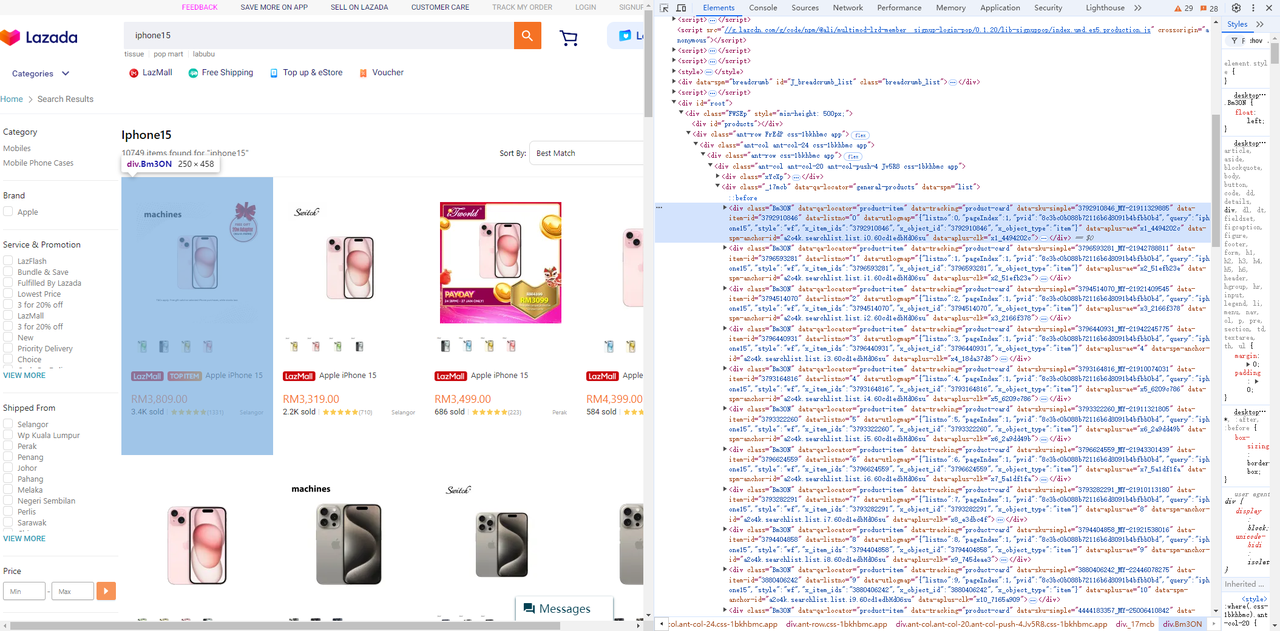
-
छवि तत्व
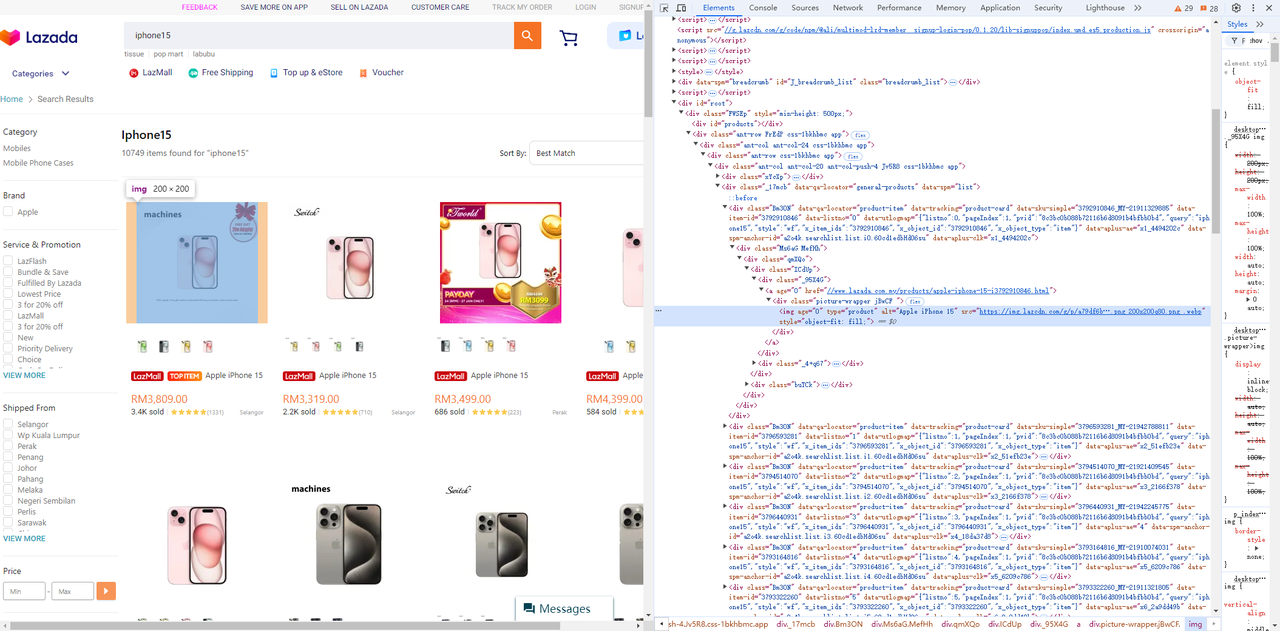
-
शीर्षक तत्व
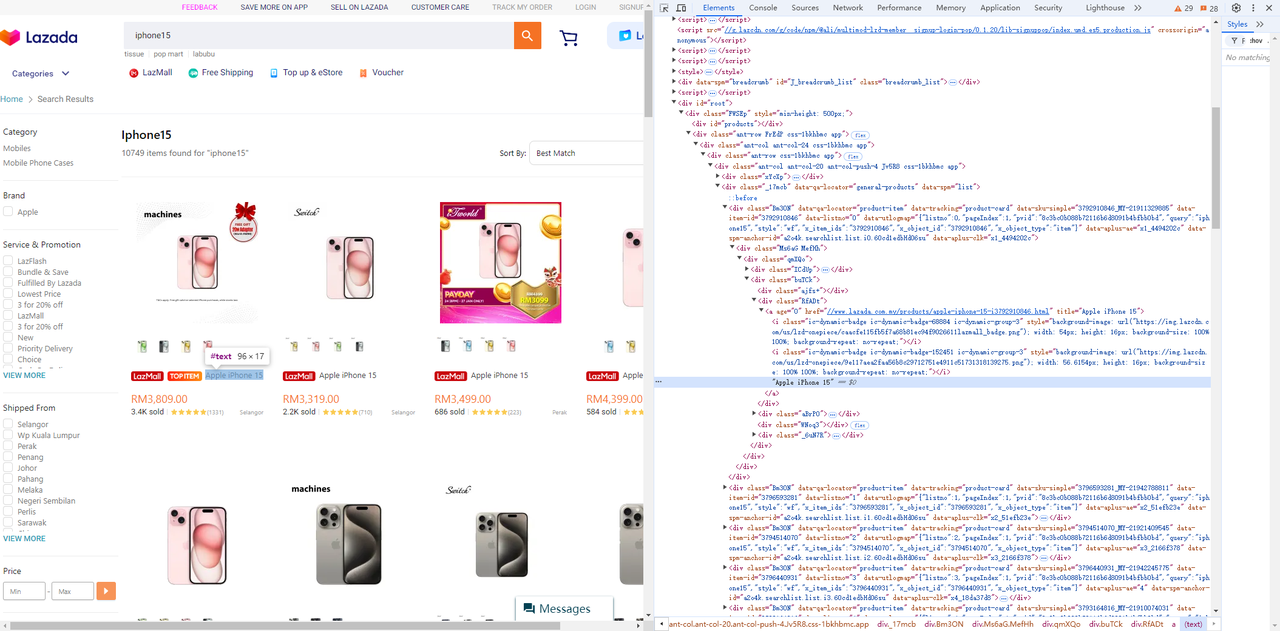
-
मूल्य तत्व
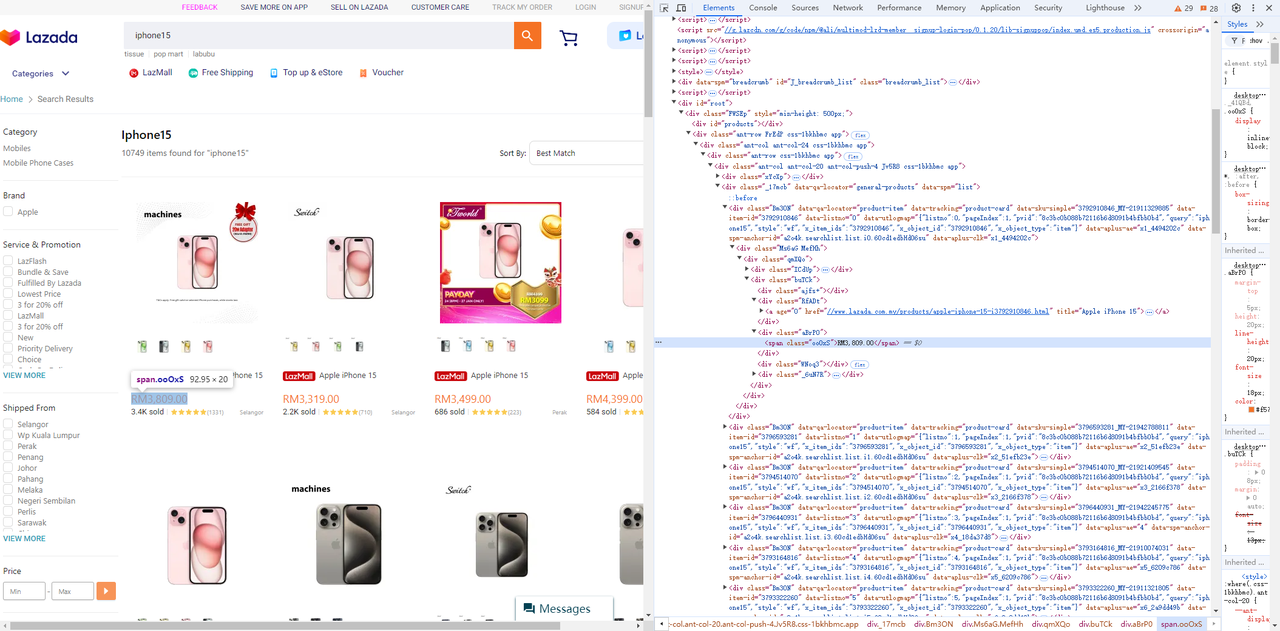
Go
func getNodes(nodes *[]*cdp.Node) chromedp.Tasks {
return chromedp.Tasks{
chromedp.WaitReady(`div[data-spm=list] .Bm3ON`, chromedp.ByQuery),
scrollToBottom(), // Scroll to the bottom to ensure that all page elements are rendered.
chromedp.Nodes("div[data-spm=list] .Bm3ON", nodes, chromedp.ByQueryAll),
}
}
func scrollToBottom() chromedp.Action {
return chromedp.ActionFunc(func(ctx context.Context) error {
for i := 0; i < 4; i++ { // Scroll repeatedly to ensure that all pictures are loaded.
_ = chromedp.Evaluate("window.scrollBy(0, window.innerHeight);", nil).Do(ctx)
time.Sleep(1 * time.Second)
}
return nil
})
}
func getProductData(ctx context.Context, node *cdp.Node) (*Product, error) {
product := new(Product)
err := chromedp.Run(ctx,
chromedp.WaitVisible(".Bm3ON img[type=product]", chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON img[type=product]", "src", &product.Img, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON .RfADt a", "title", &product.Title, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.TextContent(".Bm3ON .aBrP0 span", &product.Price, chromedp.ByQuery, chromedp.FromNode(node)),
)
if err != nil {
return nil, err
}
return product, nil
}क्रोम वातावरण सेट करें
आसान डिबगिंग के लिए, हम PowerShell में एक क्रोम ब्राउज़र लॉन्च कर सकते हैं और एक रिमोट डिबगिंग पोर्ट निर्दिष्ट कर सकते हैं।
PowerShell
chrome.exe --remote-debugging-port=9223हम ब्राउज़र के उजागर रिमोट डिबगिंग एड्रेस, webSocketDebuggerUrl को पुनः प्राप्त करने के लिए http://localhost:9223/json/list तक पहुँच सकते हैं।
PowerShell
[
{
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=localhost:9223/devtools/page/85CE4D807D11D30D5F22C1AA52461080",
"id": "85CE4D807D11D30D5F22C1AA52461080",
"title": "localhost:9223/json/list",
"type": "page",
"url": "http://localhost:9223/json/list",
"webSocketDebuggerUrl": "ws://localhost:9223/devtools/page/85CE4D807D11D30D5F22C1AA52461080"
}
]कोड चलाएँ
पूरा कोड इस प्रकार है:
Go
package main
import (
"context"
"encoding/json"
"flag"
"log"
"time"
"github.com/chromedp/cdproto/cdp"
"github.com/chromedp/chromedp"
)
type Product struct {
ID string `json:"id"`
Img string `json:"img"`
Price string `json:"price"`
Title string `json:"title"`
}
func main() {
product := flag.String("product", "iphone15", "your product keyword")
url := flag.String("webSocketDebuggerUrl", "", "your websocket url")
flag.Parse()
var baseCxt context.Context
if *url != "" {
baseCxt, _ = chromedp.NewRemoteAllocator(context.Background(), *url)
} else {
baseCxt = context.Background()
}
ctx, cancel := chromedp.NewContext(
baseCxt,
)
defer cancel()
var nodes []*cdp.Node
err := chromedp.Run(ctx,
chromedp.Navigate(`https://www.lazada.com.my/`),
searchProduct(*product),
getNodes(&nodes),
)
products := make([]*Product, 0, len(nodes))
for _, v := range nodes {
product, err := getProductData(ctx, v)
if err != nil {
log.Println("run node task err: ", err)
continue
}
products = append(products, product)
}
if err != nil {
log.Fatal(err)
}
jsonData, _ := json.Marshal(products)
log.Println(string(jsonData))
}
func searchProduct(keyword string) chromedp.Tasks {
return chromedp.Tasks{
// wait for input element is visible
chromedp.WaitVisible(`input[type=search]`, chromedp.ByQuery),
// Enter the searched product.
chromedp.SendKeys("input[type=search]", keyword, chromedp.ByQuery),
// Click search
chromedp.Click(".search-box__button--1oH7", chromedp.ByQuery),
}
}
func getNodes(nodes *[]*cdp.Node) chromedp.Tasks {
return chromedp.Tasks{
chromedp.WaitReady(`div[data-spm=list] .Bm3ON`, chromedp.ByQuery),
scrollToBottom(), // Scroll to the bottom to ensure that all page elements are rendered.
chromedp.Nodes("div[data-spm=list] .Bm3ON", nodes, chromedp.ByQueryAll),
}
}
func scrollToBottom() chromedp.Action {
return chromedp.ActionFunc(func(ctx context.Context) error {
for i := 0; i < 4; i++ { // Scroll repeatedly to ensure that all pictures are loaded.
_ = chromedp.Evaluate("window.scrollBy(0, window.innerHeight);", nil).Do(ctx)
time.Sleep(1 * time.Second)
}
return nil
})
}
func getProductData(ctx context.Context, node *cdp.Node) (*Product, error) {
product := new(Product)
err := chromedp.Run(ctx,
chromedp.WaitVisible(".Bm3ON img[type=product]", chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON img[type=product]", "src", &product.Img, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON .RfADt a", "title", &product.Title, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.TextContent(".Bm3ON .aBrP0 span", &product.Price, chromedp.ByQuery, chromedp.FromNode(node)),
)
if err != nil {
return nil, err
}
product.ID = node.AttributeValue("data-item-id")
return product, nil
}निम्न कमांड चलाकर, आपको स्क्रैप किया गया डेटा परिणाम प्राप्त होगा:
PowerShell
go run .\crawl.go -product="YOU KEYWORD"-webSocketDebuggerUrl="YOU WEBSOCKETDEBUGGERURL"
JSON
[
{
"id": "3792910846",
"img": "https://img.lazcdn.com/g/p/a79df6b286a0887038c16b7600e38f4f.png_200x200q75.png_.webp",
"price": "RM3,809.00",
"title": "Apple iPhone 15"
},
{
"id": "3796593281",
"img": "https://img.lazcdn.com/g/p/627828b5fa28d708c5b093028cd06069.png_200x200q75.png_.webp",
"price": "RM3,319.00",
"title": "Apple iPhone 15"
},
{
"id": "3794514070",
"img": "https: //img.lazcdn.com/g/p/6f4ddc2693974398666ec731a713bcfd.jpg_200x200q75.jpg_.webp",
"price": "RM3,499.00",
"title": "Apple iPhone 15"
},
{
"id": "3796440931",
"img": "https://img.lazcdn.com/g/p/8df101af902d426f3e3a9748bafa7513.jpg_200x200q75.jpg_.webp",
"price": "RM4,399.00",
"title": "Apple iPhone 15"
},
......
{
"id": "3793164816",
"img": "https://img.lazcdn.com/g/p/b6c3498f75f1215f24712a25799b0d19.png_200x200q75.png_.webp",
"price": "RM3,799.00",
"title": "Apple iPhone 15"
},
{
"id": "3793322260",
"img": "https: //img.lazcdn.com/g/p/67199db1bd904c3b9b7ea0ce32bc6ace.png_200x200q75.png_.webp",
"price": "RM5,644.00",
"title": "[Ready Stock] Apple iPhone 15 Pro"
},
{
"id": "3796624559",
"img": "https://img.lazcdn.com/g/p/81a814a9c829afa200fbc691c9a0c30c.png_200x200q75.png_.webp",
"price": "RM6,679.00",
"title": "Apple iPhone 15 Pro (1TB)"
}
]स्केलेबल आपके वेब क्रॉलर के लिए उन्नत तकनीकें
आपके वेब क्रॉलिंग में सुधार की आवश्यकता है! ब्लॉक किए जाने या अधिभारित किए जाने के बिना प्रभावी ढंग से डेटा एकत्र करने के लिए, आपको ऐसी तकनीकों को लागू करना होगा जो गति, विश्वसनीयता और संसाधन अनुकूलन को संतुलित करती हैं।
आइए कुछ उन्नत रणनीतियों का पता लगाएँ ताकि यह सुनिश्चित हो सके कि आपका क्रॉलर भारी कार्यभार के तहत उत्कृष्ट प्रदर्शन करता है।
अपने अनुरोध और सत्र को बनाए रखें
वेब क्रॉलिंग करते समय, थोड़े समय में बहुत अधिक अनुरोधों से सर्वर पर बमबारी करना पता चलने और प्रतिबंधित होने का एक निश्चित तरीका है। वेबसाइटें अक्सर एक ही क्लाइंट से अनुरोधों की आवृत्ति की निगरानी करती हैं, और अचानक वृद्धि से एंटी-बॉट तंत्र सक्रिय हो सकते हैं।
Go
package main
import (
"fmt"
"io/ioutil"
"net/http"
"time"
)
func main() {
// Create a reusable HTTP client
client := &http.Client{}
// URLs to crawl
urls := []string{
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3",
}
// Interval between requests (e.g., 2 seconds)
requestInterval := 2 * time.Second
for _, url := range urls {
// Create a new HTTP request
req, _ := http.NewRequest("GET", url, nil)
req.Header.Set("User-Agent", "Mozilla/5.0 (compatible; WebCrawler/1.0)")
// Send the request
resp, err := client.Do(req)
if err != nil {
fmt.Println("Error:", err)
continue
}
// Read and print the response
body, _ := ioutil.ReadAll(resp.Body)
fmt.Printf("Response from %s:\n%s\n", url, body)
resp.Body.Close()
// Wait before sending the next request
time.Sleep(requestInterval)
}
}डुप्लिकेट लिंक से बचें
एक ही URL को दो बार क्रॉल करने में संसाधन बर्बाद करने से बुरा कुछ नहीं है। पहले से देखे गए पृष्ठों को ट्रैक करने के लिए URL सेट (जैसे, हैश मैप या Redis डेटाबेस) को बनाए रखकर एक मज़बूत डुप्लिकेशन सिस्टम लागू करें। यह न केवल बैंडविड्थ बचाता है, बल्कि यह यह भी सुनिश्चित करता है कि आपका क्रॉलर कुशलतापूर्वक काम करता है और नए पृष्ठों को याद नहीं करता है।
आईपी प्रतिबंध से बचने के लिए प्रॉक्सी प्रबंधन।
बड़े पैमाने पर स्क्रैपिंग अक्सर एंटी-बॉट उपायों को ट्रिगर करता है, जिससे आईपी प्रतिबंध लगते हैं। इससे बचने के लिए, अपने क्रॉलर में प्रॉक्सी रोटेशन को एकीकृत करें।
- कई आईपी पर अनुरोधों को वितरित करने के लिए प्रॉक्सी पूल का उपयोग करें।
- अपने अनुरोधों को अलग-अलग उपयोगकर्ताओं और स्थानों से उत्पन्न होने के रूप में दिखाने के लिए गतिशील रूप से प्रॉक्सी घुमाएँ।
विशिष्ट पृष्ठों को प्राथमिकता दें
विशिष्ट पृष्ठों को प्राथमिकता देने से आपकी क्रॉलिंग प्रक्रिया को कारगर बनाने में मदद मिलती है और आपको उपयोग योग्य लिंक क्रॉल करने पर ध्यान केंद्रित करने देता है। वर्तमान क्रॉलर में, हम केवल पृष्ठांकन लिंक को लक्षित करने और मूल्यवान उत्पाद जानकारी निकालने के लिए CSS चयनकर्ताओं का उपयोग करते हैं।
हालाँकि, यदि आप किसी पृष्ठ पर सभी लिंक में रुचि रखते हैं और पृष्ठांकन को प्राथमिकता देना चाहते हैं, तो आप एक अलग कतार बनाए रख सकते हैं और पहले पृष्ठांकन लिंक को संसाधित कर सकते हैं।
Go
package main
import (
"fmt"
"github.com/gocolly/colly"
)
// ...
// create variables to separate pagination links from other links
var paginationURLs = []string{}
var otherURLs = []string{}
func main() {
// ...
}
func crawl (currenturl string, maxdepth int) {
// ...
// ----- find and visit all links ---- //
// select the href attribute of all anchor tags
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
// get absolute URL
link := e.Request.AbsoluteURL(e.Attr("href"))
// check if the current URL has already been visited
if link != "" && !visitedurls[link] {
// add current URL to visitedURLs
visitedurls[link] = true
if e.Attr("class") == "page-numbers" {
paginationURLs = append(paginationURLs, link)
} else {
otherURLs = append(otherURLs, link)
}
}
})
// ...
// process pagination links first
for len(paginationURLs) > 0 {
nextURL := paginationURLs[0]
paginationURLs = paginationURLs[1:]
visitedurls[nextURL] = true
err := c.Visit(nextURL)
if err != nil {
fmt.Println("Error visiting page:", err)
}
}
// process other links
for len(otherURLs) > 0 {
nextURL := otherURLs[0]
otherURLs = otherURLs[1:]
visitedurls[nextURL] = true
err := c.Visit(nextURL)
if err != nil {
fmt.Println("Error visiting page:", err)
}
}
}Scrapeless स्क्रैपिंग API: प्रभावी क्रॉलिंग टूल
Scrapeless स्क्रैपिंग API अधिक आदर्श क्यों है?
Scrapeless स्क्रैपिंग API वेबसाइटों से डेटा निकालने की प्रक्रिया को सरल बनाने के लिए डिज़ाइन किया गया है और यह सबसे जटिल वेब वातावरणों को नेविगेट कर सकता है, प्रभावी रूप से गतिशील सामग्री और जावास्क्रिप्ट रेंडरिंग का प्रबंधन कर सकता है।
इसके अलावा, Scrapeless स्क्रैपिंग API एक वैश्विक नेटवर्क का लाभ उठाता है जो 195 देशों में फैला हुआ है, जो 70 मिलियन से अधिक आवासीय आईपी तक पहुँच द्वारा समर्थित है। 99.9% अपटाइम और असाधारण सफलता दर के साथ, Scrapeless आसानी से आईपी ब्लॉक और CAPTCHA जैसी चुनौतियों को पार कर जाता है, जिससे यह जटिल वेब ऑटोमेशन और AI-संचालित डेटा संग्रह के लिए एक मज़बूत समाधान बन जाता है।
हमारे उन्नत स्क्रैपिंग API के साथ, आप जटिल स्क्रैपिंग स्क्रिप्ट लिखे या बनाए रखे बिना, अपनी आवश्यक डेटा तक पहुँच सकते हैं!
स्क्रैपिंग API के लाभ
Scrapeless उच्च-प्रदर्शन जावास्क्रिप्ट रेंडरिंग का समर्थन करता है, जिससे यह गतिशील सामग्री (जैसे AJAX या जावास्क्रिप्ट के माध्यम से लोड किया गया डेटा) को संभाल सकता है और आधुनिक वेबसाइटों को स्क्रैप कर सकता है जो सामग्री वितरण के लिए JS पर निर्भर करती हैं।
- किफायती मूल्य: Scrapeless असाधारण मूल्य प्रदान करने के लिए डिज़ाइन किया गया है।
- स्थिरता और विश्वसनीयता: एक सिद्ध ट्रैक रिकॉर्ड के साथ, Scrapeless स्थिर API प्रतिक्रियाएँ प्रदान करता है, भारी कार्यभार के तहत भी।
- उच्च सफलता दर: असफल निष्कर्षण को अलविदा कहें और Scrapeless Google SERP डेटा तक 99.99% सफल पहुँच का वादा करता है।
- स्केलेबिलिटी: Scrapeless के पीछे के मज़बूत बुनियादी ढाँचे के कारण, हज़ारों क्वेरीज़ को आसानी से संभालें।
अब सस्ता और शक्तिशाली Scrapeless स्क्रैपिंग API प्राप्त करें!
Scrapeless प्रतिस्पर्धी कीमतों पर एक विश्वसनीय और स्केलेबल वेब स्क्रैपिंग प्लेटफ़ॉर्म प्रदान करता है, जो अपने उपयोगकर्ताओं के लिए उत्कृष्ट मूल्य सुनिश्चित करता है:
- स्क्रैपिंग ब्राउज़र: प्रति घंटे $0.09 से
- स्क्रैपिंग API: प्रति 1k URL $1.00 से
- वेब अनलॉकर: प्रति 1k URL $0.20
- कैप्चा सॉल्वर: प्रति 1k URL $0.80 से
- प्रॉक्सी: प्रति GB $2.80
सदस्यता लेने से, आप प्रत्येक सेवा पर 20% तक की छूट का आनंद ले सकते हैं। क्या आपकी कोई विशिष्ट आवश्यकताएँ हैं? आज ही हमसे संपर्क करें, और हम आपकी आवश्यकताओं के अनुसार और भी बड़ी बचत प्रदान करेंगे!
Scrapeless स्क्रैपिंग API का उपयोग कैसे करें?
Lazada डेटा क्रॉल करने के लिए scrapeless स्क्रैपिंग API का उपयोग करना बहुत आसान है। आपको अपनी इच्छित सभी डेटा प्राप्त करने के लिए केवल एक साधारण अनुरोध की आवश्यकता है। scrapeless API को जल्दी से कैसे कॉल करें? कृपया मेरे चरणों का पालन करें:
- चरण 1। Scrapeless में लॉग इन करें
- चरण 2। "स्क्रैपिंग API" पर क्लिक करें
- चरण 3। हमारे "Lazada" API को खोजें और इसे दर्ज करें:
- चरण 4। बाईं ओर ऑपरेशन बॉक्स में आपके द्वारा क्रॉल किए जाने वाले उत्पाद की पूरी जानकारी भरें। जब आप डेटा क्रॉल करने के लिए
chromedpका उपयोग करते हैं, तो आप पहले ही क्रॉल किए गए उत्पाद की ID प्राप्त कर चुके होते हैं। अब आपको केवल उत्पाद के बारे में अधिक विस्तृत डेटा प्राप्त करने के लिए itemId पैरामीटर में ID जोड़ने की आवश्यकता है। फिर वह एक्सप्रेशन भाषा चुनें जो आप चाहते हैं:
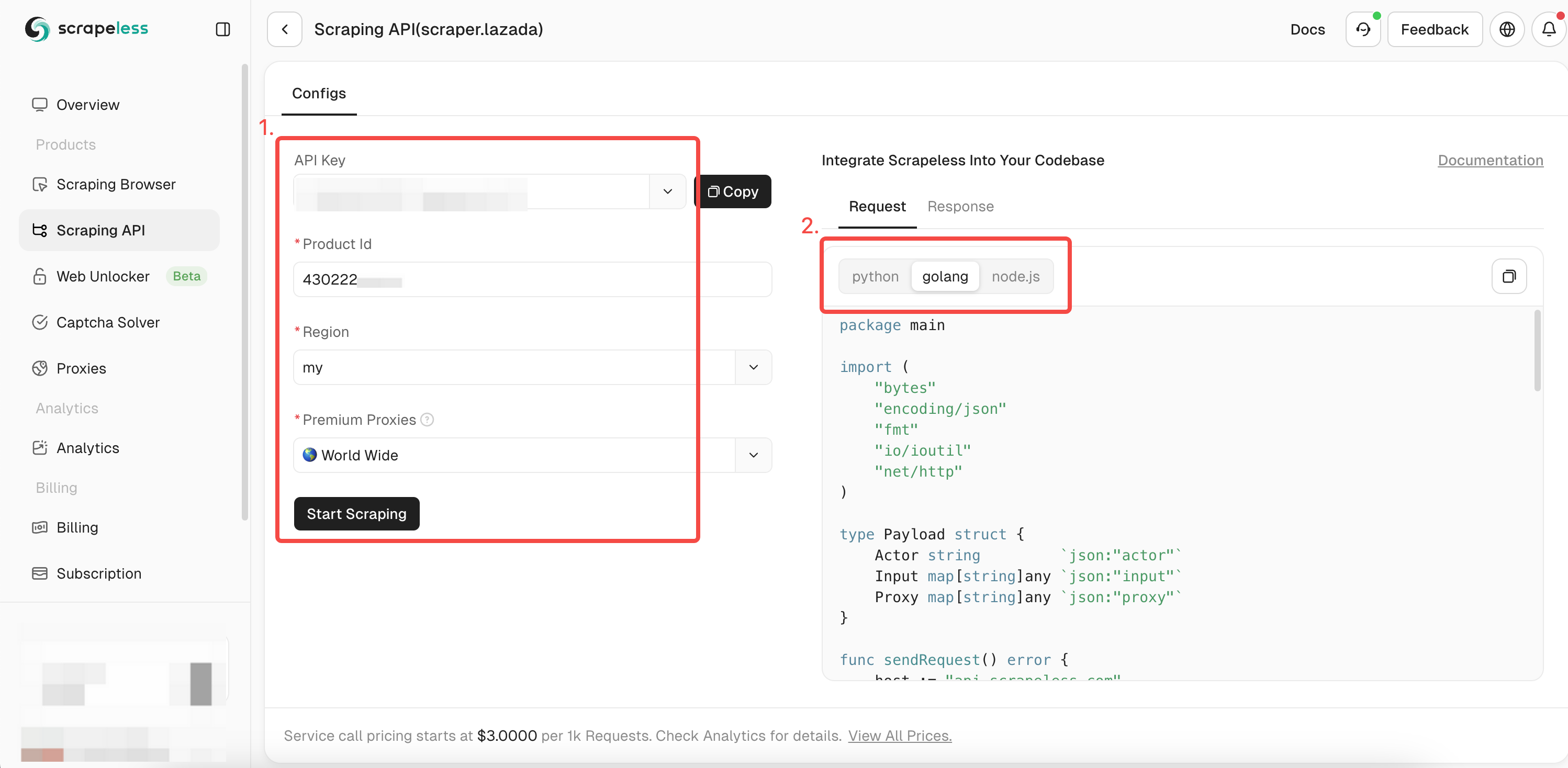
- चरण 5। "स्क्रैपिंग शुरू करें" पर क्लिक करें, और उत्पाद के क्रॉलिंग परिणाम दाईं ओर पूर्वावलोकन बॉक्स में दिखाई देंगे:
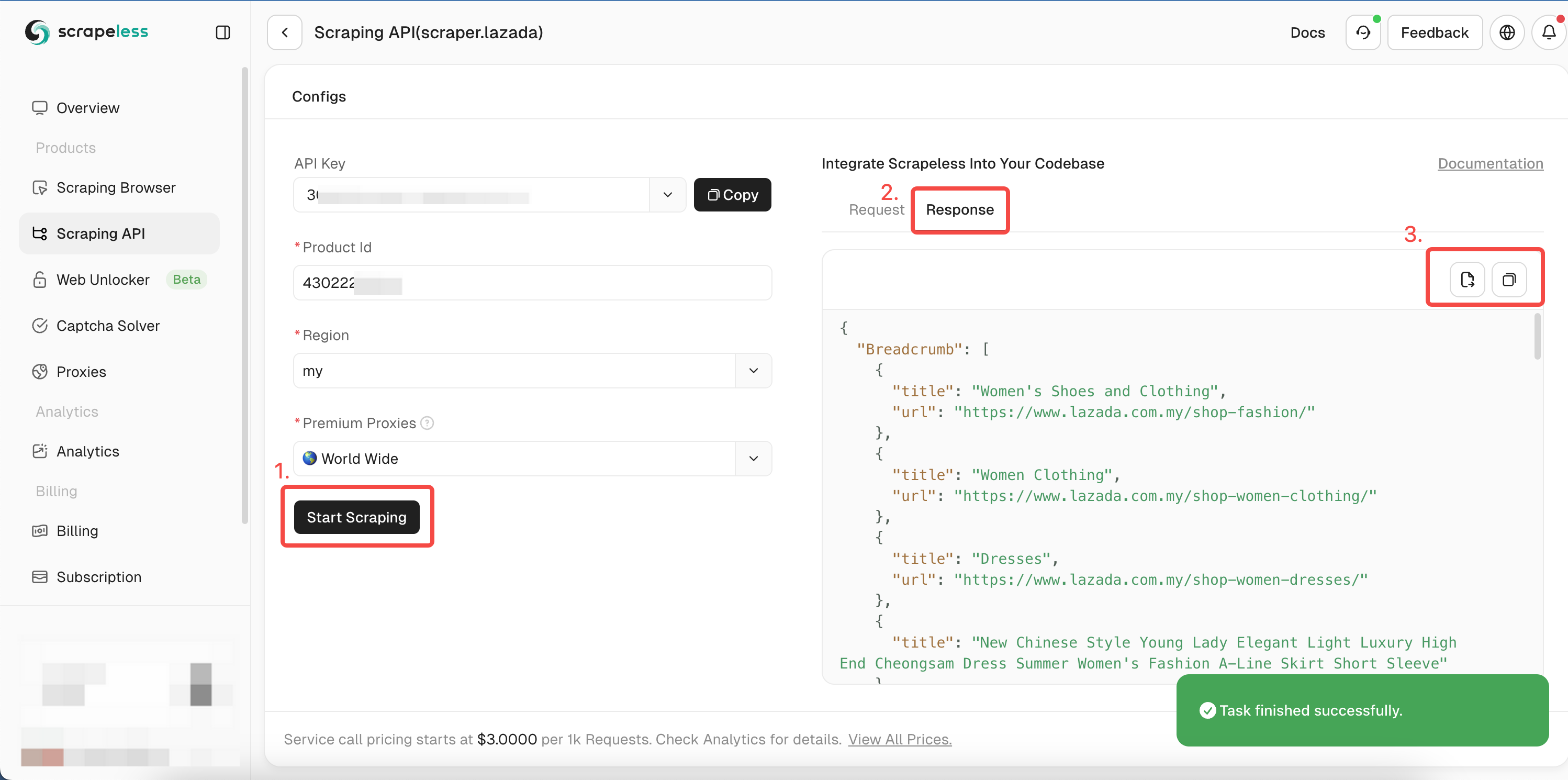
आप हमारे Golang सैंपल कोड को संदर्भित कर सकते हैं, या अन्य भाषाओं के लिए हमारे API दस्तावेज़ को देख सकते हैं।
Go
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
type Payload struct {
Actor string `json:"actor"`
Input map[string]any `json:"input"`
Proxy map[string]any `json:"proxy"`
}
func sendRequest() error {
host := "api.scrapeless.com"
url := fmt.Sprintf("https://%s/api/v1/scraper/request", host)
token := "YOU_TOKEN"
headers := map[string]string{"x-api-token": token}
inputData := map[string]any{
"itemId": "3792910846", // वह itemId डालें जिसे आप प्राप्त करना चाहते हैं।
"site": "my",
}
proxy := map[string]any{
"country": "ANY",
}
payload := Payload{
Actor: "scraper.lazada",
Input: inputData,
Proxy: proxy,
}
jsonPayload, err := json.Marshal(payload)
if err != nil {
return err
}
req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonPayload))
if err != nil {
return err
}
for key, value := range headers {
req.Header.Set(key, value)
}
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
fmt.Printf("body %s\n", string(body))
return nil
}
func main() {
err := sendRequest()
if err != nil {
fmt.Println("Error:", err)
return
}
}चलाने के बाद, आपको निम्नलिखित विस्तृत डेटा मिलेगा। इसमें लिंक, चित्र, SKU, समीक्षाएँ, वही विक्रेता आदि शामिल हैं।
स्पेस की सीमाओं के कारण, हम यहाँ पर केवल क्रॉलिंग परिणामों का एक हिस्सा दिखाते हैं। आप हमारे डैशबोर्ड पर जाएं और एक मुफ्त ट्रायल प्राप्त करें ताकि आप जल्दी से क्रॉल कर सकें और पूर्ण परिणाम प्राप्त कर सकें!
JSON
{
"Breadcrumb": [
{
"title": "मोबाइल और टैबलेट्स",
"url": "https://www.lazada.com.my/shop-mobiles-tablets/"
},
{
"title": "स्मार्टफोन",
"url": "https://www.lazada.com.my/shop-mobiles/"
},
{
"title": "Apple iPhone 15"
}
],
"deliveryOptions": {
"21911329880": [
{
"badge": false,
"dataType": "delivery",
"deliveryWorkTimeMax": "2025-01-27T23:27+08:00[GMT+08:00]",
"deliveryWorkTimeMin": "2025-01-24T23:27+08:00[GMT+08:00]",
"description": "स्थानीय सामानों के लिए, आप अपने आइटम को 2-4 कार्य दिवसों में प्राप्त कर सकते हैं। <br/>शिपिंग शुल्क उस विक्रेता से खरीदी गई उत्पादों के कुल आकार/वजन के आधार पर निर्धारित किया जाता है।<br/><br/><a href=\"https://www.lazada.com.my/helpcenter/shipping_delivery/#answer-faq-whatisshippingfee-ans\" target=\"_blank\">अधिक जानें</a>",
"duringTime": "24-27 जनवरी तक सुनिश्चित",
"fee": "RM4.90",
"feeValue": 4.9,
"hasTip": true,
"title": "मानक वितरण",
"type": "standard"
},
{
"badge": true,
"dataType": "service",
"description": "",
"feeValue": 0,
"hasTip": true,
"title": "कैश ऑन डिलीवरी उपलब्ध नहीं है",
"type": "noCOD"
}
],
"21911329881": [
{
"badge": false,
"dataType": "delivery",
"deliveryWorkTimeMax": "2025-01-27T23:27+08:00[GMT+08:00]",
"deliveryWorkTimeMin": "2025-01-24T23:27+08:00[GMT+08:00]",
"description": "स्थानीय सामानों के लिए, आप अपने आइटम को 2-4 कार्य दिवसों में प्राप्त कर सकते हैं। <br/>शिपिंग शुल्क उस विक्रेता से खरीदी गई उत्पादों के कुल आकार/वजन के आधार पर निर्धारित किया जाता है।<br/><br/><a href=\"https://www.lazada.com.my/helpcenter/shipping_delivery/#answer-faq-whatisshippingfee-ans\" target=\"_blank\">अधिक जानें</a>",
"duringTime": "24-27 जनवरी तक सुनिश्चित",
"fee": "RM4.90",
"feeValue": 4.9,
"hasTip": true,
"title": "मानक वितरण",
"type": "standard"
},
{
"badge": true,
"dataType": "service",
"description": "",
"feeValue": 0,
"hasTip": true,
"title": "कैश ऑन डिलीवरी उपलब्ध नहीं है",
"type": "noCOD"
}
],
...आगे की पढ़ाई
- Shopee उत्पाद विवरण को स्क्रैप करने के पूर्ण चरण
- Google Trends डेटा को जल्दी और आसानी से कैसे स्क्रैप करें?
- Google Flights API का उपयोग करके सस्ते फ्लाइट्स ट्रैक करने के चरण प्राप्त करें!
Golang क्रॉलिंग सर्वोत्तम प्रथाएँ और विचार
समानांतर क्रॉलिंग और समानांतरता
कई पृष्ठों को समकालिक रूप से स्क्रैप करने से अप्रभावी हो सकता है क्योंकि किसी भी समय केवल एक गोरोटिन सक्रिय रूप से कार्यों को संभाल सकता है। आपका वेब क्रॉलर अपना अधिकांश समय प्रतिक्रियाओं का इंतजार करने और डेटा प्रोसेस करने में बिता देता है, फिर अगला कार्य शुरू करता है।
हालांकि, Go की समानांतरता की क्षमताओं का लाभ उठाकर समानांतर क्रॉलिंग की कोशिश करना आपके समग्र क्रॉलिंग समय को महत्वपूर्ण रूप से घटा सकता है!
हालांकि, आपको उपयुक्त रूप से समानांतरता का प्रबंधन करना चाहिए ताकि लक्षित सर्वर को अधिक न लोड करें और एंटी-बॉट प्रतिबंधों को ट्रिगर न करें।
Go में JavaScript रेंडर्ड पृष्ठों को क्रॉल करना
हालाँकि Colly एक शानदार वेब क्रॉलर टूल है जिसमें कई अंतर्निहित विशेषताएँ हैं, यह JavaScript रेंडर्ड पृष्ठों (डायनेमिक सामग्री) को क्रॉल नहीं कर सकता। यह केवल स्थिर HTML को फेच और पार्स कर सकता है, और डायनेमिक सामग्री वेबसाइट के स्थिर HTML में मौजूद नहीं होती है।
हालांकि, आप हेडलैस ब्राउज़र या JavaScript इंजन के साथ एकीकृत करके डायनेमिक सामग्री को क्रॉल कर सकते हैं।
अंतिम विचार
आपने सीखा कि कैसे गोलैंग वेब क्रॉलर बनाएं और उन्नत प्रोग्रामिंग का उपयोग करें। ध्यान रखें कि वेब ब्राउज़ करने के लिए एक वेब स्क्रैपर बनाना एक शानदार शुरुआत है, लेकिन आपको आधुनिक वेबसाइटों तक पहुँचने के लिए एंटी-बॉट उपायों को पार करना होगा।
मैन्युअल कॉन्फ़िगरेशन से जूझने की बजाय, जो शायद विफल हो, Scrapeless Scraping API पर विचार करें, जो किसी भी एंटी-बॉट सिस्टम को बायपास करने के लिए सबसे विश्वसनीय समाधान है।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


